毕业设计:基于时间序列分析的电力负荷预测算法研究
深度学习技术实现电力负荷预测与分析。通过分析历史负荷数据和气候因素,构建高效的电力负荷预测模型。结合时间序列分析与深度学习算法,实验结果显示,所提出的方法在电力负荷预测任务中表现优异,能够有效提升电力系统的调度效率。对于计算机专业、人工智能专业、大数据专业、信息安全专业、软件工程专业的毕业生而言,不论是对于深度学习技术感兴趣的同学,还是希望探索机器学习、算法或人工智能的领域的同学,都能为您提供丰富
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
大家好,这里是海浪学长计算机毕设专题,本次分享的课题是
🎯基于时间序列分析的电力负荷预测算法研究
项目背景
随着社会经济的发展和城市化进程的加快,电力需求日益增加。准确预测电力负荷对电力系统的安全稳定运行至关重要。传统电力负荷预测方法多依赖于线性回归等统计学模型,无法有效处理复杂的非线性关系和多维特征。引入深度学习技术,可以充分挖掘历史负荷数据与其他相关因素之间的复杂关系,从而提高预测的准确性和可靠性。结合气象因素和时间序列分析,提升电力负荷预测的准确性和实用性。
数据集
收集历史负荷数据、气象数据和时间特征,确保涵盖了多年的用电记录。进行了数据清洗,处理了缺失值和异常值,以确保数据的完整性和准确性。对数据进行了标准化,使不同特征在同一尺度上,将数据集按时间序列划分为训练集、验证集和测试集,确保训练集包含足够的历史数据以供模型学习。
设计思路
长短期记忆网络(LSTM)是一种特殊类型的循环神经网络,专门用于处理和预测序列数据。LSTM能够有效捕捉长时间依赖关系,克服传统RNN在处理长序列时面临的梯度消失和梯度爆炸问题。传统的时间序列预测方法往往无法充分利用历史数据中的时间依赖关系,而LSTM通过引入记忆单元,能够将重要信息存储在细胞状态中,并根据输入数据的变化动态调整信息流。这种机制使得LSTM能够在复杂的负荷变化模式中提取有价值的特征,提高预测的准确性和稳定性。
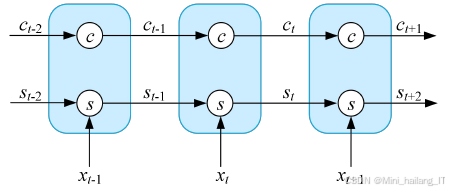
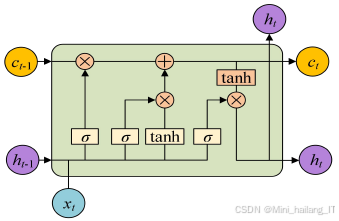
LSTM的核心结构由多个门控机制组成,包括输入门、遗忘门和输出门。输入门负责决定当前输入信息对细胞状态的影响程度,遗忘门用于选择保留或丢弃先前细胞状态中的信息,而输出门则控制最终输出的内容。这些门控机制的引入使得LSTM能够灵活地选择哪些信息需要保留、更新或丢弃,从而有效地处理时间序列数据。在电力负荷预测中,输入的序列数据通常包括历史负荷数据、气象数据以及节假日、工作日等特征。这些信息通过LSTM网络进行处理,经过多层LSTM单元后,最终生成未来负荷的预测值。通过对历史负荷的学习,LSTM能够识别出负荷变化的趋势和周期性,从而为后续的电力需求预测提供更为精准的依据。LSTM的训练过程通常采用反向传播算法,通过最小化预测值与真实值之间的损失函数来调整网络参数。随着训练的进行,LSTM能够逐渐学习到电力负荷变化的规律,提高模型的预测能力。
LSTM在电力负荷预测中的应用展现了其强大的时序建模能力。通过对历史负荷数据的深入分析,LSTM模型能够捕捉到负荷的季节性、日常变化和突发事件等特征。可以利用LSTM模型进行短期和长期的负荷预测,支持日常的电力调度和长期的电力规划。短期负荷预测通常关注未来几小时或几天的电力需求,LSTM能够通过实时收集的历史数据,快速更新模型并生成短期预测结果。长期负荷预测则涉及到未来几个月甚至几年的电力需求变化,LSTM通过充分利用历史数据中的长期依赖关系,能够提供更为可靠的预测结果。
收集与电力负荷相关的历史数据,通常包括负荷数据、气象数据、时间特征等。这些数据可以从相关数据库获取。对数据进行清洗和预处理,包括处理缺失值、异常值和噪声。数据标准化或归一化也是重要的步骤,能够加速模型训练并提高收敛速度。此外,数据需要按照时间序列特性进行划分,通常将数据集分为训练集、验证集和测试集
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
# 加载数据
data = pd.read_csv('electricity_load_data.csv')
# 处理缺失值
data.fillna(method='ffill', inplace=True)
# 特征选择
features = data[['load', 'temperature', 'humidity', 'hour', 'day_of_week']]
target = data['load']
# 数据归一化
scaler = MinMaxScaler()
