【读点论文】Energy-based Out-of-distribution Detection训练时通过辅助OOD数据微调模型,推理使用训练模型计算能量分数,替代softmax置信度进行OOD检测
确定输入是否为非分布(OOD)是在开放世界中安全部署机器学习模型的基本构件。然而,以前依赖于softmax置信度得分的方法会受到OOD数据的过度自信后验分布的影响。我们提出了一个统一的框架,OOD检测,使用能量评分。我们表明,与使用softmax评分的传统方法相比,能量评分可以更好地区分分布内和分布外样本。与softmax置信度得分不同,能量得分理论上与输入的概率密度一致,并且不太容易受到过度自信
Energy-based Out-of-distribution Detection
Abstract
- 确定输入是否为非分布(OOD)是在开放世界中安全部署机器学习模型的基本构件。然而,以前依赖于softmax置信度得分的方法会受到OOD数据的过度自信后验分布的影响。我们提出了一个统一的框架,OOD检测,使用能量评分。我们表明,与使用softmax评分的传统方法相比,能量评分可以更好地区分分布内和分布外样本。与softmax置信度得分不同,能量得分理论上与输入的概率密度一致,并且不太容易受到过度自信问题的影响。在此框架内,能量可以灵活地用作任何预训练神经分类器的评分函数以及可训练的成本函数,以明确地形成用于 OOD 检测的能量表面。在CIFAR-10预训练的WideResNet上,与softmax置信度得分相比,使用能量得分将平均FPR(TPR 95%)降低了18.03%。通过基于能量的训练,我们的方法在公共基准上优于最先进的方法。
- 论文地址:[2010.03759] Energy-based Out-of-distribution Detection
- 使用能量分数(energy score)替代传统的 softmax 置信度来检测 OOD 样本。能量分数基于能量模型(EBM),通过将输入映射到一个标量值,In-distribution 样本能量较低,OOD 样本能量较高。数学上,能量分数定义为负的对数配分函数,与 softmax 的 logits 相关,公式为 E ( x ; f ) = − T ・ l o g ( s u m ( e x p ( f i ( x ) / T ) ) ) E (x; f) = -T・log (sum (exp (f_i (x)/T))) E(x;f)=−T・log(sum(exp(fi(x)/T))),其中 f i ( x ) f_i (x) fi(x) 是 logits,T 是温度参数。softmax 置信度在 OOD 样本上可能过高,因为其后验分布过度拟合标签空间,而能量分数在理论上与输入数据的概率密度对齐,OOD 样本的能量更高,更适合区分。引用了能量模型的背景,如 Gibbs 分布和 Helmholtz 自由能,说明能量分数的合理性。
- 研究目标是提高 OOD 检测的性能,解决 softmax 的过自信问题。方法分为两部分:推理时使用预训练模型的能量分数作为检测分数,训练时使用能量约束学习(energy-bounded learning)调整网络,通过平方铰链损失在 In 和 OOD 数据间创建能量差距。应用到图像分类网络时,需要准备预训练的分类模型,计算能量分数作为检测分数,或在训练时加入能量约束损失,使用辅助 OOD 数据进行微调。配置上需注意温度参数的设置,margin 参数的选择,以及数据预处理步骤。
- 推理阶段主要是使用预训练模型计算能量分数,而训练阶段则涉及到能量约束学习的微调。利用预训练图像分类模型的 logits 计算能量分数(无需重训练),替代传统 softmax 置信度进行 OOD 检测。
- 获取分类模型的 logits 输出 :假设已有训练好的图像分类网络(如 ResNet、WideResNet),输入图像 x 后输出 K 维 logits 向量 ( f ( x ) = [ f 1 ( x ) , f 2 ( x ) , … , f K ( x ) ] f(x) = [f_1(x), f_2(x), \dots, f_K(x)] f(x)=[f1(x),f2(x),…,fK(x)] ),其中 K 为类别数。
- 计算能量分数 (E(x; f)) :能量分数为对数配分函数的负值(默认温度 (T=1)):( E ( x ; f ) = − log ( ∑ i = 1 K e f i ( x ) ) E(x; f) = -\log \left( \sum_{i=1}^K e^{f_i(x)} \right) E(x;f)=−log(∑i=1Kefi(x)))。
- 设定 OOD 检测阈值:使用负能量分数 (-E(x; f))(与 softmax 置信度方向一致,In 样本分数更高),若 ( − E ( x ; f ) ≤ τ -E(x; f) \leq \tau −E(x;f)≤τ),判为 OOD,否则判为 In。使用 In 分布验证集,计算所有样本的负能量分数,选择阈值 τ \tau τ 使得 In 样本的 TPR(真阳性率)达到目标值(如 95%)。无需修改模型结构或重训练,直接替换 softmax 置信度。无需调整温度 T(默认 (T=1) 效果最佳)。
- 训练阶段:能量约束学习(Fine-tuning),通过辅助 OOD 数据微调分类模型,显式优化 In/OOD 样本的能量分布,增大两者的能量差距。数据准备:使用原分类任务的训练集 D in train \mathcal{D}_{\text{in}}^{\text{train}} Dintrain。选择与 In 分布不同的数据集(如自然图像、纹理、场景等,论文中使用 80 Million Tiny Images)。确保 OOD 数据与 In 数据无重叠。总损失由交叉熵损失(保证分类精度)和能量约束损失(优化能量分布)组成: L = L CE + λ ⋅ L energy \mathcal{L} = \mathcal{L}_{\text{CE}} + \lambda \cdot \mathcal{L}_{\text{energy}} L=LCE+λ⋅Lenergy。交叉熵损失(针对 In 分布有标签数据), L CE = − 1 N in ∑ ( x , y ) ∈ D in train log ( e f y ( x ) ∑ i = 1 K e f i ( x ) ) \mathcal{L}_{\text{CE}} = -\frac{1}{N_{\text{in}}} \sum_{(x, y) \in \mathcal{D}_{\text{in}}^{\text{train}}} \log \left( \frac{e^{f_y(x)}}{\sum_{i=1}^K e^{f_i(x)}} \right) LCE=−Nin1∑(x,y)∈Dintrainlog(∑i=1Kefi(x)efy(x))。能量约束损失(针对 In 和 OOD 无标签数据), L energy = 1 N in ∑ x in ∈ D in train max ( 0 , E ( x in ) − m in ) 2 + 1 N out ∑ x out ∈ D out train max ( 0 , m out − E ( x out ) ) 2 \mathcal{L}_{\text{energy}} = \frac{1}{N_{\text{in}}} \sum_{x_{\text{in}} \in \mathcal{D}_{\text{in}}^{\text{train}}} \max(0, E(x_{\text{in}}) - m_{\text{in}})^2 + \frac{1}{N_{\text{out}}} \sum_{x_{\text{out}} \in \mathcal{D}_{\text{out}}^{\text{train}}} \max(0, m_{\text{out}} - E(x_{\text{out}}))^2 Lenergy=Nin1∑xin∈Dintrainmax(0,E(xin)−min)2+Nout1∑xout∈Douttrainmax(0,mout−E(xout))2 其中: m in m_{\text{in}} min:In 样本能量上界(迫使 In 样本能量低于 m in m_{\text{in}} min)。 m out m_{\text{out}} mout:OOD 样本能量下界(迫使 OOD 样本能量高于 m out m_{\text{out}} mout)。
