基于机器学习的餐饮企业经营数据挖掘与预测(含原数据和代码)
Cluster 0: 新客户或低活跃度客户,需要通过促销活动等手段提高其消费频率和金额。Cluster 1: 高频消费者或忠诚客户,是企业的核心客户群体,需要提供优质服务和个性化营销策略来保持其忠诚度。Cluster 2: 高价值但低活跃度客户,需要通过定向营销等手段重新激活其消费行为。
随着市场竞争的加剧和消费者需求的变化,为了提高市场竞争力,餐饮企业必须借助现代数据分析技术,挖掘消费者行为、市场趋势和经营效率等方面的潜力,从而优化运营策略和提升盈利能力。数据挖掘技术在餐饮行业的应用,正逐渐成为企业决策支持的重要工具,帮助企业从大量的业务数据中提取有价值的信息,为经营决策提供科学依据。
第一章主要进行数据初步探索,从菜品、消费、时间三个维度来进行可视化分析,并给出相应建议。
第二章使用Apriori算法,通过不断地探索项集的频繁模式,并从中提取出有意义的关联规则,对菜品进行套餐组合,从而达到更高盈利的目的 。
第三章通过K-means聚类算法对某餐饮平台的用户进行聚类分析,识别出不同的客户群体,并分析这些群体的消费行为特征。
第四章使用决策树算法对餐饮行业客户流失进行了预测,并通过混淆矩阵、精确率、召回率和F1值对模型进行了评估。结果表明,决策树模型能够较为准确地预测客户是否流失,并且在流失客户的识别上具有较高的精确性。
第五章基于SARIMA模型对餐饮店的营业额进行预测。通过对历史数据进行差分处理、平稳性检验、模型建立及误差分析,展示了如何使用SARIMA模型进行营业额的预测,并通过实际数据分析验证了模型的有效性。
通过对这些方法的综合应用,本研究为餐饮企业提供了切实可行的经营数据分析方案,旨在
帮助企业实现精细化管理和精准营销,提高市场竞争力和盈利能力。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns第1章 数据探索与预处理
1.1数据预处理
#导入数据
dishes=pd.read_csv(r'C:\Users\Lenovo\Desktop\案例集\基于机器学习的餐饮企业经营数据挖掘与预测\data\meal_dishes_detail.csv')
order=pd.read_csv(r'C:\Users\Lenovo\Desktop\案例集\基于机器学习的餐饮企业经营数据挖掘与预测\data\meal_order_detail.csv')
#数据去重
dishes.drop_duplicates(inplace=True)
order.drop_duplicates(inplace=True)1.1.1对菜品详情表进行预处理
#删除空列
dishes.drop(['bar_code','is_info_menu_item','balance_price','pinyin','creation_method','dishes_characteristic'],axis=1,inplace=True)
dishes.head()
可知:amt_discount、sortorder、stock_count、dept_name、dept_id这几个字段无具体值,不具有参考意义,同时picture_file和研究问题不相关,也不具有参考价值,进行删除。
#删除列
dishes.drop(['amt_discount','sortorder','stock_count','dept_name','dept_id','picture_file'],axis=1,inplace=True)#查看缺失值
dishes.isnull().sum()
可知:description缺失值占比比较大且不具有参考价值,label和recommend_percent缺失值数量比较少,label列的值不影响最终结果,不做处理,recommend_percent缺失值采用均值代替
#删除description列
dishes.drop(['description'],axis=1,inplace=True)
#recommend_percent缺失值处理(均值)
dishes['recommend_percent'].fillna(round(dishes['recommend_percent'].mean(),2),inplace=True);
#新加一个字段profit,等于price减去cost
dishes['profit']=dishes['price']-dishes['cost']
dishes.isnull().sum()
1.1.2对订单详情表进行预处理
#删除列
order.drop(['logicprn_name','parent_class_name','cost','discount_amt','discount_reason','kick_back','add_info','bar_code'],axis=1,inplace=True)
order.drop(['picture_file','add_inprice','itemis_add'],axis=1,inplace=True)#将两个数据表进行合并
data = pd.merge(order, dishes[['id','profit','dishes_class_name']], how='left', left_on='dishes_id', right_on='id')
data.reset_index(drop=True,inplace=True)
data.drop(columns=['id'],inplace=True)1.2数据分析与可视化
1.2.1菜品维度进行可视化分析
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体字
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题#最受欢迎的菜品top_10
popular_dishestop_10=data['dishes_name'].value_counts()[:10]
colors = ['#FFB6C1', '#D8BFD8', '#B0E0E6', '#ADD8E6', '#E0FFFF', '#F0E68C', '#98FB98', '#FFD700', '#FF6347', '#FF4500']
