人工智能发展史 — MP 模型和感知机模型的数学模型与编程应用
这意味着用于描述样本的特征需要由专家设计,算法性能依赖于人工设计和抽取这些特征的准确度,以便使模型能够完成特定的任务,因此它的应用受到了很大的限制。其中,“阈值逻辑”、“Hebb 学习率”,前 2 个理论解决了单个神经元层面的建模问题,来自于对大脑神经元的生理学研究,共同构成了 “感知机” 的理论基础,在 1950s 提出;所以,和 MP 模型一样,感知机模型也是一个应用于线性分类场景的 “二分类
目录
文章目录
人工智能发展流派
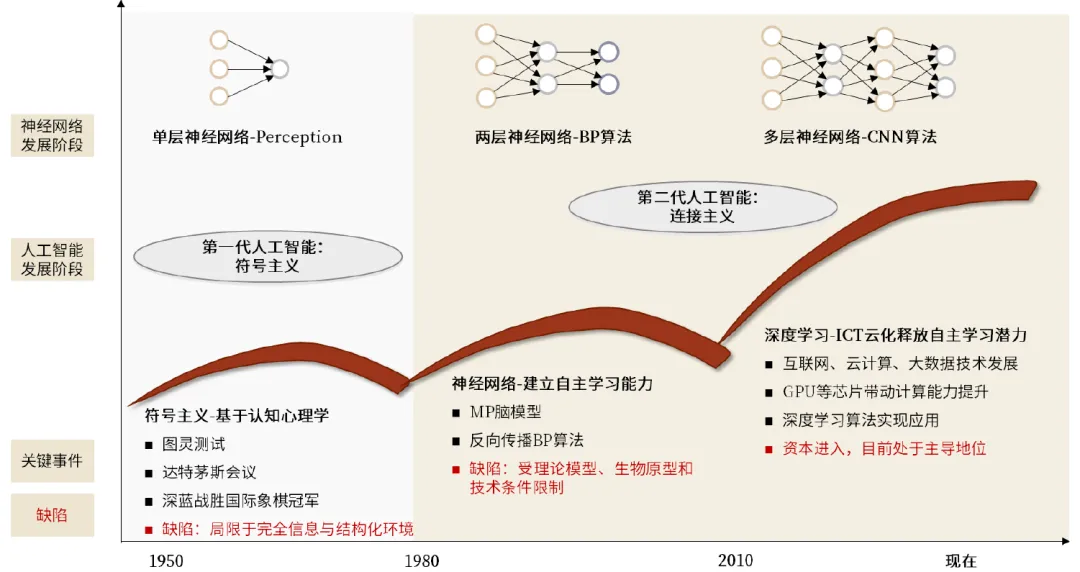
人工智能的发展历程中,主要形成了三大技术流派:符号主义、联结主义和行为主义。它们在理论基础、研究方向和应用场景上各有侧重,并随着技术的发展交叉融合形成新的研究方向。
符号主义
符号逻辑思想认为人类理解力范围内的一切事物皆可以用符号来标记,人类理解力本身可以被描述成这些符号之间的运算。结合以上两者,得到一套带运算的符号系统(物理符号系统),它就等于人类的智能,并且,这套系统可以被完整地写进机器,从而机器便可拥有与人类一致的智能。在这个视角下,智能表现为对符号的操作(比如基于规则的推理)。符号逻辑思想之下最具代表性的实例就是专家系统。(Siri 最初就是一个专家系统。)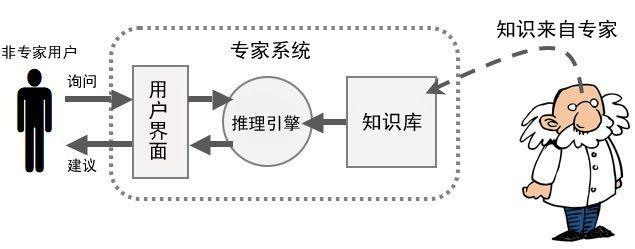
基于符号逻辑思想的方法需要由人去把事物及其相关规律描述出来,这类方法毕竟受限于人力,只能适用于少部分场景。而在它的对立面,一种不依赖于人类描述的“生智”思路出现了,这就是联结涌现思想。
联结主义
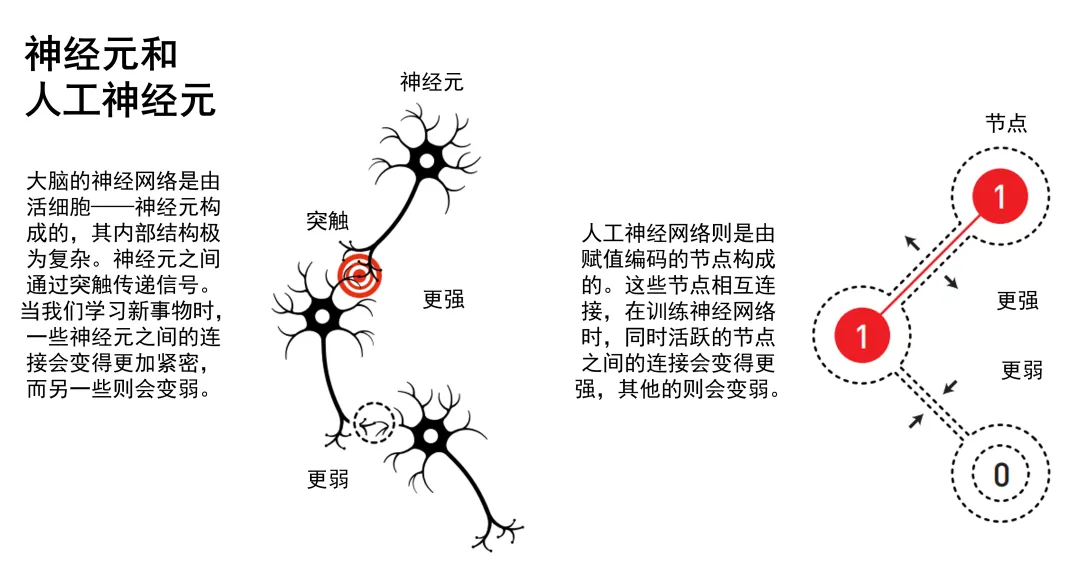
又称为:仿生学派或生理学派。源于仿生学,特别是人脑模型的研究。联结涌现思想认为:智能不必非得表现为一套显式的、复杂的人类符号或规则,它也可从大量简单单元之间的联结之中涌现出来(正如人脑的实际情况那样),即便人类无法用符号标记它、描述它、思考它、操控它。联结主义认为人的智能归结为人脑的高层活动的结果,强调智能活动是由大量简单的单元通过复杂链接后并行运行的结果。所以联结主义 AI 学派的原理是模仿人脑神经网络结构,即:神经网络单元及单元之间的连接机制与学习算法。代表成果:人工神经网络(artificial neural network,ANN)。
直至 2010 年之后,联结主义(Connectionism)依托大数据与 GPU 算力支撑深度学习在计算机视觉、自然语言处理、自动驾驶、AGI 等领域持续突破,已经主导了当前 AI 技术前沿。
然而,联结涌现思想也有它的问题:
- 难解释:智能从简单单元的联结之中涌现出来的机制机理是什么?很难回答。
- 难控制:这是 “难解释” 的直接后果,我们难以弄清楚其机制机理,也就难以弄清楚其边界,这里面便可能潜藏着伦理风险。
基于联结涌现思想,人们可以创造出一个模型,但是,要如何调整这个模型,才能让它具备智能、提高智能呢?这就是概率统计思想发挥作用的地方。概率统计思想给了我们提供了一个看待模型的新视角、一套描述模型及其工作流程的新概念,在这套概念下我们将形成操控模型的思路与方法,宛如给模型这匹野马上了一套马具。具体来说:
- 模型:概率分布描述式,类似于概率密度函数、概率分布函数。
- 模型的参数:概率分布描述式中的参数。
- 模型的输入:条件。
- 模型的输出:从条件概率分布中采样出来的样本。
- 模型的输出值与训练数据的误差:估计值与观测值之间的差异。
- 模型训练中的参数调整:最大似然估计。
在这套概念之下,模型的训练过程被理解成概率统计中参数估计的过程,而模型的推理过程则被理解成从概率分布中采样的过程。从概率统计的角度看,它把自己的一整套世界观和方法论“摁”到了模型的头上,把模型收编为了自己的分布建模工具。而从模型的角度看,它的制作与使用都获得了方法论。
行为主义
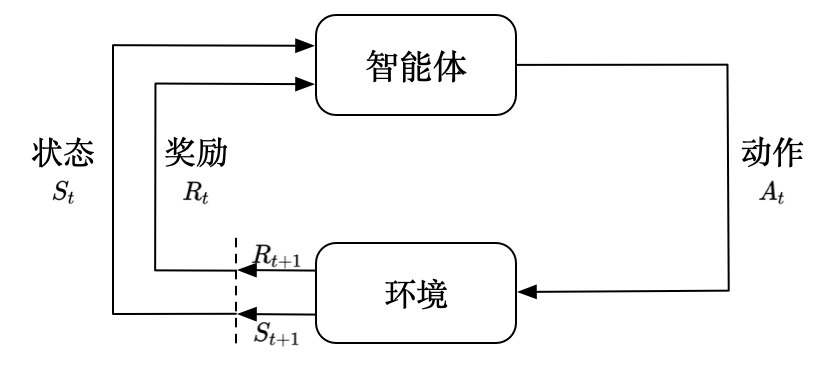
符号逻辑思想和联结涌现思想关心的主要是 “用什么方式表示智能”,行为反馈思想关心的则主要是 “用什么方式增强智能”。行为反馈思想认为,无论是在机器中还是在人脑中,无论是用符号来表示还是用模型来承载,任何智能都要在与环境的交互中得到体现,都能从与环境的交互中学习提升。这就是在行为反馈思想之下出现的强化学习方法。
联结主义人工智能发展史时间线

联结主义 AI 的典型人工神经网络的 4 大理论支柱分别为:
- 阈值逻辑
- Hebb 学习率
- 梯度下降算法
- 反向传播算法
其中,“阈值逻辑”、“Hebb 学习率”,前 2 个理论解决了单个神经元层面的建模问题,来自于对大脑神经元的生理学研究,共同构成了 “感知机” 的理论基础,在 1950s 提出;“梯度下降算法” 与 “反向传播算法” 则解决了多层神经网络训练问题,在 1980s 以后相继被提出。后面我们都将一一介绍。
1943 年:M-P 神经元数学模型
美国神经科学家沃伦·斯特·麦卡洛克(Warren McCulloch)和逻辑学家沃尔特·皮茨(Walter Pitts)发表了论文《A logical calculus of the ideas immanent in nervous activity》(神经活动中固有思想的逻辑演算),提出世界上第一个简化的神经元数学模型,称为 MP 神经元(McCulloch-Pitts Neuron),为联结主义 AI 神经网络机器学习奠定了数学基础。
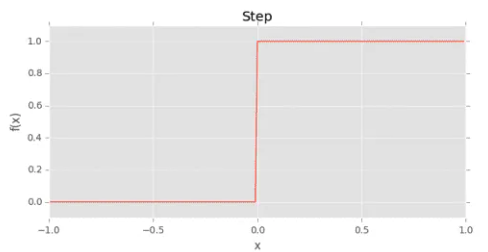
生物学神经元
人工智能使用的神经网络,起源于对人脑神经元的生理学研究,人工智能的未来发展方向,如类脑智能,和对大脑的生理学研究的联系更是十分密切。
下图是一个生物神经元结构,包括:
- 树突(Dendrites):一个神经元可以有多个树突,负责接收来自其他神经元的信号,并将这些信号传递到胞体。
- 细胞核(Soma):处理接收到的信息,并决定是否激活神经元。
- 轴突(Axon):一旦神经元被激活,轴突会将信号传递给其他神经元。
- 突触(Synapse):是神经元之间进行连接的接口。
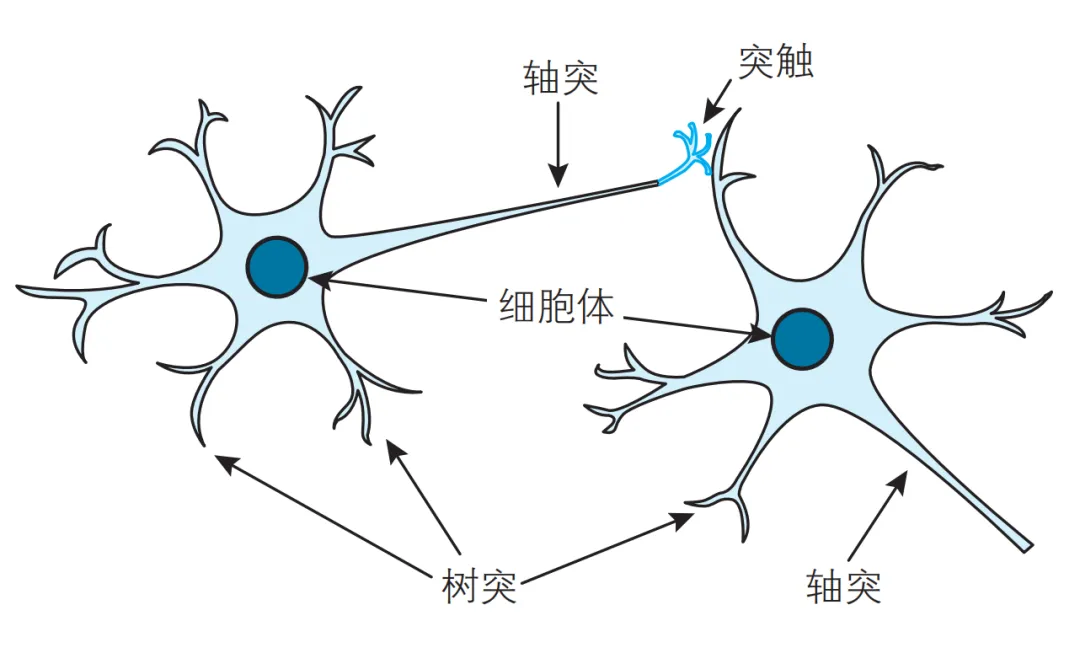
生物神经元具有多输入、单输出的特性。每个神经元平均有 7000 个突触,用于接收其他神经元传递来的电脉冲。
每个电脉冲会激活 “突触” 内的一些金属正离子从而导致接收神经元细胞壁内电位差产生一定变化。当一个神经元收到足够多的电脉冲, 累积的电位差达到一定 “阈值” 时就会引发一个新的电脉冲。这个新脉冲会通过 “轴突” 的输出结构向其他神经元传播,并且被激活的突触所引发的电位差变化并不依赖电脉冲的强度,而是主要取决于该突触自身的 “活性”。
