yolo v4和v5目标检测模型(上)
目标检测作为计算机视觉领域的核心任务之一,旨在从图像或视频中精确定位并识别出特定目标的类别与位置。随着深度学习技术的快速发展,基于卷积神经网络(CNN)的目标检测算法在精度和效率上取得了显著突破。其中,YOLO(You Only Look Once)系列模型因其“单阶段检测”的设计理念和实时性优势,成为工业界与学术界广泛关注的研究热点。自YOLOv1提出以来,该系列算法通过迭代优化网络结构、损失函
文章目录
前言
目标检测作为计算机视觉领域的核心任务之一,旨在从图像或视频中精确定位并识别出特定目标的类别与位置。随着深度学习技术的快速发展,基于卷积神经网络(CNN)的目标检测算法在精度和效率上取得了显著突破。其中,YOLO(You Only Look Once)系列模型因其“单阶段检测”的设计理念和实时性优势,成为工业界与学术界广泛关注的研究热点。
自YOLOv1提出以来,该系列算法通过迭代优化网络结构、损失函数与训练策略,持续平衡检测速度与精度之间的矛盾。2020年发布的YOLOv4在继承YOLO框架高效特性的基础上,引入CSPDarknet53主干网络、Mish激活函数、SPP模块(Spatial Pyramid Pooling)等创新设计,结合马赛克数据增强(Mosaic Augmentation)和自对抗训练(SAT),显著提升了模型对小目标与复杂场景的适应性。与此同时,YOLOv5作为非官方但广泛应用的改进版本,凭借其模块化架构设计、自适应锚框计算和高效的训练-推理流程,进一步降低了模型部署门槛。其采用PyTorch框架实现,支持灵活的参数调整与模型轻量化(如YOLOv5s/m/l/x版本),在保证实时性的前提下优化了检测精度。
