机器学习-K聚类代码详解(含例子)
第一步:标准化以下是个人学习理解的K聚类算法,欢迎大家指正错误。另外代码在结尾哦~整个过程和底部代码环环相扣,可以边看代码边看这边的解读。选择的数据一般是数值类的,可以参考代码,我选择了5列,共300行数据(这里我使用numpy模拟的工业数据,大家可以自行模拟一个csv数据)第一步:标准化所谓标准化就是把一些单位不统一的数据归成近似0或1的数据,变成了一个300*5的矩阵,如下(打印代码中的X_s
声明:以下是个人学习理解的K聚类算法,欢迎大家指正错误。另外代码在结尾哦~
聚类大致过程:选择合适的列数据后,标准化->找k->聚类分组->降维可视化->结果分析
整个过程和底部代码环环相扣,可以边看代码边看这边的解读。选择的数据一般是数值类的,可以参考代码,我选择了5列,共300行数据(这里我使用numpy模拟的工业数据,大家可以自行模拟一个csv数据)

第一步:标准化
所谓标准化就是把一些单位不统一的数据归成近似0或1的数据,变成了一个300*5的矩阵,如下(打印代码中的X_scaled即可):

第二步:利用肘部法找k
设置一个k的范围,每个k都会计算出一个组内平方和,n_init参数是找初始质心的次数(每次循环找到k个最合适的质心),判断方式就是由陡变缓的那个k,如图所示:
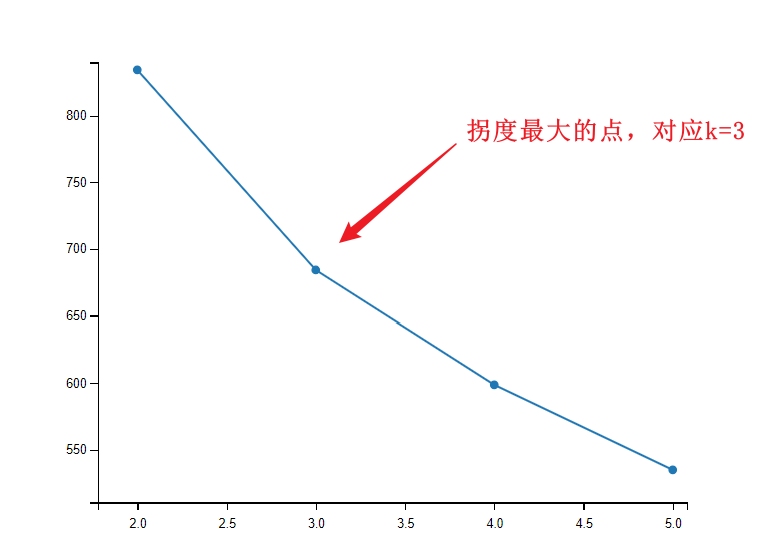
第三步:聚类分组。
300份数据都需要对应一个类别。之前已经得出k为3,所以有3个类别(对应0、1、2),输出内容如下(打印代码中的clustering_results即可):

第四步:降维可视化以及绘图。
设置n_components=2,即降成二维。大家平时见到的k聚类散点图都是通过坐标点的形式做出的,所以这里当然需要进行一个降维操作,将原先标准化的300行数据转化为坐标的形式,如下(打印main_contituent即可):