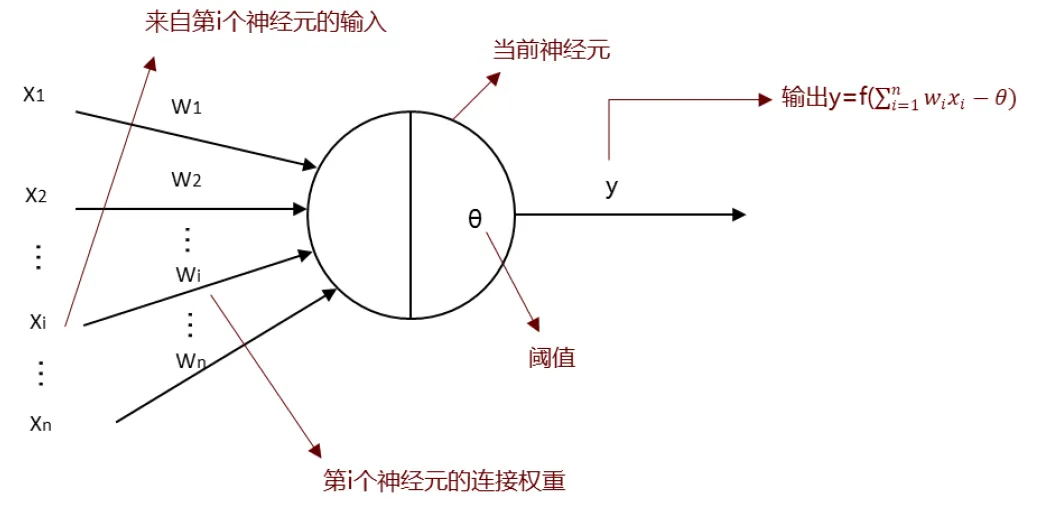
人工神经元数学模型(阈值逻辑)
上述可知,生物神经元通过 “有或无” 电脉冲来传递信息的,类似数字电路中 01 信号的方式,所以 MP 人工神经元数据模型的本质是一个阈值逻辑单元(基于阈值的二进制的逻辑门),模拟了生物神经元的兴奋与抑制机制。
其数学模型如下图所示。
其数学公式如下图所示: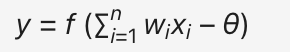
- 输入 xi:二值化信号(0或1),表示第 i 个神经元的输入。
- 权重 ωi:神经元对 xi 的敏感度,正值为兴奋性输入,负值为抑制性输入。每个 x 都有对应的一个 ω(欧米伽)。
- 阈值 θ:临界值,决定神经元是否激活。
- 输出 y:神经元激活函数计算的结果。
- 激活函数 f():MP 模型采用跃阶函数,输出二值结果(0 或 1),函数性质如下图所示:
- 当实参 >= 0 时,sgn() 返回 1;
- 当实参 < 0 时,sgn() 返回 0;
跃阶函数:为了将净输入值进行二值压缩。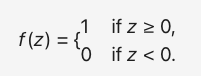
激活函数 f() 模拟了神经元受到输入信号刺激后进行二分类运算并输出 0 或 1。这符合生物神经元的特点,生物神经元对输入信号所产生的输出就是 “兴奋 or 抑制”。
最后我们再总结生物模型和数学模型的映射关系。
实际应用
在 MP 模型的实际应用中,x 和 y 的因果逻辑关系往往是根据生活经验来确定的,建模过程的主要工作内容就是通过调整 ω 和 θ 参数来实现 x 和 y 的逻辑关系。
这里举一个简单的,只有一个输入 x 和 ω 的例子:通过 MP 模型实现根据天气情况(晴天、雨天)决定是否带伞,其建模过程如下。
- 确定输入 x:枚举天气情况,晴天 0,雨天 1;
- 确定输出 y:枚举带伞情况,不带伞 -1,带伞 1。
- 确定 sgn 函数结果:如果 <0,则输出 -1;如果 >0,则输出 1。
- 调整权重 ω 和偏置值 θ:ω 和 θ 作为唯二的可调参数,其中 ω 表示天气情况决定是否带伞的权重。这里我们假设 ω = 1 和 θ = 0.5,可以得到 MP 模型 y = sgn(x*1 - 0.5),则:
- 当 x=0(晴天),0*1 - 0.5 = -0.5 < 0,则 y=-1(不带伞)。
- 当 x=1(雨天),1*1 - 0.5 = 0.5 > 0,则 y=1(带伞)。
可见,通过手动调整权重 ω 和阈值 θ,可以使得 MP 模型实现我们所期望的输入输出映射。
局限性
综合上述内容,可以介绍 MP 模型的 2 个关键局限:
-
MP 模型不会自己学习调整参数,需要人为地根据经验和知识来手动调整这些 ω 和 b 参数。例如:我们可能认为雨天带伞的重要性高于晴天,因此我们可以给雨天的权重分配一个较高的值,实现只要雨天就一定会带伞。这意味着用于描述样本的特征需要由专家设计,算法性能依赖于人工设计和抽取这些特征的准确度,以便使模型能够完成特定的任务,因此它的应用受到了很大的限制。
-
MP 模型采用的 sgn 激活函数,本质是一个二分类函数,仅能处理线性可分问题。例如:降雨概率和带伞概率是线性正相关的。这意味着 MP 模型无法求解非线性相关场景,根本上限制了它的应用场景。
1949 年:Hebb 学习率
巴甫洛夫的狗实验
俄国生理学家伊万·巴甫洛夫(Ivan Pavlov)著名的狗实验揭示了经典条件反射的生理学机制。
其实验过程如下:
- 无条件反射阶段:巴甫洛夫观察到,当狗直接接触食物(无条件刺激)时,会自然分泌唾液(无条件反应)。这是无需学习的生理本能。
- 中性刺激引入:他选择与食物无关的中性刺激(如铃声、红灯、节拍器等),并在每次喂食前重复呈现这些刺激,例如摇铃后立即提供食物。
- 条件反射建立:经过多次重复后,中性刺激(铃声)与无条件刺激(食物)形成关联。此时,仅摇铃而不提供食物,狗仍会分泌唾液。此时中性刺激转变为条件刺激,引发的唾液分泌称为条件反应。
- 实验扩展:巴甫洛夫还尝试测试了其他刺激(如不同音调的铃声)对条件反射的影响,发现狗会对相似刺激产生泛化反应。
通过实验研究,巴甫洛夫证明了经典条件反射的形成机制:
- 习得:中性刺激与无条件刺激的多次配对是建立条件反射的关键。
- 消退:若仅呈现条件刺激而无食物,唾液分泌反应会逐渐减弱直至消失。
- 泛化:狗会对类似的刺激(如不同音调铃声)产生相同的反应。
巴甫洛夫的狗实验证明了神经回路的可塑性,以及大脑学习的生理机制。
赫布定律
心理学家和神经科学家唐纳德·赫布(Donald Hebb)受到了巴甫洛夫条件反射实验的启发,在《The Organization of Behavior》(行为的组织)一文中提出了一个假设用以说明神经回路是可以通过反复训练来塑造,这被称之为赫布定律。原文如下。
当细胞 A 的突触足够接近细胞 B 并能使之兴奋,且持续地激活细胞 B 时,这两个细胞就会发生某些生长过程或代谢变化,使得 A 成为了了更能刺激 B 兴奋的细胞之一。
Hebb 的著名观点 “Neurons that fire together, wire together(共同激发的相邻神经元将彼此建立连接)”。他假设生物神经元之间的突触上的强度是会自适应变化的,神经元之间的连接会因反复的同步激活而被加强,反之则变弱。连接的强弱反过来又会影响到往后神经元接收刺激之后产生的反应,表现在行为上就产生一种学习的效果。
例如:铃声响时狗的一个神经元被激发,在同一时间食物的出现会激发附近的另一个神经元,那么这两个神经元间的联系就会强化,形成一个神经回路,记住了这两个事物之间存在着联系。
因此,赫布定律说明了 “学习的本质是神经元之间的关联”。
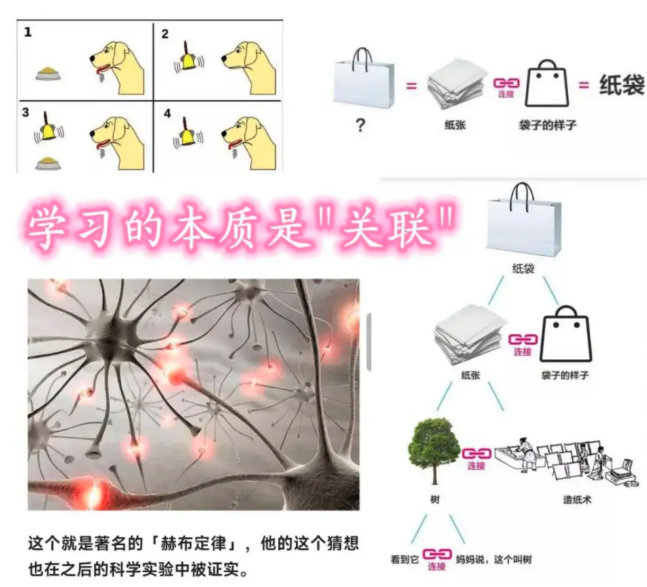
Hebb 学习规则
在一个神经网络的训练过程中,其内涵就是让权重 ω 和偏置项 b 的值调整到预期最佳,以使得整个网络的预测效果符合预期。ω 和 b 的精度直接决定了神经网络的预测表现。
在早期的 MP 模型中,ω 的值都是人为预先设置的,不能够完成自学习。赫布定律让计算机科学家们开始考虑通过学习的方式来动态调整 ω 权值,这为后面的学习算法奠定了基础。这就是 Hebb 学习规则,其中心思想是 “如果一个神经元反复地或持续地参与激活另一个神经元,那么两者之间的连接(ω)会得到加强。” 如下图所示。
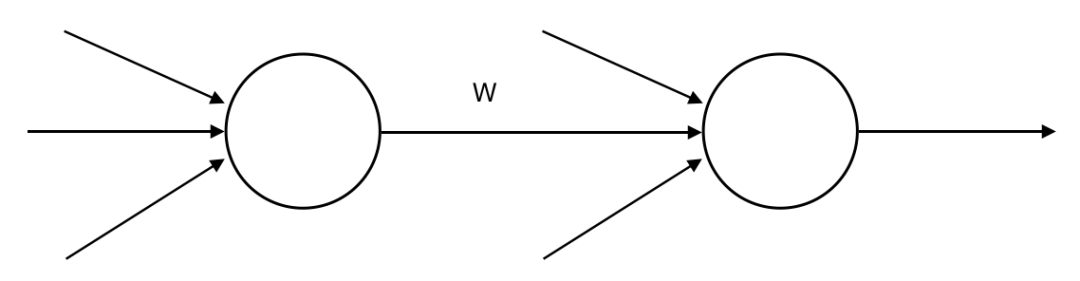
Hebb 学习规则,是一种人工神经网络中的无监督学习规则,通过调整神经元之间的连接权值(synaptic weights)来实现学习,而不需要外部提供数据样本的标签或答案。
