【有啥问啥】深度学习中的 Free Running 模式:原理、挑战与优化策略
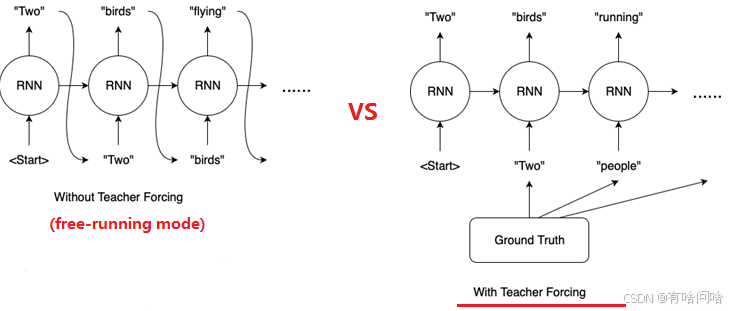
Free running 模式也常称为自动回归生成模式。其核心思想是:在生成序列时,模型不再使用真实历史数据,而是将上一步的预测结果作为下一步的输入。初始令牌(例如 “[START]”)作为输入,模型预测出第一个词将预测出的第一个词作为输入,生成第二个词如此反复,直到生成结束符“[END]”或达到预定长度这种模式直接模拟模型在实际应用中的工作方式,因此更接近真实场景。但同时,由于依赖自身预测作为输
深度学习中的 Free Running 模式:原理、挑战与优化策略
在序列生成任务(如自然语言生成、语音合成、时序预测等)中,深度学习模型大多采用自回归(autoregressive)结构,其核心思想是利用前面生成的内容预测后续输出。训练过程中常用的**教师强制(Teacher Forcing)方法可以加速模型收敛,但在推理阶段却需要切换为free running(自由运行)**模式。本文将详细介绍什么是 free running 模式、它与教师强制的区别、由此带来的问题以及当前常见的改进策略。
1. 引言
近年来,深度学习在自然语言处理、语音合成及其他序列生成任务中取得了巨大成功。其中,循环神经网络(RNN)、长短时记忆网络(LSTM)、以及基于 Transformer 的自回归模型等结构,都依赖于时间序列中前后信息的传递。训练这类模型时,**教师强制(Teacher Forcing)是一种常用的技术:在模型每一步的预测中,将真实的历史输出作为当前时刻的输入,从而大大简化学习问题,加速收敛;而在推理阶段,模型则需要基于自己生成的输出继续生成下一个结果,这种模式即为free running(自由运行)**模式。二者之间的“训练—推理差距”也是近年来研究的重要方向之一。
2. 序列建模基础:教师强制与 Free Running 模式
- 传送门链接: 深入浅出讲解 Teacher Forcing 技术
2.1 教师强制(Teacher Forcing)训练
在教师强制模式下,模型在每一步的预测中,都使用真实的、人工标注的序列作为输入。以语言模型为例,给定一个句子:
“我 今天 去 学校”
训练时,模型预测下一个词的条件为:
- 时刻 1:输入“我”,目标“今天”
- 时刻 2:输入“今天”(真实序列),目标“去”
- 时刻 3:输入“去”,目标“学校”
这种方法的优点在于:
- 利用正确答案信息,降低了训练难度
- 加速梯度传播(backpropagation through time),使得模型能够更快收敛
然而,教师强制训练存在**暴露偏差(Exposure Bias)**的问题,即模型在训练过程中总是看到“理想化”的输入序列,但在推理时只能依赖自身生成的、不完美的预测,导致错误可能逐步累积。
2.2 Free Running(自由运行)模式及其定义
Free running 模式也常称为自动回归生成模式。其核心思想是:在生成序列时,模型不再使用真实历史数据,而是将上一步的预测结果作为下一步的输入。例如,在推理过程中,对于同一句子生成过程:
- 初始令牌(例如 “[START]”)作为输入,模型预测出第一个词
- 将预测出的第一个词作为输入,生成第二个词
- 如此反复,直到生成结束符“[END]”或达到预定长度
这种模式直接模拟模型在实际应用中的工作方式,因此更接近真实场景。但同时,由于依赖自身预测作为输入,如果模型在初始阶段出现错误,可能导致错误信息逐步累积,最终导致输出质量下降。
3. Free Running 模式的重要性
在推理(inference)阶段,模型并不知道真实答案,只能依赖自身已有的输出进行预测。因此,我们必须让模型学会在 free running 模式下进行连续生成。这种模式不仅适用于语言生成、图像描述等任务,也在语音合成、视频生成等领域具有非常广泛的应用。只有在 free running 模式下训练得当,模型才能在实际应用中生成连贯且质量较高的序列。
4. Free Running 模式下的挑战
4.1 曝光偏差(Exposure Bias)