Introduction
-
现实世界是开放的,充满了未知,这对必须可靠处理不同输入的机器学习模型提出了重大挑战。当机器学习模型看到不同于其训练数据的输入时,就会出现分布外(OOD)不确定性,因此不应该由模型预测。确定输入是否不符合分布是在安全关键应用(如罕见疾病识别)中部署ML的一个基本问题。最近的大量研究研究了分布外检测问题 。
-
以前的方法依靠softmax置信度得分来防止OOD输入。具有低softmax置信度得分的输入被分类为OOD。然而,神经网络可以为远离训练数据的输入产生任意高的softmax置信度。由于softmax后验分布可能具有标签过度拟合的输出空间,这使得softmax置信度得分对于OOD检测来说不是最佳的,所以会出现这种故障模式。
-
在本文中,我们建议使用能量分数来检测OOD输入,并提供数学见解和经验证据表明能量分数优于基于softmax的分数和基于生成的方法。基于能量的模型将每个输入映射到单个标量,该标量对于观察到的数据较低,对于未观察到的数据较高。我们证明能量分数对于OOD检测是可取的,因为它在理论上与输入的概率密度一致——具有较高能量的样本可以被解释为出现可能性较低的数据。相比之下,我们从数学上证明了softmax置信度得分是一个有偏差的得分函数,它与输入的密度不一致,因此不适用于OOD检测。
-
重要的是,能量分数可以从纯粹的判别分类模型中导出,而不明显依赖于密度估计器,因此避开了训练生成模型中的困难的优化过程。这与 JEM 形成对比,后者从生成建模的角度推导出似然得分 log p(x)。在实践中,JEM的目标可能难以优化且不稳定,因为它需要估计整个输入空间的归一化密度以最大化似然性。此外,虽然 JEM 只利用分布内数据,但我们的框架允许利用分布内数据和辅助异常数据来灵活地形成训练和OOD数据之间的能量差距,这是一种比JEM或异常暴露更有效的学习方法。
-
Contributions. 我们提出了一个使用能量分数进行OOD检测的统一框架【GitHub - wetliu/energy_ood】。我们证明了可以灵活地使用能量作为任何预训练神经分类器的评分函数(无需重新训练),以及可训练的成本函数来微调分类模型。我们证明了能量函数对于两种用例的OOD检测的有效性。
-
在推理时,我们表明,对于任何预训练的神经网络,能量可以方便地取代softmax置信度。我们表明,在常见的OOD评估基准上,能量分数优于softmax置信度分数。例如,在WideResNet上,与使用softmax置信度得分相比,能量得分在CIFAR-10上将平均FPR(在95% TPR下)降低了18.03%。使用预训练模型的现有方法可能需要调整几个超参数,并且有时需要额外的数据。相比之下,能量分数是一种无参数的度量,易于使用和实现,并且在许多情况下,实现了相当甚至更好的性能。
-
在训练时,我们提出一个能量受限的学习目标来微调网络。学习过程形成能量表面,以将低能量值分配给非分布数据,并将较高能量值分配给OOD训练数据。具体来说,我们使用两个平方铰链损失项来正则化能量,这明确地创建了分布内和分布外训练数据之间的能量间隙。我们表明,能量微调模型优于之前在六个OOD数据集上评估的最先进的方法。与基于softmax的微调方法相比,我们的方法在CIFAR-100上将平均FPR(TPR为95%)降低了10.55%。这种微调提高了OOD检测性能,同时保持了相似的内分布数据分类精度。
-

-
图1:基于能量的非分布检测框架。该能量可以用作任何预训练神经网络的评分函数(无需重新训练),或者用作可训练的成本函数来微调分类模型。在推断时间期间,对于给定的输入x,能量得分E(x;f)是为神经网络f(x)计算的。如果负能量分数小于阈值,则OOD检测器将输入分类为OOD。
-
-
本文的其余部分组织如下。第2节提供了基于能量的模型的背景。在第3节中,我们提出了使用能量分数进行OOD检测的方法,并在第4节中给出了实验结果。第5节提供了关于OOD检测和基于能量的学习的综合文献综述。我们在第6节结束,在第7节讨论更广泛的影响。
-
能量分数替代 softmax:利用能量模型(Energy-Based Model, EBM)将输入映射为标量能量值,In 样本能量低,OOD 样本能量高,从理论上对齐数据密度(高能量对应低概率密度)。推理时直接使用预训练模型的能量分数(无需重训练),训练时通过能量约束学习(Energy-Bounded Learning)显式优化 In/OOD 样本的能量差距,提升检测性能。
-
能量函数:对于分类模型的 logits f ( x ) ∈ R K f(x) \in \mathbb{R}^K f(x)∈RK,能量分数定义为 Helmholtz 自由能: E ( x ; f ) = − T ⋅ log ∑ i = 1 K e f i ( x ) / T E(x; f) = -T \cdot \log \sum_{i=1}^K e^{f_i(x)/T} E(x;f)=−T⋅log∑i=1Kefi(x)/T 其中 T 为温度参数,默认取 (T=1)。该式本质是 softmax 的对数配分函数的负值,反映样本在特征空间的 “能量”——In 样本因接近训练分布,能量更低;OOD 样本因远离训练分布,能量更高。softmax 置信度 max y p ( y ∣ x ) \max_y p(y|x) maxyp(y∣x) 是能量分数的偏移版本( f i ( x ) f_i(x) fi(x) 减去最大 logit),导致对 OOD 样本过自信。能量分数直接基于原始 logit 空间,避免偏移带来的偏差,理论上更贴近数据密度。
-
能量约束学习(训练阶段): 在交叉熵损失基础上,引入平方铰链损失约束 In/OOD 样本的能量范围: L energy = E In max ( 0 , E ( x In ) − m in ) 2 + E OOD max ( 0 , m out − E ( x OOD ) ) 2 L_{\text{energy}} = \mathbb{E}_{\text{In}} \max(0, E(x_{\text{In}}) - m_{\text{in}})^2 + \mathbb{E}_{\text{OOD}} \max(0, m_{\text{out}} - E(x_{\text{OOD}}))^2 Lenergy=EInmax(0,E(xIn)−min)2+EOODmax(0,mout−E(xOOD))2 其中 m in 和 m out m_{\text{in}} 和 m_{\text{out}} min和mout 分别为 In/OOD 样本的能量阈值,迫使 In 样本能量低于 m in m_{\text{in}} min,OOD 样本能量高于 m out m_{\text{out}} mout,形成明确能量差距。通过对比学习,显式分离 In/OOD 的能量分布,避免 softmax 因标签过拟合导致的 OOD 误判。
