基于标准反向传播算法的改进BP神经网络算法(Matlab代码实现)
💥💥💞💞❤️❤️💥💥博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。⛳️行百里者,半于九十。📋📋📋🎁🎁🎁。
💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
⛳️赠与读者
👨💻做科研,涉及到一个深在的思想系统,需要科研者逻辑缜密,踏实认真,但是不能只是努力,很多时候借力比努力更重要,然后还要有仰望星空的创新点和启发点。建议读者按目录次序逐一浏览,免得骤然跌入幽暗的迷宫找不到来时的路,它不足为你揭示全部问题的答案,但若能解答你胸中升起的一朵朵疑云,也未尝不会酿成晚霞斑斓的别一番景致,万一它给你带来了一场精神世界的苦雨,那就借机洗刷一下原来存放在那儿的“躺平”上的尘埃吧。
或许,雨过云收,神驰的天地更清朗.......🔎🔎🔎
💥1 概述
基于标准反向传播算法的改进BP神经网络算法研究
一、标准反向传播算法(BP)的基本原理
标准BP算法是一种基于梯度下降的监督学习算法,通过链式法则逐层计算误差梯度并更新网络参数,其核心流程分为以下步骤:
- 前向传播:输入数据从输入层经隐藏层逐层传递至输出层,计算各层激活值。
- 误差计算:通过损失函数(如均方误差MSE、交叉熵等)量化预测输出与真实值的差异,例如MSE公式为:
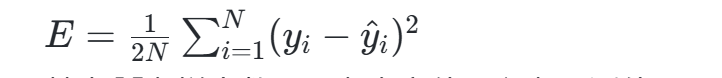
其中N为样本数,yi为真实值,y^i为预测值。 - 反向传播:从输出层到输入层逐层计算各参数的梯度,利用链式法则分解复合函数的导数。
- 参数更新:根据梯度下降法调整权重和偏置,公式为:
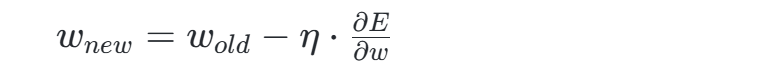
其中η为学习率。 - 迭代训练:重复上述步骤直至损失收敛或达到停止条件。
二、基于标准BP的改进方法分类与实现
1. 启发式改进方法
-
动量梯度法(Momentum)
在梯度更新中引入动量项,公式为: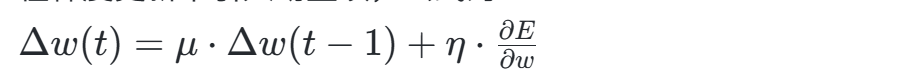
其中μ为动量因子(通常取0.8-0.95),通过累积历史梯度方向减少震荡,加速平坦区域的收敛。实验表明,动量法可使MNIST数据集训练时间缩短30%。 -
自适应学习率方法
动态调整学习率以应对不同参数的敏感性,典型算法包括:- AdaGrad:根据历史梯度平方和调整学习率:

其中Gt为梯度平方累积。 - Adam:结合动量项和自适应学习率,通过一阶矩(均值)和二阶矩(方差)估计调整步长。
- AdaGrad:根据历史梯度平方和调整学习率:
2. 优化算法结合
-
遗传算法(GA)与模拟退火(SA)
GA通过选择、交叉、变异操作全局搜索最优初始权重;SA利用概率突跳避免局部极小。实验显示,GA-BP在316L焊接残余应力预测中RMSE降低0.82%。GSA-BP(遗传模拟退火优化)在智能车控制中提升了收敛速度和稳定性。 -
分数阶动量梯度法
采用分数阶导数(Grünwald-Letnikov定义)替代整数阶,增强梯度信息表达能力。自适应动量系数进一步优化收敛轨迹,实验表明在MNIST数据集上收敛速度提升20%。
3. 正则化与结构优化
-
正则化技术
L1/L2正则化在损失函数中添加惩罚项,限制权重幅值以防止过拟合。例如L2正则化公式为: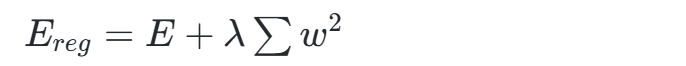
其中λ为正则化系数。 -
批量归一化(Batch Normalization)
对每层输入进行标准化处理,加速训练并减少对初始权重的敏感性。 -
陡度因子调整
动态调整激活函数的陡度参数,例如Sigmoid函数中引入可调参数ββ:
实验显示,结合动态学习率可使迭代次数从3000次降至118次。
三、改进方法的对比分析
| 方法 | 优势 | 局限性 | 适用场景 |
|---|---|---|---|
| 动量梯度法 | 减少震荡,加速平坦区域收敛 | 需手动调整动量因子 | 高维非凸优化问题 |
| Adam | 自适应学习率,结合动量法 | 超参数敏感,可能早熟收敛 | 大部分深度学习任务 |
| 遗传算法(GA) | 全局搜索,避免局部极小 | 计算开销大,局部搜索能力弱 | 复杂非线性问题初始化优化 |
| 正则化技术 | 防止过拟合,提高泛化能力 | 需平衡正则化强度与模型复杂度 | 高方差模型 |
| 分数阶梯度法 | 增强梯度信息,跳出局部极小 | 数学推导复杂,实现难度高 | 非平稳数据优化 |
四、典型研究案例与实验数据
-
动态学习率与动量法融合
在非线性函数拟合中,采用动态学习率(初始η=0.01η=0.01,增长比1.05,下降比0.75)和动量因子μ=0.95μ=0.95,迭代次数由3000次降至118次,MSE从0.026降至0.0006。 -
GA-BP网络在冷鲜肉品质预测中的应用
MFO-BP(蛾群算法优化)模型相比标准BP,TVB-N指标的测试集R2R2提升10%,RMSE降低15%,验证了混合算法的优越性。 -
自适应动量分数阶梯度法
在XOR问题和MNIST数据集上,分数阶梯度法收敛速度提升30%,且学习率选择范围扩大50%。
五、最新研究进展
-
混合优化模型
- PSO-BP:粒子群优化(PSO)初始化BP网络权重,在土遗址锚固力预测中全局搜索效率提升40%。
- 深度BP网络:结合残差连接(ResNet思想)缓解梯度消失,层数增至10层以上。
-