对于绘图。有了坐标,那么直接画出散点图即可。注意将参数clustering_results传入,以此来区分各个类别。三个类别刚好三种颜色,如下图:(注意如果你的聚类图很多颜色的点串在一起,说明k的设置可能有问题)
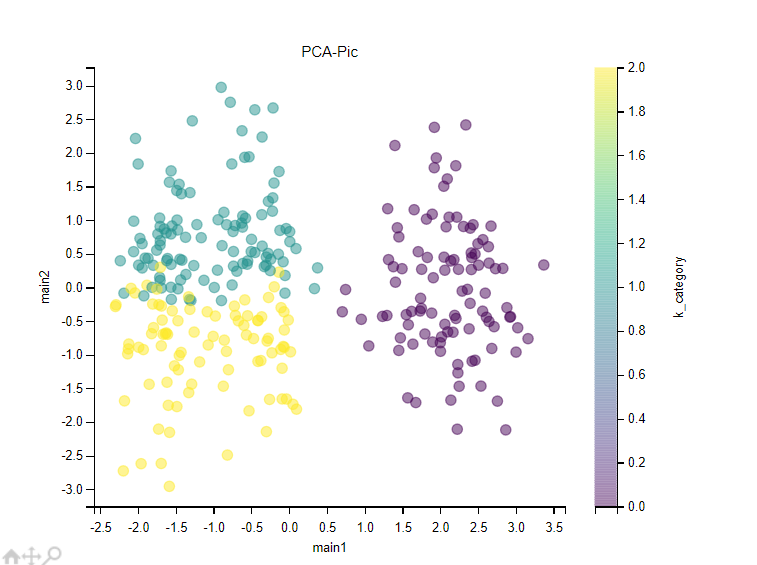
第五步:分析
有人可能想到,这样的一个图像有啥用?
先看下面结果,最右侧列为“所属簇”,也就是说,每一份数据我都知道它属于哪个类了,而这些类的定义,你可以根据的得出的各个簇的平均值来定义。比如下面的结果中,0簇的电机温度是1.16,注意这里的温度是经过处理的数据,均值为0,而1.16已经超过了1,所以说0号簇的相关数据存在温度过高的情况(注意0号簇不代表某类机器,它反映的是设备在特定时间点的运行状态,而非设备本身的固有属性),具体分析如下:
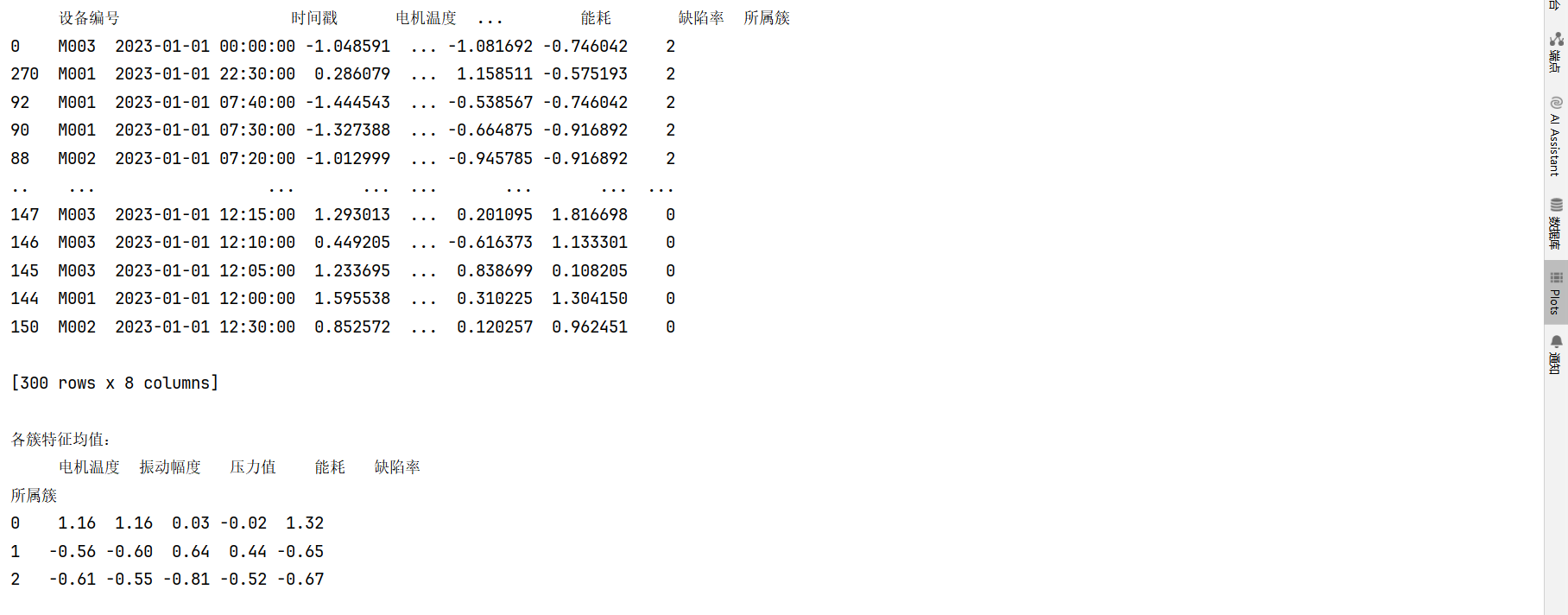
做出定义如下:
簇特征分析(标准化值)
| 簇类 | 电机温度 | 振动幅度 | 压力值 | 能耗 | 缺陷率 | 核心特征 |
|---|---|---|---|---|---|---|
| 0 | +1.16 | +1.16 | +0.03 | -0.02 | +1.32 | 高温、高振动、高缺陷 |
| 1 | -0.56 | -0.60 | +0.64 | +0.44 | -0.65 | 低温、低振动、高压力 |
| 2 | -0.61 | -0.55 | -0.81 | -0.52 | -0.67 | 全面低值(节能健康状态) |
-
簇0是异常状态:
-
温度、振动、缺陷率均超均值1σ以上
-
典型故障模式(如轴承磨损导致温升和振动加剧)
-
-
簇1特殊工况:
-
异常高压力(+0.64σ)但其他参数正常
-
可能原因:系统短时过载运行
-
-
簇2理想状态:
-
所有参数显著低于均值
-
对应设备低负荷高效运行时段
-
另一个角度分析(代码的最后一次打印):
设备-簇分布(比例)
| 设备编号 | 簇0(异常) | 簇1(高压) | 簇2(健康) |
|---|---|---|---|
| M001 | 33% | 37% | 29% |
| M002 | 27% | 41% | 32% |
| M003 | 39% | 32% | 29% |
-
M002:
-
健康状态占比最高(32%)
-
但高压工况占比达41%(需检查压力控制系统)
-
-
M003:
-
异常状态占比最高(39%)
-
优先安排全面检修
-
-
M001:
-
各状态分布相对均衡
-
建议增加实时监控频率
-
综上,针对相应的分析结果,你可以对不同的簇类别进行合适的决策。这就是K-Means的大致流程和作用。
六、代码
# 聚类分析
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
# 读取数据
df = pd.read_csv('industrial_data_cn.csv')
# 数据预处理
X = df[['电机温度', '振动幅度', '压力值', '能耗', '缺陷率']] # 选择5个参数,与产量无关
# 第一步-标准化处理
scaler = StandardScaler() # 对象
X_scaled = scaler.fit_transform(X) # 标准化后的矩阵,形状为(300,5)(300个样本,5个特征),300行5列,把所有的数据归整为一个近似1的数
# 第二步(可选)-肘部法找k
wcss=[]
for i in range(2,6):