权值调整公式如下图所示:Δωij 是权重的变化量,η 是学习率(控制权值更新的速度), xi 是前向神经元的输入,yj 是后向神经元的输出。
xi 是前向神经元和后向神经元连接之间的最初的输入、yj 是最后的输出、η 则由科学家设置、那么就可以求得 Δωij,即:学习的成果,是正向的、还是负向的,是习得了,还是消退了。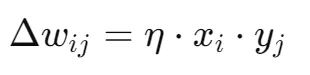
或等价形式: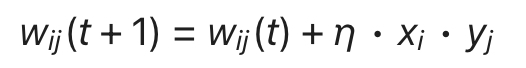
当两个神经元同时被激活(即前后神经元的激活值都很高)时,其连接权值 ω 就会增加。
Hebb 学习的结果是使网络能够提取训练集的统计特性,从而把输入信息按照它们的相似性程度划分为若干类。这一点与人类观察和认识世界的过程非常吻合,人类观察和认识世界在相当程度上就是在根据事物的统计特征进行分类。比如:喝水是神经元 A,打雷是神经元 B,喝水与打雷如果经常发生,我们会把这两件事归类成某种关联,即便我们还不清楚有什么关联。
1958 年:感知机模型(Perceptron)
1958 年,美国心理学家和计算机科学家弗兰克·罗森布拉特(Frank Rosenblatt)在康奈尔航空实验室(Cornell Aeronautical Laboratory)基于 MP 模型和 Hebb 学习率的基础上开发了一种新的感知机模型(Perceptron),这是世界上第一个具有学习能力的人工神经网络。
罗森布拉特还基于 IBM 704 计算机开发了一台名为 “Mark I” 的设备,是世界上第一个神经网络硬件,美国海军研究办公室甚至将 Mark I 称为 “第一台能够拥有人类思想的机器”。
如下图所示,罗森布拉特将一系列打孔卡输入到 Mark I 中,然后经过 50 次学习后,Mark I 学会了区分带有 “左侧标记的卡片” 和 “右侧标记的卡片”。换句话说,这台机器学会了 “分类”,如同孩子在父母的教导下学会分辨猫和狗一样。
分类能力是早期人工智能领域的一个重要研究!

训练和推理范式
感知机模型受到 MP 模型的启发,是专为图像识别而设计的,并添加了额外的机器学习机制。
所以,和 MP 模型一样,感知机模型也是一个应用于线性分类场景的 “二分类” 分类器,训练的目标是找到一个超平面(例如:在二维空间中的超平面是一条直线),来将特征空间中的样本分为两类。例如:当我们输入一个图片的特征向量 x_i,感知机就可以判断这个图片属于类型 I 还是类型 II。
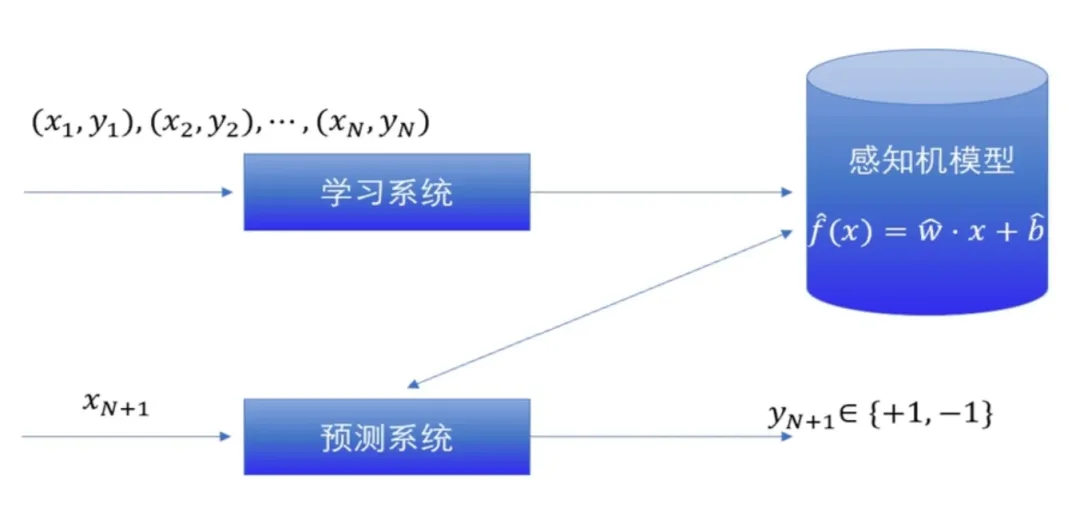
感知机模型作为神经网络的雏形建立了 “训练和推理” 的 AI 应用范式。如下图所示,学习系统即训练,预测系统即推理。通过大量的训练后,感知机模型就可用于二分类。
- 训练阶段:旨在调整模型的权重参数和偏置量参数,使得模型能够正确分类训练数据;
- 预测阶段:使用训练好的模型对新数据进行分类。
二分类模型应用场景
- 邮件垃圾分类:使用感知机分类器区分垃圾邮件和正常邮件。特征可以包括邮件的单词频率、发送时间等。
- 信用卡欺诈检测:使用感知机模型检测信用卡交易中的欺诈行为。特征可以包括交易金额、时间、地点等。
- 图像边缘检测:使用感知机检测图像中的边缘和线条。通过对像素值的特征提取,感知机可以识别图像中的直线边缘。
- 市场营销中的客户分类:使用感知机将客户分类为潜在客户和非潜在客户。特征可以包括客户的购买历史、浏览行为、人口统计数据等。
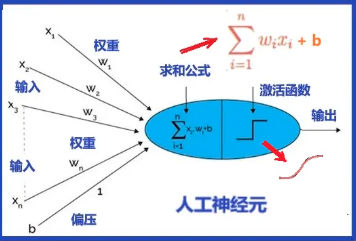
数学模型:单层神经网络
2 层神经元
如下图所示,感知机模型由 2 层神经元组成,具备神经元之间的学习条件。在 MP 模型的 “输入” 位置增加了神经元节点,称为 “输入单元”。因此,感知机模型拥有有 2 个层次,分别是:
- 输入层:输入单元只负责传输数据,并不做计算。
- 计算 & 输出层:输出单元则根据输入层的输入来进行计算。
由于感知机只有 1 个计算层,所以属于单层神经网络。

感知机的数学公式如下: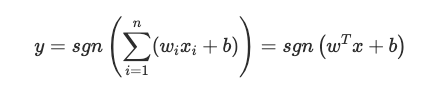
- 输入 xi:实数值向量,支持连续数据。
- 权重 ωi:可训练参数,通过误分类驱动调整。
- 偏置项 b:替代 MP 模型的 θ 阈值参数,允许超平面平移。MP 模型的公式中只有 θ 带有负号,看起来不协调。另外负号具有容易导致计算错误的缺点,因此将 -θ 替换为 +b。
- 输出 y:神经元激活函数计算的结果。
- 激活函数 sign():感知机使用符号函数,输出二值结果(-1 或 +1)。函数性质如下图所示:
- 当实参 >= 0 时,sgn() 返回 +1;
- 当实参 < 0 时,sgn() 返回 -1;
感知器的净输入,表示为 z: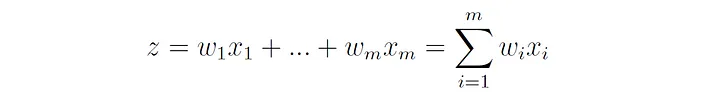
如果净输入超过某个预定义的阈值 0,则感知器激发(输出为 1),否则不激发(输出为 -1):
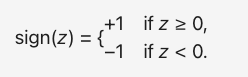
符号函数,其值对于负输入为 -1,非负输入为 1: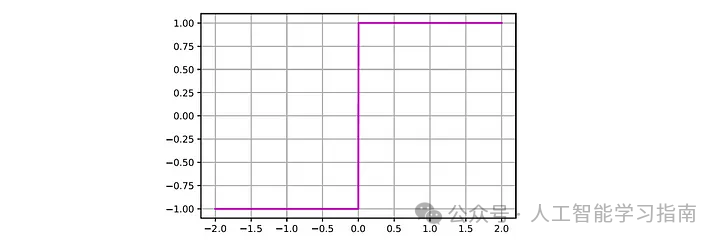
向量矩阵运算
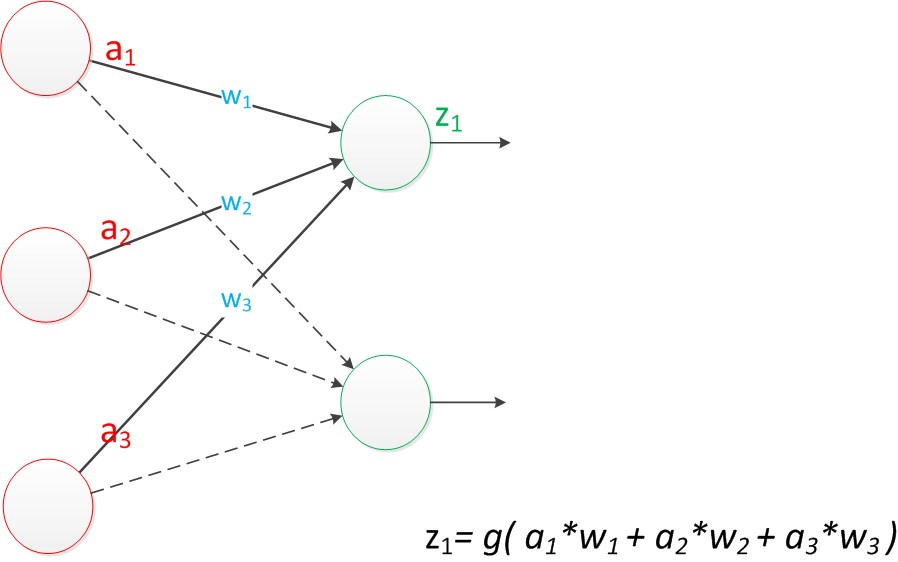
区别于 MP 模型,只能预测/输出一个数值,例如:1。感知机模型支持预测一个向量,例如:[2, 3]。要实现这个效果,只需要在输出层再增加一个 “输出单元”。如下图所示。
-
输出 z1 的计算公式
-
输出 z2 计算公式
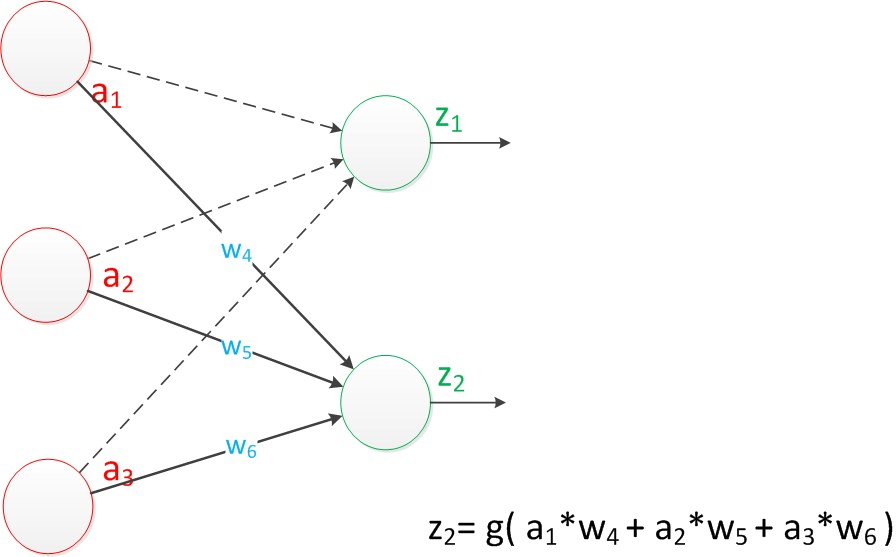
2 条计算公式的关键不同是权重参数 ωi,利用吴恩达(Andrew Ng)标记方式,可以将公式写成如下图所示。
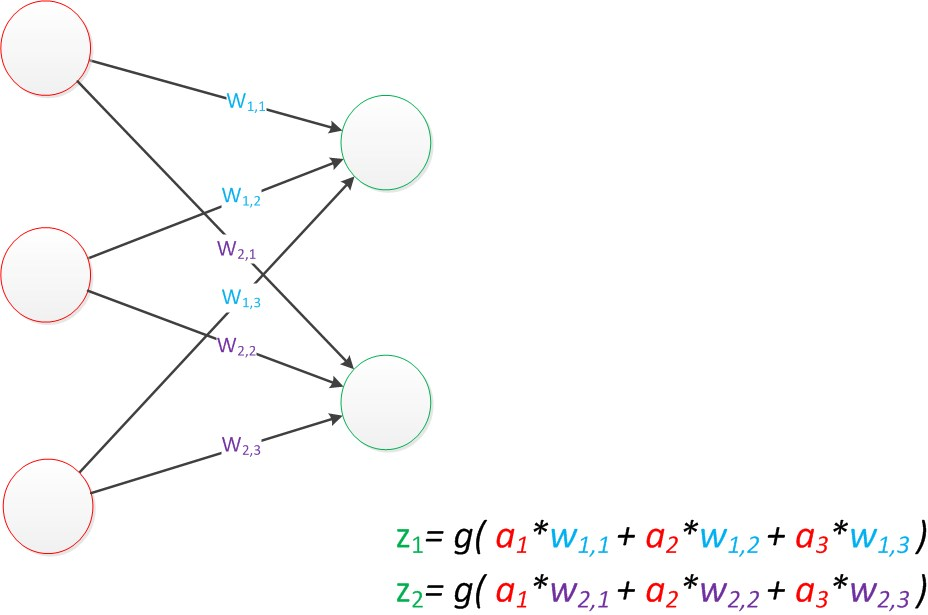
显然,这是一个线性代数方程组,因此可以使用矩阵乘法来表达这 2 个公式,并将公式简化为向量矩阵的形式:
z = g(W * a)
- 输入向量 a 是 [a1,a2,a3]T,表示由 a1,a2,a3 组成的列向量;
- 权重矩阵 W 是一个 2 行 3 列矩阵。
- 输出向量 z 是 [z1,z2]T;
例如:向量矩阵计算过程例如下图所示,B 为特征向量,A 为权重矩阵,得到输出向量为 z = [50, 122]T
综上,感知机数学模型的向量形式如下所示:
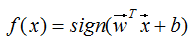
几何解释
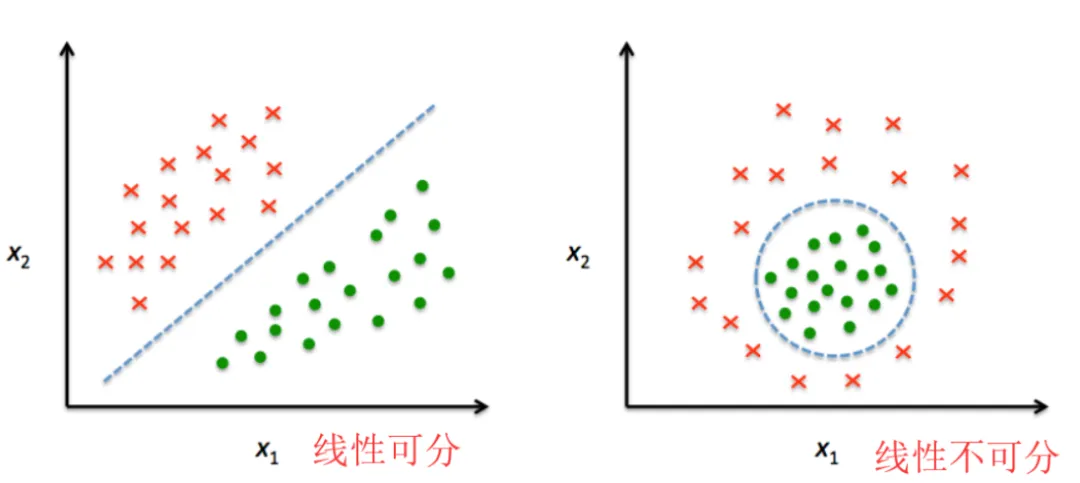
