【AI大模型】低代码 RAG 只是信息搬运工,Graph RAG 让 AI 具备垂直深度推理能力!
在现实世界中,数据往往不是零散的文字,而是以图结构的形式交织在一起——实体(如人、物、事件)是节点,语义关系(如“购买”、“发现”、“属于”)是连接它们的边。这种结构化的数据在电商、社交网络等场景中无处不在,也为人工智能注入了新的灵感。传统RAG通过从外部数据库检索知识并注入大模型,已显著提升了生成内容的质量,但它有个致命短板:擅长处理独立的文本片段,却无法理解这些片段之间的深层联系。比如,当你问
前言
在现实世界中,数据往往不是零散的文字,而是以图结构的形式交织在一起——实体(如人、物、事件)是节点,语义关系(如“购买”、“发现”、“属于”)是连接它们的边。这种结构化的数据在电商、社交网络等场景中无处不在,也为人工智能注入了新的灵感。传统RAG通过从外部数据库检索知识并注入大模型,已显著提升了生成内容的质量,但它有个致命短板:擅长处理独立的文本片段,却无法理解这些片段之间的深层联系。比如,当你问一个需要跨文本推理的问题时,传统RAG可能会“迷路”,答案零散而不完整。今天,我们将一起揭开Graph RAG的奥秘,看它如何突破传统RAG的局限,让你轻松上手!
一、从传统RAG到Graph RAG
RAG技术通过从外部检索知识并注入大模型,已经显著提升了生成内容的准确性和实用性。然而,当面对复杂查询或需要关联多段信息时,传统RAG的短板就暴露出来了。简单来说,它更擅长处理独立的文本片段,却很难理解这些片段之间的深层联系。
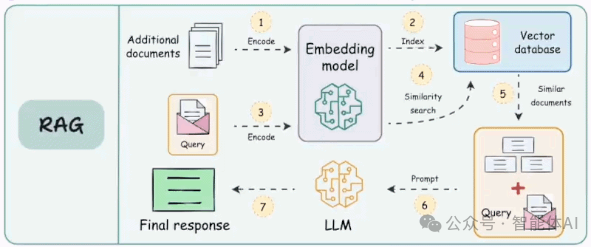
为了解决这些问题,Graph RAG应运而生。它通过将零散的文本转化为结构化的知识图谱,让大模型能够更高效地推理和生成答案。接下来,我们先从传统RAG的局限性说起,再逐步揭开Graph RAG的运作机制。
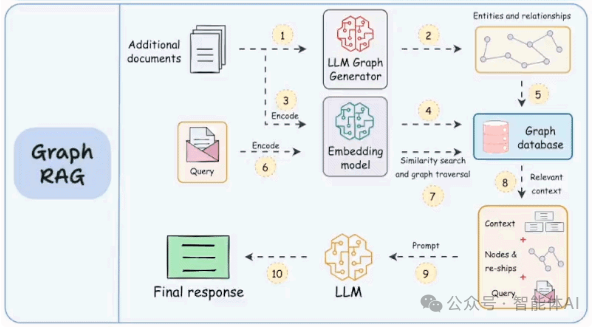
二、传统RAG的局限性
尽管传统RAG已经很强大,但它在处理复杂场景时有三个明显的瓶颈:
1. 大模型更喜欢“结构化”的输入
大语言模型在处理结构化数据时往往表现得更出色,因为结构化数据能清楚地展示事物之间的关系。
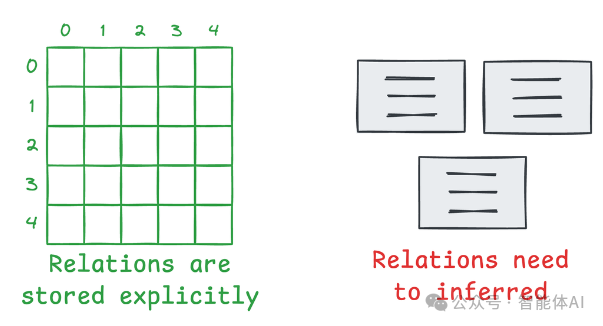
我们来看一个例子:
-
非结构化句子:“微信是腾讯旗下面向大众的即时通讯工具。”
-
结构化三元组:
-
- (微信, 类型, 即时通讯工具)
- (微信, 目标用户, 大众)
- (微信, 母公司, 腾讯)
在非结构化句子中,模型需要自己分析“微信”和“腾讯”“大众”之间的关系。如果文本再长一些,这种推断的难度会成倍增加,甚至可能出错。而结构化三元组直接把关系讲得明明白白,模型几乎不用费力就能理解。
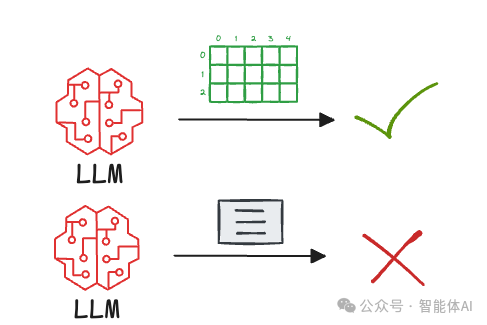
传统RAG依赖向量数据库检索非结构化的文本块,这些文本块虽然包含信息,却没有标注实体之间的关系。模型拿到这些“散装”信息后,很难高效地建立联系。而Graph RAG通过知识图谱,把信息整理得井井有条,让模型用起来更顺手。
2. 跨文本块的联系容易断裂
现实中,很多问题的答案并不是集中在一块文本里,而是分散在多个相关但独立的片段中。
比如:
- 文本块1:“居里夫人发现镭元素并获得诺贝尔奖。”
- 文本块2:“居里夫人对镭元素的发现极大推动了癌症治疗。”
传统RAG会分别检索这两个文本块,但它没法自动告诉你这两段话其实是有关联的。更麻烦的是,如果某个关键片段因为跟查询的相似度不够高而没被检索到,答案就直接缺了一角。即使所有片段都找回来了,模型还得自己费劲去拼凑这些信息的逻辑关系。
3. 多跳推理和因果关系的难题
有些问题需要跨越多段文本才能回答完整。比如,想总结某个人物X的全部成就,传统RAG可能会因为只抓取了“前k个”相关文本片段而漏掉一部分信息。更糟的是,它检索的每个片段都是孤立的,模型得自己猜这些片段怎么连起来,效率低不说,还容易出错。
什么是"多跳推理"?“跳”(Hop) 指的是在图结构中从一个节点到另一个节点的遍历步骤。例如:
- 第一跳:查询"居里夫人" → 找到"镭元素"
- 第二跳:从"镭元素" → 找到"癌症治疗"
“多跳推理” 意味着模型需要跨越多个节点(即多次"跳转")才能得到最终答案,而不是仅依赖单次检索。
