病毒传播模拟:多智能体系统与时空可视化引擎
本设计构建了一个融合流行病学模型、个体行为决策和多维可视化的病毒传播沙盒系统。通过建立多层传播网络与实时数据映射,实现从微观个体互动到宏观传播趋势的全链路模拟。
目录
病毒传播模拟:多智能体系统与时空可视化引擎
需要源码请+V:xrbcgfh0214
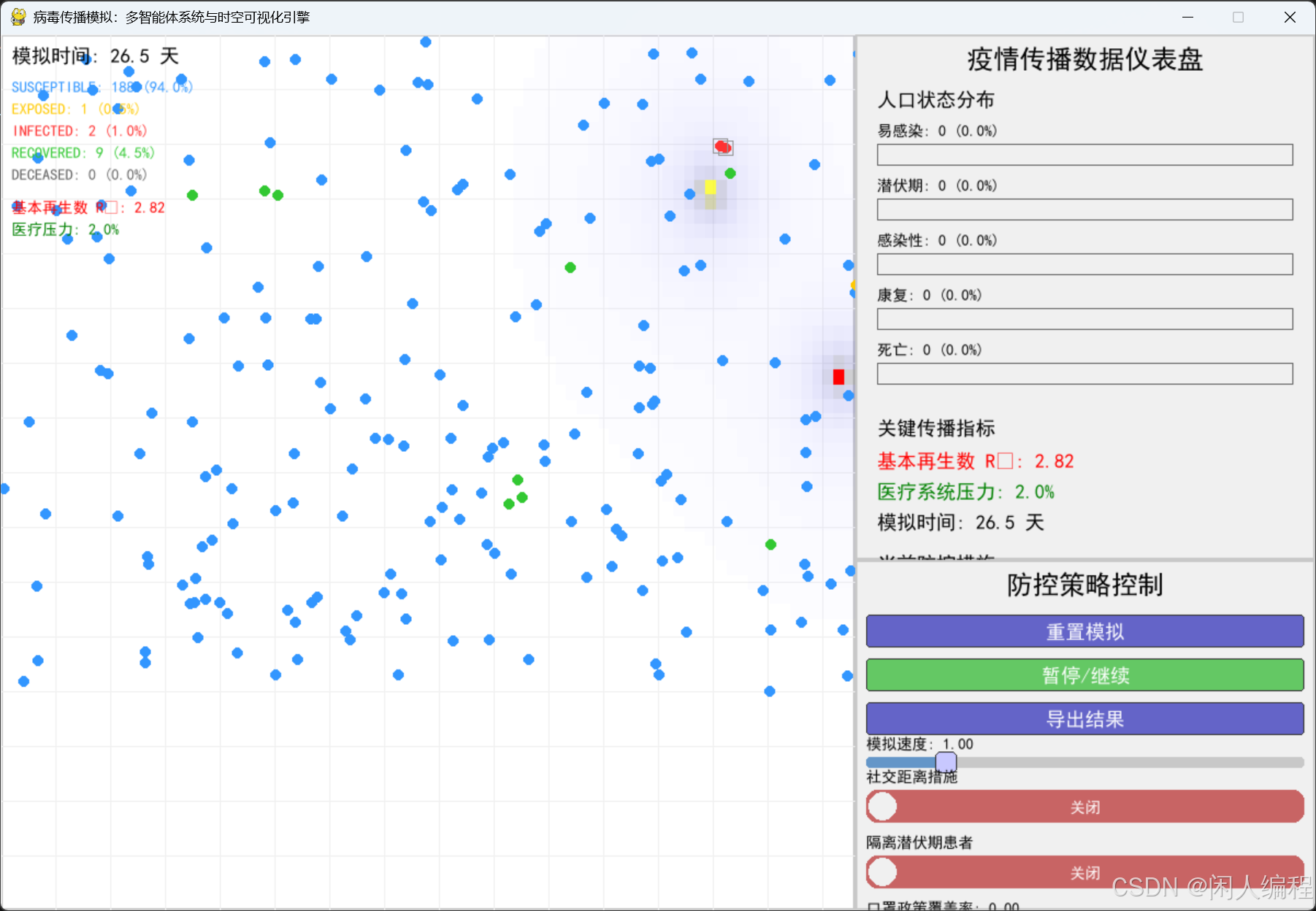
引言
本设计构建了一个融合流行病学模型、个体行为决策和多维可视化的病毒传播沙盒系统。通过建立多层传播网络与实时数据映射,实现从微观个体互动到宏观传播趋势的全链路模拟。
第一章 传播动力学模型
1.1 扩展SEIRD模型
{ d S d t = − β S I N d E d t = β S I N − σ E d I d t = σ E − γ I d R d t = γ I ( 1 − μ ) d D d t = γ I μ \begin{cases} \frac{dS}{dt} = -\beta S\frac{I}{N} \\ \frac{dE}{dt} = \beta S\frac{I}{N} - \sigma E \\ \frac{dI}{dt} = \sigma E - \gamma I \\ \frac{dR}{dt} = \gamma I (1 - \mu) \\ \frac{dD}{dt} = \gamma I \mu \end{cases} ⎩ ⎨ ⎧dtdS=−βSNIdtdE=βSNI−σEdtdI=σE−γIdtdR=γI(1−μ)dtdD=γIμ
参数说明:
- β \beta β: 接触感染率
- σ \sigma σ: 潜伏转化率
- γ \gamma γ: 康复率
- μ \mu μ: 病死率
1.2 空间传播网络
构建双层传播网络:
第二章 群体行为建模
2.1 个体移动模式
改进的随机游走模型:
Δ x = v cos θ + D ξ x \Delta x = v\cos\theta + D\xi_x Δx=vcosθ+Dξx
Δ y = v sin θ + D ξ y \Delta y = v\sin\theta + D\xi_y Δy=vsinθ+Dξy
其中 D D D为社交距离影响因子
2.2 行为决策树
第三章 可视化系统设计
3.1 实时热力图生成
反距离加权插值算法:
I ( x , y ) = ∑ w i I i ∑ w i , w i = 1 d i p I(x,y) = \frac{\sum w_i I_i}{\sum w_i}, \quad w_i = \frac{1}{d_i^p} I(x,y)=∑wi∑wiIi,wi=dip1
3.2 传播网络图
力导向布局动力学方程:
{ x ¨ i = k ∑ ( ∥ x j − x i ∥ − l ) x j − x i ∥ x j − x i ∥ y ¨ i = k ∑ ( ∥ y j − y i ∥ − l ) y j − y i ∥ y j − y i ∥ \begin{cases} \ddot{x}_i = k \sum (\|x_j - x_i\| - l)\frac{x_j - x_i}{\|x_j - x_i\|} \\ \ddot{y}_i = k \sum (\|y_j - y_i\| - l)\frac{y_j - y_i}{\|y_j - y_i\|} \end{cases} {x¨i=k∑(∥xj−xi∥−l)∥xj−xi∥xj−xiy¨i=k∑(∥yj−yi∥−l)∥yj−yi∥yj−yi
3.3 数据仪表盘
关键指标实时监控:
- 基本再生数 R t = β / γ R_t = \beta/\gamma Rt=β/γ
- 空间传播熵 H = − ∑ p i log p i H = -\sum p_i \log p_i H=−∑pilogpi
- 医疗压力指数 M = I c u r r e n t / I m a x M = I_{current}/I_{max} M=Icurrent/Imax
第四章 干预策略模拟
4.1 防控措施系统
4.2 个体防护参数化
口罩有效性模型:
β m a s k = β 0 × ( 1 − e − α t ) \beta_{mask} = \beta_0 \times (1 - e^{-\alpha t}) βmask=β0×(1−e−αt)
第五章 扩展系统设计
5.1 多病原体竞争
病毒进化方程:
d V i d t = r i V i ( 1 − ∑ V j K ) \frac{dV_i}{dt} = r_i V_i (1 - \sum \frac{V_j}{K}) dtdVi=riVi(1−∑KVj)
5.2 经济影响模型
投入产出分析:
X = ( I − A ) − 1 Y X = (I - A)^{-1}Y X=(I−A)−1Y
其中 A A A为技术系数矩阵
第六章 性能优化策略
6.1 空间分区加速
四叉树空间索引:
6.2 LOD细节分级
渲染精度控制:
L O D = ⌊ log 2 ( D S ) ⌋ LOD = \lfloor \log_2(\frac{D}{S}) \rfloor LOD=⌊log2(SD)⌋
其中 D D D为观察距离, S S S为基准尺寸
结语
本系统通过建立多尺度耦合模型,实现了流行病传播的可视化推演与策略验证。从分子级的病毒动力学到宏观的社会经济影响,构建了完整的数字孪生实验场。
