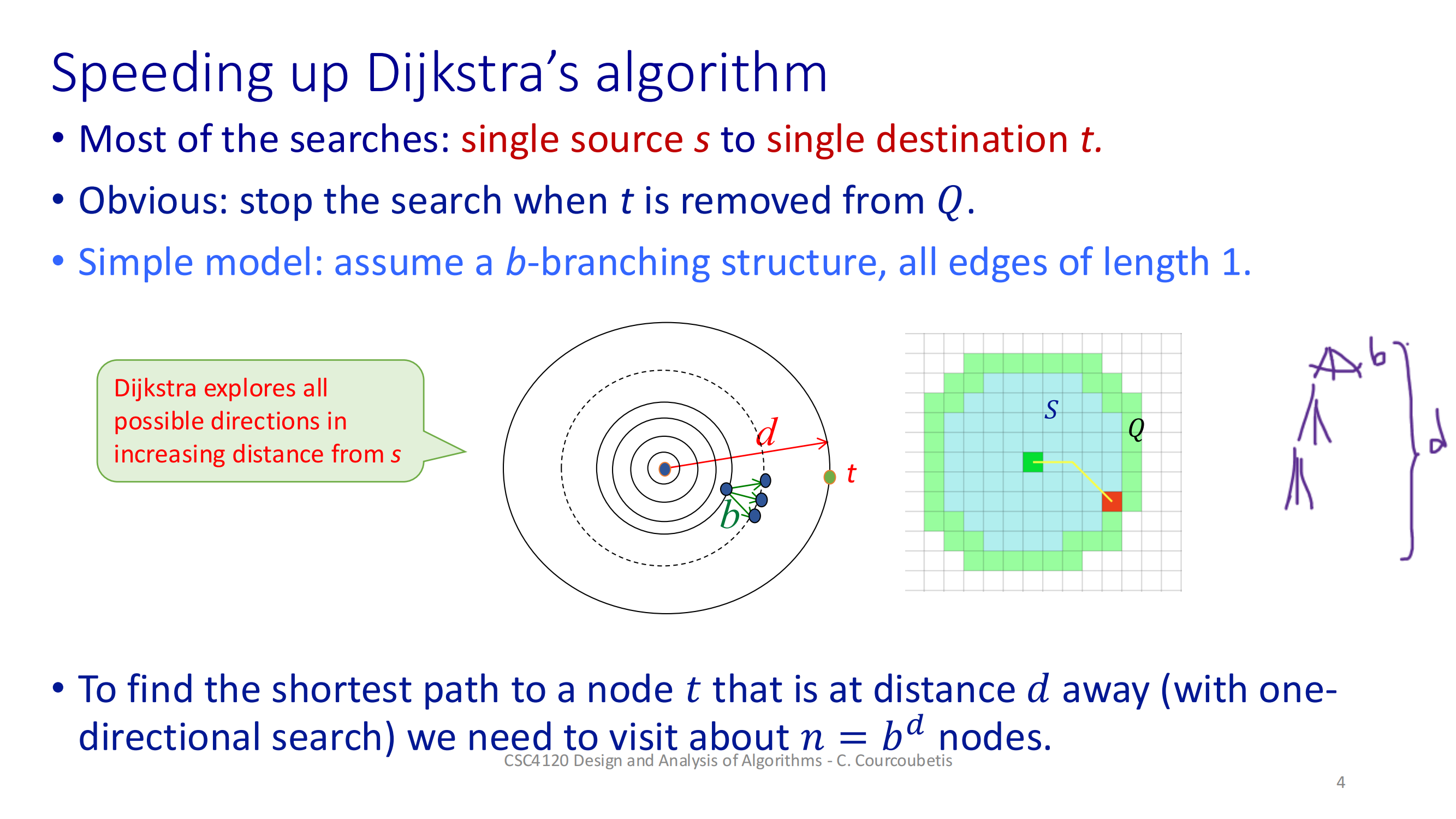
Dijkstra & A*
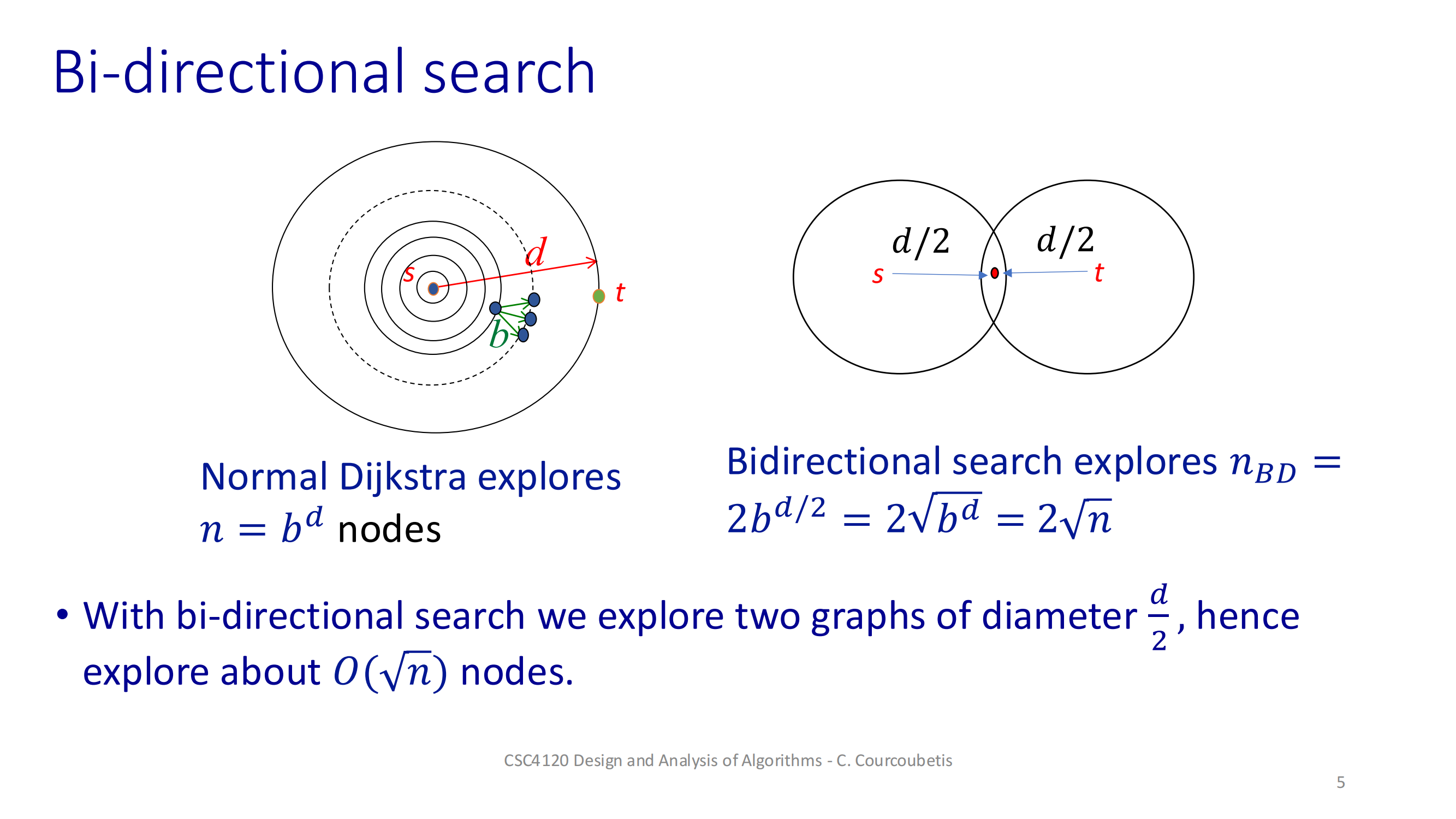
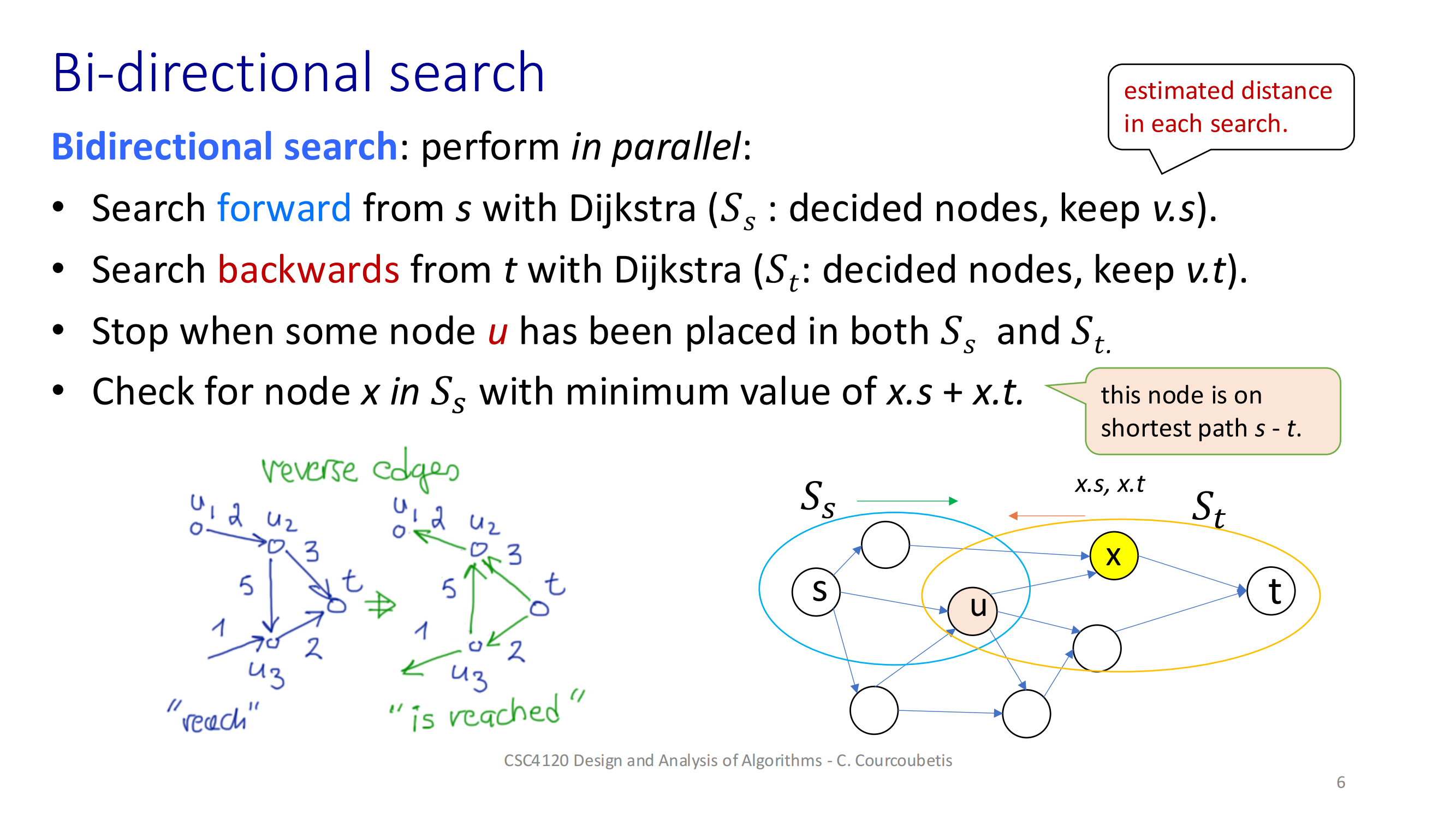
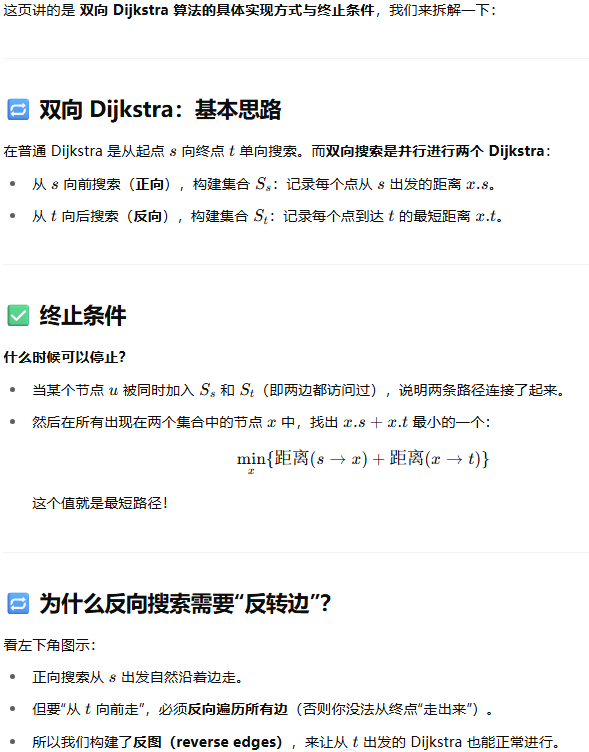
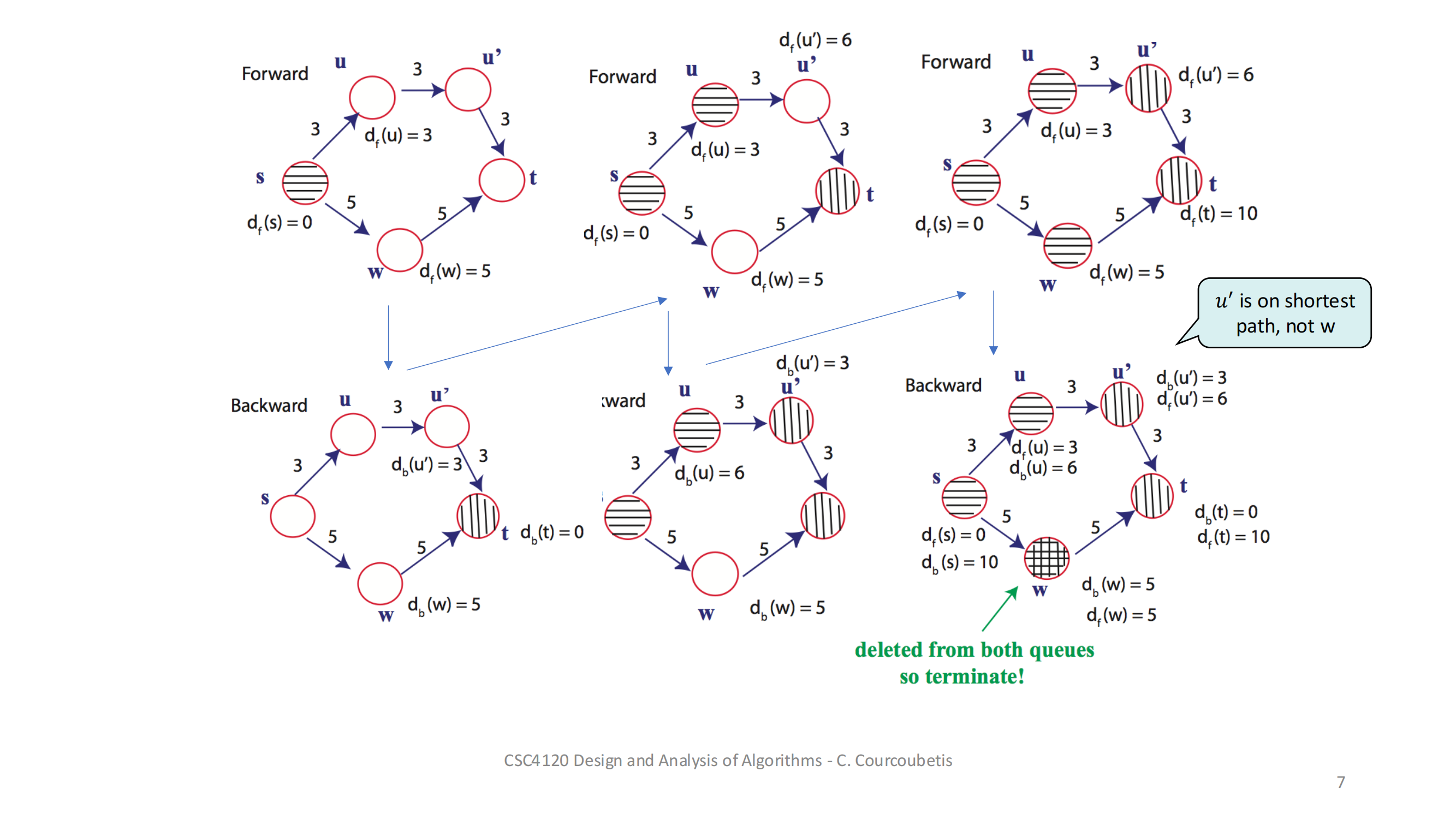
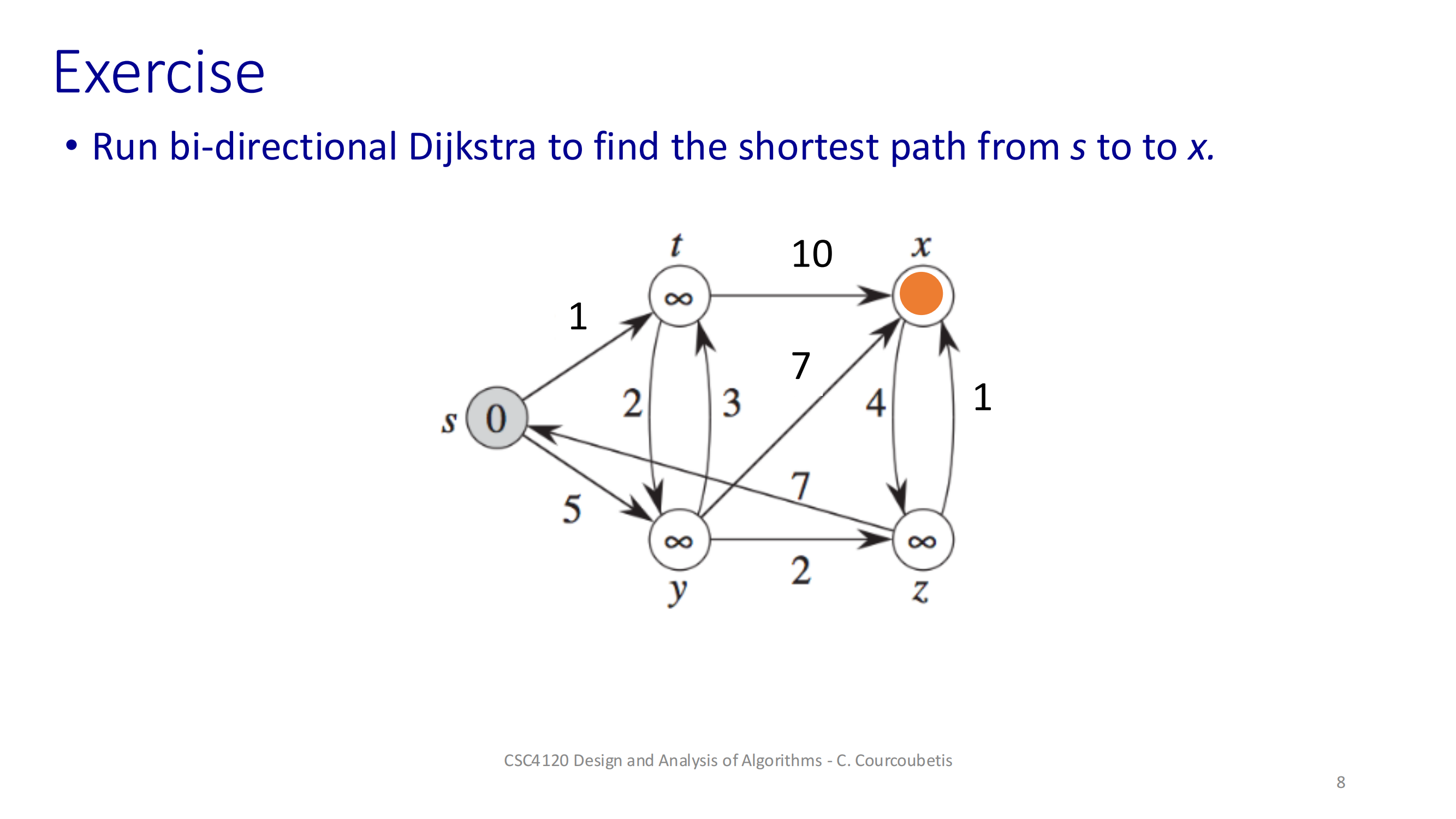
初始化两端距离和 μ交替弹出各自队列里最小 dist 的节点,做松弛每次如果两边访问到了同一个节点,就尝试更新 μ检查前向最小 + 后向最小 ≥ μ,就可以退出重建路径:从相遇点 y 往前、往后拼起来这样就能比单向 Dijkstra 更早“相遇”并停下来,节省一部分工作量。深入探讨 A* 搜索算法的一个重要变种——使用势函数 h(.) 的 A* 算法。这是一个在人工智能和路径规划中非常实用的主题,






⚠️ 注意:
-
双向搜索通常需要:
-
可逆边(也就是说,从终点 ttt 出发反向走也合法);
-
在两个搜索前沿相遇时有办法“合并”路径。
-
-
不适合所有图,比如:
-
有向图(不一定能从 ttt 回头);
-
启发式算法(例如 A*)不容易做双向版本。
-
1. 初始化:
μ = +∞
distₛ[s] = 0,其他 distₛ[*] = ∞
distₓ[x] = 0,其他 distₓ[*] = ∞
思路
-
μ 代表“到现在为止我们从 s 到 x 找到的最短路径长度”,一开始当然还没找到,设为无穷大。
-
distₛ[u] 是“从 s 出发到 u 的当前最优距离”,distₓ[v] 是“从 x 反向出发到 v 的当前最优距离”。
-
这俩都是 Dijkstra 的标准初始化。
对错
-
正确,这是双向 Dijkstra 的基础准备。
2. 松弛(Relax)公式:
前向搜索(F)松弛边 (u→v) 时用
