【机器学习|学习笔记】 k-means 聚类(k-means clustering ,K-Means )详解,附代码。
【机器学习|学习笔记】 k-means 聚类(k-means clustering ,K-Means )详解,附代码。
·
【机器学习|学习笔记】 k-means 聚类(k-means clustering ,K-Means )详解,附代码。
【机器学习|学习笔记】 k-means 聚类(k-means clustering ,K-Means )详解,附代码。
欢迎铁子们点赞、关注、收藏!
祝大家逢考必过!逢投必中!上岸上岸上岸!upupup
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文。详细信息可关注VX “
学术会议小灵通”或参考学术信息专栏:https://blog.csdn.net/2401_89898861/article/details/147567533
前言
- k-means 聚类是一种经典的无监督学习算法,通过反复执行“分配—更新”两步迭代,将 n 个样本划分为 k 个簇,使得簇内样本到质心的平方距离和最小化。
- 该算法最早由 Lloyd 在1957年提出,并于1967年由 MacQueen 命名;2007年 Arthur 和 Vassilvitskii 提出 k-means++ 初始化方法显著提升了收敛速度和结果质量。
- k-means 算法因其简单高效,已在市场细分、图像分割、特征学习、天文学、能源负荷分析等众多领域得到广泛应用,并在大规模与高维场景中衍生出 mini‑batch 、X‑means 、bisecting 等多种改进变体。
起源
- k-means 算法最早可追溯到1957年 Stuart Lloyd 在 Bell Labs 为脉冲编码调制(PCM)问题而提出的最小平方量化方法,后于1982年以论文形式发表 。
- 1965年,Edward W. Forgy 独立提出了相同的合并策略,因此该算法也常被称为 Lloyd–Forgy 方法 。
- 1967年,James MacQueen 首次在其论文“Some Methods for Classification and
Analysis of Multivariate Observations”中使用了“k‑means”这一术语,为该方法命名 。 - 更早在1956年,数学家 Hugo Steinhaus 在集合划分的理论研究中提出了类似思想,但未形成具体算法 。
发展
- k-means++(2007):David Arthur 和 Sergei Vassilvitskii 提出一种随机但按距离加权的初始化策略,使最终结果在期望上达到 O(log k) 的近似比保证,显著降低了对初始质心的敏感性 。
- mini‑batch k-means:通过在每次迭代中仅使用数据子集进行更新,将计算和内存开销降至常数级,使算法可扩展到数亿样本 。
- X‑means 与 G‑means:在运行过程中自动估计最优簇数,通过统计检验或聚类分裂策略改进 k 的选择 。
- 全局优化与元启发式:如基于分支定界、半定规划、遗传算法、灰狼优化等方法,用于跳出局部最优 。
原理
- 目标函数: k-means 旨在最小化簇内平方和
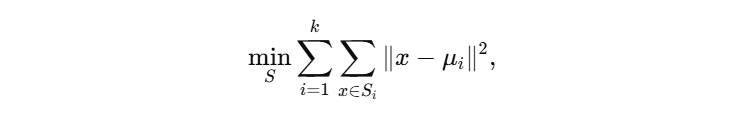
其中 μ i μ_i μi 为第 i 簇的质心 。 - 迭代过程(Lloyd 算法):
1.分配步:将每个样本指派到距离最近的质心所属簇 。
2.更新步:重新计算每个簇的质心为该簇所有样本的均值 。
如此循环,簇内平方和单调递减,直至收敛(簇分配不再变化或减幅低于阈值) 。
- 距离度量与链接:通常使用欧氏距离,也可推广到曼哈顿、余弦等度量;目标函数只对平方欧氏距离具有最优性。
应用
- 市场细分:将消费者按购买行为、人口统计学特征分组,用于精准营销 ;在线零售中分出“预算型”“高频”“大额”消费群,实现差异化推广 。
- 图像分割与压缩:在色彩空间对像素聚类,实现分区分割与调色板量化 ;视频编码中用于矢量量化 。
- 特征学习:作为字典学习步骤,将 k 个质心视为原子,后接线性分类器用于半监督或无监督学习 。
- 天文学谱分类:对恒星光谱或天体图像进行聚类,辅助识别天体类型 。
- 能源负荷剖面:对居民用电曲线聚簇,为需求响应和电网调度提供用户细分 。
- 网络安全与文档聚类:用于日志分析、异常检测、主题聚类等场景 。
Python 代码实现
下面示例展示如何使用 scikit‑learn 一行代码完成 k-means 聚类,并可视化结果。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
# 生成示例数据
X, y_true = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0)
# 构造并训练 k-means 模型
kmeans = KMeans(n_clusters=4, init='k-means++', n_init=10, random_state=0)
labels = kmeans.fit_predict(X)
# 绘制聚类结果
plt.scatter(X[:, 0], X[:, 1], c=labels, s=30, cmap='tab10')
centroids = kmeans.cluster_centers_
plt.scatter(centroids[:, 0], centroids[:, 1], marker='X', s=200, linewidths=3)
plt.title("K-Means Clustering Results")
plt.show()
init='k-means++'使用 Arthur & Vassilvitskii 的初始化方法 。n_init=10运行多次以避免陷入单次初始化的局部最优 。
该代码在200行以内即可对任意二维或高维数据进行高效聚类,并可通过 kmeans.inertia_ 获取最终簇内平方和,用于评估簇质量。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐



 17
17 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)