【每天一种机器学习算法】逻辑回归+PCA的超强组合
逻辑回归和主成分分析(PCA)的结合方法在数学建模比赛中是非常适用的,尤其是在处理高维数据和复杂特征时,这种方法可以显著提升模型的性能和效率。
数学建模必备机器学习算法
逻辑回归+PCA,超实用组合!
逻辑回归和主成分分析(PCA)的结合方法在数学建模比赛中是非常适用的,尤其是在处理高维数据和复杂特征时,这种方法可以显著提升模型的性能和效率。
逻辑回归
逻辑回归算法(Logistic Regression)一般用于需要明确输出的场景,如某些事件的发生(预测是否会发生降雨)。通常,逻辑回归使用某种函数将概率值压缩到某一特定范围。例如,Sigmoid 函数(S 函数)是一种具有 S 形曲线、用于二元分类的函数。它将发生某事件的概率值转换为 0, 1 的范围表示。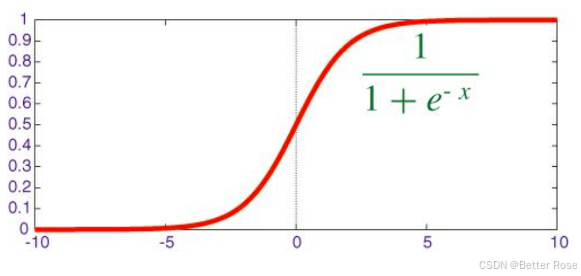
PCA(主成分分析)
PCA 是一种无监督的降维技术,旨在通过线性变换将原始数据转换为一组新的特征向量,即主成分。
这些主成分是原始特征的线性组合,它们按照方差大小进行排序,方差越大的主成分包含的原始数据信息越多。通过选择前几个主要的主成分,可以在保留大部分数据信息的同时降低数据的维度,从而减少数据的复杂性和噪声。
两者结合
适用性
1. 数据降维与特征提取
数学建模比赛中的数据往往具有高维性,特征之间可能存在冗余和相关性。PCA可以有效地降低数据维度,提取出最重要的特征,从而简化模型的复杂度。例如,在处理矿山监测数据时,PCA可用于降维和去噪。
2. 解决多重共线性问题
在多元回归分析中,特征之间的多重共线性会严重影响模型的稳定性和准确性。PCA通过将原始特征转换为正交的主成分,可以有效解决这一问题。
3. 提升模型效率和泛化能力
结合PCA后的逻辑回归模型在低维空间中训练,计算复杂度降低,训练速度加快,同时模型的泛化能力也得到提升。
比赛案例
- 在2025年五一数学建模竞赛的B题中,PCA被用于处理矿山监测数据的降维和去噪问题,逻辑回归可用于后续的分类或预测任务。
- 在其他数学建模比赛中,PCA和逻辑回归的组合也常用于处理高维数据的分类问题,例如预测用户行为或疾病诊断。
方法
首先对原始数据集进行 PCA 变换,得到降维后的主成分数据集。
然后,将这些主成分作为新的特征输入到逻辑回归模型中进行训练和预测。
在实际应用中,需要根据具体情况选择合适的主成分数量,以平衡数据信息的保留和模型的复杂度。
实战案例:乳腺癌预测
“维度削减+逻辑回归”:如何使用PCA大幅提升乳腺癌的预测成功率?
如何将PCA引入乳腺癌预测模型?
- 数据准备:收集和整理乳腺癌预测所需的特征数据,确保数据已经进行了预处理(如缺失值填充、标准化等)。
- PCA模型训练:使用原始特征数据训练PCA模型。在训练过程中,PCA会计算主成分的方差和协方差矩阵,并确定每个主成分的权重系数。
- 主成分选择:根据方差解释率或其他准则,选择保留的主成分数量。通常选择保留能够解释大部分数据方差(如80%以上)的主成分。
- 特征变换:将原始特征数据通过PCA模型进行转换,得到降维后的特征数据。这些降维后的特征即为选取的主成分。
【数据集准备】
library(survival)head(gbsg)
【结果展示】
pid age meno size grade nodes pgr er hormon rfstime status1
1 32 49 0 18 2 2 0 0 0 1838 0
2 1575 55 1 20 3 16 0 0 0 403 1
3 1140 56 1 40 3 3 0 0 0 1603 0
4 769 45 0 25 3 1 0 4 0 177 0
5 130 65 1 30 2 5 0 36 1 1855 0
6 1642 48 0 52 2 11 0 0 0 842 1
【示例数据集介绍】
> str(gbsg)
> 'data.frame': 686 obs. of 10 variables:
> $ age : int 49 55 56 45 65 48 48 37 67 45 ...