如果 distₛ[u] + w(u,v) < distₛ[v]
那就更新:distₛ[v] = distₛ[u] + w(u,v)
后向搜索(B)松弛边 (v→u) 时用
如果 distₓ[u] + w(u,v) < distₓ[v]
那就更新:distₓ[v] = distₓ[u] + w(u,v)
思路
-
“松弛”就是看能不能经过当前节点 u 再走一条边到 v,得到更短的路线,就把 dist 更新一下。
-
前向和后向只是把边的方向反过来用,其他一模一样。
对错
-
完全正确,这是 Dijkstra 算法的核心。
3. 相遇(meeting)时更新 μ:
当 F 和 B 搜索都“访问”到同一个节点 y 的时候,出现了这样一个候选路径:
候选长度 = distₛ[y] + distₓ[y]
我们用 μ = min(μ, 候选长度) 来保存最优值。
思路
-
假设前向搜到了 y,花了 distₛ[y];后向也搜到 y,花了 distₓ[y]。那么 s→…→y→…→x 的总路程就是两者相加。
-
每次遇到新的相交点,就算一次“可能的全程”,取最小值。
对错
-
正确;这是双向 Dijkstra 找到全程路径的关键一步。
4. 停止条件:
min(F-PQ 中剩余节点的 distₛ)
+ min(B-PQ 中剩余节点的 distₓ)
>= μ
就可以停了,不用再继续松弛别的边。
思路
-
F-PQ(前向的优先队列)顶上的 distₛ[u] 一定是“前向还能拓展到的最小候选距离”;
-
B-PQ 顶上的 distₓ[v] 一定是“后向还能拓展到的最小候选距离”;
-
它们俩再加一起,如果都加起来都不可能比 μ(我们已经找到的最短 s→x)更小,那么不管怎么找,都不会出新的更短路径,安全地结束。
对错
-
正确,这是保证算法既能提早结束,又不丢失最优解的条件。
5. 具体数值示例(第 3 步遇到 y 时):
表里写
μ = distₛ[y] + distₓ[y] = 3 + 3 = 6
思路+对错
-