感知机二分类只适用于线性可分场景,即:用于训练的样本数据必须是线性可分的,即:可以找到一个能够将训练集的正实例点和负实例点完全分割开的超平面。
如下图所示,在二维特征空间中,训练样本的特征属性有 x1 和 x2 这两个,特征向量为 [x1 x2]T。而几何解析则为点 (x1, x2),超平面则是一条直线,这条直线也称为决策边界。当数据的维度是 3 时,就是划出一个平面,当数据的维度是 n 时,就是划出一个 n-1 维的超平面。
根据数学模型可知,当 w · x + b > 0 时,模型输出 y 为正类(+1);反之则为负类(-1)。因此,决策边界是模型输出 y 从正类切换为负类的临界点,即 w · x + b = 0(w、x 为向量矩阵)。
- 发向量 w 垂直于该超平面,因此决定其方向;
- 偏置 b 定义其距原点的距离。
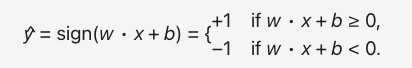
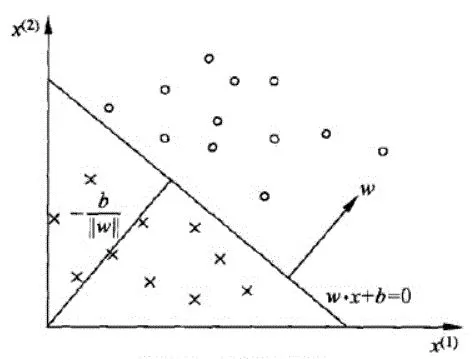
那么特征空间中的任意一个点到超平面的距离公式为:
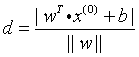
类比直角坐标系中的点到直线距离公式: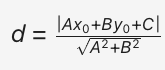
训练算法:误分类点损失函数 + 梯度下降优化方法
感知机中的 w、b 模型参数,也是通过训练来确定,若参数确定,则二分类模型也相应的确定。
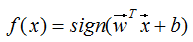
感知机的训练算法(学习机制)采用了 “基于误分类点的损失函数”,并利用 “梯度下降法优化方法” 来对损失函数进行极小化,最后通过多次迭代来找到 “总是” 能够正确分类(最优的)的模型参数。
损失函数
神经网络通过损失函数判断自己预测是否准确,损失函数是指导模型训练学习的关键。
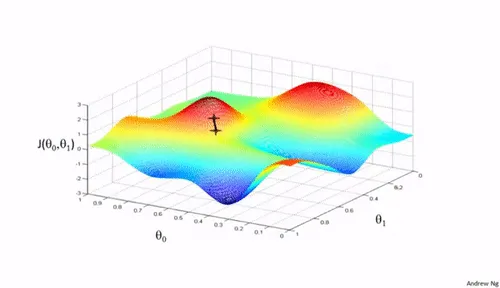
- 神经网络训练的本质:就是找到一个参数集合使得损失函数最小(即给定输入后,模型输出最逼近真实结果输出)。损失函数即预测值和实际值之差。如下图所示,典型损失函数呈漏斗型,且由 w 和 b 参数决定。
- 神经网络学习的本质:就是利用损失函数,来调节网络中的权重和阈值参数的过程。大脑对于事物的记忆分布式地存在于神经网络中,本质上神经元之间的 w、b 对应人脑中对于特定事物的 “记忆” 的具化。
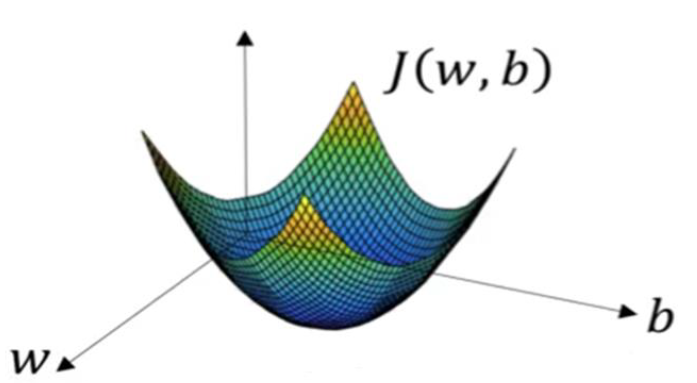
误分类点损失函数
感知机的目标是找到一个超平面,使得所有样本的分类错误最小。为了衡量模型的性能,需要定义一个损失函数。而传统的二分类损失函数(误分类点数)对权重 w 和偏置 b 的梯度计算不连续,不适合优化。因此,感知机采用的是 “所有误分类点到超平面的总距离” 的损失函数。
根据下图中的数学模型可知,当 y · z > 0 时,表示符合 sign() 函数,能够正确二分类。反之,如果 y · z < 0 时,那么这个样本就属于错误的分类,即误分类点。
误分类点的特征不等式如下所示:
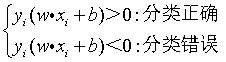
我们将误分类点函数作为损失函数来度量预测错误的程度,并对其进行极小化,即可得到正确分类点极大化的参数结果。
更进一步的,感知机采用误分类点到超平面总距离的定义。根据 “点到超平面距离公式” 和 “误分类点的特征不等式”,即可推导出 “误分类点到超平面距离”。然后对所有误分类点 xi 求和,即可得到 “所有误分类点到超平面总距离 d”。
-
点到超平面距离公式
-
误分类点的特征不等式
-
所有误分类点到超平面总距离公式:(负号是为了表达求最小)
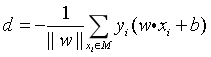
最后,由于 ||w|| 是权重向量的范数,为常数,不影响损失函数的相对大小,因此可以不考虑系数 ||w||,这便得到了 “误分类点损失函数”: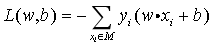
其中 xi 是第 i 个训练样本向量、yi 是第 i 个样本的真实标签(-1 或 1),均为已知参数,训练后输出梯度 w 权重向量矩阵和 b。
梯度下降优化算法
梯度下降(Gradient Descent)的概念来源于微积分中的优化问题。18 世纪,数学家们开始通过微积分来研究函数的极值问题,微积分的发展为梯度下降提供了理论基础。20 世纪,随着计算机科学的发展,梯度下降作为 “数值优化方法” 的一部分(e.g. 求损失函数的最值),开始被广泛研究。现如今,梯度下降在多个领域中都有着广泛的应用,包括:训练线性回归、逻辑回归、神经网络等模型。
梯度下降算法的类型:
- 随机梯度下降(Stochastic Gradient Descent)使用单个样本计算梯度:每次迭代只使用一个样本计算梯度并更新参数,计算效率高但波动性强。其核心思想是通过 “随机性” 跳出局部最优,但需动态调整学习率以平衡收敛速度与稳定性。
- 批量梯度下降(Batch Gradient Descent)使用整个数据集计算梯度:使用全部数据计算梯度并更新参数,收敛稳定但计算成本高,适合小数据集。
- 小批量梯度下降(Mini-batch Gradient Descent)使用小批量样本计算梯度:结合 BGD 与 SGD 的优点,使用小批量数据计算梯度并更新参数,成为现代深度学习的主流方法。
基本概念
- 损失函数(Loss Function):衡量模型预测值(推理)与实际值(训练)之间的差异的函数,梯度下降的目标是最小化损失函数。
- 梯度(Gradient):是损失函数关于参数的导数(代数用于描述函数自变量和因变量之间的变化率),指示了损失函数最陡峭下降的方向。
- 导数:在单变量函数(一元函数)中,梯度与导数的本质是统一的。导数表示函数在某一点的瞬时变化率(即切线斜率),其物理意义是函数值随自变量变化的快慢和方向。
- 学习率(Learning Rate):控制每次迭代的步长的参数。如果步长太小,算法收敛速度会非常缓慢;而如果步长太大,则可能导致算法无法收敛,甚至在最小值附近振荡。
对于任意函数,方向导数表示函数在某一方向上的变化率。梯度方向的物理意义就是函数值 y 增长最快的方向,相对的,梯度的反方向就是函数值下降最快的方向。梯度下降算法的本质就是往梯度的反方向前进(以最快速度求得损失函数的最小值),而学习率就指示了前进的步长,以此通过多轮的迭代来找到 loss 函数的极小值。
-
二维示意图