plt.figure(figsize=(10, 6))
popular_dishestop_10.plot(kind='bar',width=0.8,color=colors)
plt.title("最受欢迎的菜品top_10",size=16)
plt.xlabel("菜品名",size=10)
plt.ylabel("销量",size=10)
plt.xticks(rotation=45)
#添加数值标签
for x, y in enumerate(popular_dishestop_10):
plt.text(x, y + 2, str(y), ha='center', fontsize=10)
#展示最受欢迎菜品销量的变化趋势
ax2 = plt.twinx()
popular_dishestop_10.plot(kind='line', ax=ax2, color='r', marker='o', linewidth=2, fontsize=10)
#自动调整子图参数以适应图像区域,避免标签被截断。
plt.tight_layout()
plt.show()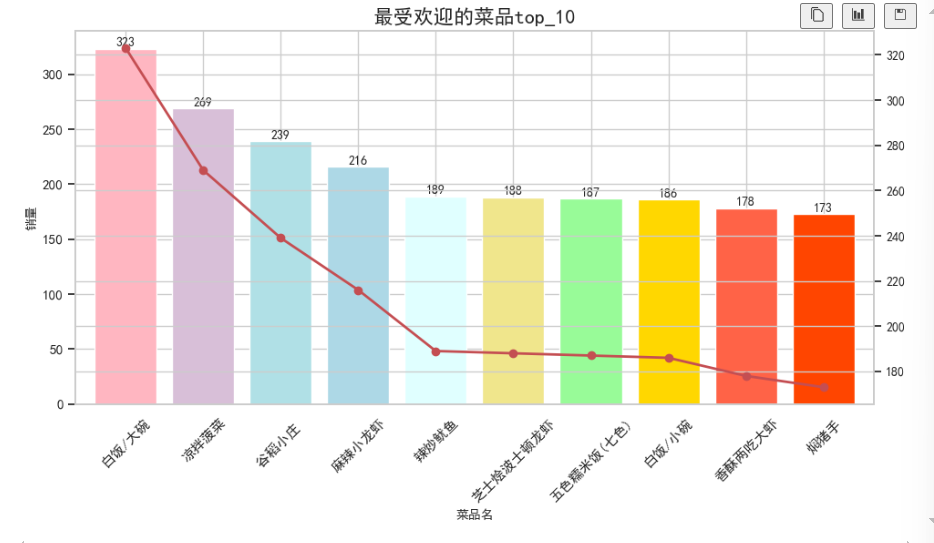
如下条形图所示,可以看出热销菜品有:凉拌菠菜、谷稻小庄、麻辣小龙虾等等,销量较高的菜品反映了顾客的口味偏好,餐厅可以考虑加大对这些菜品的推广力度,同时保持菜品的质量和口感不变。对于销量较低的菜品,餐厅可以考虑优化配方、调整定价策略,或是通过促销活动来提升销量。
#最受欢迎的菜品类别
dishes_class_10=data['dishes_class_name'].value_counts()[:5]
# categories=dishes_class_10.index.tolist()
# counts=dishes_class_10.values.tolist()
# plt.figure(figsize=(10, 6))
# plt.pie(counts,labels=categories,autopct='%1.1f%%');
dishes_class_10.plot(kind='pie',autopct='%1.1f%%')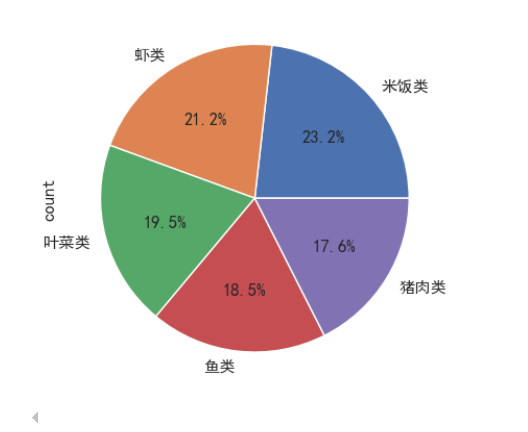
通过下面的统计图,我们可以发现虾类、叶菜类、鱼类、猪肉类是最受欢迎的类别。
1.2.2消费维度进行可视化分析
#单点菜种类前10名
order_count_10 = data['order_id'].value_counts()[:10]
order_count_10.plot(kind='bar', fontsize=16)
plt.title('订单点菜Top10', fontsize=16)
plt.xlabel('订单ID', fontsize=16)
plt.ylabel('菜品数量', fontsize=16)
plt.show()
#单点菜数量前10名
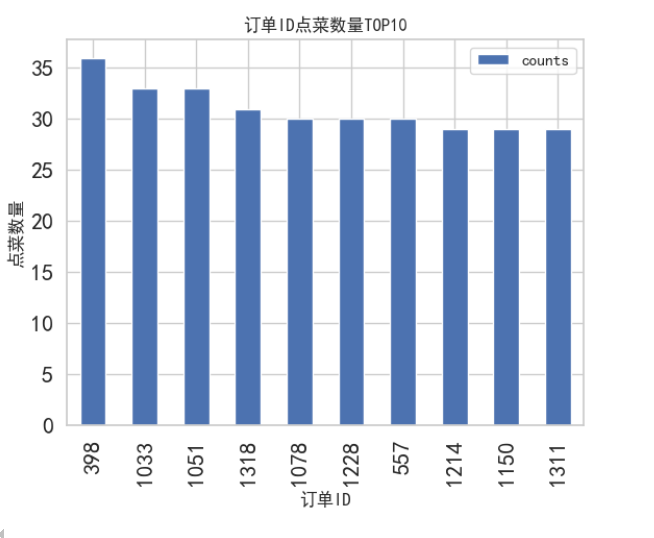
#订单ID点菜数量TOP10(分组order_id,counts求和,排序,前十)
dataGroup = data[['order_id','counts']].groupby(by='order_id')
Group_sum = dataGroup.sum()#分组求和
#根据数量进行排序,默认是升序
sort_counts = Group_sum.sort_values(by='counts',ascending=False)[:10]
sort_counts.plot(kind='bar',fontsize=16)
plt.xlabel('订单ID')
plt.ylabel('点菜数量')
plt.title('订单ID点菜数量TOP10')
#下单数与小时的关系
#添加新列,方便汇总求和,用作计数器
data['hourcount'] = 1
data['time'] = pd.to_datetime(data['place_order_time']) # 加时间转换成日期类型存储
data['hour'] = data['time'].map(lambda x: x.hour)
gp_by_hour = data.groupby(by=data['hour']).count() ['hourcount']
gp_by_hour.plot(kind='bar')
plt.xlabel('小时')
plt.ylabel('下单数量')
plt.title('下单数与小时的关系')
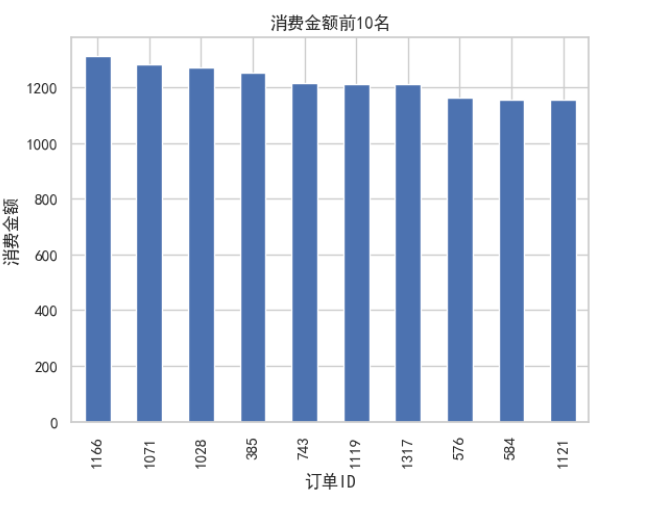
#订单消费总额TOP10,默认是降序排序
sort_total_amounts = Group_sum.sort_values(by='total_amounts',ascending=False)[:10]
sort_total_amounts['total_amounts'].plot(kind='bar')
plt.xlabel('订单ID')
plt.ylabel('消费金额')
plt.title('消费金额前10名')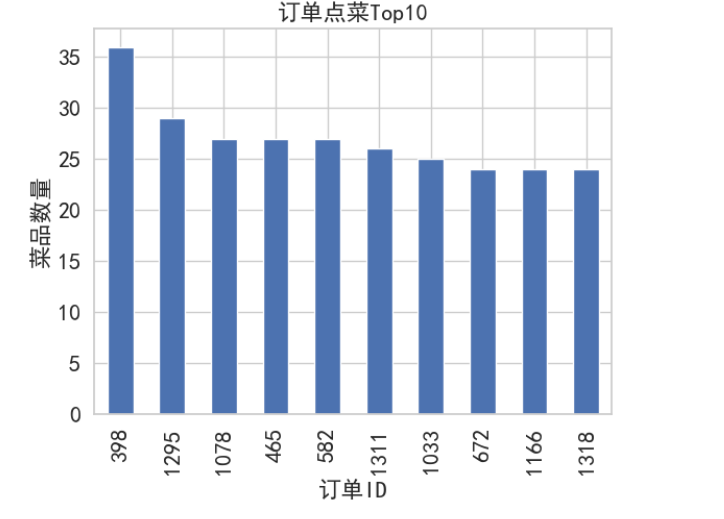
1.2.3时间维度进行可视化分析
#下单数与小时的关系
#添加新列,方便汇总求和,用作计数器
data['hourcount'] = 1
data['time'] = pd.to_datetime(data['place_order_time']) # 加时间转换成日期类型存储
data['hour'] = data['time'].map(lambda x: x.hour)
gp_by_hour = data.groupby(by=data['hour']).count() ['hourcount']
gp_by_hour.plot(kind='bar')
plt.xlabel('小时')
plt.ylabel('下单数量')
plt.title('下单数与小时的关系')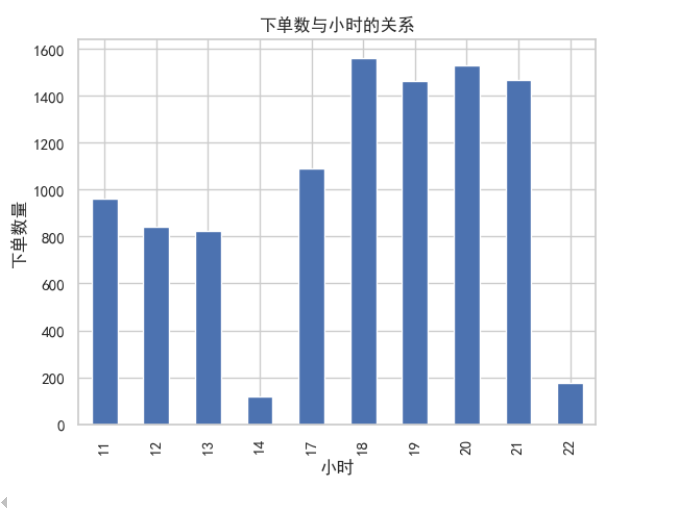
# 添加新列,方便汇总求和,用作计数器
data['daycount'] = 1
data['day'] = data['time'].map(lambda x: x.day)
