Pytorch深度学习框架60天进阶学习计划 - 第54天 工业级部署实战(二)
Pytorch深度学习框架60天进阶学习计划 - 第54天 工业级部署实战(二)!如果文章对你有帮助,还请给个三连好评,感谢感谢!
Pytorch深度学习框架60天进阶学习计划 - 第54天 工业级部署实战(二)
欢迎回来!在第一部分中,我们已经了解了TorchServe的基础知识,并成功部署了一个简单的图像分类服务。现在,让我们深入探索更高级的部署技术和最佳实践,让你的模型服务更加强大、可靠和高效。拿好你的工具箱,我们要开始打造真正生产级别的模型服务了!
第二部分:高级部署策略与性能优化
14. TorchServe请求处理流程详解
在深入高级主题之前,让我们先详细了解TorchServe是如何处理一个请求的,这有助于我们理解后续的优化策略。
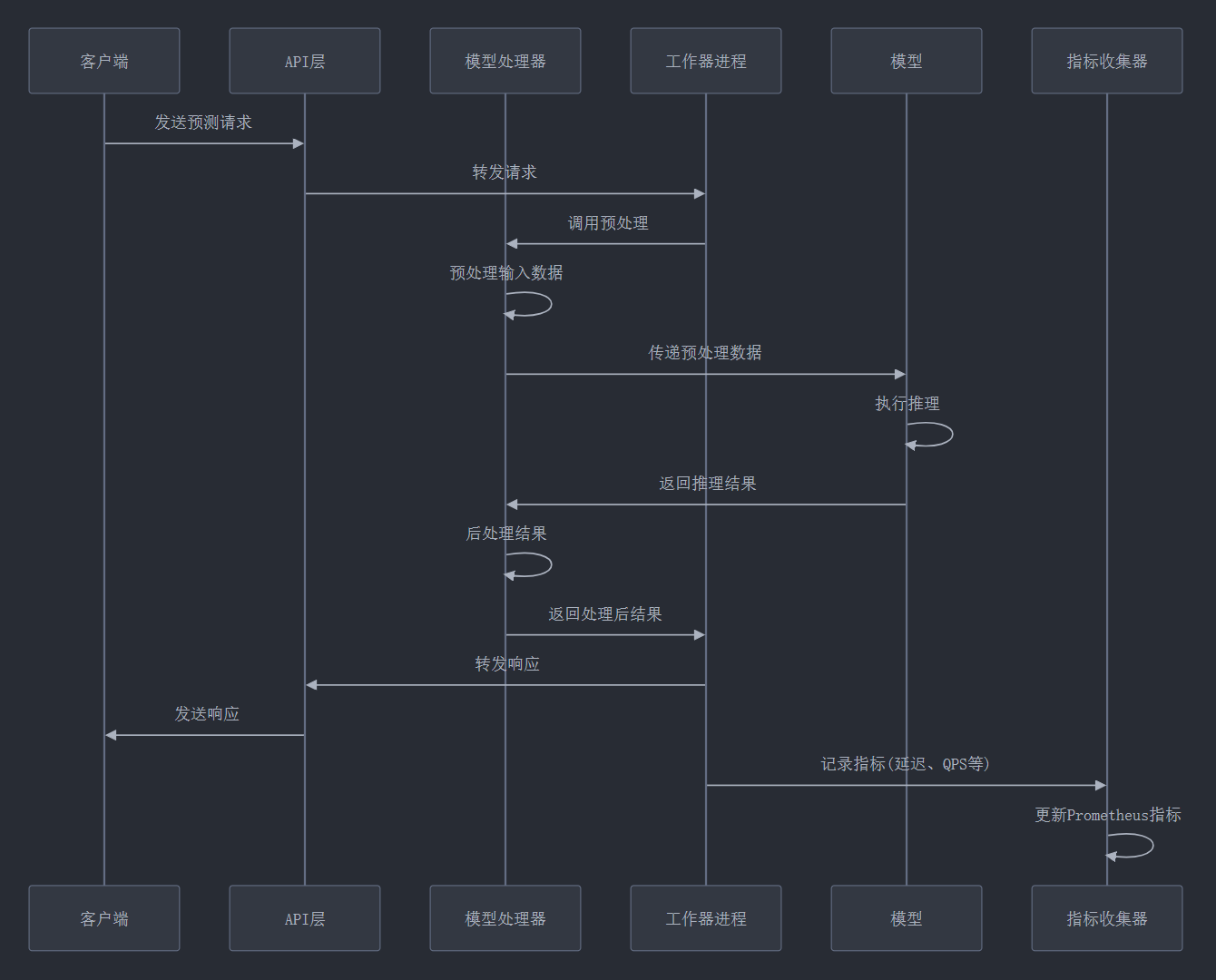
上图展示了TorchServe处理一个预测请求的完整流程。理解这个流程对于诊断性能问题和进行优化至关重要。
15. 分布式部署与负载均衡
在实际生产环境中,单个服务实例可能无法处理所有流量,我们需要进行分布式部署并配置负载均衡。
15.1 Docker容器化部署
首先,让我们创建一个Dockerfile来容器化我们的TorchServe服务:
# Dockerfile for TorchServe
FROM pytorch/torchserve:latest
# 安装额外的依赖
RUN pip install prometheus-client
# 复制模型文件和配置
WORKDIR /home/model-server
COPY ./model_store /home/model-server/model_store
COPY ./config.properties /home/model-server/config.properties
COPY ./index_to_name.json /home/model-server/index_to_name.json
# 暴露TorchServe的API端口
EXPOSE 8080 8081 8082
# 启动TorchServe
CMD ["torchserve", "--start", "--ncs", "--model-store=/home/model-server/model_store", "--ts-config=/home/model-server/config.properties"]
构建和运行Docker容器:
# 构建镜像
docker build -t torchserve-resnet .