前向走 s→t→y,共 1 + 2 = 3;
-
后向走 x←z←y,也共 1 + 2 = 3;
-
所以拼起来是 6,这是目前找到的最短 s→x。
-
数值没跑错,就这么拼凑。
6. 为什么后面就不再更新 μ 了?
因为此时 F-PQ 中最小是 z:5,B-PQ 中最小是 t:5,
5 + 5 = 10 ≥ μ(=6)
“后面不会出现比 6 更小的组合”——算法就可以安全停。
思路
-
再往前向松弛,也得至少 5;后向最优也至少 5,合起来至少 10。
-
既然不可能更短,就没必要再搜。
对错
-
正确,满足双向 Dijkstra 的停机准则。
总结思路:
-
初始化 两端距离和 μ
-
交替 弹出各自队列里最小 dist 的节点,做松弛
-
每次 如果两边访问到了同一个节点,就尝试更新 μ
-
检查 前向最小 + 后向最小 ≥ μ,就可以退出
-
重建路径:从相遇点 y 往前、往后拼起来
这样就能比单向 Dijkstra 更早“相遇”并停下来,节省一部分工作量。

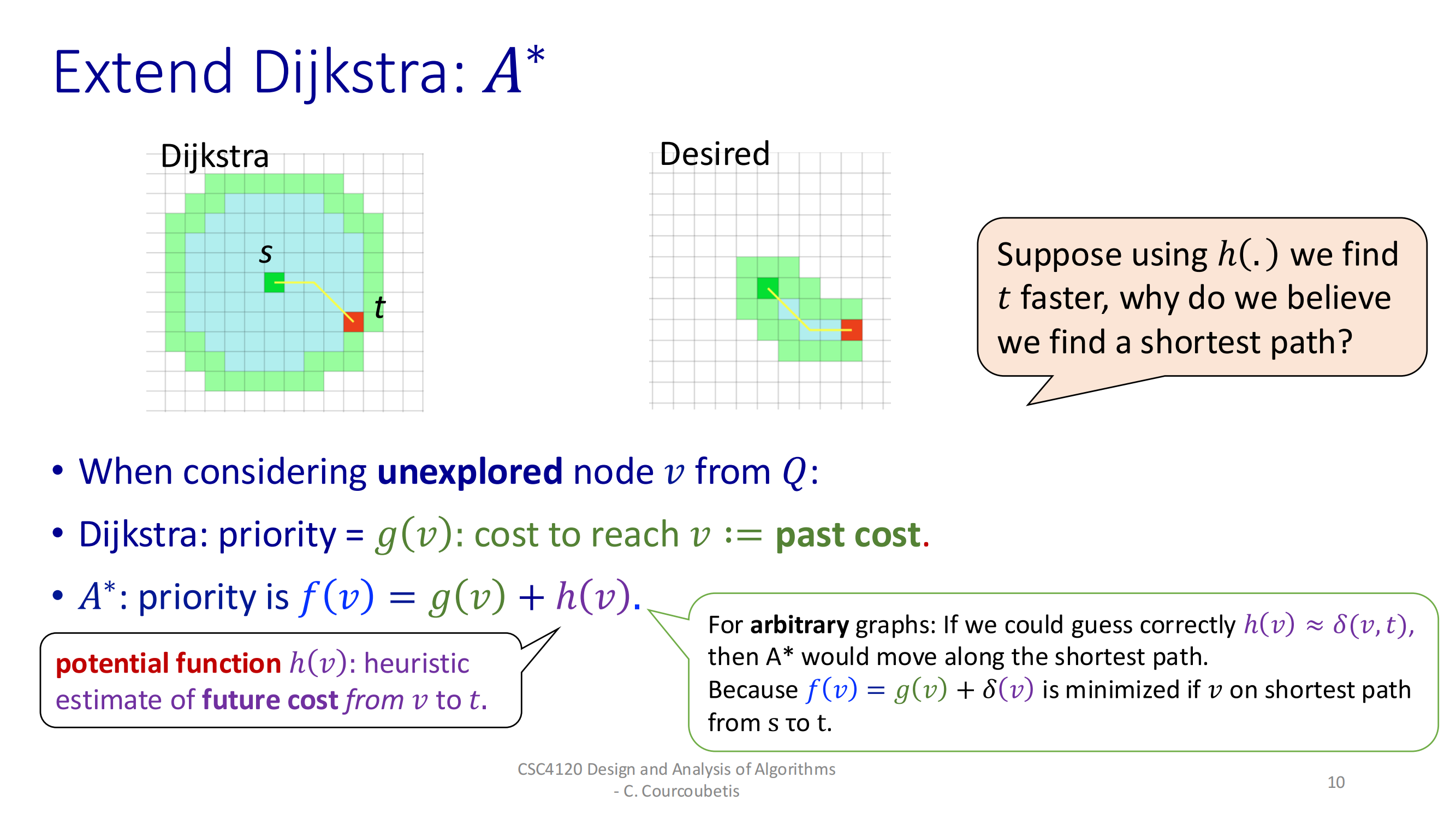

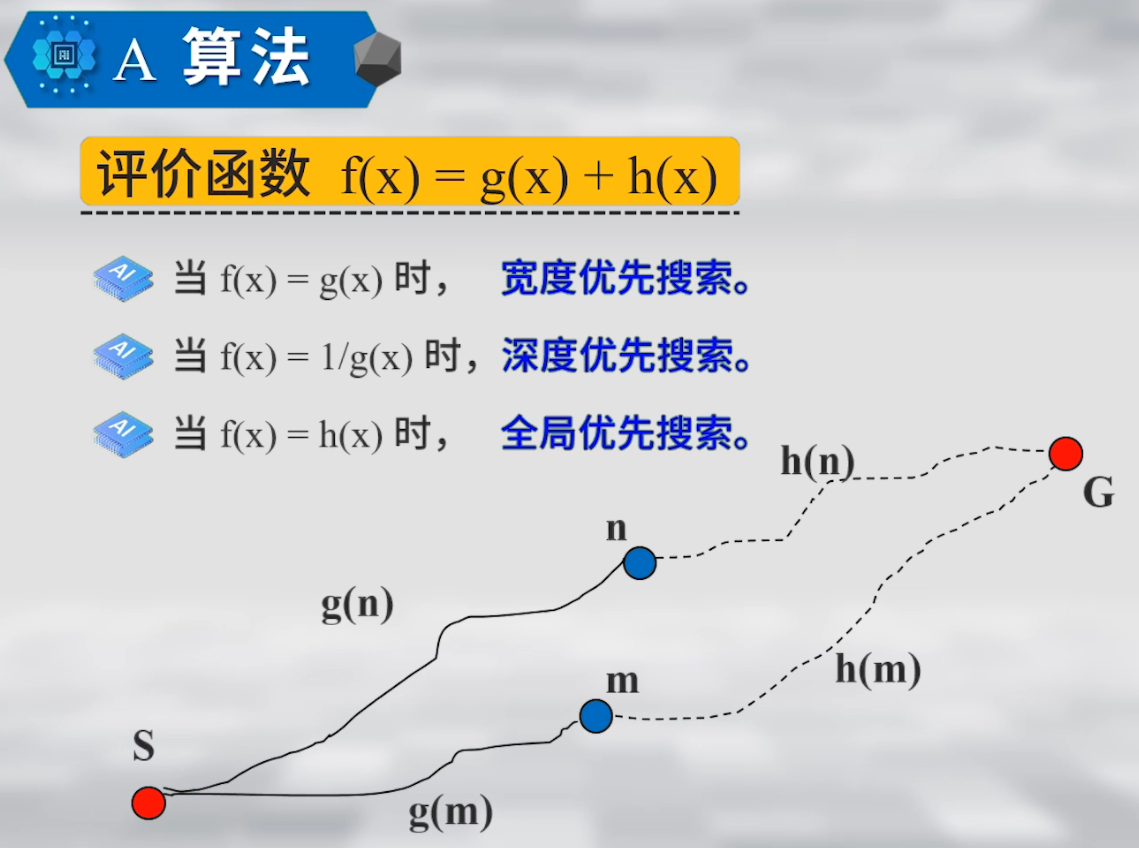
深入探讨 A* 搜索算法的一个重要变种——使用势函数 h(.) 的 A* 算法。这是一个在人工智能和路径规划中非常实用的主题,请大家集中注意力,我会尽量用简单的语言解释清楚。
基本概念
如图所示,A* 算法使用两个关键集合:
• Closed set (S): 已经确定最短路径的节点集合
• Open set (Q): 待考察的节点集合
这对于理解 A* 的工作流程至关重要。记住,这与我们之前学过的 Dijkstra 算法很相似,但有一些重要区别。
关键组成部分
-
g(v) 函数:表示从起点 s 到节点 v 的最短距离,且这个路径只经过已经确定最短路径的节点(即 S 中的节点)。
-
优先级规则:这是 A* 的核心!我们从 open set (Q) 中选择使 [g(un) + h(un)] 值最小的节点加入 closed set (S)。这个公式结合了:
• g(un):实际已经付出的代价• h(un):对剩余代价的估计
-
松弛操作:对节点 v 的所有后继节点进行松弛,注意这里包括已经在 S 中的节点。任何"严格"更新的后继节点会被重新放回 Q 中。
启发式函数的类型
右侧的信息框非常重要,它区分了两种启发式函数:
-
可采纳的启发式函数 (Admissible heuristic)
• 特点:如果目标节点 t 进入 S,那么 S 中的节点可能会回到 Q• 要求:h(v) ≤ δ(v,t),即估计值不超过实际最小代价
• 这是 A* 的典型情况,能保证找到最优解,但没有性能保证
-
一致的启发式函数 (Consistent heuristic)
• 特点:S 中的节点知道自己的最短路径,永远不会回到 Q• 要求:w_ij + h(uj) - h(ui) ≥ 0,这是三角形不等式的形式
• 一致性意味着可采纳性(一致性⇒可采纳性)
• 工作原理类似于 Dijkstra 算法
• 需要特殊工作来获取一致的启发式函数,且不总是实用的
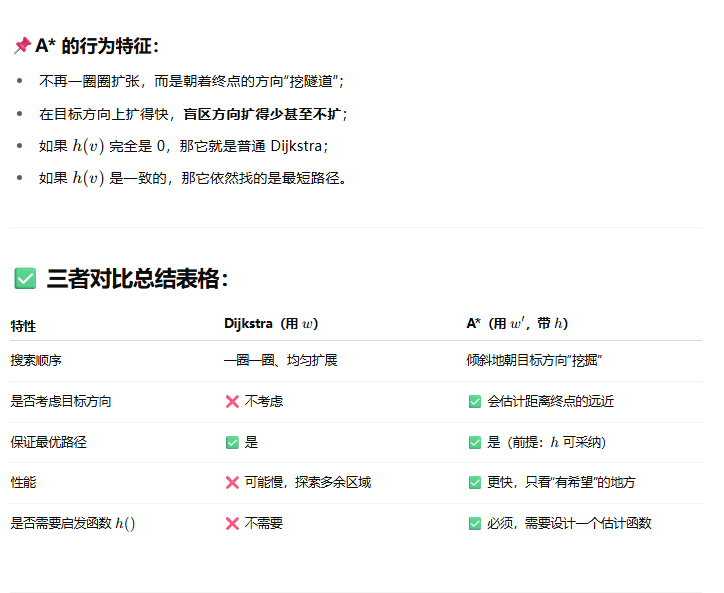
A* 与 Dijkstra 的关系
这是一个关键点,我来详细解释:
-
相似之处:
• 两者都使用优先队列来选择下一个要处理的节点• 两者都是贪心算法,试图扩展最有可能导致最短路径的节点
• 两者都需要维护已确定最短路径的节点集合
-
区别之处:
• Dijkstra 不使用启发式函数,等同于 A* 中 h(n)=0 的特殊情况• A* 使用启发式函数引导搜索方向,可以更高效地找到目标
• 当使用一致的启发式函数时,A* 实际上就是 Dijkstra 算法
-
为什么 A* 更高效:
• 启发式函数引导搜索朝着目标方向前进• 减少了需要扩展的节点数量
• 在很多情况下,可以找到最优解而不必探索整个图
实际应用示例
想象一下你要从北京到上海:
• Dijkstra 算法会平等地探索所有可能的路径
