【读点论文】Mitigating Neural Network Overconfidence with Logit Norm 对分类特征层及输出归一化,对softmax温度调优
在开放世界中部署的现代神经网络经常与分布外(OOD)输入进行斗争,分布外(OOD)输入是指来自不同分布的样本,网络在训练期间没有接触过这些样本,因此不应该在测试时以高置信度进行预测。一个可靠的分类器不仅应该准确地分类已知的内部分布(ID)样本,而且还应该将任何OOD输入识别为“未知”。这提高了OOD检测的重要性,它确定输入是ID还是OOD,并允许模型在部署中采取预防措施。一种简单的解决方案使用最大
Mitigating Neural Network Overconfidence with Logit Normalization
Abstract
- 检测 out-of-distribution 输入对于机器学习模型在现实世界中的安全部署至关重要。然而,众所周知,神经网络存在过度自信的问题,它们对分布内和分布外的输入都产生异常高的置信度。在这项工作中,我们表明这个问题可以通过Logit归一化(LogitNorm)来缓解,Logit norm是一种对交叉熵损失的简单修复方法,通过在训练中对Logit实施恒定向量范数来实现。我们的方法是基于这样的分析:logit的范数在训练期间不断增加,导致过度自信的输出。因此,LogitNorm背后的关键思想是在网络优化期间消除输出范数的影响。通过LogitNorm训练,神经网络可以在分布内和分布外数据之间产生高度可区分的置信度得分。大量实验证明了LogitNorm的优越性,在常用基准上平均FPR95降低了42.30%。
- 本文旨在解决神经网络对 OOD 数据的高置信度错误问题,通过调整损失函数使模型输出更可靠的置信度。LogitNorm 通过归一化 logits 的范数,将损失函数的优化集中在方向而非 magnitude,从而避免过度自信。数学逻辑上,证明了 logits 的范数增加会导致 softmax 置信度升高,而 LogitNorm 通过约束范数来控制置信度。证明范数对分类和置信度的影响,并给出 LogitNorm 损失的下界。涉及如何让模型 “知道自己不知道”,通过显式约束输出范数,使模型对未知数据保持谦逊。超参数方面,温度参数 τ 的设置影响损失下界和模型性能,需要在训练中调整。
- 命题 3.1:logits 范数缩放不改变分类结果(仅方向决定类别),证明范数优化与分类方向无关。
- 命题 3.2:范数增大必然导致 Softmax 置信度升高(即使分类正确),揭示 CE Loss 导致过度自信的本质。
- 命题 3.3(损失下界): LogitNorm 损失存在下界 log ( 1 + ( k − 1 ) e − 2 / τ ) \log(1 + (k-1)e^{-2/\tau}) log(1+(k−1)e−2/τ),表明当 τ 较小时,损失下界较高,模型难以对 OOD 数据输出高置信度。
- 降低未训练类别置信度:采用 LogitNorm 方法对模型进行训练,通过约束 logit 向量的大小,使模型在面对未训练类别时输出较低的置信度。此外,还可以结合其他 OOD 检测方法,如 ODIN、能量评分等,进一步提高对未训练类别的识别能力。在实际应用中,也可以根据具体的业务需求和数据特点,对模型的输出进行适当的后处理,例如设置置信度阈值,当模型对某个输入的置信度低于阈值时,将其标记为未知类别。
- 核心创新点:对 Logit 进行 L2 归一化,结合温度参数调整分布,缓解过自信。然后,查看提供的代码,特别是 loss_function.py 中的 LogitNormLoss 类,以及模型中的 NormedLinear 层和特征归一化部分。修改调整的地方主要包括损失函数、模型的最后一层线性层、特征归一化以及温度参数的引入。损失函数需要替换为 LogitNormLoss,该函数对输入的 Logit 进行 L2 归一化,然后除以温度 t,再计算交叉熵。模型的最后一层线性层可能需要替换为 NormedLinear,或者在原有的线性层前对特征进行归一化,如代码中的 feature_norm 选项,对全局平均池化后的特征进行归一化并缩放。
Introduction
-
在开放世界中部署的现代神经网络经常与分布外(OOD)输入进行斗争,分布外(OOD)输入是指来自不同分布的样本,网络在训练期间没有接触过这些样本,因此不应该在测试时以高置信度进行预测。一个可靠的分类器不仅应该准确地分类已知的内部分布(ID)样本,而且还应该将任何OOD输入识别为“未知”。这提高了OOD检测的重要性,它确定输入是ID还是OOD,并允许模型在部署中采取预防措施。
-
一种简单的解决方案使用最大软最大概率(MSP)——也称为软最大置信度——进行OOD检测 。操作假设是OOD数据应该比ID数据触发相对较低的 softmax 置信度。虽然直观,但现实显示了一个重要的困境。特别是,深度神经网络很容易产生过度自信的预测,即异常高的 softmax 置信度,即使输入远离训练数据 。这给使用 softmax 置信度进行 OOD 检测带来了很大的疑问。事实上,许多先前的工作转向定义替代的OOD评分函数 。然而,到目前为止,社区对过度自信问题的根本原因和缓解措施的了解仍然有限。
-
在这项工作中,我们表明,过度自信问题可以通过对交叉熵损失(最常用的分类训练目标)的简单修复来缓解,方法是对logit向量(即,presoftmax输出)实施常数范数。我们的方法,logit归一化(称为LogitNorm),是由我们对神经网络的Logit向量的范数的分析所激发的。我们发现,即使大多数训练样本被分类到它们的正确标签,softmax交叉熵损失也可以继续增加logit向量的大小。因此,尽管在分类精度上没有改进,但是在训练期间不断增长的数量级导致了过度自信的问题。
-
为了缓解这一问题,我们在LogitNorm背后的关键思想是将输出规范的影响从训练目标及其优化中分离出来。这可以通过归一化logit向量以在训练期间具有恒定的范数来实现。实际上,我们的 LogitNorm 损失促使 logit 输出的方向与相应的独热标签一致,而不会加剧输出的幅度。经过标准化输出的训练,网络倾向于给出保守的预测,并导致ID和OOD输入之间softmax置信度得分的强可分性(见图4)。
-
大量的实验证明了LogitNorm优于现有的 OOD 检测方法。首先,我们的方法使用softmax置信度分数显著提高了OOD检测性能。例如,使用CIFAR-10数据集作为ID,SVHN作为OOD数据,我们的方法将FPR95从50.33%降低到8.03%—比基线提高了42.30% 。与使用具有交叉熵损失的softmax分数相比,我们的方法将FPR95降低了33.87%。除了MSP,我们还证明了我们的方法不仅优于,而且提升了更高级的事后OOD评分函数,如ODIN ,energy score ,和GradNorm score 。除了OOD检测任务,我们的方法还通过事后温度调整提高了ID数据本身的校准性能。
-
总的来说,使用LogitNorm loss在食品检测和校准任务中实现了强大的性能,同时保持了ID数据的分类准确性。我们的方法很容易在实践中采用。利用现有的深度学习框架实现起来很简单,并且不需要对损失或训练方案进行复杂的改变。代码和数据可在 GitHub - hongxin001/logitnorm_ood: Official code for ICML 2022: Mitigating Neural Network Overconfidence with Logit Normalization上公开获取。我们的贡献总结如下:
-
我们引入了logits norm——一种简单有效的交叉熵损失替代方法,它将logit范数的影响从训练过程中分离出来。我们证明了LogitNorm可以有效地推广到不同的网络架构,并促进不同的事后OOD检测方法。
-
我们进行了广泛的评估,以表明 LogitNorm 可以改善 OOD 检测和置信度校准,同时保持ID数据的分类准确性。与交叉熵损失相比,LogitNorm 在具有 softmax 置信度得分的公共基准上实现了33:87%的FPR95降低。
-
我们进行消融研究,从而加深对我们方法的理解。特别是,我们对比了替代方法(例如,GODIN ,Logit Penalty)并展示了LogitNorm 的优势。我们希望我们的见解能启发未来的研究,进一步探索 OOD 检测的损失函数设计。
-
-