三、Graph RAG:结构化检索的“救星”
Graph RAG的出现,像是给传统RAG装上了“结构化大脑”。它通过知识图谱和图遍历的方式,把零散的信息串联起来,让大模型能更聪明地工作。它的核心优势有以下几点:
1. 把文本变成知识图谱
Graph RAG的第一步,就是从非结构化文本中提取信息,构建一个知识图谱。以某人物X的传记为例,假设传记里分散记录了X的各种成就:
- 第一章:成就1
- 第二章:成就2
- ……
- 第十章:成就10
Graph RAG会把这些信息整理成一个图谱,结构可能是这样的:
- X → <达成> → 成就1
- X → <达成> → 成就2
- ……
- X → <达成> → 成就10
有了这个图谱,实体和关系一目了然,检索和推理的基础就打好了。
2. 用图遍历找答案
在检索阶段,Graph RAG不再依赖向量相似度,而是通过图谱遍历来获取完整信息。比如要总结X的成就,它会直接从X这个节点出发,沿着“达成”这条边,把所有相关成就都找出来。这种方式不仅确保信息不遗漏,还天然保持了信息的连贯性。
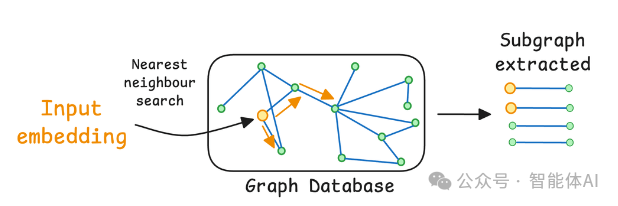
再比如前面提到的居里夫人案例,Graph RAG会生成这样的图谱:
- [居里夫人] → (发现) → [镭元素]
- [镭元素] → (应用) → [癌症治疗]
- [居里夫人] → (获奖) → [诺贝尔奖]
如果问题是“居里夫人对癌症治疗的贡献”,Graph RAG能顺着图谱的路径快速找到答案,比传统RAG的“盲找”高效多了。
3. 让大模型推理更轻松
Graph RAG把结构化的图谱信息喂给大模型,相当于把一堆散乱的拼图拼好后再交给它。这样,模型在处理多跳推理或因果关系时就轻松得多,结果自然更准确、更连贯。
四、Graph RAG的应用场景
Graph RAG的潜力远不止理论探讨,它在实际场景中已经展现出强大的价值,实际使用过程中,如果我们直接上传的文档不太好,那么就启用Graph RAG,这个检索结果就准确多了:
-
电商推荐:通过构建用户和商品的交互图谱,系统能更精准地推荐用户可能感兴趣的商品。
-
社交网络:用图谱分析用户间的关注、评论等关系,可以更高效地检测虚假账号,提升平台安全。
-
知识问答:面对复杂问题,Graph RAG能整合分散的信息,给出更全面的回答。
五、Graph RAG 的具体实现
在了解了 Graph RAG 的理论基础和优势后,本章节将通过一个具体的实现示例,展示如何基于 Neo4j 图数据库和 LangChain 框架构建并使用 Graph RAG 系统。这个示例涵盖了从知识图谱的构建、图数据的检索,到与大模型集成的完整流程。以下是实现步骤的详细说明和代码。
1. 环境准备
在开始编码之前,需要确保开发环境中安装了必要的 Python 库。您可以通过以下命令安装所需的依赖:
# 安装必要库pip install neo4j langchain openai py2neo transformers spacypython -m spacy download en_core_web_sm
这些库分别用于连接 Neo4j 数据库(neo4j, py2neo)、构建 LangChain 应用(langchain)、调用 OpenAI 大模型(openai)、处理自然语言(spacy)以及支持图嵌入(transformers)。
2. 知识图谱构建模块
知识图谱的构建是 Graph RAG 的核心步骤之一。我们将使用 spaCy 从文本中提取实体和关系,并将结果存储到 Neo4j 图数据库中。以下是实现代码:
from py2neo import Graph, Node, Relationshipimport spacy
# 初始化 Neo4j 连接graph = Graph("bolt://localhost:7687", auth=("neo4j", "password"))
# 加载 spaCy 模型nlp = spacy.load("en_core_web_sm")
def extract_entities_relations(text): """ 从文本中提取实体和关系 """ doc = nlp(text) entities = [ent.text for ent in doc.ents] # 提取命名实体 relations = []
