深度学习周报--第四周
本周跟着吴恩达老师的机器学习系列课程学习了多元线性回归的相关知识,了解了特征缩放与正规方程的原理及公式,用两种方法完成了多元线性回归的代码实现,对特征缩放的作用与正规方程有了更加清楚的了解。
摘要
本周跟着吴恩达老师的机器学习系列课程在单变量线性回归的基础上学习了多元线性回归,了解了特征缩放和正规方程等技术,并利用代码进行了实现。其中多元线性回归允许模型考虑多个输入特征,从而更准确地预测输出结果。特征缩放通过归一化和标准化方法,确保不同特征的量级相近,加速了梯度下降的收敛过程。正规方程则可以直接计算最优参数。
Abstract
This week, I studied multivariate linear regression based on univariate linear regression in Andrew Ng's Machine Learning course. I learned techniques such as feature scaling and the normal equation, and implemented the models using code. Multiple linear regression allows the model to take into account multiple input features, thereby enabling more accurate prediction of the output. Feature scaling, through normalization and standardization techniques, ensures that different features are on a similar scale, which accelerates the convergence of gradient descent. The normal equation provides a direct way to compute the optimal parameters analytically.
1 多元线性回归
多元线性回归是单变量线性回归的拓展,它根据多个输入特征来预测输出结果,考虑了多个影响因素,使得模型更加贴近现实世界的问题。
由于有多个输入特征,那么可以定义假设函数为:
也可以写成向量形式:
其中是参数向量,x 是包含偏置项 1 的特征向量,下式中
通常为1.
所以,代价函数可以定义为:
梯度下降公式:
即:
上述式子中,m代表样本数量,n代表特征数量,代表第i个样本中第j个特征量。
2 多元梯度下降中的使用技巧
2.1 特征缩放
在多元线性回归中,各个输入特征可能具有不同的量级或单位,这可能会导致某些特征对目标变量的影响被放大或缩小,进而影响模型训练的效果。
例如,如果一个特征的范围是从0到1,而另一个特征的范围是从0到1000,那么在不进行特征缩放的情况下,梯度下降算法可能会花费更多的时间来收敛,甚至可能无法正确收敛。
特征缩放就能够确保不同特征的取值处在相近范围内(不必完全相同),使梯度下降更快收敛。
常见的特征缩放方法包括归一化和标准化
2.1.1 归一化
归一化是指将特征缩放到一个特定的区间,通常为[-1, 1]或[0, 1],公式为:
其中为第i个特征的最大值最小值之差。
以房价预测为例,假设有两个特征,是房屋面积,取值范围0~2000平方英尺,
是卧室数量,取值范围1~5个,进行归一化操作:
其代价函数等值线与梯度下降过程可能发生如下变化:
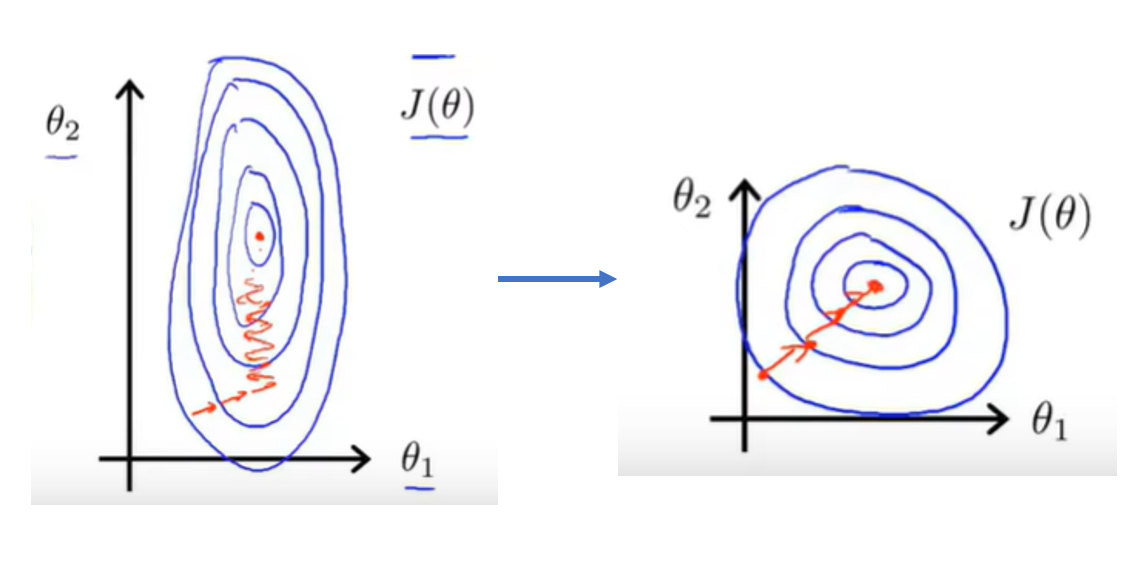
均值归一化是在归一化的基础上,将数据集中心化的方法,其目的是让所有特征值围绕0分布,并且具有相似的尺度。这有助于加速梯度下降等优化算法的收敛速度。其公式为:
其中为第i个特征的均值。
2.1.2 标准化
标准化的目标是将数据转换为均值为0、标准差为1的分布,即标准正态分布。其计算方式如下:
其中为第i个特征的均值,
为第i个特征的标准差。
2.2 学习率
判断梯度下降是否正常运行有两种方法。
一种是自动收敛测试。自动收敛测试是一种用于判断模型训练是否已经收敛的技术,它的难点在于选择合适的阈值(当代价函数值小于阈值时认为已经收敛)。
另一种是通过绘制代价函数随迭代次数变化的图表来手动监控收敛情况,如果梯度下降算法正常工作,那么每一步迭代之后都应下降,如下图:
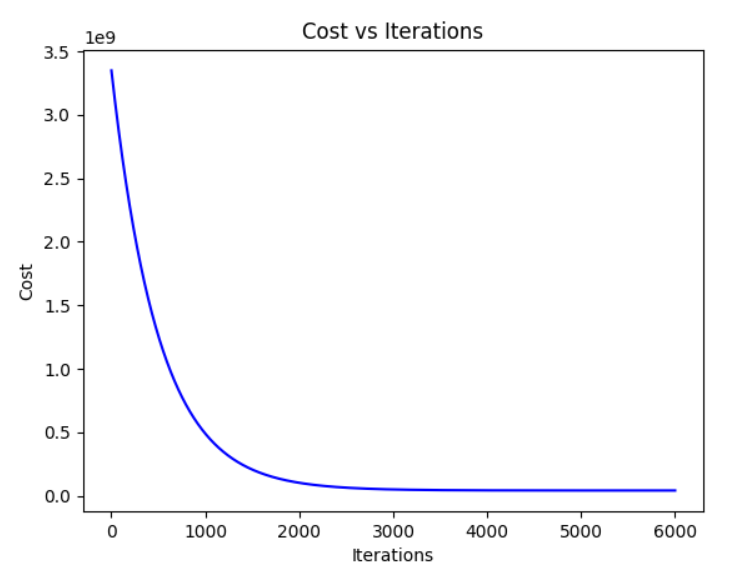
纵坐标为最小化代价函数的值,横坐标为迭代次数。当图像变得平坦(如上图中横坐标4000~6000轮),则可适当减少迭代轮次。
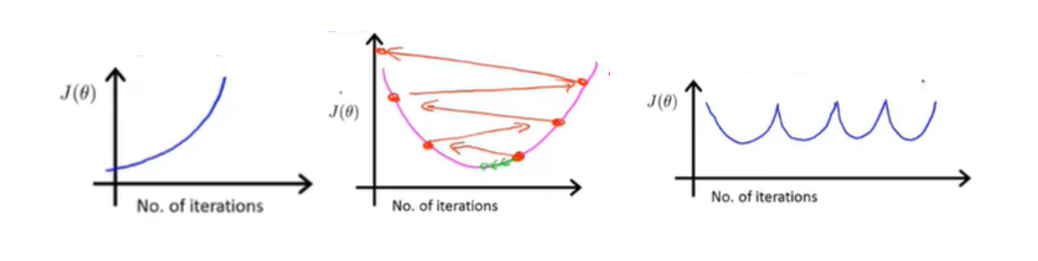
学习率太小则会导致收敛速度太慢,浪费时间;学习率太大可能导致代价函数值不下降甚至不收敛,如下图:
3 正规方程
除了使用梯度下降来最小化代价函数外,另一种求解线性回归问题的方法是利用正规方程。正规方程可以直接计算出使得代价函数最小化的参数值。相比梯度下降,它无需迭代过程,无需选择学习率,无需进行特征缩放,但计算量大,当特征数目多(万以上)时,计算速度会变慢。
其公式为:
其中X为设计矩阵,包含所有的输入特征,维度为,m是样本数量,n是特征数量。
y是m维向量,包含所有的目标值。
设计矩阵:一行是一个样本的所有特征,一列对应一个特征的所有样本(默认为1)。
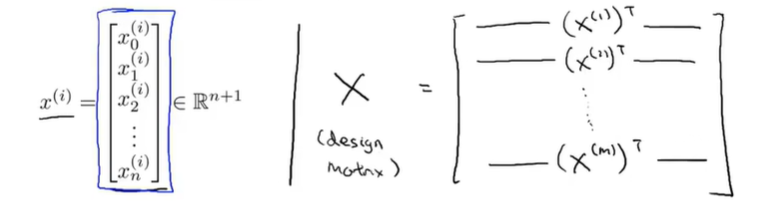
单变量线性回归的设计矩阵如下:
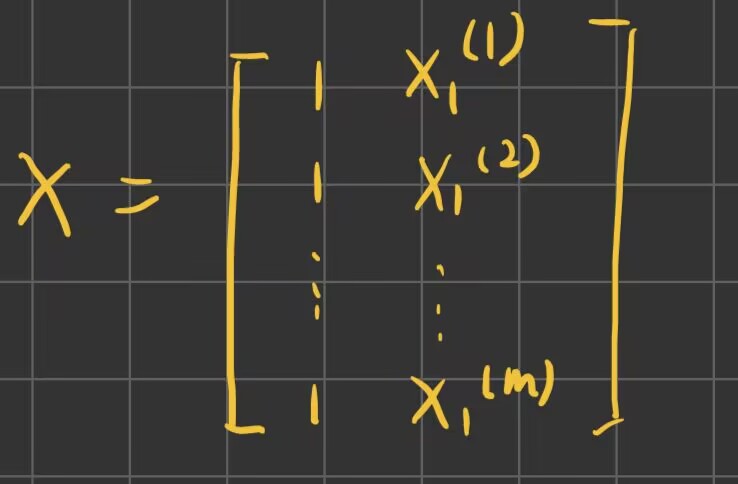
如果不可逆,可能有两方面的原因,一方面是包含了多余的特征,即特征之间存在线性相关,例如不同单位下的房屋面积;另一方面是特征数量太大,超过了样本数量(参数多样本少)。因此可以通过减少特征数量或者利用正则化来解决。
4 代码实现
根据面积,房间客厅数,学区数量,年份,以及楼层预测房价,数据集是和鲸社区上的北京房价预测,链接:北京房价预测 - Heywhale.com
4.1 梯度下降
使用梯度下降的方法,总体代码与单变量线性回归类似,只在数据处理与初始化参数时稍有不同。
4.1.1 数据处理
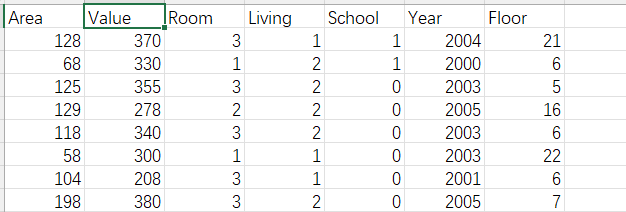
原数据如下图,可观察到房价在第二列。
def load_data(file_path):
data = np.loadtxt(file_path, delimiter=',', skiprows=1).astype(int)
X = np.delete(data, obj=1, axis=1)
