从数学原理到代码实现:线性回归推导全解析(附逐行代码映射)
本章介绍了机器学习中的线性回归模型,从数学原理到代码实现一站式解决
本文将以「单变量线性回归」为例,用「数学公式→自然语言→代码实现」的三重映射,带你从线性回归的核心原理一步步写出可运行的代码。即使你是数学小白,也能看懂每一步推导逻辑。
一、模型假设:用直线拟合数据的数学表达
1. 问题定义
我们有一组数据点 (xi,yi)(x_i, y_i)(xi,yi),其中:
- xix_ixi 是特征(如学习时间、房屋面积)
- yiy_iyi 是标签(如考试成绩、房价)
目标:找到一条直线 y=w⋅x+by = w \cdot x + by=w⋅x+b,使得这条直线尽可能接近所有数据点。
- www 是斜率(特征对标签的影响程度)
- bbb 是截距(当特征为0时的标签初始值)
2. 数学表达
模型的预测值为:
y^i=w⋅xi+b(1) \hat{y}_i = w \cdot x_i + b \quad \text{(1)} y^i=w⋅xi+b(1)
其中 y^i\hat{y}_iy^i 表示第 iii 个数据点的预测值。
二、损失函数:衡量预测误差的「标尺」
那么我们如何衡量模拟的好坏呢,答案就是损失函数,直接上图吧,就是图中实际值和模拟值的差值的平方和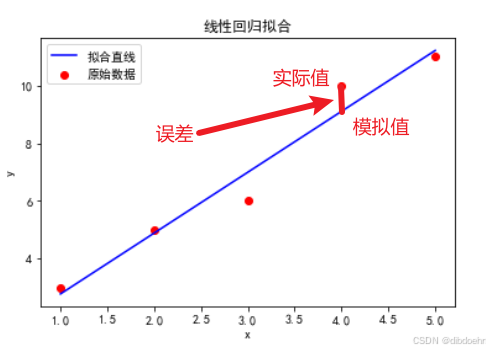
1. 误差定义
每个数据点的预测误差为:
误差i=y^i−yi=(w⋅xi+b)−yi(2) \text{误差}_i = \hat{y}_i - y_i = (w \cdot x_i + b) - y_i \quad \text{(2)} 误差i=y^i−yi=(w⋅xi+b)−yi(2)
我们希望所有数据点的误差总和最小,但直接相加会导致正负误差抵消,因此用平方误差放大差距:
平方误差i=(y^i−yi)2=(w⋅xi+b−yi)2(3) \text{平方误差}_i = (\hat{y}_i - y_i)^2 = (w \cdot x_i + b - y_i)^2 \quad \text{(3)} 平方误差i=(y^i−yi)2=(w⋅xi+b−yi)2(3)
2. 均方误差(MSE)
将所有平方误差求平均,得到损失函数:
L(w,b)=12m∑i=1m(y^i−yi)2=12m∑i=1m(w⋅xi+b−yi)2(4) L(w, b) = \frac{1}{2m} \sum_{i=1}^m (\hat{y}_i - y_i)^2 = \frac{1}{2m} \sum_{i=1}^m (w \cdot x_i + b - y_i)^2 \quad \text{(4)} L(w,b)=2m1i=1∑m(y^i−yi)2=2m1i=1∑m(w⋅xi+b−yi)2(4)
- mmm 是数据点数量
- 除以 222 是为了后续梯度计算时抵消平方的导数(简化计算)
三、梯度下降:让参数「自动优化」的数学原理
1. 优化目标
我们需要找到使损失函数 L(w,b)L(w, b)L(w,b) 最小的 www 和 bbb,即求解:
minw,bL(w,b) \min_{w, b} L(w, b) w,bminL(w,b)
2. 梯度计算(核心推导)
梯度是损失函数对参数的偏导数,代表函数增长最快的方向,我们沿负梯度方向更新参数以减小损失。
此部分数学知识可参考复合函数求导
(1)对 www 的偏导数
∂L∂w=1m∑i=1m(w⋅xi+b−yi)⋅xi(5) \frac{\partial L}{\partial w} = \frac{1}{m} \sum_{i=1}^m (w \cdot x_i + b - y_i) \cdot x_i \quad \text{(5)} ∂w∂L=m1i=1∑m(w⋅xi+b−yi)⋅xi(5)
推导过程:
- 对单个平方项求导:∂∂w(wxi+b−yi)2=2(wxi+b−yi)xi\frac{\partial}{\partial w} (w x_i + b - y_i)^2 = 2(w x_i + b - y_i) x_i∂w∂(wxi+b−yi)2=2(wxi+b−yi)xi
- 对所有项求平均并乘以 12m\frac{1}{2m}2m1 中的系数抵消,得到最终形式。
(2)对 bbb 的偏导数
∂L∂b=1m∑i=1m(w⋅xi+b−yi)(6) \frac{\partial L}{\partial b} = \frac{1}{m} \sum_{i=1}^m (w \cdot x_i + b - y_i) \quad \text{(6)} ∂b∂L=m1i=1∑m(w⋅xi+b−yi)(6)
推导过程:
- 对单个平方项求导:∂∂b(wxi+b−yi)2=2(wxi+b−yi)\frac{\partial}{\partial b} (w x_i + b - y_i)^2 = 2(w x_i + b - y_i)∂b∂(wxi+b−yi)2=2(wxi+b−yi)