gp_by_day = data.groupby(by=['day']).count()['daycount']
# 绘制每天的订单数量条形图
plt.figure(figsize=(10, 5))
gp_by_day.plot(kind='bar', color='skyblue')
plt.xlabel('8月份日期')
plt.ylabel('点菜数量')
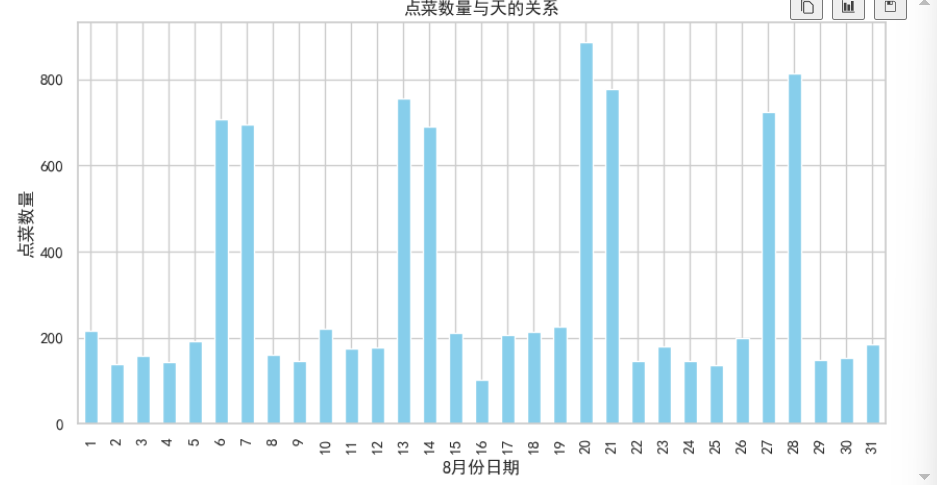
plt.title('点菜数量与天的关系')
plt.show()
# 添加新列,方便汇总求和,用作计数器
data['weekcount'] = 1
data['weekday'] = data['time'].map(lambda x: x.weekday)
gp_by_week = data.groupby(by=['weekday']).count()['weekcount']
# 绘制每周的订单数量条形图
plt.figure(figsize=(8, 5))
gp_by_week.plot(kind='bar', color='lightcoral')
plt.xlabel('星期')
plt.ylabel('点菜数量')
plt.title('点菜数量与星期的关系')
plt.xticks(range(7), ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday'])
plt.show()
第2章 基于Apriori算法进行菜品关联分析
2.1数据准备
#数据准备
dishes_value=dishes.iloc[:,[0,2,3,11]]
#新增毛利率列(profit/price)
dishes_value['profit_percent']=round(dishes_value['profit']/dishes_value['price'],5)
# 新增热销度popularitylie
# 将两表连接
order_popularitylie = pd.merge(dishes, order, how='left', left_on='id', right_on='dishes_id')
# 计算每个菜品的总订单数,并按菜品名称分组
total_counts = order_popularitylie.groupby('dishes_id')['counts'].sum().reset_index()
total_counts.columns = ['dishes_id', 'total_counts']
#合并数据(订单总和表和菜品表)
dishes_value=pd.merge(dishes_value,total_counts,how='left',left_on='id',right_on='dishes_id')
dishes_value
# 新增热销度popularitylie
max_value =dishes_value['total_counts'].max()
min_value =dishes_value['total_counts'].min()
difference=max_value-min_value
list=[]
for i in dishes_value['total_counts']:
rxd=round((i-min_value)/difference,5)
list.append(rxd)
dishes_value['popularitylie']=list
dishes_value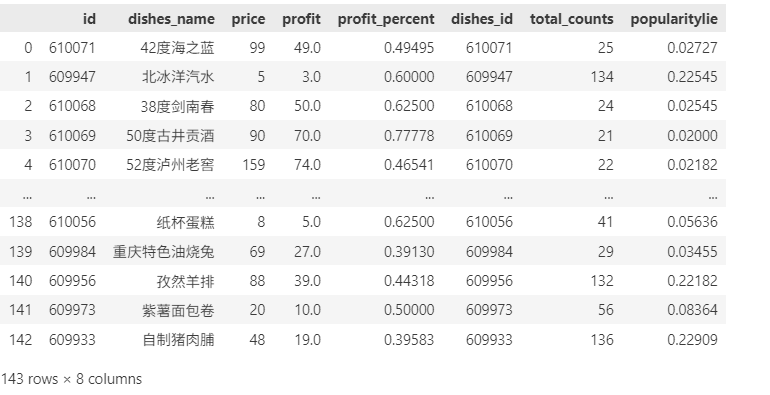
2.2构建Apriori模型
2.2.1.生成购物篮数据
#导入所需要的库
from mlxtend.frequent_patterns import apriori, association_rules
# 生成购物篮数据
basket=pd.pivot_table(order, index='order_id', columns='dishes_name', values='counts', aggfunc='sum', fill_value=0)
basket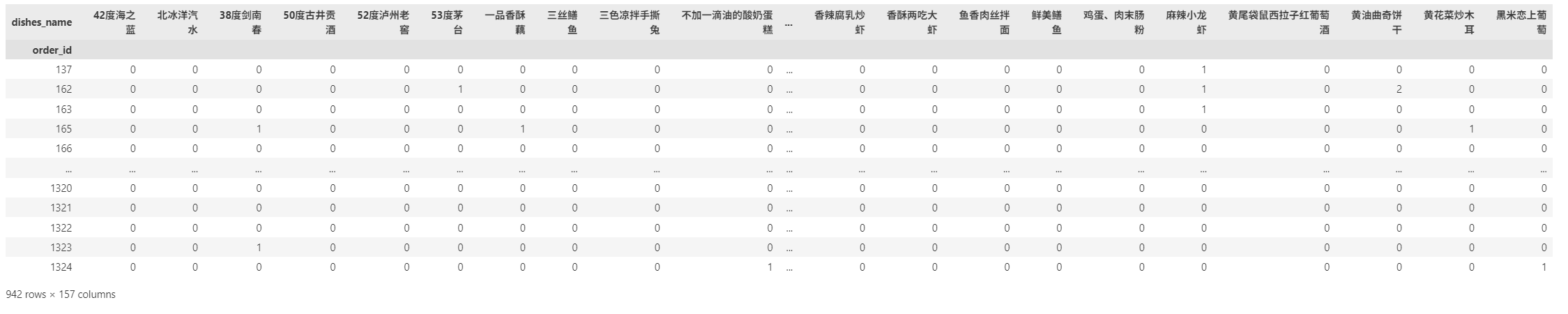
2.2.2构建Apriori模型的二元矩阵
# 将 counts 转换为 1 和 0,表示菜品是否出现
basket = basket.applymap(lambda x: 1 if x > 0 else 0)
#因为米饭属于主食,所以在进行Apriori模型训练的时候,删除了关于米饭列。
columns_to_drop = ['白饭/大碗', '白饭/小碗']
basket = basket.drop(columns=columns_to_drop)2.2.3训练模型
# 运行 Apriori 算法,找到频繁项集
frequent_itemsets = apriori(basket, min_support=0.01, use_colnames=True)
frequent_itemsets
# 根据频繁项集生成关联规则
rules = association_rules(frequent_itemsets, metric="lift", min_threshold=1)
rules_sorted=rules.sort_values(by='support',ascending=False)
rules_sorted
dishes_combination=rules_sorted.iloc[:,[0,1,4]]
dishes_combination.head(10)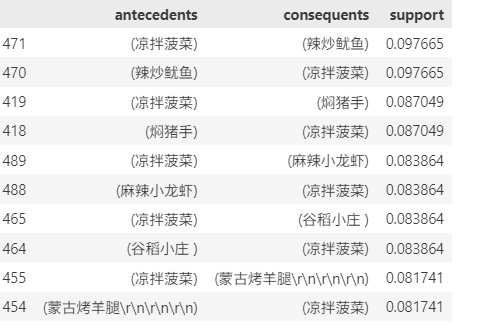
2.3模型评价以及菜品套餐组合
#读取数据
Apriori_combination=pd.read_excel(r'C:\Users\Lenovo\Desktop\案例集\基于机器学习的餐饮企业经营数据挖掘与预测\data\菜品.xlsx')
Apriori_combination.head()
Apriori_combination=Apriori_combination.merge(dishes_value[['id','popularitylie','profit_percent']],left_on='dishes1_id',right_on='id',how='left')
