Python 训练营打卡 Day 14
SHAP可视化解释机器学习。
SHAP可视化解释机器学习
一.数据预处理
import pandas as pd
import pandas as pd #用于数据处理和分析,可处理表格数据。
import numpy as np #用于数值计算,提供了高效的数组操作。
import matplotlib.pyplot as plt #用于绘制各种类型的图表
import seaborn as sns #基于matplotlib的高级绘图库,能绘制更美观的统计图形。
import warnings
warnings.filterwarnings("ignore")
# 设置中文字体(解决中文显示问题)
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows系统常用黑体字体
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
data = pd.read_csv('data.csv') #读取数据
# 先筛选字符串变量
discrete_features = data.select_dtypes(include=['object']).columns.tolist()
# Home Ownership 标签编码
home_ownership_mapping = {
'Own Home': 1,
'Rent': 2,
'Have Mortgage': 3,
'Home Mortgage': 4
}
data['Home Ownership'] = data['Home Ownership'].map(home_ownership_mapping)
# Years in current job 标签编码
years_in_job_mapping = {
'< 1 year': 1,
'1 year': 2,
'2 years': 3,
'3 years': 4,
'4 years': 5,
'5 years': 6,
'6 years': 7,
'7 years': 8,
'8 years': 9,
'9 years': 10,
'10+ years': 11
}
data['Years in current job'] = data['Years in current job'].map(years_in_job_mapping)
# Purpose 独热编码,记得需要将bool类型转换为数值
data = pd.get_dummies(data, columns=['Purpose'])
data2 = pd.read_csv("data.csv") # 重新读取数据,用来做列名对比
list_final = [] # 新建一个空列表,用于存放独热编码后新增的特征名
for i in data.columns:
if i not in data2.columns:
list_final.append(i) # 这里打印出来的就是独热编码后的特征名
for i in list_final:
data[i] = data[i].astype(int) # 这里的i就是独热编码后的特征名
# Term 0 - 1 映射
term_mapping = {
'Short Term': 0,
'Long Term': 1
}
data['Term'] = data['Term'].map(term_mapping)
data.rename(columns={'Term': 'Long Term'}, inplace=True) # 重命名列