YOLOv4与YOLOv5的并行发展体现了目标检测领域的两大技术方向:前者侧重于通过严谨的算法优化与理论验证提升模型性能上限,后者则聚焦于工程实践中的易用性与部署效率。二者的对比研究不仅有助于深入理解单阶段检测器的优化路径,也为实际应用场景(如自动驾驶、工业质检、安防监控等)中的模型选型提供了重要参考。本文将从算法原理、性能指标、应用场景等方面系统分析YOLOv4与YOLOv5的技术特点,探讨其优势与局限性,以期为相关研究与工程实践提供理论依据和技术指导。
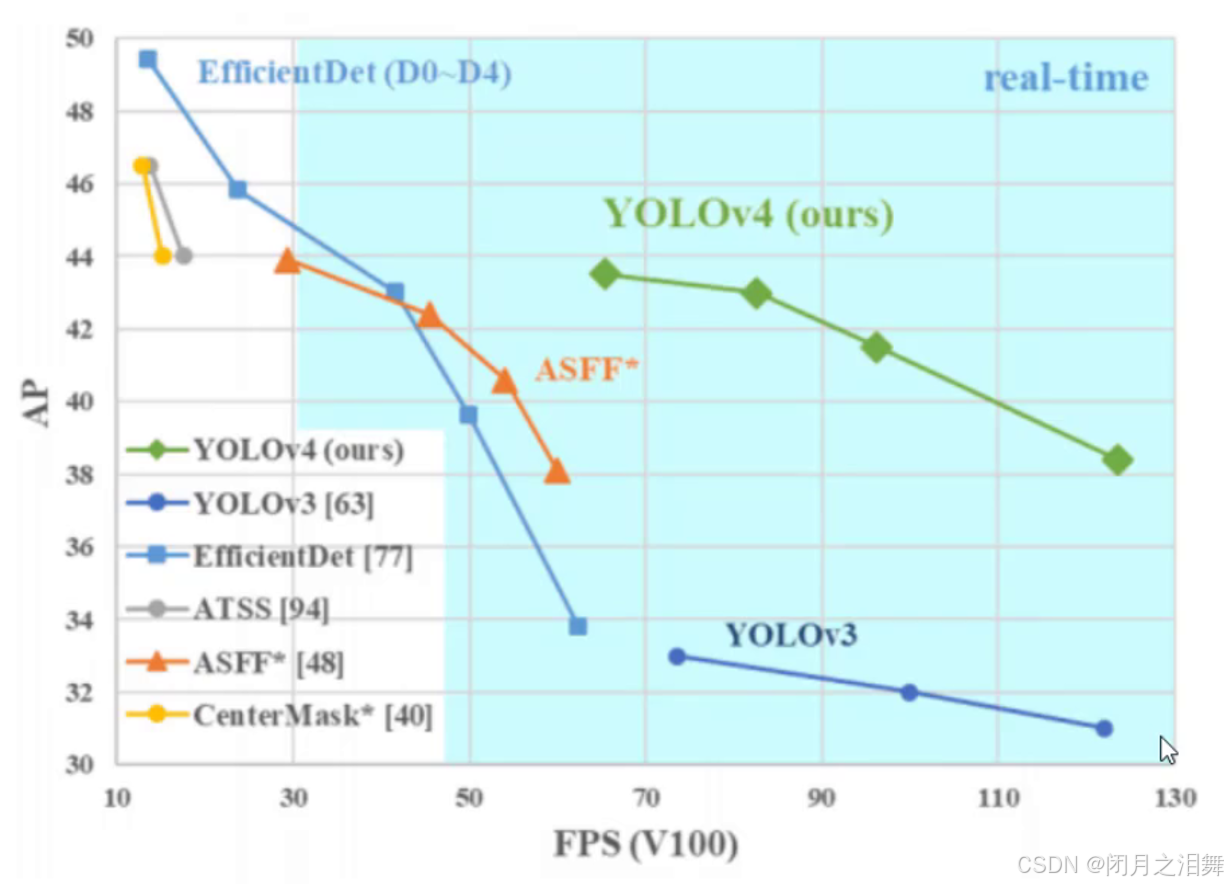
一、yolo-v4的改进之数据增强
1、Bag of freebies(BOF)
Bag of freebies 指的是那些不增加模型复杂度,也不增加推理的计算量,通过改进模型和数据的预处理,来提高模型的准确度。
只增加训练成本,能显著提高精度,并不影响推理速度
数据增强可以调整亮度、对比度、色调、随机缩放、剪切、翻转、旋转
网络正则化的方法有Dropout、Dropblock等,可以通过设计损失函数解决类别不平衡的问题。
2、马赛克数据增强
方法很简单,参考cutmix然后四张图像拼接成一张进行训练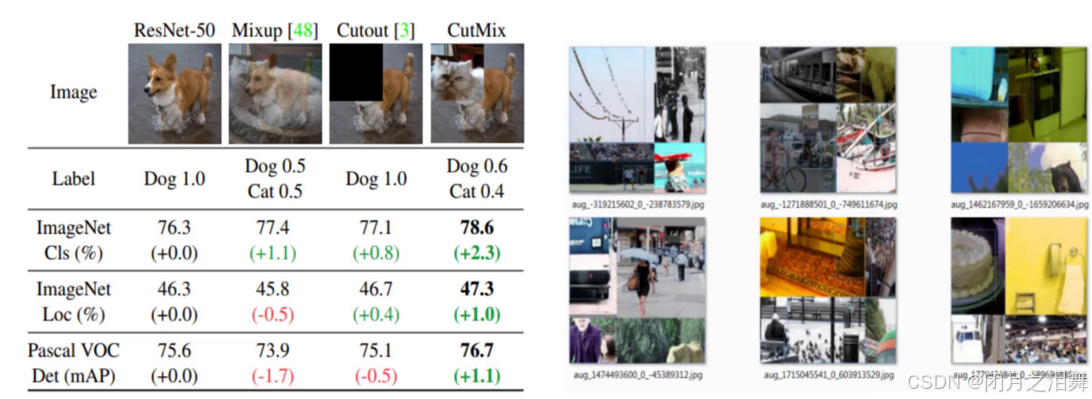