Apriori_combination =Apriori_combination.rename(columns={'profit_percent': 'profit_percent1', 'popularitylie': 'popularitylie1'})
Apriori_combination=Apriori_combination.merge(dishes_value[['id','popularitylie','profit_percent']],left_on='dishes2_id',right_on='id',how='left')
Apriori_combination =Apriori_combination.rename(columns={'profit_percent': 'profit_percent2', 'popularitylie': 'popularitylie2'})
Apriori_combination=Apriori_combination.iloc[:,[0,1,2,7,8,10,11]]
#得到打分工具
Apriori_combination['value']=Apriori_combination['profit_percent1']+Apriori_combination['profit_percent2']+Apriori_combination['popularitylie1']+Apriori_combination['popularitylie2']
Apriori_combination.sort_values(by='value',ascending=False)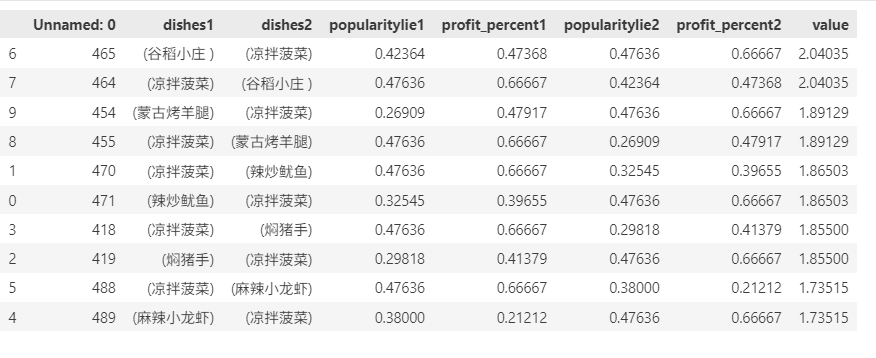
根据结果可以进行一些套餐组合推荐,例如凉拌菠菜和谷稻小庄;凉拌菠菜和蒙古烤羊腿等等。也可以进行三种菜品的组合套餐推荐,例如凉拌菠菜、辣炒鱿鱼和谷稻小庄,可以根据毛利率和热销度数据来打造店里的招牌菜品同时获得最大盈利。
第3章 基于K-means聚类进行客户价值分析
3.1数据处理
order_info=pd.read_csv(r'C:\Users\Lenovo\Desktop\案例集\基于机器学习的餐饮企业经营数据挖掘与预测\data\meal_order_info.csv')
order.info()
order_info.drop(['mode','check_closed','cashier_id','pc_id','order_number','print_doc_bill_num','lock_table_info'],axis=1,inplace=True)3.2构建K-means模型
3.2.1计算RFM值
F(Frequency):统计每个用户的订单次数,表示用户的活跃度。M(Monetary):计算每个用户的总消费金额,表示用户的经济贡献。R(Recency):根据用户的最后一次用餐时间计算客户的活跃度,越接近当前时间的用户越活跃。
# 假设你的DataFrame叫做order_info
order_info['use_start_time'] = pd.to_datetime(order_info['use_start_time'])
# 找到数据中的最新日期作为基准日期
recent_date = order_info['use_start_time'].max()
#计算Recency(最近一次消费时间)
order_info['Recency'] = (recent_date - order_info['use_start_time']).dt.days
#3. 计算Frequency(消费频率)
frequency = order_info.groupby('emp_id')['info_id'].count().reset_index()
frequency.columns = ['emp_id', 'Frequency']
#计算Monetary(消费金额)
monetary = order_info.groupby('emp_id')['expenditure'].sum().reset_index()
monetary.columns = ['emp_id', 'Monetary']
#合并数据
rfm = order_info[['emp_id', 'Recency']].drop_duplicates()
rfm = rfm.merge(frequency, on='emp_id', how='left')
rfm = rfm.merge(monetary, on='emp_id', how='left')
#RFM评分
quantiles = rfm.quantile(q=[0.25, 0.5, 0.75]).to_dict()
def RScore(x, p, d):
if x <= d[p][0.25]:
return 1
elif x <= d[p][0.50]:
return 2
elif x <= d[p][0.75]:
return 3
else:
return 4
def FMScore(x, p, d):
if x <= d[p][0.25]:
return 4
elif x <= d[p][0.50]:
return 3
elif x <= d[p][0.75]:
return 2
else:
return 1
rfm['R_Quartile'] = rfm['Recency'].apply(RScore, args=('Recency', quantiles,))
rfm['F_Quartile'] = rfm['Frequency'].apply(FMScore, args=('Frequency', quantiles,))
rfm['M_Quartile'] = rfm['Monetary'].apply(FMScore, args=('Monetary', quantiles,))
#计算RFM综合得分
rfm['RFM_Score'] = rfm.R_Quartile.map(str) + rfm.F_Quartile.map(str) + rfm.M_Quartile.map(str)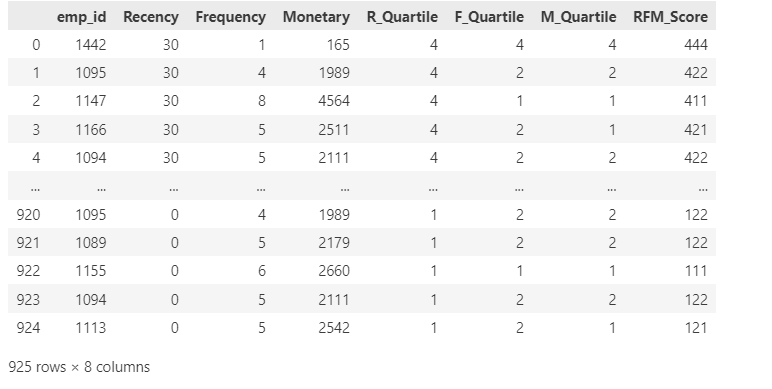