• 使用 A* 算法,你可以加入启发式函数 h(n) = 到上海的直线距离
• 这会优先探索那些看起来更接近上海的路径,大大提高搜索效率

1. g(v):记录“走过来的最短距离”
g(v) = 从 s 出发,经过 S(已关闭节点集)中的节点,到 v 的最短距离
-
思路:就跟普通 Dijkstra 里的
dist[v]一样,只不过这里我们把已经“敲定”进 S 的节点当作可靠节点,用它们去松弛新节点。 -
对错:完全正确,这是 A* 里评价“已经走到哪里”的标准。
2. f(n) = g(n) + h(n):优先级评分
选择 uₙ ∈ Q,使得 f(uₙ) = g(uₙ) + h(uₙ) 最小,把它从 Q 拉进 S
-
思路:
-
g(uₙ):你已经付出的“真是成本”
-
h(uₙ):你“预计还要付出”的“启发式估价”
-
把两者加起来,就估算了“从 s 经 uₙ 再到目标 t,总共要花多少”,每次先往“看起来最划算”的节点扩展。
-
-
对错:这正是 A* 的核心——综合真成本和估成本来导引搜索。
3. 松弛所有后继,包括已在 S 的节点
“Relax all successors of v, including nodes in S. All the ‘strictly’ updated successors of v are put back to Q.”
-
思路:
-
普通 Dijkstra 只松弛 Q 中的后继,A* 由于启发式可能让已关闭的节点(S 中)变得“更有希望”,所以也要把它们再松弛一次,如果距离真的比之前记录的小,就要把它们重新丢回 Q。
-
-
对错:
-
如果你用的是可采纳但不一致的启发(见下面),就必须这样才能保证“不会漏掉更优”——正确但可能性能差。
-
如果你用的是一致性好的启发,就不用回头松弛 S 中的节点,效率更好。
-
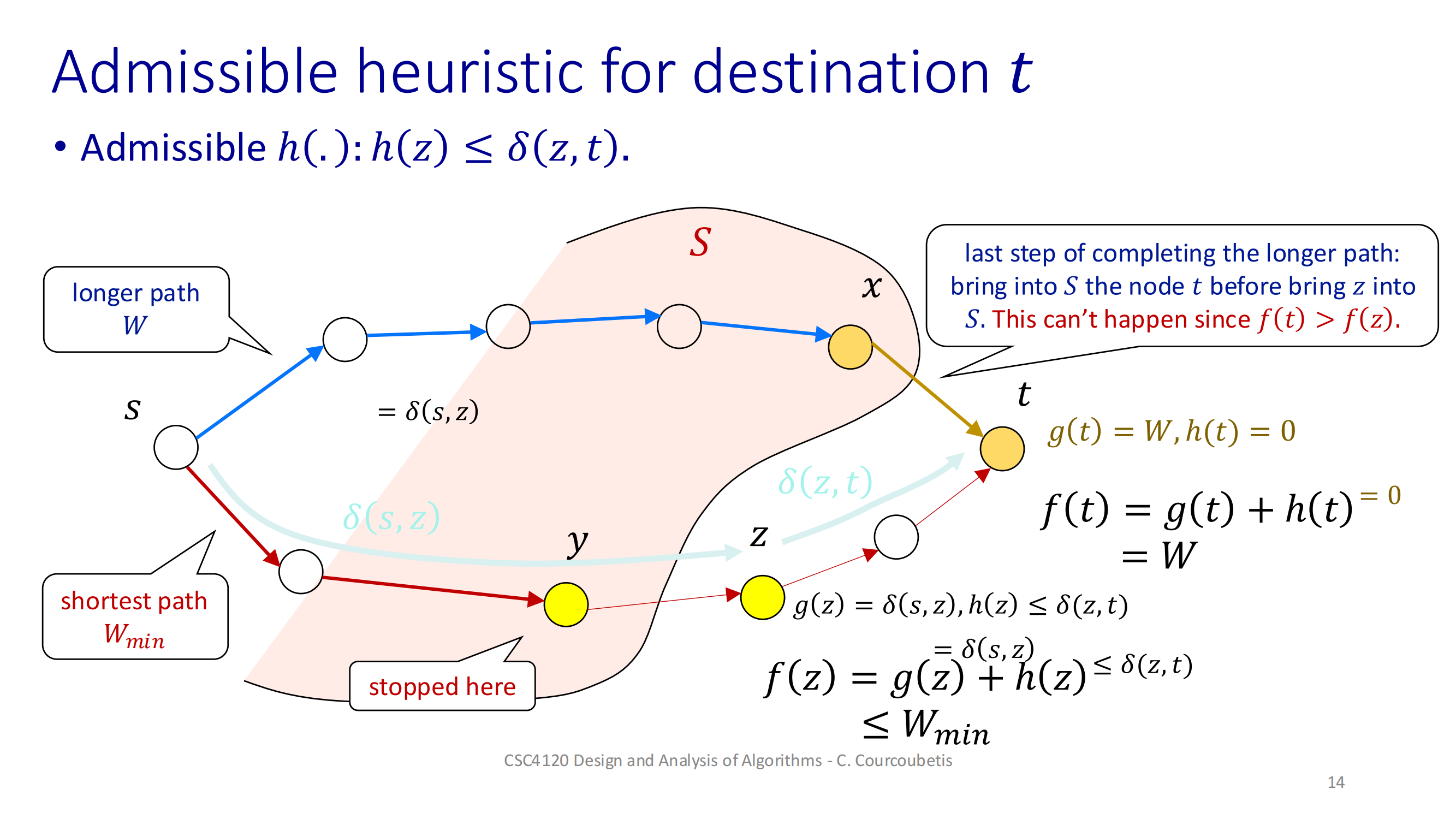
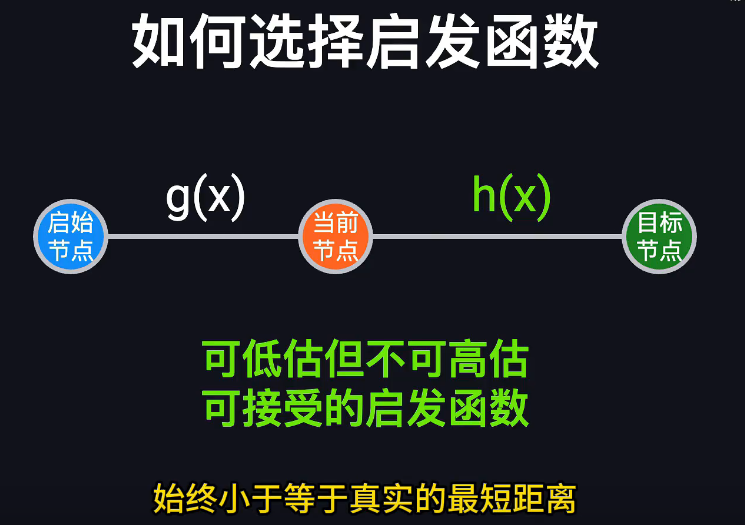