传统神经网络在面对分布外(OOD)数据时,即使输入与训练数据差异极大,仍会输出异常高的置信度(如 Softmax 概率接近 1),导致误判。这种过度自信问题在安全关键场景(如医疗、自动驾驶)中极具风险。提出 Logit Normalization (LogitNorm) 方法,通过调整训练过程中的损失函数,使模型对分布内(ID)数据保持高置信度正确分类,对 OOD 数据输出低置信度,从而提升 OOD 检测的可靠性。神经网络的过度自信源于 Softmax 交叉熵损失对 logits 范数的无约束优化。具体来说,模型倾向于增大 logits 的范数(magnitude)以降低损失,即使方向正确(分类正确),范数的增大会导致 Softmax 置信度异常升高,尤其是对 OOD 数据。通过归一化 logits 范数,将优化聚焦于方向(direction)而非范数,迫使模型对 OOD 数据输出低置信度。
-
Logits 分解:将 logits 向量分解为范数(|f|)和方向 (单位向量 f ^ \hat{f} f^),即 f = ∥ f ∥ ⋅ f ^ f = \|f\| \cdot \hat{f} f=∥f∥⋅f^。在训练时对 logits 进行归一化,使范数固定为常数(如 1/τ),仅优化方向。损失函数变为: L LogitNorm = − log e f y / ( τ ∥ f ∥ ) ∑ i = 1 k e f i / ( τ ∥ f ∥ ) \mathcal{L}_{\text{LogitNorm}} = -\log \frac{e^{f_y / (\tau\|f\|)}}{\sum_{i=1}^k e^{f_i / (\tau\|f\|)}} LLogitNorm=−log∑i=1kefi/(τ∥f∥)efy/(τ∥f∥)其中 τ 为温度参数,控制归一化后的范数规模。归一化后,模型无法通过增大范数来降低损失,只能通过调整方向来优化,从而避免对 OOD 数据的过度自信。
Background
Preliminaries: Out-of-distribution Detection
-
设置。我们考虑一个有监督的多类分类问题。我们用 X 表示输入空间, Y = { 1 , . . . , k } Y = \{1,...,k\} Y={1,...,k} 个类的标签空间。训练数据集 D t r a i n = { x i , y i } i = 1 N D_{train} = \{x_i,y_i\} ^N _{i=1} Dtrain={xi,yi}i=1N 由 N 个数据点组成,从联合数据分布 P X Y P_{X Y} PXY 中进行i.i.d .采样。我们使用Pin来表示X上的边际分布,它代表 Pin分布(ID)。给定训练数据集,我们学习分类器 f : X → R x f : X\rightarrow \R^x f:X→Rx 具有可训练参数 θ ∈ R p θ \in \R ^p θ∈Rp ,它将输入映射到输出空间。理想的分类器可以通过最小化以下预期风险来获得:
-
R L ( f ) = E ( x ; y ) ∼ P X Y [ L ( f ( x ; θ ) ; y ) ] ; R_L(f) = E_{(x;y)∼PXY} [L(f(x; θ); y)] ; RL(f)=E(x;y)∼PXY[L(f(x;θ);y)];
-
其中L是softmax激活函数常用的交叉熵损失:
-
L C E ( f ( x ; θ ) , y ) = − log p ( y ∣ x ) = − log e f y ( x ; θ ) ∑ i = 1 k e f i ( x ; θ ) . \mathcal{L}_{\mathrm{C E}} ( f ( \boldsymbol{x} ; \theta), y )=-\operatorname{l o g} p ( y | \boldsymbol{x} )=-\operatorname{l o g} \frac{e^{f_{y} ( \boldsymbol{x} ; \theta)}} {\sum_{i=1}^{k} e^{f_{i} ( \boldsymbol{x} ; \theta)}}. LCE(f(x;θ),y)=−logp(y∣x)=−log∑i=1kefi(x;θ)efy(x;θ).
-
这里,fy(x;θ)表示 f(x;θ)对应于 GT 标签 y,p(y|x)是对应的softmax概率。
-
-
问题陈述。在部署期间,测试数据最好与训练数据来自同一个分配引脚。然而,在现实中,可能会出现来自未知分布的输入,其标注集可能与 y 没有交集。此类输入被称为分布外(OOD)数据,不应由模型预测。OOD检测任务可以被公式化为二进制分类问题:确定输入 x ∈ X x \in X x∈X 是否来自引脚(ID )( OOD)。OOD检测可以通过水平集估计来执行:
-
g ( x ) = { i n i f S ( x ) ≥ γ o u t i f S ( x ) < γ , (1) g ( \boldsymbol{x} )=\left\{\begin{array} {l l} {{\mathrm{i n}}} & {{\mathrm{i f ~} S ( \boldsymbol{x} ) \geq\gamma}} \\ {{\mathrm{o u t}}} & {{\mathrm{i f ~} S ( \boldsymbol{x} ) < \gamma}} \\ \end{array} \right., \tag{1} g(x)={inoutif S(x)≥γif S(x)<γ,(1)
-
其中S(x)表示得分函数,γ 通常被选择为使得高比例(例如,95%)的ID数据被正确分类。按照惯例,具有较高分数S(x)的样本被分类为ID,反之亦然。在第4.2节中,我们将考虑各种流行的OOD评分函数,包括MSP 、ODIN 、energy score 和GradNorm 。
-
Method: Logit Normalization
Motivation
-
在下文中,我们研究了为什么用普通的softmax交叉熵损失训练的神经网络倾向于给出过度自信的预测。我们的分析表明,大量的神经网络输出可能是罪魁祸首。
-
对于简写符号,我们用 f 来表示网络输出f(x;θ)对于输入x 。 f(x;θ)也称为logit或前softmax输出。不失一般性,logit向量 f 可以分解成两个分量:
-
f = ∣ ∣ f ∣ ∣ ⋅ f ^ ; ( 2 ) f = ||f|| ·\hat f; (2) f=∣∣f∣∣⋅f^;(2)
-
其中 ∣ ∣ f ∣ ∣ = f 1 2 + f 2 2 + . . . + f k 2 ||f|| = \sqrt {f^ 2 _1 + f^ 2 _2 + ...+ f ^2 _k} ∣∣f∣∣=f12+f22+...+fk2 是logit向量 ||f|| 的欧几里德范数, f ^ \hat f f^ 是与 f 方向相同的单位向量。换句话说,||f|| 和 f ^ \hat f f^ 分别是logit向量f的大小和方向。在测试阶段,模型通过 c = a r g m a x i ( f i ) c = arg max_i(f_i) c=argmaxi(fi) 进行分类预测。我们有以下主张。
-
-
提议3.1。对于任意给定的常数值s > 1,如果 a r g m a x i ( f i ) = c arg max_i(f_i) = c argmaxi(fi)=c,那么 a r g m a x i ( s f i ) = c arg max_i(sf_i) = c argmaxi(sfi)=c 总是成立。鉴于上述命题,我们发现对logit的大小||f||进行缩放不会改变预测的c类。在下文中,我们将进一步探讨它如何影响softmax置信度得分。
-
提议3.2。对于softmax交叉熵损失,设σ为softmax激活函数。对于任意给定的标量s > 1,若 c = a r g m a x i ( f i ) c = arg max_i(f_i) c=argmaxi(fi),则 σ c ( s f ) ≥ σ c ( f ) σ_c(sf) ≥ σ_c(f) σc(sf)≥σc(f) 成立。上述命题的证明在附录A和b中给出。从命题3.2中,我们发现增加||f||的大小将导致softmax置信度得分的更高值,但最终预测保持不变。为了分析对训练目标的影响,我们根据Eq 2提供以下公式:
- L C E ( f ( x ; θ ) , y ) = − log p ( y ∣ x ) = − log e ∥ f ∥ ⋅ f ^ y ∑ i = 1 k e ∥ f ∥ ⋅ f ^ i . \mathcal{L}_{\mathrm{C E}} ( f ( \boldsymbol{x} ; \theta), y )=-\operatorname{l o g} p ( y | \boldsymbol{x} )=-\operatorname{l o g} \frac{e^{\| \boldsymbol{f} \| \cdot\hat{f}_{y}}} {\sum_{i=1}^{k} e^{\| \boldsymbol{f} \| \cdot\hat{f}_{i}}}. LCE(f(x;θ),y)=−logp(y∣x)=−log∑i=1ke∥f∥⋅f^ie∥f∥⋅f^y.