由于训练时使用教师强制提供的正确历史信息,而推理时模型需要以自己的预测为依据,训练与推理之间存在分布差异。这个问题称为“曝光偏差”,其后果如下:
- 错误累积:一旦模型早期预测出错误信息,这个错误可能会传递至后续步骤,导致越来越多的偏差
- 模型不稳定:在 free running 模式下,模型可能无法从错误中恢复,从而影响整体输出质量
4.2 自回归生成的非平行化
在 free running 模式下,由于每一步都依赖上一步的结果,因此生成过程必须按顺序进行,难以充分利用并行计算资源。这在训练大型模型时可能带来效率瓶颈,尤其对于需要实时响应的应用(如低延迟语音增强)尤为关键。
5. 优化 Free Running 模式的策略
为了缩小教师强制训练与 free running 推理之间的差距,研究者们提出了多种方法:
5.1 Scheduled Sampling(计划采样)
Scheduled Sampling 由 Bengio 等人提出,其基本思想是:在训练过程中,随机决定在下一步输入中使用真实数据还是模型生成的数据,并随着训练进程逐渐增加使用模型预测结果的比例。这样既能利用真实数据加速初期学习,又能逐步让模型适应 free running 模式,从而降低暴露偏差的问题。
优点:能平滑过渡,降低错误累积问题
缺点:需要设计合适的采样衰减策略,调参较为复杂
5.2 Professor Forcing(教授强制)
Professor Forcing 是一种更高级的方案,其思路是使用一个辅助判别器(discriminator)来比较模型在教师强制模式下与 free running 模式下的隐藏状态及输出分布。通过对抗训练,鼓励模型在两种模式下表现一致,从而提高推理时的稳定性与生成质量。
优点:能有效缩小训练与推理间的分布差异
缺点:增加了训练过程的复杂度,需要额外设计判别器及相应的对抗训练策略
5.3 其他技术
除此之外,还有一些方法试图从模型结构或损失函数层面改善 free running 模式下的表现,例如:
- 利用混合损失函数(mixed loss function),将 MLE 损失与基于生成序列质量的其他指标(如BLEU、PESQ)结合
- 引入后处理模块(如神经 vocoder),为 free running 模式生成的序列提供额外补救
- 采用自注意力(Self-Attention)机制及 Transformer 架构,利用全局信息进行生成调整
6. 应用场景与实践案例
6.1 自然语言生成
在机器翻译、对话生成、文章写作等任务中,模型通常在推理时采用 free running 模式。如何避免因早期预测错误而导致整体语句偏差,是提高生成质量的关键。
6.2 语音合成
例如在 WaveNet 模型中,推理时每个采样点都是基于前面的生成结果,因此 free running 模式下的错误累积可能导致语音噪音。研究人员采用采样策略和后处理技术缓解这一问题,同时也通过 professor forcing 优化模型内部状态。
6.3 时序预测与其他领域
在股票价格预测或传感器数据预测等应用中,模型同样需要基于自身预测进行未来趋势推断。采用 free running 模式训练好的模型,能够在实时预测中更稳定地运行。
7. 总结与展望
本文详细介绍了深度学习中“free running(自由运行)”模式的概念及其与教师强制训练的主要区别,探讨了该模式下常见的挑战——尤其是曝光偏差和错误累积问题,并介绍了目前两种最常见的优化策略:Scheduled Sampling 和 Professor Forcing。此外,还讨论了 free running 模式在自然语言生成、语音合成以及时序预测等应用中的重要性。
未来,如何设计更为高效的训练策略以缩小“训练—推理差距”,以及如何在保持高生成质量的同时提升生成速度,将是该领域的重要研究方向。通过不断探索和改进,我们有望使模型在 free running 模式下拥有更强的鲁棒性和更高的实际应用价值。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 11
11 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)