创新特性:
- 多层网络传播机制
- 行为-传播双向耦合系统
- 时空熵值预警指标
- 经济-健康平衡分析模型
应用场景:
- 公共卫生教育工具
- 防疫政策模拟平台
- 城市应急管理演练
附录:部分代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
多智能体模型:个体行为建模
"""
import numpy as np
import pygame
from enum import Enum, auto
from dataclasses import dataclass
class AgentState(Enum):
"""智能体状态枚举"""
SUSCEPTIBLE = auto() # 易感
EXPOSED = auto() # 潜伏
INFECTED = auto() # 感染
RECOVERED = auto() # 康复
DECEASED = auto() # 死亡
@dataclass
class AgentParameters:
"""智能体参数定义"""
# 移动相关参数
max_speed: float = 2.0 # 最大移动速度
direction_change_prob: float = 0.05 # 随机改变方向的概率
social_distance: float = 30.0 # 社交距离
# 疾病相关参数
infection_radius: float = 20.0 # 感染半径
mask_effectiveness: float = 0.0 # 口罩有效性 (0-1)
vaccine_effectiveness: float = 0.0 # 疫苗有效性 (0-1)
class Agent:
"""
智能体类
模拟个体在环境中的移动和感染状态变化
"""
# 状态对应的颜色
COLORS = {
AgentState.SUSCEPTIBLE: (50, 150, 255), # 蓝色
AgentState.EXPOSED: (255, 200, 0), # 黄色
AgentState.INFECTED: (255, 50, 50), # 红色
AgentState.RECOVERED: (50, 200, 50), # 绿色
AgentState.DECEASED: (100, 100, 100) # 灰色
}
def __init__(self, agent_id, x, y, state=AgentState.SUSCEPTIBLE, params=None):
"""
初始化智能体
Args:
agent_id: 智能体唯一ID
x, y: 初始位置坐标
state: 初始状态
params: 智能体参数
"""
self.id = agent_id
self.position = np.array([x, y], dtype=float)
self.velocity = np.zeros(2, dtype=float)
self.state = state
self.params = params or AgentParameters()
# 设置随机初始方向
self._randomize_direction()
# 疾病相关计时器
self.time_in_state = 0
self.contacts = [] # 接触历史
# 其他属性
self.age = np.random.randint(5, 85) # 随机年龄
self.has_mask = False
self.is_vaccinated = False
self.is_quarantined = False
def _randomize_direction(self):
"""随机化移动方向"""
angle = np.random.uniform(0, 2 * np.pi)
speed = np.random.uniform(0.5, self.params.max_speed)
self.velocity[0] = speed * np.cos(angle)
self.velocity[1] = speed * np.sin(angle)
def update(self, dt, environment=None):
"""
更新智能体状态
Args:
dt: 时间步长
environment: 环境对象引用
"""
if self.state == AgentState.DECEASED:
return # 死亡状态不更新
# 更新疾病状态计时器
self.time_in_state += dt
# 根据当前状态决定行为
self._update_behavior(dt, environment)
# 可能随机改变方向
if np.random.random() < self.params.direction_change_prob:
self._randomize_direction()
# 更新位置
if not self.is_quarantined:
self.position += self.velocity * dt
# 确保在边界内
if environment:
self.position[0] = np.clip(self.position[0], 0, environment.width)
