Pytorch深度学习框架60天进阶学习计划 - 第44天:游戏AI训练(二)
Pytorch深度学习框架60天进阶学习计划 - 第44天:游戏AI训练(二)!如果文章对你有帮助,还请给个三连好评,感谢感谢!
Pytorch深度学习框架60天进阶学习计划 - 第44天:游戏AI训练(二)
嘿,欢迎来到第44天的学习!今天我们将踏入游戏AI的奇妙世界,学习如何让AI玩游戏!想象一下,你将创造一个能自己学会玩Atari经典游戏的AI——这不仅超级酷,还能帮你深入理解强化学习的核心概念。
我们继续今天的内容:
第二部分:构建完整的DQN智能体与实验分析
1. 环境设置与预处理
首先,我们需要设置Atari游戏环境并进行预处理,以便为DQN提供适当的输入:
import gym
import numpy as np
import cv2
from collections import deque
class AtariPreprocessing:
def __init__(self, env, frame_skip=4, frame_size=84, stack_frames=4):
"""
Atari环境预处理器
参数:
- env: gym环境
- frame_skip: 跳过的帧数(执行同一动作的连续帧数)
- frame_size: 调整后的帧大小
- stack_frames: 堆叠的帧数
"""
self.env = env
self.frame_skip = frame_skip
self.frame_size = frame_size
self.stack_frames = stack_frames
# 动作和观察空间
self.action_space = env.action_space
obs_shape = (stack_frames, frame_size, frame_size)
self.observation_space = gym.spaces.Box(
low=0, high=255, shape=obs_shape, dtype=np.uint8
)
# 帧堆栈
self.frames = deque([], maxlen=stack_frames)
def reset(self):
"""重置环境并返回初始状态"""
observation = self.env.reset()
# 清空帧堆栈
self.frames.clear()
# 处理初始观察并填充帧堆栈
processed_frame = self._process_frame(observation)
for _ in range(self.stack_frames):
self.frames.append(processed_frame)
return self._get_observation()
def step(self, action):
"""执行动作并返回结果"""
total_reward = 0.0
done = False
# 执行同一动作frame_skip次
for _ in range(self.frame_skip):
observation, reward, done, info = self.env.step(action)
total_reward += reward
if done:
break
# 处理观察并更新帧堆栈
processed_frame = self._process_frame(observation)
self.frames.append(processed_frame)
return self._get_observation(), total_reward, done, info
def _process_frame(self, frame):
"""处理单帧"""
# 转换为灰度图
if len(frame.shape) == 3 and frame.shape[2] == 3:
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2GRAY)
# 调整大小
frame = cv2.resize(frame, (self.frame_size, self.frame_size),
interpolation=cv2.INTER_AREA)
return frame
def _get_observation(self):
"""返回当前观察(堆叠的帧)"""
return np.array(self.frames)
def render(self):
"""渲染环境"""
return self.env.render()
def close(self):
"""关闭环境"""
self.env.close()
# 使用示例
def create_atari_env(game_name):
"""创建预处理过的Atari环境"""
env = gym.make(f"{game_name}-v4")
return AtariPreprocessing(env)
2. 完整的DQN智能体实现
现在让我们实现一个完整的DQN智能体,包括训练和评估功能:
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import random
import time
from collections import deque
class DQNAgent:
def __init__(
self,
state_shape,
n_actions,
replay_size=100000,
batch_size=32,
gamma=0.99,
learning_rate=0.0001,
epsilon_start=1.0,
epsilon_final=0.01,
epsilon_decay=0.0001,
target_update=1000,
device="cuda" if torch.cuda.is_available() else "cpu"
):
"""
DQN智能体
参数:
- state_shape: 状态的形状(通常是(stack_frames, height, width))
- n_actions: 可用动作数量
- replay_size: 经验回放缓冲区大小
- batch_size: 训练批次大小
- gamma: 折扣因子
- learning_rate: 学习率
- epsilon_start: 初始探索率
- epsilon_final: 最终探索率
- epsilon_decay: 探索率衰减系数
- target_update: 目标网络更新频率
- device: 计算设备(CPU或GPU)
"""
self.state_shape = state_shape
self.n_actions = n_actions
self.batch_size = batch_size
self.gamma = gamma
self.target_update = target_update
self.device = device
# 创建策略网络和目标网络
self.policy_net = DQN(state_shape, n_actions).to(device)
self.target_net = DQN(state_shape, n_actions).to(device)
# 目标网络初始化为与策略网络相同的权重
self.target_net.load_state_dict(self.policy_net.state_dict())
self.target_net.eval() # 目标网络不需要训练
# 创建优化器
self.optimizer = optim.Adam(self.policy_net.parameters(), lr=learning_rate)
# 创建经验回放缓冲区
self.memory = ReplayBuffer(replay_size)
# 创建ε-greedy策略
self.strategy = EpsilonGreedyStrategy(epsilon_start, epsilon_final, epsilon_decay)
# 训练步数
self.steps_done = 0
def select_action(self, state):
"""根据当前策略选择动作"""
return self.strategy.select_action(
self.steps_done, self.policy_net, state, self.n_actions, self.device
)
def store_transition(self, state, action, reward, next_state, done):
"""存储经验到回放缓冲区"""
self.memory.add(state, action, reward, next_state, done)
def optimize_model(self):
"""从回放缓冲区采样并优化模型"""
if len(self.memory) < self.batch_size:
return
# 从回放缓冲区采样
states, actions, rewards, next_states, dones = self.memory.sample(self.batch_size)
# 转换为PyTorch张量
states = torch.tensor(states, dtype=torch.float32).to(self.device)
actions = torch.tensor(actions, dtype=torch.long).to(self.device)
rewards = torch.tensor(rewards, dtype=torch.float32).to(self.device)
next_states = torch.tensor(next_states, dtype=torch.float32).to(self.device)
dones = torch.tensor(dones, dtype=torch.float32).to(self.device)
# 计算当前Q值
current_q_values = self.policy_net(states).gather(1, actions.unsqueeze(1)).squeeze(1)
# 计算目标Q值(使用目标网络)
with torch.no_grad():
next_q_values = self.target_net(next_states).max(1)[0]
target_q_values = rewards + (1 - dones) * self.gamma * next_q_values
# 计算损失
loss = nn.functional.smooth_l1_loss(current_q_values, target_q_values)
# 优化模型
self.optimizer.zero_grad()
loss.backward()
# 梯度裁剪,防止梯度爆炸
torch.nn.utils.clip_grad_norm_(self.policy_net.parameters(), max_norm=10.0)
self.optimizer.step()
# 更新步数
self.steps_done += 1
# 定期更新目标网络
if self.steps_done % self.target_update == 0:
self.target_net.load_state_dict(self.policy_net.state_dict())
return loss.item()
def train(self, env, num_episodes, max_steps=10000):