3.2.2K-means模型
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
#为了避免某一特征对聚类结果产生过大影响,对RFM特征进行了标准化处理。通过StandardScaler对数据进行标准化,使得所有特征的均值为0,标准差为1,确保每个特征在聚类时有相等的权重。
scaler = StandardScaler()
rfm_scaled= scaler.fit_transform(rfm[['Recency', 'Frequency', 'Monetary']])
# K-means聚类
kmeans = KMeans(n_clusters=3, random_state=42)
rfm['Cluster'] = kmeans.fit_predict(rfm_scaled)3.2.3聚类结果可视化及结果分析
# 设置绘图风格
sns.set(style="whitegrid")
# 创建一个新的图形
plt.figure(figsize=(10, 8))
# 使用seaborn的scatterplot函数绘制散点图
sns.scatterplot(data=rfm, x='R_Quartile', y='F_Quartile', hue='Cluster', palette='Set1', s=100)
# 添加标题和标签
plt.title('2D Scatter Plot of Clusters based on R_Quartile and F_Quartile')
plt.xlabel('R_Quartile')
plt.ylabel('F_Quartile')
# 显示图例
plt.legend(title='Cluster', loc='upper right')
# 显示图形
plt.show()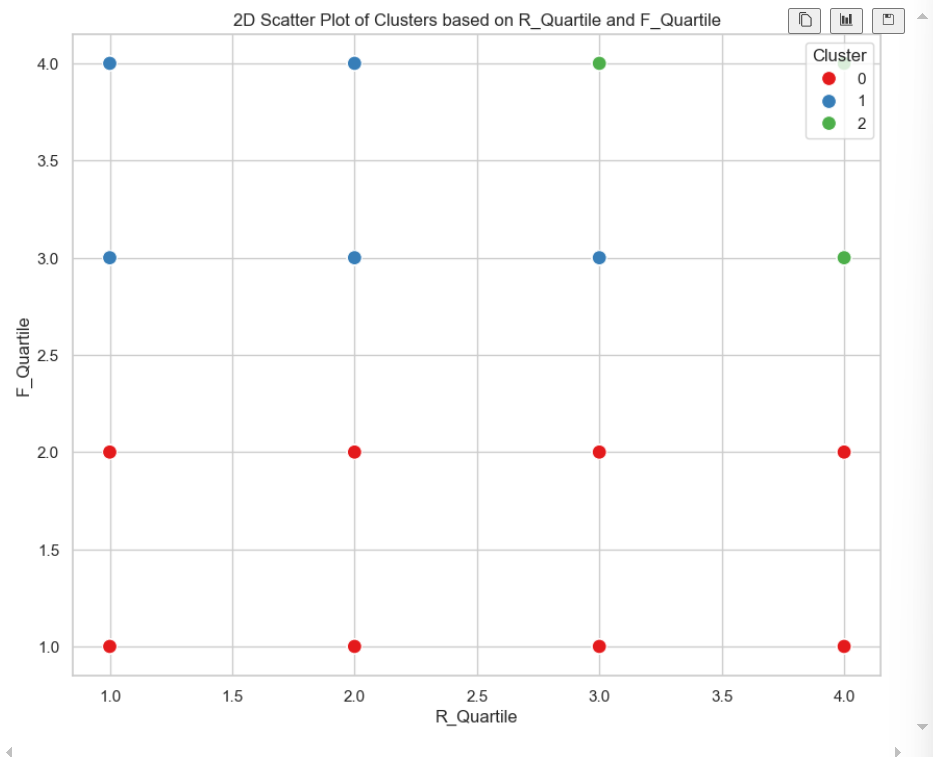
# 创建一个新的图形和一个3D子图
fig = plt.figure(figsize=(10, 8))
ax = fig.add_subplot(111, projection='3d')
# 使用不同的颜色表示不同的簇
colors = ['r', 'g', 'b']
for cluster in range(3):
# 获取属于当前簇的数据
cluster_data = rfm[rfm['Cluster'] == cluster]
# 绘制3D散点图
ax.scatter(cluster_data['R_Quartile'],
cluster_data['F_Quartile'],
cluster_data['M_Quartile'],
c=colors[cluster],
label=f'Cluster {cluster}',
s=50)
# 添加标签和标题
ax.set_xlabel('R_Quartile')
ax.set_ylabel('F_Quartile')
ax.set_zlabel('M_Quartile')
ax.set_title('3D Scatter Plot of Clusters based on R_Quartile, F_Quartile, and M_Quartile')
# 显示图例
ax.legend()
# 显示图形
plt.show()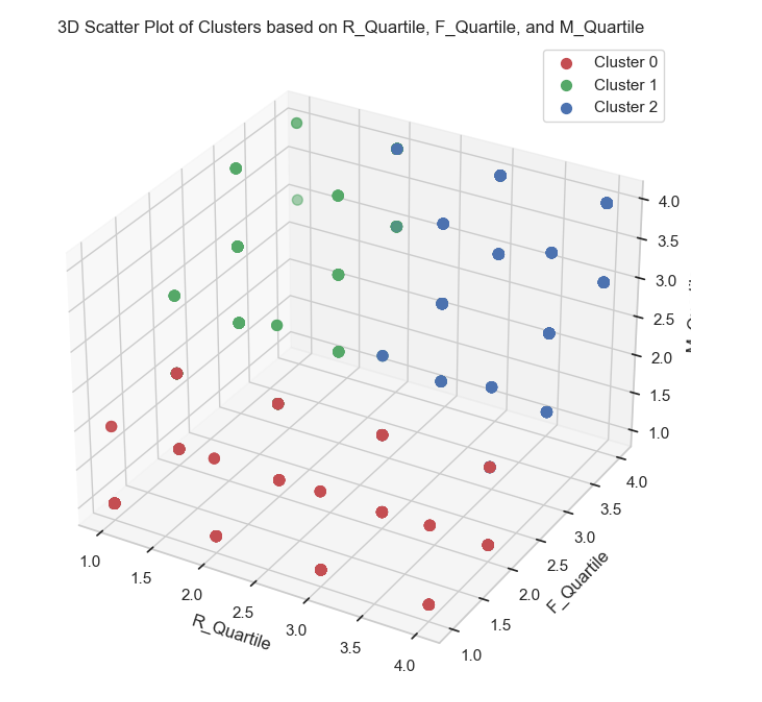
# 雷达图
# 计算每个簇的平均值
cluster_means = rfm.groupby('Cluster')[['R_Quartile', 'F_Quartile', 'M_Quartile']].mean().reset_index()
def make_spider_plot(cluster_means, title):
# 设置标签和角度
labels = ['R_Quartile', 'F_Quartile', 'M_Quartile']
angles = [n / float(len(labels)) * 2 * np.pi for n in range(len(labels))]
angles += angles[:1] # 闭合图形
# 创建子图
fig, ax = plt.subplots(figsize=(6, 6), subplot_kw=dict(polar=True))
# 绘制每个簇的数据
for i, cluster in enumerate(cluster_means['Cluster']):
values = cluster_means.loc[cluster_means['Cluster'] == cluster, ['R_Quartile', 'F_Quartile', 'M_Quartile']].values.flatten().tolist()
values += values[:1] # 闭合图形
ax.plot(angles, values, label=f'Cluster {cluster}', linewidth=2)
ax.fill(angles, values, alpha=0.25)
# 设置标签和标题
ax.set_theta_offset(np.pi / 2)
ax.set_theta_direction(-1)
ax.set_thetagrids(np.degrees(angles[:-1]), labels)
ax.set_title(title)
ax.legend(loc='upper right')
# 显示图形
plt.show()
# 调用函数绘制雷达图
make_spider_plot(cluster_means, "RFM Clusters Radar Plot")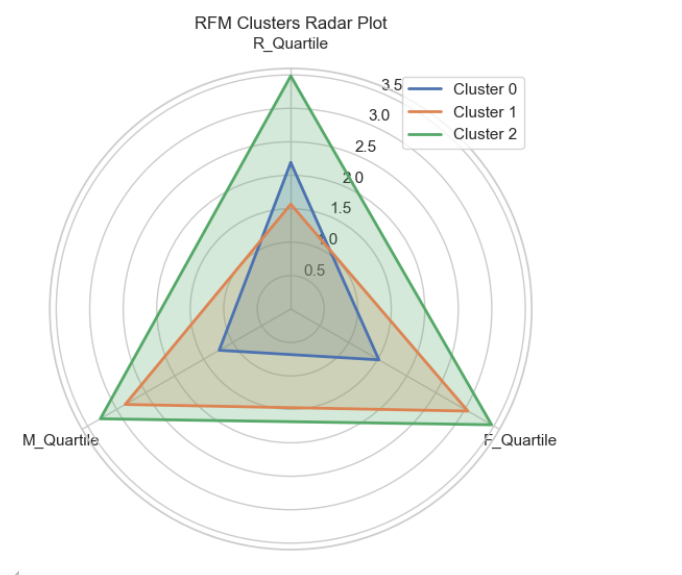
Cluster 0 (蓝色)
3D 散点图: 在3D散点图中,Cluster 0的数据点主要集中在较低的R_Quartile值上,表明这类用户的最近一次消费时间相对较近。同时,它们的F_Quartile和M_Quartile值也相对较低。
雷达图: 雷达图显示Cluster 0在三个维度上的平均值都较低,特别是在F_Quartile和M_Quartile上表现更为明显。
