关于YOLO模型,实现视频识别!
# 介绍 UltralyticsYOLO11YOLO11 基于深度学习和计算机视觉领域的尖端技术,在速度和准确性方面具有无与伦比的性能。其流线型设计使其适用于各种应用,并可轻松适应从边缘设备到云 API 等不同硬件平台。
探索Ultralytics 文档,这是一个旨在帮助您了解和利用其特性和功能的综合资源。无论您是经验丰富的机器学习实践者,还是刚进入该领域的新手,该中心都旨在最大限度地发挥YOLO 在您的项目中的潜力。
一,了解YOLO
详细了解请查看官网:主页 -Ultralytics YOLO 文档
二,下载安装pycharm软件,网址PyCharm: the Python IDE for data science and web development
第一步:下载(拉取代码)
# Clone the ultralytics repository
git clone https://github.com/ultralytics/ultralytics
第二步:安装Yolo代码所需依赖
如果使用venv:pip install ultralytics
如果使用aconda:conda install ultralytics
第三步:安装cuda 和cuDNN
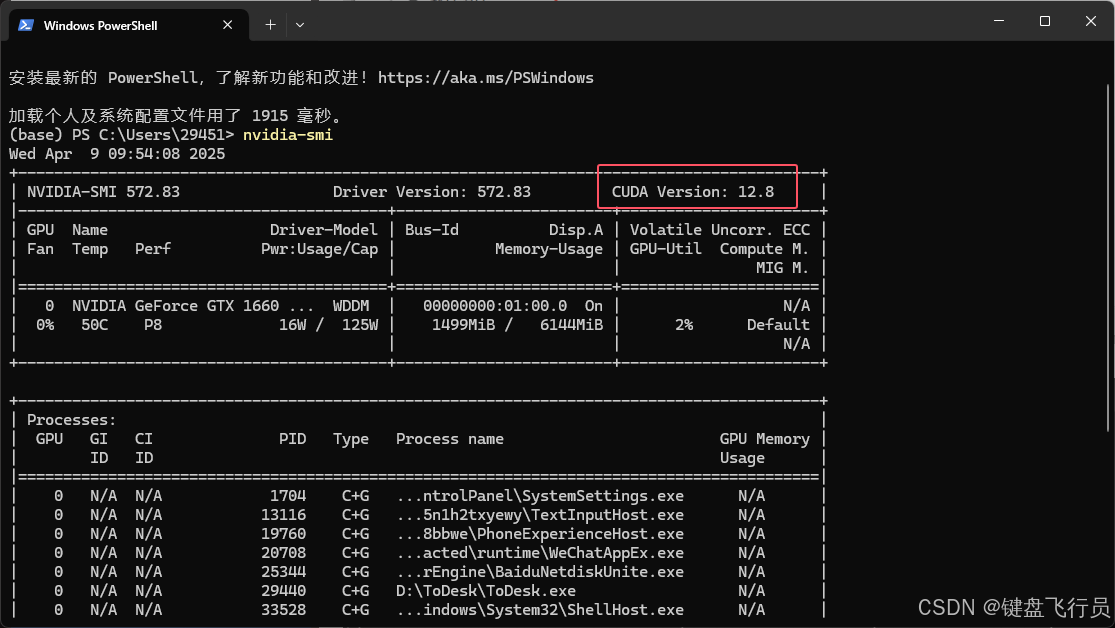
1.CUDA查询电脑支持最高cuda版本是多少,终端输入命令nvidia-smi查看
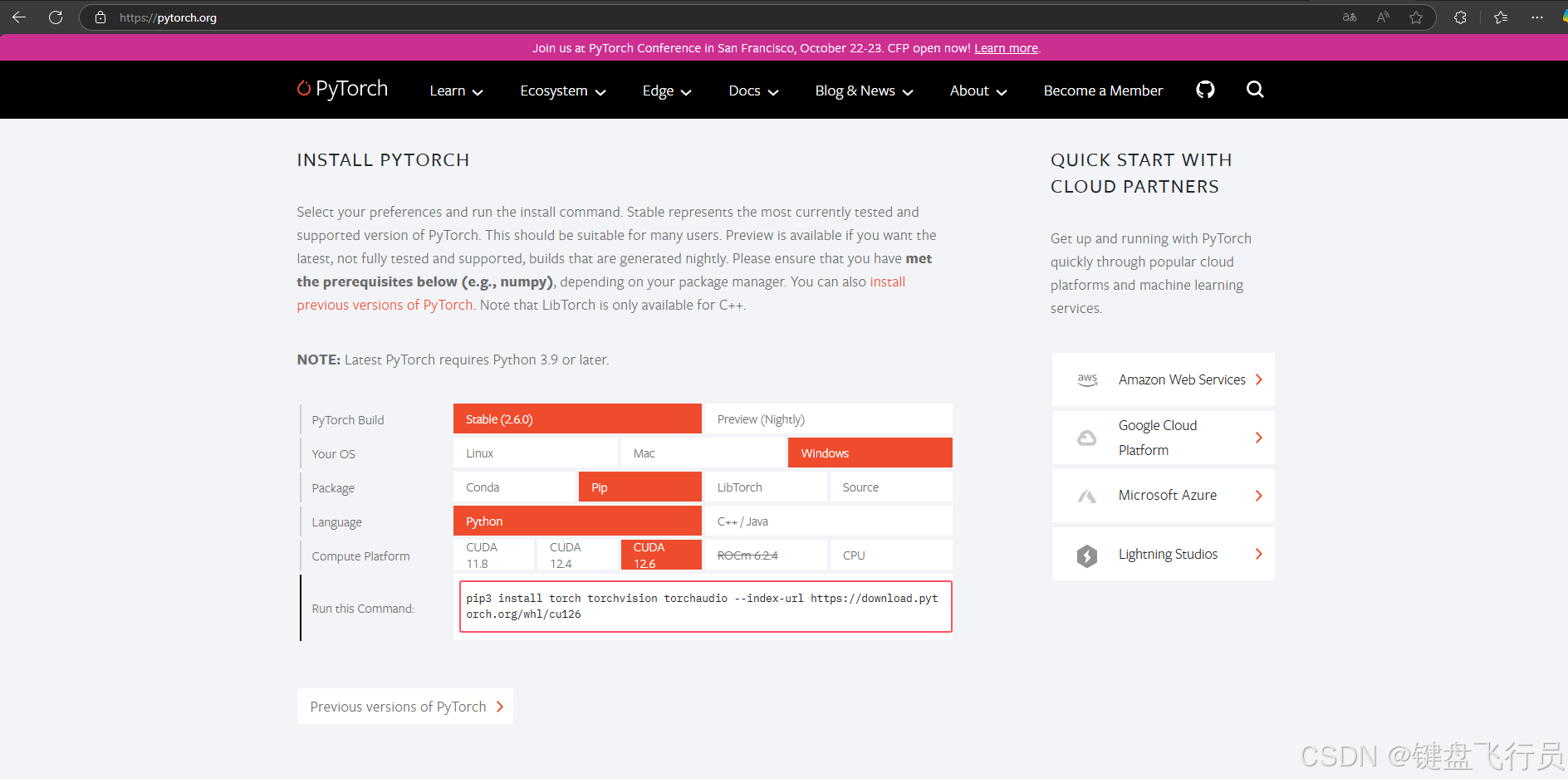
2.去pytorch官网下载,对应版本的CUDA,网址:PyTorch
3.切换虚拟环境安装
注意# 默认是 base 虚拟环境,要切换到虚拟环境安装
如果你想要使用其他环境首先就要取消掉base环境:conda deactivate base
查看 当前使用虚拟环境 conda env list 带*代表就是正在使用
然后选择自己要使用的虚拟环境:conda activate yourselfxxx
4.下载安装cuda
5.cuDNN官网下载对应版本的CUDAA 网址cuDNN Archive | NVIDIA Developer
第四步:激活环境
aconda环境激活:
默认是 base 虚拟环境
然后如果你想要使用其他环境首先就要取消掉base环境:conda deactivate base
查看 当前使用虚拟环境 conda env list 带*代表就是正在使用的
然后选择自己要使用的虚拟环境:conda activate yourselfxxxvenv 环境激活:
D:\test>cd myvenv
D:\test\myvenv>cd Scripts
D:\test\myvenv\Scripts>activate
(myvenv)D:\test\myvenv\Scripts>
第五步:验证
import torch
print(torch.cuda.is_available())
# 如果为True就代表gpu可用 torch 配置成功
第六步:验证yolo是否可用
from ultralytics import YOLO
# Load a pretrained YOLOv8n model
model = YOLO("yolov8n.pt")
# Run inference on 'bus.jpg' with arguments
results = model.predict("bus.jpg", save=True, imgsz=320, conf=0.5)
# Value of result
for result in results:
print("图像原始大小:", result.orig_shape)
data_numpy = result.boxes.data.cpu().numpy()