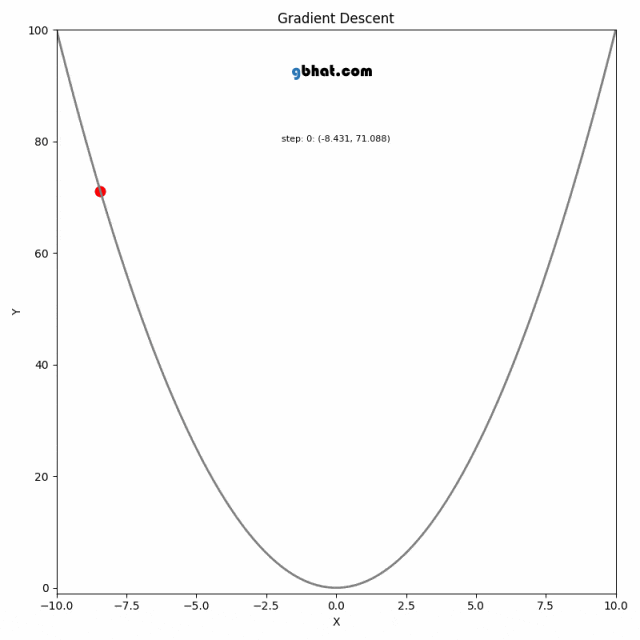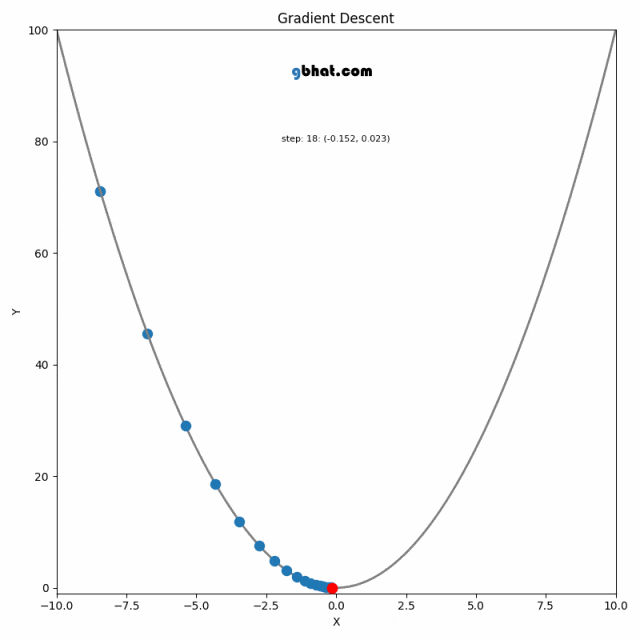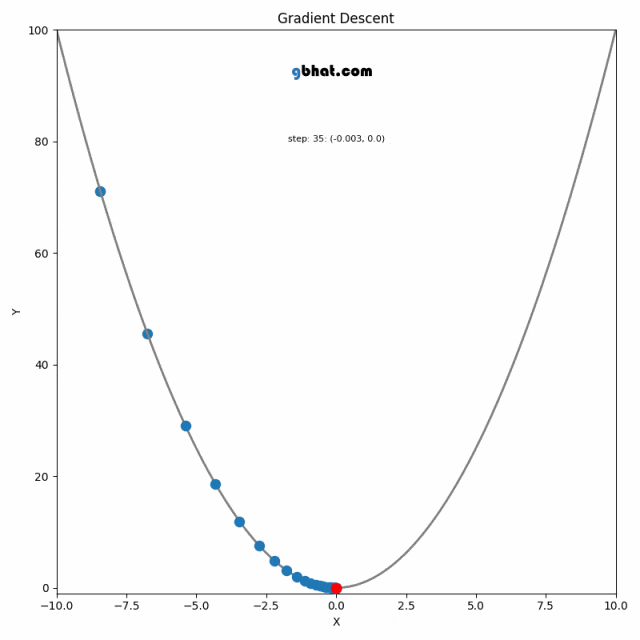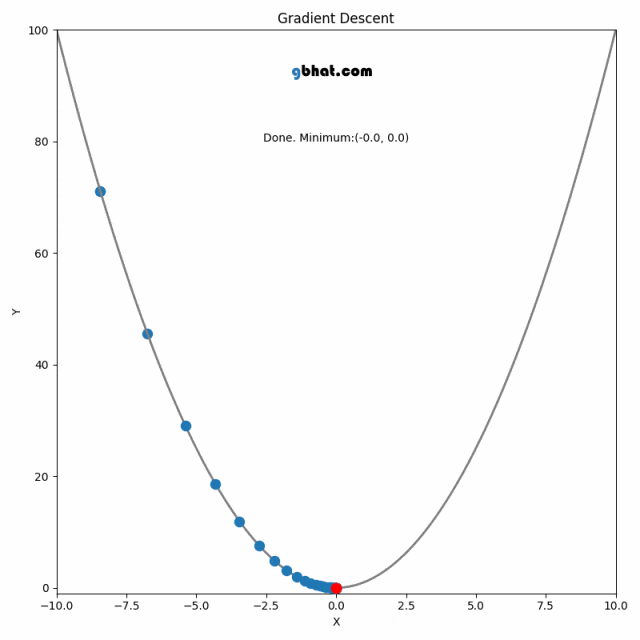
-
三维示意图
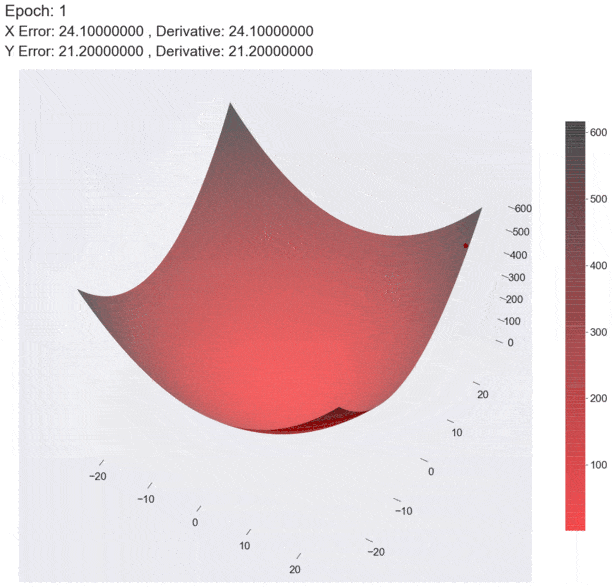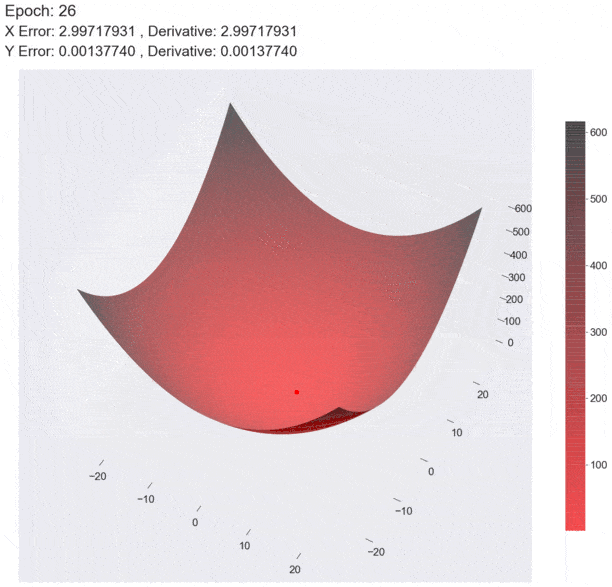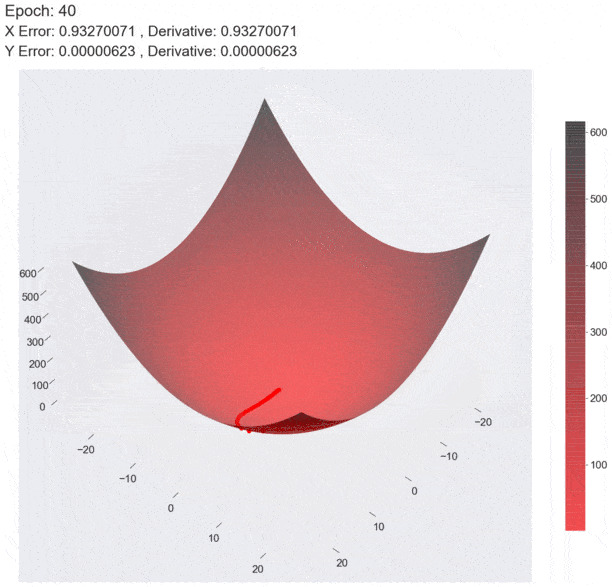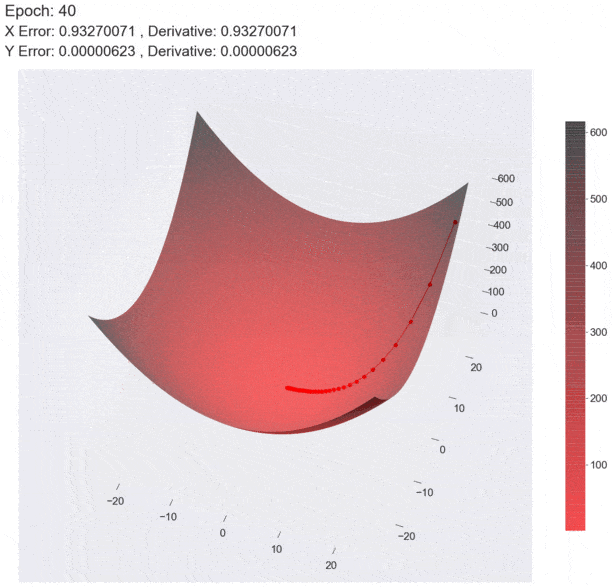
基本原理
梯度下降(Gradient Descent)是一种 “一阶求导最优化算法”,在 ML/AI 领域,梯度下降算法通过不断调整模型参数,使得 loss 损失函数的值逐渐减小,从而使模型逐步逼近最优解。
具体而言,梯度下降法通过计算 loss 损失函数与模型参数之间的梯度(一阶求导),然后沿着梯度的反方向逐步调整参数,以达到最小化损失函数的目的。
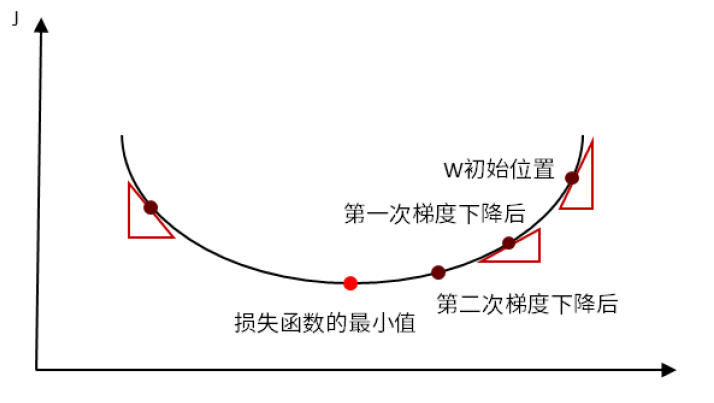
因为函数的梯度指向了函数值增长最快的方向,那么它的相反方向(即梯度的负方向)则是损失函数值减小最快的方向。并且,通过连续的小步长(学习率)沿着负梯度方向移动,最终就可以到达函数的一个局部最小点(直到梯度接近零时截止),从而实现模型参数的优化。如下图所示。
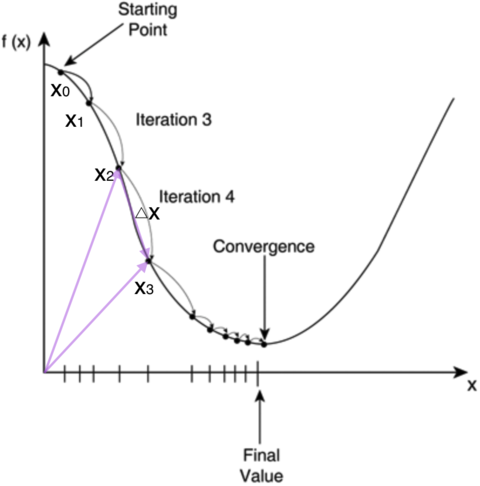
数学公式

NOTE:上图中模型参数,指的是权重参数。公式的内涵是基于梯度下降,以损失函数最小化,倒逼求出预测效果最好的权重参数。
几何解释
在几何上,梯度下降可以被形象地理解为一个在山谷中寻找最低点的人:
- 当前位置的梯度指示了最陡峭的下山方向。
- 学习率决定了每一步的步长。
- 每次迭代都沿着当前最陡下降方向移动一定距离。
- 直到到达一个梯度接近零的点(也可能是局部最低点)。
神经网络应用梯度下降算法来调整参数
在神经网络的训练过程中,梯度下降法起到了至关重要的作用。神经网络的训练过程本质上就是一个通过梯度下降法优化损失函数的过程。具体步骤如下:
- 计算当前参数下的模型输出和损失函数值。
- 计算损失函数相对于模型参数的梯度。
- 使用梯度下降法更新模型参数。
这个过程会反复进行,直到损失函数的值收敛到某个最小值。
梯度下降参数调整
-
计算当前参数下的模型输出和损失函数值。其中,M 表示所有当前误分类样本的集合。
-
计算损失函数相对于模型参数的梯度 ∇L(损失函数对模型参数进行一阶求导)。要使损失函数极小化,首先来计算函数的梯度,分别对 w 和 b 参数求损失函数的偏导,得到 w 和 b 的梯度(一阶求导公式)。
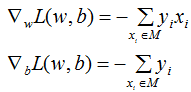
-
使用梯度下降法更新模型参数。随机梯度下降算法(SGD)选取一个误分类点 (xi, yi),设步长为 0<η ≤1(学习率),控制每次更新中的权重调整量(梯度迭代步长)。确定学习率之后,沿负梯度方向迭代更新参数 w 和 b。
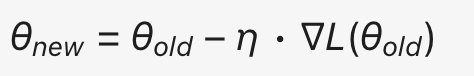
将 w、b 的梯度带入梯度更新公式得到 w、b 的梯度更新公式。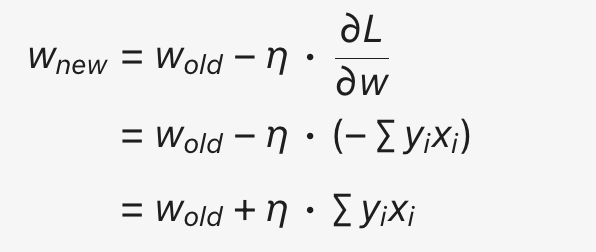
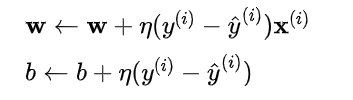
由于 L 损失函数是非负数的,因此,一直迭代下去,使损失函数不断减小,直至为 0,便得到最优解,即训练结束,得到了模型即为权重参数。
几何解释
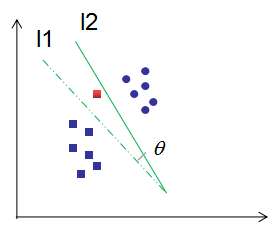
如下图所示,当存在误分类点时,调整 w、b,向误分类点方向修正权重,使超平面向误分类点方向移动,以减少误分类点与超平面距离。例如:红色框为误分类点,l1 为决策边界,随机梯度下降法使 l1 直线顺时针旋转角度为 l2 直线,点到分类直线的距离逐渐减小直到被正确分类。
- 权重调整:将 w 向误分类样本 xi 的方向调整,使得 w⋅xi 增大(或减小),从而改变超平面的方向。
- 偏置调整:平移超平面,使样本点被正确分类。
有监督学习
- 有监督学习:指利用标注好了标签的数据样本来训练模型,使模型能够准确地将 “新的输入” 映射到 “预期的输出(标签)”。更具体的,有监督学习能够训练找出一个最优的权重 w₁, …, wₘ 参数和偏置量 b 参数,使得模型能够正确地将新的输入 x₁, …, xₘ(特征向量)映射到预期的输出 y(代表标签)。
- 无监督学习:指的是训练数据中不包含标签信息,模型需要自行发现数据的内在结构和模式。
应用示例:用感知器实现 AND 逻辑门

1)逻辑门(AND 门)的感知器模型
AND 逻辑门函数有 2 个二进制输入 x1、x2,当且仅当 2 个输入都为真时返回真(1),否则返回假(-1)。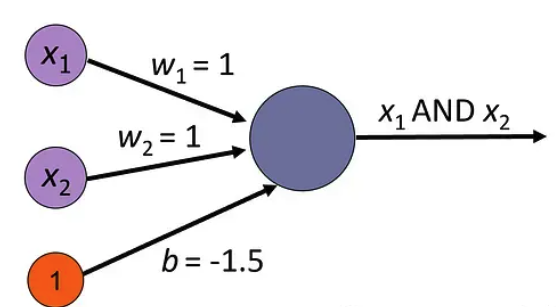
2)输入训练数据集和学习率
有监督训练数据集如下所示。
| 训练样本 | 特征属性输入 x1 | 特征属性输入 x2 | 输出 y(标签) |
|---|---|---|---|
| 1 | 0 | 0 | -1 |
| 2 | 0 | 1 | -1 |
| 3 | 1 | 0 | -1 |
| 4 | 1 | 1 | 1 |
3)迭代训练步骤流程
-
初始化权重 w = [w0, w1] = [0, 0]
-
初始化偏差 b = 0
-
设定学习率 η=1
-
激活函数:符号函数 sign(z),输出 ±1
-
模型输出计算公式:
-
损失函数计算公式(下列公式只有对误分类点才需要计算),M 为误分类点的集合,w 为当前权重向量,x_i 为输入的误分类点样本向量的编号(而不是样本 x 的特征编号),y_i 为对应的样本标签(期望值):
-
w、b 参数相对于损失函数的梯度计算公式:
-
w、b 参数更新计算公式:
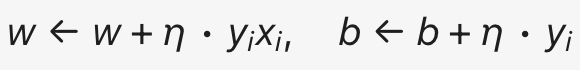
第一轮迭代
样本 1(x = [0, 0], y = -1)
- 净输入计算:z = w_newTx + b_new = 0 ⋅ 0 + 0 ⋅ 0 + 0 = 0
- 模型输出计算:y hat = sign(z) = +1
- 误分类判断:y hat 不等于 y,识别为误分类点
- 损失函数计算(非必须,因为梯度就包含了损失函数的意义):L(w, b) = (-1) ⋅ y ⋅ z = (-1) ⋅ (-1) ⋅ 0 = 0
- 梯度计算:
- ∇w = (−1) ⋅ y ⋅ x = (-1) ⋅ (-1) ⋅ [0, 0] = [0, 0]
