day02 机器学习入门筑基2
0set;1set;2set;3set;4set;创建上下文(MLContext)加载数据(IDataView)构建转换管道(Concatenate + 算法)训练模型(Fit)判断文本的情感极性(积极或消极)【二分类问题】//训练的数据0set;1//训练的数据 public class SentimentData {get;set;get;set;} } //待预测数据 public clas
机器学习框架-ML.NET
介绍
继上次使用ML.NET开源机器学习框架和官方的训练数据【资料+答案】,在本地训练出来一个根据语句判断某个语境是积极的还是消极的。
特点
(1)支持将机器学习模型打包为 DLL 或嵌入应用程序,便于部署和维护。
(2)提供 分类、回归、聚类、异常检测、推荐系统、自然语言处理(NLP)、计算机视觉 等常见任务的预定义算法。
(3)两种使用模式:
代码优先(Code-First):通过编写 C# 代码定义数据管道、选择算法并训练模型,适合需要高度定制化的场景
自动化机器学习(AutoML):使用 ML.NET AutoML 工具自动搜索最优算法和超参数,降低入门门槛,适合快速原型开发。
(4)模型训练与推理一体化:支持 本地训练(基于内存数据或文件)和 分布式训练(通过 ML.NET 扩展或结合其他框架),训练后的模型可直接在 .NET 应用中进行 推理(预测),无需额外部署步骤,适合边缘计算或客户端推理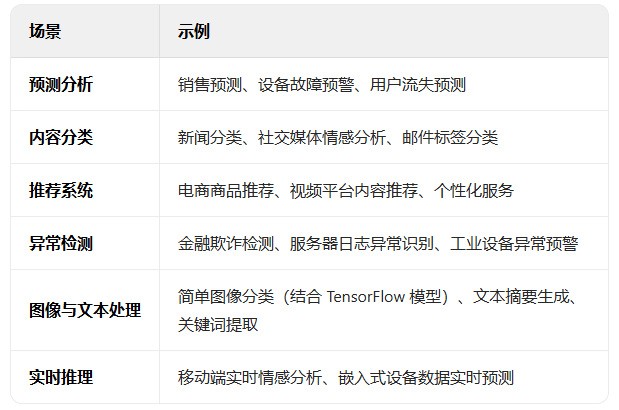
使用【代码优先模式】开发模型
1、定义数据模型
public class IrisData
{
[LoadColumn(0)] public float SepalLength { get; set; }
[LoadColumn(1)] public float SepalWidth { get; set; }
[LoadColumn(2)] public float PetalLength { get; set; }
[LoadColumn(3)] public float PetalWidth { get; set; }
[LoadColumn(4)] public string Label { get; set; }
}
代码详解:
数据类结构
数据模型是公共类:ML.NET要求数据模型必须是公共类,以便反射访问属性。每个字段通过public float/string PropertyName { get; set; }定义,支持自动 getter/setter。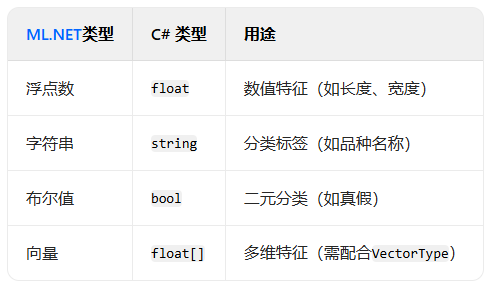
[LoadColumn] 属性特性
这是ML.NET最重要的数据映射特性,用于指定:
列索引(Column Index):[LoadColumn(0)]表示该属性对应数据源的第 0 列(从 0 开始)。
用途:在加载 CSV / 文本数据时,自动将指定列映射到属性。【数据映射】
2、构建数据管道
var mlContext = new MLContext();
var data = mlContext.Data.LoadFromEnumerable(irisDataList); // 加载数据
var pipeline = mlContext.Transforms.Concatenate("Features", "SepalLength", "SepalWidth", "PetalLength", "PetalWidth")
.Append(mlContext.MulticlassClassification.Trainers.StochasticDualCoordinateAscent()); // 选择算法
var model = pipeline.Fit(data); // 训练模型
代码详解:
MLContext
MLContext:ML.NET的核心入口点,类似于 Entity Framework 的DbContext。
提供数据加载、转换、模型训练、评估和预测的 API。
管理随机数生成器和组件生命周期,确保可重现性。
线程安全:建议在应用程序中共享同一个实例。
数据加载-LoadFromEnumerable(irisDataList)
数据来源:从内存中的IEnumerable加载数据(也支持从文件 / 数据库加载)。
数据格式:irisDataList是一个包含IrisData对象的集合,每个对象对应一行数据。
返回类型:IDataView接口,ML.NET内部使用的高效数据抽象(类似 DataTable 但更高效)。
管道构建-特征拼接
mlContext.Transforms.Concatenate("Features", "SepalLength", "SepalWidth", "PetalLength", "PetalWidth")
特征拼接作用:将多个输入列合并为一个名为Features的向量列。
输入列:SepalLength, SepalWidth, PetalLength, PetalWidth(均为float类型)。
输出列:Features(类型为VBuffer,即四维特征向量)。
为什么需要拼接:大多数 ML 算法要求输入是单一特征向量。
管道构建-添加分类算法
.Append(mlContext.MulticlassClassification.Trainers.StochasticDualCoordinateAscent())
任务类型:MulticlassClassification(多分类问题,如鸢尾花有 3 个品种)。
算法选择:StochasticDualCoordinateAscent(随机对偶坐标上升算法)。
适用于线性分类问题,支持多类别分类。
默认会自动将string类型的标签(如 “Iris-setosa”)转换为数值键。
管道结构
数据 → 特征拼接 → 分类算法
3、训练模型
var model = pipeline.Fit(data);
Fit 方法:
遍历IDataView中的数据,执行所有转换步骤(如特征拼接)。
使用训练数据拟合算法参数(如线性分类器的权重)。
返回类型:ITransformer接口,表示训练好的模型。
特征拼接转换器 → 分类模型转换器
4、评估模型
// 评估模型
var predictions = model.Transform(split.TestSet);
var metrics = mlContext.MulticlassClassification.Evaluate(predictions);