"""训练智能体"""
rewards = []
for episode in range(num_episodes):
state = env.reset()
episode_reward = 0
episode_loss = 0
for step in range(max_steps):
# 选择动作
action = self.select_action(state)
# 执行动作
next_state, reward, done, _ = env.step(action)
# 存储经验
self.store_transition(state, action, reward, next_state, done)
# 优化模型
loss = self.optimize_model()
if loss is not None:
episode_loss += loss
# 更新状态和奖励
state = next_state
episode_reward += reward
if done:
break
# 记录奖励
rewards.append(episode_reward)
# 打印进度
if (episode + 1) % 10 == 0:
avg_reward = np.mean(rewards[-10:])
print(f"Episode {episode+1}/{num_episodes} | Avg Reward: {avg_reward:.2f} | "
f"Epsilon: {self.strategy.current:.4f} | Steps: {self.steps_done}")
return rewards
def evaluate(self, env, num_episodes=10, render=False):
"""评估智能体性能"""
self.policy_net.eval()
rewards = []
for _ in range(num_episodes):
state = env.reset()
episode_reward = 0
done = False
while not done:
if render:
env.render()
time.sleep(0.02)
# 选择最佳动作(无探索)
with torch.no_grad():
state_tensor = torch.tensor(state, dtype=torch.float32).unsqueeze(0).to(self.device)
q_values = self.policy_net(state_tensor)
action = torch.argmax(q_values).item()
next_state, reward, done, _ = env.step(action)
state = next_state
episode_reward += reward
rewards.append(episode_reward)
self.policy_net.train()
return np.mean(rewards)
def save(self, path):
"""保存模型"""
torch.save({
'policy_net': self.policy_net.state_dict(),
'target_net': self.target_net.state_dict(),
'optimizer': self.optimizer.state_dict(),
'steps_done': self.steps_done
}, path)
def load(self, path):
"""加载模型"""
checkpoint = torch.load(path)
self.policy_net.load_state_dict(checkpoint['policy_net'])
self.target_net.load_state_dict(checkpoint['target_net'])
self.optimizer.load_state_dict(checkpoint['optimizer'])
self.steps_done = checkpoint['steps_done']
3. 主程序:训练DQN玩Atari游戏
现在,让我们创建一个完整的训练脚本,用于训练DQN玩Atari游戏:
import torch
import numpy as np
import matplotlib.pyplot as plt
import os
import argparse
from datetime import datetime
# 导入我们之前定义的模块
# 在实际使用时,你需要确保这些模块都已定义
from dqn_model import DQN
from replay_buffer import ReplayBuffer
from epsilon_greedy import EpsilonGreedyStrategy
from atari_preprocessing import AtariPreprocessing, create_atari_env
from dqn_agent import DQNAgent
def plot_rewards(rewards, window_size=10, save_path=None):
"""绘制奖励曲线"""
plt.figure(figsize=(10, 5))
plt.plot(rewards, alpha=0.5, label='Reward')
# 计算移动平均
moving_avg = np.convolve(rewards, np.ones(window_size)/window_size, mode='valid')
plt.plot(np.arange(len(moving_avg)) + window_size-1, moving_avg, label=f'Moving Avg (window={window_size})')
plt.xlabel('Episode')
plt.ylabel('Total Reward')
plt.title('Training Rewards')
plt.legend()
if save_path:
plt.savefig(save_path)
plt.show()
def main():
# 解析命令行参数
parser = argparse.ArgumentParser(description='Train DQN on Atari games')
parser.add_argument('--game', type=str, default='Breakout', help='Atari game to play')
parser.add_argument('--episodes', type=int, default=500, help='Number of training episodes')
parser.add_argument('--batch-size', type=int, default=32, help='Batch size for training')
parser.add_argument('--lr', type=float, default=0.0001, help='Learning rate')
parser.add_argument('--gamma', type=float, default=0.99, help='Discount factor')
parser.add_argument('--epsilon-start', type=float, default=1.0, help='Initial exploration rate')
parser.add_argument('--epsilon-final', type=float, default=0.01, help='Final exploration rate')
parser.add_argument('--epsilon-decay', type=float, default=0.0001, help='Exploration rate decay')
parser.add_argument('--target-update', type=int, default=1000, help='Target network update frequency')
parser.add_argument('--eval-episodes', type=int, default=10, help='Number of evaluation episodes')
parser.add_argument('--render', action='store_true', help='Render during evaluation')
parser.add_argument('--save-dir', type=str, default='models', help='Directory to save models')
args = parser.parse_args()
# 设置实验ID(时间戳)
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
experiment_id = f"{args.game}_{timestamp}"
# 创建保存目录
save_dir = os.path.join(args.save_dir, experiment_id)
os.makedirs(save_dir, exist_ok=True)
# 创建环境
env = create_atari_env(args.game)
eval_env = create_atari_env(args.game)
# 获取状态形状和动作数量
state_shape = env.observation_space.shape
n_actions = env.action_space.n
print(f"Game: {args.game}")
print(f"State shape: {state_shape}")
print(f"Number of actions: {n_actions}")
# 创建DQN智能体
agent = DQNAgent(
state_shape=state_shape,
n_actions=n_actions,
batch_size=args.batch_size,
gamma=args.gamma,
learning_rate=args.lr,
epsilon_start=args.epsilon_start,
epsilon_final=args.epsilon_final,
epsilon_decay=args.epsilon_decay,
target_update=args.target_update
)
# 训练
print("Starting training...")
rewards = agent.train(env, args.episodes)
# 保存模型
model_path = os.path.join(save_dir, f"dqn_model.pt")
agent.save(model_path)
print(f"Model saved to {model_path}")
# 绘制奖励曲线
plot_path = os.path.join(save_dir, f"rewards.png")
plot_rewards(rewards, save_path=plot_path)
# 评估
print("Evaluating agent...")
