深度Q网络DQN
DQN受max操作影响,估计的Q值往往会偏大,这是因为它是以下一时刻的状态St+1的Q值的最大值来估算的,但是St+1的Q值也是一个估算值,也依赖其下一个状态的Q值,由于误差传递,往往导致Q值偏大问题出现。含有多层激活函数的神经网络,能够实现非线性的函数逼近,是非常强大的函数逼近器。用两套神经网络分别来估计两个不同的Q函数,原来的神经网络训练Qw,然后固定住t时刻的Qw(左)的值,用另一个神经网络
一、核心思想和原理
1. 传统的强化学习会使用表格的形式来存储价值函数V(s)或者价值函数Q(s,a),这对于状态和动作空间比较小的情况尚且可以,但是当状态或动作空间过大时(比如一些强化学习任务,他的状态空间是连续的,故存在无穷多的状态),Q表格无法对价值函数存储。深度Q网络的核心思想就是将强化学习中的Q-Learing算法与深度神经网络相结合,用神经网络实现对高纬状态空间价值函数的近似。含有多层激活函数的神经网络,能够实现非线性的函数逼近,是非常强大的函数逼近器。
2. 模型结构
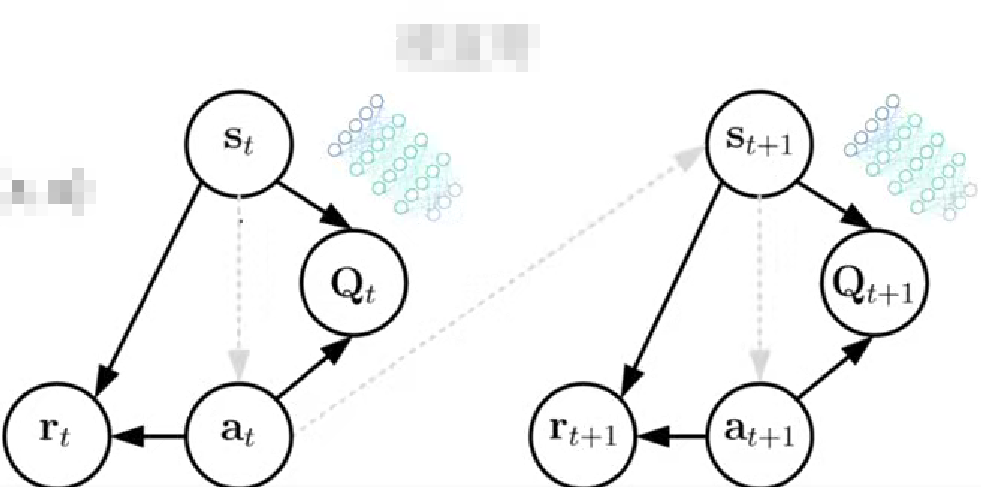
深度Q网络依然是Q-Learing算法,因此模型结构上与Q-Learing几乎是一样的。属于无模型结构,没有明确的状态转移。隐式的策略,依然属于基于价值的强化学习算法。根据Q函数直接求解动作,比如arg maxQ(s,a)。和传统的Q学习最大的区别就是价值函数这两条线,改用神经网络作为价值函数的函数逼近器,将状态和动作的组合作为输入,并输出相应的Q值进行估计。换句话说有如下的转换![]() ,其中w是神经网络的参数,参数再多也是有限的,其组成的网络却能模拟任意复杂的函数,完美解决了Q表格不够用的问题。神经网络本身结构与监督学习类似,但损失函数不同。监督学习中,通常有标注好的输入和相应的目标输出,通过最小化预测与目标函数之间的差异来进行训练,在强化学习中,使用奖励信号来指导网络学习,目标是最大化累计回报,就好比同样一把刀可以用来削苹果,也可以拿来剁肉一样。