-
我们可以发现训练损失取决于大小||f||和方向f^.。通过保持方向不变,我们分析了大小kfk对训练损失的影响。当y = arg maxi(fi)时,我们可以看到增加 ||f|| 会增加p(y|x)。这意味着,对于那些已经被正确分类的训练示例,对训练损失的优化将进一步增加网络输出的大小 ||f||,以产生更高的softmax置信度得分,从而获得更小的损失。
-
为了提供一个直观的视图,我们在图1中显示了训练期间logit norm的动态。事实上,softmax交叉熵损失鼓励模型为ID和OOD示例产生具有越来越大的规范的逻辑。大标准直接转化为过度自信的softmax分数,导致难以区分ID和OOD数据。我们继续介绍我们的方法,针对这个问题。
-
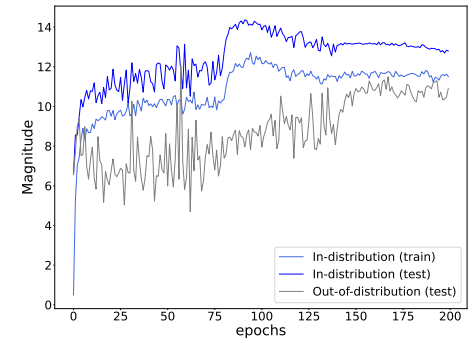
-
图一。不同训练时期下 logits 的平均大小。模型在CIFAR-10上与WRN-402一起训练。OOD示例来自SVHN数据集。
-
Method
-
在我们之前的分析中,我们表明softmax交叉熵损失鼓励网络产生更大幅度的逻辑,导致过度自信问题,使得难以区分ID和OOD示例。为了缓解这一问题,我们的主要想法是将逻辑值的大小从网络优化中分离出来。换句话说,我们的目标是在训练期间保持logits的L2向量范数不变。形式上,目标可以表述为:
- m i n i m i z e E P X Y [ L C E ( f ( x ; θ ) , y ) ] s u b j e c t t o ∥ f ( x ; θ ) ∥ 2 = α . \begin{array} {l l} {{\mathrm{m i n i m i z e}}} & {{\mathbb{E}_{\mathcal{P}_{X Y}} \left[ \mathcal{L}_{\mathrm{C E}} \left( f ( \boldsymbol{x} ; \theta), y \right) \right]}} \\ {{\mathrm{s u b j e c t ~ t o}}} & {{\left\Vert f ( \boldsymbol{x} ; \theta) \right\Vert_{2}=\alpha.}} \\ \end{array} minimizesubject toEPXY[LCE(f(x;θ),y)]∥f(x;θ)∥2=α.
-
在现代神经网络的环境中执行约束优化并不简单。正如我们将在第5节中展示的,简单地通过拉格朗日乘数增加约束效果不好。为了避免这个问题,我们将目标转换成一个可端到端训练的替代损失函数,它严格执行一个恒定向量范数。
-
Logit标准化。我们采用logit规范化(称为logitNorm),它鼓励 Logit 的方向与相应的独热标签一致,而不优化Logit的大小。特别地,logit向量被归一化为具有恒定幅度的单位向量。然后将softmax交叉熵损失应用于归一化logit向量,而不是原始输出。形式上,LogitNorm的目标函数由下式给出:
-
R L ( f ) = E ( x , y ) ∼ P X Y [ L C E ( f ^ ( x ; θ ) , y ) ] , (3) \mathcal{R}_{\mathcal{L}} ( f )=\mathbb{E}_{( \boldsymbol{x}, y ) \sim\mathcal{P}_{\mathcal{X} \mathcal{Y}}} \left[ \mathcal{L}_{\mathrm{C E}} \left( \hat{f} ( \boldsymbol{x} ; \theta), y \right) \right], \tag{3} RL(f)=E(x,y)∼PXY[LCE(f^(x;θ),y)],(3)
-
-
其中 f ^ ( x ; θ ) = f ( x ; θ ) / ∣ ∣ f ( x ; θ ) ∣ ∣ \hat f(x;θ)= f(x;θ)/||f(x;θ)|| f^(x;θ)=f(x;θ)/∣∣f(x;θ)∣∣ 是归一化的logit向量。实际上,分母上加一个小的正值(如10e-7),以确保数值的稳定性。等效地,新的损失函数可以定义为:
-
L l o g i t , n o r m ( f ( x ; θ ) , y ) = − log e f y / ( τ ∥ f ∥ ) ∑ i = 1 k e f i / ( τ ∥ f ∥ ) , (4) \mathcal{L}_{\mathrm{l o g i t, n o r m}} ( f ( \boldsymbol{x} ; \theta), y )=-\operatorname{l o g} \frac{e^{f_{y} / ( \tau\| \boldsymbol{f} \| )}} {\sum_{i=1}^{k} e^{f_{i} / ( \tau\| \boldsymbol{f} \| )}}, \tag{4} Llogit,norm(f(x;θ),y)=−log∑i=1kefi/(τ∥f∥)efy/(τ∥f∥),(4)
-
其中温度参数 τ 调制logits的幅度。有趣的是,我们的损失函数可以被视为具有依赖于输入的温度 τ||f(x;θ)||,它取决于输入x。
-
-
通过logit归一化,输出向量的幅度是严格恒定的(即,1/τ)。最小化等式 4 中的损失。只能通过调整logit输出f的方向来实现,所得模型往往给出保守的预测,尤其是对于远离Pin的输入。我们用图2中的一个例子来说明,其中使用logit归一化的训练导致softmax输出在分布内和分布外样本之间更容易区分(右),而不是使用交叉熵损失(左)。
-
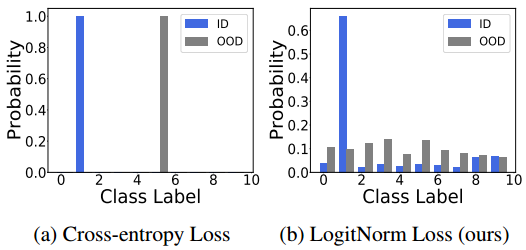
-
图二。CIFAR-10 预训练WRN-40-2 上的两个示例的softmax输出具有(a)交叉熵损失和(b) logit归一化损失。对于交叉熵损失,对于ID和OOD示例,softmax置信度得分分别为1.0和1.0。相比之下,对于ID和OOD示例,用LogitNorm损失训练的网络的softmax置信度得分是0.66和0.14。虽然使用交叉熵损失对于OOD示例产生了非常有把握的预测,但是我们的方法产生了几乎一致的softmax概率(接近0.1),这有利于OOD检测。
-
-
在图3中,我们展示了使用交叉熵的softmax输出的t-SNE可视化 LogitNorm损失,其中LogitNorm导致更有意义的信息,以在softmax输出空间中区分ID和OOD样本。下面我们进一步提供等式 4 中的这个新损失函数的下限。
-

-