avg_reward = agent.evaluate(eval_env, args.eval_episodes, args.render)
print(f"Average evaluation reward: {avg_reward:.2f}")
# 关闭环境
env.close()
eval_env.close()
if __name__ == "__main__":
main()
4. ε-greedy策略与其他探索策略的对比
让我们对比几种不同的探索策略,以了解它们对DQN性能的影响:
import torch
import numpy as np
import random
import math
class EpsilonGreedyStrategy:
"""标准的ε-greedy策略,使用指数衰减"""
def __init__(self, start, end, decay):
self.start = start
self.end = end
self.decay = decay
self.current = start
def get_exploration_rate(self, step):
"""返回当前的探索率(指数衰减)"""
self.current = self.end + (self.start - self.end) * \
math.exp(-1. * step * self.decay)
return self.current
def select_action(self, step, net, state, n_actions, device):
"""选择动作"""
exploration_rate = self.get_exploration_rate(step)
if random.random() < exploration_rate:
# 探索:随机选择动作
return random.randrange(n_actions)
else:
# 利用:选择Q值最大的动作
with torch.no_grad():
state_tensor = torch.tensor(state, dtype=torch.float32).unsqueeze(0).to(device)
q_values = net(state_tensor)
return torch.argmax(q_values).item()
class LinearEpsilonGreedyStrategy:
"""使用线性衰减的ε-greedy策略"""
def __init__(self, start, end, decay_steps):
self.start = start
self.end = end
self.decay_steps = decay_steps
self.current = start
def get_exploration_rate(self, step):
"""返回当前的探索率(线性衰减)"""
# 线性衰减
fraction = min(float(step) / self.decay_steps, 1.0)
self.current = self.start + fraction * (self.end - self.start)
return self.current
def select_action(self, step, net, state, n_actions, device):
"""选择动作"""
exploration_rate = self.get_exploration_rate(step)
if random.random() < exploration_rate:
# 探索:随机选择动作
return random.randrange(n_actions)
else:
# 利用:选择Q值最大的动作
with torch.no_grad():
state_tensor = torch.tensor(state, dtype=torch.float32).unsqueeze(0).to(device)
q_values = net(state_tensor)
return torch.argmax(q_values).item()
class BoltzmannExplorationStrategy:
"""Boltzmann探索策略(基于概率分布)"""
def __init__(self, temp_start, temp_end, decay):
self.temp_start = temp_start
self.temp_end = temp_end
self.decay = decay
self.current_temp = temp_start
def get_temperature(self, step):
"""返回当前温度(指数衰减)"""
self.current_temp = self.temp_end + (self.temp_start - self.temp_end) * \
math.exp(-1. * step * self.decay)
return self.current_temp
def select_action(self, step, net, state, n_actions, device):
"""基于Boltzmann分布选择动作"""
temperature = self.get_temperature(step)
with torch.no_grad():
state_tensor = torch.tensor(state, dtype=torch.float32).unsqueeze(0).to(device)
q_values = net(state_tensor)[0]
# 应用Boltzmann分布(softmax with temperature)
probs = torch.softmax(q_values / temperature, dim=0).cpu().numpy()
# 基于概率分布选择动作
return np.random.choice(n_actions, p=probs)
class OrnsteinUhlenbeckNoiseStrategy:
"""Ornstein-Uhlenbeck噪声探索策略(适用于连续动作空间,这里为演示)"""
def __init__(self, mu=0, theta=0.15, sigma=0.2, dt=1e-2):
self.mu = mu
self.theta = theta
self.sigma = sigma
self.dt = dt
self.noise = 0
def get_noise(self):
"""生成Ornstein-Uhlenbeck噪声"""
self.noise = self.noise + self.theta * (self.mu - self.noise) * self.dt + \
self.sigma * np.sqrt(self.dt) * np.random.normal()
return self.noise
def select_action(self, step, net, state, n_actions, device):
"""基于网络输出加噪声选择动作(适用于连续动作空间,这里转换为离散)"""
with torch.no_grad():
state_tensor = torch.tensor(state, dtype=torch.float32).unsqueeze(0).to(device)
q_values = net(state_tensor)[0].cpu().numpy()
# 为每个Q值添加噪声
noisy_q_values = q_values + np.array([self.get_noise() for _ in range(n_actions)])
# 选择具有最高噪声Q值的动作
return np.argmax(noisy_q_values)
class UCBStrategy:
"""上置信界(UCB)探索策略"""
def __init__(self, c=2.0):
self.c = c # 探索常数
self.action_counts = None
self.step = 0
def reset(self, n_actions):
"""重置动作计数"""
self.action_counts = np.zeros(n_actions)
self.step = 0
def select_action(self, step, net, state, n_actions, device):
"""使用UCB策略选择动作"""
