Python----深度学习((Improving neural networks by preventing co-adaptation of feature detectors)解读 和 正则化)
在深度学习中,防止特征探测器间的共同适应(co-adaptation)是提高神经网络性能的重要策略。共同适应指的是特征探测器在训练过程中互相依赖,使得网络对特定的输入模式过于敏感,从而导致过拟合。通过引入正则化技术,如Dropout,可以有效减少这种适应性。在训练过程中,Dropout随机地丢弃一部分神经元,使得网络在每次迭代中都依赖于不同的子集特征,从而强迫网络学习更加鲁棒的特征表示。这不仅提高
一、论文解读
1.1、标题与作者
论文标题为《通过防止特征检测器的共适应改进神经网络》(Improving Neural Networks by Preventing Co-adaptation of Feature Detectors),由多伦多大学计算机科学系的G. E. Hinton(通讯作者)、N. Srivastava、A. Krizhevsky、I. Sutskever和R. R. Salakhutdinov合作完成,于2012年7月以预印本形式发布(arXiv编号:1207.0580v1)。Hinton作为深度学习领域的先驱之一,其团队提出的Dropout技术在此后成为神经网络正则化的核心方法之一。
1.2、摘要与核心思想
论文针对神经网络在小规模训练数据上易过拟合的问题,提出了一种名为Dropout的正则化策略。其核心思想是在训练过程中随机“丢弃”(即临时禁用)部分隐藏单元(默认丢弃率为50%),迫使剩余单元独立学习鲁棒性特征,而非依赖特定神经元组合的共适应(co-adaptation)。这种方法通过动态生成大量子网络并隐式集成其预测结果,显著提升了模型的泛化能力。实验表明,Dropout在MNIST手写数字识别、TIMIT语音识别、CIFAR-10与ImageNet物体分类等任务中均大幅降低了测试错误率,刷新了当时的性能记录。
1.3、方法原理与技术细节
Dropout的操作分为训练与测试两个阶段。训练时,每次输入样本前,每个隐藏单元以概率p=0.5p=0.5被随机丢弃,形成不同的稀疏子网络结构。这一过程迫使神经元在缺失其他单元支持的情况下,独立捕捉输入数据的通用特征。例如,在图像识别任务中,单个神经元可能被迫学习边缘或纹理等基础模式,而非依赖其他神经元修正其错误。测试时,所有神经元均被保留,但每个隐藏单元的输出权重需乘以1−p1−p(即权重减半),以补偿训练时激活概率的差异。这种“平均网络”近似等效于对指数级数量(2N2N,NN为隐藏单元数)的子网络预测进行几何平均,但其计算成本仅相当于单次前向传播。
为优化训练稳定性,论文提出对每个隐藏单元的输入权重向量施加L2范数约束,而非传统的全局权重衰减。具体而言,若权重更新后其L2范数超过阈值(如15),则通过缩放使其满足约束。这一方法有效防止了权重无界增长,并允许采用高初始学习率(如10.0)结合指数衰减策略(衰减因子0.998/epoch),从而更充分地探索参数空间。此外,动量机制从0.5逐步提升至0.99,加速收敛并平滑梯度更新。