,其中w是神经网络的参数,参数再多也是有限的,其组成的网络却能模拟任意复杂的函数,完美解决了Q表格不够用的问题。神经网络本身结构与监督学习类似,但损失函数不同。监督学习中,通常有标注好的输入和相应的目标输出,通过最小化预测与目标函数之间的差异来进行训练,在强化学习中,使用奖励信号来指导网络学习,目标是最大化累计回报,就好比同样一把刀可以用来削苹果,也可以拿来剁肉一样。
2. 目标函数
Q-Learing更新规则
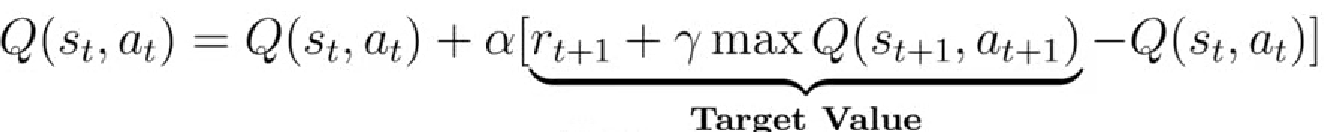
Q网络使用均方误差作为损失函数
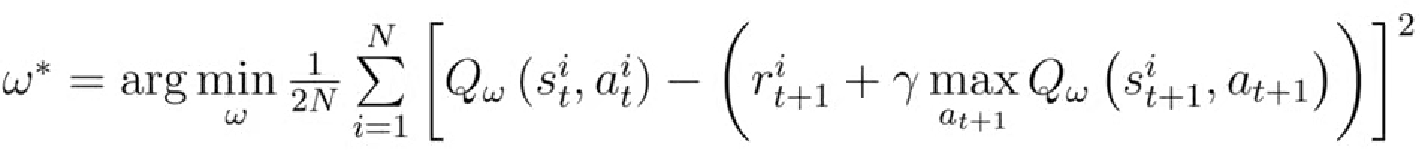
3. 经验回放(Experience Replay)
边训练边储存中间数据到经验池中,随着交互和训练的进行,经验池会被填满,经验数据也会不断更新和替换。
每次训练时,agent从经验池中随机抽样一批样本来进行训练,随机抽取可以提高样本的独立性,有效保证训练的稳定性和效率。使用经验回放策略有很多好处,首先是高效利用历史数据提高数据的使用率,避免在每次更新中只使用最新样本,极大缓解了强化学习中小样本喂不饱神经网络的难题。其次连续样本往往在时间上高度相关,可能导致训练过程中的偏差和不稳定,通过经验回放可以有效降低样本之间的相关性,使样本满足所谓的独立假设。最后是有助于在探索和利用之间寻找最佳的平衡。
4. 探索策略![]()
在深度Q网络DQN中,常用的探索策略是![]() ,这是一种基于贪心思想的策略,目的是平衡探索和利用之间的权衡。原理是以ε的概率随机探索,而以1-ε的概率选择Q值最高的动作进行利用。在初始阶段需要探索,因此可以选用较大的ε的值,随着训练进行,agent逐渐学习到更好地策略,可以逐渐减小ε值,增加利用的比例,以便更加依赖当前估计的Q值来选择动作。除了ε-greedy策略,DQN也可以使用其他的策略,比如贪心衰减策略、Softmax策略等等。策略π是更大意义上的概念,ε-greedy是一种具体的策略方法。探索策略发生在DQN的动作选择阶段,是在经验池之前进行的,这个过程就好比把不同的水倒进一个烧杯中,再倒进经验池子,在训练的时候在用勺子一勺一勺挖出来。