总结: 这一类用户可以被描述为“新客户”或“低活跃度客户”。他们可能刚刚开始与企业互动,或者虽然消费时间较近但消费频率和金额都不高。对于这类用户,企业可以通过提供优惠券、促销活动等方式来提高他们的消费频率和金额
Cluster 1 (橙色)
3D 散点图: 在3D散点图中,Cluster 1的数据点分布较为均匀,但在F_Quartile和M_Quartile上有较高的值,表明这类用户的消费频率和消费金额较高。
雷达图: 雷达图显示Cluster 1在F_Quartile和M_Quartile上的平均值较高,而在R_Quartile上的值相对较低。
总结: 这一类用户可以被视为“高频消费者”或“忠诚客户”。他们不仅消费频繁,而且消费金额也较高,是企业的核心客户群体。企业应该特别关注这类用户的满意度和忠诚度,通过优质的服务和个性化的营销策略来保持他们的忠诚度。
Cluster 2 (绿色)
3D 散点图: 在3D散点图中,Cluster 2的数据点在R_Quartile上有较高的值,表明这类用户的最近一次消费时间相对较远。同时,它们的F_Quartile和M_Quartile值也相对较高。
雷达图: 雷达图显示Cluster 2在F_Quartile和M_Quartile上的平均值较高,但在R_Quartile上的值相对较低。
总结: 这一类用户可以被称为“高价值但低活跃度客户”。他们虽然消费金额较高,但消费频率和最近一次消费时间都显示他们并不是非常活跃的客户。企业需要采取措施重新激活这类客户的消费行为,例如通过定向营销、会员计划等手段来激发他们的购买欲望。
总结
Cluster 0: 新客户或低活跃度客户,需要通过促销活动等手段提高其消费频率和金额。
Cluster 1: 高频消费者或忠诚客户,是企业的核心客户群体,需要提供优质服务和个性化营销策略来保持其忠诚度。
Cluster 2: 高价值但低活跃度客户,需要通过定向营销等手段重新激活其消费行为。
第4章 基于决策树模型进行客户流失预测
4.1数据预处理
4.1.1数据清洗
users=pd.read_csv(r'C:\Users\Lenovo\Desktop\案例集\基于机器学习的餐饮企业经营数据挖掘与预测\data\users.csv',encoding='gbk')
user_loss=pd.read_csv(r'C:\Users\Lenovo\Desktop\案例集\基于机器学习的餐饮企业经营数据挖掘与预测\data\user_loss.csv',encoding='gbk')
# 要删除的列索引列表
cols_to_drop = [1, 6, 7, 9, 10, 11, 13, 15, 16, 17, 18, 19, 20, 21, 22, 24, 26, 29, 30, 31, 32]
# 使用 iloc 按照位置删除列
users = users.drop(users.columns[cols_to_drop], axis=1)
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体字
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
users=users.iloc[:,[0,1,6,7,12,15]]
users = users.drop(index=[0,1])
users_order= pd.merge(users, order_info, left_on='ACCOUNT', right_on='name', how='inner')
users_order=users_order.iloc[:,[0,1,8,11,12,13,14]]
4.1.2特征工程
# 计算观测时间(取数据中最晚的日期)
obs_time = users_order['use_start_time'].max()
# 按USER_ID分组
grouped = users_order.groupby('USER_ID')
# 计算各指标
frequence = grouped.size().reset_index(name='frequence')
numbers = grouped['number_consumers'].sum().reset_index(name='numbers')
amount = grouped['expenditure'].sum().reset_index(name='amount')
last_time = grouped['use_start_time'].max().reset_index(name='last_time')
last_time['recently'] = (obs_time - last_time['last_time']).dt.days
# 合并结果
result = frequence.merge(numbers, on='USER_ID') \
.merge(amount, on='USER_ID') \
.merge(last_time[['USER_ID', 'recently']], on='USER_ID')
# 计算平均消费
result['average'] = result['amount'] / result['frequence']
# 输出结果(包含USER_ID和所有指标)
print(result[['USER_ID', 'frequence', 'numbers', 'amount', 'average', 'recently']])
result=pd.merge(result,user_loss[['USER_ID','type']],how='left',left_on='USER_ID',right_on='USER_ID')
4.2构建决策树模型
4.2.1数据准备
# 删除缺失值
result = result.dropna(axis=0)
# 提取特征和标签
result = result.iloc[:, [0,1,3,5,4,6]]
# 删除流失用户
result = result[result['type'] != "已流失"]4.2.2模型的训练与评估
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import confusion_matrix, classification_report
