权重剪枝技术理论概述
随着深度学习模型在计算机视觉、自然语言处理等领域的广泛应用,模型规模呈指数级增长。例如,GPT-4参数量达到1.8万亿,这对计算资源和部署环境提出了严峻挑战。权重剪枝(Weight Pruning)作为模型压缩的核心技术,通过删除冗余参数实现模型轻量化,同时保持性能稳定。
目录
随着深度学习模型在计算机视觉、自然语言处理等领域的广泛应用,模型规模呈指数级增长。例如,GPT-4参数量达到1.8万亿,这对计算资源和部署环境提出了严峻挑战。权重剪枝(Weight Pruning)作为模型压缩的核心技术,通过删除冗余参数实现模型轻量化,同时保持性能稳定。
1.权重剪枝的核心原理
深度学习模型存在大量冗余参数,主要体现在:
1.参数重要性差异:部分参数对输出的影响可忽略不计(如接近零的权重);
2.结构冗余:卷积层中的通道冗余、全连接层中的神经元冗余;
3.表达冗余:不同参数组合可产生相似的功能输出;
实验表明,ResNet-50在ImageNet上达到76.1%准确率时,可剪枝至原参数量的5%而性能基本不变。权重剪枝可视为带约束的优化问题:

剪枝的三个阶段
1.训练初始化:预训练完整模型
2.剪枝执行:根据剪枝标准删除参数
3.重训练优化:微调剩余参数恢复性能
2.常用剪枝方法
常用剪枝方法有幅度剪枝,L1 正则化剪枝,通道剪枝,块剪枝,彩票假设,动态稀疏训练。
2.1 幅度剪枝
幅度剪枝是一种简单且直观的权重剪枝方法,其核心基于这样一个假设:在神经网络中,绝对值较小的权重对模型输出的贡献相对较小,因此可以将这些权重移除而不会对模型的性能产生显著影响。通过删除这些不重要的权重,能够减少模型的参数数量,降低模型的复杂度和计算量。

1.实现步骤
1.计算所有权重的绝对值:将神经网络中所有层的权重提取出来,并计算它们的绝对值。
2.确定阈值:根据预设的剪枝比例,对所有绝对值进行排序,选取合适的阈值 θ,使得绝对值小于 θ 的权重数量占总权重数量的比例达到预设的剪枝比例。
3.生成掩码:根据阈值生成掩码矩阵,掩码矩阵中的元素与权重矩阵中的元素一一对应,绝对值大于或等于 θ 的位置对应掩码矩阵中的元素为 1,否则为 0。
4.应用掩码:将权重矩阵与掩码矩阵进行逐元素乘法,得到剪枝后的权重矩阵。
2.简要的python源码如下:
import torch
def magnitude_prune(model, pruning_ratio):
all_weights = []
for name, param in model.named_parameters():
if 'weight' in name:
all_weights.extend(param.view(-1).abs().tolist())
all_weights.sort()
threshold_index = int(len(all_weights) * pruning_ratio)
threshold = all_weights[threshold_index]
masks = {}
for name, param in model.named_parameters():
if 'weight' in name:
mask = (torch.abs(param) >= threshold).float()
masks[name] = mask
param.data *= mask
return model, masks
# 示例使用
import torch.nn as nn
# 定义一个简单的神经网络
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(10, 20)
self.fc2 = nn.Linear(20, 1)
def forward(self, x):
x = self.fc1(x)
x = torch.relu(x)
x = self.fc2(x)
return x
model = SimpleNet()
pruned_model, masks = magnitude_prune(model, 0.2)通过上述程序,可以将那些幅度较小的权重进行剪除,因为它们对模型的影响可能较小。相反,幅度大的权重通常认为更重要,不宜删除。
2.2 L1正则化剪枝
L1正则化剪枝是在神经网络的训练过程中引入L1正则化项,通过对权重的绝对值之和进行惩罚,使得一些权重的值趋近于 0。L1正则化具有稀疏化的特性,能够促使模型自动将一些不重要的权重置为0,从而实现剪枝的目的。与幅度剪枝不同,L1正则化剪枝是在训练过程中动态地进行剪枝,而不是在训练完成后进行一次性剪枝。