图3。WRN-40-2 的 softmax 输出的 t-SNE 可视化 在CIFAR-10上进行训练,具有(a)交叉熵损失和(b)对数范数损失。除棕色外的所有颜色表示10个不同的ID类别。棕色点表示来自SVHN的 OOD 示例。softmax 输出经过logit标准化训练,可提供更有意义的信息来区分分布内和分布外样本。
-
-
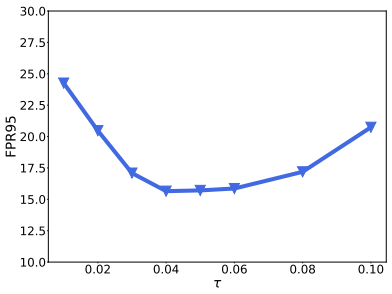
命题3.3(损失下限)。对于任何输入 x 和任何正数 τ ∈ R + τ \in \R^ + τ∈R+,每样本损耗定义为等式。(4)有一个下界: L l o g i t _ n o r m ≥ l o g ( 1 + ( k − 1 ) e − 2 / τ L_{logit\_norm}≥log( 1+(k-1)e^{-2 /τ} Llogit_norm≥log(1+(k−1)e−2/τ,其中 k 是类的个数。命题3.3的证明在附录c中提供。从命题3.3中,我们发现 LogitNorm 损失具有依赖于 τ 和类数 k 的下界。特别地,它暗示损失值的下界随着 τ 的值而增加。例如,当 k = 10 且 τ = 1 时,logits的范数将线性缩放为1,下限约为0.7966。较高下限会导致优化困难。出于这个原因,我们发现希望具有相对小的τ < 1。我们将在第五节详细分析 τ的影响。
Experiments
- 在本节中,我们使用几个基准数据集验证了LogitNorm loss 在OOD检测中的有效性。
Experimental Setup
-
分布式数据集。在这项工作中,我们使用CIFAR10和CIFAR-100 数据集作为分布数据集,这是 OOD 检测的常用基准。具体来说,我们对50,000幅训练图像和10,000幅测试图像使用标准分割。所有图像的尺寸都是32 × 32。
-
非分布数据集。对于OOD检测评估,我们使用六个常见的基准作为OOD测试数据集 D o u t t e s t D^{test} _{out} Douttest : Textures 、SVHN 、Places365 、LSUN-Crop 、LSUN-Resize 和 iSUN 。对于所有测试数据集,图像大小为32 × 32。六个数据集的详细信息见附录d。
-
评估指标。我们通过测量以下度量来评估OOD检测的性能:(1)当分布内样本的真阳性率为95%时,OOD样本的假阳性率(FPR 95);(2)受试者工作特性曲线下的面积(AUROC);和(3)精确调用曲线下的面积(AUPR)。
-
训练详情。对于主要结果,我们在CIFAR-10/100上用 WRN-40-2进行了训练。使用动量为0.9、权重衰减为 0.0005、dropout 率为 0.3、批量为128的SGD对网络进行200个时期的训练。我们将初始学习率设置为0.1,并在 80 和 140 个时期将其减少10倍。超参数 τ选自范围 { 0.001 , 0.005 , 0.01 , . . . , 0.05 } \{0.001,0.005,0.01,...,0.05\} {0.001,0.005,0.01,...,0.05}。默认情况下,我们为CIFAR-10设置了 0.04。对于超参数调整,我们使用高斯噪声作为验证集。所有实验用不同的种子重复五次,我们报告平均性能。我们在NVIDIA GeForce RTX 3090上进行所有实验,并使用PyTorch 使用默认参数实现所有方法。
Results
-
logit 标准化如何影响 OOD 检测性能?在表1中,我们比较了分别用交叉熵损失和对数范数损失训练的模型的OOD检测性能。为了隔离训练中损失函数的影响,我们保持测试时OOD评分函数相同,即softmax置信度得分:
- S ( x ) = max i e f i ( x ; θ ) ∑ j = 1 k e f j ( x ; θ ) . S ( \boldsymbol{x} )=\operatorname* {m a x}_{i} \frac{e^{f_{i} ( \boldsymbol{x} ; \theta)}} {\sum_{j=1}^{k} e^{f_{j} ( \boldsymbol{x} ; \theta)}}. S(x)=imax∑j=1kefj(x;θ)efi(x;θ).
-
一个显著的观察结果是,我们的方法通过采用 LogitNorm 损失显著地提高了OOD检测性能。例如,在CIFAR-10模型上,当将SVHN作为 OOD 数据进行评估时,我们的方法将FPR95从 50.33% 降低到 8.03% —直接提高了 42.3%。在六个测试数据集上平均,与使用交叉熵损失训练的模型上的MSP相比,我们的方法降低了33.87%的 FPR95。在CIFAR-100上,我们的方法也显著提高了性能。
-
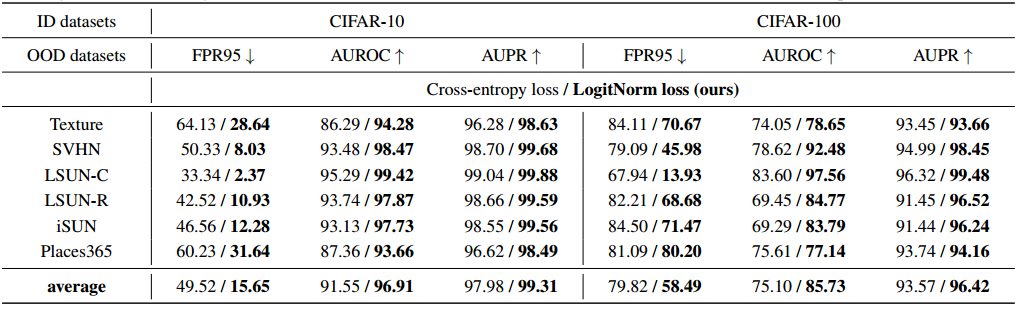
-
表1。使用softmax交叉熵损失和LogitNorm损失的OOD检测性能比较。我们使用WRN-40-2 在分布数据集上进行训练,并使用softmax 置信度得分作为评分函数。所有数值均为百分比。 ↑ \uparrow ↑ 表示值越大越好, ↓ \downarrow ↓ 表示值越小越好。粗体数字是优越的结果。
-
-
为了进一步说明OOD检测的两种损失之间的差异,我们可视化并比较了ID和OOD数据的softmax置信度得分的分布,该分布来自于用交叉熵与对数正态损失训练的网络。在交叉熵损失的情况下,ID和OOD数据的softmax得分集中在高值上,如图4a所示。相反,用LogitNorm损失训练的网络在ID和OOD数据之间产生高度可区分的分数。从图4b中,我们观察到大多数OOD示例的softmax置信度得分约为0.1,这表明softmax输出接近均匀分布。总的来说,实验表明,利用LogitNorm损失的训练使得softmax分数在分布内和分布外之间更容易区分,从而实现更有效的OOD检测。
-
logit 归一化能改善现有的评分函数吗?在表2中,我们表明 LogitNorm 损失不仅优于,而且提高了竞争性OOD评分函数。请注意,所有考虑的OOD评分函数最初都是基于交叉熵损失训练的模型开发的,因此是比较的自然选择。特别地,我们考虑:1) MSP 使用softmax置信度得分来检测OOD样本。2) ODIN 采用温度缩放和输入扰动来改进OOD检测。按照原始设置,我们使用温度参数T = 1000和 ϵ \epsilon ϵ= 0:0014。3)能量得分 利用logits中的信息进行OOD检测,它是softmax函数中分母的负对数: E ( x , y ) = − T ⋅ l o g ∑ i = 1 k e f ( x i ) / T E(x,y)=-T·log\sum^k_{i=1}e^{f(x_i)/T} E(x,y)=−T⋅log∑i=1kef(xi)/T,对于 LogitNorm loss,我们为CIFAR-10设置T = 0.1,为CIFAR-100设置T = 0.01。4) GradNorm通过利用从梯度空间提取的信息来检测OOD输入。