features_scaled = scaler.fit_transform(features)
target_scaled = scaler.fit_transform(target.values.reshape(-1, 1))
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(features_scaled, target_scaled, test_size=0.2, random_state=42)使用深度学习框架构建LSTM模型。在构建过程中,需要确定LSTM层的数量、每层的单元数、激活函数以及优化器。模型的设计应能够有效捕捉电力负荷的时序特征。在训练过程中,使用训练集对模型进行训练,通过最小化损失函数来优化模型参数。监控训练过程中的损失值和准确率变化,确保模型能够有效学习。为了防止过拟合,可以使用早停法和正则化技术。
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Dropout
# 数据重塑
X_train_reshaped = X_train.reshape((X_train.shape[0], 1, X_train.shape[1]))
X_test_reshaped = X_test.reshape((X_test.shape[0], 1, X_test.shape[1]))
# 构建LSTM模型
model = Sequential()
model.add(LSTM(50, return_sequences=True, input_shape=(X_train_reshaped.shape[1], X_train_reshaped.shape[2])))
model.add(Dropout(0.2))
model.add(LSTM(50, return_sequences=False))
model.add(Dropout(0.2))
model.add(Dense(1)) # 输出层
# 编译模型
model.compile(optimizer='adam', loss='mean_squared_error')
# 训练模型
history = model.fit(X_train_reshaped, y_train, epochs=100, batch_size=32, validation_data=(X_test_reshaped, y_test), verbose=2)使用测试集对模型进行评估,计算相关的性能指标,如均方误差(MSE)、均方根误差(RMSE)和R²分数等。这些指标能够反映模型在电力负荷预测中的表现。评估完成后,可以使用训练好的模型进行未来电力负荷的预测。根据新的输入数据,模型能够生成预测结果,提供决策支持。在实际应用中,定期更新模型并重新训练,可以确保模型在不断变化的电力负荷环境中保持良好的预测性能。
from sklearn.metrics import mean_squared_error, r2_score
# 模型评估
predictions = model.predict(X_test_reshaped)
mse = mean_squared_error(y_test, predictions)
rmse = np.sqrt(mse)
r2 = r2_score(y_test, predictions)
print(f'MSE: {mse:.4f}')
print(f'RMSE: {rmse:.4f}')
print(f'R² Score: {r2:.4f}')
# 未来负荷预测示例
future_data = np.array([[0.8, 0.7, 0.6, 12, 5]]) # 示例输入
future_data_scaled = scaler.transform(future_data)
future_data_reshaped = future_data_scaled.reshape((1, 1, future_data_scaled.shape[1]))
future_prediction = model.predict(future_data_reshaped)
print(f'未来负荷预测: {scaler.inverse_transform(future_prediction):.2f}')海浪学长项目示例:
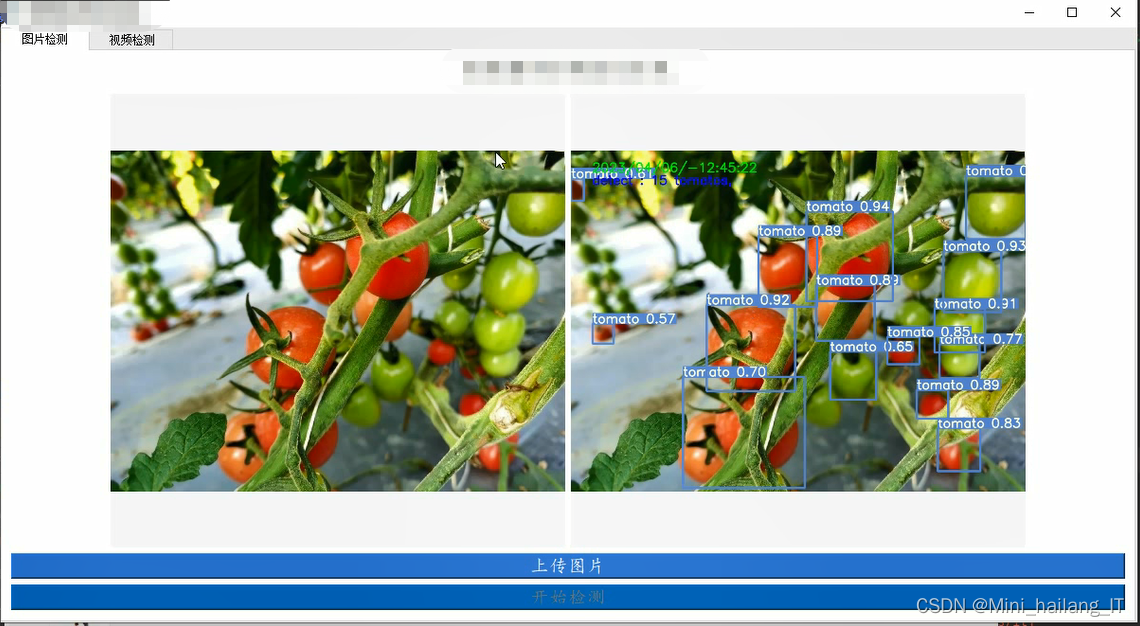



更多帮助

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 25
25 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)