[CVPR 2025]OverLoCK: An Overview-first-Look-Closely-next ConvNet with Context-Mixing Dynamic Kernels
计算机-人工智能-应用于图像分类/目标检测/语义分割的基础ConvNet

英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用
目录
2.4.1. Deep-stage Decomposition
2.4.2. Dynamic Convolution with Context-Mixing
2.5.2. Object Detection and Instance Segmentation
1. 心得
(1)接Oral接接接
(2)很标准的ConvNet文章写法,可以直接套模型来跑
2. 论文逐段精读
2.1. Abstract
①Challenge: feature pyramid (downsampling) did not achieve top-down attention mechanism
2.2. Introduction
①Key property of top-down attention mechanism: guidience of feedback signal
②Effective Receptive Fields (ERF) at stage 3 and 4
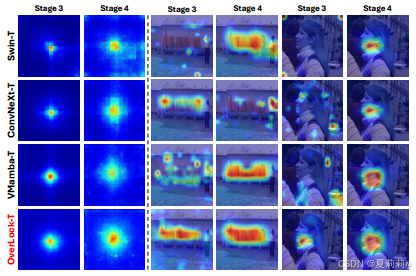
other models fail to localize object in stage 3 due to classification (loss) dependence
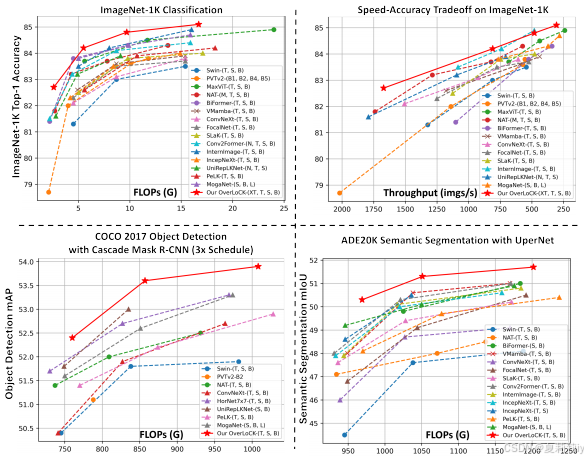
③Performance chart of OverLoCK and other compared models:
biomimetic adj.仿生的;仿生化(技术)的
2.3. Related Work
①Mentioned classic conv nets, dynamic convs, and biomimetic models
2.4. Methodology
2.4.1. Deep-stage Decomposition
①The overview of OverLoCK:
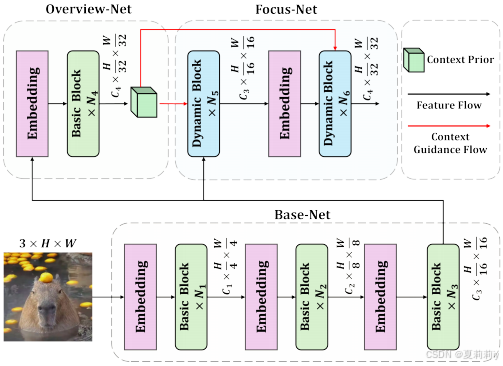
where red lines are only applied in pre-training stage
②Structures of each block:
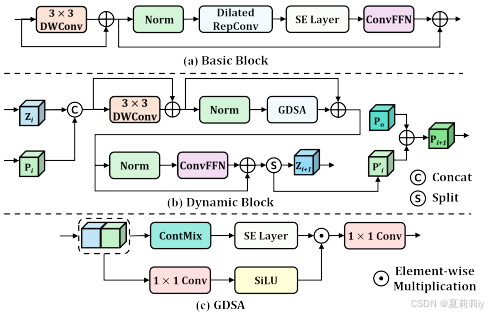
where feature map , context prior
,
,
. Initial context prior
is added for preventing context prior dilution
,
and
are learnable scalars
2.4.2. Dynamic Convolution with Context-Mixing
①The pipeline of ContMix:
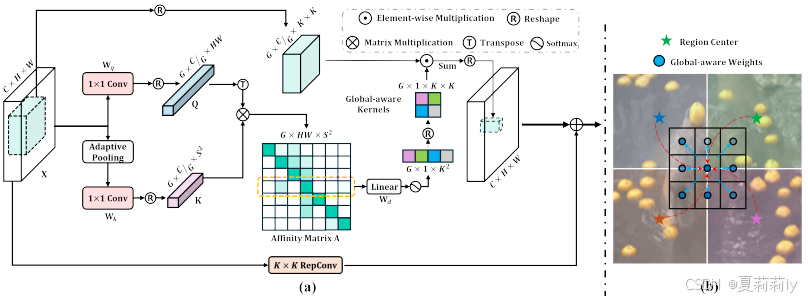
where ,
,
denotes reshape operator
②Evenly divide the channels of and
into