-
能量分数与输入数据的概率密度通过 Gibbs 分布关联 p ( y ∣ x ) ∝ e − E ( x , y ) / T p(y|x) \propto e^{-E(x,y)/T} p(y∣x)∝e−E(x,y)/T,高能量对应低概率密度,天然适合 OOD 检测。无需显式密度估计(如生成模型),直接利用分类模型的 logits 计算能量,规避生成模型的复杂优化和不稳定问题。跳出 softmax 的概率归一化框架,以 “能量” 这一非概率指标重新定义样本与分布的距离,体现对机器学习本质的反思 —— 分类模型不仅输出标签,其 logits 空间本身蕴含丰富的分布信息。能量分数是参数无关的度量(推理时仅需计算 logsumexp),却能超越复杂的生成模型方法,体现 “奥卡姆剃刀” 原则:简单而理论坚实的设计往往更具实用性。
Background: Energy-based Models
-
基于能量的模型(EBM) 的本质是建立一个函数 E ( x ) : R D → R E(x) : \R^D\rightarrow \R E(x):RD→R,它将输入空间的每个点x映射到称为能量的单个非概率标量。能量值的集合可以通过吉布斯分布转换成概率密度p(x ):
-
p ( y ∣ x ) = e − E ( x , y ) / T ∫ y ′ e − E ( x , y ′ ) / T = e − E ( x , y ) / T e − E ( x ) / T , (1) p ( y \mid{\bf x} )=\frac{e^{-E ( {\bf x}, y ) / T}} {\int_{y^{\prime}} e^{-E ( {\bf x}, y^{\prime} ) / T}}=\frac{e^{-E ( {\bf x}, y ) / T}} {e^{-E ( {\bf x} ) / T}}, \tag{1} p(y∣x)=∫y′e−E(x,y′)/Te−E(x,y)/T=e−E(x)/Te−E(x,y)/T,(1)
-
其中分母 ∫ y ′ e E ( x ; y ′ ) = T \int_{y'} e^{E(x;y' )=T} ∫y′eE(x;y′)=T 称为配分函数,在y上边缘化,T是温度参数。给定数据点 x ∈ R D x\in \R^D x∈RD 的亥姆霍兹自由能E(x)可以表示为对数配分函数的负值:
-
E ( x ) = − T ⋅ log ∫ y ′ e − E ( x , y ′ ) / T E ( {\bf x} )=-T \cdot\operatorname{l o g} \int_{y^{\prime}} e^{-E ( {\bf x}, y^{\prime} ) / T} E(x)=−T⋅log∫y′e−E(x,y′)/T
-
-
能量函数:基于能量的模型与现代机器学习有着内在的联系,尤其是判别模型。为了看到这一点,我们考虑一个判别神经分类器 f ( x ) : R D → R K f(x) : \R^D\rightarrow \R^K f(x):RD→RK,它将输入 x ∈ R D x\in\R^D x∈RD 映射到K个实数值,称为logits。这些逻辑用于使用 softmax 函数推导分类分布:
-
p ( y ∣ x ) = e f y ( x ) / T ∑ i K e f i ( x ) / T , (3) p ( y \mid{\bf x} )=\frac{e^{f_{y} ( {\bf x} ) / T}} {\sum_{i}^{K} e^{f_{i} ( {\bf x} ) / T}}, \tag{3} p(y∣x)=∑iKefi(x)/Tefy(x)/T,(3)
-
其中 fy(x) 表示 f(x) 的第 y 个索引,即对应于第 y 个类标签的logit。通过连接等式 1 和等式 3、我们可以为给定的输入定义一个能量 (x;y) 作为E(x;y)=-fy(x)。更重要的是,在不改变神经网络f(x)的参数化的情况下,我们可以表示自由能函数 E(x;f) 根据softmax激活的分母 x ∈ R D x\in\R^ D x∈RD:
-
E ( x ; f ) = − T ⋅ log ∑ i K e f i ( x ) / T . (4) E ( \mathbf{x} ; f )=-T \cdot\operatorname{l o g} \sum_{i}^{K} e^{f_{i} ( \mathbf{x} ) / T}. \tag{4} E(x;f)=−T⋅logi∑Kefi(x)/T.(4)
-
Energy-based Out-of-distribution Detection
-
我们提出了一个统一的框架,使用能量分数进行 OOD 检测,其中分布内和分布外之间的能量差异允许有效的区分。对于OOD示例,能量分数缓解了具有任意高值的softmax置信度的关键问题。在下文中,我们首先描述使用能量作为预训练模型的OOD分数,以及能量和softmax分数之间的联系(第3.1节)。然后,我们描述如何使用能量作为模型微调的可训练成本函数(3.3节)。
-
在 CIFAR/train.py 和 CIFAR/test.py 中分别实现了模型的训练和测试过程。以 CIFAR/train.py 中的
train函数为例:-
def train(): net.train() # enter train mode loss_avg = 0.0 # start at a random point of the outlier dataset; this induces more randomness without obliterating locality train_loader_out.dataset.offset = np.random.randint(len(train_loader_out.dataset)) for in_set, out_set in zip(train_loader_in, train_loader_out): data = torch.cat((in_set[0], out_set[0]), 0) target = in_set[1] data, target = data.cuda(), target.cuda() # forward x = net(data) # backward scheduler.step() optimizer.zero_grad() loss = F.cross_entropy(x[:len(in_set[0])], target) # cross-entropy from softmax distribution to uniform distribution if args.score == 'energy': Ec_out = -torch.logsumexp(x[len(in_set[0]):], dim=1) Ec_in = -torch.logsumexp(x[:len(in_set[0])], dim=1) loss += 0.1*(torch.pow(F.relu(Ec_in-args.m_in), 2).mean() + torch.pow(F.relu(args.m_out-Ec_out), 2).mean()) elif args.score == 'OE': loss += 0.5 * -(x[len(in_set[0]):].mean(1) - torch.logsumexp(x[len(in_set[0]):], dim=1)).mean() loss.backward() optimizer.step() # exponential moving average loss_avg = loss_avg * 0.8 + float(loss) * 0.2 state['train_loss'] = loss_avg -