# 简化的关系提取逻辑 - 实际应用中可使用更复杂的模型 for token in doc: if token.dep_ in ("nsubj", "dobj"): # 提取主语和宾语关系 relations.append((token.head.text, token.dep_, token.text))
return entities, relations
def build_knowledge_graph(text_data): """ 构建知识图谱 """ for text in text_data: entities, relations = extract_entities_relations(text)
# 创建节点 nodes = {} for entity in entities: node = Node("Entity", name=entity) graph.create(node) nodes[entity] = node
# 创建关系 for rel in relations: head, relation, tail = rel if head in nodes and tail in nodes: relationship = Relationship(nodes[head], relation, nodes[tail]) graph.create(relationship)
# 示例数据texts = [ "智能体AI公众号主要写AI相关的文章", "老谭是智能体AI公众号的作者", "智能体AI公众号的作者一般在长沙"]
build_knowledge_graph(texts)
说明:
- extract_entities_relations 函数使用 spaCy 提取文本中的实体和简单的依存关系(主语、宾语)。
- build_knowledge_graph 函数将提取的实体作为节点、关系作为边,存储到 Neo4j 中。
- 示例数据展示了如何从三句话中构建一个简单的知识图谱。
3. 图检索模块
构建好知识图谱后,我们需要实现从图谱中检索相关信息的功能。这里我们使用 LangChain 的 Neo4jGraph 和 Cypher 查询来完成这一步骤:
from langchain.graphs import Neo4jGraphfrom langchain.chains import GraphCypherQAChainfrom langchain.chat_models import ChatOpenAI
# 连接 Neo4jgraph = Neo4jGraph( url="bolt://localhost:7687", username="neo4j", password="password")
# 定义检索函数def graph_retrieval(query): """ 使用 Cypher 查询从知识图谱中检索相关信息 """ # 自动生成 Cypher 查询 cypher_query = f""" MATCH path = (e1)-[r]->(e2) WHERE toLower(e1.name) CONTAINS toLower('{query}') OR toLower(e2.name) CONTAINS toLower('{query}') OR toLower(type(r)) CONTAINS toLower('{query}') RETURN path LIMIT 5 """
# 执行查询 result = graph.query(cypher_query)
# 格式化结果 context = [] for record in result: path = record["path"] nodes = path.nodes rels = path.relationships
for rel in rels: start_node = nodes[rel.start] end_node = nodes[rel.end] context.append( f"{start_node['name']} - {rel.type} - {end_node['name']}" )
return "\n".join(context) if context else "No relevant information found."