4. 可采纳(Admissible)启发式
h(v) ≤ δ(v, t) ∀ v
-
δ(v, t) 表示从 v 到目标 t 的真实最短距离。
-
思路:保证你的估价永远不会高估真实成本,才不会误导搜索“看起来比真实更糟”而跳过最优路径。
-
对错:
-
正确且必要,只要满足这个条件,A* 就能保证一旦 t 被拉进 S,那条路一定最短。
-
但不保证“每次都不回头”,可能会反复把节点从 S 丢回 Q,性能没有上界。
-
5. 一致(Consistent,又叫 Monotone)启发式
wᵢⱼ + h(uⱼ) − h(uᵢ) ≥ 0 ∀ 边 (uᵢ → uⱼ)
-
思路:这条不等式等价于
h(uᵢ) ≤ wᵢⱼ + h(uⱼ)
→ “从 uᵢ 估价到 t,先走一条边到 uⱼ 再估价,不会更便宜”。
换句话说,沿着边走,估价只能“往上爬”或“持平”,不会突然降下来。
-
对错:
-
正确,而且比可采纳更强;满足它就自动满足 h(v) ≤ δ(v,t),所以一致性蕴含可采纳。
-
好处:一旦节点被放到 S,就再也不会被回滚到 Q,等同于把 A* 当成带启发的 Dijkstra,性能有保证。
-
坏处:要想出一个一致的 h() 往往很费事,不是所有场景都好做。
-
6. 答案正确性 & 性能对比
| 条件 | 正确性 | 性能保障 | 会不会回滚 S 中节点? |
|---|---|---|---|
| 可采纳 h | ✔️ 保证最短路径 | ❌ 无最坏情况时间界 | 会,有可能反复回滚 |
| 一致 h | ✔️ 保证最短路径 | ✔️ 类似 Dijkstra 时间界 | 不会,放进 S 就一锤定音 |
总结
-
记录真实走过来的成本 g(v),再加上对未来的估计 h(v),得到 f(v)=g(v)+h(v)。
-
每次取 f 最小的节点 扩展,就像告诉你“这个节点最有希望通往目标”。
-
如果你保证 h(v) 永远不高估(可采纳),就能保证找到最短路;
如果你又能让 估价沿边单调不下降(一致性),搜索效率更稳定。 -
