【漫话机器学习系列】221.支持向量(Support Vectors)
SVM 并不是一个“黑盒模型”,其决策边界是完全由少数的支持向量决定的。理解支持向量的概念,有助于我们深入理解 SVM 的学习机制、优化方式,以及它在实际工程中的表现。在模型调优时,比如使用 soft-margin SVM 或核 SVM,支持向量的变化也能直观反映模型的复杂度与过拟合程度。
支持向量机(SVM)中的“支持向量”到底是什么?
标签:SVM、机器学习、支持向量机、可视化学习
本文借助一张手绘风格的图(图片来源:Chris Albon),来深入讲解支持向量机(Support Vector Machine)中核心概念之一:支持向量(Support Vectors)。如果你还对这个概念有点模糊,那么接下来这篇文章一定能让你“恍然大悟”!
一、背景知识:什么是 SVM?
支持向量机(SVM)是一种二分类模型,它的核心思想是:
寻找一个最优超平面,将不同类别的数据分隔开来,并尽可能地让两边的数据点离这个超平面尽可能远。
这种最大间隔的思想使得模型具有良好的泛化能力,尤其适用于样本数量不多但特征维度较高的情况。
二、本文重点:什么是“支持向量”?
我们看下面这张图
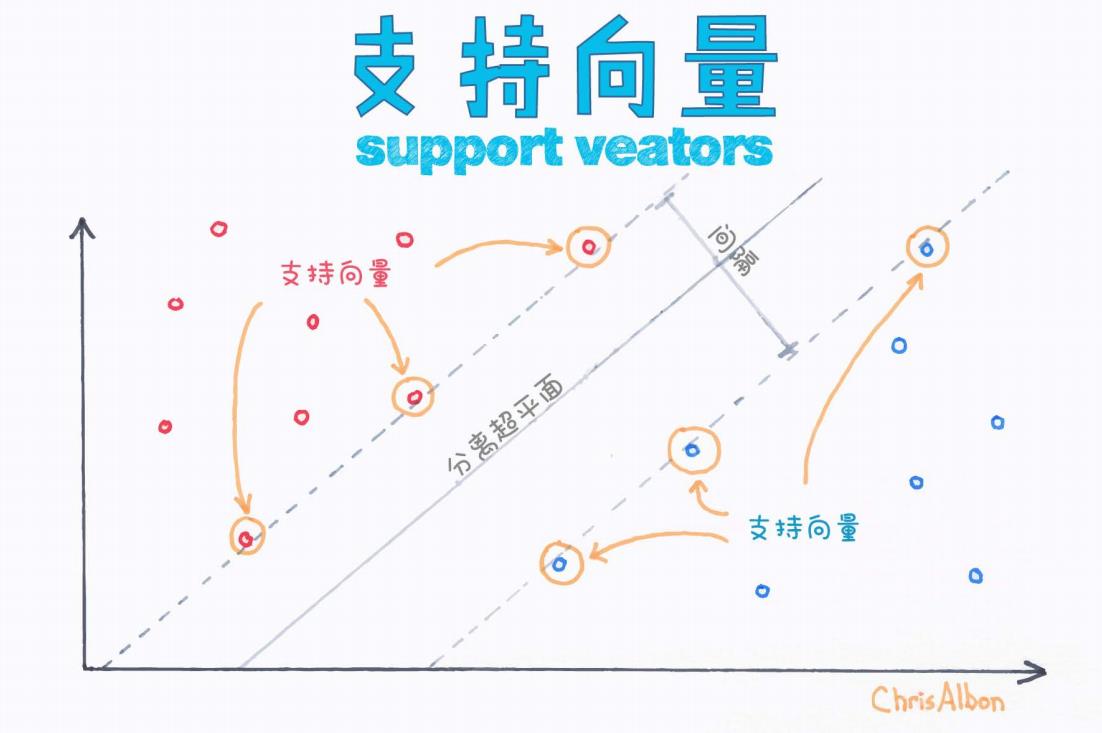
图中蓝色圈表示一类样本(例如:正类),红色圈表示另一类样本(负类)。中间那条实线是“分离超平面”,它正好把两类样本区分开。而在它两侧的那两条虚线,是定义“最大间隔”的边界线。
接下来,重点来了:
那些距离分离超平面最近的点,就叫做“支持向量”。
它们决定了这个超平面的位置和方向。换句话说:
-
如果没有这些支持向量,SVM 就没有依据来划定边界。
-
如果你把数据中所有非支持向量的点移除,SVM 的分界线仍然不会发生变化!
在图中,这些点已经被标注出圆圈并用箭头标记为“支持向量”。
三、最大间隔的意义
在图中,分离超平面两边的虚线之间的宽度,就是我们常说的“间隔(margin)”。SVM 的目标就是最大化这个间隔。
为什么这么做?
-
间隔越大,对未知数据的鲁棒性越强。
-
更大的间隔通常意味着更强的泛化能力。
而正是图中那些最靠近分离超平面的点(即支持向量),决定了这个间隔的大小。
四、SVM 的数学表达式
我们从几何上理解了支持向量,那么从数学上如何定义呢?
SVM 的最优超平面可以定义为:
其中:
-
是法向量(决定方向)
-
b 是偏置项(决定距离原点的远近)
而间隔可以表达为:
SVM 的优化目标是:
五、支持向量的实际意义
我们回顾下这个概念为什么重要:
模型泛化的关键因子
决定模型参数的点
可以用于特征选择、异常点检测等任务
在某些核方法中,比如高维映射后的核SVM中,支持向量同样是关键,它们的组合决定了整个模型在高维空间的决策边界。
六、结语:为什么要关注“支持向量”?
SVM 并不是一个“黑盒模型”,其决策边界是完全由少数的支持向量决定的。理解支持向量的概念,有助于我们深入理解 SVM 的学习机制、优化方式,以及它在实际工程中的表现。
在模型调优时,比如使用 soft-margin SVM 或核 SVM,支持向量的变化也能直观反映模型的复杂度与过拟合程度。
推荐动手实践:用
scikit-learn的 SVM 训练一个简单的模型,调用model.support_vectors_,看看哪些点被选为了支持向量。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 10
10 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)