> $ meno : int 0 1 1 0 1 0 0 0 1 0 ...
> $ size : int 18 20 40 25 30 52 21 20 20 30 ...
> $ grade : int 2 3 3 3 2 2 3 2 2 2 ...
> $ nodes : int 2 16 3 1 5 11 8 9 1 1 ...
> $ pgr : int 0 0 0 0 0 0 0 0 0 0 ...
> $ er : int 0 0 0 4 36 0 0 0 0 0 ...
> $ hormon : int 0 0 0 0 1 0 0 1 1 0 ...
> $ rfstime: int 1838 403 1603 177 1855 842 293 42 564 1093 ...
> $ status : Factor w/ 2 levels "0","1": 1 2 1 1 1 2 2 1 2 2 ...
> age:患者年龄
> meno:更年期状态(0表示未更年期,1表示已更年期)
> size:肿瘤大小
> grade:肿瘤分级
> nodes:受累淋巴结数量
> pgr:孕激素受体表达水平
> er:雌激素受体表达水平
> hormon:激素治疗(0表示否,1表示是)
> rfstime:复发或死亡时间(以天为单位)
> status:事件状态(0表示被截尾,1表示事件发生)
【加载依赖库】
# 安装并加载所需的包
install.packages("factoextra") # 安装factoextra包
library(factoextra) # 加载factoextra包
【PCA主成分分析】