- ∇b = (-1) ⋅ y = (-1) ⋅ (-1) = 1
- 参数更新计算(梯度下降):
- w_new = w_old + η ⋅ (-∇w) = [0, 0] + 1 ⋅ (-1) ⋅ [0, 0] = [0, 0]
- b_new = b_old + η ⋅ (-∇b) = 0 + 1 ⋅ (-1) ⋅ 1 = -1
样本 2(x = [0, 1], y = -1)
- 净输入计算:z = w_newTx + b_new = 0 ⋅ 0 + 0 ⋅ 1 + (-1) = -1
- 模型输出计算:y hat = sign(z) = -1
- 误分类判断:y hat 等于 y,识别为正确分类点,无需更新 w、b 参数。
样本 3(x = [1, 0], y = -1)
- 净输入计算:z = w_newTx + b_new = 0 ⋅ 1 + 0 ⋅ 0 + (-1) = -1
- 模型输出计算:y hat = sign(z) = -1
- 误分类判断:y hat 等于 y,识别为正确分类点,无需更新 w、b 参数。
样本 4(x = [1, 1], y = +1)
- 净输入计算:z = w_newTx + b_new = 0 ⋅ 1 + 0 ⋅ 1 + (-1) = -1
- 模型输出计算:y hat = sign(z) = -1
- 误分类判断:y hat 不等于 y,识别为误分类点
- 损失函数计算:L(w, b) = (-1) ⋅ y ⋅ z = (-1) ⋅ 1 ⋅ (-1) = 1
- 梯度计算:
- ∇w = (−1) ⋅ y ⋅ x = (-1) ⋅ 1 ⋅ [1, 1] = [-1, -1]
- ∇b = (-1) ⋅ y = (-1) ⋅ 1 = -1
- 参数更新计算(梯度下降):
- w_new = w_old + η ⋅ (-∇w) = [0, 0] + 1 ⋅ (-1) ⋅ [-1, -1] = [1, 1]
- b_new = b_old + η ⋅ (-∇b) = -1 + 1 ⋅ (-1) ⋅ (-1) = 0
本轮误分类样本数为:2(样本 1、4)。
第二轮迭代
样本 1(x = [0, 0], y = -1)
- 净输入计算:z = w_newTx + b_new = 1 ⋅ 0 + 1 ⋅ 0 + 0 = 0
- 模型输出计算:y hat = sign(z) = +1
- 误分类判断:y hat 不等于 y,识别为误分类点
- 损失函数计算:L(w, b) = (-1) ⋅ y ⋅ z = (-1) ⋅ (-1) ⋅ 0 = 0
- 梯度计算:
- ∇w = (−1) ⋅ y ⋅ x = (-1) ⋅ (-1) ⋅ [0, 0] = [0, 0]
- ∇b = (-1) ⋅ y = (-1) ⋅ (-1) = 1
- 参数更新计算(梯度下降):
- w_new = w_old + η ⋅ (-∇w) = [1, 1] + 1 ⋅ (-1) ⋅ [0, 0] = [1, 1]
- b_new = b_old + η ⋅ (-∇b) = 0 + 1 ⋅ (-1) ⋅ 0 = -1
样本 2(x = [0, 1], y = -1)
- 净输入计算:z = w_newTx + b_new = 1 ⋅ 0 + 1 ⋅ 1 + 0 = 1
- 模型输出计算:y hat = sign(z) = +1
- 误分类判断:y hat 不等于 y,识别为误分类点
- 损失函数计算:L(w, b) = (-1) ⋅ y ⋅ z = (-1) ⋅ (-1) ⋅ 1 = 1
- 梯度计算:
- ∇w = (−1) ⋅ y ⋅ x = (-1) ⋅ (-1) ⋅ [0, 1] = [0, 1]
- ∇b = (-1) ⋅ y = (-1) ⋅ (-1) = 1
- 参数更新计算(梯度下降):
- w_new = w_old + η ⋅ (-∇w) = [1, 1] + 1 ⋅ (-1) ⋅ [0, 1] = [1, 0]
- b_new = b_old + η ⋅ (-∇b) = -1 + 1 ⋅ (-1) ⋅ 1 = -2
样本 3(x = [1, 0], y = -1)
- 净输入计算:z = w_newTx + b_new = 1 ⋅ 1 + 0 ⋅ 0 + (-2) = -1
- 模型输出计算:y hat = sign(z) = -1
- 误分类判断:y hat 等于 y,识别为正确分类点,无需更新参数
样本 4(x = [1, 1], y = +1)
- 净输入计算:z = w_newTx + b_new = 1 ⋅ 1 + 0 ⋅ 1 + (-2) = -1
- 模型输出计算:y hat = sign(z) = -1
- 误分类判断:y hat 不等于 y,识别为误分类点
- 损失函数计算:L(w, b) = (-1) ⋅ y ⋅ z = (-1) ⋅ 1 ⋅ (-1) = 1
- 梯度计算:
- ∇w = (−1) ⋅ y ⋅ x = (-1) ⋅ 1 ⋅ [1, 1] = [-1, -1]
- ∇b = (-1) ⋅ y = (-1) ⋅ 1 = -1
- 参数更新计算(梯度下降):
- w_new = w_old + η ⋅ (-∇w) = [1, 0] + 1 ⋅ (-1) ⋅ [-1, -1] = [2, 1]
- b_new = b_old + η ⋅ (-∇b) = -2 + 1 ⋅ (-1) ⋅ (-1) = -1
第 N 轮迭代
经过多轮调整,最终收敛到参数:
- w = [3, 2]
- b = -5
- 推理(预测)模型为:f(x_i) = sign([3,2]Tx_i + (-5))
4)推理
使用训练好的 AND 逻辑门感知器模型 f(x_i) = sign([3,2]Tx_i + (-5)) 来进行新数据样本的推理:
-
x_1 = (0, 0)
- z = [3, 2] ⋅ [1, 0] + (-5) = 3 ⋅ 0 + 2 ⋅ 0 - 5 = -5
- y hat = sign(z) = -1
- 被分类为 -1(False),符合 AND 逻辑门的预期输出。
-
x_2 = (0, 1)
- z = [3, 2] ⋅ [0, 1] + (-5) = 3 ⋅ 0 + 2 ⋅ 1 - 5 = -3
- y hat = sign(z) = -1
- 被分类为 -1(False),符合 AND 逻辑门的预期输出。
-
x_3 = (1, 0)
- z = [3, 2] ⋅ [1, 0] + (-5) = 3 ⋅ 1 + 2 ⋅ 0 - 5 = -2
- y hat = sign(z) = -1
- 被分类为 -1(False),符合 AND 逻辑门的预期输出。
-
x_4 = (1, 1)