可解释性与动态调整
研究焦点转向动态调整策略(如基于损失曲率的自适应学习率)和多目标优化(如同时优化精度与计算效率)。
六、结论与展望
改进BP算法的核心在于平衡收敛速度、全局优化与泛化能力。未来趋势包括:
- 算法融合:如量子优化与BP结合,提升复杂问题求解效率。
- 自动化调参:基于元学习(Meta-Learning)的动态超参数调整。
- 硬件协同设计:针对GPU/TPU架构优化分布式BP训练。
通过持续的方法创新与跨学科融合,BP神经网络在实时控制、高维数据处理等领域的应用潜力将进一步释放。
📚2 运行结果


W1W1 =-0.1900 -0.7425 -2.9507-0.3955 0.2059 -0.8937-0.4751 0.5315 -1.2644-2.5390 -1.8319 3.2741-1.0816 -0.6534 0.7954-1.4622 -0.0331 -0.4283-0.3125 0.0840 -0.8470-0.6496 -0.2922 -0.6272b1b1 =9.42431.54310.18602.46300.10970.53901.6335-0.4229W2W2 =-1.6282 0.5796 0.2008 1.0366 0.9238 -0.3099 0.6122 -0.0681b2b2 =0.3461Mean Error Square at Iter = 2000eSq =0.0016eSq_v =0.0022eSq_t =0.0017Trained时间已过 1540.739160 秒。No. of Iterations = 2001Final Mean Squared Error at Iter = 2001eSq =0.0016>>

部分代码:
%****Load the Input File******
load ./nnm_train.txt
redData = nnm_train(:,2);
nir1Data = [nnm_train(:,3) ./ redData]';
nir2Data = [nnm_train(:,4) ./ redData]';
nir3Data = [nnm_train(:,5) ./ redData]';
pg = [ nir1Data; nir2Data; nir3Data];
targetData = nnm_train(:,7) ;
%*******Validate Data*******
load ./nnm_validate.txt
redData_v = nnm_validate(:,2);
nir1Data_v = [nnm_validate(:,3) ./ redData_v]';
nir2Data_v = [nnm_validate(:,4) ./ redData_v]';
nir3Data_v = [nnm_validate(:,5) ./ redData_v]';
targetData_v = nnm_validate(:,7) ;
pValidate = [nir1Data_v; nir2Data_v; nir3Data_v];
%*******Test Data*******
load ./nnm_test.txt
redData_t = nnm_test(:,2);
nir1Data_t = [nnm_test(:,3) ./ redData_t]';
nir2Data_t = [nnm_test(:,4) ./ redData_t]';
nir3Data_t = [nnm_test(:,5) ./ redData_t]';
targetData_t = nnm_test(:,7) ;
pTest = [nir1Data_t; nir2Data_t; nir3Data_t];
%---Plot the Original Function----
pa = 1 : length(targetData_t);
actLine = 0:0.1:0.8;
subplot(2,1,2), plot (actLine, actLine); legend('Actual');%scatter(targetData_t, targetData_t,'^b');
hold on
%-----Randomized First Layer Weights & Bias-------
fprintf( 'Initial Weights and Biases');
%****3-8-1******
W1 = [ -0.5+rand -0.5+rand -0.5+rand -0.5+rand -0.5+rand -0.5+rand -0.5+rand -0.5+rand; -0.5+rand -0.5+rand -0.5+rand -0.5+rand -0.5+rand -0.5+rand -0.5+rand -0.5+rand;...
-0.5+rand -0.5+rand -0.5+rand -0.5+rand -0.5+rand -0.5+rand -0.5+rand -0.5+rand]'; %Uniform distribution [-0.5 0.5]
b1 = [ -0.5+rand -0.5+rand -0.5+rand -0.5+rand -0.5+rand -0.5+rand -0.5+rand -0.5+rand]';
W2 = [ -0.5+rand -0.5+rand -0.5+rand -0.5+rand -0.5+rand -0.5+rand -0.5+rand -0.5+rand];