# 运行容器
docker run -d --name torchserve-instance-1 -p 8080:8080 -p 8081:8081 -p 8082:8082 torchserve-resnet
15.2 使用Kubernetes进行分布式部署
对于大规模部署,我们可以使用Kubernetes来管理多个TorchServe实例。以下是一个简单的Kubernetes部署配置:
# torchserve-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: torchserve
labels:
app: torchserve
spec:
replicas: 3 # 部署3个副本
selector:
matchLabels:
app: torchserve
template:
metadata:
labels:
app: torchserve
spec:
containers:
- name: torchserve
image: torchserve-resnet:latest
ports:
- containerPort: 8080
name: inference
- containerPort: 8081
name: management
- containerPort: 8082
name: metrics
resources:
limits:
cpu: "2"
memory: "4Gi"
nvidia.com/gpu: 1 # 如果使用GPU
requests:
cpu: "1"
memory: "2Gi"
---
apiVersion: v1
kind: Service
metadata:
name: torchserve-service
spec:
selector:
app: torchserve
ports:
- name: inference
port: 8080
targetPort: 8080
- name: management
port: 8081
targetPort: 8081
- name: metrics
port: 8082
targetPort: 8082
type: LoadBalancer
应用Kubernetes配置:
kubectl apply -f torchserve-deployment.yaml
15.3 集成Ingress控制器进行路由
为了更灵活地管理路由,我们可以使用Kubernetes Ingress控制器:
# torchserve-ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: torchserve-ingress
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
rules:
- host: model-inference.example.com
http:
paths:
- path: /predictions
pathType: Prefix
backend:
service:
name: torchserve-service
port:
number: 8080
- host: model-management.example.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: torchserve-service
port:
number: 8081
16. 高级A/B测试策略
在第一部分中,我们已经介绍了基本的A/B测试设置。现在,让我们探索更高级的A/B测试策略。
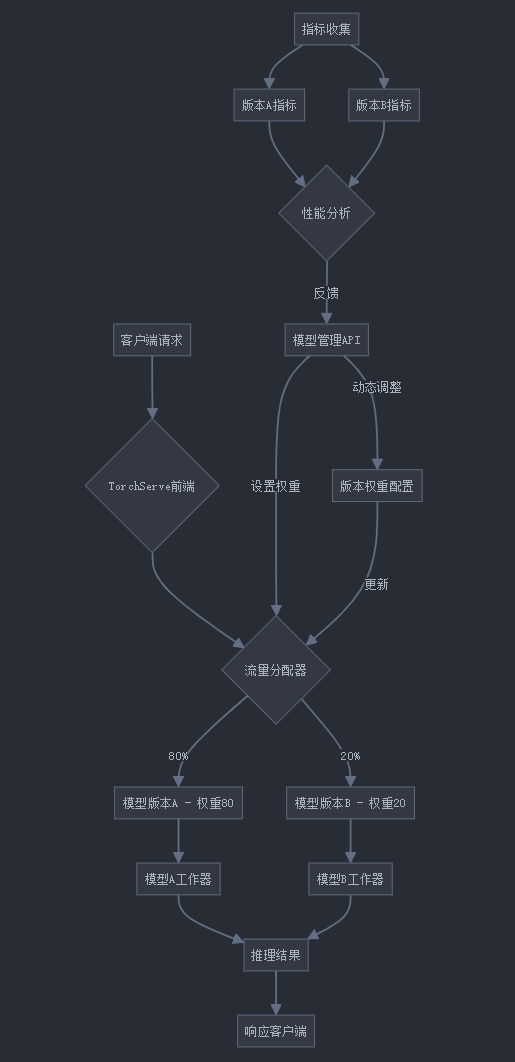
16.1 基于用户特征的A/B测试
在实际应用中,我们可能希望基于用户特征进行更精细的流量分配。以下是一个自定义处理程序,它可以根据用户ID或其他特征决定使用哪个模型版本:
# user_aware_handler.py
import json
import logging
import os
import hashlib
from PIL import Image
import io
import torch
from torchvision import transforms
import torch.nn.functional as F
logger = logging.getLogger(__name__)
def get_transform():
return transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
class_mapping = None
def initialize(context):
global class_mapping
# 加载类别映射
with open("index_to_name.json") as f:
class_mapping = json.load(f)
properties = context.system_properties
model_dir = properties.get("model_dir")
device = torch.device("cuda:" + str(properties.get("gpu_id")) if torch.cuda.is_available() else "cpu")
# 加载两个版本的模型
model_v1_path = os.path.join(model_dir, "resnet50_v1.pth")
model_v2_path = os.path.join(model_dir, "resnet50_v2.pth")
model_v1 = torch.load(model_v1_path, map_location=device)
model_v2 = torch.load(model_v2_path, map_location=device)
model_v1.eval()
model_v2.eval()
# 将模型保存到上下文中
context.model_v1 = model_v1
context.model_v2 = model_v2
context.device = device
# 设置默认A/B测试比例
context.v1_weight = 80
context.v2_weight = 20
logger.info("两个版本的模型加载完成")
def preprocess(data, context):
"""
预处理请求数据
"""
# 从请求中获取用户ID (假设以JSON格式提供)
user_id = None
metadata = context.get_request_header(0, "X-User-Data")
if metadata:
try:
user_data = json.loads(metadata)
user_id = user_data.get("user_id")
except:
logger.warning("无法解析用户数据")
# 处理图像
if len(data) > 0:
image_data = data[0]
image = Image.open(io.BytesIO(image_data))