3、Random erase
用随机值或训练集的平均像素替换图像的区域。
4、Hide and Seek
根据概率设置随机隐藏一些补丁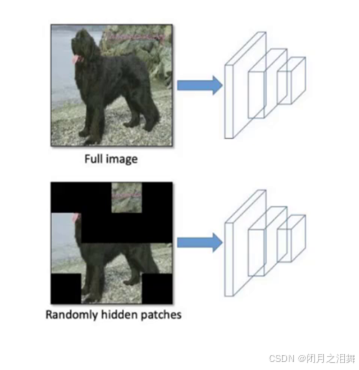
5、Self-adversarial-training(SAT)
通过引入噪声点来增加数据维度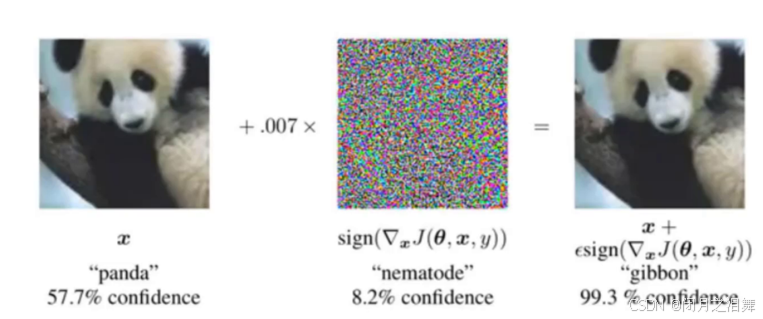
二、yolo-v4中的网络正则化
1、Dropout
2、DropBlock
DropBlock是谷歌在2018年提出的一种用于卷积神经网络(CNN)的正则化方法。这是一种用于解决过拟合问题的技术,在训练神经网络时非常有用。过拟合问题是指在训练集上表现很好,但在测试集上表现不佳的问题。
相比于传统的Dropout技术,DropBlock不是随机屏蔽掉一部分特征(注意是对特征图进行屏蔽),而是随机屏蔽掉多个部分连续的区域。这种方法有助于减少神经网络中的冗余连接,从而提高模型的泛化能力。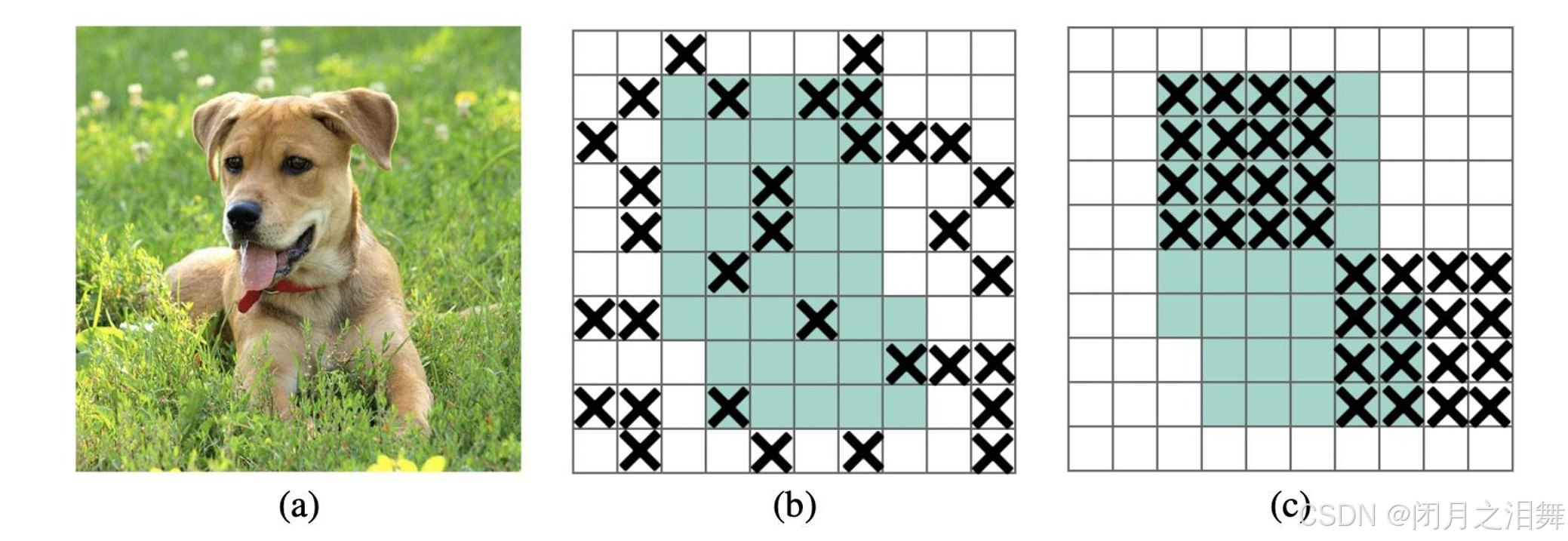
三、标签平滑
神经网络最大的缺点就是容易过拟合,对于神经网络的标签为0和为1但是实际神经网络的预测始终不能达到0和1,所以,此处我们做标签平滑处理。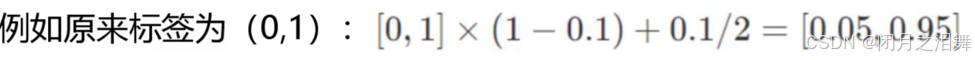
四、yolo-v4损失函数的改进
1、IOU损失函数
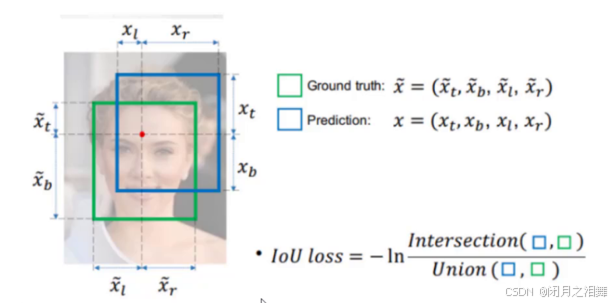