不一致的可采纳虽然也能找到最优解,但会经常“回头改记录”,开销没法预估;一致的启发则更像“镶了程序员自己的权重版 Dijkstra”,效率有保证。


✅ 中文翻译(逐句翻)
标题:下一页内容预告(Next slides)
在接下来的几页里,我们将分析 A* 算法在假设启发函数 h(.)h(.) 满足更强的一致性(consistent heuristic)条件下的行为。
第2句:实际应用中的假设
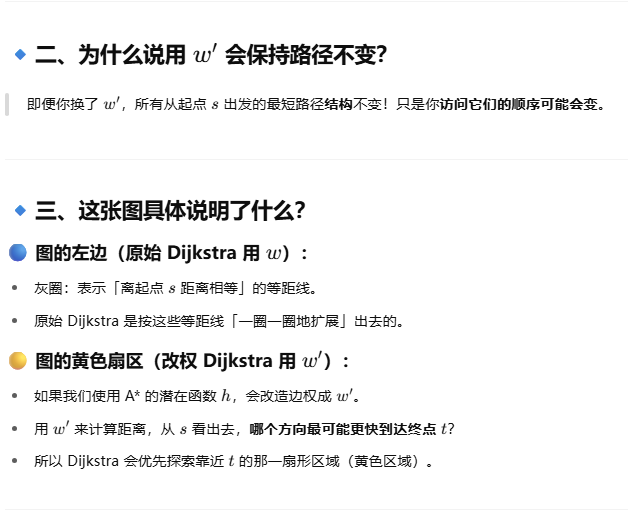
在实际中,A* 通常被认为使用的是“可采纳”的启发式函数。这种做法更常见,因为 A* 常被用于欧几里得图(比如地图导航),而此时 h(v)h(v) 可以简单地用点 vv 到目标 tt 的欧几里得距离来估计。
第3句:可采纳情况的分析结果
因此,在典型的 A* 中,只要启发函数是可采纳的,我们就可以保证找到正确答案(也就是找到最短路径),但没有性能保证(也就是说,算法最坏情况下时间复杂度无法界定):
某些节点可能会反复加入或移出已关闭集 SS;
并且我们无法确定这种“进进出出”最多可能发生多少次;
当某个节点(除了目标 tt)被加入 SS 时,我们仍不能确定它的最短路径就已找到,因为以后可能会出现更短路径;
只有目标 tt 被加入 SS 时,才能 100% 确定找到了从 ss 到 tt 的最短路径。
第4句:一致性条件下的好处
如果 h(.)h(.) 是一致的,那么集合 SS 是稳定的:每一个被加入 SS 的节点,其从起点 ss 出发的最短路径已经确定,并且一定是通过 SS 中的节点路径得到的。
🧠 通俗解释:
🌟 A* 用“可采纳”启发式时的优缺点:
-
✅ 优点:能保证你找到的路径是最短的(只要 h(v)≤h(v)\le 到目标的真实最短距离)。
-
❌ 缺点:性能可能很差,因为:
-
节点可以被反复放进放出 SS(就像思路反复试探);
-
没有“最多扩展几次”的保证;
-
除了目标节点 tt,其他节点加入 SS 时,不能保证就找到了它的最短路径。