self.position[1] = np.clip(self.position[1], 0, environment.height)
def _update_behavior(self, dt, environment):
"""
根据当前状态更新行为
Args:
dt: 时间步长
environment: 环境对象引用
"""
# 状态特定的行为决策
if self.state == AgentState.SUSCEPTIBLE:
# 易感状态:正常活动,可能避开感染者
if environment and environment.policy.social_distancing_active:
self._apply_social_distancing(environment)
elif self.state == AgentState.EXPOSED:
# 潜伏状态:部分可能自我隔离
if environment and environment.policy.quarantine_exposed:
self.is_quarantined = np.random.random() < 0.7 # 70%概率自我隔离
elif self.state == AgentState.INFECTED:
# 感染状态:可能就医或自我隔离
if environment:
self.is_quarantined = np.random.random() < 0.9 # 90%概率隔离
if self.velocity.any(): # 降低移动速度
self.velocity *= 0.5
elif self.state == AgentState.RECOVERED:
# 康复状态:恢复正常活动
self.is_quarantined = False
def _apply_social_distancing(self, environment):
"""
应用社交距离行为
Args:
environment: 环境对象引用
"""
if not environment:
return
# 获取附近的其他智能体
nearby_agents = environment.get_nearby_agents(self, self.params.social_distance)
# 计算社交距离力(远离其他人)
if nearby_agents:
repulsion_force = np.zeros(2)
for agent in nearby_agents:
if agent.id == self.id:
continue
# 计算方向和距离
direction = self.position - agent.position
distance = np.linalg.norm(direction)
# 避免除以零
if distance < 0.1:
continue
# 力度与距离成反比
force = direction / distance**2
# 感染者有更强的排斥力
if agent.state in (AgentState.INFECTED, AgentState.EXPOSED):
force *= 2.0
repulsion_force += force
# 应用到速度上
if np.linalg.norm(repulsion_force) > 0:
repulsion_force = repulsion_force / np.linalg.norm(repulsion_force)
self.velocity += repulsion_force * 0.5
# 限制速度
speed = np.linalg.norm(self.velocity)
if speed > self.params.max_speed:
self.velocity = self.velocity / speed * self.params.max_speed
def draw(self, surface, camera_offset=(0, 0)):
"""
在表面上绘制智能体
Args:
surface: Pygame表面对象
camera_offset: 相机偏移量
"""
if self.state == AgentState.DECEASED:
radius = 3 # 死亡状态画得小一点
else:
radius = 5
# 计算屏幕位置
screen_pos = (int(self.position[0] - camera_offset[0]),
int(self.position[1] - camera_offset[1]))
# 绘制主体
pygame.draw.circle(surface, self.COLORS[self.state], screen_pos, radius)
# 如果戴口罩,画一个小标记
if self.has_mask and self.state != AgentState.DECEASED:
mask_pos = (screen_pos[0], screen_pos[1] - radius - 2)
pygame.draw.circle(surface, (200, 200, 200), mask_pos, 2)
# 如果已接种疫苗,画一个小标记
if self.is_vaccinated and self.state != AgentState.DECEASED:
vac_pos = (screen_pos[0] - radius - 2, screen_pos[1])
pygame.draw.circle(surface, (0, 200, 100), vac_pos, 2)
# 如果被隔离,画一个方框
if self.is_quarantined and self.state != AgentState.DECEASED:
rect = pygame.Rect(screen_pos[0] - radius - 2,
screen_pos[1] - radius - 2,
radius * 2 + 4, radius * 2 + 4)
pygame.draw.rect(surface, (150, 150, 150), rect, 1)
def try_infect(self, other_agent, environment):
"""
尝试感染其他智能体
Args:
other_agent: 其他智能体
environment: 环境对象
Returns:
bool: 是否成功感染
"""
# 只有感染状态的智能体才能传染
if self.state != AgentState.INFECTED:
return False
# 目标必须是易感状态
if other_agent.state != AgentState.SUSCEPTIBLE:
return False
# 计算距离
distance = np.linalg.norm(self.position - other_agent.position)
# 超出感染半径
if distance > self.params.infection_radius:
return False
# 记录接触
self.contacts.append((other_agent.id, environment.current_time))
other_agent.contacts.append((self.id, environment.current_time))
# 计算基础传染概率(距离越近概率越高)
base_prob = 1.0 - (distance / self.params.infection_radius)
# 应用口罩和疫苗效果
if self.has_mask:
base_prob *= (1.0 - self.params.mask_effectiveness)
if other_agent.has_mask:
base_prob *= (1.0 - other_agent.params.mask_effectiveness)
if other_agent.is_vaccinated:
base_prob *= (1.0 - other_agent.params.vaccine_effectiveness)
# 环境政策的影响
if environment and environment.policy:
base_prob *= environment.policy.get_transmission_factor()
# 随机判定是否感染
if np.random.random() < base_prob:
other_agent.state = AgentState.EXPOSED
other_agent.time_in_state = 0
return True
return False
def get_state_duration(self, state_type):
"""
根据状态类型和个人特征计算状态持续时间
Args:
state_type: AgentState枚举值
Returns:
float: 该状态的持续时间(天)
"""
if state_type == AgentState.EXPOSED:
# 潜伏期:3-6天,老年人略长
base_duration = np.random.uniform(3, 6)
age_factor = 1.0 + max(0, (self.age - 50)) / 100
return base_duration * age_factor
elif state_type == AgentState.INFECTED:
# 感染期:7-14天,老年人略长,有并发症风险更高
base_duration = np.random.uniform(7, 14)
age_factor = 1.0 + max(0, (self.age - 40)) / 80
complication_risk = 0.05 + max(0, (self.age - 60)) / 100
# 疫苗可能降低感染期和并发症风险
if self.is_vaccinated:
base_duration *= 0.8
complication_risk *= 0.5
# 一定概率出现严重并发症,延长感染期
if np.random.random() < complication_risk:
base_duration *= 1.5
return base_duration * age_factor
return 0 # 其他状态无固定持续时间

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 24
24 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)