1.4、实验验证与结果分析
论文在多个基准任务中验证了Dropout的有效性。MNIST手写数字识别任务中,未使用预训练或数据增强的标准前馈网络错误率为160,加入隐藏层50%丢弃与输入层20%丢弃后,错误率降至110;结合深度信念网络(DBN)预训练后进一步优化至77错误,显著优于传统方法。TIMIT语音识别任务中,帧分类错误率从22.7%降至19.7%,刷新了无说话人信息的记录。CIFAR-10物体分类任务中,通过引入局部连接层并结合Dropout,错误率从18.5%降至15.6%。在更具挑战性的ImageNet数据集上,单网络错误率从48.6%降至42.4%,接近集成模型的性能。此外,Reuters文本分类任务中错误率从31.05%降至29.62%,表明Dropout在非图像任务中同样有效。
实验还揭示了Dropout对特征学习的影响。通过可视化MNIST任务中第一层隐藏单元的特征(附录A.3),发现Dropout学习到的特征更简单且可解释(如笔画片段),而标准反向传播的特征则复杂且依赖上下文。这表明Dropout通过抑制共适应,迫使网络提取更基础的模式,从而提升泛化能力。
1.5、理论对比与扩展讨论
论文将Dropout与多种传统方法进行了理论对比。相较于贝叶斯模型平均(需通过MCMC采样计算后验分布),Dropout假设所有子网络权重相等,通过共享参数实现高效训练与预测。与装袋(Bagging)相比,Dropout可视为一种极端形式:每个子网络仅基于单样本训练,但参数共享提供了更强的正则化效果。此外,论文将Dropout与进化理论中的性别机制类比,指出两者均通过打破共适应(基因或神经元间的依赖)提升系统的鲁棒性,避免因环境变化(或数据分布偏移)导致的性能崩溃。
对于网络架构设计,论文指出Dropout对全连接层的效果最为显著,而卷积层因参数共享天然具备抗过拟合能力,需结合局部连接层方能体现优势(如CIFAR-10实验)。输入层的丢弃率通常低于隐藏层(如20%),且可通过自适应调整进一步提升性能。作者还推测,对于多模态任务,可设计输入相关的动态丢弃率,构建“混合专家”系统,但未深入展开。
1.6、创新意义与后续影响
Dropout的提出标志着神经网络正则化方法的重大突破。其核心创新在于通过极简的操作(随机丢弃单元)实现了高效的隐式模型集成,极大降低了过拟合风险。这一方法不仅在小数据场景下表现优异,也为大规模深度网络的训练提供了新思路。后续研究衍生出多种变体,如DropConnect(随机断开权重连接)、Zoneout(循环网络中的状态丢弃)等,进一步扩展了其应用范围。
在工业界,Dropout迅速成为深度学习模型的标准组件,被整合进TensorFlow、PyTorch等主流框架。其思想亦影响了其他技术(如批量归一化、残差连接),共同推动了深度学习的实用化进程。尽管后续研究指出Dropout在某些场景下(如极深网络)可能被其他正则化方法部分替代,但其在平衡模型容量与泛化能力方面的核心价值仍不可替代。
1.7、总结与评价