image_tensor = get_transform()(image)
image_tensor = image_tensor.unsqueeze(0).to(context.device)
# 存储用户ID供后续决策使用
context.user_id = user_id
return image_tensor
else:
raise ValueError("请求中没有图像数据")
def inference(model_input, context):
"""
根据用户ID决定使用哪个模型版本
"""
user_id = getattr(context, "user_id", None)
# 基于用户ID决定使用哪个模型版本
if user_id:
# 使用哈希函数确保相同用户总是获得相同版本
hash_value = int(hashlib.md5(user_id.encode()).hexdigest(), 16) % 100
# 根据权重决定使用哪个版本
if hash_value < context.v1_weight:
model = context.model_v1
context.used_model = "v1"
else:
model = context.model_v2
context.used_model = "v2"
else:
# 如果没有用户ID,随机选择模型版本
import random
if random.randint(1, 100) <= context.v1_weight:
model = context.model_v1
context.used_model = "v1"
else:
model = context.model_v2
context.used_model = "v2"
# 进行推理
with torch.no_grad():
output = model(model_input)
probabilities = F.softmax(output, dim=1)
return probabilities
def postprocess(inference_output, context):
"""
处理模型输出并返回预测结果
"""
global class_mapping
# 获取top-5预测类别和概率
probabilities, indices = torch.topk(inference_output, 5)
result = {}
for i in range(5):
idx = indices[0, i].item()
prob = probabilities[0, i].item()
class_name = class_mapping.get(str(idx), f"Unknown class {idx}")
result[class_name] = float(prob)
# 添加使用的模型版本信息
result["model_version"] = getattr(context, "used_model", "unknown")
return [json.dumps(result)]
16.2 渐进式发布策略
在生产环境中,我们通常希望逐步增加新模型版本的流量比例,以降低风险。以下是一个Python脚本,可以实现渐进式发布:
# progressive_rollout.py
import requests
import time
import argparse
import logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger("progressive-rollout")
def update_model_weights(management_url, model_name, version_a, version_b, weight_a, weight_b):
"""更新模型版本的权重"""
# 更新版本A的权重
url_a = f"{management_url}/models/{model_name}?version={version_a}&weight={weight_a}"
response_a = requests.put(url_a)
# 更新版本B的权重
url_b = f"{management_url}/models/{model_name}?version={version_b}&weight={weight_b}"
response_b = requests.put(url_b)
if response_a.status_code == 200 and response_b.status_code == 200:
logger.info(f"成功更新权重: v{version_a}={weight_a}%, v{version_b}={weight_b}%")
return True
else:
logger.error(f"更新权重失败: {response_a.text}, {response_b.text}")
return False
def progressive_rollout(management_url, model_name, old_version, new_version,
initial_new_weight=5, target_new_weight=100, step=5, interval_minutes=60):
"""
渐进式发布新模型版本
Args:
management_url: TorchServe管理API URL
model_name: 模型名称
old_version: 旧版本号
new_version: 新版本号
initial_new_weight: 新版本初始权重百分比
target_new_weight: 新版本目标权重百分比
step: 每次增加的权重百分比
interval_minutes: 权重更新间隔(分钟)
"""
current_new_weight = initial_new_weight
logger.info(f"开始渐进式发布 {model_name} v{new_version}")
logger.info(f"初始权重: v{old_version}={100-initial_new_weight}%, v{new_version}={initial_new_weight}%")
logger.info(f"目标权重: v{old_version}={100-target_new_weight}%, v{new_version}={target_new_weight}%")
# 设置初始权重
if not update_model_weights(management_url, model_name, old_version, new_version,
100-current_new_weight, current_new_weight):
logger.error("初始权重设置失败,退出")
return False
# 逐步增加新版本权重
while current_new_weight < target_new_weight:
# 等待指定时间
logger.info(f"等待 {interval_minutes} 分钟后增加权重...")