self.step = step
# 首次调用时初始化计数器
if self.action_counts is None:
self.reset(n_actions)
with torch.no_grad():
state_tensor = torch.tensor(state, dtype=torch.float32).unsqueeze(0).to(device)
q_values = net(state_tensor)[0].cpu().numpy()
# 计算UCB值
ucb_values = np.zeros(n_actions)
for a in range(n_actions):
if self.action_counts[a] > 0:
# UCB公式:Q(s,a) + c * sqrt(ln(t) / N(a))
ucb_values[a] = q_values[a] + self.c * \
np.sqrt(np.log(self.step + 1) / self.action_counts[a])
else:
# 未选择过的动作赋予高优先级
ucb_values[a] = 1e6
# 选择具有最高UCB值的动作
action = np.argmax(ucb_values)
self.action_counts[action] += 1
return action
5. 探索策略对比实验
现在让我们创建一个脚本来对比不同探索策略的性能:
import torch
import numpy as np
import matplotlib.pyplot as plt
import os
import time
from datetime import datetime
# 假设已导入所有必要的类(DQN模型、环境预处理等)
from exploration_strategies import (
EpsilonGreedyStrategy,
LinearEpsilonGreedyStrategy,
BoltzmannExplorationStrategy,
UCBStrategy
)
class StrategyExperiment:
def __init__(self, game_name='Breakout', episodes=200, train_steps=10000):
self.game_name = game_name
self.episodes = episodes
self.train_steps = train_steps
self.strategies = {
'Epsilon-Greedy (Exponential)': EpsilonGreedyStrategy(start=1.0, end=0.01, decay=0.0001),
'Epsilon-Greedy (Linear)': LinearEpsilonGreedyStrategy(start=1.0, end=0.01, decay_steps=100000),
'Boltzmann': BoltzmannExplorationStrategy(temp_start=10.0, temp_end=0.1, decay=0.0001),
'UCB': UCBStrategy(c=2.0)
}
# 设置实验ID
self.timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
self.experiment_id = f"{game_name}_strategy_comparison_{self.timestamp}"
self.save_dir = os.path.join('experiments', self.experiment_id)
os.makedirs(self.save_dir, exist_ok=True)
# 设置日志文件
self.log_file = os.path.join(self.save_dir, 'experiment_log.txt')
with open(self.log_file, 'w') as f:
f.write(f"Exploration Strategy Comparison Experiment\n")
f.write(f"Game: {game_name}\n")
f.write(f"Episodes: {episodes}\n")
f.write(f"Train Steps: {train_steps}\n")
f.write(f"Date: {self.timestamp}\n\n")
def log(self, message):
"""记录消息到日志文件"""
print(message)
with open(self.log_file, 'a') as f:
f.write(message + '\n')
def run_experiment(self):
"""运行所有策略的实验"""
results = {}
for name, strategy in self.strategies.items():
self.log(f"\n{'='*50}")
self.log(f"Training with strategy: {name}")
self.log(f"{'='*50}")
# 创建环境
env = create_atari_env(self.game_name)
eval_env = create_atari_env(self.game_name)
# 获取状态形状和动作数量
state_shape = env.observation_space.shape
n_actions = env.action_space.n
# 创建DQN智能体(使用指定的探索策略)
agent = self.create_agent(state_shape, n_actions, strategy)
# 训练智能体
start_time = time.time()
rewards = agent.train(env, self.episodes, self.train_steps)
train_time = time.time() - start_time
# 评估性能
eval_reward = agent.evaluate(eval_env, 10)
# 保存结果
results[name] = {
'rewards': rewards,
'eval_reward': eval_reward,
'train_time': train_time
}
# 保存模型
model_path = os.path.join(self.save_dir, f"{name.replace(' ', '_').lower()}.pt")
agent.save(model_path)
# 记录结果
self.log(f"Training time: {train_time:.2f} seconds")
self.log(f"Final average reward: {np.mean(rewards[-10:]):.2f}")
self.log(f"Evaluation reward: {eval_reward:.2f}")
# 关闭环境
env.close()
eval_env.close()
return results
def create_agent(self, state_shape, n_actions, strategy):
"""创建DQN智能体,使用指定的探索策略"""
# 这里我们修改DQNAgent的构造方法,允许传入自定义策略
agent = DQNAgent(
state_shape=state_shape,
n_actions=n_actions,
batch_size=32,
gamma=0.99,
learning_rate=0.0001,
target_update=1000,
custom_strategy=strategy # 传入自定义策略
)
return agent
def plot_results(self, results):
"""绘制结果对比图"""
# 学习曲线对比
plt.figure(figsize=(12, 8))
for name, data in results.items():
rewards = data['rewards']
plt.plot(rewards, alpha=0.3, label=f"{name} (raw)")
# 计算移动平均
window_size = 10
moving_avg = np.convolve(rewards, np.ones(window_size)/window_size, mode='valid')