# 删除第二列(obj代表索引,axis代表方向(0行,1列))
y = data[:, 1].reshape(-1, 1)
#归一化
min = np.min(X, axis=0)
max = np.max(X, axis=0)
r = max-min
X = (X - min) / r
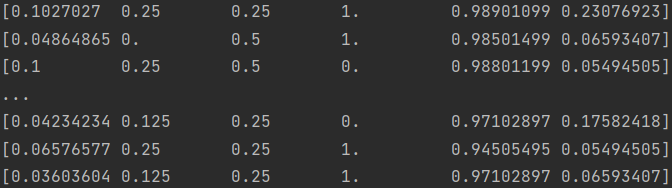
return X, y最终处理得到的输入特征矩阵如下:
4.1.2 初始化参数
共有6个输入特征,应初始化参数向量为7维向量。
theta_initial = np.zeros((7, 1))4.1.3 结果
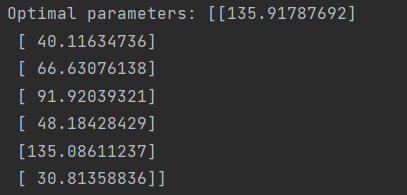
最优参数向量为:
代价随迭代轮次变化图像如下: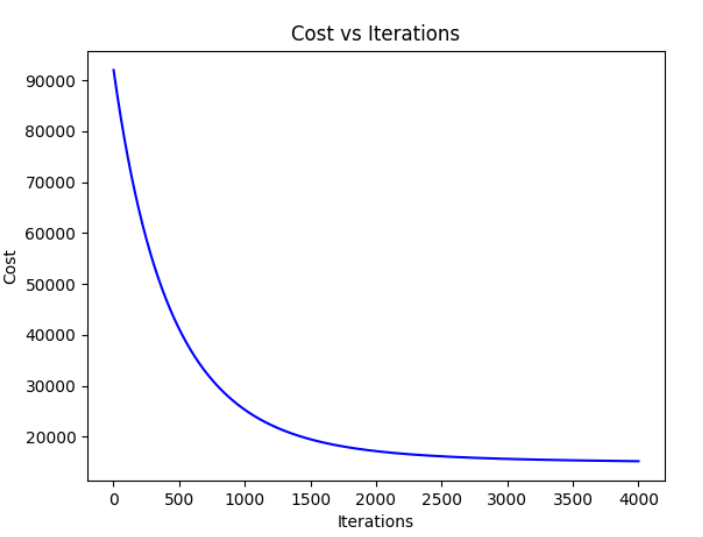
4.2 正规方程
def normal_equation(X, y):
theta = np.linalg.inv(X.T.dot(X)).dot(X.T).dot(y)
#X.T代表X的转置矩阵,.dot(X)代表与X矩阵相乘,得到(n+1)*(n+1)矩阵
#np.linalg.inv求解逆矩阵
#再与转置相乘得到(n+1)*m矩阵,最终与m维向量相乘得到n+1维向量,即参数向量
return theta
# 添加偏置单元
x_b = np.c_[np.ones((len(X), 1)), X]
#调用正规方程函数
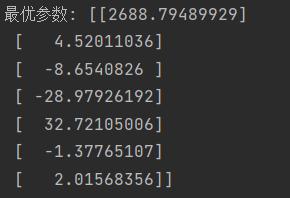
theta_optimal = normal_equation(x_b, y)最终所得参数向量如下所示:
5 总结
本周跟着吴恩达老师的机器学习系列课程学习了多元线性回归的相关知识,了解了特征缩放与正规方程的原理及公式,用两种方法完成了多元线性回归的代码实现,对特征缩放的作用与正规方程有了更加清楚的了解。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐



 42
42 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)