-
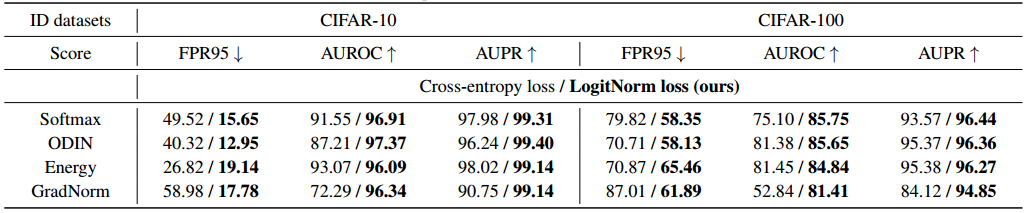
-
表二。使用softmax交叉熵损失和logit归一化损失与各种评分函数的OOD检测性能比较。我们使用WRN-40-2在分布数据集上进行训练。所有数值均为百分比。 ↑ \uparrow ↑ 表示值越大越好, ↓ \downarrow ↓ 表示值越小越好。粗体数字是优越的结果。
-
-
我们在表2中的结果表明,logit标准化可以使下游OOD评分函数受益。由于篇幅限制,我们报告了六个测试OOD数据集的平均性能。附录f提供了每个OOD测试数据集的OOD检测性能。例如,我们观察到,当采用logit归一化时,ODIN方法的FPR95从40.32%降至12.95%,从而建立了强大的性能。此外,我们发现logit归一化使得能量分数和GradNorm分数也能够实现不错的OOD检测性能。
-
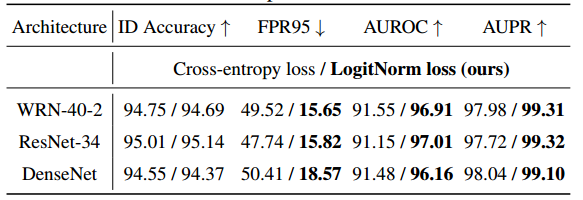
Logit规范化在不同的架构上都是有效的。在表3中,我们展示了LogitNorm在各种模型架构上是有效的。结果基于softmax置信度得分作为测试时OOD得分。特别是,我们的方法在使用 WRN-40-2 、ResNet 和DenseNet 架构时,性能得到了持续改善。例如,在DenseNet上,使用LogitNorm loss将平均FPR95从50.41%降低到18.57%。
-
-
表3。在具有不同网络架构的CIFAR-10上训练的OOD检测性能比较:WRN-40-2 ,ResNet-34 ,DenseNet-BC 。所有数值均为百分比。 ↑ \uparrow ↑ 表示值越大越好, ↓ \downarrow ↓ 表示值越小越好。粗体数字是优越的结果。
-
-
Logit 标准化保持了分类的准确性。我们还验证了 LogitNorm 损失是否影响分类精度。表3中的结果表明,LogitNorm 可以提高OOD检测性能,同时获得与交叉熵损失相似的精度。例如,当使用CIFAR10作为ID数据集在ResNet-34上训练时,使用 LogitNorm loss 在CIFAR-10上实现了95.14%的测试准确度,与使用交叉熵损失的95.01%的测试准确度相当。在CIFAR-100上,对数损失和交叉熵损失也达到了相当的测试精度(75.12%对75.23%)。整体LogitNorm损失保持了ID数据的可比分类精度,同时显著提高了 OOD 检测性能。
-
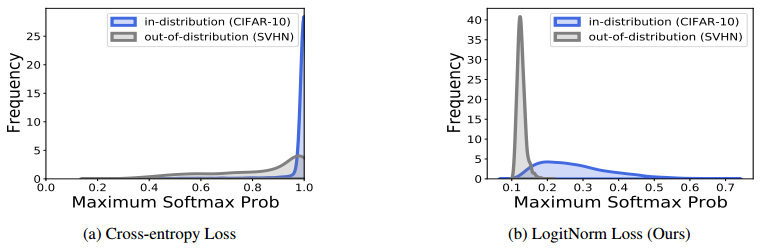
Logit标准化可实现更好的校准。虽然OOD检测任务集中于ID和OOD数据之间的可分性,但校准任务仅关注ID数据——soft max置信度得分应代表正确的真实概率 。在实践中,预期校准误差(ECE) 通常用于测量有限样本的校准性能。在图4中,我们观察到LogitNorm损失 导致ID示例的softmax置信度得分分布更平滑,与交叉熵损失导致的尖峰分布形成对比(即,值集中在1附近)。
-
-
图4。在CIFAR-10上训练的WRN-40-2 的 softmax 置信度得分分布,具有(a)交叉熵损失和(b)对数范数损失。
-
-
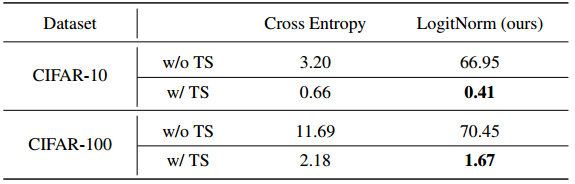
这意味着用LogitNorm损失训练的模型保留了不同ID样本的可区分信息,表明其在改进模型校准方面的潜力。事实上,我们在表4中的结果表明,通过事后温度缩放,用LogitNorm训练的模型实现了更好的校准性能。
-
-
表4。ECE (%)与M = 15的比较结果,使用在CIFAR-10上训练的WRN-40-2。对于温度缩放(TS ),通过优化方法在保持验证集上调整T。
-
Discussion
-
Logit归一化与Logit惩罚。虽然我们的对数归一化显示了强大的前景,但一个问题出现了:通过对对数的L2范数施加惩罚可以达到类似的效果吗?在这种消融中,我们表明,通过拉格朗日乘数显式约束logit范数 效果不佳。具体来说,我们考虑替代损失:
-
L l o g i t , p e n a l r y ( f ( x ; θ ) , y ) = L C E ( f ( x ; θ ) , y ) + λ ∥ f ( x ; θ ) ∥ 2 . {\mathcal{L}}_{\mathrm{l o g i t, p e n a l r y}} ( f ( \boldsymbol{x} ; \theta), y )={\mathcal{L}}_{\mathrm{C E}} ( f ( \boldsymbol{x} ; \theta), y )+\lambda\| f ( \boldsymbol{x} ; \theta) \|_{2}. Llogit,penalry(f(x;θ),y)=LCE(f(x;θ),y)+λ∥f(x;θ)∥2.
-
其中λ表示控制交叉熵损失和正则化项之间权衡的拉格朗日乘数。
-
-
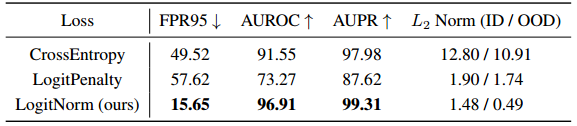
我们在表5中的结果表明,与使用交叉熵损失相比,logit惩罚和logit归一化都导致具有小L2范数的logit。然而,与LogitNorm不同,logit罚函数法也会对OOD数据产生较大的L2范数,从而导致OOD检测的较差性能。在实践中,我们注意到,如果λ太大(这是有效地正则化logit范数所需要的),用logit罚值训练的网络可能遭遇优化困难,并且有时不能收敛。总的来说,我们表明在训练期间简单地限制logit范数不能帮助OOD检测任务,而我们的logit norm损失显著地提高了性能。
-
-
表5。不同损失函数下的OOD检测性能比较。我们使用在CIFAR-10上训练过的WRN-40-2。粗体数字是优越的结果。我们将对数的平均范数报告为L2范数,其中我们使用SVHN作为OOD测试数据集。
-
-
与温度标度的关系。如第3节所述,logit归一化可视为logit上的输入依赖温度。与我们的工作相关,之前的工作ODIN 提出了一种softmax得分的变体,在测试阶段使用常数T进行温度缩放:
-
S ( x ) = max i e f i ( x ; θ ) / T ∑ j = 1 k e f j ( x ; θ ) / T . S ( \boldsymbol{x} )=\operatorname* {m a x}_{i} \frac{e^{f_{i} ( \boldsymbol{x} ; \theta)/T}} {\sum_{j=1}^{k} e^{f_{j} ( \boldsymbol{x} ; \theta)/T}}. S(x)=imax∑j=1kefj(x;θ)/Tefi(x;θ)/T.