time.sleep(interval_minutes * 60)
# 计算新权重
current_new_weight = min(current_new_weight + step, target_new_weight)
old_weight = 100 - current_new_weight
logger.info(f"更新权重: v{old_version}={old_weight}%, v{new_version}={current_new_weight}%")
# 更新权重
if not update_model_weights(management_url, model_name, old_version, new_version,
old_weight, current_new_weight):
logger.error("权重更新失败,退出")
return False
logger.info(f"渐进式发布完成! 最终权重: v{old_version}={100-target_new_weight}%, v{new_version}={target_new_weight}%")
return True
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="TorchServe渐进式发布工具")
parser.add_argument("--url", type=str, default="http://localhost:8081", help="TorchServe管理API URL")
parser.add_argument("--model", type=str, required=True, help="模型名称")
parser.add_argument("--old-version", type=str, required=True, help="旧版本号")
parser.add_argument("--new-version", type=str, required=True, help="新版本号")
parser.add_argument("--initial", type=int, default=5, help="新版本初始权重百分比")
parser.add_argument("--target", type=int, default=100, help="新版本目标权重百分比")
parser.add_argument("--step", type=int, default=5, help="每次增加的权重百分比")
parser.add_argument("--interval", type=int, default=60, help="权重更新间隔(分钟)")
args = parser.parse_args()
progressive_rollout(
args.url, args.model, args.old_version, args.new_version,
args.initial, args.target, args.step, args.interval
)
使用方法:
# 启动渐进式发布,初始5%流量到新版本,每小时增加5%,最终100%流量到新版本
python progressive_rollout.py --model resnet --old-version 1.0 --new-version 2.0 --initial 5 --target 100 --step 5 --interval 60
16.3 基于性能指标的自动调整
我们可以进一步优化A/B测试,通过监控性能指标自动调整流量分配。以下脚本可以根据指标自动决定流量分配:
# auto_traffic_adjustment.py
import requests
import time
import argparse
import logging
import json
from prometheus_client.parser import text_string_to_metric_families
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger("auto-traffic-adjustment")
def get_model_metrics(metrics_url, model_name, version):
"""获取指定模型版本的性能指标"""
response = requests.get(f"{metrics_url}/metrics")
if response.status_code != 200:
logger.error(f"获取指标失败: {response.status_code}")
return None
# 解析Prometheus格式的指标
metrics = {}
for family in text_string_to_metric_families(response.text):
for sample in family.samples:
# 过滤出特定模型版本的指标
if ('model_name' in sample.labels and
sample.labels['model_name'] == f"{model_name}_{version}"):
metrics[sample.name] = sample.value
return metrics
def update_model_weights(management_url, model_name, version_a, version_b, weight_a, weight_b):
"""更新模型版本的权重"""
# 更新版本A的权重
url_a = f"{management_url}/models/{model_name}?version={version_a}&weight={weight_a}"
response_a = requests.put(url_a)
# 更新版本B的权重
url_b = f"{management_url}/models/{model_name}?version={version_b}&weight={weight_b}"
response_b = requests.put(url_b)
if response_a.status_code == 200 and response_b.status_code == 200:
logger.info(f"成功更新权重: v{version_a}={weight_a}%, v{version_b}={weight_b}%")
return True
else:
logger.error(f"更新权重失败: {response_a.text}, {response_b.text}")
return False
def auto_adjust_traffic(management_url, metrics_url, model_name, version_a, version_b,
check_interval=5, min_weight=5, max_weight=95):
"""
根据性能指标自动调整流量分配
Args:
management_url: TorchServe管理API URL
metrics_url: TorchServe指标API URL
model_name: 模型名称
version_a: 版本A
version_b: 版本B
check_interval: 检查间隔(分钟)
min_weight: 最小权重百分比
max_weight: 最大权重百分比
"""
while True:
# 获取两个版本的指标
metrics_a = get_model_metrics(metrics_url, model_name, version_a)
metrics_b = get_model_metrics(metrics_url, model_name, version_b)
if metrics_a is None or metrics_b is None:
logger.error("无法获取指标,等待下一次检查")
time.sleep(check_interval * 60)
continue
# 提取我们关心的指标
latency_a = metrics_a.get('ts_inference_latency_microseconds', float('inf'))
latency_b = metrics_b.get('ts_inference_latency_microseconds', float('inf'))
accuracy_a = metrics_a.get('model_accuracy', 0) # 假设有这样的指标