for data in data_numpy:
print("data", data)
print("左上角X轴坐标:", data[0])
print("左上角Y轴坐标:", data[1])
print("右下角X轴坐标:", data[2])
print("右下角Y轴坐标:", data[3])
print("置---信---度:", data[4])
print("检测到的类有:", data[5])
第七步:AI视觉识别domo
1.新建domo文件(项目根目录下)文件名如:aiVisualModel.py
2.domo代码
from collections import defaultdict
import cv2
import numpy as np
from ultralytics import YOLO
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE" # 允许临时忽略冲突
# 加载YOLO模型
model = YOLO("yolov8n.pt")
video_path = "video.mp4"
cap = cv2.VideoCapture(video_path)
track_history = defaultdict(lambda: [])
# 循环读取视频帧
while cap.isOpened():
success, frame = cap.read()
if not success:
break # 视频结束或读取失败时退出循环
# 使用跟踪器处理当前帧,指定跟踪器配置
results = model.track(frame, persist=True, tracker="bytetrack.yaml")
# 获取带标注的帧,若结果无效则使用原帧
annotated_frame = frame.copy()
if results:
annotated_frame = results[0].plot() # 绘制检测结果
# 检查是否存在检测框
if results[0].boxes is not None:
# 遍历每个检测框
for box in results[0].boxes:
# 确认该检测框有跟踪ID
if box.id is not None:
# 提取ID和坐标
track_id = int(box.id.cpu().tolist()[0])
x, y, w, h = box.xywh.cpu().numpy()[0]
# 更新轨迹历史
track = track_history[track_id]
track.append((float(x), float(y)))
if len(track) > 30: # 限制轨迹长度
track.pop(0)
# 绘制轨迹线
points = np.array(track, dtype=np.int32).reshape((-1, 1, 2))
cv2.polylines(annotated_frame, [points], isClosed=False,
color=(16, 210, 115), thickness = 3)
# 显示结果
cv2.imshow("YOLOv8 Tracking", annotated_frame)
if cv2.waitKey(1) & 0xFF == ord("q"):
break
# 释放资源
cap.release()
cv2.destroyAllWindows()最后看最终的效果
#如果对你有帮助记得三联一下哈!!!
YOLO AI视觉识别

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐



 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)