Python打卡 DAY 8 标签编码与连续变量处理
这段代码使用字典映射(mapping)方法,将heart数据集中的分类变量(字符串类型)转换为数值型编码,便于后续机器学习算法处理。将数据线性变换到[0,1]区间(默认)或指定区间[a,b]有序分类变量应按业务逻辑顺序编码(如疼痛程度)可自定义特殊值的编码(如'unknown')对异常值敏感(最大值/最小值会严重影响结果)将数据转换为均值为0,标准差为1的分布。避免使用-1等可能干扰模型的数值。顶
·
目录
1 标签编码
输入:
import pandas as pd
import sklearn as skl
data = pd.read_csv(r"heart.csv")
# 字典的键值对可以嵌套字典
mapping = {
"sex":
{
"male": 1,
"female": 0
},
'cp':
{
'typical angina': 0,
'atypical angina': 1,
'non-anginal pain': 2,
'asymptomatic': 3
},
'fbs':
{
'false': 0,
'true': 1
},
'restecg':
{
'normal': 0,
'ST-T wave abnormality': 1,
'left ventricular hypertrophy': 2
},
'exang':
{
'no': 0,
'yes': 1
},
'slope':
{
'upsloping': 0,
'flat': 1,
'downsloping': 2
},
'thal':
{
'normal': 0,
'fixed defect': 1,
'reversible defect': 2
},
"target":
{
'no': 0,
'yes': 1,
'unknown': 2},
}
data['sex'] = data['sex'].map(mapping['sex'])
data['cp'] = data['cp'].map(mapping['cp'])
data['fbs'] = data['fbs'].map(mapping['fbs'])
data['restecg'] = data['restecg'].map(mapping['restecg'])
data['exang'] = data['exang'].map(mapping['exang'])
data['slope'] = data['slope'].map(mapping['slope'])
data['thal'] = data['thal'].map(mapping['thal'])
data['target'] = data['target'].map(mapping['target'])
data.head()输出:
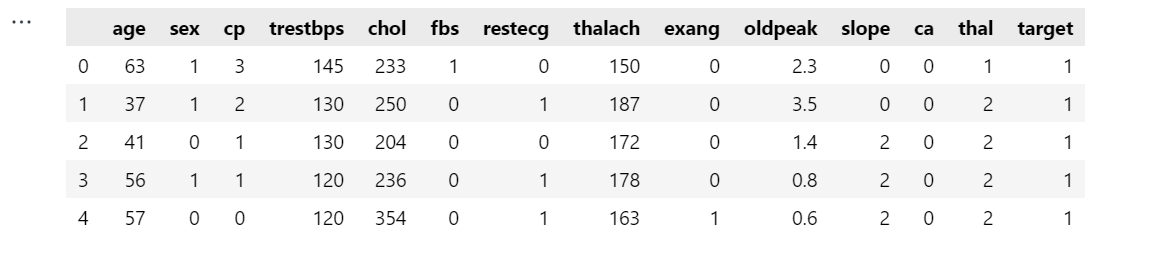
笔记:
这段代码使用字典映射(mapping)方法,将heart数据集中的分类变量(字符串类型)转换为数值型编码,便于后续机器学习算法处理。
1. 1 字典映射编码原理
mapping = {
"sex": {"male": 1, "female": 0},
"cp": {"typical angina": 0, ...}
}
data['sex'] = data['sex'].map(mapping['sex'])-
实现机制:
-
创建嵌套字典定义各列的映射关系
-
使用
Series.map()方法应用转换
-
-
优势:
-
编码规则清晰可见
-
可自定义特殊值的编码(如'unknown')
-
保持业务逻辑的可解释性
-
1.2. 字典结构设计技巧
{
"列名1": {"原始值1": 编码1, "原始值2": 编码2},
"列名2": {"原始值A": 编码A, ...}
}-
设计原则:
-
顶层键为列名,底层键为原始值
-
有序分类变量应按业务逻辑顺序编码(如疼痛程度)
-
二分类建议用0/1编码
-
1.3. 特殊值处理
"target": {'no': 0, 'yes': 1, 'unknown': 2}-
最佳实践:
-
为缺失/未知值保留专用编码
-
避免使用-1等可能干扰模型的数值
-
2.连续变量的处理
2.1 手动归一化
输入:
data = pd.read_csv(r"heart.csv")
# 手动实现归一化处理
list = ['age', 'trestbps', 'chol', 'thalach', 'oldpeak', 'slope']
for i in list:
data[i] = (data[i] - data[i].min())/(data[i].max() - data[i].min())
data.head()输出:
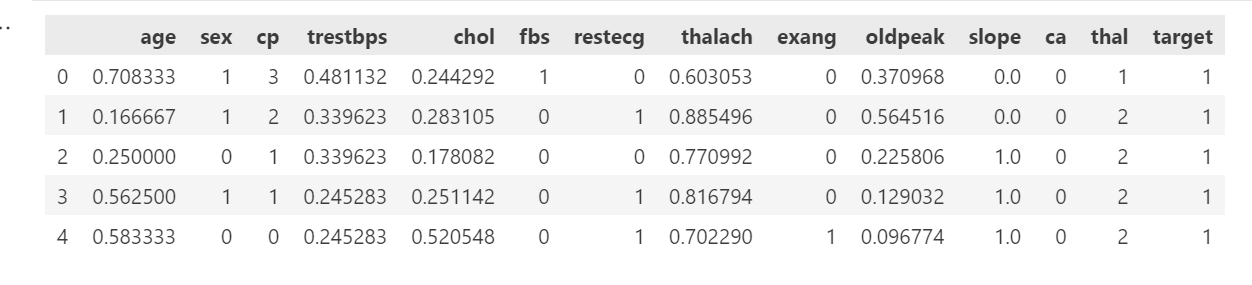
2.2 借助 sklearn 库实现归一化
输入:
#借助sklearn库进行归一化处理
from sklearn.preprocessing import StandardScaler, MinMaxScaler
data = pd.read_csv("heart.csv")# 重新读取数据
list = ['age', 'trestbps', 'chol', 'thalach', 'oldpeak', 'slope']
for i in list:
# 归一化处理
min_max_scaler = MinMaxScaler() # 实例化 MinMaxScaler类,之前课上也说了如果采取这种导入函数的方式,不需要申明库名
data[i] = min_max_scaler.fit_transform(data[[i]])
data.head()输出:
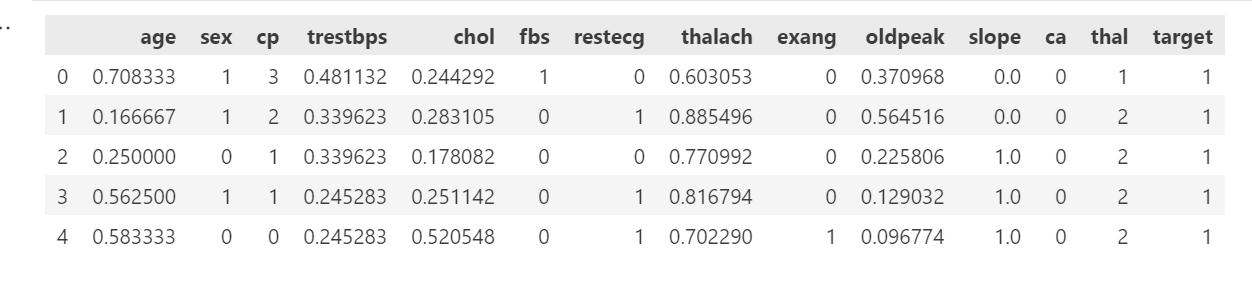
2.3 手动标准化
输入:
data = pd.read_csv(r'heart.csv')