-
其中所有输入的温度都相同。相比之下,我们的方法揭示了两个关键差异: (1)logit norm中的有效温度是依赖于输入的,而不是全局常数;(2) logit norm中的温度可以在训练阶段强制实施。如第4.2节所示,我们的方法与OOD检测中的测试时温度调整兼容,并且可以通过温度调整提高校准性能。
-
-
在图5中,我们进一步研究了我们方法中的参数 τ (参见等式4)影响OOD检测性能。该分析基于CIFAR-10,FPR95是六个测试数据集的平均值。我们的结果呼应了命题3.3中的分析,其中大的 τ 将导致损失的较大下限,从优化的角度来看,这是不太理想的。
-
-
图5。τ 对CIFAR-10对数表的影响。
-
-
与其他标准化方法的关系。在文献中,归一化方法以余弦相似度的形式应用于OOD检测。特别地,余弦损失和广义ODIN (GODIN) 分解logit f i ( x ; θ ) f_i(x;θ) fi(x;θ) 对于I级为: f i ( x ; θ ) = h i ( x ; θ ) g ( x ; θ ) f_i(x;θ)=\frac {h_i(x;θ)}{g(x;θ)} fi(x;θ)=g(x;θ)hi(x;θ),其中
-
{ h i ( x ) = cos ( w i , ϕ p ( x ) ) = w i T ϕ p ( x ) ∥ w i ∥ ∥ ϕ p ( x ) ∥ , g ( x ; θ ) = exp { B N ( W ⊤ ϕ p ( x ) + b ) } . \left\{\begin{aligned} {{}} & {{} {{} h_{i} ( \boldsymbol{x} )=\operatorname{c o s} ( \boldsymbol{w}_{i}, \phi^{p} ( \boldsymbol{x} ) )=\frac{\boldsymbol{w}_{i}^{\mathrm{T}} \phi^{p} ( \boldsymbol{x} )} {\| \boldsymbol{w}_{i} \| \| \phi^{p} ( \boldsymbol{x} ) \|},}} \\ {{}} & {{} g ( \boldsymbol{x} ; \theta)=\operatorname{e x p} \left\{\mathrm{B N} \left( \boldsymbol{W}^{\top} \phi^{p} ( \boldsymbol{x} )+b \right) \right\}.} \\ \end{aligned} \right. ⎩ ⎨ ⎧hi(x)=cos(wi,ϕp(x))=∥wi∥∥ϕp(x)∥wiTϕp(x),g(x;θ)=exp{BN(W⊤ϕp(x)+b)}.
-
-
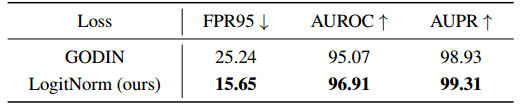
在测试阶段,最大余弦相似度被用作评分函数。相比之下,LogitNorm有两个关键区别:(1) h i ( x ) h_i(x) hi(x) 中的余弦相似度对最后一层权重w和学习的特征 φ p ( x ) φ ^p (x) φp(x)应用L2归一化,而我们的 LogitNorm 对网络输出 f ( x ; θ ) f(x;θ) f(x;θ);(2)我们的LogitNorm可以提升常见OOD评分函数的性能,而GODIN 和 Cosine loss 则以其特定的评分函数来检测OOD实例。在表6中,我们展示了我们的LogitNorm与MSP分数在OOD检测中实现了比GODIN更好的性能。附录E中提供了关于未来工作的更多讨论。
-
-
表6。GODIN和LogitNorm的比较。我们使用在CIFAR-10上训练的WRN-40-2。为了公平比较,我们使用ODIN分数来表示LogitNorm损失。粗体数字是优越的结果。
-
Related Work
-
OOD 检测。对于在开放世界中部署机器学习模型来说,OOD检测是一个越来越重要的主题,并且在两个方向上吸引了大量的兴趣。
-
1)一些方法旨在为OOD检测设计评分函数,如OpenMax score 、maximum soft max probability 、ODIN score 、基于Mahalanobis距离的评分、基于energy的评分,ReAct,GradNorm评分,以及基于非参数的评分。在这项工作中,我们首先表明,logit归一化可以极大地缓解OOD数据的过度自信问题,从而提高现有评分函数在OOD检测中的性能。
-
2)一些工作通过训练时间正则化来解决非分布检测问题。例如,鼓励模型给出均匀分布的预测 或 更高的能量 的异常值。基于能量的正则化具有对对数似然进行整形的直接理论解释,因此自然适合于 OOD 检测。对比学习方法也被用于OOD检测任务 ,这可能比我们的训练在计算上更昂贵。在这项工作中,我们致力于探索基于分类的损失函数的 OOD 检测,只需要在训练中的非分布数据。LogitNorm易于实现和使用,并保持与标准交叉熵损失相同的训练方案。
-
-
深度学习中的规范化。在文献中,归一化已被广泛应用于度量学习,人脸识别,以及自我监督学习。受约束的softmax 对特征应用归一化,而SphereFace 稍后仅对最后一个内积的权重进行归一化。余弦损失 归一化特征和权重,以实现更好的人脸验证性能。LayerNorm 对中间层的分布进行归一化处理,以获得更高的概化精度。在自监督学习中,SimCLR 采用余弦相似度来度量正样本对之间的特征距离。最近的一项研究表明,包括logit归一化和余弦softmax在内的几个损失函数在ImageNet上导致更高的准确性,但降低了传输任务的性能。此外,GODIN 和余弦损失 采用余弦相似性,以获得更好的OOD检测性能。如在第5节中所讨论的,我们的方法优于这些基于余弦的方法,因为它适用于现有的评分函数,并且在OOD检测中实现了强大的性能。
-
置信度校准。近年来,在各种背景下研究了置信度校准。一些工作通过事后方法解决了误校准问题,例如温度缩放 和直方图 。此外,还提出了一些正则化方法来提高深度神经网络的校准质量,如权重衰减 ,标签平滑 ,以及焦损失 。基于共形预测的方法 在“非典型性”过高的情况下输出空集作为预测。顶部标签校准旨在校准预测类别标签的报告概率 。最近的工作 表明,这些正则化方法使得用事后方法进一步提高校准性能变得更加困难。与交叉熵相比,LogitNorm损耗在温度缩放下具有更好的校准性能。
Conclusion
- 在本文中,我们介绍了Logit归一化(LogitNorm),它是交叉熵损失的一种简单替代方法,可以增强许多现有的用于OOD检测的事后方法。通过将logits范数的影响与训练目标及其优化解耦,该模型倾向于对OOD输入给出保守的预测,从而导致与ID数据的更强的可分性。大量实验表明,LogitNorm可以在保持ID数据分类精度的同时,提高OOD检测和置信度校准。这种方法很容易在实际环境中采用。利用现有的深度学习框架实现起来很简单,并且不需要对损失或训练方案进行复杂的改变。我们希望我们的见解能启发未来的研究,进一步探索 OOD 检测的损失函数设计。
- LogitNorm 是对交叉熵损失的一个简单修正。在训练过程中,将 logit 向量归一化为其单位向量,然后在此归一化后的 logit 向量上应用 softmax 交叉熵损失。这样,网络的输出范数被严格限制为常数(1/τ),模型只能通过调整 logit 输出的方向来最小化损失,从而倾向于给出保守的预测,尤其是对于远离训练分布的输入。
- 将 logit 向量 f 分解为大小 ∥f∥ 和方向 f̂,通过分析发现,增加 ∥f∥ 会提高 softmax 置信度但不影响最终预测类别。LogitNorm 通过约束 ∥f∥ 来避免过度自信问题。具体地,LogitNorm 损失函数定义为 $ L_{LogitNorm}(f(x;θ),y) = -log\frac {e fy/(τ∥f∥) } {∑^k _{i=1} e fi/(τ∥f∥)}$,其中 τ 是温度参数,用于调节 logit 的大小。
- 超参数 τ 的选择对模型性能有一定影响。较大的 τ 会导致损失的下界较大,优化难度增加,而较小的 τ 更有利于优化。在实验中,通过在高斯噪声验证集上进行超参数调整,为 CIFAR-10 默认设置 τ 为 0.04。未来的工作可以探索如何在训练过程中自动调整 τ。
A. Proof of Proposition 3.1
-
来自Eq(2),那么我们有 f = ∣ ∣ f ∣ ∣ ⋅ f ^ . f = ||f||·\hat f. f=∣∣f∣∣⋅f^.,
-
arg max i ( f i ) = arg max i ( ∥ f ∥ ⋅ f ^ i ) = arg max i ( f ^ i ) . \operatorname{a r g} \operatorname* {m a x}_{i} ( f_{i} )=\operatorname{a r g} \operatorname* {m a x}_{i} ( \| \boldsymbol{f} \| \cdot\hat{f}_{i} )=\operatorname{a r g} \operatorname* {m a x}_{i} ( \hat{f}_{i} ). argimax(fi)=argimax(∥f∥⋅f^i)=argimax(f^i).