from sklearn.preprocessing import LabelEncoder
# 假设数据已加载为DataFrame,变量名为result
# 删除无关列(USER_ID不作为特征)
data = result.drop('USER_ID', axis=1)
# 将目标变量编码为数值
le = LabelEncoder()
data['type_encoded'] = le.fit_transform(data['type'])
# 划分特征和标签
X = data[['frequence', 'amount', 'average', 'recently']]
y = data['type_encoded']
# 分割数据集(80%训练,20%测试)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
# 初始化并训练决策树模型
model = DecisionTareeClassifier(random_state=42)
model.fit(X_train, y_train)
# 预测测试集
y_pred = model.predict(X_test)
# 输出评估指标
print("混淆矩阵:\n", confusion_matrix(y_test, y_pred))
print("\n分类报告:\n", classification_report(y_test, y_pred, target_names=le.classes_))
第5章 基于SARIMA模型对未来营业额进行预测
5.1数据预处理
# 转换时间列为datetime类型(自动兼容不同分隔符)
order['place_order_time'] = pd.to_datetime(
order['place_order_time'],
format='%Y/%m/%d %H:%M:%S',
errors='coerce' # 无效时间转为NaT
)
# 提取年月日并创建新列
order['year'] = order['place_order_time'].dt.year
order['month'] = order['place_order_time'].dt.month
order['day'] = order['place_order_time'].dt.day
order['total_amounts']=order['counts']*order['amounts']
#计算每个菜品的总销售额
daily_sales = order.groupby('day')['total_amounts'].sum().reset_index(name='dish_total_sales')
daily_sales
5.2数据平稳化
plt.figure(figsize=(12, 6))
# 绘制折线图
sns.lineplot(
x='day',
y='dish_total_sales',
data=daily_sales,
marker='o', # 显示数据点
linewidth=2,
color='royalblue'
)
# 添加标题和标签
plt.title('Daily Total Sales by Dish (August 2016)', fontsize=14, pad=20)
plt.xlabel('Day of Month', fontsize=12)
plt.ylabel('Total Sales (Yuan)', fontsize=12)
plt.xticks(range(1, 32)) # 显示1-31日的刻度
# 高亮峰值点
max_day = daily_sales.loc[daily_sales['dish_total_sales'].idxmax(), 'day']
max_sales = daily_sales['dish_total_sales'].max()
plt.scatter(max_day, max_sales, color='red', s=100, zorder=5)
plt.annotate(
f'Peak: Day {max_day}\n¥{max_sales:,}',
xy=(max_day, max_sales),
xytext=(10, 10),
textcoords='offset points',
arrowprops=dict(arrowstyle='->')
)
# 网格和布局优化
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show()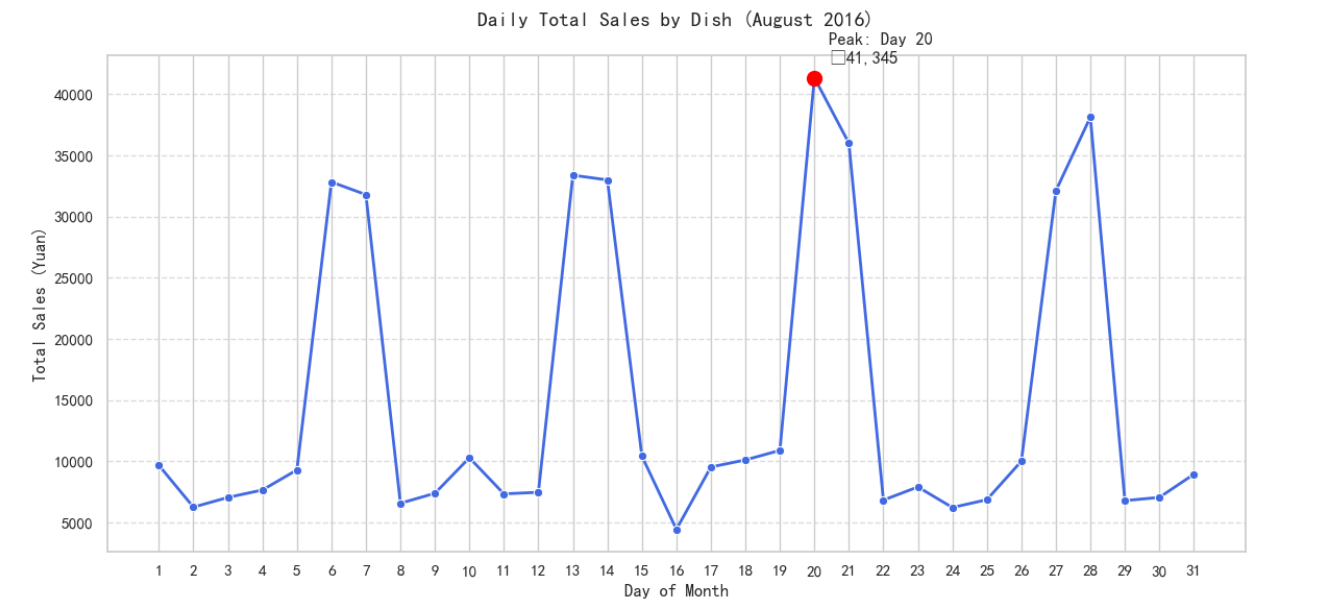
对八月营业额进行描述性统计,如下图所示,可以看出数据是具有明显的季节性,所以可以采用差分的方法来进行处理,让数据变得更加平稳。
plt.rcParams['font.sans-serif'] = ['STHeiti']
plt.rcParams['axes.unicode_minus'] = False
# 一阶差分
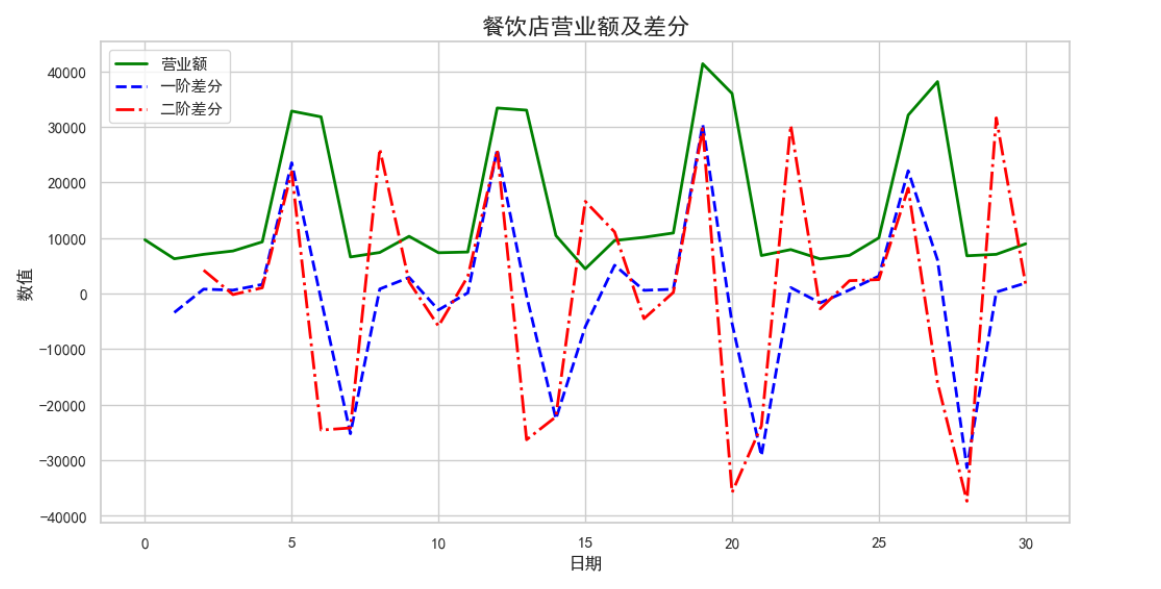
daily_sales['diff_1'] = daily_sales['dish_total_sales'].diff(1)
# 二阶差分
daily_sales['diff_2'] = daily_sales['diff_1'].diff(1)
# 绘制营业额、一阶差分和二阶差分的数据
plt.figure(figsize=(12, 6))
plt.plot(daily_sales.index, daily_sales['dish_total_sales'], label='营业额', color='green', linestyle='-', linewidth=2)
plt.plot(daily_sales.index, daily_sales['diff_1'], label='一阶差分', color='blue', linestyle='--', linewidth=2)
plt.plot(daily_sales.index, daily_sales['diff_2'], label='二阶差分', color='red', linestyle='-.', linewidth=2)