accuracy_b = metrics_b.get('model_accuracy', 0)
# 计算综合得分 (这里使用一个简单的加权公式,可以根据需要调整)
# 低延迟高准确率得高分
score_a = (1 / latency_a) * 0.3 + accuracy_a * 0.7
score_b = (1 / latency_b) * 0.3 + accuracy_b * 0.7
# 根据得分调整权重
total_score = score_a + score_b
if total_score > 0:
weight_a = max(min(int(score_a / total_score * 100), max_weight), min_weight)
weight_b = 100 - weight_a
logger.info(f"性能得分: v{version_a}={score_a:.4f}, v{version_b}={score_b:.4f}")
logger.info(f"调整权重: v{version_a}={weight_a}%, v{version_b}={weight_b}%")
# 更新权重
update_model_weights(management_url, model_name, version_a, version_b, weight_a, weight_b)
# 等待下一次检查
time.sleep(check_interval * 60)
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="TorchServe自动流量调整工具")
parser.add_argument("--mgmt-url", type=str, default="http://localhost:8081", help="TorchServe管理API URL")
parser.add_argument("--metrics-url", type=str, default="http://localhost:8082", help="TorchServe指标API URL")
parser.add_argument("--model", type=str, required=True, help="模型名称")
parser.add_argument("--version-a", type=str, required=True, help="版本A")
parser.add_argument("--version-b", type=str, required=True, help="版本B")
parser.add_argument("--interval", type=int, default=5, help="检查间隔(分钟)")
parser.add_argument("--min-weight", type=int, default=5, help="最小权重百分比")
parser.add_argument("--max-weight", type=int, default=95, help="最大权重百分比")
args = parser.parse_args()
auto_adjust_traffic(
args.mgmt_url, args.metrics_url, args.model, args.version_a, args.version_b,
args.interval, args.min_weight, args.max_weight
)
17. 高级性能监控
在第一部分中,我们已经介绍了基本的指标监控。现在,让我们探索更全面的性能监控方案。
17.1 自定义指标收集
TorchServe允许我们收集自定义指标。以下是一个扩展处理程序,增加了自定义指标:
# custom_metrics_handler.py
import json
import logging
import os
import time
from PIL import Image
import io
import torch
from torchvision import transforms
import torch.nn.functional as F
logger = logging.getLogger(__name__)
def get_transform():
return transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
class_mapping = None
def initialize(context):
global class_mapping
# 加载类别映射
with open("index_to_name.json") as f:
class_mapping = json.load(f)
properties = context.system_properties
model_dir = properties.get("model_dir")
device = torch.device("cuda:" + str(properties.get("gpu_id")) if torch.cuda.is_available() else "cpu")
# 加载模型
model_path = os.path.join(model_dir, "resnet50.pth")
model = torch.load(model_path, map_location=device)
model.eval()
# 将模型保存到上下文中
context.model = model
context.device = device
# 初始化指标计数器
context.processed_requests = 0
context.error_requests = 0
context.avg_confidence = 0.0
context.batch_size_counts = {}
# 注册自定义指标
if hasattr(context, 'metrics'):
context.metrics.add_counter('processed_requests', 'Number of requests processed')
context.metrics.add_counter('error_requests', 'Number of requests with errors')
context.metrics.add_gauge('avg_confidence', 'Average confidence score for top prediction')
context.metrics.add_counter('requests_per_class', 'Number of requests per class', ['class'])
context.metrics.add_histogram('batch_size_distribution', 'Distribution of batch sizes')
logger.info("模型加载完成,自定义指标已初始化")
def preprocess(data, context):
"""
预处理请求数据
"""
start_time = time.time()
# 记录批大小
batch_size = len(data)
if hasattr(context, 'metrics'):
context.metrics.add_counter('processed_requests', batch_size)
context.metrics.add_histogram('batch_size_distribution', batch_size)
if batch_size > 0:
images = []
for image_data in data:
try:
# 读取图像文件
image = Image.open(io.BytesIO(image_data))
# 应用转换
image_tensor = get_transform()(image)
images.append(image_tensor)
except Exception as e:
if hasattr(context, 'metrics'):
context.metrics.add_counter('error_requests', 1)
logger.error(f"图像预处理错误: {e}")
raise
# 记录预处理时间
context.preprocess_time = time.time() - start_time
return torch.stack(images).to(context.device)
else:
if hasattr(context, 'metrics'):
context.metrics.add_counter('error_requests', 1)
raise ValueError("请求中没有图像数据")
def inference(model_input, context):
"""
对预处理后的数据执行推理
"""
start_time = time.time()
model = context.model
# 进行推理
with torch.no_grad():
output = model(model_input)
probabilities = F.softmax(output, dim=1)
# 记录推理时间
context.inference_time = time.time() - start_time
return probabilities
def postprocess(inference_output, context):
"""
处理模型输出并返回预测结果
"""
global class_mapping
start_time = time.time()
# 获取top-5预测类别和概率
probabilities, indices = torch.topk(inference_output, 5)
results = []
batch_size = probabilities.shape[0]
total_confidence = 0.0
for i in range(batch_size):
result = {}
# 获取第一个(最高置信度)预测
top_idx = indices[i, 0].item()
top_prob = probabilities[i, 0].item()
# 更新平均置信度
total_confidence += top_prob
# 记录每个类别的请求数
if hasattr(context, 'metrics') and class_mapping:
class_name = class_mapping.get(str(top_idx), f"unknown_{top_idx}")
context.metrics.add_counter('requests_per_class', 1, [class_name])
# 添加所有top-5预测到结果
for j in range(5):
idx = indices[i, j].item()
prob = probabilities[i, j].item()
if class_mapping:
class_name = class_mapping.get(str(idx), f"Unknown class {idx}")
else:
class_name = f"Class {idx}"
result[class_name] = float(prob)
# 添加时间信息
result["timing"] = {
"preprocess_ms": round(getattr(context, "preprocess_time", 0) * 1000, 2),
"inference_ms": round(getattr(context, "inference_time", 0) * 1000, 2),
"postprocess_ms": 0 # 将在处理结束时更新
}
results.append(result)
# 更新平均置信度指标
if batch_size > 0 and hasattr(context, 'metrics'):
avg_confidence = total_confidence / batch_size
context.metrics.add_gauge('avg_confidence', avg_confidence)
# 记录后处理时间
postprocess_time = time.time() - start_time
# 更新时间信息
for result in results:
result["timing"]["postprocess_ms"] = round(postprocess_time * 1000, 2)
result["timing"]["total_ms"] = round((
result["timing"]["preprocess_ms"] +
result["timing"]["inference_ms"] +
result["timing"]["postprocess_ms"]
), 2)
return [json.dumps(result) for result in results]
17.2 创建全面的监控仪表板
让我们创建一个更全面的Grafana仪表板,包含我们关心的所有指标:
{
"annotations": {
"list": []
},
"editable": true,
"gnetId": null,
"graphTooltip": 0,
"id": 1,
"links": [],
"panels": [
{
"aliasColors": {},
"bars": false,
"dashLength": 10,
"dashes": false,
"datasource": "Prometheus",
"fieldConfig": {
"defaults": {},
"overrides": []
},
"fill": 1,
"fillGradient": 0,
"gridPos": {
"h": 8,
"w": 12,
"x": 0,
"y": 0
},
"hiddenSeries": false,
"id": 2,
"legend": {
"avg": true,
"current": true,
"max": true,
"min": false,
"show": true,
"total": false,
"values": true
},
"lines": true,
"linewidth": 1,
"nullPointMode": "null",
"options": {
"alertThreshold": true
},
"percentage": false,
"pluginVersion": "7.5.3",
"pointradius": 2,
"points": false,
"renderer": "flot",
"seriesOverrides": [],
"spaceLength": 10,
"stack": false,
"steppedLine": false,
"targets": [
{
"expr": "rate(ts_inference_requests_total{model_name=~\"resnet.*\"}[1m])",
"interval": "",
"legendFormat": "{{model_name}} QPS",
"refId": "A"
}
],
"thresholds": [],
"timeFrom": null,
"timeRegions": [],
"timeShift": null,
"title": "每秒请求数 (QPS)",
"tooltip": {
"shared": true,
"sort": 0,
"value_type": "individual"
},
"type": "graph",
"xaxis": {
"buckets": null,
"mode": "time",
"name": null,
"show": true,
"values": []
},
"yaxes": [
{
"format": "short",
"label": "请求/秒",
"logBase": 1,
"max": null,
"min": null,
"show": true
},
{
"format": "short",
"label": null,
"logBase": 1,
"max": null,
"min": null,
"show": false
}
],
"yaxis": {
"align": false,
"alignLevel": null
}
},
{
"aliasColors": {},
"bars": false,
"dashLength": 10,
"dashes": false,
"datasource": "Prometheus",
"fieldConfig": {
"defaults": {},
"overrides": []
},
"fill": 1,
"fillGradient": 0,
"gridPos": {
"h": 8,
"w": 12,
"x": 12,
"y": 0
},
"hiddenSeries": false,
"id": 3,
"legend": {
"avg": false,
"current": true,