kmeans=KMeans(n_clusters=i, random_state=42,n_init=10)
kmeans.fit(X_scaled)
wcss.append(kmeans.inertia_)
plt.plot(range(2,6),wcss,marker='o') # 添加上下文
plt.show() # k值是图像从陡变缓的那个点
# 第三步-找到k=3,进行分组
kmeans = KMeans(n_clusters=3, n_init=10, random_state=42) # 可以选择手动调整k值,或者利用肘部法
clustering_results = kmeans.fit_predict(X_scaled) # # 聚类结果,三个类别有三个族标签,0,1,2,
# 第四步-PCA可视化,降维可视化
pca = PCA(n_components=2)
main_constituent = pca.fit_transform(X_scaled) # 主成分,将所有的数据变成一个二维坐标,相当于300个坐标点
# 绘图
plt.scatter(main_constituent[:, 0], main_constituent[:, 1], #以第0列作为x坐标,第1列作为y,进行散点图绘制
c=clustering_results,alpha=0.7) # 注意clustering_results会作为颜色序列,0,1,2分别代表不同颜色
plt.xlabel('main1') # 主成分1
plt.ylabel('main2')
plt.title('PCA-Pic') # PCA降维可视化
plt.colorbar(label='k_category')
plt.show()
# 第五步-结果分析,clustering_data作为一个DataFrame
clustering_data = pd.concat([ # 聚类数据,进行合并。利用concat合并
df[['设备编号', '时间戳']], # 明确指定非数值类型,前面增加两列
pd.DataFrame(X_scaled, columns=X.columns), # 原有的5列,这里的5列数据已经进行了处理,正负值都有,加上列名
pd.Series(clustering_results, name='所属簇') # 增加一列Series,并且命名
], axis=1) # 竖着合并
print(clustering_data.sort_values('所属簇', ascending=False)) # 排序分类
# 修正后的均值计算
print("\n各簇特征均值:")
print(clustering_data[['电机温度', '振动幅度', '压力值', '能耗', '缺陷率', '所属簇']].groupby('所属簇').mean().round(2))
# 另一个角度分析
print('--------------------')
device_cluster_dist = clustering_data.groupby('设备编号')['所属簇'].value_counts(normalize=True)
print(device_cluster_dist.unstack().fillna(0).round(2))
脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐

 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)