-
✅ 如果你用“一致”的启发式:
-
每次进入 SS 的节点,一定是“最终解”,以后不会被更新或推翻;
-
就像 Dijkstra 一样,队列中最小的就是“终极答案”;
-
整个过程变得稳定高效,能提前结束很多搜索分支。
📌 总结一行话:
“可采纳 h() 保证找对路径,一致 h() 还能保证高效率。”



 🌟 如果我们用一个一致的启发式 hhh,对边权进行某种“平移变换”,那么最短路径不会变,只是路径的代价整体被加上了一个常数而已。
🌟 如果我们用一个一致的启发式 hhh,对边权进行某种“平移变换”,那么最短路径不会变,只是路径的代价整体被加上了一个常数而已。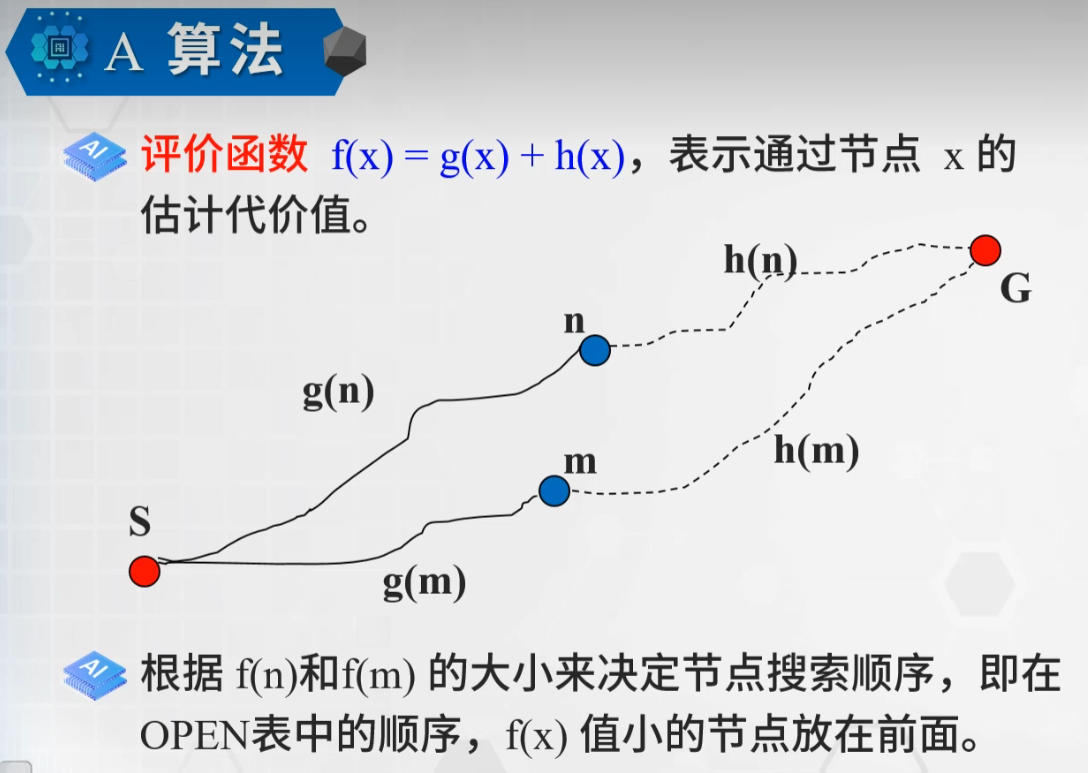


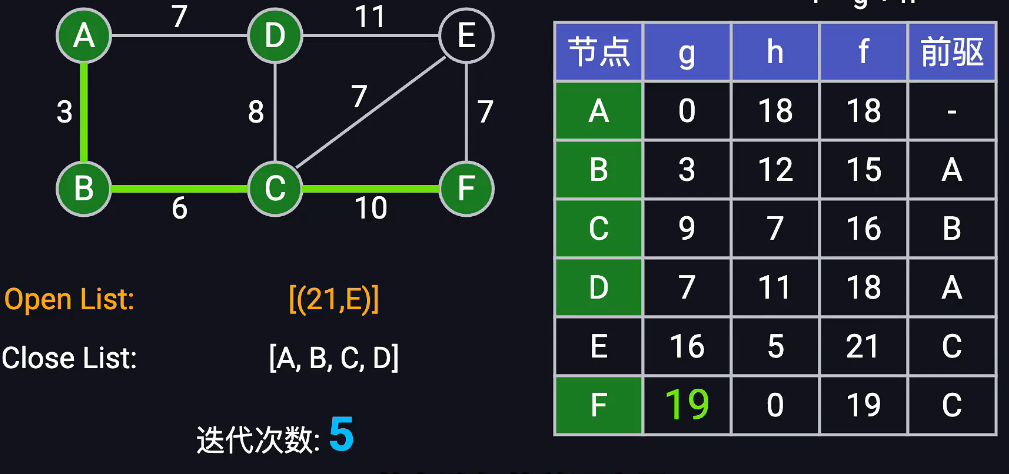
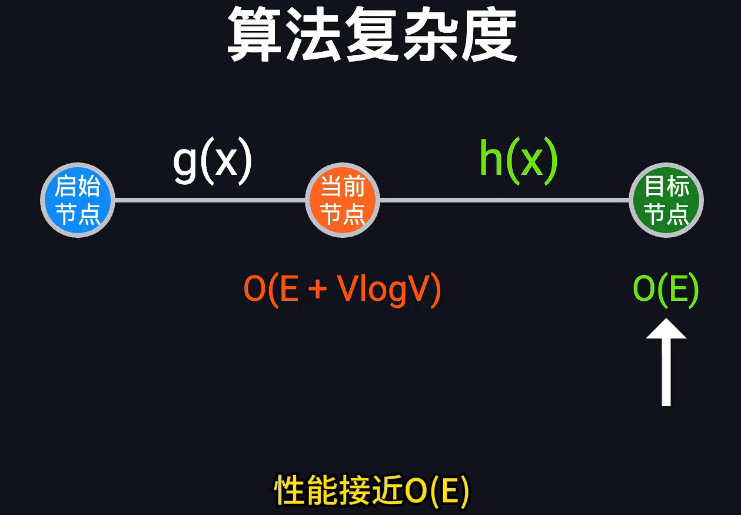


















最短路径算法的结论
根据图片内容,我可以总结以下关于最短路径算法的重要结论:
-
Dijkstra算法的局限性:在寻找单一目标的最短路径时,Dijkstra算法可能效率较低,因为它会向图中所有可能方向进行探索。
-
改进方法:
- 双向搜索(bi-directional search)是一种有效的改进方法
- 基于势能的方法(potential-based methods)也很有用,它们通过修改Dijkstra算法使其搜索更聚焦于目标节点
-
A*算法:
- A*是一种在平面中找到插入障碍物时的最短路径的人工智能算法
- 它使用势能函数h来估计从任何给定节点到目标的未来成本
- A*本质上是Dijkstra算法的一个特例,其权重考虑了未来成本信息

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 25
25 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)