- 同样抵消系数后得到平均误差和。
3. 参数更新公式
w=w−α⋅∂L∂w(7) w = w - \alpha \cdot \frac{\partial L}{\partial w} \quad \text{(7)} w=w−α⋅∂w∂L(7)
b=b−α⋅∂L∂b(8) b = b - \alpha \cdot \frac{\partial L}{\partial b} \quad \text{(8)} b=b−α⋅∂b∂L(8)
- α\alphaα 是学习率(控制步长)
- 每次迭代用梯度乘以学习率,更新参数值。
- 这里的=是赋值而不是相等
四、代码实现:将数学公式翻译成Python语言
1. 数据准备(对应模型假设)
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
matplotlib.rcParams['font.family'] = 'SimHei'
# 真实数据:x是特征,y是标签
x = np.array([1, 2, 3, 4, 5]) # 对应数学中的 x_i
y = np.array([3, 5, 6, 10, 11]) # 对应数学中的 y_i
m = len(x) # 数据量,对应公式中的 m
plt.autoscale(enable=True, axis='both', tight=None)
plt.scatter(x, y)
初始数据如图所示: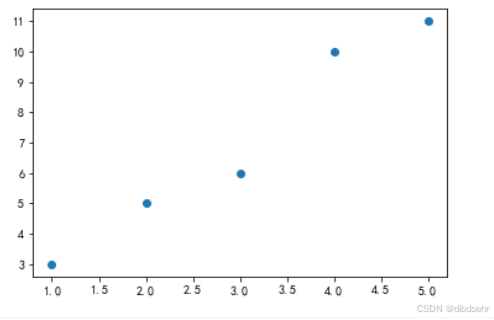
2. 参数初始化(给模型一个起点)
w = 0.0 # 初始斜率,对应公式中的 w(初始假设无影响)
b = 0.0 # 初始截距,对应公式中的 b(初始假设基线为0)
learning_rate = 0.01 # 学习率 α,控制参数更新步长
num_iterations = 1000 # 迭代次数,让模型学习1000次
3. 定义损失函数(实现公式4)
def compute_loss(w, b, x, y):
predictions = w * x + b # 对应公式1:ŷ_i = w·x_i + b
errors = predictions - y # 对应公式2:误差 = ŷ_i - y_i
squared_errors = errors ** 2 # 对应公式3:平方误差
loss = np.sum(squared_errors) / (2 * m) # 对应公式4:均方误差
return loss
4. 实现梯度下降(实现公式5-8)
def gradient_descent(w, b, x, y, learning_rate, num_iterations):
for _ in range(num_iterations):
predictions = w * x + b # 计算当前预测值(公式1)
# 计算梯度(公式5和公式6)
dw = (1/m) * np.sum((predictions - y) * x) # 对w的偏导数
db = (1/m) * np.sum(predictions - y) # 对b的偏导数
# 更新参数(公式7和公式8)
w = w - learning_rate * dw
b = b - learning_rate * db
return w, b # 返回最优参数
5. 训练模型(让参数「动起来」)
# 执行梯度下降
final_w, final_b = gradient_descent(w, b, x, y, learning_rate, num_iterations)
# 输出结果
print(f"最优斜率 w = {final_w}") # 输出:w = 2.1056062480285425
print(f"最优截距 b = {final_b}") # 输出:b = 0.6797596657640954
五、关键步骤的「数学→代码」映射表
| 数学公式 | 代码实现 | 说明 |
|---|---|---|
| y^i=w⋅xi+b\hat{y}_i = w \cdot x_i + by^i=w⋅xi+b | predictions = w * x + b |
向量化计算所有数据点的预测值 |
| L(w,b)=12m∑(y^i−yi)2L(w, b) = \frac{1}{2m}\sum(\hat{y}_i - y_i)^2L(w,b)=2m1∑(y^i−yi)2 | loss = np.sum((predictions - y)**2) / (2*m) |
均方误差的向量化实现 |