本文系统性地提出了Dropout方法,通过阻止神经元的共适应,解决了神经网络过拟合的经典难题。其设计兼具理论深度与工程实用性,在多个领域验证了广泛的有效性。作为深度学习发展史上的里程碑工作,Dropout不仅革新了模型正则化的方法论,也为理解神经网络的泛化机制提供了新视角。尽管存在丢弃率依赖经验设定、卷积层收益有限等局限性,其核心思想仍持续启发后续研究,成为现代人工智能技术栈中不可或缺的一环。
二、正则化
2.1、正则化
正则化是一种用于控制模型复杂度的技术。它通过在损失函数中添加额外的项(正则 化项)来降低模型的复杂度,以防止过拟合。
在机器学习中,模型的目标是在训练数据上获得较好的拟合效果。然而,过于复杂的 模型可能会在训练数据上表现良好,但在未见过的数据上表现较差,这种现象称为过 拟合。为了避免过拟合,正则化技术被引入。

2.2、为什么加入正则化可以解决过拟合?
加入正则化之后,想要损失函数尽可能的小,不仅仅要让原来的MSE的 值尽可能的小,还需要让后面正则化项的值尽可能的小。 要让正则化项的的值尽可能的小,那么就要使的参数 尽可能的小。
参数 小和解决过拟合的关系:
过拟合的实质是模型过于复杂或者训练样本较少,也可以理解为:针对当前 样本,模型过于复杂。 模型的复杂程度是由参数的个数和参数大小范围决定的,那么如果降低参数 的大 小范围,就可以降低模型的复杂度,因此可以用来解决过拟合问题。
2.3、正则化的基本思想
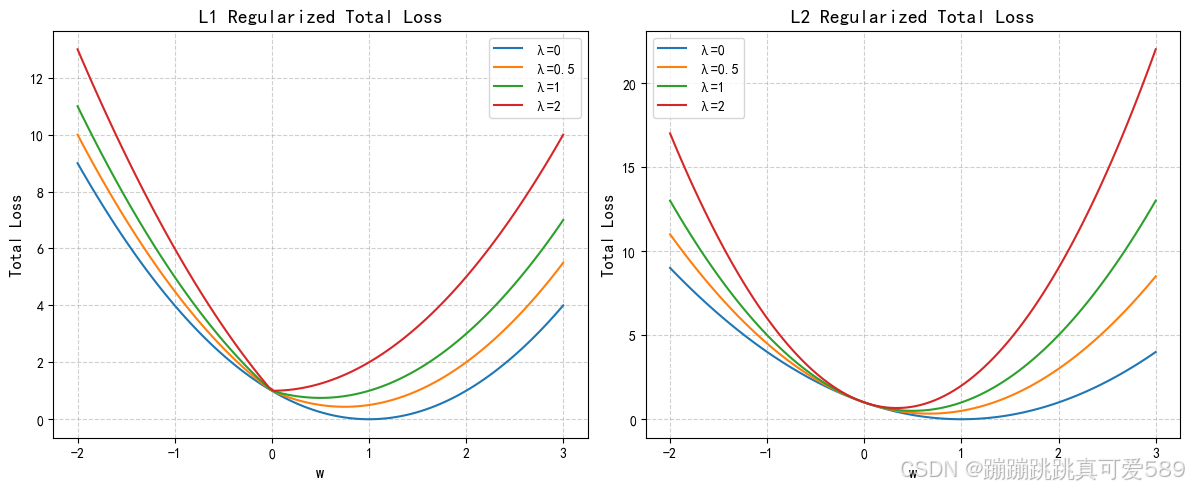
正则化的基本思想是在损失函数中引入一个额外的项,该项与模型的复杂度相关。这 个额外的项可以是参数的平方和(L2正则化),参数的绝对值和(L1正则化)或其 他形式的复杂度度量。通过调整正则化参数,可以控制正则化项在损失函数中的权 重。
正则化的目的是通过在损失函数中添加一个正则项(通常是权重的 L1 或 L2 范 数),以惩罚模型的复杂度,从而避免过拟合问题。
2.4、L1正则化和L2正则化
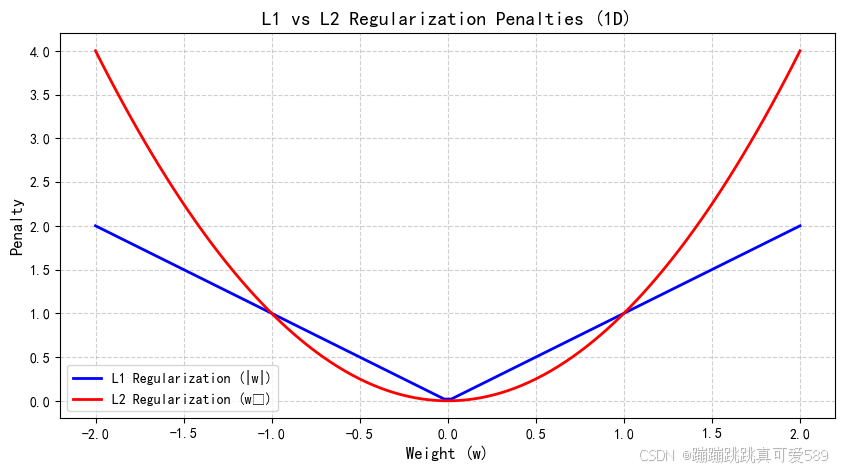
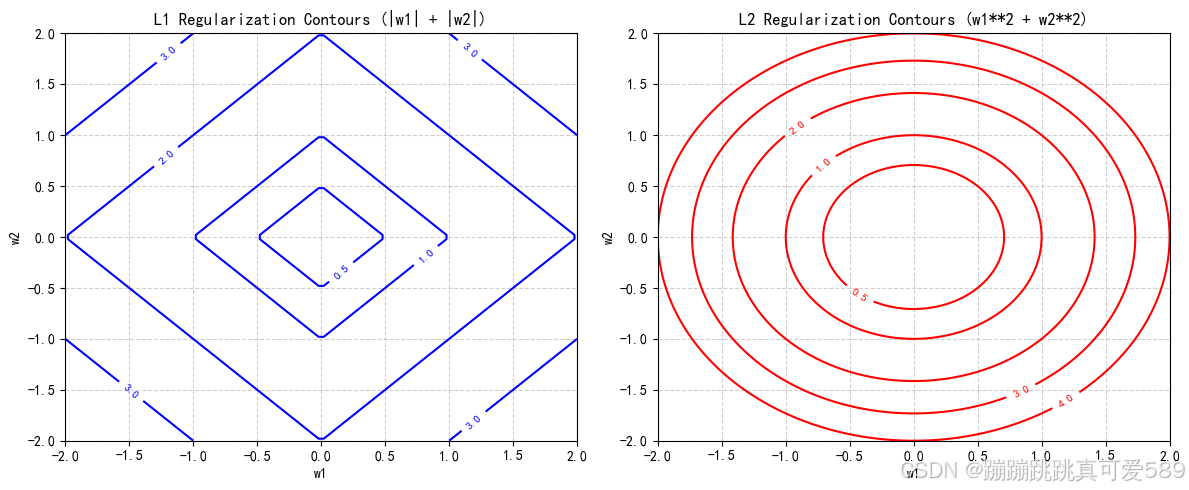
| 特性 | L1正则化 | L2正则化 |
|---|---|---|
| 稀疏性 | 产生稀疏解(部分权重为零) | 不产生稀疏解(权重接近零) |
| 优化特性 | 在零点不可导,需特殊处理 | 在零点可导,优化稳定 |
| 几何形状(2D) | 菱形 | 圆形 |
| 应用场景 | 特征选择、高维稀疏数据 | 防止过拟合、平滑权重分布 |
三、设计思路
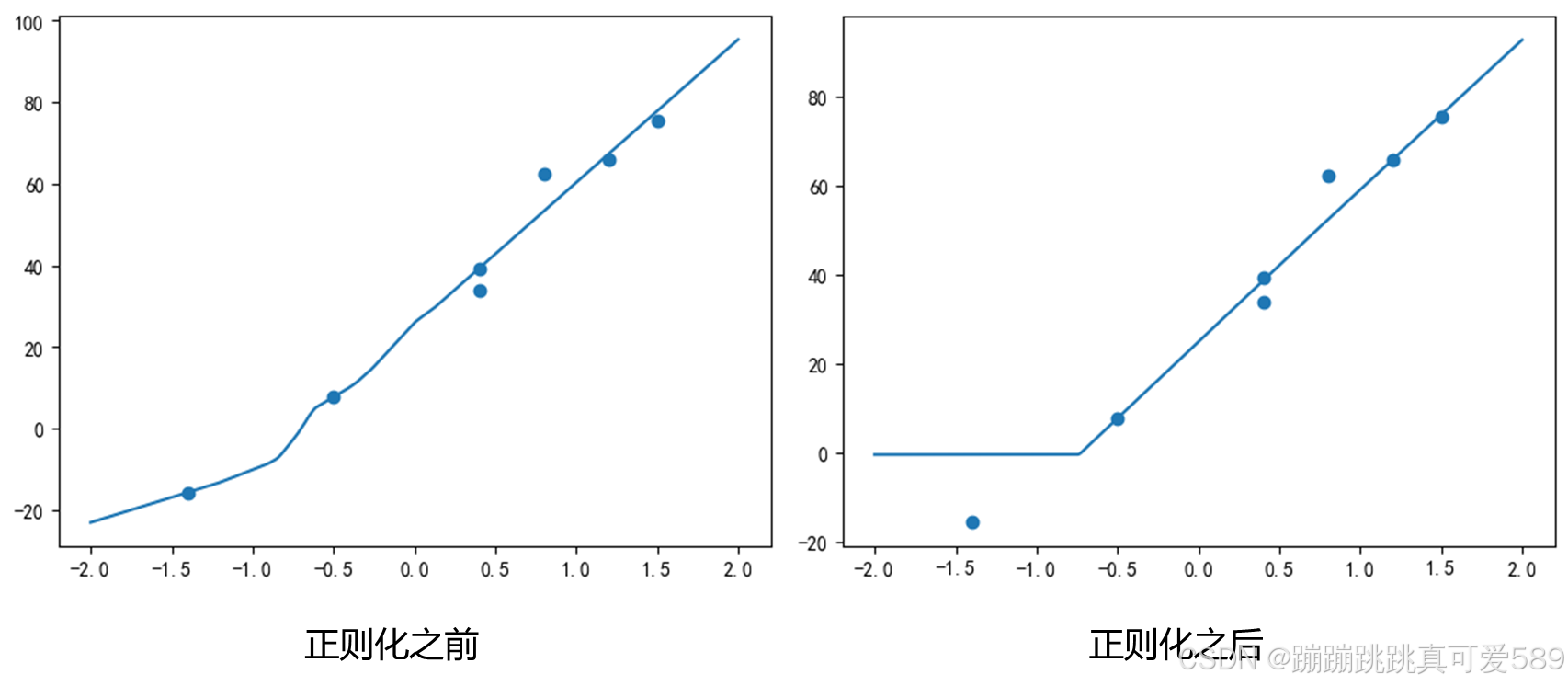
输入数据
torch.manual_seed(42)
points = np.array([[-0.5, 7.7], [1.2, 65.8], [0.4, 39.2], [-1.4, -15.7], [1.5, 75.6], [0.4, 34.0], [0.8, 62.3]])
x=points[:,0]
y=points[:,1]建立模型
class Moudel(nn.Module):
def __init__(self):
super().__init__()
self.liner1=nn.Linear(1,16)
self.liner2=nn.Linear(16,32)