plt.plot(np.arange(len(moving_avg)) + window_size-1, moving_avg,
label=f"{name} (MA-{window_size})")
plt.xlabel('Episode')
plt.ylabel('Total Reward')
plt.title(f'Exploration Strategy Comparison - {self.game_name}')
plt.legend()
plt.grid(True, alpha=0.3)
plot_path = os.path.join(self.save_dir, 'learning_curves.png')
plt.savefig(plot_path)
plt.close()
# 性能指标对比
plt.figure(figsize=(10, 6))
names = list(results.keys())
eval_rewards = [data['eval_reward'] for data in results.values()]
train_times = [data['train_time'] / 60 for data in results.values()] # 转换为分钟
x = np.arange(len(names))
width = 0.35
fig, ax1 = plt.subplots(figsize=(12, 6))
ax2 = ax1.twinx()
bars1 = ax1.bar(x - width/2, eval_rewards, width, label='Evaluation Reward', color='royalblue')
bars2 = ax2.bar(x + width/2, train_times, width, label='Training Time (min)', color='lightcoral')
ax1.set_xlabel('Exploration Strategy')
ax1.set_ylabel('Average Evaluation Reward', color='royalblue')
ax2.set_ylabel('Training Time (minutes)', color='lightcoral')
ax1.set_xticks(x)
ax1.set_xticklabels(names, rotation=45, ha='right')
ax1.legend(loc='upper left')
ax2.legend(loc='upper right')
plt.title(f'Performance Metrics - {self.game_name}')
plt.tight_layout()
metrics_path = os.path.join(self.save_dir, 'performance_metrics.png')
plt.savefig(metrics_path)
plt.close()
# 总结指标到日志
self.log("\n\nExperiment Summary:")
self.log("-" * 50)
self.log(f"{'Strategy':<25} {'Eval Reward':<15} {'Train Time (min)':<15}")
self.log("-" * 50)
for i, name in enumerate(names):
self.log(f"{name:<25} {eval_rewards[i]:<15.2f} {train_times[i]:<15.2f}")
# 主函数
def compare_exploration_strategies(game='Breakout', episodes=200):
experiment = StrategyExperiment(game_name=game, episodes=episodes)
results = experiment.run_experiment()
experiment.plot_results(results)
return results
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(description='Compare exploration strategies for DQN')
parser.add_argument('--game', type=str, default='Breakout', help='Atari game to play')
parser.add_argument('--episodes', type=int, default=200, help='Number of training episodes')
args = parser.parse_args()
compare_exploration_strategies(args.game, args.episodes)
6. DQN训练完整流程图
让我们通过一个详细的流程图来理解DQN在Atari游戏中的训练过程: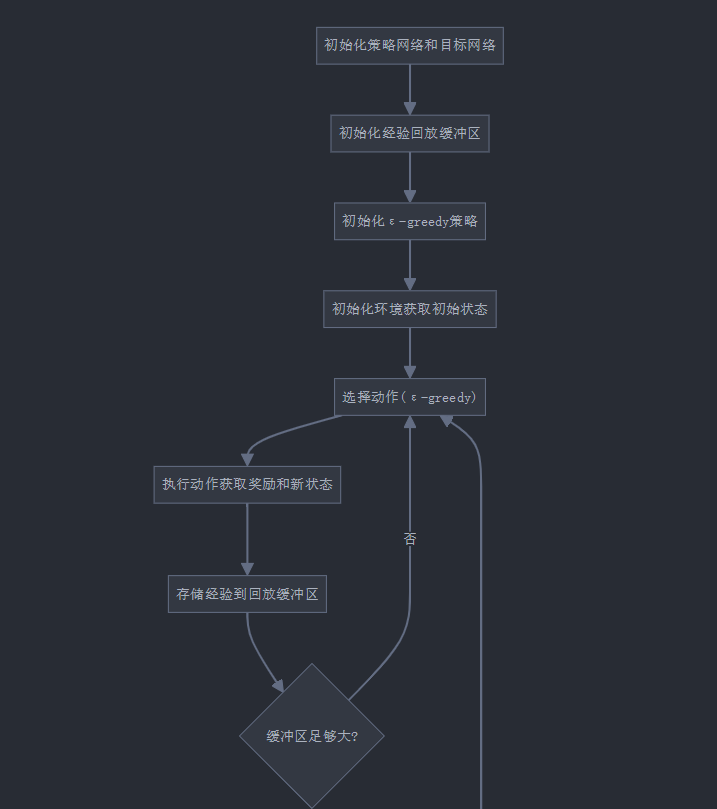
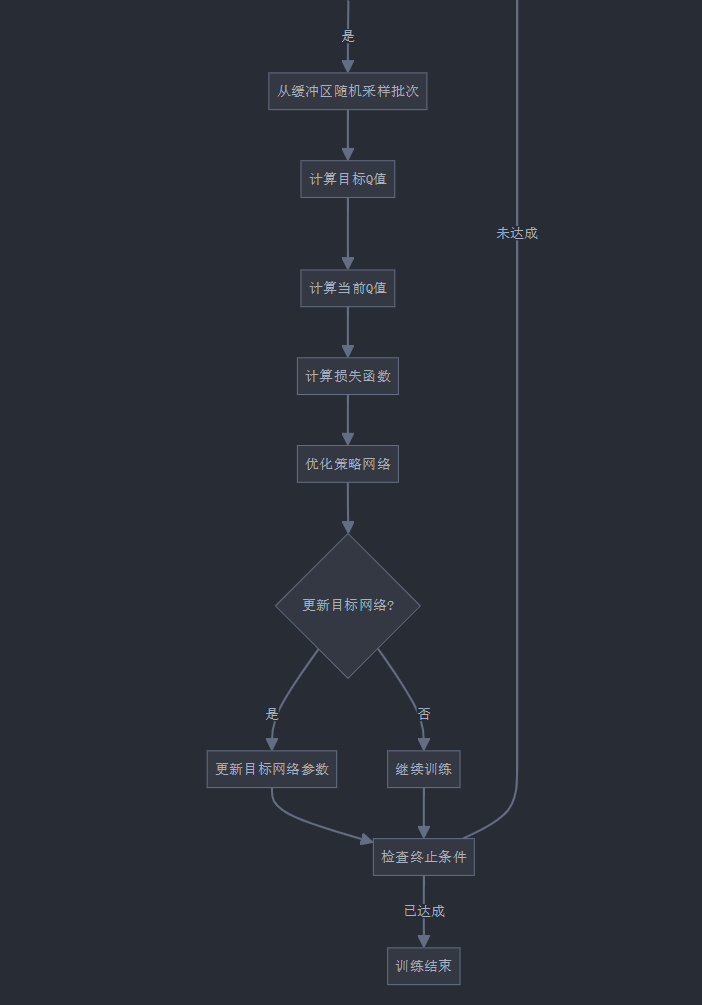
7. 结果分析与优化建议
让我们分析不同探索策略的优缺点,并提供一些优化DQN性能的建议:
探索策略对比分析
探索策略比较表
| 策略 | 优点 | 缺点 | 最适用场景 |
|---|---|---|---|
| ε-greedy(指数衰减) | • 实现简单 • 参数较少 • 收敛稳定 • 初期大范围探索,后期高效利用 |
• 探索方式粗暴,纯随机 • 可能错过重要状态 • 探索与状态价值无关 |
• 大多数一般性问题 • 环境比较简单的游戏 • 需要平衡探索与利用的场景 |
| ε-greedy(线性衰减) | • 实现简单 • 衰减速度可预测 • 更渐进的探索-利用过渡 |
• 初期可能探索不足 • 衰减可能过快或过慢 • 对学习进度缺乏适应性 |
• 任务难度适中 • 训练步数有明确上限 • 需要可控的探索过程 |
| Boltzmann(Softmax) | • 基于状态价值智能探索 • 探索更有针对性 • 动作选择更平滑、概率化 |
• 温度参数难调整 • 计算成本较高 • 对Q值规模敏感 |
• 动作空间较大 • 需要精细探索 • 动作价值差异明显 |
| UCB(上置信界) | • 理论保证更好 • 智能平衡探索与利用 • 关注未充分探索的动作 |
• 实现相对复杂 • 需要额外记录动作计数 • 可能在某些环境下过度探索 |
• 多臂赌博机问题 • 需要保证探索完整性 • 动作选择至关重要 |
不同游戏类型的最佳策略选择
| 游戏类型 | 推荐策略 | 理由 |
|---|---|---|
| Pong, Breakout (简单规则) | ε-greedy (指数) | 规则简单,探索空间小,标准ε-greedy足够 |
| Space Invaders, Assault (中等复杂度) | ε-greedy (线性) + 优先经验回放 | 需要更均衡的探索时间,优先学习重要经验 |
| Seaquest, Ms. Pacman (复杂状态空间) | Boltzmann | 状态复杂,需要智能探索不同状态的价值 |
| Montezuma’s Revenge (稀疏奖励) | UCB + 内在激励 | 奖励稀疏,需要系统探索未知区域 |
优化DQN性能的建议
1. 经验回放机制优化
- 优先经验回放: 根据TD误差大小对经验进行抽样,关注更具信息量的经验
- 分层经验回放: 将经验按照不同特征(如罕见程度)分层存储
- 情节经验回放: 存储完整游戏情节,保留时序关系
2. 网络架构优化
- 双DQN: 使用单独网络选择动作和评估动作,减少过高估计问题
- 杜宾DQN: 结合双DQN和优先经验回放
- 彩虹DQN: 集成多种DQN改进,实现更稳定高效学习
3. 探索策略增强
- 噪声网络: 在策略网络中添加噪声层,生成探索行为
- 内在激励: 为访问新状态或减少不确定性提供额外奖励
- 好奇心驱动探索: 通过预测误差作为好奇心信号驱动探索
4. 训练流程优化
- 帧堆叠优化: 尝试不同帧数(2-8)的堆叠
- 奖励裁剪: 将奖励限制在[-1,1]范围,提高训练稳定性
- 游戏终止处理: 正确处理游戏自然结束与失败终止
实践经验
- 对于初学者: 从标准ε-greedy策略开始,熟悉DQN基本流程
- 提高性能: 添加双DQN和优先经验回放,通常能显著提升
- 解决困难游戏: 对于奖励稀疏的游戏,考虑添加内在激励或好奇心机制
- 调参技巧:
- 初始ε设置为1.0,确保充分探索