continuous_features = data.select_dtypes(include=['int64', 'float64']).columns.tolist() #把筛选出来的列名转换成列表
# 连续特征用中位数补全
for feature in continuous_features:
mode_value = data[feature].mode()[0] #获取该列的众数。
data[feature].fillna(mode_value, inplace=True) #用众数填充该列的缺失值,inplace=True表示直接在原数据上修改。
# 最开始也说了 很多调参函数自带交叉验证,甚至是必选的参数,你如果想要不交叉反而实现起来会麻烦很多
# 所以这里我们还是只划分一次数据集
from sklearn.model_selection import train_test_split
X = data.drop(['Credit Default'], axis=1) # 特征,axis=1表示按列删除
y = data['Credit Default'] # 标签
# 按照8:2划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 80%训练集,20%测试集以随机森林为例,来介绍几种shap可视化图像
from sklearn.ensemble import RandomForestClassifier #随机森林分类器
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score # 用于评估分类器性能的指标
from sklearn.metrics import classification_report, confusion_matrix #用于生成分类报告和混淆矩阵
import warnings #用于忽略警告信息
warnings.filterwarnings("ignore") # 忽略所有警告信息
# --- 1. 默认参数的随机森林 ---
# 评估基准模型,这里确实不需要验证集
print("--- 1. 默认参数随机森林 (训练集 -> 测试集) ---")
import time # 这里介绍一个新的库,time库,主要用于时间相关的操作,因为调参需要很长时间,记录下会帮助后人知道大概的时长
start_time = time.time() # 记录开始时间
rf_model = RandomForestClassifier(random_state=42)
rf_model.fit(X_train, y_train) # 在训练集上训练
rf_pred = rf_model.predict(X_test) # 在测试集上预测
end_time = time.time() # 记录结束时间
print(f"训练与预测耗时: {end_time - start_time:.4f} 秒")
print("\n默认随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred))
print("默认随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred))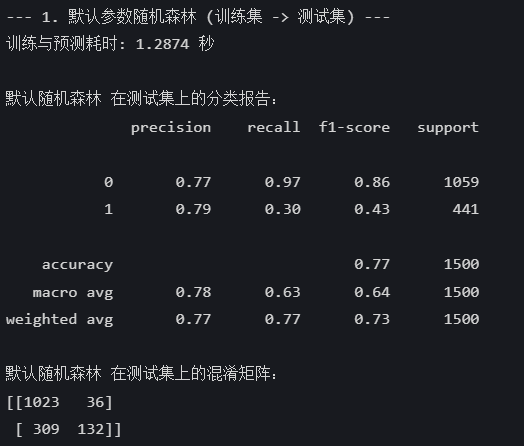
利用shap库解释随机森林模型
import shap
import matplotlib.pyplot as plt
# 初始化SHAP解释器
explainer = shap.TreeExplainer(rf_model)
#计算shap值(基于测试集)
shap_values = explainer.shap_values(X_test)
