机器学习之决策树:原理、算法与应用
决策树作为一种直观且易于实现的机器学习算法,在分类和回归任务中都有着广泛的应用。通过细致的数据预处理、合理的特征选择、递归的分裂过程和有效的剪枝技术,决策树能够在保持模型简洁的同时,提供准确的预测结果。然而,决策树的性能受多种因素影响,包括特征选择方法、数据质量、树的深度以及剪枝策略等。在实际应用中,需要根据具体问题和数据特点,仔细调整和验证模型,以充分发挥决策树的优势,避免其缺点带来的影响。希望
引言
在机器学习的众多算法中,决策树以其直观的树形结构和易于理解的决策过程脱颖而出。它不仅能够高效地处理分类问题,还能在回归任务中发挥重要作用。本文将深入探讨决策树的基本原理、构建过程、常用算法以及实际应用案例,帮助读者全面掌握这一强大的机器学习工具。
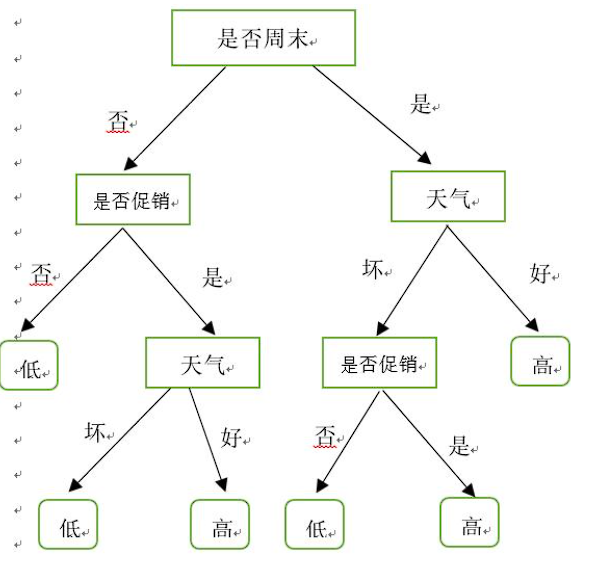
决策树的基本原理
决策树是一种基于树形结构的分类和回归模型。它通过对数据特征的不断测试和划分,将数据集逐步细分,最终达到对数据进行分类或预测的目的。决策树的每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,而每个叶节点则代表一种类别或一个具体的数值(在回归问题中)。
想象一个简单的场景:我们要根据天气、温度、湿度等特征来决定是否去户外野餐。决策树可以将这些特征作为节点,通过一系列的判断(如天气是否晴朗、温度是否适宜等),最终得出 “去” 或 “不去” 的决策。这就是决策树在实际生活中的一个简单应用示例。
决策树的构建过程
数据预处理
在构建决策树之前,首先需要对数据进行预处理。这包括清洗数据,去除噪声和异常值;处理缺失值,可以采用填充、删除等方法;对类别型特征进行编码,将其转换为数值形式,以便算法能够处理。
特征选择
特征选择是构建决策树的关键步骤之一。其目的是选取对训练数据具有最强分类能力的特征,以提高决策树的学习效率和准确性。常用的特征选择准则有信息增益、信息增益比和基尼系数。
- 信息增益:信息增益基于信息论中的熵概念。熵表示样本集合的 “不纯度”,样本集合越混乱,熵越高。特征 A 对训练数据集 D 的信息增益 g (D, A) 定义为集合 D 的熵和特征 A 在给定条件下 D 的熵之差。一般来说,信息增益越大,使用属性 a 进行划分获得的纯度提升越大,也就意味着该特征对分类越有帮助。例如,在一个包含年龄、工作、是否有房等特征的贷款申请数据集中,通过计算各个特征的信息增益,我们可以确定哪个特征对判断是否批准贷款最为关键。
- 信息增益比:信息增益对取值数目较多的属性相对友好,这可能导致在某些情况下,算法会偏向选择取值多的属性,而这些属性并不一定具有最强的分类能力。信息增益比则通过对信息增益进行修正,解决了这一问题。它在信息增益的基础上,除以该特征的固有值(一种与特征取值数量相关的度量),使得算法能够更加公平地选择最优划分属性。
- 基尼系数:基尼系数衡量的是从数据集中随机抽取两个样本,其类别标记不一致的概率。基尼系数越小,数据集的纯度越高。在构建决策树时,选择基尼系数最小的特征作为划分依据,能够使划分后的子数据集更加纯净,从而提高分类的准确性。
构建树模型
从根节点开始,决策树算法会选择数据集中最优分裂特征进行分裂。具体来说,就是根据前面计算的信息增益、信息增益比或基尼系数等指标,选择最优的特征及其对应的分裂点(对于连续型特征)。然后,对每个子集重复分裂过程,直到满足停止条件。