self.liner3=nn.Linear(32,16)
self.liner4=nn.Linear(16,1)
def forward(self,x):
x=torch.relu(self.liner1(x))
x = torch.relu(self.liner2(x))
x = torch.relu(self.liner3(x))
x = self.liner4(x)
return x
model=Moudel()定义损失函数和优化器
cri=nn.MSELoss()
optim=torch.optim.Adam(model.parameters(),lr=0.1,weight_decay=8)模型训练
for epoch in range(1,1001):
x=torch.tensor(x,dtype=torch.float32)
y=torch.tensor(y,dtype=torch.float32)
y_pred=model(x.unsqueeze(1))
loss=cri(y_pred.squeeze(1),y)
optim.zero_grad()
loss.backward()
optim.step()
if epoch%100==0 or epoch==1:
print(epoch,loss.item())可视化
for epoch in range(1,1001):
x=torch.tensor(x,dtype=torch.float32)
y=torch.tensor(y,dtype=torch.float32)
y_pred=model(x.unsqueeze(1))
loss=cri(y_pred.squeeze(1),y)
optim.zero_grad()
loss.backward()
optim.step()
if epoch%100==0 or epoch==1:
print(epoch,loss.item())
plt.cla()
plt.scatter(x,y)
x_range=torch.tensor(np.linspace(-2,2,300),dtype=torch.float32).unsqueeze(1)
y_range=model(x_range).detach().numpy()
plt.plot(x_range,y_range)
plt.show()完整代码
import numpy as np
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
# 设置随机种子以便重现结果
torch.manual_seed(42)
# 定义数据点,x为自变量,y为因变量
points = np.array([
[-0.5, 7.7], [1.2, 65.8], [0.4, 39.2], [-1.4, -15.7],
[1.5, 75.6], [0.4, 34.0], [0.8, 62.3]
])
# 提取 x 和 y
x = points[:, 0] # 自变量
y = points[:, 1] # 因变量
# 定义神经网络模型
class Moudel(nn.Module):