,这是一种基于贪心思想的策略,目的是平衡探索和利用之间的权衡。原理是以ε的概率随机探索,而以1-ε的概率选择Q值最高的动作进行利用。在初始阶段需要探索,因此可以选用较大的ε的值,随着训练进行,agent逐渐学习到更好地策略,可以逐渐减小ε值,增加利用的比例,以便更加依赖当前估计的Q值来选择动作。除了ε-greedy策略,DQN也可以使用其他的策略,比如贪心衰减策略、Softmax策略等等。策略π是更大意义上的概念,ε-greedy是一种具体的策略方法。探索策略发生在DQN的动作选择阶段,是在经验池之前进行的,这个过程就好比把不同的水倒进一个烧杯中,再倒进经验池子,在训练的时候在用勺子一勺一勺挖出来。
5. 目标网络(Target Network)
用两套神经网络分别来估计两个不同的Q函数,原来的神经网络训练Qw,然后固定住t时刻的Qw(左)的值,用另一个神经网络训练右边t+1时刻的目标Qw(右),前边网络中的参数每步都会更新,而后边目标网络中的参数隔几步才会更新。下图中右边的神经网络中的参数自己不会更新,只是隔几步把前边神经网络中的数值同步一下。
6. DQN的算法步骤(伪代码)

7. DQN的应用场景
DQN最适合离散的动作空间,因为agent需要从有限的动作集合中选择动作,用Q值函数来估计每个动作的价值,并选择具有最高Q值的动作。其次DQN适合大型状态空间的问题,和传统的Q-Learing相比使用深度神经网络作为函数逼近器,因此可以处理高纬连续的状态表示,从而扩展到更加复杂的问题。此外DQN能够处理存在延时奖励的问题,同时由于它利用了经验回放技术,随机抽样进行训练,这种数据复用机制吗,大大提高了数据训练的效率和样本的利用率。
二、DQN常见问题改进和扩展
1. 双深度Q网络DDQN
DQN受max操作影响,估计的Q值往往会偏大,这是因为它是以下一时刻的状态St+1的Q值的最大值来估算的,但是St+1的Q值也是一个估算值,也依赖其下一个状态的Q值,由于误差传递,往往导致Q值偏大问题出现。取max操作就好比是报喜不报忧,人传人,最后看似全部都是喜事,其实不然。会造成一种欺瞒上级的效果,于是DeepMind就想到了互相监督的点子双深度Q网络。核心思想如下:单一的Q网络容易出现报喜不报忧的情况出现,那就用两个参数不同的Q网络,恰好目标网络本身就已经用了两个网络,只不过target网络是定期拿前边网络参数来更新自己的参数,现在让两个网络的输入互相掺和。