能量分数 E 定义为 ( E = − log ∑ i = 1 C exp ( z i ) E = -\log\sum_{i=1}^{C}\exp(z_i) E=−log∑i=1Cexp(zi)),其中 z i z_i zi 是模型的输出。通过计算分布内和分布外数据的能量分数,并与阈值进行比较,得到额外的损失项。
-
-
分解 test.py 的各个模块。test.py 使用 argparse 定义了各种参数,包括测试批次大小、模型加载路径、评分方法(如 MSP、energy)等。
test.py的get_ood_scores函数根据模型输出计算 OOD 评分(如 MSP、能量分数)-
output = net(data) # 模型输出 logits(shape: [batch_size, num_classes]) smax = to_np(F.softmax(output, dim=1)) # softmax 概率 score = -np.max(smax, axis=1) # MSP 评分(越小越可能为 OOD) ############## def get_ood_scores(loader, in_dist=False): _score = [] _right_score = [] _wrong_score = [] with torch.no_grad(): for batch_idx, (data, target) in enumerate(loader): if batch_idx >= ood_num_examples // args.test_bs and in_dist is False: break data = data.cuda() output = net(data) smax = to_np(F.softmax(output, dim=1)) if args.use_xent: _score.append(to_np((output.mean(1) - torch.logsumexp(output, dim=1)))) else: if args.score == 'energy': _score.append(-to_np((args.T*torch.logsumexp(output / args.T, dim=1)))) else: # original MSP and Mahalanobis (but Mahalanobis won't need this returned) _score.append(-np.max(smax, axis=1)) if in_dist: preds = np.argmax(smax, axis=1) targets = target.numpy().squeeze() right_indices = preds == targets wrong_indices = np.invert(right_indices) if args.use_xent: _right_score.append(to_np((output.mean(1) - torch.logsumexp(output, dim=1)))[right_indices]) _wrong_score.append(to_np((output.mean(1) - torch.logsumexp(output, dim=1)))[wrong_indices]) else: _right_score.append(-np.max(smax[right_indices], axis=1)) _wrong_score.append(-np.max(smax[wrong_indices], axis=1)) if in_dist: return concat(_score).copy(), concat(_right_score).copy(), concat(_wrong_score).copy() else: return concat(_score)[:ood_num_examples].copy() -
使用特征空间的马氏距离:
-
def get_ood_scores(loader, in_dist=False): _score = [] with torch.no_grad(): for data, _ in loader: data = data.cuda() features = net.extract_features(data) # 假设模型可提取特征 # 计算特征与 ID 数据分布的马氏距离(需提前计算 ID 数据的均值和协方差) score = compute_mahalanobis(features, sample_mean, precision) _score.append(score) return concat(_score)
-
-
score_calculation.py 用于计算OOD(Out-of-Distribution,分布外)检测的关键分数,包含两种经典方法:ODIN(基于输入扰动的 OOD 检测)和马氏距离(基于特征分布统计的 OOD 检测)。ODIN(Out-of-Distribution Detection with Input Perturbations)是一种通过输入扰动增强 OOD 检测的方法。核心思想:对输入数据添加微小扰动,放大 OOD 数据与模型的不匹配性,结合温度缩放(Temperature Scaling)软化概率分布,从而降低 OOD 数据的置信度。
-
def get_ood_scores_odin(loader, net, bs, ood_num_examples, T, noise, in_dist=False): _score = [] _right_score = [] # 分布内数据中分类正确的分数 _wrong_score = [] # 分布内数据中分类错误的分数 net.eval() # 模型切换到评估模式(关闭Dropout等) for batch_idx, (data, target) in enumerate(loader): # 限制处理的批量数(仅OOD数据需要) if batch_idx >= ood_num_examples // bs and in_dist is False: break data = data.cuda() # 数据转移到GPU data = Variable(data, requires_grad=True) # 启用梯度计算 output = net(data) # 模型前向传播 smax = to_np(F.softmax(output, dim=1)) # 原始Softmax概率 # 计算ODIN分数(通过扰动输入后的Softmax概率) odin_score = ODIN(data, output, net, T, noise) _score.append(-np.max(odin_score, 1)) # 取最大类别的负置信度(OOD分数通常取负值) # 分布内数据需要区分分类正确/错误的样本 if in_dist: preds = np.argmax(smax, axis=1) # 模型预测类别 targets = target.numpy().squeeze() # 真实类别 right_indices = preds == targets # 正确分类的索引 wrong_indices = np.invert(right_indices) # 错误分类的索引 # 记录正确/错误分类样本的分数 _right_score.append(-np.max(smax[right_indices], axis=1)) _wrong_score.append(-np.max(smax[wrong_indices], axis=1)) if in_dist: return concat(_score).copy(), concat(_right_score).copy(), concat(_wrong_score).copy() else: return concat(_score)[:ood_num_examples].copy() # 仅返回OOD样本分数 def ODIN(inputs, outputs, model, temper, noiseMagnitude1): # 步骤1:计算交叉熵损失的梯度(用于生成扰动) criterion = nn.CrossEntropyLoss() # 交叉熵损失函数 maxIndexTemp = np.argmax(outputs.data.cpu().numpy(), axis=1) # 模型预测的类别(伪标签) # 温度缩放:软化概率分布(temper>1时,概率更平滑) outputs = outputs / temper # 以模型预测的类别为“伪标签”计算损失(梯度指向降低伪标签置信度的方向) labels = Variable(torch.LongTensor(maxIndexTemp).cuda()) loss = criterion(outputs, labels) loss.backward() # 反向传播计算输入的梯度 # 步骤2:归一化梯度(生成扰动方向) gradient = torch.ge(inputs.grad.data, 0) # 梯度符号(大于0为1,否则为0) gradient = (gradient.float() - 0.5) * 2 # 转换为{-1, 1}方向(梯度符号的标准化) # 根据数据标准差调整扰动幅度(使扰动对不同通道的影响一致) # 原始数据标准化的均值/标准差(CIFAR-10统计值) gradient[:,0] = gradient[:,0] / (63.0/255.0) # 通道0标准差:63.0/255 gradient[:,1] = gradient[:,1] / (62.1/255.0) # 通道1标准差:62.1/255 gradient[:,2] = gradient[:,2] / (66.7/255.0) # 通道2标准差:66.7/255 # 步骤3:添加扰动到输入数据 tempInputs = torch.add(inputs.data, -noiseMagnitude1, gradient) # 扰动方向:-梯度方向(降低伪标签置信度) # 步骤4:计算扰动后的模型输出(再次温度缩放) outputs = model(Variable(tempInputs)) # 扰动数据的前向传播 outputs = outputs / temper # 再次温度缩放 # 步骤5:计算扰动后的Softmax置信度 nnOutputs = outputs.data.cpu().numpy() nnOutputs = nnOutputs - np.max(nnOutputs, axis=1, keepdims=True) # 减去最大值(数值稳定) nnOutputs = np.exp(nnOutputs) / np.sum(np.exp(nnOutputs), axis=1, keepdims=True) # Softmax return nnOutputs -
温度缩放(Temperature Scaling):通过参数
T>1软化模型输出的概率分布,使分布内数据的置信度降低、OOD 数据的置信度进一步降低,放大两者差异。
-
Energy as Inference-time OOD Score
-
分布外检测是一个二元分类问题,它依靠分数来区分分布内和分布外的例子。评分函数应该生成可区分分布内和分布外的值。一个自然的选择是使用(x)中数据p的密度函数,并考虑不太可能是 ood 的例子。然而,以前的研究表明,通过深度生成模型估计的密度函数不能可靠地用于 OOD 检测。为了减轻挑战,我们求助于从用于OOD检测的判别模型导出的能量函数。用负对数似然(NLL)损失训练的模型将降低分布内数据点的能量。为了看到这一点,我们可以表示对分布内数据 ( x ; y ) ∞ P i n (x;y)∞P^{in} (x;y)∞Pin:
-
通过定义能量E(x;y)=-fy(x),NLL损耗可改写为:
- L n l l = E ( x , y ) ∼ P i n ( − log e f y ( x ) / T ∑ j = 1 K e f j ( x ) / T ) . (5) \mathcal{L}_{\mathrm{n l l}}=\mathbb{E}_{( \mathbf{x}, y ) \sim P^{\mathrm{i n}}} \big(-\operatorname{l o g} \frac{e^{f_{y} ( \mathbf{x} ) / T}} {\sum_{j=1}^{K} e^{f_{j} ( \mathbf{x} ) / T}} \big). \tag{5} Lnll=E(x,y)∼Pin(−log∑j=1Kefj(x)/Tefy(x)/T).(5)
-
第一项推低了 GT 答案y的能量,第二个对比项可以解释为能量系综的自由能(对数配分函数)。对比项导致基础真理答案y的能量被拉低,而所有其他标签的能量被拉高。这可以从单个例子的梯度表达式中看出:
-
∂ L n l l ( x , y ; θ ) ∂ θ = 1 T ∂ E ( x , y ) ∂ θ − 1 T ∑ j = 1 K ∂ E ( x , y ) ∂ θ e − E ( x , y ) / T ∑ j = 1 K e − E ( x , j ) / T = 1 T ( ∂ E ( x , y ) ∂ θ ( 1 − p ( Y = y ) ∣ x ) ⏟ ↓ energy push down for y − ∑ j ≠ y ∂ E ( x , j ) ∂ θ p ( Y = j ∣ x ) ⏟ ↑ energy pull up for other labels . \begin{aligned} \frac{\partial\mathcal{L}_{\mathrm{nll}}(\mathbf{x},y;\theta)}{\partial\theta} & =\frac{1}{T}\frac{\partial E(\mathbf{x},y)}{\partial\theta} \\ & -\frac{1}{T}\sum_{j=1}^{K}\frac{\partial E(\mathbf{x},y)}{\partial\theta}\frac{e^{-E(\mathbf{x},y)/T}}{\sum_{j=1}^{K}e^{-E(\mathbf{x},j)/T}} \\ & =\frac{1}{T}(\underbrace{\frac{\partial E(\mathbf{x},y)}{\partial\theta}(1-p(Y=y)|\mathbf{x})}_{\downarrow\text{ energy push down for }y} \\ & -\underbrace{\sum_{j\neq y}\frac{\partial E(\mathbf{x},j)}{\partial\theta}p(Y=j|\mathbf{x})}_{\uparrow\text{ energy pull up for other labels}}. \end{aligned} ∂θ∂Lnll(x,y;θ)=T1∂θ∂E(x,y)−T1j=1∑K∂θ∂E(x,y)∑j=1Ke−E(x,j)/Te−E(x,y)/T=T1(↓ energy push down for y ∂θ∂E(x,y)(1−p(Y=y)∣x)−↑ energy pull up for other labels j=y∑∂θ∂E(x,j)p(Y=j∣x).