- 衰减率应考虑总训练步数(decay ≈ 5/总步数)
- Boltzmann温度从高值(约10)开始,缓慢降至低值(约0.1)
常见问题解决方案
| 问题 | 可能原因 | 解决方案 |
|---|---|---|
| 训练不稳定 | ε衰减过快,经验不足 | 降低衰减率,增大回放缓冲区 |
| 陷入局部最优 | 探索不足,缺乏探索策略多样性 | 尝试Boltzmann或UCB策略 |
| 奖励稀疏无法学习 | 正面反馈太少,无法有效学习 | 添加内在激励,使用优先经验回放 |
| 过拟合特定场景 | 经验多样性不足,泛化能力差 | 增加随机性,应用正则化技术 |
8. Atari游戏案例分析:Breakout
为了更好地理解DQN在游戏中的应用,让我们分析一个经典案例——Breakout游戏:
Breakout游戏DQN案例分析
游戏特点分析
Breakout(打砖块)是一款经典的Atari游戏,它具有以下特点:
- 状态空间:游戏画面包含挡板、球和砖块
- 动作空间:3个动作(左移、右移、不动)
- 奖励设计:击碎砖块获得正奖励,丢球则游戏结束
- 游戏难度:规则简单,但需要良好的时机判断和预测能力
- 策略要点:跟踪球的运动并移动挡板接球
DQN学习分析
通过对DQN训练Breakout的过程分析,可以观察到以下学习阶段:
-
初始阶段(0-100回合):
- 智能体表现:随机移动挡板,很少能接到球
- 学习重点:建立基本的"挡板-球"关联
- 典型问题:经验不足,Q值估计不准确
-
基础策略期(100-300回合):
- 智能体表现:学会跟随球移动,偶尔能进行几次连续接球
- 学习重点:建立"当前球位置→挡板位置"的映射
- 典型问题:缺乏预测能力,只关注当前状态
-
策略提升期(300-500回合):
- 智能体表现:能预测球的轨迹,提前移动到合适位置
- 学习重点:识别球的运动规律,优化时间差
- 典型问题:特定场景处理不佳,如角落反弹
-
高级策略期(500+回合):
- 智能体表现:掌握复杂策略,如创造通道打高层砖块
- 学习重点:理解长期奖励最大化的策略
- 成就:能够实现远超人类平均水平的游戏得分
关键学习阶段与Q值变化
下面是Breakout游戏中DQN智能体学习过程中的关键阶段和对应的Q值变化:
| 学习阶段 | 游戏画面描述 | 动作Q值分布 | 策略解读 |
|---|---|---|---|
| 早期 | 球向下落,挡板位于中间 | 左: 0.2, 不动: 0.1, 右: 0.3 | 随机探索阶段,Q值无明显规律 |
| 中期 | 球向左下方落,挡板在右 | 左: 4.8, 不动: 1.2, 右: -2.3 | 学会基本追球,向球移动的Q值明显更高 |
| 后期 | 球即将反弹到高层砖块 | 左: -1.2, 不动: 6.7, 右: -0.8 | 学会预测并等待,有时故意不动以等待最佳时机 |
| 高级 | 左侧形成通道,球在右侧 | 左: 8.9, 不动: 2.1, 右: 1.3 | 学会创造并利用通道策略,主动向左让球进入通道 |
经验回放对学习的影响
经验回放对Breakout游戏的学习至关重要,具体影响如下:
-
关键经验保存:
- 成功接到球的经验被保存并多次重用
- 罕见事件(如形成通道并获得高分)能够被记住并学习
-
样本相关性破解:
- 打破连续帧之间的高相关性
- 避免智能体陷入局部策略循环
-
数据效率提升:
- 每个经验平均被使用8-10次
- 特别是游戏初期,稀缺的正向经验得到充分利用
-
学习稳定性:
- 减少策略震荡
- 平滑学习曲线,避免灾难性遗忘
ε-greedy策略效果分析
在Breakout游戏中,ε-greedy策略的效果表现如下:
-
探索阶段影响:
- 初始高ε值(0.9-1.0)确保全面探索动作空间
- 发现偶然成功的策略(如通道战术)
-
利用阶段效果:
- ε降至0.1以下时,智能体能稳定执行已学习的策略
- 保留少量随机性有助于发现新策略并适应游戏随机性
-
衰减率影响:
- 过快衰减(如0.001)导致过早放弃探索,难以发现高级策略
- 过慢衰减(如0.00001)导致学习效率低,浪费训练时间
- 最佳衰减率约为0.0001,平衡探索与利用
-
策略收敛分析:
- 300回合后开始形成稳定追球策略
- 500回合后能够表现出预测能力
- 1000回合后可能发现创造通道等高级策略
困难与解决方案
在训练Breakout游戏DQN智能体过程中常见的挑战及其解决方案:
-
延迟奖励问题:
- 挑战:击打砖块与移动挡板之间存在时间差
- 解决:增加堆叠帧数(4→8),使模型能看到更长的动作序列
-
策略崩溃:
- 挑战:有时训练中后期性能突然下降
- 解决:实现Double DQN减少过高估计,降低学习率
-
通道策略难发现:
- 挑战:创造并利用砖块通道是高分关键,但难以通过随机探索发现
- 解决:加入好奇心奖励,鼓励尝试新颖状态
-
困难场景处理:
- 挑战:某些特殊球路(如快速斜线)难以学习
- 解决:优先经验回放,增加稀有场景的采样概率
性能提升技巧
基于实验和分析,以下技巧能显著提升Breakout游戏的DQN性能:
-
网络架构优化:
- 增加一个注意力层,关注球和挡板位置
- 适当扩大网络(512→1024神经元)提升表达能力
-
奖励设计调整:
- 为接球添加小额正奖励(+0.1)
- 为球靠近挡板但未接到添加小额负奖励(-0.1)
-
学习率调度:
- 初期使用较高学习率(1e-4)快速学习
- 后期降低学习率(5e-5)微调策略
-
经验回放增强:
- 实现优先经验回放,关注TD误差大的经验
- 保留一定比例的高分回合经验,不被覆盖
结论
通过Breakout游戏的DQN训练案例,我们可以得出以下结论和启示:
-
探索策略至关重要:ε-greedy策略在Breakout等简单规则游戏中表现良好,但对于更复杂游戏可能需要更智能的探索方法
-
经验回放是关键:适当的经验回放机制对于学习效率和稳定性有决定性影响
-
结构化奖励有助学习:为中间目标设计小额奖励可以显著加速学习过程
-
泛化与记忆平衡:DQN需要同时具备对常见情况的泛化能力和对关键策略的记忆能力
-
层次化学习过程:DQN学习呈现明显的阶段性,从基础反应到策略规划,类似人类学习过程
让我继续完成Breakout游戏案例分析的内容:
9. 实用代码片段与调试技巧
最后,让我提供一些实用的代码片段和调试技巧,帮助你在实际项目中更好地应用DQN:
import numpy as np
import matplotlib.pyplot as plt
import time
import torch
from torch.utils.tensorboard import SummaryWriter
from collections import deque
class DQNMonitor:
"""DQN训练监控器,用于跟踪和可视化训练过程"""
def __init__(self, log_dir='runs/dqn_monitor'):
"""初始化监控器"""
self.writer = SummaryWriter(log_dir)
self.rewards_history = []
self.q_values_history = []
self.losses_history = []
self.exploration_rates = []
self.evaluation_rewards = []
self.episode_lengths = []
# 性能监控
self.fps_buffer = deque(maxlen=100)
self.start_time = time.time()
self.steps = 0
# TD误差直方图数据
self.td_errors = []
def log_episode(self, episode, rewards, q_values, losses, exploration_rate, episode_length):
"""记录一个训练回合的数据"""
# 计算统计数据
episode_reward = sum(rewards)
mean_q = np.mean(q_values) if q_values else 0
mean_loss = np.mean(losses) if losses else 0
# 存储历史数据
self.rewards_history.append(episode_reward)
self.q_values_history.append(mean_q)
self.losses_history.append(mean_loss)
self.exploration_rates.append(exploration_rate)
self.episode_lengths.append(episode_length)