# 每一行代表一个样本,每一列代表一个特征,值表示该特征对该样本的预测结果的影响程度。正值表示该特征对预测结果有正向影响,负值表示负向影响。
shap_values
# 第一维是样本数,第二维是特征数,第三维是类别数
shap_values.shape 输出结果:(1500, 31, 2)
print("shap_values shape:", shap_values.shape)
print("shap_values[0] shape:", shap_values[0].shape)
print("shap_values[:, :, 0] shape", shap_values[:, :, 0].shape)
print("X_test shape:", X_test.shape)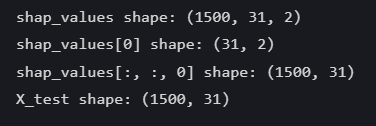
SHAP 特征重要性条状图
将 SHAP 值矩阵传递给条形图函数会创建一个全局特征重要性图,其中每个特征的全局重要性被视为该特征在所有给定样本中的平均绝对值
print("--- 1. SHAP 特征重要性条形图 ---")
shap.summary_plot(shap_values[:, :, 0], X_test, plot_type="bar", show=Flase) # 这里的show=False表示不直接显示图形,这样可以继续用plt来修改元素,不然就直接输出了
"SHAP Feature Importance (Bar Plot)"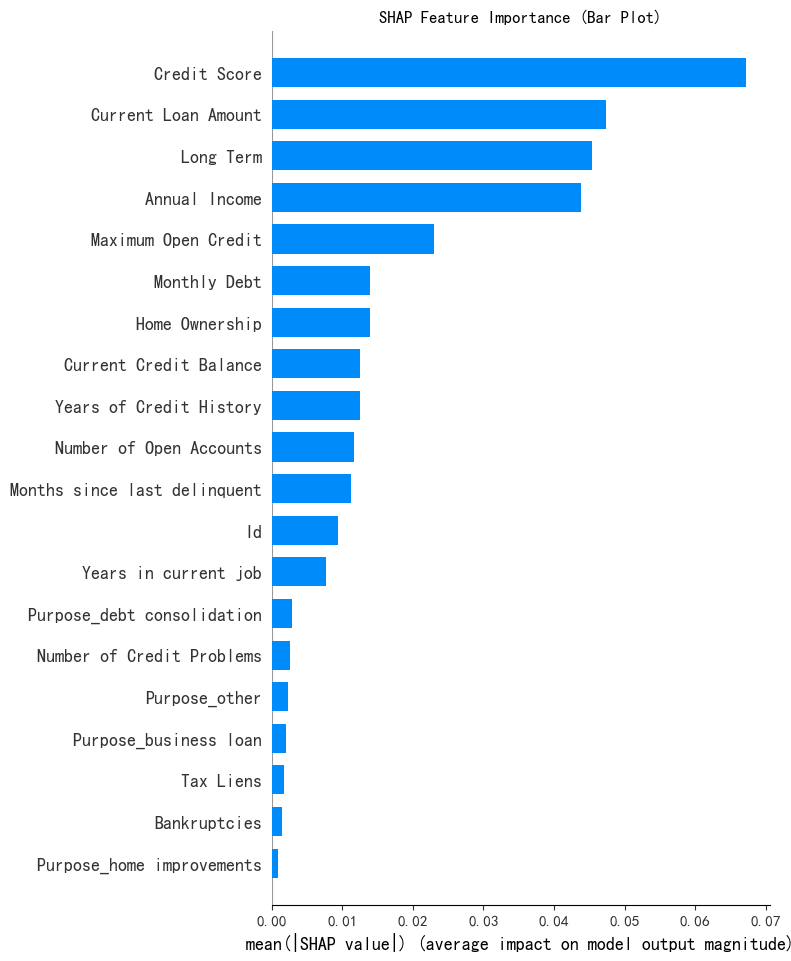
SHAP 特征重要性蜂巢图
蜂群图以信息密集的形式,直观展现数据集中关键特征对模型输出的影响。图中每个实例在各特征流上对应一个点,点的横向位置由特征的 SHAP 值决定(shap_values.value[instance,feature]),且沿特征行堆积呈现数据密度。同时,通过颜色映射特征原始值(shap_values.data[instance,feature]),帮助快速理解特征作用机制。
print("--- 2. SHAP 特征重要性蜂巢图 ---")
shap.summary_plot(shap_values[:, :, 0], X_test, plot_type="Violin", show=Flase, max_display=10)
plt.title("SHAP Feature Importance (Violin Plot)")
plt.show()
# plot_type可以是bar和violin,max_display表示显示前多少个特征,默认是20个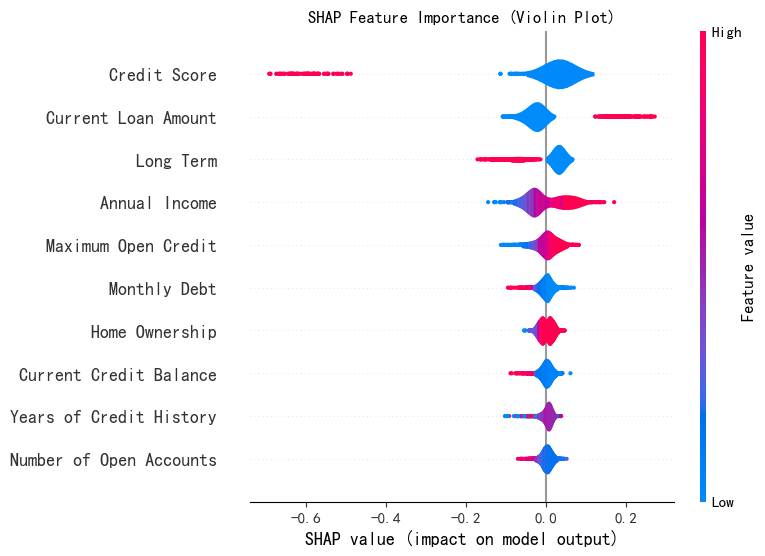
生成下方几个图时,shap_values.shape 和 X_test.shape 不匹配,因此做了基础处理
1.确保SHAP值计算正确
2.处理多分类情况并检查维度
3.确保维度匹配
4.增加错误处理
SHAP 依赖图
依赖图显示了一个或两个特征对机器学习模型的预测结果的边际效应,它可以显示目标和特征之间的关系是线性的、单调的还是更复杂的。他们在许多样本中绘制了一个特征的值与该特征的 SHAP 值
# 1. 确保SHAP值计算正确
import shap
explainer = shap.TreeExplainer(rf_model)
shap_values = explainer.shap_values(X_test)
# 2. 处理多分类情况并检查维度
if isinstance(shap_values, list):
shap_values_class0 = shap_values[0] # 取第一个类别的SHAP值
else:
shap_values_class0 = shap_values
# 3. 确保维度匹配
if len(shap_values_class0.shape) == 3:
shap_values_class0 = shap_values_class0[:,:,0] # 取第一个特征维度
# 4. 绘制依赖图(添加错误处理)
try:
shap.dependence_plot(
"Annual Income",
shap_values_class0,
X_test.values if hasattr(X_test, 'values') else X_test,
feature_names=X_test.columns.tolist(),
show=False,
interaction_index=None # 明确指定不计算交互特征
)
plt.title("SHAP Dependence Plot for Annual Income")
plt.tight_layout()
plt.show()
except Exception as e:
print(f"绘图出错: {str(e)}")
print(f"SHAP值形状: {shap_values_class0.shape}")
print(f"X_test形状: {X_test.shape}")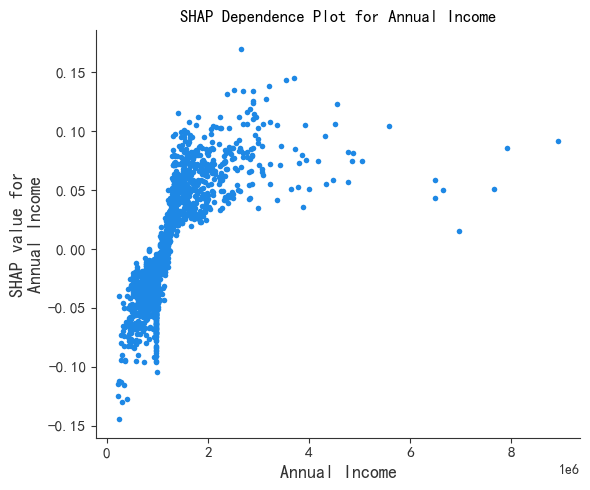
单个预测的解释可视化
SHAP force plot(力图)
SHAP force plot 将每个特征的 SHAP 值以力的形式展示出来,箭头的方向表示特征对预测结果的影响方向,箭头的长度表示特征的重要性程度
import shap
explainer = shap.TreeExplainer(rf_model)
shap_values = explainer.shap_values(X_test)
# 2. 维度检查与修正
print(f"原始SHAP值形状: {shap_values.shape}") # 检查维度
print(f"X_test形状: {X_test.shape}")
if isinstance(shap_values, list):
shap_values = shap_values[0] # 多分类取第一个类别
if len(shap_values.shape) == 3:
shap_values = shap_values[:,:,0] # 处理三维情况
# 3. 绘制力图(带完整错误处理)
try:
sample_idx = 0 # 可修改为其他样本索引
shap.initjs()
shap.force_plot(
explainer.expected_value[0],
shap_values[sample_idx],
X_test.iloc[sample_idx],
feature_names=X_test.columns.tolist(),
matplotlib=True,
show=False
)
plt.title(f"SHAP特征影响力 - 样本{sample_idx}")
plt.tight_layout()
plt.show()
except Exception as e:
print(f"绘图失败: {str(e)}")
print("建议检查:")
print("1. SHAP值形状:", shap_values.shape)
print("2. 数据形状:", X_test.shape)
print("3. 列名匹配:", X_test.columns.tolist())原始SHAP值形状: (1500, 31, 2)
X_test形状: (1500, 31)

具体特征分析
红色负向影响特征:
Current Credit Balance:当前信用余额,值为 13985900.0 ,该特征值较大,且呈现红色,说明它对预测结果有较大的负向影响,即当前信用余额越高,越可能使预测结果降低。
Home Ownership = 4.0:房屋所有权情况(可能是某种编码值 ),值为 4.0 ,产生负向影响。Long Term - Annual:长期 - 年度相关特征(推测可能是某种长期的年度指标 ),值为 970 ,有负向影响。
Income:收入,值为 2396375.0 ,通常直观上收入高可能预期正向影响,但在此处呈现红色,说明在该模型中,这个收入数值对预测结果起到负向作用。
Credit Score = 7130.0:信用评分,值为 7130.0 ,同样呈现负向影响,与一般认知中信用评分高应是正向作用相悖,说明模型中该特征作用方向特殊。
蓝色正向影响特征:
Current Loan Amount:当前贷款金额,值为 1250400.0 ,对预测结果有正向影响,即当前贷款金额在模型中促使预测结果升高。
Month:月份(推测 ),值为 2.5 ,起到正向作用。
Year:年份(推测 ),值为 25.0 ,有正向影响。
Credit History = 10.5:信用记录时长,值为 10.5 ,正向影响预测结果,符合一般认知,即信用历史越长越有利。
Decision plot(决策图)
决策图旨在展示各个特征对特定样本预测结果的影响,帮助理解模型为何做出这样的预测,是模型可解释性工具。
# 1. 安全检查SHAP值维度
print(f"SHAP值结构类型: {type(shap_values)}")
if isinstance(shap_values, list):
print(f"类别数量: {len(shap_values)}")
print(f"第一个类别SHAP值形状: {shap_values[0].shape}")
else:
print(f"SHAP值形状: {shap_values.shape}")
# 2. 修正决策图绘制
plt.figure(figsize=(12, 8))
try:
shap.decision_plot(
explainer.expected_value[0],
shap_values[0] if isinstance(shap_values, list) else shap_values,
feature_names=X_test.columns.tolist(),
show=False
)
plt.title("SHAP决策图", fontsize=14)
plt.tight_layout()
plt.show()
except Exception as e:
print(f"绘图错误: {str(e)}")
print("建议检查SHAP值与特征维度是否匹配")SHAP值结构类型: <class 'numpy.ndarray'>
SHAP值形状: (1500, 31)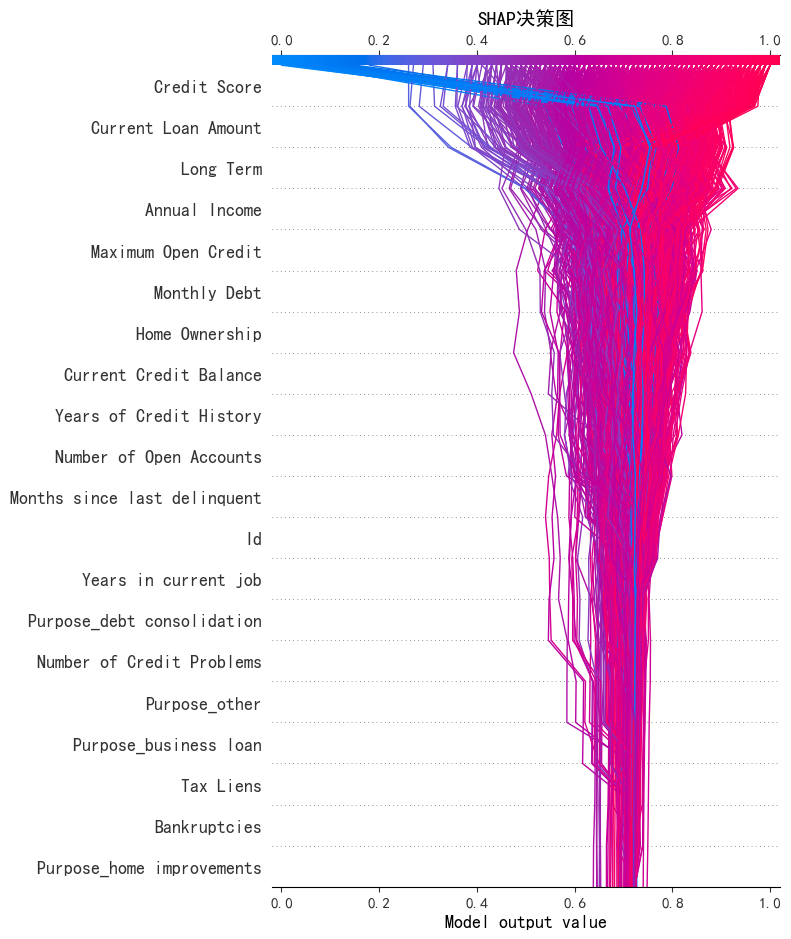
重要特征:
Credit Score(信用评分):线条跨度较大且多数为蓝色向红色过渡,说明信用评分对模型输出影响显著。较高的信用评分(红色区域)会使模型输出值增加,即更有利于得到模型倾向的结果(如贷款批准 );较低信用评分(蓝色区域)则相反。
Current Loan Amount(当前贷款金额):线条分布也较广,当前贷款金额越高(红色区域 ),可能越不利于模型倾向结果,使模型输出值降低。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 32
32 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)