-
-
而且,能量得分E(x;f)在等式 4 中定义。是fy(x) = E(x;y) 的平滑近似值,在所有标签中以 GT 标签 y 为主。因此,NLL损耗总体上推低了能量 E(x;f) 分发中的数据。鉴于能量的特性,我们建议使用能量函数E(x;f)在等式4中。对于 OOD 检测:
-
g ( x ; τ , f ) = { 0 i f − E ( x ; f ) ≤ τ , 1 i f − E ( x ; f ) > τ , (7) g ( \mathbf{x} ; \tau, f )=\left\{\begin{matrix} {{0}} & {{\quad\mathrm{i f} \ -E ( \mathbf{x} ; f ) \leq\tau,}} \\ {{1}} & {{\quad\mathrm{i f} \ -E ( \mathbf{x} ; f ) > \tau,}} \\ \end{matrix} \right. \tag{7} g(x;τ,f)={01if −E(x;f)≤τ,if −E(x;f)>τ,(7)
-
其中,τ 是能量阈值。具有较高能量的例子被认为是OOD输入,反之亦然。实际上,我们使用分布内数据来选择阈值,以便OOD检测器 g(x) 能够正确地对大部分输入进行分类。这里我们使用负能量分数,E(x;f),以符合阳性(分布内)样本具有较高分数的传统定义。能量分数是非概率的,可以通过logsumexp算子方便地计算。
-
Energy Score vs. Softmax Score
-
我们的方法可以作为任何预训练神经网络的softmax置信度得分的简单而有效的替代。为了看到这一点,我们首先推导出能量分数和softmax置信度分数之间的数学关系:
-
max y p ( y ∣ x ) = max y e f y ( x ) ∑ i e f i ( x ) = e f max ( x ) ∑ i e f i ( x ) = 1 ∑ i e f i ( x ) − f max ( x ) ⟹ log max y p ( y ∣ x ) = E ( x ; f ( x ) − f max ( x ) ) = E ( x ; f ) ⏟ ↓ for in-dist x + f max ( x ) ⏟ ↑ for in-dist x , \begin{aligned} \operatorname*{max}_{y}p(y\mid\mathbf{x}) & =\max_{y}\frac{e^{f_{y}(\mathbf{x})}}{\sum_{i}e^{f_{i}(\mathbf{x})}}=\frac{e^{f^{\max}(\mathbf{x})}}{\sum_{i}e^{f_{i}(\mathbf{x})}} \\ & =\frac{1}{\sum_ie^{f_i(\mathbf{x})-f^{\max}(\mathbf{x})}} \\ \Longrightarrow\log\max_{y}p(y\mid\mathbf{x}) & =E(\mathbf{x};f(\mathbf{x})-f^{\max}(\mathbf{x})) \\ & =\underbrace{E(\mathbf{x};f)}_{\downarrow\text{for in-dist x}}+\underbrace{f^{\max}(\mathbf{x})}_{\uparrow\text{for in-dist x}}, \end{aligned} ymaxp(y∣x)⟹logymaxp(y∣x)=ymax∑iefi(x)efy(x)=∑iefi(x)efmax(x)=∑iefi(x)−fmax(x)1=E(x;f(x)−fmax(x))=↓for in-dist x E(x;f)+↑for in-dist x fmax(x),
-
当T = 1时。这揭示了 softmax 置信度得分的对数实际上等价于自由能得分的特殊情况,其中所有的对数都移动了它们的最大logit值。因为 f max(x) 趋向于更高并且 E(x;f) 对于分布内数据来说趋于更低,这种移动导致有偏差的评分函数,该函数不再适合于OOD检测。因此,softmax 置信度得分不太能够可靠地区分分布内和分布外的示例。
-
-
为了举例说明,图2显示了来自SVHN数据集(OOD)的一个示例和来自in-distribution数据CIFAR-10的另一个示例。虽然他们的softmax置信度得分几乎相同(1.0比0.99),但负能量得分更有区别(11.19比7.11).因此,在原始logit空间(能量分数)而不是移位的logit空间(softmax分数)中工作会为每个样本产生更多有用的信息。我们在第4.2节的实验结果中显示,对于OOD检测,能量分数是比softmax分数更好的度量。
-

-
图2: (a)在CIFAR-10预训练WideResNet上计算的两个样本的Softmax和(b) logit输出。分布外样本来自SVHN。对于(a ),对于内分布和外分布示例,softmax置信度得分分别为1.0和0.99。相比之下,根据logit计算的能量分数为E(Xin)=-11:19,E(xout)=-7:11。虽然softmax置信度得分对于内分布和外分布样本几乎相同,但能量得分提供了更有意义的信息来区分它们。
-
Energy-bounded Learning for OOD Detection
-
虽然能量分数对于预训练的神经网络可能是有用的,但是分布内和分布外之间的能量差距对于区分可能并不总是最佳的。因此,我们还提出了一个能量受限的学习目标,其中神经网络被微调以通过将较低的能量分配给in-distribution数据而将较高的能量分配给OOD数据来明确地创建能量间隙。该学习过程允许在对比成形能量表面时具有更大的灵活性,从而产生更可区分的分布内和分布外数据。具体来说,我们的基于能量的分类器使用以下目标来训练:
-
min θ E ( x , y ) ∼ D i n m i n [ − log F y ( x ) ] + λ ⋅ L e n c r g y (8) \operatorname* {m i n}_{\theta} \quad\mathbb{E}_{( \mathbf{x}, y ) \sim\mathcal{D}_{\mathrm{i n}}^{\mathrm{m i n}}} [-\operatorname{l o g} F_{y} ( \mathbf{x} ) ]+\lambda\cdot L_{\mathrm{e n c r g y}} \tag{8} θminE(x,y)∼Dinmin[−logFy(x)]+λ⋅Lencrgy(8)
-
其中F(x)是分类模型的softmax输出,Dtrain是分布内训练数据。总体训练目标结合了标准交叉熵损失,以及根据能量定义的正则化损失:
-