# 去除分类变量,PCA 主要负责处理连续型变量
data <- gbsg[,c(-1,-3,-9,-11)]
head(data)
# 执行 PCA
pca_result <- prcomp(data, scale. = TRUE) # 使用 prcomp 函数进行 PCA,scale. = TRUE 表示对数据进行标准化处理
# 获取分析结果
get_eig(pca_result)
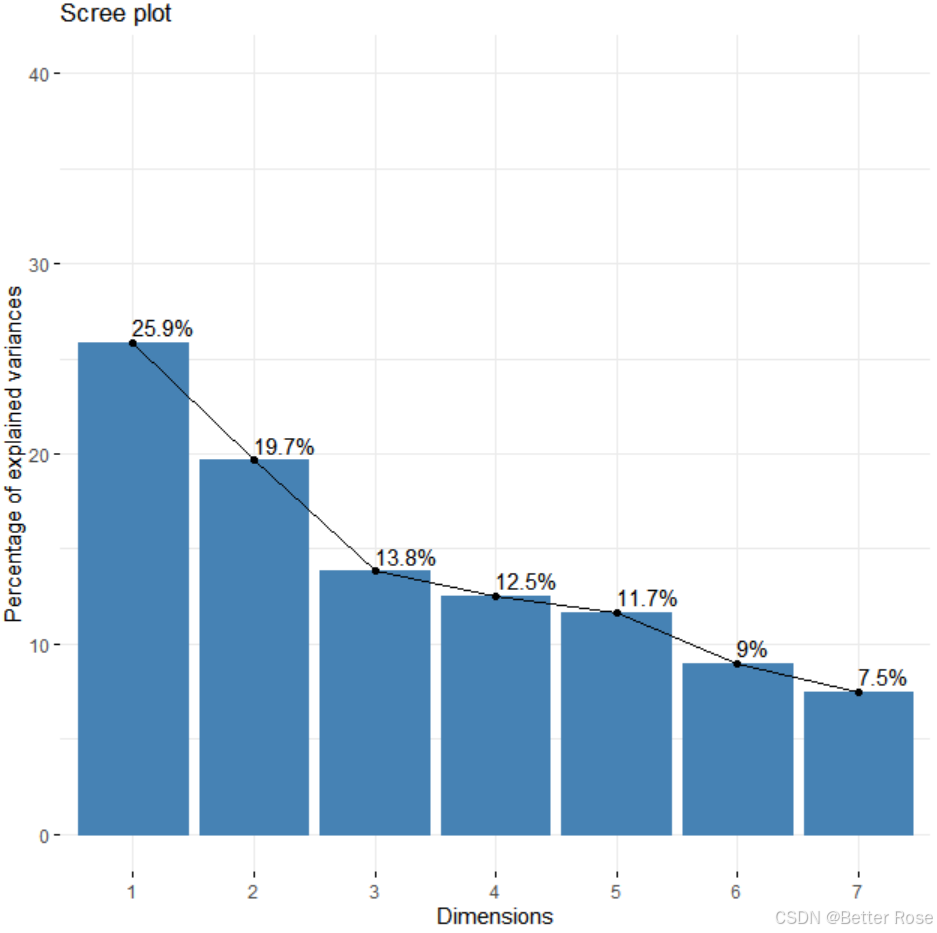
# 绘制方差贡献图
fviz_eig(pca_result, addlabels = TRUE, ylim = c(0, 40)) # 使用 fviz_eig 函数绘制累计方差贡献图
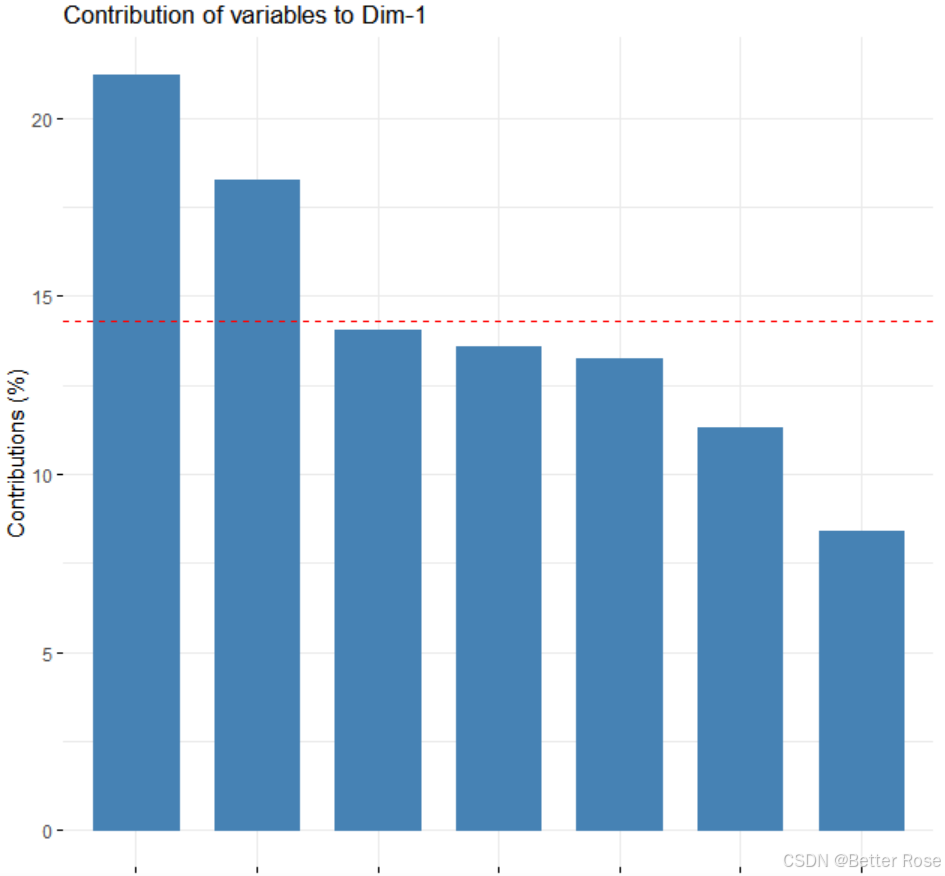
# 绘制主成分贡献度图
fviz_contrib(pca_result, choice = "var", axes = 1)
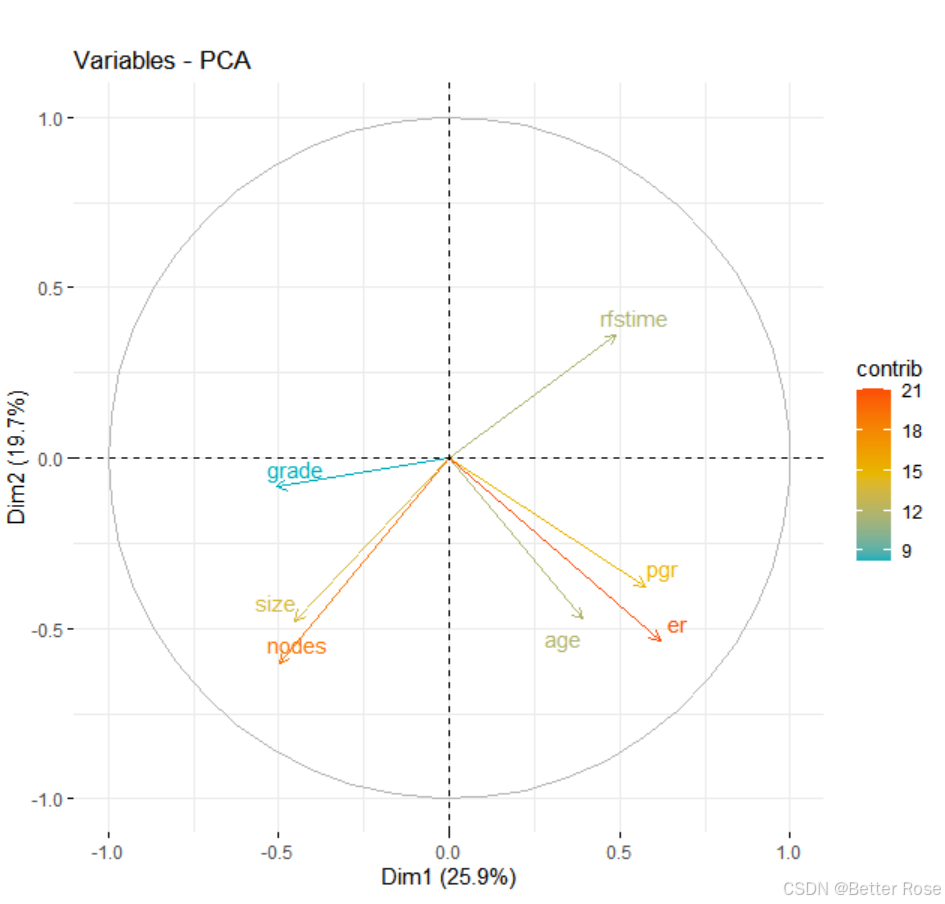
# 变量分别可视化
fviz_pca_var(pca_result,
col.var = "contrib",
gradient.cols = c("#00AFBB", "#E7B800", "#FC4E07"),
repel = TRUE)
# 样本 PCA 图
fviz_pca_ind(pca_result,
label = "none",
habillage = gbsg$age,
addEllipses = TRUE)
【结果展示】
> get_eig(pca_result)