"max": true,
"min": true,
"show": true,
"total": false,
"values": true
},
"lines": true,
"linewidth": 1,
"nullPointMode": "null",
"options": {
"alertThreshold": true
},
"percentage": false,
"pluginVersion": "7.5.3",
"pointradius": 2,
"points": false,
"renderer": "flot",
"seriesOverrides": [],
"spaceLength": 10,
"stack": false,
"steppedLine": false,
"targets": [
{
"expr": "ts_inference_latency_microseconds{model_name=~\"resnet.*\",quantile=\"0.5\"} / 1000",
"interval": "",
"legendFormat": "{{model_name}} p50",
"refId": "A"
},
{
"expr": "ts_inference_latency_microseconds{model_name=~\"resnet.*\",quantile=\"0.9\"} / 1000",
"interval": "",
"legendFormat": "{{model_name}} p90",
"refId": "B"
},
{
"expr": "ts_inference_latency_microseconds{model_name=~\"resnet.*\",quantile=\"0.99\"} / 1000",
"interval": "",
"legendFormat": "{{model_name}} p99",
"refId": "C"
}
],
"thresholds": [],
"timeFrom": null,
"timeRegions": [],
"timeShift": null,
"title": "推理延迟",
"tooltip": {
"shared": true,
"sort": 0,
"value_type": "individual"
},
"type": "graph",
"xaxis": {
"buckets": null,
"mode": "time",
"name": null,
"show": true,
"values": []
},
"yaxes": [
{
"format": "ms",
"label": "延迟",
"logBase": 1,
"max": null,
"min": null,
"show": true
},
{
"format": "short",
"label": null,
"logBase": 1,
"max": null,
"min": null,
"show": false
}
],
"yaxis": {
"align": false,
"alignLevel": null
}
},
{
"aliasColors": {},
"bars": false,
"dashLength": 10,
"dashes": false,
"datasource": "Prometheus",
"fieldConfig": {
"defaults": {},
"overrides": []
},
"fill": 1,
"fillGradient": 0,
"gridPos": {
"h": 8,
"w": 12,
"x": 0,
"y": 8
},
"hiddenSeries": false,
"id": 4,
"legend": {
"avg": false,
"current": true,
"max": false,
"min": false,
"show": true,
"total": false,
"values": true
},
"lines": true,
"linewidth": 1,
"nullPointMode": "null",
"options": {
"alertThreshold": true
},
"percentage": false,
"pluginVersion": "7.5.3",
"pointradius": 2,
"points": false,
"renderer": "flot",
"seriesOverrides": [],
"spaceLength": 10,
"stack": false,
"steppedLine": false,
"targets": [
{
"expr": "avg_confidence{model_name=~\"resnet.*\"}",
"interval": "",
"legendFormat": "{{model_name}} 平均置信度",
"refId": "A"
}
],
"thresholds": [],
"timeFrom": null,
"timeRegions": [],
"timeShift": null,
"title": "预测置信度",
"tooltip": {
"shared": true,
"sort": 0,
"value_type": "individual"
},
"type": "graph",
"xaxis": {
"buckets": null,
"mode": "time",
"name": null,
"show": true,
"values": []
},
"yaxes": [
{
"format": "percentunit",
"label": "置信度",
"logBase": 1,
"max": "1",
"min": "0",
"show": true
},
{
"format": "short",
"label": null,
"logBase": 1,
"max": null,
"min": null,
"show": false
}
],
"yaxis": {
"align": false,
"alignLevel": null
}
},
{
"datasource": "Prometheus",
"fieldConfig": {
"defaults": {
"color": {
"mode": "thresholds"
},
"mappings": [],
"thresholds": {
"mode": "absolute",
"steps": [
{
"color": "green",
"value": null
},
{
"color": "red",
"value": 80
}
]
}
},
"overrides": []
},
"gridPos": {
"h": 8,
"w": 6,
"x": 12,
"y": 8
},
"id": 5,
"options": {
"colorMode": "value",
"graphMode": "area",
"justifyMode": "auto",
"orientation": "auto",
"reduceOptions": {
"calcs": [
"lastNotNull"
],
"fields": "",
"values": false
},
"text": {},
"textMode": "auto"
},
"pluginVersion": "7.5.3",
"targets": [
{
"expr": "sum(rate(ts_inference_requests_total{model_name=~\"resnet.*\"}[5m]))",
"interval": "",
"legendFormat": "",
"refId": "A"
}
],
"title": "总QPS(5分钟平均)",
"type": "stat"
},
{
"datasource": "Prometheus",
"fieldConfig": {
"defaults": {
"color": {
"mode": "thresholds"
},
"mappings": [],
"thresholds": {
"mode": "absolute",
"steps": [
{
"color": "green",
"value": null
},
{
"color": "yellow",
"value": 50
},
{
"color": "red",
"value": 80
}
]
},
"unit": "percentunit"
},
"overrides": []
},
"gridPos": {
"h": 8,
"w": 6,
"x": 18,
"y": 8
},
"id": 6,
"options": {
