【案例解释】模型测试指标项介绍:理解召回率、精确率与F1分数
本文以**医疗影像AI模型(肺炎检测)**为例,详细介绍这些指标的计算方法、曲线分析及实际应用场景。精确率(Precision,又称。调整置信度阈值,以优化模型性能。召回率(Recall,又称。在机器学习模型的评估中,在实际应用中,需根据。
·
模型测试指标项介绍:理解召回率、精确率与F1分数
在机器学习模型的评估中,召回率(Recall)、精确率(Precision)和F1分数(F1-Score) 是关键的性能指标。本文以**医疗影像AI模型(肺炎检测)**为例,详细介绍这些指标的计算方法、曲线分析及实际应用场景。
1. 基本概念:TP、TN、FP、FN
在二分类问题中,模型的预测结果可以分为以下四种情况: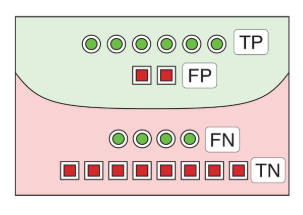
| 指标 | 含义 | 医疗案例解释 |
|---|---|---|
| TP(True Positive,真阳性) | 模型预测为正类,实际为正类 | 病人是肺炎,系统正确诊断为肺炎 |
| TN(True Negative,真阴性) | 模型预测为负类,实际为负类 | 病人不是肺炎,系统正确诊断为非肺炎 |
| FP(False Positive,假阳性) | 模型预测为正类,实际为负类 | 病人不是肺炎,系统误诊为肺炎(误报) |
| FN(False Negative,假阴性) | 模型预测为负类,实际为正类 | 病人是肺炎,系统漏诊为非肺炎(漏报) |
2. 召回率(Recall)
定义
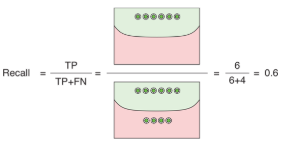
召回率(Recall,又称查全率)衡量的是模型能检测出多少真实的正类样本,计算公式为:
召回率-置信度曲线(Recall-Confidence Curve)
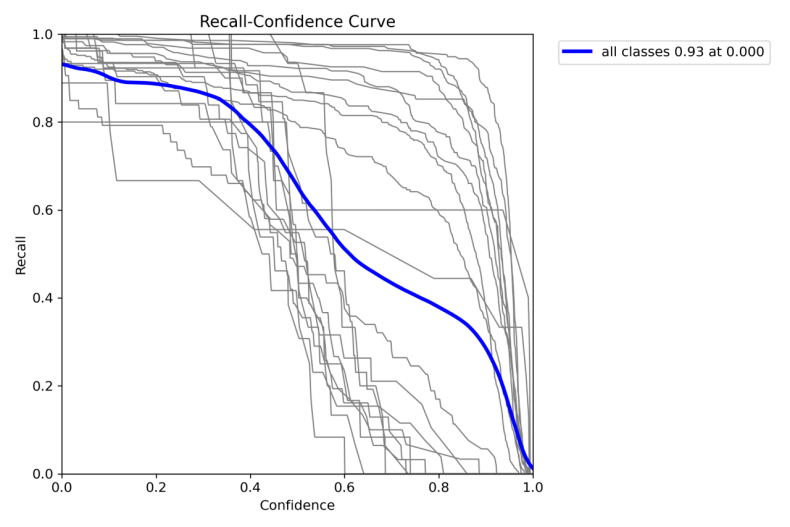
- 横轴(Confidence):模型对预测结果的置信度(0.0~1.0)。
- 纵轴(Recall):召回率(0.0~1.0)。
关键点分析:
- 当 置信度阈值=0.0 时,召回率=0.93(图中最高点)。
- 含义:模型对所有样本都预测为“肺炎”,能检测出93%的真实肺炎患者。
- 问题:误诊率(FP)极高,许多健康人会被错误归类。
适用场景:
- 疾病筛查(如新冠检测),宁可误诊也不能漏诊。
3. 精确率(Precision)
定义
精确率(Precision,又称查准率)衡量的是模型预测为正类的样本中有多少是正确的,计算公式为:

精确率-置信度曲线(Precision-Confidence Curve)
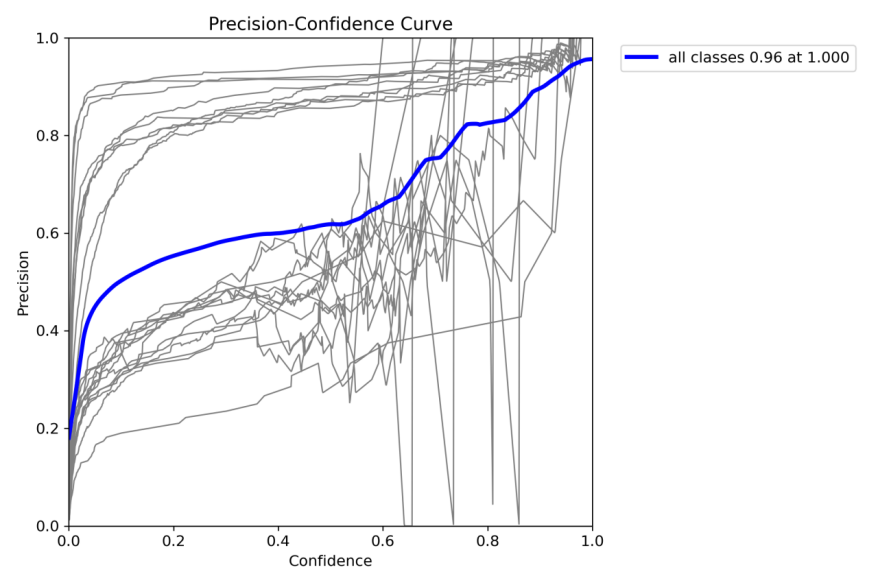
- 横轴(Confidence):模型对预测结果的置信度(0.0~1.0)。
- 纵轴(Precision):精确率(0.0~1.0)。
关键点分析:
- 当 置信度阈值=1.0 时,精确率=0.96(图中最高点)。
- 含义:模型仅在100%确定时才诊断为肺炎,此时96%的预测是正确的。
- 问题:漏诊率(FN)高,许多真实患者未被检测到。
适用场景:
- 高风险诊断(如癌症确诊),必须确保预测结果高度可靠。
4. F1分数(F1-Score)
定义
F1分数是精确率和召回率的调和平均数,用于综合评估模型性能,计算公式为:

F1-置信度曲线(F1-Confidence Curve)
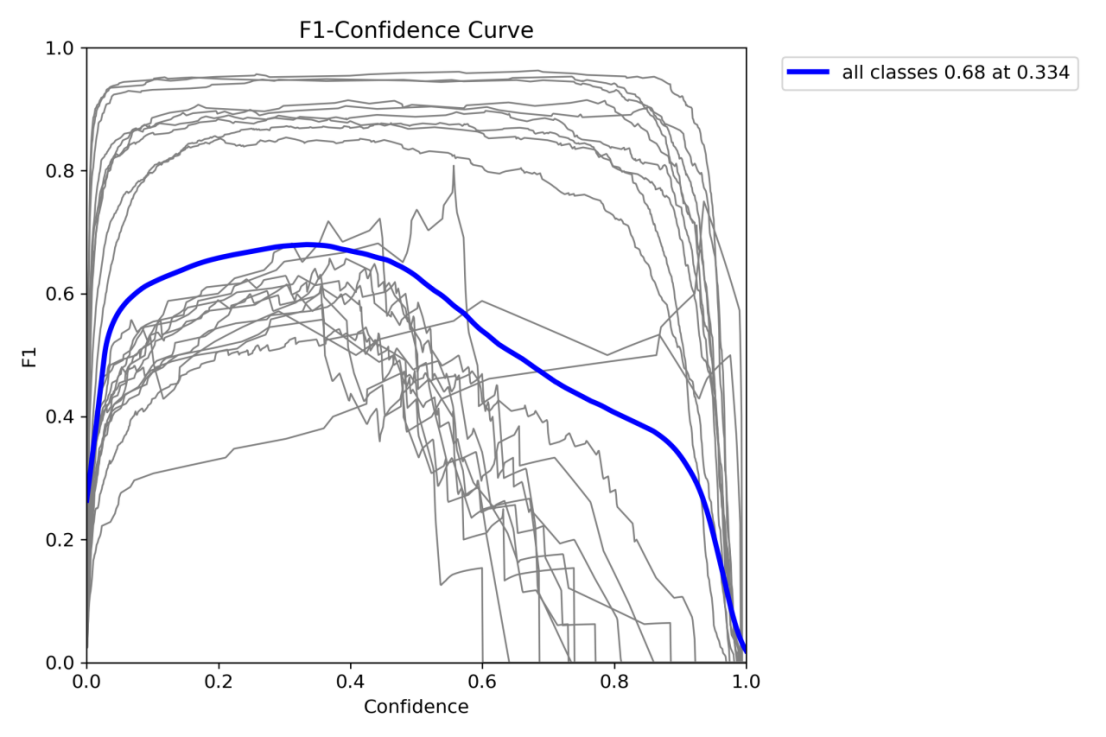
- 横轴(Confidence):模型对预测结果的置信度(0.0~1.0)。
- 纵轴(F1):F1分数(0.0~1.0)。
关键点分析:
- 当 置信度阈值=0.334 时,F1=0.68(图中最佳点)。
- 含义:此时模型在精确率和召回率之间取得最佳平衡。
- 适用场景:普通医疗诊断,既不过于激进(高FP),也不过于保守(高FN)。
5. 如何选择最佳置信度阈值?
| 业务需求 | 推荐阈值 | 优先指标 | 案例 |
|---|---|---|---|
| 绝不能误诊(如癌症确诊) | 高阈值(如0.8~1.0) | 精确率 | 只有模型高度确信时才治疗,避免误诊。 |
| 绝不能漏诊(如传染病筛查) | 低阈值(如0.0~0.3) | 召回率 | 所有疑似病例均需检测,避免漏诊。 |
| 平衡误诊和漏诊 | 中阈值(如0.3~0.5) | F1分数 | 普通肺炎诊断,兼顾准确性和覆盖率。 |
6. 总结
- 召回率(Recall):关注“不漏诊”,适用于筛查场景。
- 精确率(Precision):关注“不误诊”,适用于高风险诊断。
- F1分数:平衡误诊和漏诊,适用于一般医疗决策。
在实际应用中,需根据业务需求调整置信度阈值,以优化模型性能。
平均精度均值(mAP)介绍:https://developer.baidu.com/article/details/3211523

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐

 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)