Console.WriteLine($"微平均准确率: {metrics.MicroAccuracy:P2}");
5、模型保存与加载
// 保存模型
mlContext.Model.Save(model, data.Schema, "iris-model.zip");
// 加载模型
ITransformer loadedModel = mlContext.Model.Load("iris-model.zip", out var modelSchema);
6、添加数据预处理
var pipeline = mlContext.Transforms.Concatenate("Features", "SepalLength", "SepalWidth", "PetalLength", "PetalWidth")
.Append(mlContext.Transforms.NormalizeMinMax("Features")) // 数据归一化
.Append(mlContext.MulticlassClassification.Trainers.SdcaNonCalibrated());
总结
整体流程
创建上下文(MLContext)
加载数据(IDataView)
构建转换管道(Concatenate + 算法)
训练模型(Fit)
数据管道(Pipeline)
链式结构:通过.Append()方法连接多个转换器(Transformers)和训练器(Trainers)。
惰性执行:定义时不立即执行,调用Fit()时才处理数据。
转换器(Transformers)
实现ITransformer接口,用于数据转换。
常见转换器:
Concatenate:特征拼接
NormalizeMinMax:数据归一化
TextFeaturizer:文本向量化
OneHotEncoding:类别特征编码
训练器(Trainers)
实现IEstimator接口,用于模型训练。
按任务类型分类:
MulticlassClassification:多分类
BinaryClassification:二分类
Regression:回归
Clustering:聚类
Recommendation:推荐
数据视图(IDataView)
内存高效的数据抽象,支持延迟加载和流式处理。
不直接存储数据,而是定义数据的来源和转换逻辑。
1、数据准备【标注数据集】
文本,标签
"这部电影太棒了!",积极
"这服务真差",消极
部分数据可能需要数据清洗:去除噪声(如 HTML 标签、特殊符号)
2、特征工程
将文本转换为数值特征向量,常见方法:
词袋模型(Bag of Words):统计每个词的出现频率。
TF-IDF:评估词在文档中的重要性。
词嵌入(Word Embedding):如 Word2Vec、BERT,捕获语义信息。
3、模型训练
选择分类算法学习文本特征与情感标签的关系:
传统机器学习:逻辑回归、朴素贝叶斯、支持向量机。
深度学习:LSTM、BERT 等预训练模型。
个人总结
判断文本的情感极性(积极或消极)【二分类问题】
上次的文本分析属于二分类问题,映射到本次的学习中:
1、定义数据模型
//训练的数据
public class SentimentData
{
[LoadColumn(0)] public string Text { get; set; }
[LoadColumn(1), ColumnName("Label")] public bool Sentiment { get; set; }
}
//待预测数据
public class SentimentPrediction
{
[ColumnName("PredictedLabel")] public bool Prediction { get; set; }
public float Probability { get; set; }
public float Score { get; set; }
}
2、构建管道与训练模型
var mlContext = new MLContext();
// 加载数据
var data = mlContext.Data.LoadFromTextFile<SentimentData>("sentiment-data.csv", hasHeader: true);
// 构建转换管道
var pipeline = mlContext.Transforms.Text.FeaturizeText(
outputColumnName: "Features",
inputColumnName: nameof(SentimentData.Text))
.Append(mlContext.BinaryClassification.Trainers.LinearSvm());
// 训练模型
var model = pipeline.Fit(data);
FeaturizeText内部实现解析
- 文本预处理
小写化:将所有文本转换为小写,消除大小写差异(如 “Great” 和 “great” 视为相同)。
去除标点符号:移除无情感意义的符号(如 “!”、“?”)。
分词(Tokenization):将文本拆分为单个词元(Tokens)。
"这部电影太棒了!" → ["这部", "电影", "太棒了"]
3、预测文本情感
var predictionEngine = mlContext.Model.CreatePredictionEngine<SentimentData, SentimentPrediction>(model);
// 测试输入
var input = new SentimentData { Text = "这部电影太精彩了!" };
var prediction = predictionEngine.Predict(input);
Console.WriteLine($"文本: {input.Text}");
Console.WriteLine($"情感预测: {(prediction.Prediction ? "积极" : "消极")}");
Console.WriteLine($"置信度: {prediction.Probability:P2}");
按此方法,即可获得一个自己训练的模型。
可以感受到,特征工程在模型训练中,发挥了核心的作用。进阶特征工程设计后续慢慢了解。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)