%-----Randomized Second Layer Bias------
b2 = [ -0.5+rand ];
if (lambda == 0) % Save the Weights and Bias on SBP
W1_initial = W1;
b1_initial = b1;
W2_initial = W2;
b2_initial = b2;
else % Reuse the Weights and Bias on MBP
W1 = W1_initial;
b1 = b1_initial;
W2 = W2_initial;
b2 = b2_initial;
end
%-----RandPermutation of Input Training Set-------
j = randperm(length(targetData));
j_v = randperm(length(targetData_v));
j_t = randperm(length(targetData_t));
%--Set Max. Iterations---
maxIter = 2000;
tic
for train = 1 : maxIter +1
eSq = 0; eSq_v = 0; eSq_t = 0;
% **** Mean Square Error ****
%if ( train <= maxIter )
for p = 1 : length(targetData)
n1 = W1*pg(:,p)+ b1 ;
a1 = logsig(n1);
a2 = poslin( W2 * a1 + b2 );
e = targetData(p) - a2 ;
eSq = eSq + (e^2);
end
eSq = eSq/length(targetData);
%*******Validate Error**********
for p = 1 : length(targetData_v)
n1 = W1*pValidate(:,p)+ b1 ;
a1 = logsig(n1);
a2 = poslin( W2 * a1 + b2 );
e = targetData_v(p) - a2 ;
eSq_v = eSq_v + (e^2);
end
eSq_v = eSq_v/length(targetData_v);
%********Use Validate Error for Early Stopping********
if ( train > 200 )
earlyStopCount = earlyStopCount + 1;
% fprintf('EarlyStop = %d', earlyStopCount);
if (earlyStopCount == 50)
if ( (prev_eSq_v - eSq_v) < 0 )
W2 = W2_25;
b2 = b2_25;
W1 = W1_25;
b1 = b1_25;
break;
end
prev_eSq_v = eSq_v; % Store previous validation error
earlyStopCount = 0; % Reset Early Stopping
%----Save the weights and biases-------
disp('Saving'); eSq
W2_25 = W2;
b2_25 = b2;
W1_25 = W1;
b1_25 = b1;
end
else
% ----Initialize the Weights----
if ( train == 200 )
W2_25 = W2;
b2_25 = b2;
W1_25 = W1;
b1_25 = b1;
end
prev_eSq_v = eSq_v; % Store previous validation error
end
%*******Test Error**********
for p = 1 : length(targetData_t)
n1 = W1*pTest(:,p)+ b1 ;
a1 = logsig(n1);
a2 = poslin( W2 * a1 + b2 );
e = targetData_t(p) - a2 ;
eSq_t = eSq_t + (e^2);
end
eSq_t = eSq_t/length(targetData_t);
if (train == 1 || mod (train, 100) == 0 )
fprintf( 'Weights and Biases at Iter = %d\n',train);
fprintf('W1');
(W1)
fprintf('b1')
b1
fprintf('W2')
W2
fprintf('b2')
b2
fprintf( 'Mean Error Square at Iter = %d',train);
eSq
eSq_v
eSq_t
end
subplot(2,1,1),
xlabel('No. of Iterations');
ylabel('Mean Square Error');
title('Convergence Characteristics ');
loglog(train, eSq, '*r'); hold on
loglog(train, eSq_v, '*g'); hold on