说明:
- graph_retrieval 函数根据用户查询生成 Cypher 查询,从图谱中检索匹配的路径(节点和关系)。
- 返回结果格式化为“节点 - 关系 - 节点”的字符串,便于后续输入大模型。
4. 与大模型集成
检索到图谱信息后,我们将其与用户问题结合,输入到大模型中生成回答。这里使用 LangChain 的 RetrievalQA 链实现:
from langchain.prompts import PromptTemplatefrom langchain.chains import RetrievalQAfrom langchain.llms import OpenAI
# 定义提示模板GRAPH_PROMPT = PromptTemplate( template="""基于以下知识图谱信息和问题,提供详细的回答。如果信息不足,请说明。
知识图谱信息: {context}
问题: {question}
回答:""", input_variables=["context", "question"],)
# 创建 Graph RAG 链llm = OpenAI(temperature=0)graph_qa_chain = RetrievalQA.from_chain_type( llm=llm, chain_type="stuff", retriever=graph_retrieval, # 使用自定义的图检索函数 chain_type_kwargs={"prompt": GRAPH_PROMPT}, verbose=True)
# 使用示例question = "谁是智能体AI公众号的作者"result = graph_qa_chain.run(question)print(result)
说明:
- GRAPH_PROMPT 定义了如何将检索到的上下文和用户问题组织成提示。
- RetrievalQA 链将图检索结果输入 OpenAI 模型,生成最终回答。
- 示例问题“谁是智能体AI公众号的作者?”会基于图谱信息返回“老谭”。
5. 进阶实现 - 带图嵌入的版本
为了提升 Graph RAG 的性能,我们可以引入图嵌入技术,将图谱中的节点和关系转为向量表示,支持更复杂的查询和推理:
from torch_geometric.data import Dataimport torchfrom transformers import AutoModel, AutoTokenizer
class GraphEmbedder: def __init__(self): self.tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased") self.model = AutoModel.from_pretrained("bert-base-uncased")
def get_embeddings(self, text): inputs = self.tokenizer(text, return_tensors="pt", padding=True, truncation=True) with torch.no_grad(): outputs = self.model(**inputs) return outputs.last_hidden_state.mean(dim=1)
def create_graph_data(self, cypher_result): """ 将 Cypher 查询结果转换为 PyG 图数据 """ node_texts = [] edge_index = [] edge_attrs = []
node_dict = {} node_counter = 0
for record in cypher_result: path = record["path"] nodes = path.nodes rels = path.relationships
for rel in rels: start_node = nodes[rel.start] end_node = nodes[rel.end]
# 添加节点 if start_node["name"] not in node_dict: node_dict[start_node["name"]] = node_counter node_texts.append(start_node["name"]) node_counter += 1
if end_node["name"] not in node_dict: node_dict[end_node["name"]] = node_counter node_texts.append(end_node["name"]) node_counter += 1
# 添加边 edge_index.append([node_dict[start_node["name"]], node_dict[end_node["name"]]]) edge_attrs.append(rel.type)
# 获取节点嵌入 node_embeddings = torch.cat([self.get_embeddings(text) for text in node_texts])
# 创建图数据对象 data = Data( x=node_embeddings, edge_index=torch.tensor(edge_index, dtype=torch.long).t().contiguous(), edge_attr=edge_attrs )
return data
使用示例embedder = GraphEmbedder()cypher_result = graph.query(“MATCH path=(e1)-[r]->(e2) RETURN path LIMIT 10”)graph_data = embedder.create_graph_data(cypher_result)
说明:
- 使用 BERT 模型为节点生成嵌入向量。
- 将 Cypher 查询结果转换为 PyTorch Geometric(PyG)的图数据格式,为后续图神经网络(GNN)应用奠定基础。
6. 完整应用示例
最后,我们将上述模块整合为一个 Web 应用,使用 FastAPI 提供 RESTful API 接口:
from fastapi import FastAPIfrom pydantic import BaseModel
app = FastAPI()
class Query(BaseModel): question: str
@app.post("/ask")async def ask_question(query: Query): # 1. 从知识图谱检索 context = graph_retrieval(query.question)
# 2. 使用大模型生成回答 response = graph_qa_chain.run({ "question": query.question, "context": context })
# 3. 返回结果 return {"answer": response}
运行命令: uvicorn app:app --reload
说明:
- 定义了一个 /ask 端点,接收用户查询。
- 通过图检索和大模型生成回答,返回 JSON 格式的结果。
- 可通过 HTTP 请求访问此服务,例如 POST /ask。
六、总结
Graph RAG通过知识图谱和结构化检索,完美弥补了传统RAG在处理复杂查询和关联数据时的不足。它不仅让大模型的推理更高效,还为智能检索开辟了新的可能性。无论是电商推荐、社交网络分析,还是知识问答,Graph RAG都展现出了巨大的潜力。希望这篇文章能让你对Graph RAG有更清晰的认识。
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐



 30
30 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)