-
-
类似地,对于任何给定的标量s > 1,我们有,
-
arg max i ( s f i ) = arg max i ( s ∥ f ∥ ⋅ f ^ i ) = arg max i ( f ^ i ) . \operatorname{a r g} \operatorname* {m a x}_{i} ( sf_{i} )=\operatorname{a r g} \operatorname* {m a x}_{i} ( s\| \boldsymbol{f} \| \cdot\hat{f}_{i} )=\operatorname{a r g} \operatorname* {m a x}_{i} ( \hat{f}_{i} ). argimax(sfi)=argimax(s∥f∥⋅f^i)=argimax(f^i).
B. Proof of Proposition 3.2
-
从命题3.1,我们有
-
arg max i ( f i ) = arg max i ( s f i ) = c \operatorname{a r g} \operatorname* {m a x}_{i} ( f_{i} )=\operatorname{a r g} \operatorname* {m a x}_{i} ( sf_{i} )=c argimax(fi)=argimax(sfi)=c
-
设 f c = m a x i ( f i ) f_c = max_i(f_i) fc=maxi(fi),t = s-1,则我们有:
-
σ c ( s f ) = e ( 1 + t ) f c ∑ j = 1 n e ( 1 + t ) f j = e f c ∑ j = 1 n e f j + t ( f j − f c ) . \begin{aligned} {{\sigma_{c} ( s {\boldsymbol{f}} )}} & {{} {{} {}={\frac{e^{( 1+t ) f_{c}}} {\sum_{j=1}^{n} e^{( 1+t ) f_{j}}}}}} \\ {{}} & {{} {{} {} {{}={\frac{e^{f_{c}}} {\sum_{j=1}^{n} e^{f_{j}+t ( f_{j}-f_{c} )}}}.}}} \\ \end{aligned} σc(sf)=∑j=1ne(1+t)fje(1+t)fc=∑j=1nefj+t(fj−fc)efc.
-
对于任意 j ∈ [ 1 , . . . , n ] j\in [1,...,n] j∈[1,...,n],我们有, f j − f c ≤ 0 f_j- f_c≤0 fj−fc≤0。然后
-
σ c ( s f ) ≥ e f c ∑ j = 1 n e f j = σ c ( f ) . \sigma_{c} ( s \boldsymbol{f} ) \geq\frac{e^{f_{c}}} {\sum_{j=1}^{n} e^{f_{j}}}=\sigma_{c} ( \boldsymbol{f} ). σc(sf)≥∑j=1nefjefc=σc(f).
-
C. Proof of Proposition 3.3
- Let f ~ = f / ( τ ∥ f ∥ ) \widetilde{f}=f / ( \tau\| f \| ) f
=f/(τ∥f∥) , then we have ∥ f ~ ∥ = 1 / τ \| \widetilde{f} \|=1 / \tau ∥f
∥=1/τ
That is, ∑ i = 1 k f ~ i 2 = ∥ f ~ ∥ 2 = 1 / τ 2 \sum_{i=1}^{k} \widetilde{\boldsymbol{f}}_{i}^{\, 2}=\left\| \widetilde{\boldsymbol{f}} \right\|^{2}=1 / \tau^{2} ∑i=1kf i2= f 2=1/τ2
Hence,
$$- 1 / \tau\leq\widetilde{f}{i} \leq1 / \tau, \forall, i \in1, \ldots, k.
KaTeX parse error: Can't use function '$' in math mode at position 6: Let $̲\sigma( \wideti…
\begin{aligned} {{\sigma( \widetilde{\boldsymbol{f}} )}} & {{} {{} {} \leq\frac{e^{1 / \tau}} {e^{1 / \tau}+( k-1 ) e^{-1 / \tau}}}} \ {{}} & {{} {{} {}=\frac{1} {1+( k-1 ) e^{-2 / \tau}}}} \ \end{aligned}
H e n c e , Hence, Hence,
\begin{aligned} {{\mathcal{L}{\mathrm{l o g i t, n o m n}}}} & {{} {{} {}=-\operatorname{l o g} ( \sigma( \widetilde{\boldsymbol{f}} ) )}} \ {{}} & {{} {{} {} \geq-\operatorname{l o g} \frac{1} {1+( k-1 ) e^{-2 / \tau}}}} \ {{}} & {{} {{}=\operatorname{l o g} ( 1+( k-1 ) e^{-2 / \tau} )}} \ \end{aligned}
$$
- 1 / \tau\leq\widetilde{f}{i} \leq1 / \tau, \forall, i \in1, \ldots, k.