停止条件通常包括以下几种情况:当节点中的样本全部属于同一类别,此时该节点成为叶节点,无需再进行分裂;达到预设的最大深度,防止树生长得过于复杂,导致过拟合;样本数量低于某个阈值,表明该节点的数据量过少,继续分裂意义不大。
剪枝
为了防止决策树过拟合,需要进行剪枝操作。剪枝可以分为预剪枝和后剪枝。
- 预剪枝:在构建树的过程中进行。当满足某些条件(如信息增益小于某个阈值、节点样本数小于某个值等)时,就停止该节点的分裂,将其直接作为叶节点。预剪枝能够有效降低过拟合风险,同时减少计算量,但可能会导致模型欠拟合,因为过早停止分裂可能会错过一些有价值的信息。
- 后剪枝:在决策树构建完成后进行。后剪枝从叶节点开始,自下而上地对非叶节点进行考察。如果将该节点对应的子树替换为叶节点后,模型在验证集上的性能(如准确率、召回率等)有所提升,那么就进行剪枝操作。后剪枝能够避免预剪枝的 “视界局限” 问题,通常能得到比预剪枝更准确的模型,但计算量较大。
决策树的常见算法
ID3 算法
ID3(Iterative Dichotomiser 3)算法是决策树的经典算法之一。它使用信息增益作为分裂准则,选择信息增益最大的特征进行分裂。ID3 算法的优点是简单直观,易于理解和实现。然而,正如前面提到的,它存在对取值数目较多的属性有偏好的问题,容易导致过拟合。
C4.5 算法
C4.5 算法是对 ID3 算法的改进。它使用信息增益比作为分裂准则,克服了 ID3 算法对取值多的属性的偏向问题。此外,C4.5 算法还在树构造过程中进行剪枝,能够完成对连续属性的离散化处理,并且能够对不完整数据进行处理。C4.5 算法产生的分类规则易于理解,准确率较高,但在构造树的过程中,需要对数据集进行多次的顺序扫描和排序,导致算法效率较低,且只适合于能够驻留于内存的数据集。
CART 算法
CART(Classification and Regression Tree)算法使用基尼系数作为分裂准则,可以处理分类和回归问题。它构建的是二叉树,即每个内部节点只有两个分支。CART 算法的优点是能够处理各种类型的数据,包括数值型和类别型数据,且对数据的分布要求不严格。在实际应用中,CART 算法表现出良好的性能,特别是在处理大规模数据集时具有优势。
决策树的应用案例
- 贷款数据表格(Sheet1):
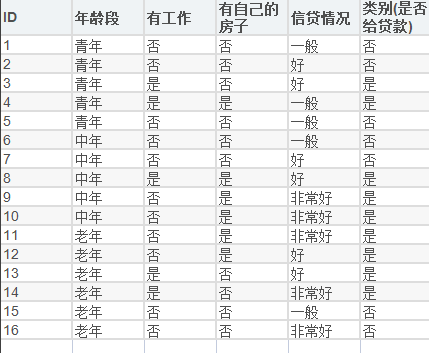
- 数据维度:包含 16 条样本数据,5 个字段(ID、年龄段、有工作、有自己的房子、信贷情况、是否给贷款)。
- 字段说明:
- 年龄段:取值为青年、中年、老年。
- 有工作:取值为是、否。
- 有自己的房子:取值为是、否。
- 信贷情况:取值为一般、好、非常好。
- 类别(是否给贷款):取值为是、否,为目标变量。
- 数据规律:
- 青年群体中,有工作且有房或信贷情况为 “好” 时可能获批贷款(如样本 3、4),无工作或信贷一般时不获批(如样本 1、2、5)。
- 中年群体中,有工作且有房、或有房且信贷较好时获批(如样本 8、9、10),无房且信贷一般 / 好时不获批(如样本 6、7)。
- 老年群体中,有房或有工作时多数获批(如样本 11-14),无房且信贷一般 / 非常好时不获批(如样本 15、16)。
- 训练集:

- 数据格式:共 16 条记录,每行 5 个数字,以逗号分隔,可能对应贷款数据表格的编码版本(假设:年龄段 = 0/1/2 对应青年 / 中年 / 老年;有工作 = 0/1 对应否 / 是;有自己的房子 = 0/1 对应否 / 是;信贷情况 = 0/1/2 对应一般 / 好 / 非常好;类别 = 0/1 对应否 / 是)。