# 写入TensorBoard
self.writer.add_scalar('Training/Episode Reward', episode_reward, episode)
self.writer.add_scalar('Training/Mean Q Value', mean_q, episode)
self.writer.add_scalar('Training/Mean Loss', mean_loss, episode)
self.writer.add_scalar('Training/Exploration Rate', exploration_rate, episode)
self.writer.add_scalar('Training/Episode Length', episode_length, episode)
# 更新步数和计算FPS
self.steps += episode_length
elapsed = time.time() - self.start_time
fps = episode_length / elapsed if elapsed > 0 else 0
self.fps_buffer.append(fps)
self.start_time = time.time()
self.writer.add_scalar('Performance/FPS', fps, episode)
self.writer.add_scalar('Performance/Total Steps', self.steps, episode)
# 每10回合打印一次摘要
if episode % 10 == 0:
avg_reward = np.mean(self.rewards_history[-10:])
avg_q = np.mean(self.q_values_history[-10:])
avg_loss = np.mean(self.losses_history[-10:])
avg_fps = np.mean(list(self.fps_buffer)) if self.fps_buffer else 0
print(f"Episode {episode} | "
f"Avg Reward: {avg_reward:.2f} | "
f"Avg Q: {avg_q:.4f} | "
f"Avg Loss: {avg_loss:.6f} | "
f"Epsilon: {exploration_rate:.4f} | "
f"FPS: {avg_fps:.1f}")
def log_td_errors(self, td_errors, episode):
"""记录TD误差分布"""
self.td_errors.extend(td_errors)
# 每100回合记录一次直方图
if episode % 100 == 0 and self.td_errors:
self.writer.add_histogram('Training/TD Errors',
np.array(self.td_errors),
episode)
self.td_errors = [] # 清空缓存
def log_evaluation(self, episode, eval_rewards):
"""记录评估结果"""
avg_eval_reward = np.mean(eval_rewards)
self.evaluation_rewards.append(avg_eval_reward)
self.writer.add_scalar('Evaluation/Mean Reward', avg_eval_reward, episode)
print(f"Evaluation at episode {episode}: Avg Reward = {avg_eval_reward:.2f}")
def log_action_distribution(self, episode, actions):
"""记录动作分布"""
unique, counts = np.unique(actions, return_counts=True)
action_dist = dict(zip(unique, counts))
# 写入动作分布
for action, count in action_dist.items():
self.writer.add_scalar(f'Actions/Action_{action}', count, episode)
# 计算熵,衡量动作多样性
probs = counts / np.sum(counts)
entropy = -np.sum(probs * np.log(probs + 1e-10))
self.writer.add_scalar('Actions/Entropy', entropy, episode)
def log_network_gradients(self, episode, net):
"""记录网络梯度"""
total_norm = 0
for p in net.parameters():
if p.grad is not None:
param_norm = p.grad.data.norm(2)
total_norm += param_norm.item() ** 2
total_norm = total_norm ** 0.5
self.writer.add_scalar('Network/Gradient Norm', total_norm, episode)
def log_layer_activations(self, episode, layer_outputs):
"""记录网络层激活值"""
for name, outputs in layer_outputs.items():
# 计算激活统计数据
mean_act = torch.mean(outputs).item()
std_act = torch.std(outputs).item()
max_act = torch.max(outputs).item()
self.writer.add_scalar(f'Activations/{name}_mean', mean_act, episode)
self.writer.add_scalar(f'Activations/{name}_std', std_act, episode)
self.writer.add_scalar(f'Activations/{name}_max', max_act, episode)
def plot_training_progress(self, save_path=None):
"""绘制训练进度图表"""
fig, axs = plt.subplots(3, 2, figsize=(15, 12))
# 奖励曲线
axs[0, 0].plot(self.rewards_history)
# 添加移动平均线
window = min(10, len(self.rewards_history))
if window > 0:
moving_avg = np.convolve(self.rewards_history,
np.ones(window)/window,
mode='valid')
axs[0, 0].plot(range(window-1, len(self.rewards_history)),
moving_avg, 'r-')
axs[0, 0].set_title('Episode Rewards')
axs[0, 0].set_xlabel('Episode')
axs[0, 0].set_ylabel('Total Reward')
# Q值曲线
axs[0, 1].plot(self.q_values_history)
axs[0, 1].set_title('Mean Q Values')
axs[0, 1].set_xlabel('Episode')
axs[0, 1].set_ylabel('Mean Q Value')
# 损失曲线
axs[1, 0].plot(self.losses_history)
axs[1, 0].set_title('Training Loss')
axs[1, 0].set_xlabel('Episode')
axs[1, 0].set_ylabel('Mean Loss')
axs[1, 0].set_yscale('log') # 对数尺度更易观察
# 探索率曲线
axs[1, 1].plot(self.exploration_rates)