loglog(train, eSq_t, '*c'); hold on
legend('Training Error', 'Validation Error', 'Testing Error');
%************Train Data**********************
% Update only when the error is decreasing
% if ( earlyStopCount == 0 )
for p = 1 : length(targetData)
%----Output of the 1st Layer-----------
n1 = W1*pg(:,j(p))+ b1 ;
a1 = logsig(n1) ;
%-----Output of the 2nd Layer----------
n2 = W2 * a1 + b2;
a2 = (poslin( n2 ));
%a2 = (logsig( n2 ));
%-----Error-----
t = targetData(j(p));
e = t - a2;
%******CALCULATE THE SENSITIVITIES************
%-----Derivative of logsig function----
%f1 = dlogsig(n1,a1)
% f1 = [(1-a1(1))*a1(1) 0; 0 (1-a1(2))*a1(2)] ;
f1 = diag((1-a1).*a1);
%-----Derivative of purelin function---
f2 = 1;
%f2 = diag((1-a2).*a2);
%------Last Layer (2nd) Sensitivity----
S2 = -2 * f2 * e;
S2mbp = ((t)-n2);
%------First Layer Sensitivity---------
S1 = f1 *(W2' * S2);
S1mbp = f1 * (W2' * S2mbp);
%******UPDATE THE WEIGHTS**********************
%-----Second Layer Weights & Bias------
W2 = W2 - (alpha * S2*(a1)') - (alpha * lambda * S2mbp *(a1)');
b2 = b2 - alpha * S2 - (alpha * lambda * S2mbp);
%-----First Layer Weights & Bias-------
W1 = W1 - alpha * S1*(pg(:,j(p)))' - (alpha * lambda * S1mbp *(pg(:,j(p)))');
b1 = b1 - alpha * S1 - (alpha * lambda * S1mbp );
% end
end
%end
% End of 21 Input Training Sets
% ********** Function Apporx. *****************
if (train == 1 || mod (train, 100) == 0 || train == maxIter )
disp('Trained');
subplot(2,1,2),
xlabel('Actual Fraction of Weeds in 3 sq feet of grass area');
ylabel('Estimated Fraction of Weeds in 3 sq feet of grass area');
title('Correlation of Estimated Value with respect to the Actual Function using Standard Backpropagation');
legend('Estimated');
for p = 1 : length(targetData_t)
n1 = W1*pTest(:,p)+ b1 ; % Test Data
a1 = logsig(n1) ;
a2(p) = (poslin( W2 * a1 + b2 ));
end %end for
%scatter(targetData_t, a2); hold on;
end
end
toc
%-------End of Iterations------------
%***Plot of Final Function******
subplot(2,1,2),
for p = 1 : length(targetData_t)
n1 = W1*pTest(:,p)+ b1 ; % Test Data
a1 = logsig(n1) ;
a2(p) = (poslin( W2 * a1 + b2 ));
end %end for
🎉3 参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。(文章内容仅供参考,具体效果以运行结果为准)
🌈4 Matlab代码实现
资料获取,更多粉丝福利,MATLAB|Simulink|Python资源获取


脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 18
18 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)