- z = [3, 2] ⋅ [1, 1] + (-5) = 3 ⋅ 1 + 2 ⋅ 1 - 5 = 0
- y hat = sign(z) = +1
- 被分类为 +1(True),符合 AND 逻辑门的预期输出。
5)Python 编程示例
# -*- coding: utf-8 -*-
import numpy as np
class VerbosePerceptron:
def __init__(self, learning_rate=1, max_epochs=100):
self.weights = None
self.bias = 0
self.lr = learning_rate
self.max_epochs = max_epochs
def sign_activate(self, z):
return 1 if z >= 0 else -1 # 使用-1/+1标签
def fit(self, X, y, verbose=True):
n_features = X.shape[1]
self.weights = np.zeros(n_features)
epoch = 0
while epoch < self.max_epochs:
misclassified = 0
if verbose: print(f"\n=== Epoch {epoch+1} ===")
for i, (xi, yi) in enumerate(zip(X, y)):
z = np.dot(self.weights, xi) + self.bias
y_pred = self.sign_activate(z)
loss = max(0, -yi * z) # 合页损失函数
is_wrong = (y_pred != yi)
if verbose:
print(f"样本{i+1}: x={xi}, y={yi}")
print(f" 净输入 z = {self.weights}·{xi} + {self.bias} = {z:.1f}")
print(f" 预测 ŷ = sign({z:.1f}) = {y_pred}")
print(f" 误分类判断: {is_wrong}")
print(f" 损失值 L = max(0, -({yi}*{z:.1f})) = {loss:.1f}")
if is_wrong:
# 计算梯度
grad_w = -yi * xi
grad_b = -yi
# 参数更新
self.weights += self.lr * (-grad_w)
self.bias += self.lr * (-grad_b)
misclassified += 1
if verbose:
print(f" 梯度计算: ∇w = {grad_w}, ∇b = {grad_b}")
print(f" 参数更新: w = {self.weights - self.lr*grad_w} + {self.lr*(-grad_w)} = {self.weights}")
print(f" b = {self.bias - self.lr*grad_b} + {self.lr*(-grad_b)} = {self.bias}")
else:
if verbose: print(" 正确分类,不更新参数")
if misclassified == 0:
if verbose: print(f"第{epoch+1}轮后无误分类,训练终止")
break
epoch += 1
# 数据集(AND逻辑门)
X = np.array([[0,0], [0,1], [1,0], [1,1]])
y = np.array([-1, -1, -1, 1])
# 训练模型并打印详细过程
perceptron = VerbosePerceptron(learning_rate=1)
perceptron.fit(X, y, verbose=True)
# 输出最终参数
print("\n最终模型参数:")
print(f"权重 w = {perceptron.weights}, 偏置 b = {perceptron.bias}")
执行结果:
$ python3 perceptron.py
=== Epoch 1 ===
样本1: x=[0 0], y=-1
净输入 z = [ 0. 0.]·[0 0] + 0 = 0.0
预测 ŷ = sign(0.0) = 1
误分类判断: True
损失值 L = max(0, -(-1*0.0)) = 0.0
梯度计算: ∇w = [0 0], ∇b = 1
参数更新: w = [ 0. 0.] + [0 0] = [ 0. 0.]
b = -2 + -1 = -1
样本2: x=[0 1], y=-1
净输入 z = [ 0. 0.]·[0 1] + -1 = -1.0
预测 ŷ = sign(-1.0) = -1
误分类判断: False
损失值 L = max(0, -(-1*-1.0)) = 0.0
正确分类,不更新参数
样本3: x=[1 0], y=-1
净输入 z = [ 0. 0.]·[1 0] + -1 = -1.0
预测 ŷ = sign(-1.0) = -1
误分类判断: False
损失值 L = max(0, -(-1*-1.0)) = 0.0
正确分类,不更新参数
样本4: x=[1 1], y=1
净输入 z = [ 0. 0.]·[1 1] + -1 = -1.0
预测 ŷ = sign(-1.0) = -1
误分类判断: True
损失值 L = max(0, -(1*-1.0)) = 1.0
梯度计算: ∇w = [-1 -1], ∇b = -1
参数更新: w = [ 2. 2.] + [1 1] = [ 1. 1.]
b = 1 + 1 = 0
=== Epoch 2 ===
样本1: x=[0 0], y=-1
净输入 z = [ 1. 1.]·[0 0] + 0 = 0.0
预测 ŷ = sign(0.0) = 1
误分类判断: True
损失值 L = max(0, -(-1*0.0)) = 0.0
梯度计算: ∇w = [0 0], ∇b = 1
参数更新: w = [ 1. 1.] + [0 0] = [ 1. 1.]
b = -2 + -1 = -1
样本2: x=[0 1], y=-1
净输入 z = [ 1. 1.]·[0 1] + -1 = 0.0
预测 ŷ = sign(0.0) = 1
误分类判断: True
损失值 L = max(0, -(-1*0.0)) = 0.0
梯度计算: ∇w = [0 1], ∇b = 1
参数更新: w = [ 1. -1.] + [ 0 -1] = [ 1. 0.]