D. Descriptions of OOD Datasets
- 根据以前的文献,我们使用六个OOD测试数据集:纹理是一个可描述的纹理图像数据集。SVHN数据集包含32 × 32的门牌号彩色图像,它有十个由数字0-9组成的类别。LSUN 是另一个比Places365类更少的场景理解数据集。这里,我们使用LSUN-C和LSUN-R分别表示LSUN数据集的裁剪和调整版本。iSUN 是一个大规模的眼睛跟踪数据集,选自太阳数据库中的自然场景图像。Places365 存在于用于场景识别而非物体识别的图像中。
E. Future Work
- 在本文中,我们介绍了一种简单的交叉熵损失修复方法,该方法增强了现有的用于检测OOD实例的事后方法。我们期望这项工作中的观察和分析可以启发未来设计用于OOD检测的损失函数。一些未来的作品包括:
- 理论认识。在这项工作中,我们从经验上证明了Logit归一化可以显著提高OOD检测性能。在理论方面,我们只提出一个分析来说明为什么softmax交叉熵损失鼓励产生更大幅度的逻辑,导致过度自信问题,使得区分ID和OOD的例子具有挑战性。在未来的工作中,我们希望提供一个更严格的理论证明来分析LogitNorm损失是如何提高OOD检测的。
- 超参数调谐。在我们的实验中,我们用一个验证集——高斯噪声来调整超参数τ。虽然所提出的方法在调整后可以实现显著的改进,但是调整过程在计算上是昂贵的,因为它需要训练多个模型。因此,我们期望未来的工作能够在训练过程中自动调整τ。
F. Detailed Experimental Results
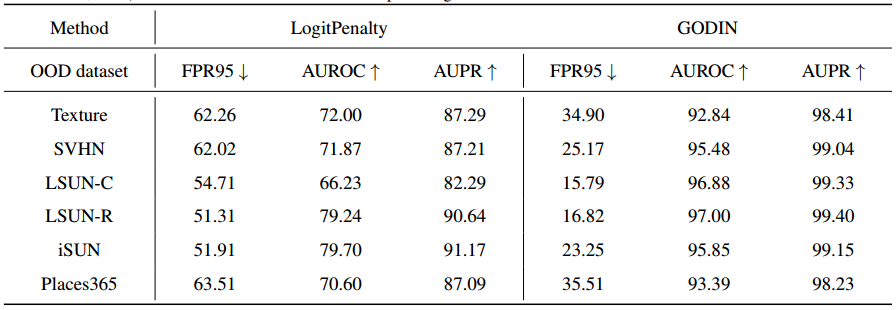
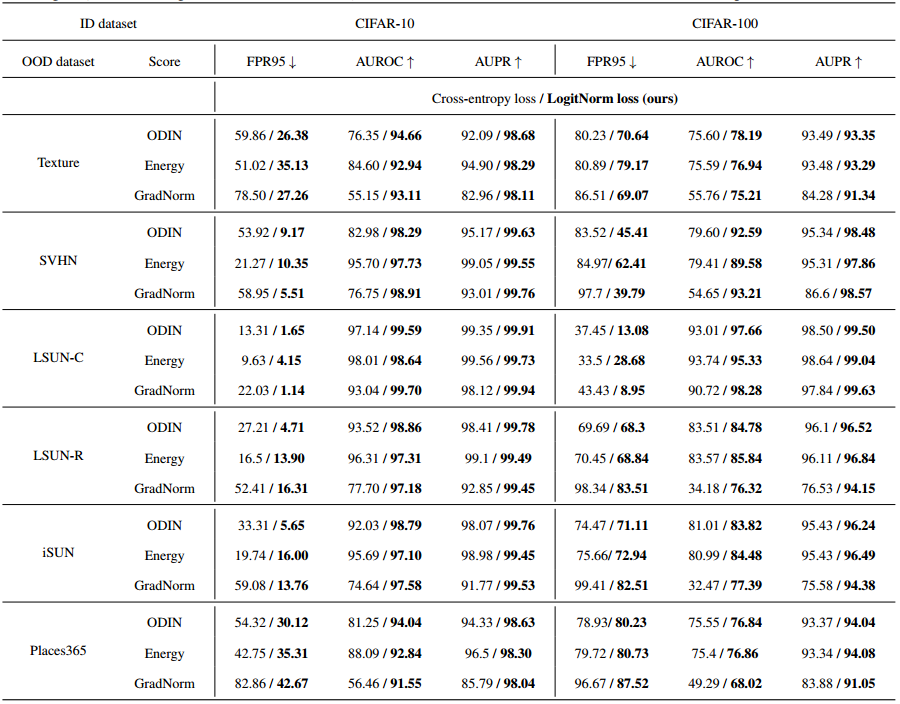
- 我们在表7、8和9中报告了OOD检测器在每个OOD测试数据集上的性能。特别是,表7显示了Logit Penalty 和 GODIN 方法的详细性能。表8 显示了在 ce 损失和 LogitNorm 损失的情况下不同评分函数的详细性能。表9显示了不同模型架构下ce损耗和LogitNorm损耗的详细性能。
-
-
表7。Logit Penalty (λ = 0:05)和GODIN方法的OOD检测性能比较。我们在CIFAR-10数据集上训练WRN-40-2 (Zagoruyko & Komodakis,2016)。所有数值均为百分比。
-
-
表8。交叉熵损失和对数损失下的 OOD 检测性能比较。我们使用WRN-40-2 (Zagoruyko & Komodakis,2016)在分布数据集上进行训练,并使用softmax置信度得分作为评分函数。所有数值均为百分比。”表示值越大越好,#表示值越小越好。粗体数字是优越的结果。
-
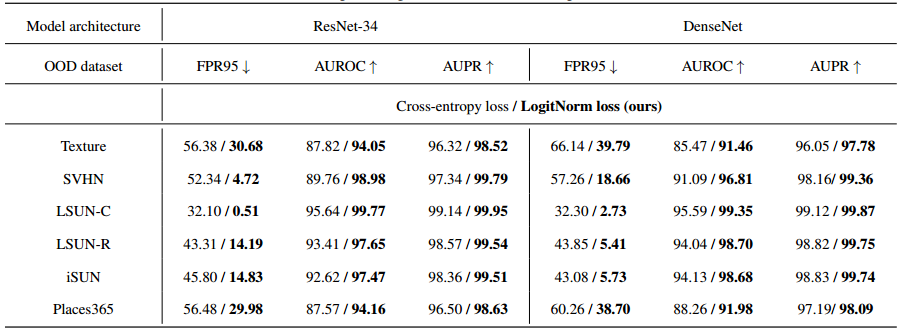
-
表9。使用交叉熵损失和 LogitNorm 损失与 ResNet-34 和DenseNet-BC的 OOD 检测性能比较。分发数据集是CIFAR-10。所有数值均为百分比。粗体数字是优越的结果。
-
项目简析:
-
论文提出通过对数几率(Logit)归一化缓解神经网络过自信问题,核心在于对模型输出的 Logit 进行 L2 范数归一化,并通过温度参数调整分布,使模型在分布内(In-distribution, ID)和分布外(Out-of-distribution, OOD)数据上的预测更可靠。
-
在 common/loss_function.py 中有 LogitNormLoss 类,其 forward 方法对输入的 logits 进行 L2 归一化,然后除以温度参数 t,再计算交叉熵损失。这符合论文中提到的对数几率归一化的方法,通过归一化使得 logits 的范数统一,减少过自信。
-
class LogitNormLoss(nn.Module): def forward(self, x, target): norms = torch.norm(x, p=2, dim=-1, keepdim=True) + 1e-7 # L2范数计算 logit_norm = torch.div(x, norms) / self.t # 归一化后除以温度t return F.cross_entropy(logit_norm, target) -
对 Logit 进行 L2 归一化(
x / ||x||_2),消除范数差异对 softmax 的影响,再通过温度t调整分布尖锐度。迫使模型输出的 Logit 范数统一,避免因过大范数导致的过度自信预测。
-
-
models/wrn.py 中的 WideResNet 模型,当使用 normed linear 层时,fc 层是 NormedLinear,其 forward 方法对输入和权重都进行归一化。另外,模型中的 feature_norm 参数用于对特征进行归一化,乘以 25 可能是为了调整尺度,保持模型输出的稳定性。WideResNet,采用残差块和归一化层,确保模型的深度和稳定性。NormedLinear 层的使用可能在某些实验中作为对比,而 LogitNormLoss 则是核心的改进部分,直接作用于 logits,进行归一化处理。NormedLinear 层(用于对比实验):
-
class NormedLinear(nn.Module): def forward(self, x): out = F.normalize(x, dim=1).mm(F.normalize(self.weight, dim=0)) return out -
对输入特征和权重同时归一化后计算内积,确保输出 Logit 的范数稳定性。在
WideResNet的前向传播中,对全局平均池化后的特征进行 L2 归一化并缩放(F.normalize(out, dim=1) * 25),增强特征稳定性。
-
-
训练框架在 algorithms/base_framework.py 和 standard.py 中,Standard 算法使用定义的损失函数,无论是交叉熵还是 LogitNormLoss,训练过程中使用 SGD 优化器和多步学习率衰减,符合常规的训练流程。论文中可能比较了不同损失函数的效果,这里的代码实现了两种损失的切换。
-
datasets/validation_dataset.py 提供了数据集分割的工具,确保训练和验证集的正确划分。svhn_loader.py 和 cifar.py 处理具体数据集的加载和完整性检查,确保数据正确输入模型。
-
common/ood_tools.py 中的 get_ood_gradnorm 函数计算 OOD 样本的梯度范数,可能用于评估模型在分布外数据上的表现,这与论文中讨论的 OOD 检测或过自信评估相关。另外,_ECELoss 类计算预期校准误差(ECE),用于衡量模型的校准程度,是论文中重要的评估指标。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 26
26 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)