1.实现步骤
定义损失函数:在原有的损失函数基础上,加入 L1 正则化项。
训练模型:使用加入正则化的损失函数进行模型训练,在训练过程中,L1 正则化会使得一些权重的值逐渐趋近于 0。
阈值化:训练完成后,根据预设的阈值,将绝对值小于阈值的权重置为 0,得到剪枝后的模型。
2.简要的python源码如下:
import torch
import torch.nn as nn
import torch.optim as optim
# 定义一个简单的神经网络
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(10, 20)
self.fc2 = nn.Linear(20, 1)
def forward(self, x):
x = self.fc1(x)
x = torch.relu(x)
x = self.fc2(x)
return x
model = SimpleNet()
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
lambda_l1 = 0.001
# 训练模型
for epoch in range(100):
inputs = torch.randn(32, 10)
labels = torch.randn(32, 1)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
l1_reg = torch.tensor(0., requires_grad=True)
for name, param in model.named_parameters():
if 'weight' in name:
l1_reg = l1_reg + torch.norm(param, 1)
total_loss = loss + lambda_l1 * l1_reg
total_loss.backward()
optimizer.step()
# 阈值化
threshold = 1e-3
for name, param in model.named_parameters():
if 'weight' in name:
mask = (torch.abs(param) >= threshold).float()
param.data *= mask2.3 通道剪枝
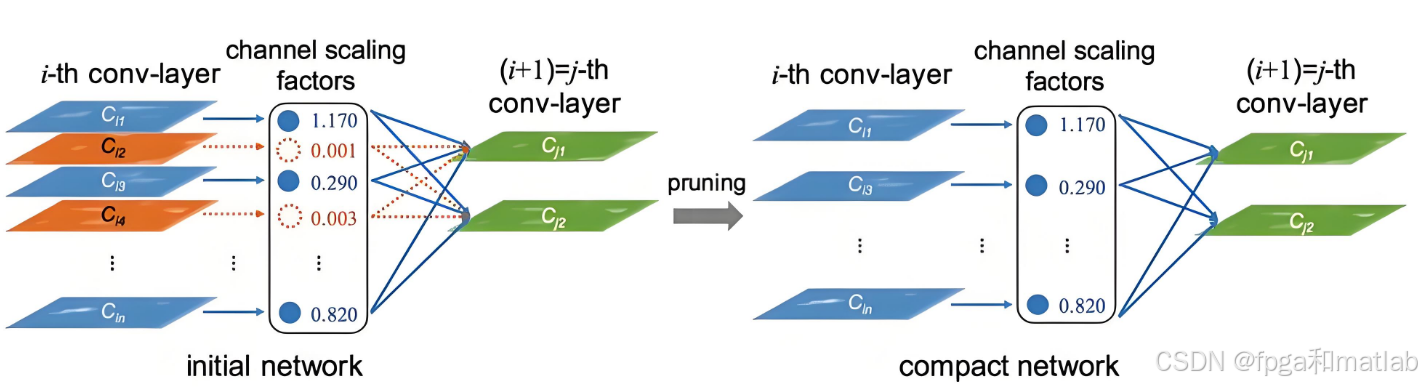
通道剪枝是一种结构化剪枝方法,它针对卷积神经网络中的卷积层进行剪枝。在卷积神经网络中,每个卷积层通常由多个卷积核组成,每个卷积核对应一个通道。通道剪枝的核心思想是评估每个通道的重要性,然后删除那些重要性较低的通道,从而减少卷积层的计算量和参数数量。
计算通道重要性的一种常见方法是计算通道内所有权重的绝对值之和:

1.实现步骤
计算通道重要性:对于每个卷积层,计算每个通道的重要性。
排序:根据通道重要性对所有通道进行排序。
选择保留通道:根据预设的剪枝比例,选择重要性较高的前M个通道保留。
重构卷积层:删除不重要的通道,重构卷积层的权重和偏置。
2.简要的python源码如下:
import torch
import torch.nn as nn
def channel_prune(model, pruning_ratio):
for name, module in model.named_modules():
if isinstance(module, nn.Conv2d):
channel_importance = []
for c in range(module.out_channels):
importance = torch.sum(torch.abs(module.weight[c]))
channel_importance.append(importance.item())
sorted_indices = sorted(range(len(channel_importance)), key=lambda k: channel_importance[k])
num_channels_to_keep = int(module.out_channels * (1 - pruning_ratio))
kept_indices = sorted_indices[-num_channels_to_keep:]
module.weight = nn.Parameter(module.weight[kept_indices])
if module.bias is not None:
module.bias = nn.Parameter(module.bias[kept_indices])
return model
# 示例使用
model = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(16, 32, kernel_size=3, padding=1)
)
pruned_model = channel_prune(model, 0.2)2.4 块剪枝
块剪枝也是一种结构化剪枝方法,它将权重矩阵划分为多个不重叠的块,然后评估每个块的重要性,删除那些重要性较低的块。块剪枝可以在不同的粒度上进行,例如按行、按列或按固定大小的子矩阵进行划分。与非结构化剪枝相比,块剪枝可以更好地利用硬件的并行计算能力,提高计算效率。