# 手动标准化
list = ['age', 'trestbps', 'chol', 'thalach', 'oldpeak', 'slope']
for i in list:
data[i] = (data[i] - data[i].mean()) / data[i].std()
data.head()输出:
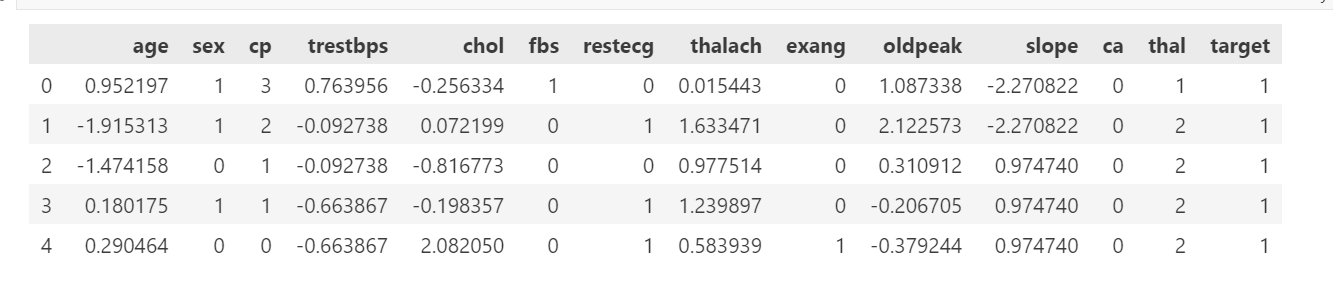
2.4 借助sklearn 库实现标准化
输入:
#借助sklearn库进行标准化处理
# 导入库
from sklearn.preprocessing import StandardScaler, MinMaxScaler
# 读取数据
data = pd.read_csv("heart.csv") # 重新读取数据
list = ['age', 'trestbps', 'chol', 'thalach', 'oldpeak', 'slope']
for i in list:
# 标准化处理
scaler = StandardScaler() # 实例化 StandardScaler,
data[i] = scaler.fit_transform(data[[i]]) # 标准化处理
data.head() 输出:
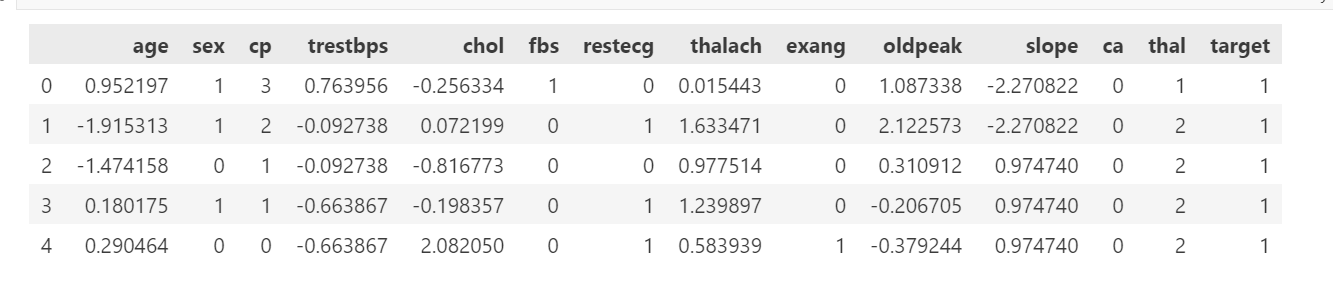
笔记:
2.4.1 归一化 (Normalization)
公式:
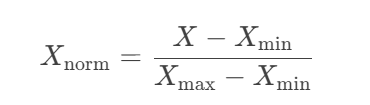
特性:
-
将数据线性变换到[0,1]区间(默认)或指定区间[a,b]
-
对异常值敏感(最大值/最小值会严重影响结果)
Python借助sklearn库实现:
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(0, 1)) # 可调整范围
X_normalized = scaler.fit_transform(X)2.4.2 标准化 (Standardization)
公式:
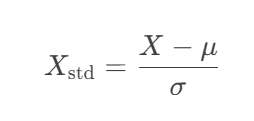
其中:
-
μ 是特征均值
-
σ 是特征标准差
特性:
-
将数据转换为均值为0,标准差为1的分布
-
保留异常值信息但减小其影响
-
适用于假设数据服从高斯分布的场景
Python实现:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
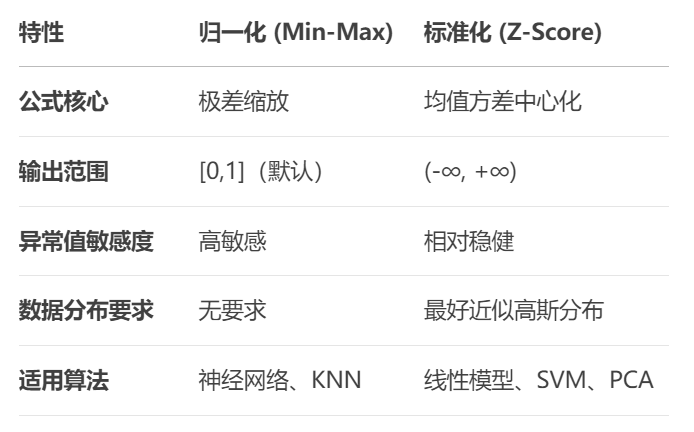
X_standardized = scaler.fit_transform(X)2.4.3 核心差异对比

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
 31
31 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)