没有相交则IOU=0无法计算梯度,相同的IOU反应不出实际情况。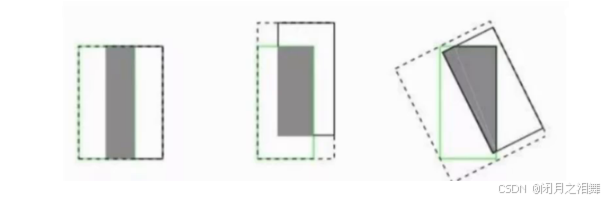
2、GIOU损失
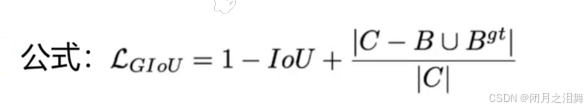
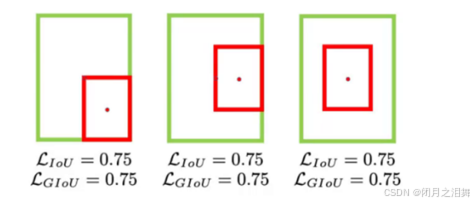
引入了最小封闭形状C(C可以把A,B包含在内),在不重叠的情况下能让预测框尽可能朝着真是框前进
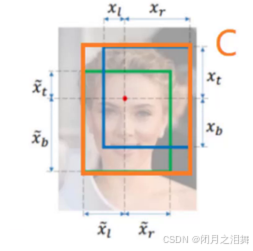
3、DIOU损失
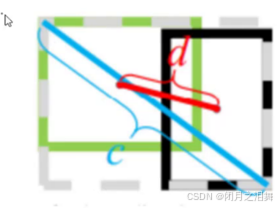
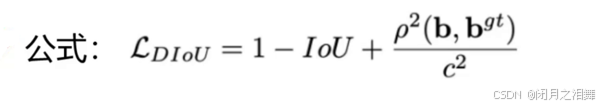
其中分子计算预测框与真实框的中心点欧式距离d,分母是能覆盖预测框与真实框的最小BOX的对角线长度c,此方法直接优化距离,速度更快,并解决GIOU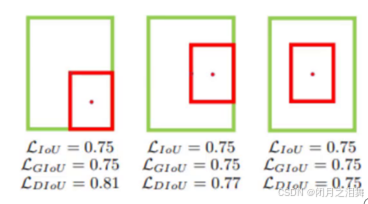
4、CIOU损失
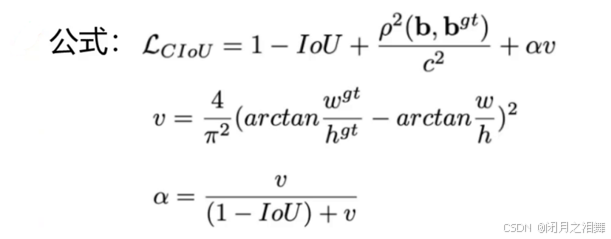
损失函数必须考虑三个几何因素:重叠面积,中心点距离,长宽比,其中a可以当做权重参数。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 25
25 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)