1.实现步骤
划分块:将权重矩阵划分为多个不重叠的块。
计算块的重要性:计算每个块的 Frobenius 范数。
排序:根据块的重要性对所有块进行排序。
选择保留块:根据预设的剪枝比例,选择重要性较高的前 M 个块保留。
重构权重矩阵:删除不重要的块,重构权重矩阵。
2.简要的python源码如下:
import torch
import torch.nn as nn
def block_prune(model, pruning_ratio, block_size):
for name, param in model.named_parameters():
if 'weight' in name:
weight = param.data
num_blocks_h = weight.size(0) // block_size
num_blocks_w = weight.size(1) // block_size
block_importance = []
for i in range(num_blocks_h):
for j in range(num_blocks_w):
block = weight[i * block_size:(i + 1) * block_size, j * block_size:(j + 1) * block_size]
importance = torch.norm(block, p='fro')
block_importance.append((importance.item(), (i, j)))
sorted_blocks = sorted(block_importance, key=lambda x: x[0])
num_blocks_to_keep = int(num_blocks_h * num_blocks_w * (1 - pruning_ratio))
kept_blocks = sorted_blocks[-num_blocks_to_keep:]
new_weight = torch.zeros_like(weight)
for _, (i, j) in kept_blocks:
new_weight[i * block_size:(i + 1) * block_size, j * block_size:(j + 1) * block_size] = weight[
i * block_size:(i + 1) * block_size, j * block_size:(j + 1) * block_size]
param.data = new_weight
return model
# 示例使用
model = nn.Linear(10, 20)
pruned_model = block_prune(model, 0.2, 2)2.5 Lottery Ticket假设
Lottery Ticket假设是由Frankle 和Carbin在2018年提出的一个重要理论。该假设认为,在一个随机初始化的大型神经网络中,存在一个子网络,这个子网络在经过相同的初始化和训练过程后,能够达到与原网络相当甚至更好的性能。Lottery Ticket假设的核心思想是,神经网络的训练过程实际上是在寻找这个的过程,而权重剪枝可以帮助我们发现这个子网络。

1.实现步骤
训练完整模型:使用随机初始化的权重矩阵W0训练一个完整的神经网络。
剪枝:根据一定的剪枝标准(如幅度剪枝),得到掩码矩阵M。
重置权重:将剪枝后的权重矩阵重置为初始值W0⊙M。
训练子网络:使用重置后的权重矩阵训练子网络。
2.简要的python源码如下:
import torch
import torch.nn as nn
import torch.optim as optim
# 定义一个简单的神经网络
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(10, 20)
self.fc2 = nn.Linear(20, 1)
def forward(self, x):
x = self.fc1(x)
x = torch.relu(x)
x = self.fc2(x)
return x
# 步骤 1:训练完整模型
model = SimpleNet()
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
for epoch in range(100):
inputs = torch.randn(32, 10)
labels = torch.randn(32, 1)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 步骤 2:剪枝
pruning_ratio = 0.2
masks = {}
for name, param in model.named_parameters():
if 'weight' in name:
all_weights = param.view(-1).abs().tolist()
all_weights.sort()
threshold_index = int(len(all_weights) * pruning_ratio)
threshold = all_weights[threshold_index]
mask = (torch.abs(param) >= threshold).float()
masks[name] = mask
param.data *= mask
# 步骤 3:重置权重
initial_weights = {}
for name, param in model.named_parameters():
if 'weight' in name:
initial_weights[name] = param.data.clone()
for name, param in model.named_parameters():
if 'weight' in name:
param.data = initial_weights[name] * masks[name]
# 步骤 4:训练子网络
optimizer = optim.SGD(model.parameters(), lr=0.01)
for epoch in range(100):
inputs = torch.randn(32, 10)
labels = torch.randn(32, 1)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()2.6 动态稀疏训练
动态稀疏训练是一种在训练过程中动态调整模型稀疏性的方法。与传统的先训练后剪枝或在训练过程中固定稀疏率的方法不同,动态稀疏训练允许模型在训练过程中根据当前的训练状态和损失函数动态地增加或减少稀疏性。这种方法可以更好地平衡模型的性能和稀疏性,避免了传统剪枝方法可能出现的性能下降问题。
在动态稀疏训练中,目标函数通常由三部分组成:

1.实现步骤
初始化模型和稀疏率:随机初始化模型的权重,并设置初始的稀疏率。
训练模型:在训练过程中,根据目标函数 Lsparse 进行优化。
动态调整稀疏率:根据训练的进展和损失函数的变化,动态地调整模型的稀疏率。可以通过调整 λ 和 μ 的值来实现。
剪枝和重连:在训练过程中,定期进行剪枝和重连操作,删除不重要的权重,并重新连接一些权重以保持模型的表达能力。
2.简要的python源码如下:
import torch
import torch.nn as nn
import torch.optim as optim
# 定义一个简单的神经网络
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(10, 20)
self.fc2 = nn.Linear(20, 1)
def forward(self, x):
x = self.fc1(x)
x = torch.relu(x)
x = self.fc2(x)
return x
model = SimpleNet()
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
lambda_l1 = 0.001
mu = 0.0001
target_sparsity = 0.2
# 训练模型
for epoch in range(100):
inputs = torch.randn(32, 10)
labels = torch.randn(32, 1)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
l1_reg = torch.tensor(0., requires_grad=True)
l0_reg = torch.tensor(0., requires_grad=True)
for name, param in model.named_parameters():
if 'weight' in name:
l1_reg = l1_reg + torch.norm(param, 1)
l0_reg = l0_reg + torch.nonzero(param).size(0)
total_loss = loss + lambda_l1 * l1_reg + mu * l0_reg
total_loss.backward()
optimizer.step()
# 动态调整稀疏率
current_sparsity = 0
total_params = 0
for name, param in model.named_parameters():
if 'weight' in name:
total_params += param.numel()
current_sparsity += torch.sum(param == 0).item()
current_sparsity /= total_params
if current_sparsity < target_sparsity:
mu *= 1.1
elif current_sparsity > target_sparsity:
mu /= 1.1
# 剪枝和重连操作(简单示例:按幅度剪枝)
if epoch % 10 == 0:
for name, param in model.named_parameters():
if 'weight' in name:
all_weights = param.view(-1).abs().tolist()
all_weights.sort()
threshold_index = int(len(all_weights) * target_sparsity)
threshold = all_weights[threshold_index]
mask = (torch.abs(param) >= threshold).float()
param.data *= mask3.剪枝性能分析
以常用的LLaMA模型为例子。
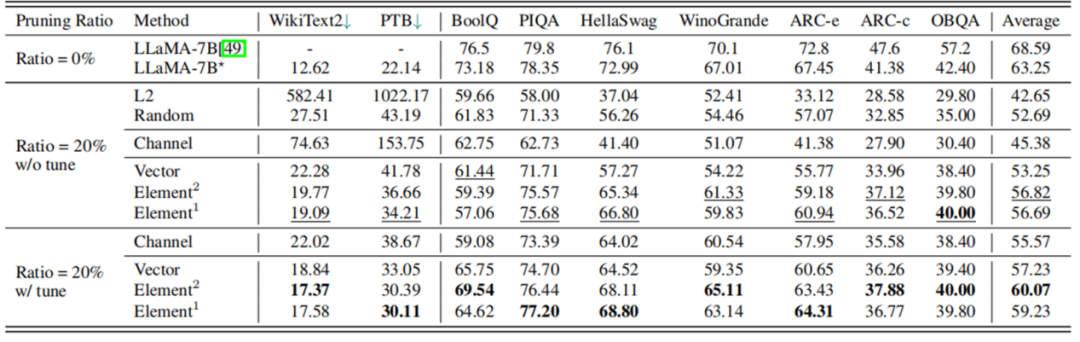
实验结果表明,剪枝20%后,模型的性能为原模型的89.8%,经过LoRA微调后,性能可提升至原模型的94.97%。在大多数数据集上,剪枝后的5.4B LLaMA甚至优于ChatGLM-6B,所以如果需要一个具有定制尺寸的更小的模型,理论上用LLM-Pruner剪枝一个比再训练一个成本更低效果更好。
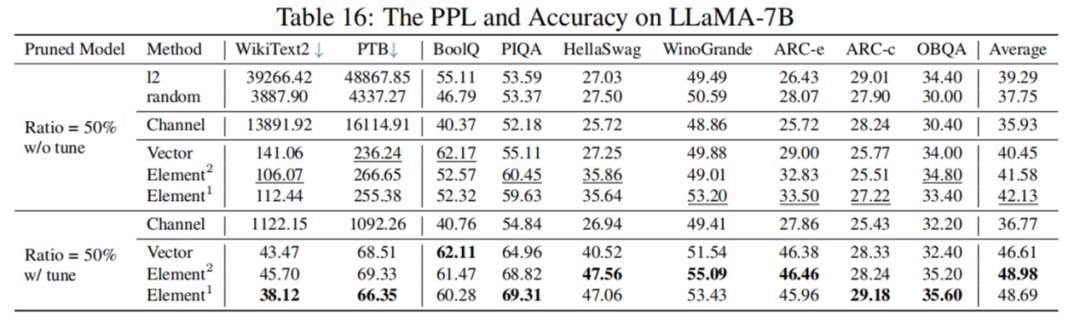
实验结果表明,剪枝50%后模型表现并不理想,LoRA微调后综合指标也仅为原模型77.44%,性能下降幅度较大。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 29
29 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)