L e n e r g y = E ( x i n , y ) ∼ D i n t r a i n ( max ( 0 , E ( x i n ) − m i n ) ) 2 + E x o u t ∼ D o u t t r a i n ( max ( 0 , m o u t − E ( x o u t ) ) ) 2 ; ( 10 ) L_{\mathrm{energy}}=\mathbb{E}_{(\mathbf{x}_{\mathrm{in}},y)\sim\mathcal{D}_{\mathrm{in}}^{\mathrm{train}}}(\max(0,E(\mathbf{x}_{\mathrm{in}})-m_{\mathrm{in}}))^{2}+\mathbb{E}_{\mathbf{x_{out}}\sim\mathcal{D}_{\mathrm{out}}^{\mathrm{train}}}(\max(0,m_{\mathrm{out}}-E(\mathbf{x_{out}})))^{2}; \mathrm{(10)} Lenergy=E(xin,y)∼Dintrain(max(0,E(xin)−min))2+Exout∼Douttrain(max(0,mout−E(xout)))2;(10)
-
其中 D o u t t r a i n D^{train}_{out} Douttrain 是未标记的辅助OOD训练数据。特别是,我们使用两个平方铰链损失项 【我们还研究了铰链损耗,如 m a x ( 0 ; E ( x i n ) − E ( x o u t ) + m ) max(0;E(x_{in})-E(x_{out})+m) max(0;E(xin)−E(xout)+m),虽然 E(Xin) 和 E(xout) 之间的差值可以是稳定的,但它们的值并不稳定。利用两个独立的铰链损失项,优化更加灵活,训练过程更加稳定】 和 独立的裕度超参数 min 和 mout 来调整能量。在一个术语中,该模型惩罚产生高于指定余量参数min的能量的分布中样本。类似地,在另一项中,模型惩罚能量低于裕度参数mout的分布外样本。换句话说,损失函数以能量 E ( x ) ∈ [ m i n ; m o u t ] E(x)\in[m_{in};m_{out}] E(x)∈[min;mout]。一旦模型被微调,下游OOD检测类似于我们在第3.1节中的描述。
-
Experimental Results
- 在本节中,我们描述了我们的实验设置(第4.1节),并展示了我们的方法在广泛的OOD评估基准上的有效性。我们还进行了消融分析,以加深对我们方法的理解(第4.2节)。
Setup
-
分布内数据集:我们使用SVHN 、CIFAR-10 和CIFAR-100 数据集作为分布内数据。我们使用标准拆分,并分别用中的 Dtrain 和中的 Dtest 来表示训练集和测试集。
-
分布外数据集:对于OOD测试数据集Dtest out,我们使用六个常见的基准:Textures 、SVHN 、Places365 、LSUN-Crop 、LSUN-Resize 和iSUN 。所有图像的像素值通过 z 归一化进行归一化,其中参数取决于网络类型。对于辅助离群数据集,我们使用8000万幅微小图像,这是一个从网络上搜集的大规模、多样化的数据集。我们删除了该数据集中出现在CIFAR-10和CIFAR-100中的所有示例。
-
评估度量:我们测量以下度量:(1)当内分布样本的真阳性率为95%时,OOD样本的假阳性率(FPR 95);(2)受试者工作特性曲线下的面积(AUROC);以及(3)精确回忆曲线下的区域(AUPR)。
-
训练细节我们使用WideResNet 来训练图像分类模型。对于能量微调,Lenergy的权重λ为0.1。我们使用与Hendryks等人中相同的训练设置,其中历元数为10,初始学习率为0.001,余弦衰减,对于分布内数据,批次大小为128,对于未标记的OOD训练数据,批次大小为256。我们使用Hendrycks等人中的验证集来确定超参数:min选自 { − 3 ; − 5 ; − 7 } \{-3;−5;-7\} {−3;−5;−7} ,mout选自 { − 15 ; − 19 ; − 23 , − 27 } \{-15;−19;−23,-27\} {−15;−19;−23,−27} ;最小化FPR95的。min 和 mout 的范围可以分别围绕来自分布内和分布外样本的预训练模型的能量得分的平均值来选择。我们在附录b中提供了最佳保证金参数。
Results
-
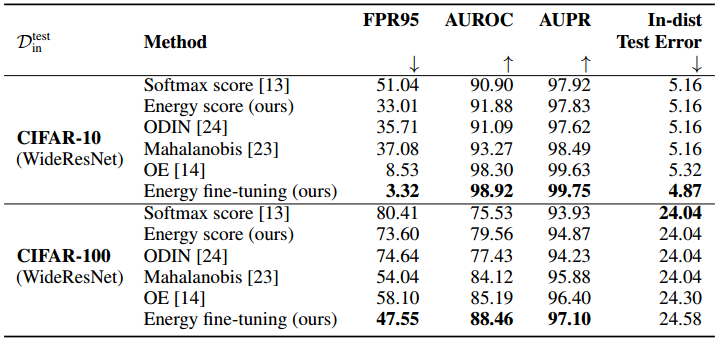
基于能量的OOD检测比基于softmax的方法更有效吗?我们首先评估能量分数相对于softmax分数的提高。表1包含CIFAR-10的详细比较。对于推断时间OOD检测(无微调),我们与softmax置信度得分基线进行比较。我们表明,与CIFAR-10上的基线相比,使用能量分数将平均FPR95降低了18.03%。表6提供了关于SVHN作为分布内数据的其他结果,其中我们显示能量得分始终比softmax得分高出8.69% (FPR95)。
-

-
表1:基于softmax和基于能量方法的OOD检测性能比较。我们使用WideResNet 在分布数据集CIFAR-10上进行训练。我们显示了使用预训练模型(顶部)和应用微调(底部)的结果。所有数值均为百分比。 ↑ \uparrow ↑ 表示值越大越好, ↓ \downarrow ↓ 表示值越小越好。粗体数字是优越的结果。
-
-
我们还考虑能量微调,并与离群值暴露(OE) 进行比较,离群值暴露将softmax概率调整为离群值训练数据的均匀分布。对于这两种方法,我们对相同的数据进行微调,并在学习速率和批量大小方面使用相同的训练配置。与OE相比,我们的能源微调模型在CIFAR-10上将FPR95降低了5.20%。这种改进在复杂数据集(如CIFAR-100)上更加明显,我们显示比OE提高了10.55%。
-
为了获得进一步的见解,我们比较了分布内和分布外数据的能量分数分布。图3 比较了能量和softmax得分直方图分布,它们来自预训练和微调的网络。从训练和OOD数据的预训练网络计算的能量分数自然形成平滑分布(见图3(b))。相比之下,分布内和分布外数据的softmax分数都集中在高值上,如图3(a)所示。总的来说,我们的实验表明,使用能量使分数在分布内和分布外之间更容易区分,因此,能够更有效地检测 OOD。
-

-
图3: (a和b)来自预训练WideResNet的softmax分数与energy分数的分布。我们对比了使用离群值暴露 ©和我们的能量有界学习(d)的微调模型的得分分布。我们对(b & d)使用负能量得分,以符合阳性(分布中)样本得分较高的惯例。使用能量分数会导致总体更平滑的分布(b & d ),并且不太容易受到softmax对分布内数据(a & c)表现出的尖峰分布的影响。
-
-
与竞争对手的 OOD 检测方法相比,我们的方法如何?在表2中,我们将我们的工作与文献中有竞争力的鉴别性OOD检测方法进行了比较。所有报告的数字都是六个OOD测试数据集的平均值。我们在附录a中提供了每个数据集的详细结果。我们注意到,使用预训练模型的现有方法需要调整超参数,有时需要借助附加数据和待训练的分类器(如Mahalanobis )。相比之下,在预先训练的网络上使用能量分数是无参数的,易于使用和部署,并且在许多情况下,实现了与ODIN相当甚至更好的性能。
-
-
表2:与基于判别的OOD检测方法的比较。 ↑ \uparrow ↑ 表示值越大越好, ↓ \downarrow ↓ 表示值越小越好。所有值都是百分比,是第4.1节中描述的六个OOD测试数据集的平均值。粗体数字是优越的结果。每个OOD测试数据集的详细结果可以在附录a中找到
-
-
在表3中,我们还与结合了生成建模的最新混合模型进行了比较 。由于在训练过程中使用了标记信息,这些方法比纯粹的基于生成模型的OOD检测方法 具有更强的基线。在这两种情况下(有和没有微调),我们的基于能量的方法优于混合模型。
-

-
表3:与基于生成的 OOD 检测模型的比较。值为AUROC。
-
-