"colorMode": "value",
"graphMode": "area",
"justifyMode": "auto",
"orientation": "auto",
"reduceOptions": {
"calcs": [
"lastNotNull"
],
"fields": "",
"values": false
},
"text": {},
"textMode": "auto"
},
"pluginVersion": "7.5.3",
"targets": [
{
"expr": "rate(error_requests[1m]) / rate(processed_requests[1m])",
"interval": "",
"legendFormat": "",
"refId": "A"
}
],
"title": "错误率",
"type": "stat"
},
{
"aliasColors": {},
"bars": true,
"dashLength": 10,
"dashes": false,
"datasource": "Prometheus",
"fieldConfig": {
"defaults": {},
"overrides": []
},
"fill": 1,
"fillGradient": 0,
"gridPos": {
"h": 8,
"w": 12,
"x": 0,
"y": 16
},
"hiddenSeries": false,
"id": 7,
"legend": {
"avg": false,
"current": false,
"max": false,
"min": false,
"show": true,
"total": false,
"values": false
},
"lines": false,
"linewidth": 1,
"nullPointMode": "null",
"options": {
"alertThreshold": true
},
"percentage": false,
"pluginVersion": "7.5.3",
"pointradius": 2,
"points": false,
"renderer": "flot",
"seriesOverrides": [],
"spaceLength": 10,
"stack": false,
"steppedLine": false,
"targets": [
{
"expr": "topk(10, sum by(class) (rate(requests_per_class[5m])))",
"interval": "",
"legendFormat": "{{class}}",
"refId": "A"
}
],
"thresholds": [],
"timeFrom": null,
"timeRegions": [],
"timeShift": null,
"title": "最常预测的10个类别",
"tooltip": {
"shared": true,
"sort": 0,
"value_type": "individual"
},
"type": "graph",
"xaxis": {
"buckets": null,
"mode": "categories",
"name": null,
"show": true,
"values": []
},
"yaxes": [
{
"format": "short",
"label": "每秒请求数",
"logBase": 1,
"max": null,
"min": null,
"show": true
},
{
"format": "short",
"label": null,
"logBase": 1,
"max": null,
"min": null,
"show": false
}
],
"yaxis": {
"align": false,
"alignLevel": null
}
},
{
"aliasColors": {},
"bars": false,
"dashLength": 10,
"dashes": false,
"datasource": "Prometheus",
"fieldConfig": {
"defaults": {},
"overrides": []
},
"fill": 1,
"fillGradient": 0,
"gridPos": {
"h": 8,
"w": 12,
"x": 12,
"y": 16
},
"hiddenSeries": false,
"id": 8,
"legend": {
"avg": false,
"current": false,
"max": false,
"min": false,
"show": true,
"total": false,
"values": false
},
"lines": true,
"linewidth": 1,
"nullPointMode": "null",
"options": {
"alertThreshold": true
},
"percentage": false,
"pluginVersion": "7.5.3",
"pointradius": 2,
"points": false,
"renderer": "flot",
"seriesOverrides": [],
"spaceLength": 10,
"stack": false,
"steppedLine": false,
"targets": [
{
"expr": "histogram_quantile(0.5, rate(batch_size_distribution_bucket[5m]))",
"interval": "",
"legendFormat": "p50",
"refId": "A"
},
{
"expr": "histogram_quantile(0.9, rate(batch_size_distribution_bucket[5m]))",
"interval": "",
"legendFormat": "p90",
"refId": "B"
},
{
"expr": "histogram_quantile(0.99, rate(batch_size_distribution_bucket[5m]))",
"interval": "",
"legendFormat": "p99",
"refId": "C"
}
],
"thresholds": [],
"timeFrom": null,
"timeRegions": [],
"timeShift": null,
"title": "批处理大小分布",
"tooltip": {
"shared": true,
"sort": 0,
"value_type": "individual"
},
"type": "graph",
"xaxis": {
"buckets": null,
"mode": "time",
"name": null,
"show": true,
"values": []
},
"yaxes": [
{
"format": "short",
"label": "批大小",
"logBase": 1,
"max": null,
"min": null,
"show": true
},
{
"format": "short",
"label": null,
"logBase": 1,
"max": null,
"min": null,
"show": false
}
],
"yaxis": {
"align": false,
"alignLevel": null
}
}
],
"refresh": "5s",
"schemaVersion": 27,
"style": "dark",
"tags": [],
"templating": {
"list": []
},
"time": {
"from": "now-15m",
"to": "now"
},
"timepicker": {},
"timezone": "",
"title": "TorchServe高级监控仪表板",
"uid": "torchserve-advanced",
"version": 1
}
清华大学全五版的《DeepSeek教程》完整的文档需要的朋友,关注我私信:deepseek 即可获得。
怎么样今天的内容还满意吗?再次感谢朋友们的观看,关注GZH:凡人的AI工具箱,回复666,送您价值199的AI大礼包。最后,祝您早日实现财务自由,还请给个赞,谢谢!

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 34
34 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)