| ∂L∂w=1m∑(y^i−yi)xi\frac{\partial L}{\partial w} = \frac{1}{m}\sum(\hat{y}_i - y_i)x_i∂w∂L=m1∑(y^i−yi)xi | dw = (1/m) * np.sum((predictions - y) * x) |
梯度计算的向量化,避免循环 |
| w=w−α⋅∂L∂ww = w - \alpha \cdot \frac{\partial L}{\partial w}w=w−α⋅∂w∂L | w = w - learning_rate * dw |
参数更新,沿负梯度方向移动 |
六、可视化验证:看看模型是否真的在学习
1. 绘制损失函数下降曲线(新增代码)
# 在梯度下降函数中增加损失记录
def gradient_descent(w, b, x, y, learning_rate, num_iterations):
loss_history = []
for _ in range(num_iterations):
predictions = w * x + b
dw = (1/m) * np.sum((predictions - y) * x)
db = (1/m) * np.sum(predictions - y)
w, b = w - learning_rate*dw, b - learning_rate*db
loss = compute_loss(w, b, x, y)
loss_history.append(loss) # 记录每次损失
return w, b, loss_history
plt.plot(loss_history)
plt.title('损失函数随迭代次数的变化')
plt.xlabel('迭代次数')
plt.ylabel('损失函数值')
plt.show()
- 预期效果:损失值随迭代次数增加逐渐减小,最终趋于稳定,说明梯度下降有效。
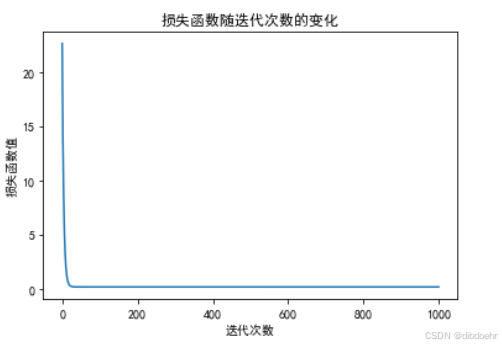
2. 绘制拟合直线(新增代码)
# 绘制原始数据和拟合直线
plt.scatter(x, y, color = 'red', label='原始数据')
plt.plot(x, w * x + b, color = 'blue', label='拟合直线')
plt.xlabel('x')
plt.ylabel('y')
plt.title('线性回归拟合')
plt.legend()
plt.show()
- 预期效果:蓝色直线穿过红色数据点集群,直观展示线性回归的拟合效果。
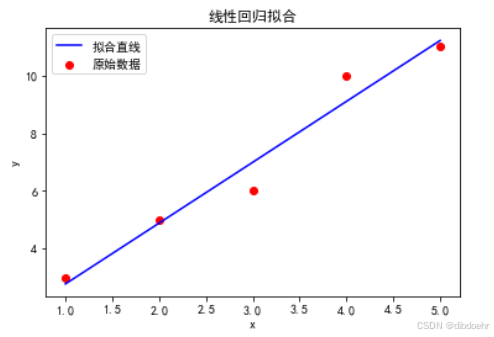
七、数学简化:为什么可以不用循环?
你可能注意到代码中没有显式循环每个数据点,这是因为使用了向量化运算:
(predictions - y) * x等价于对每个 iii 计算 (y^i−yi)xi(ŷ_i - y_i)x_i(y^i−yi)xi,然后求和- NumPy的向量化操作比Python循环快100-1000倍,这是机器学习代码的核心优化技巧
八、常见问题:从数学推导看代码陷阱
1. 学习率为什么不能太大?
- 数学角度:学习率 α\alphaα 是梯度下降的步长,若 α\alphaα 太大,可能导致参数更新时「跳过」最低点,损失函数反而上升(如 α=0.1\alpha=0.1α=0.1 时可能出现震荡)。
- 代码验证:将
learning_rate设为0.1,观察损失曲线是否发散。
2. 为什么损失函数要除以 2m2m2m 而不是 mmm?
- 数学推导:求导时,平方项的导数会产生系数2,除以2后梯度公式更简洁(如公式5、6中没有系数2)。
- 代码影响:不影响最终参数,因为梯度是比例缩放,学习率可以调整。
3. 为什么初始参数设为0而不是随机值?
- 单变量线性回归对初始值不敏感,但在神经网络等复杂模型中,初始值会影响收敛速度。
- 代码中设为0是为了简化,实际应用中常使用随机小值(如0.01)避免对称性问题。
九、总结:从原理到代码的三层映射
- 模型层:用数学公式 y=wx+by = w x + by=wx+b 描述问题
- 优化层:用均方误差定义损失,用梯度下降求解最优参数
- 代码层:用向量化运算实现数学公式,用迭代循环模拟参数更新过程
通过这种映射,你可以将任何机器学习算法从「纸上推导」转化为「可运行的代码」。线性回归的核心不是代码本身,而是理解「如何用数学描述问题→如何用优化方法求解→如何用代码高效实现」的完整逻辑。
本人也是初学者,如有错误,欢迎指正!

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐



 29
29 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)