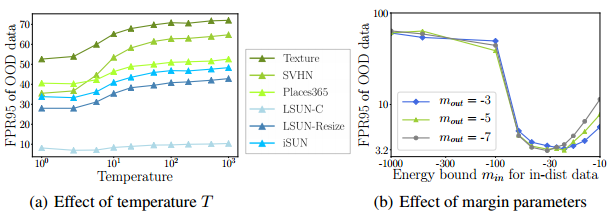
温度比例如何影响基于能量的OOD检测器?之前的工作ODIN 从经验和理论两方面表明,温度缩放可以提高非分布检测。受此启发,我们还评估了温度参数T如何影响我们基于能量的检测器的性能。应用温度T > 1将logit向量f(x)重新缩放1=T。附录A中的图4显示了当温度从T = 1升高到T = 1000时,FPR95的变化情况。有趣的是,使用较大的T会导致更均匀分布的预测,并使分布内和分布外示例之间的能量分数更难区分。我们的结果意味着可以通过简单地设置T = 1来无参数地使用能量分数。
-
-
图4: (a)我们显示了T对CIFAR-10预训练WideResNet的影响。FPR(在95% TPR时)随着t的增大而增大。(b)在能量微调期间容限参数min和mout的影响(WideResNet)。x 轴是对数刻度。
-
-
余量参数如何影响性能?图4(b)显示了在WideResNet上,能量微调(由FPR测量)的性能如何随着min和mout的不同余量参数而变化。总的来说,该方法对所选范围内的mout不太敏感。正如所料,对分布内数据施加太小的能量裕度最小值可能导致优化困难和性能下降。
-
能量微调会影响神经网络的分类精度吗?对于推理时间用例,我们的方法不改变预训练神经网络f(x)的参数,并保持其准确性。对于能量微调模型,我们在表2中比较了 f(x) 与其他方法的分类精度。当使用CIFAR-10作为 in-distribution 在WideResNet上训练时,我们的能量微调模型在CIFAR-10上实现了4.98%的测试误差,相比之下,OE微调模型的测试误差为5.32%,预训练模型的测试误差为5.16%。总的来说,这种微调提高了OOD检测性能,同时保持了几乎相当的内分布数据分类精度。
Related Work
-
预训练模型的分布外不确定性softmax置信度得分已成为 OOD 检测的常用基线。理论研究表明,具有ReLU激活的神经网络可以为OOD输入产生任意高的softmax置信度。DeVries和Taylor 提出通过将辅助分支附加到预训练的分类器并获得OOD分数来学习置信度分数。然而,以前的方法要么计算量大,要么需要调整许多超参数。相比之下,在我们的工作中,能量分数可以用作无参数测量,这在 OOD 不可知的设置中易于使用。
-
通过模型微调进行非分布检测:虽然不可能预测准确的OOD测试分布,但之前的方法已经探索了使用来自GANs的 人工合成数据 或 未标记数据 作为辅助OOD训练数据。辅助数据允许通过微调使模型显式规则化,从而降低异常示例的可信度 。损失函数用于迫使OOD样本的预测分布趋向均匀分布。最近,Mohseni等人通过为OOD分数增加额外的背景课程来探索训练。Chen等人 提出了通过对辅助OOD数据进行选择性训练来挖掘有用异常值的方法,这些辅助OOD数据会导致不确定的OOD分数,从而提高了对干净的和受干扰的对立OOD输入的OOD检测性能。在我们的工作中,我们将网络规则化,以在异常输入上产生更高的能量。我们的方法不改变语义类空间,并且可以在有和没有辅助OOD数据的情况下使用。
-
基于生成建模的非分布检测。生成模型 可以作为检测OOD样本的替代方法,因为它们可以直接估计分布内密度,如果测试样本位于低密度区域,则可以宣布其为分布外。然而,如 Nalisnick等人所示,深度生成模型可以将高可能性分配给非分布数据。使用改进的指标,包括似然比,深度生成模型可以更有效地进行分布外检测。虽然我们的工作是基于判别分类模型,我们表明,能量分数可以从数据密度的角度进行理论解释。更重要的是,基于生成的模型在训练和优化时会非常具有挑战性,尤其是在大型复杂数据集上。相比之下,我们的方法依赖于判别分类器,使用标准SGD可以更容易地优化它。因此,我们的方法继承了基于生成的方法的优点,同时避免了在训练生成模型时的困难的优化过程。
-
基于能量的学习基于能量的机器学习模型可以追溯到玻尔兹曼机器,即具有为整个网络定义的能量的单元网络。基于能量的学习 为许多概率和非概率学习方法提供了一个统一的框架。最近的工作也证明了使用能量函数来训练GANs ,其中鉴别器使用能量值来区分真实图像和生成图像。谢等人首先表明,生成随机场模型可以从判别神经网络中导出。在随后的工作中,谢等人 探索了使用EBM进行视频生成和3D形状模式生成。当Grathwohl等人 探索使用JEM进行OOD检测时,他们的优化目标是估计联合分布p(x;y)从生成的角度;他们在下游 OOD 检测中使用标准概率分数。相比之下,我们的训练目标是纯粹的区别,我们表明,非概率能量分数可以直接用作OOD检测的评分函数。此外,JEM 需要估计归一化密度,这可能是一个具有挑战性和不稳定的计算。相比之下,我们的公式不需要适当的标准化,并允许优化更大的灵活性。也许最重要的是,我们的 训练 目标直接优化了分布内和分布外之间的能量差距,这自然与基于能量分数的拟议 OOD 检测器相吻合。
Conclusion and Outlook
- 在这项工作中,我们提出了一个基于能量的非分布检测框架。我们证明了能量分数是softmax置信度分数的简单且有前途的替代。关键思想是使用非概率能量函数,该函数将较低值归属于分布内数据,将较高值归属于分布外数据。与softmax置信度得分不同,能量得分可证明与输入密度一致,因此,产生了显著改善的OOD检测性能。对于未来的工作,我们想探索使用基于能量的 OOD 检测超出图像分类任务。我们的方法对于主动学习等其他机器学习任务也是有价值的。我们希望未来的研究将从基于能源的角度增加对更广泛的OOD不确定性估计的关注。
Supplementary Material:
A Detailed Experimental Results
- 我们在表4 (CIFAR-10)和表5 (CIFAR-100)中报告了OOD检测器在六个OOD测试数据集上的性能。
-

-
表4:CIFAR-10作为每个 OOD 检测数据集的内部分布的 OOD 检测性能。Mahalanobis 得分是使用倒数第二个图层的 特征图 计算的。粗体数字是优越的结果。
-
B Details of Experiments
- 软件和硬件。我们使用PyTorch和NVIDIA Tesla V100 DGXS GPUs运行所有实验。评估运行次数。我们用固定的随机种子对模型进行一次微调。根据运行经验,每个OOD数据集的报告性能是10批随机样本的平均值。评估运行次数。我们用固定的随机种子对模型进行一次微调。根据运行经验,每个OOD数据集的报告性能是 10 批随机样本的平均值。单个GPU上的平均运行时间,能量微调的运行时间在6分钟左右;每个训练周期需要34秒。所有六个 OOD 数据集的评估时间约为 4 分钟。能量界限参数CIFAR-10的最佳最小值为 -23,CIFAR-100的最佳最小值为 -27。CIFAR-10 和 CIFAR-100 的最佳mout均为 -5。
-

-
表5:CIFAR-100对每个特定数据集的 OOD 检测性能。Mahalanobis 分数是根据倒数第二层的要素计算得出的。粗体数字是优越的结果。
-

-
表6:基于softmax和基于能量方法的OOD检测性能比较。我们使用WideResNet 仅使用其训练集在分布内数据集SVHN上进行训练。我们显示了使用预训练模型(顶部)和应用微调(底部)的结果。所有数值均为百分比。 ↑ \uparrow ↑ 表示值越大越好, ↓ \downarrow ↓ 表示值越小越好。粗体数字是优越的结果。
-

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 21
21 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)