axs[1, 1].set_title('Exploration Rate')
axs[1, 1].set_xlabel('Episode')
axs[1, 1].set_ylabel('Epsilon')
# 评估奖励曲线
axs[2, 0].plot(range(0, len(self.evaluation_rewards)*100, 100),
self.evaluation_rewards, 'g-o')
axs[2, 0].set_title('Evaluation Rewards')
axs[2, 0].set_xlabel('Episode')
axs[2, 0].set_ylabel('Mean Evaluation Reward')
# 回合长度曲线
axs[2, 1].plot(self.episode_lengths)
axs[2, 1].set_title('Episode Lengths')
axs[2, 1].set_xlabel('Episode')
axs[2, 1].set_ylabel('Steps')
plt.tight_layout()
if save_path:
plt.savefig(save_path)
plt.show()
def close(self):
"""关闭监控器"""
self.writer.close()
# 使用示例
def debug_dqn_training():
"""演示如何在训练过程中使用监控器进行调试"""
# 创建监控器
monitor = DQNMonitor(log_dir='runs/dqn_breakout_debug')
# 模拟一个训练回合
episode = 1
rewards = [0, 0, 1, 0, 0, 1, 0, 2] # 模拟每步奖励
q_values = [0.2, 0.3, 0.4, 0.5, 0.6] # 模拟Q值
losses = [0.5, 0.4, 0.3, 0.2] # 模拟损失值
exploration_rate = 0.9 # 模拟探索率
# 记录回合数据
monitor.log_episode(episode, rewards, q_values, losses,
exploration_rate, len(rewards))
# 模拟TD误差
td_errors = np.random.normal(0, 1, 100) # 模拟100个TD误差
monitor.log_td_errors(td_errors, episode)
# 模拟动作分布
actions = np.random.randint(0, 3, 100) # 模拟100个动作选择
monitor.log_action_distribution(episode, actions)
# 模拟评估结果
eval_rewards = [10, 12, 8, 15, 9] # 模拟5个评估回合的总奖励
monitor.log_evaluation(episode, eval_rewards)
# 最后关闭监控器
monitor.close()
# 调试DQN的常见问题及解决方案
def debug_common_dqn_issues():
"""DQN调试的常见问题和解决方案"""
# 1. 检查Q值是否变化
def check_q_values_change(q_values_history, threshold=0.01):
"""检测Q值是否在训练中有足够变化"""
if len(q_values_history) < 10:
return True # 数据不足,先不判断
recent_values = q_values_history[-10:]
std_dev = np.std(recent_values)
if std_dev < threshold:
print("警告: Q值变化不明显,可能学习停滞。"
"尝试增大学习率或检查梯度流动。")
return False
return True
# 2. 检查奖励是否合理
def check_reward_scale(rewards):
"""检查奖励规模是否合理"""
abs_rewards = [abs(r) for r in rewards]
max_reward = max(abs_rewards) if abs_rewards else 0
if max_reward > 100:
print("警告: 奖励规模较大,考虑进行奖励裁剪或缩放。")
elif max_reward < 0.1:
print("警告: 奖励规模较小,可能导致学习信号微弱。")
# 3. 检测灾难性遗忘
def detect_catastrophic_forgetting(eval_rewards, threshold=0.5):
"""检测是否出现灾难性遗忘"""
if len(eval_rewards) < 3:
return False
# 如果最新评估比历史最高评估低50%以上,可能发生遗忘
max_past = max(eval_rewards[:-1])
current = eval_rewards[-1]
if current < max_past * (1 - threshold):
print(f"警告: 可能出现灾难性遗忘!"
f"当前评估 {current:.2f} 比历史最高 {max_past:.2f} 低 "
f"{(1 - current/max_past)*100:.1f}%")
return True
return False
# 4. 检查探索-利用平衡
def check_exploration_exploitation(action_counts):
"""检查动作分布是否均衡"""
total = sum(action_counts.values())
probs = {a: c/total for a, c in action_counts.items()}
# 如果某个动作占比超过80%,可能过度利用
for action, prob in probs.items():
if prob > 0.8:
print(f"警告: 动作 {action} 占比 {prob*100:.1f}%,"
f"可能过度利用。考虑增加探索率。")
# 5. 模型检查工具
def inspect_model(model):
"""检查模型参数是否正常"""
# 检查参数规模
total_params = sum(p.numel() for p in model.parameters())
print(f"模型总参数量: {total_params}")
# 检查是否有梯度流动
has_grad = any(p.grad is not None for p in model.parameters())
if not has_grad:
print("警告: 未检测到梯度,检查是否调用了backward()。")
# 检查权重是否正常
for name, param in model.named_parameters():
if torch.isnan(param).any():
print(f"错误: 参数 {name} 包含NaN值!")
if torch.isinf(param).any():
print(f"错误: 参数 {name} 包含Inf值!")
总结:DQN智能体游戏AI训练
今天我们深入探讨了如何使用PyTorch构建DQN智能体来玩Atari游戏,重点关注了经验回放机制和ε-greedy探索策略。让我们总结一下今天学到的关键知识点:
主要收获
-
DQN核心组件:
- 策略网络和目标网络的双网络架构
- 经验回放缓冲区及其实现方法
- 各种探索策略及其优缺点
-
经验回放机制:
- 打破样本相关性,提高训练稳定性
- 提高数据利用效率,重复利用关键经验
- 为难得的正向反馈提供更多学习机会
-
探索策略对比:
- ε-greedy策略在简单游戏中表现良好
- Boltzmann探索能更智能地分配探索概率
- UCB策略平衡探索与利用,适合稀疏奖励环境
-
训练流程与技巧:
- 从图像预处理到动作选择的完整流程
- 如何调试和监控DQN训练过程
- 处理灾难性遗忘等常见问题的方法
清华大学全五版的《DeepSeek教程》完整的文档需要的朋友,关注我私信:deepseek 即可获得。
怎么样今天的内容还满意吗?再次感谢朋友们的观看,关注GZH:凡人的AI工具箱,回复666,送您价值199的AI大礼包。最后,祝您早日实现财务自由,还请给个赞,谢谢!

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐

 39
39 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)