- 示例对应:如第一行 “0,0,0,0,0” 对应贷款数据表格中 ID=1 的记录(青年,否,否,一般,否)。
- 测试集:

- 数据格式:共 7 条记录,字段含义与训练集一致,用于模型验证。
- 数据特点:包含不同年龄段、工作状态、房产情况和信贷等级的组合,可用于测试决策树模型的泛化能力。
分类任务:鸢尾花分类
鸢尾花数据集是机器学习中常用的数据集之一,包含了三种不同类型的鸢尾花(山鸢尾、变色鸢尾和维吉尼亚鸢尾)的四个特征(花萼长度、花萼宽度、花瓣长度、花瓣宽度)。我们可以使用决策树算法对鸢尾花进行分类。
通过构建决策树模型,对鸢尾花数据集进行训练和预测。在训练过程中,决策树根据特征的信息增益或其他分裂准则,选择最优的特征进行分裂,逐步构建出一棵能够准确分类鸢尾花的树。最终,模型能够根据输入的鸢尾花的四个特征,准确判断出它属于哪一种鸢尾花。
回归任务:房价预测
在房价预测任务中,决策树同样可以发挥作用。我们可以将房屋的面积、房间数量、地理位置、房龄等特征作为输入,使用回归决策树来预测房价。
回归决策树与分类决策树类似,但在构建过程中,它选择最小化均方误差或其他回归指标的特征进行分裂。通过不断地分裂节点,直到满足停止条件,最终得到一棵能够预测房价的回归树。模型预测的房价结果是一个具体的数值,而非类别。
决策树的优缺点
优点
- 易于理解和解释:决策树的树形结构清晰直观,很容易转化为明确的决策规则,即使是非专业人士也能轻松理解。例如,在前面提到的户外野餐决策树中,通过简单的树形结构,我们可以一目了然地看到根据不同天气、温度等条件如何做出决策。
- 自动特征选择:在构建过程中,决策树算法能够自动选择最有信息量的特征,无需额外的特征工程步骤。这大大减轻了数据处理的工作量,同时提高了模型的效率和准确性。
- 处理各种数据类型:决策树能够处理数值型和类别型数据,并且对数据的分布要求不严格。无论是连续的数值数据,还是离散的类别数据,决策树都能有效地进行处理。
缺点
- 容易过拟合:决策树在学习过程中,如果树生长得过于复杂,就容易对训练数据中的噪声和细节过度拟合,导致模型在测试集上的泛化能力下降。特别是在数据特征多或数据量少的情况下,过拟合问题更为严重。
- 对噪声数据敏感:由于决策树是基于数据的特征进行划分的,噪声数据可能会对特征选择和树的构建产生误导,导致决策树在噪声数据上构建出过于复杂的模型,从而影响模型的准确性。
- 可能产生不稳定的树:微小的数据变化可能导致生成完全不同的树。这是因为决策树的构建过程依赖于数据的顺序和特征的选择,如果数据发生一些小的变动,可能会导致不同的特征被选为分裂特征,从而生成不同结构的决策树。
总结
决策树作为一种直观且易于实现的机器学习算法,在分类和回归任务中都有着广泛的应用。通过细致的数据预处理、合理的特征选择、递归的分裂过程和有效的剪枝技术,决策树能够在保持模型简洁的同时,提供准确的预测结果。然而,决策树的性能受多种因素影响,包括特征选择方法、数据质量、树的深度以及剪枝策略等。在实际应用中,需要根据具体问题和数据特点,仔细调整和验证模型,以充分发挥决策树的优势,避免其缺点带来的影响。希望本文能够帮助读者对决策树有更深入的理解,并在实际的机器学习项目中灵活运用这一强大的工具。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐



 32
32 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)