groups, obtaining
and
, where
and
. Calculating affinity matrix by:
where
③Define a linear kernel , and execute:
2.4.3. Network Architecture
①Variants of OverLoCK: Extreme-Tiny (XT), Tiny (T), Small (S), and Base (B) with variables channels, blocks, kernel sizes, and groups
2.5. Experiments
2.5.1. Image Classification
①Dataset: ImageNet-1k
②Optimizer: AdamW
③Stochastic depth rate: 0.1, 0.15, 0.4, and 0.5 for OverLoCK-XT, -T, -S, and -B models
④Image classification performance:
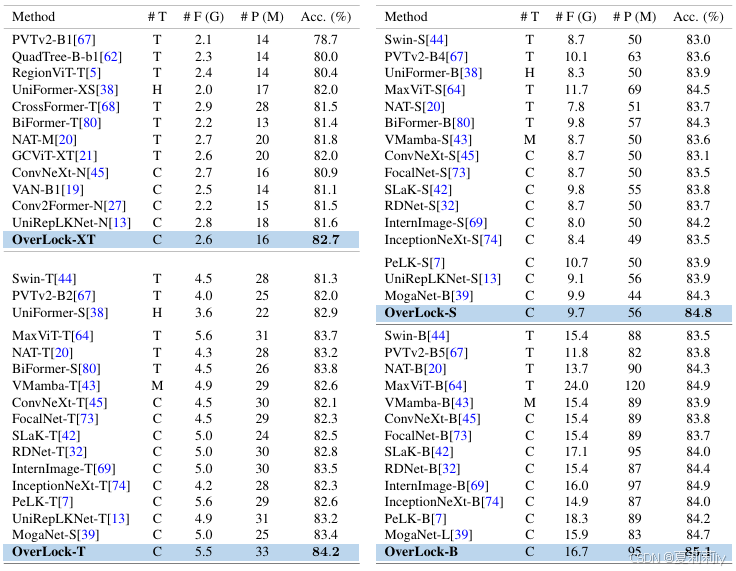
where #F and #P denote the FLOPs and number of Params of a model, respectively. #T refers to model type,where“C”, “T”, “M”, and “H” refer to ConvNet, Transformer, Mamba, and hybrid models
2.5.2. Object Detection and Instance Segmentation
①Dataset: COCO 2017
②Frameworks: both Mask R-CNN and Cascade Mask R-CNN
③Backbone is pretrained on ImageNet-1K and then fine tune on COCO
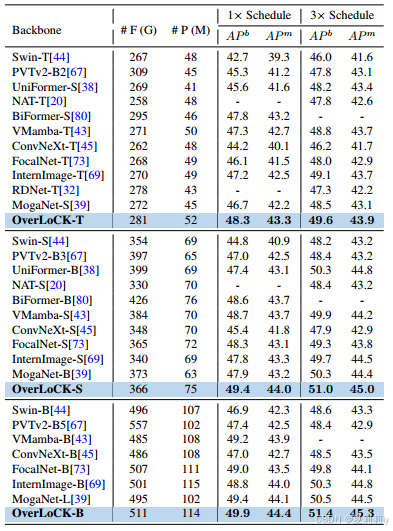
④Performance of object detection on Mask R-CNN framework:
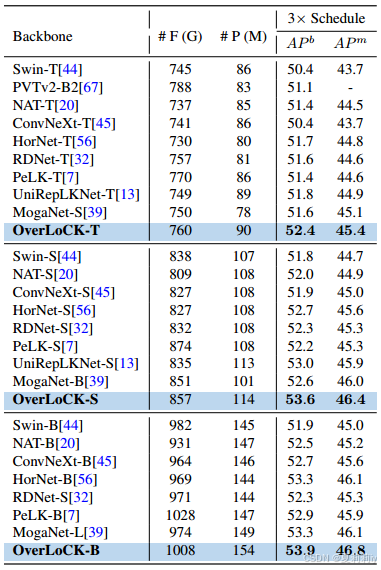
⑤Performance of object detection on Cascade Mask R-CNN framework:
2.5.3. Semantic Segmentation
①Dataset: ADE20K
②Framework: UperNet
③Backbone is pretrained on ImageNet-1K and then fine tune on COCO
④Semantic segmentation performance on ADE20K:
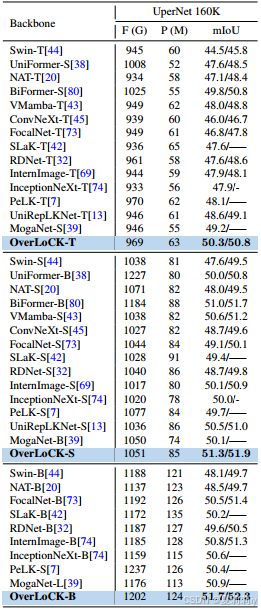
2.5.4. Ablation Studies
①Module ablation:

②Module comparison:
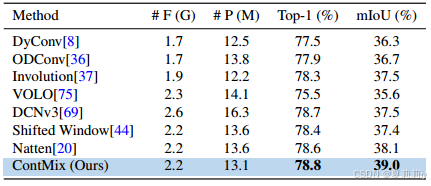
2.6. Conclusion
~

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 27
27 0
0- 0



 已为社区贡献42条内容
已为社区贡献42条内容

所有评论(0)