# 缓解过拟合之Dropout+正则化
是两种最常用的抗过拟合技术,通过限制模型复杂度或引入随机性,显著提升模型的泛化能力。本文将详解它们的原理、实现方法及实战技巧。:在损失函数中添加权重绝对值之和(L1范数),迫使模型学习稀疏权重(部分权重为0),实现特征选择。:在损失函数中添加权重平方和(L2范数),使权重均匀小化,避免单个特征对预测过度影响。随机“关闭”神经元,迫使网络学习冗余特征,测试时恢复所有神经元并缩放输出。:结合L1的稀疏
Dropout与正则化:深度学习中的过拟合克星
在深度学习中,模型复杂度与过拟合风险往往成正比。正则化与Dropout是两种最常用的抗过拟合技术,通过限制模型复杂度或引入随机性,显著提升模型的泛化能力。本文将详解它们的原理、实现方法及实战技巧。
1. 正则化:约束模型权重的艺术
1.1 L1正则化(Lasso)
核心思想:在损失函数中添加权重绝对值之和(L1范数),迫使模型学习稀疏权重(部分权重为0),实现特征选择。
公式:
Ltotal=原始损失+λ∑∣wi∣ \mathcal{L}_{\text{total}} = \text{原始损失} + \lambda \sum |w_i| Ltotal=原始损失+λ∑∣wi∣
应用场景:
- 高维稀疏数据(如文本分类)。
- 需要解释重要特征的任务(如金融风控)。
代码示例(Scikit-Learn):
from sklearn.linear_model import Lasso
model = Lasso(alpha=0.1) # alpha控制L1强度
model.fit(X_train, y_train)
1.2 L2正则化(Ridge)
核心思想:在损失函数中添加权重平方和(L2范数),使权重均匀小化,避免单个特征对预测过度影响。
公式:
Ltotal=原始损失+λ2∑wi2 \mathcal{L}_{\text{total}} = \text{原始损失} + \frac{\lambda}{2} \sum w_i^2 Ltotal=原始损失+2λ∑wi2
应用场景:
- 回归问题(如房价预测)。
- 神经网络全连接层的权重约束。
代码示例(Keras):
from tensorflow.keras import regularizers
model.add(Dense(64, activation='relu',
kernel_regularizer=regularizers.l2(0.01)))
1.3 Elastic Net(L1+L2混合)
核心思想:结合L1的稀疏性与L2的权重平滑性,适用于特征相关性强的高维数据。
公式:
Ltotal=原始损失+λ1∑∣wi∣+λ2∑wi2 \mathcal{L}_{\text{total}} = \text{原始损失} + \lambda_1 \sum |w_i| + \lambda_2 \sum w_i^2 Ltotal=原始损失+λ1∑∣wi∣+λ2∑wi2
2. Dropout:随机屏蔽的鲁棒性训练
核心思想:在训练时以概率 ppp 随机“关闭”神经元,迫使网络学习冗余特征,测试时恢复所有神经元并缩放输出。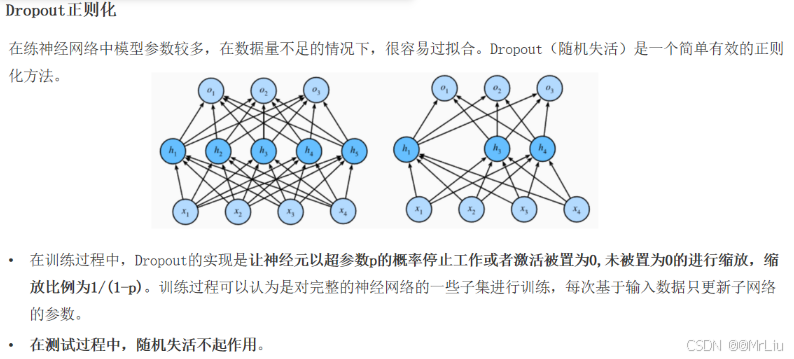
公式:
h^i={0概率 phi1−p概率 1−p \hat{h}_i = \begin{cases} 0 & \text{概率 } p \\ \frac{h_i}{1-p} & \text{概率 } 1-p \end{cases} h^i={01−phi概率 p概率 1−p
优势:
- 类似集成学习(多个子网络的平均效果)。
- 显著减少过拟合,尤其在深层网络中。
代码示例(PyTorch):
import torch.nn as nn
model = nn.Sequential(
nn.Linear(100, 50),
nn.ReLU(),
nn.Dropout(p=0.5), # 50%概率关闭神经元
nn.Linear(50, 10)
)
2.1 Dropout变种
- Spatial Dropout:在卷积层中按通道屏蔽,保留空间结构。
- Alpha Dropout:适用于自归一化网络(如SELU激活函数)。
3. 正则化 vs Dropout:对比与选择
| 特征 | L1/L2正则化 | Dropout |
|---|---|---|
| 作用方式 | 惩罚权重值 | 随机屏蔽神经元连接 |
| 适用场景 | 线性模型、全连接层 | 深层神经网络 |
| 稀疏性 | L1产生稀疏权重 | 不直接稀疏化 |
| 计算开销 | 无额外计算 | 训练时增加随机操作 |
4. 实战应用与调参技巧
4.1 图像分类(CNN)
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
model = Sequential([
Conv2D(32, (3,3), activation='relu', input_shape=(64,64,3)),
MaxPooling2D(2,2),
Conv2D(64, (3,3), activation='relu'),
MaxPooling2D(2,2),
Flatten(),
Dense(128, activation='relu', kernel_regularizer='l2'),
Dropout(0.5), # 关键层:减少过拟合
Dense(10, activation='softmax')
])
4.2 文本分类(NLP)
from transformers import BertForSequenceClassification
model = BertForSequenceClassification.from_pretrained(
'bert-base-uncased',
num_labels=2,
hidden_dropout_prob=0.3, # BERT内置Dropout
attention_probs_dropout_prob=0.1
)
4.3 超参数调优建议
- L1/L2系数:从0.001到0.1逐步尝试,观察验证损失。
- Dropout概率:
- 全连接层:0.3-0.5。
- 输入层(如嵌入层):0.1-0.2。
- 组合使用:在神经网络中同时应用L2正则化和Dropout(如ResNet)。
5. 总结
- 正则化通过数学约束限制模型复杂度,适合线性模型和小规模网络。
- Dropout通过随机性增强模型鲁棒性,是深度神经网络的标配。
- 联合使用:在复杂任务中,L2正则化(系数0.01)与Dropout(概率0.5)的组合往往效果最佳。
参考资料:
- 《深度学习》(Ian Goodfellow)
- PyTorch与TensorFlow官方文档

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 30
30 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)