PGM图解读:之前的DQN是右边的网络定期复制左边网络的参数,相当于束缚住右边的网络,优先更新左边的。现在两个网络都独立更新,可以认为先根据st+1和左边的Q网络来选择最大的动作,使用arg max操作。接着把找到的动作和st+1扔回到右边的Qt+1网络用于更新。换句话说之前右边的target网络,自己说啥就是啥,Q网络只有听的份儿,无法给自己的意见。现在Q网络不完全听他的了,先把状态st+1拿到手,自己生成最大值动作,然后在扔给右边的网络。等同于降低了对target网络的信任度,同时也减小犯错的几率。目标网络Q撇的更新方式变了,不是根据自己时刻的动作at+1,而是根据Q网络选择最大动作来更新。下边是目标Q值的更新公式
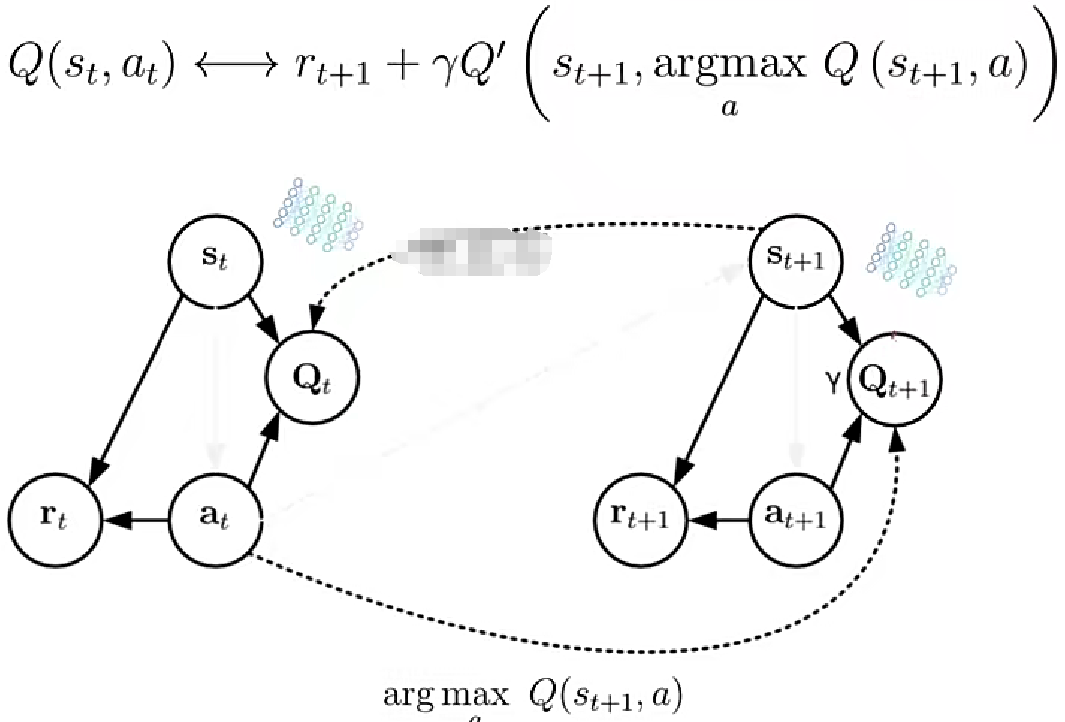
总的来说DDQN在网络结构上和DQN的没有差异,只是输入的连接方式变了。这一点点损失函数上微妙的变化,很好解决了DQN的Q值过大问题。
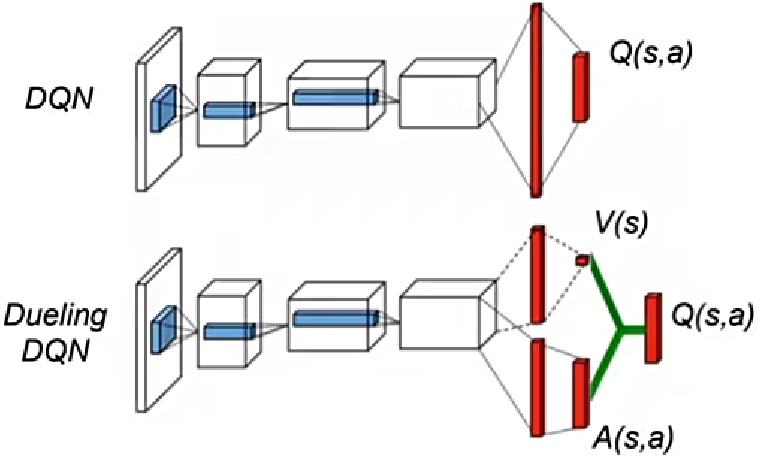
2. Dueling DQN
在传统的DQN算法中,每个动作价值Q(s,a)都需要进行计算,然而在某些情况下,评估状态价值并不需要每个动作的细节,因此会导致计算和存储的开销很大,尤其是在动作空间大的时候。如下图所示Dueling DQN通过对Q函数进行分解,将其表示为状态价值函数V(s)和动作优势A(s,a)之和的形式。其中A(s,a)表示在给定状态s下,动作a相对于其他可选动作在价值上的差异。
3. 噪声网络(Noisy DQN)
将高斯噪声直接添加到Q网络参数上,实现新动作对的探索效果。增加了探索能力,避免过早陷入孤独的行为模式,提供了算法的稳定性。
4. 优先级经验回放
打破均匀采样,赋予学习率高的状态以更大的采样权重
根据TD error确定权重,让优先级较高的经验样本更可能被选择

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐



 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)