eigenvalue variance.percent cumulative.variance.percent
Dim.1 1.8107476 25.867823 25.86782
Dim.2 1.3761590 19.659414 45.52724
Dim.3 0.9669035 13.812907 59.34014
Dim.4 0.8778691 12.540987 71.88113
Dim.5 0.8156392 11.651988 83.53312
Dim.6 0.6296778 8.995398 92.52852
Dim.7 0.5230038 7.471482 100.00000
【进行特征选择】
# 执行主成分分析
pca_result <- prcomp(data, scale = TRUE)
# 查看主成分的方差贡献度
variance_explained <- pca_result$sdev^2 / sum(pca_result$sdev^2)
# 排序主成分方差贡献度
sorted_variance <- sort(variance_explained, decreasing = TRUE)
# 设置保留的主成分数量或累积方差贡献度阈值
cumulative_threshold <- 0.95
# 根据累积方差贡献度阈值选择原始特征
cumulative_variance <- cumsum(sorted_variance)
selected_features_cumulative <- data[, 1:length(which(cumulative_variance < cumulative_threshold)) + 1]
# 打印选择的特征
colnames(selected_features_cumulative)
【结果展示】
> colnames(selected_features_cumulative)
[1] "size" "grade" "nodes" "pgr" "er" "rfstime"
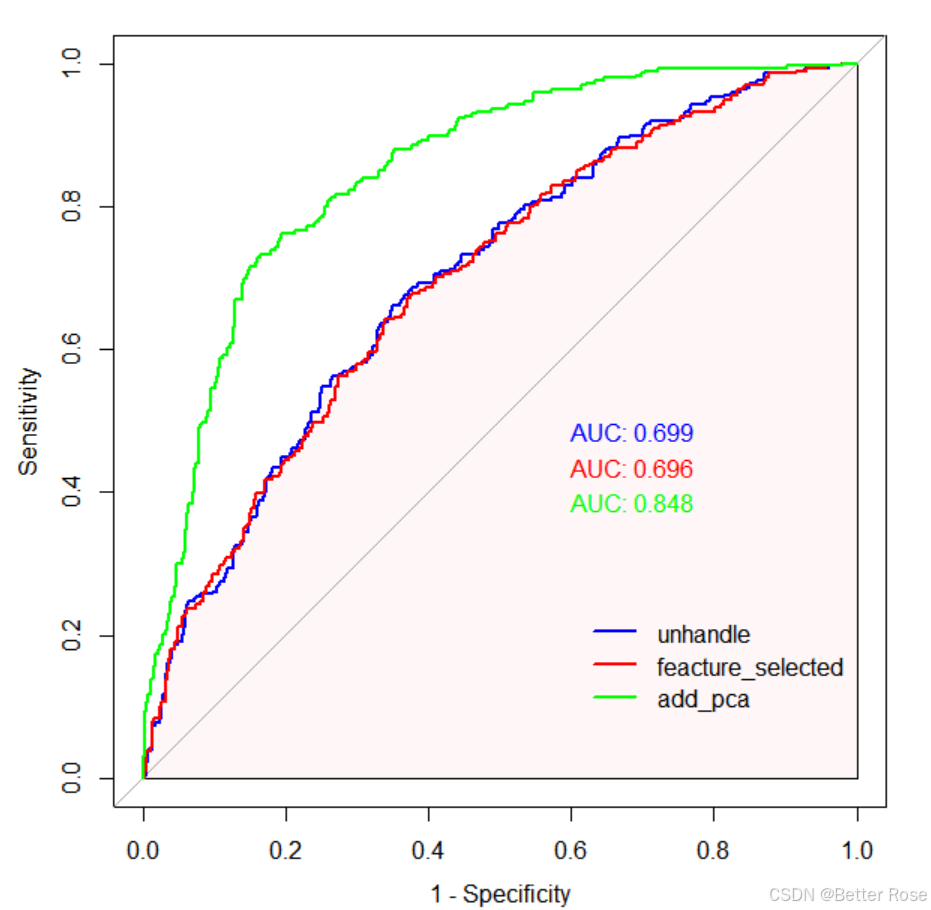
【模型拟合】
# 拟合未处理过的逻辑回归模型
model <- glm(status ~ age + meno + size + grade + nodes + pgr + er + hormon, data = gbsg, family = binomial)
# 拟合特征过滤后的逻辑回归模型
model_handle <- glm(status ~ meno + size + grade + nodes + pgr + er + hormon, data = gbsg, family = binomial)
# 拟合结合主成分结果的逻辑回归
n_components <- 3
selected_features <- pca_result$x[, 1:n_components]
data_with_pca <- cbind(gbsg, selected_features)
model_pca <- glm(status ~ ., data = data_with_pca, family = binomial)
# 使用逻辑回归模型进行预测
predictions <-
30种数学建模常用算法

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)