def __init__(self):
super().__init__()
# 定义多层感知机的各个线性层
self.liner1 = nn.Linear(1, 16) # 输入1维,输出16维
self.liner2 = nn.Linear(16, 32) # 16维到32维
self.liner3 = nn.Linear(32, 16) # 32维到16维
self.liner4 = nn.Linear(16, 1) # 16维到1维(输出)
def forward(self, x):
# 定义前向传播过程
x = torch.relu(self.liner1(x)) # 第一层的激活函数使用ReLU
x = torch.relu(self.liner2(x)) # 第二层的激活函数使用ReLU
x = torch.relu(self.liner3(x)) # 第三层的激活函数使用ReLU
x = self.liner4(x) # 输出层
return x
# 实例化模型
model = Moudel()
# 定义损失函数为均方误差损失
cri = nn.MSELoss()
# 定义Adam优化器,学习率为0.1,并应用权重衰减(L2正则化)为15
optim = torch.optim.Adam(model.parameters(), lr=0.1, weight_decay=15)
# 进行训练
for epoch in range(1, 1001):
# 将数据转换为Tensor
x = torch.tensor(x, dtype=torch.float32) # 自变量
y = torch.tensor(y, dtype=torch.float32) # 因变量
# 前向传播,预测输出
y_pred = model(x.unsqueeze(1)) # 给模型输入(需将 x 变为 2D Tensor)
# 计算损失
loss = cri(y_pred.squeeze(1), y) # 计算预测值与实际值之间的均方误差
# 优化步骤
optim.zero_grad() # 清零梯度
loss.backward() # 反向传播计算梯度
optim.step() # 更新参数
# 每100个周期绘制一次图
if epoch % 100 == 0 or epoch == 1:
plt.cla() # 清空当前图
plt.scatter(x, y) # 绘制原始数据点
x_range = torch.tensor(np.linspace(-2, 2, 300), dtype=torch.float32).unsqueeze(1) # 生成x轴范围
y_range = model(x_range).detach().numpy() # 获取对应的y轴预测值
plt.plot(x_range, y_range) # 绘制预测结果线
# 显示最终图形
plt.show() 
脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐

 26
26 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)