b = -3 + -1 = -2
样本3: x=[1 0], y=-1
净输入 z = [ 1. 0.]·[1 0] + -2 = -1.0
预测 ŷ = sign(-1.0) = -1
误分类判断: False
损失值 L = max(0, -(-1*-1.0)) = 0.0
正确分类,不更新参数
样本4: x=[1 1], y=1
净输入 z = [ 1. 0.]·[1 1] + -2 = -1.0
预测 ŷ = sign(-1.0) = -1
误分类判断: True
损失值 L = max(0, -(1*-1.0)) = 1.0
梯度计算: ∇w = [-1 -1], ∇b = -1
参数更新: w = [ 3. 2.] + [1 1] = [ 2. 1.]
b = 0 + 1 = -1
=== Epoch 3 ===
样本1: x=[0 0], y=-1
净输入 z = [ 2. 1.]·[0 0] + -1 = -1.0
预测 ŷ = sign(-1.0) = -1
误分类判断: False
损失值 L = max(0, -(-1*-1.0)) = 0.0
正确分类,不更新参数
样本2: x=[0 1], y=-1
净输入 z = [ 2. 1.]·[0 1] + -1 = 0.0
预测 ŷ = sign(0.0) = 1
误分类判断: True
损失值 L = max(0, -(-1*0.0)) = 0.0
梯度计算: ∇w = [0 1], ∇b = 1
参数更新: w = [ 2. -1.] + [ 0 -1] = [ 2. 0.]
b = -3 + -1 = -2
样本3: x=[1 0], y=-1
净输入 z = [ 2. 0.]·[1 0] + -2 = 0.0
预测 ŷ = sign(0.0) = 1
误分类判断: True
损失值 L = max(0, -(-1*0.0)) = 0.0
梯度计算: ∇w = [1 0], ∇b = 1
参数更新: w = [ 0. 0.] + [-1 0] = [ 1. 0.]
b = -4 + -1 = -3
样本4: x=[1 1], y=1
净输入 z = [ 1. 0.]·[1 1] + -3 = -2.0
预测 ŷ = sign(-2.0) = -1
误分类判断: True
损失值 L = max(0, -(1*-2.0)) = 2.0
梯度计算: ∇w = [-1 -1], ∇b = -1
参数更新: w = [ 3. 2.] + [1 1] = [ 2. 1.]
b = -1 + 1 = -2
=== Epoch 4 ===
样本1: x=[0 0], y=-1
净输入 z = [ 2. 1.]·[0 0] + -2 = -2.0
预测 ŷ = sign(-2.0) = -1
误分类判断: False
损失值 L = max(0, -(-1*-2.0)) = 0.0
正确分类,不更新参数
样本2: x=[0 1], y=-1
净输入 z = [ 2. 1.]·[0 1] + -2 = -1.0
预测 ŷ = sign(-1.0) = -1
误分类判断: False
损失值 L = max(0, -(-1*-1.0)) = 0.0
正确分类,不更新参数
样本3: x=[1 0], y=-1
净输入 z = [ 2. 1.]·[1 0] + -2 = 0.0
预测 ŷ = sign(0.0) = 1
误分类判断: True
损失值 L = max(0, -(-1*0.0)) = 0.0
梯度计算: ∇w = [1 0], ∇b = 1
参数更新: w = [ 0. 1.] + [-1 0] = [ 1. 1.]
b = -4 + -1 = -3
样本4: x=[1 1], y=1
净输入 z = [ 1. 1.]·[1 1] + -3 = -1.0
预测 ŷ = sign(-1.0) = -1
误分类判断: True
损失值 L = max(0, -(1*-1.0)) = 1.0
梯度计算: ∇w = [-1 -1], ∇b = -1
参数更新: w = [ 3. 3.] + [1 1] = [ 2. 2.]
b = -1 + 1 = -2
=== Epoch 5 ===
样本1: x=[0 0], y=-1
净输入 z = [ 2. 2.]·[0 0] + -2 = -2.0
预测 ŷ = sign(-2.0) = -1
误分类判断: False
损失值 L = max(0, -(-1*-2.0)) = 0.0
正确分类,不更新参数
样本2: x=[0 1], y=-1
净输入 z = [ 2. 2.]·[0 1] + -2 = 0.0
预测 ŷ = sign(0.0) = 1
误分类判断: True
损失值 L = max(0, -(-1*0.0)) = 0.0
梯度计算: ∇w = [0 1], ∇b = 1
参数更新: w = [ 2. 0.] + [ 0 -1] = [ 2. 1.]
b = -4 + -1 = -3
样本3: x=[1 0], y=-1
净输入 z = [ 2. 1.]·[1 0] + -3 = -1.0
预测 ŷ = sign(-1.0) = -1
误分类判断: False
损失值 L = max(0, -(-1*-1.0)) = 0.0
正确分类,不更新参数
样本4: x=[1 1], y=1
净输入 z = [ 2. 1.]·[1 1] + -3 = 0.0
预测 ŷ = sign(0.0) = 1
误分类判断: False
损失值 L = max(0, -(1*0.0)) = 0.0
正确分类,不更新参数
=== Epoch 6 ===
样本1: x=[0 0], y=-1
净输入 z = [ 2. 1.]·[0 0] + -3 = -3.0
预测 ŷ = sign(-3.0) = -1
误分类判断: False
损失值 L = max(0, -(-1*-3.0)) = 0.0
正确分类,不更新参数
样本2: x=[0 1], y=-1
净输入 z = [ 2. 1.]·[0 1] + -3 = -2.0
预测 ŷ = sign(-2.0) = -1
误分类判断: False
损失值 L = max(0, -(-1*-2.0)) = 0.0
正确分类,不更新参数
样本3: x=[1 0], y=-1
净输入 z = [ 2. 1.]·[1 0] + -3 = -1.0
预测 ŷ = sign(-1.0) = -1
误分类判断: False
损失值 L = max(0, -(-1*-1.0)) = 0.0
正确分类,不更新参数
样本4: x=[1 1], y=1
净输入 z = [ 2. 1.]·[1 1] + -3 = 0.0
预测 ŷ = sign(0.0) = 1
误分类判断: False
损失值 L = max(0, -(1*0.0)) = 0.0
正确分类,不更新参数
第6轮后无误分类,训练终止
最终模型参数:
权重 w = [ 2. 1.], 偏置 b = -3
1969 年:第一次十年 AI 寒冬:感知机模型线性分类的局限性
1969 年,MIT 的马文·闵斯基(Marvin Minsky)和 MIT 的另一位数学教授西摩·佩珀特(Seymour Papert)出了一本名为《感知机》(Perceptrons)的学术著作,从理论上证明感知机的缺陷。
感知机学习有一个严格的要求:训练数据必须线性可分。对于线性可分数据集,感知机训练算法能够收敛,即:经过有限次迭代,可以得到一个将训练数据集完全分割的超平面。但如果数据集线性不可分,感知机学习算法不收敛。
闵斯基认为感知器的缺陷是致命的,因为它无法模拟 “非线性可分” 函数,他举了一个逻辑门的例子:感知器不能区分 XOR 异或门。XOR 的特点是 2 个输入变量的输出结果是它们不同则为真(1),相同则为假(0)。如下图所示,只有一条决策边界(直线)的感知机显然无法二分类 XOR 在直角坐标系中的 4 个点。它是一个非线性问题。
- 线性分类:指存在一个线性方程可以把待分类数据分开。线性分类模型的核心思想是将输入特征和输出类别之间的关系建模为一个线性关系,从而实现对数据集的分类。常见的线性分类方法有感知机、最小二乘法(回归方程)等。
- 非线性分类:指不存在一个线性分类方程把数据分开。对于非线性可分的数据,一般的方法是先对数据进行空间映射,把数据映射到可以进行线性分类的空间中去,然后再用线性分类方法进行处理。
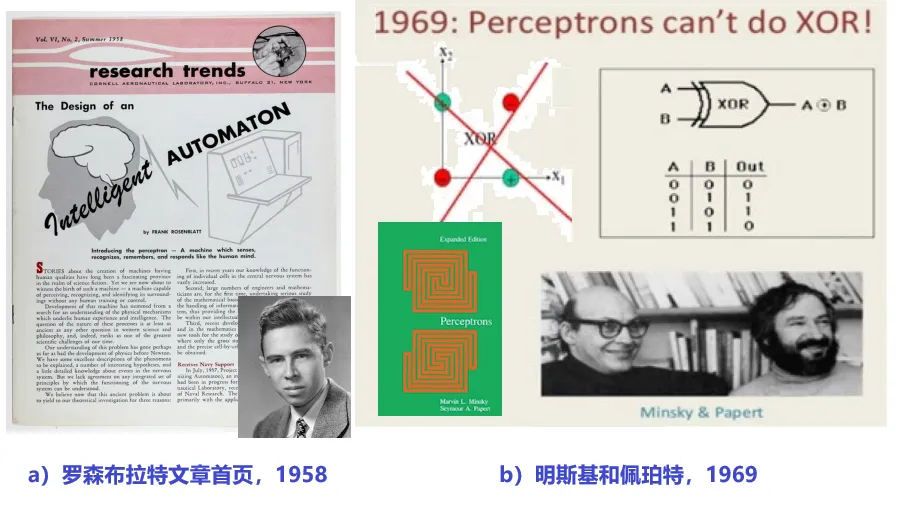
下图显示了 4 中基本逻辑门的情况,单层感知机可被用来区分其中的 3 种,包括:AND 逻辑与、NAND 逻辑与非和 OR 逻辑或。但是,无法模拟 XOR 逻辑异或函数,因为它属于线性不可分。
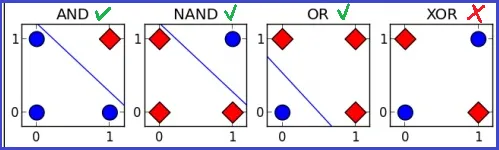
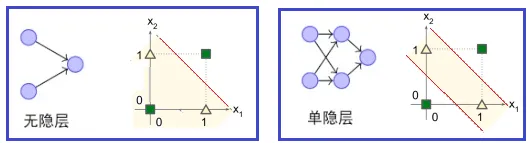
生物神经元是一个复杂的、动态的、非线性的系统,感知机显然无法实现。但实际上,那么也有人提出可以通过使用多层神经网络来解决非线性可分问题。即:在感知机的输出层与输入层之间,在添加一层隐藏层。隐藏层和输出层的神经元都是拥有计算能力的计算层,所以也称为两层神经网络。
- 如下左图为单层神经网络,决策边界只生成一条直线,无法区别异或问题。
- 如下右图为两层神经网络,增加了一个带非线性激活函数的隐含层,有助于解决非线性可分问题。多了一个隐藏层相当于增加了一个空间维度,决策计算就能生成两条直线,可以区别异或问题了。
但如果将计算层增加到 2 层就需要解决 2 个关键问题:
- 计算量过大,当时的硬件设备不支持;
- 没有跨计算层级的 w、b 参数训练算法,当时的算法不支持。
所以,当时业界认为研究多层次神经网络是没有价值的,继而引发了第一次长达十年的 AI 寒冬。
在研究停顿了近 20 年以后,杰弗里·辛顿(Geoffrey Hinton)于 1986 年提出了适用于多层感知机(Multi-Layer Perception,MLP)的反向传播算法(BP 算法),并采用 Sigmoid 函数(S 型函数,用作激活函数,将变量映射到 0 和 1 之间)进行非线性映射,有效地解决了非线性分类和学习的问题。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)