plt.title('餐饮店营业额及差分', fontsize=16)
plt.xlabel('日期', fontsize=12)
plt.ylabel('数值', fontsize=12)
plt.grid(True) # 添加网格线
# 添加图例
plt.legend()
plt.show()
from statsmodels.tsa.stattools import adfuller
# 对二阶差分后的数据进行ADF检验
result = adfuller(daily_sales['diff_2'].dropna())
print(f'ADF检验的p值: {result[1]}')
if result[1] < 0.05:
print("数据已经平稳,可以进行建模。")
else:
print("数据还未平稳,需要进一步处理。")
经过差分后的营业额如下图所示,并对二阶差分后的数据进行ADF检验,p值为0.043,低于显著性水平0.05,说明数据已经平稳可以进行建模。由于营业额是具有很明显的周期性,即周六周日会达到本周的高峰,所以针对具有周期性的数据采用SARIMA模型来进行建模。
为了选择合适的ARIMA和季节性成分参数,我们绘制了自相关函数(ACF)和偏自相关函数(PACF)图。这有助于我们选择模型中的p、q和季节性部分P、Q的值。
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
plt.rcParams['font.sans-serif'] = ['STHeiti']
plt.rcParams['axes.unicode_minus'] = False
# 绘制ACF和PACF图来帮助选择p, q值
plt.figure(figsize=(12, 6))
plt.subplot(121)
plot_acf(daily_sales['diff_2'].dropna(), lags=7, ax=plt.gca())
plt.subplot(122)
plot_pacf(daily_sales['diff_2'].dropna(), lags=7, ax=plt.gca())
plt.show()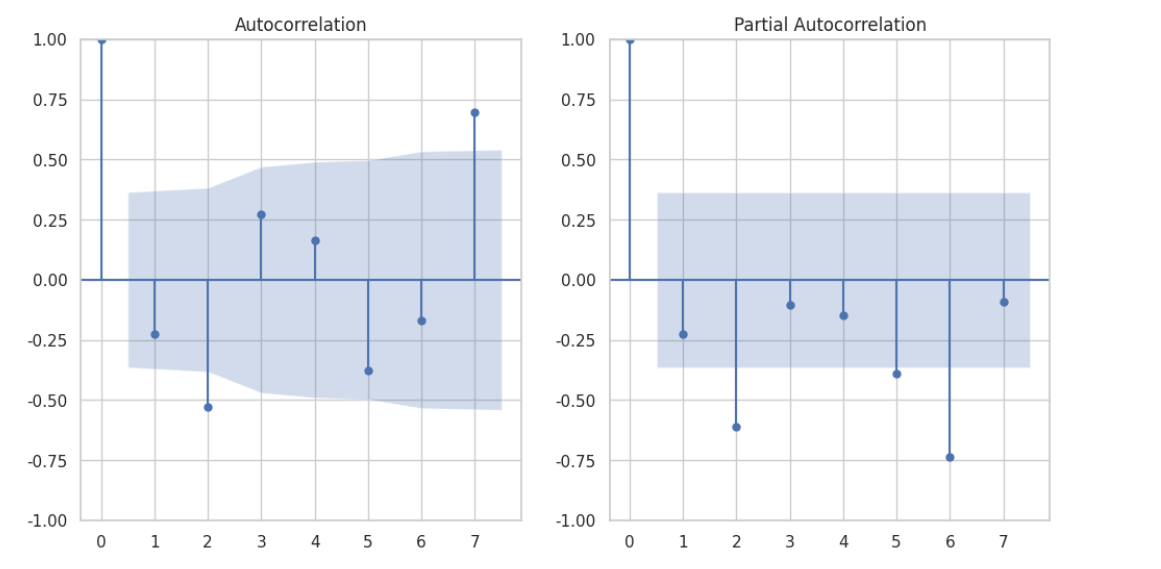
5.3模型建立
from sklearn.metrics import mean_absolute_error, mean_squared_error
import numpy as np
from statsmodels.tsa.statespace.sarimax import SARIMAX
# 定义 SARIMA 模型参数
model = SARIMAX(result['dish_total_sales'],
order=(1, 1, 1), # ARIMA部分 (p, d, q)
seasonal_order=(1, 1, 1, 7), # 季节性部分 (P, D, Q, S)
enforce_stationarity=False,
enforce_invertibility=False)
# 拟合模型
sarima_result = model.fit(disp=False)
# 打印模型的摘要信息
print(sarima_result.summary())
# 假设你将数据分为训练集和测试集(这里我们用后7天作为测试集)
train = daily_sales['dish_total_sales'][:-7]
test = daily_sales['dish_total_sales'][-7:]
# 重新拟合模型(仅使用训练集)
model = SARIMAX(train,
order=(1, 1, 1),
seasonal_order=(1, 1, 1, 7),
enforce_stationarity=False,
enforce_invertibility=False)
sarima_result = model.fit(disp=False)
# 预测测试集
predictions = sarima_result.get_forecast(steps=7).predicted_mean
# 计算误差
mae = mean_absolute_error(test, predictions)
rmse = np.sqrt(mean_squared_error(test, predictions))
print(f'MAE: {mae}')
print(f'RMSE: {rmse}')
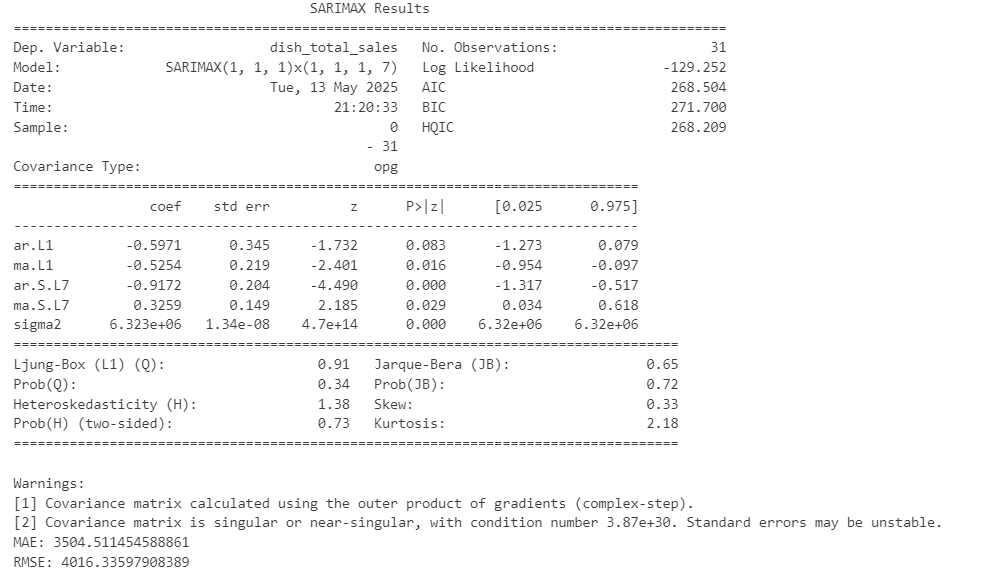
# 绘制训练集和测试集的真实值
plt.figure(figsize=(12, 6))
plt.plot(train.index, train, label='Train')
plt.plot(test.index, test, label='Test', color='orange')
# 绘制测试集的预测值
plt.plot(test.index, predictions, label='Predictions', color='green')
plt.title('SARIMAX模型预测和实际比较')
plt.xlabel('日期')
plt.ylabel('营业额')
plt.legend()
plt.grid(True)
plt.show()
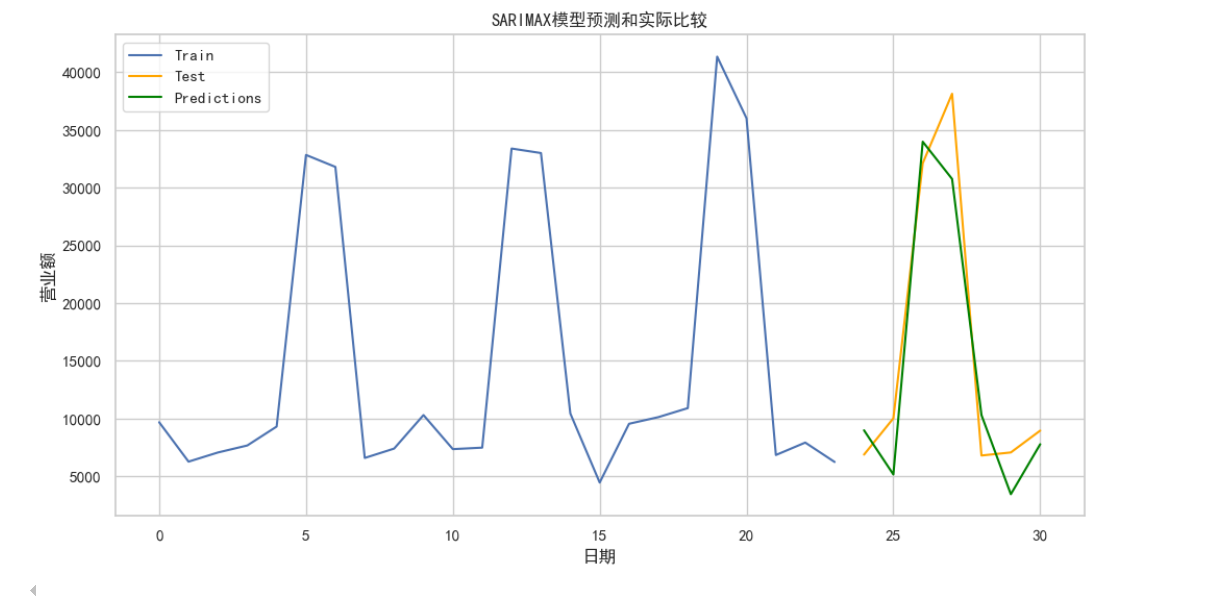
从图表中可以看出,SARIMA模型能够较好地捕捉到餐饮店营业额的季节性波动,并准确预测了未来几天的营业额。虽然模型的误差(如MAE和RMSE)并非为零,但考虑到数据的波动性和复杂性,这样的误差水平可以接受。
通过网盘分享的文件:基于机器学习的餐饮企业经营数据挖掘与预测
链接: https://pan.baidu.com/s/1u8nx_Ok6fe42Wsv2eHayWw?pwd=n4y6 提取码: n4y6

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐



 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)