深度学习中的暗流:梯度消失与梯度爆炸的成因、影响及应对策略
在深度学习的训练过程中,梯度消失(Vanishing Gradient)和梯度爆炸(Exploding Gradient)是两个如影随形的 “顽疾”。它们会严重阻碍模型的训练,导致模型无法收敛或性能下降。理解这两个问题的本质、成因及解决方法,是深度学习从业者和研究者必须掌握的重要知识。
在深度学习的训练过程中,梯度消失(Vanishing Gradient)和梯度爆炸(Exploding Gradient)是两个如影随形的 “顽疾”。它们会严重阻碍模型的训练,导致模型无法收敛或性能下降。理解这两个问题的本质、成因及解决方法,是深度学习从业者和研究者必须掌握的重要知识。接下来,我们将深入探讨梯度消失和梯度爆炸现象
一、梯度的重要性
在了解梯度消失和梯度爆炸之前,我们首先要明确梯度在深度学习中的关键作用。梯度是损失函数对模型参数的导数,它指示了参数更新的方向和幅度。在反向传播算法中,模型根据梯度信息来调整参数,以最小化损失函数。可以说,梯度是深度学习模型学习的 “指南针”,合理的梯度能够引导模型朝着最优解的方向前进。
二、梯度消失:难以抵达的 “远方”
现象描述
梯度消失指的是在深度神经网络反向传播过程中,随着网络层数的增加,梯度逐渐变小,趋近于零,导致靠近输入层的参数无法得到有效更新 。在训练过程中,会出现模型的损失值在训练初期下降较快,但随着训练进行,损失值下降变得缓慢甚至停滞,模型的性能也难以提升。
成因分析
- 激活函数的选择:早期神经网络常用的 Sigmoid 和 Tanh 激活函数存在梯度饱和问题。以 Sigmoid 函数
为例,其导数
,函数值在接近 0 或 1 时,导数趋近于 0。在深层网络中,经过多层激活函数后,梯度在反向传播时不断累乘这些趋近于 0 的导数,导致梯度越来越小。
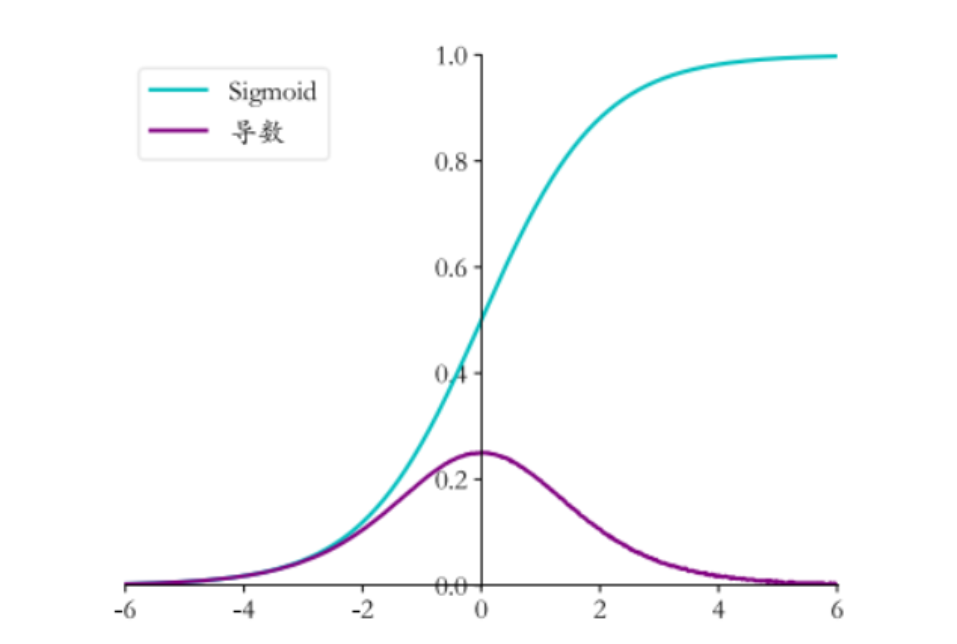
- 链式法则的累乘效应:反向传播基于链式法则计算梯度,对于一个 L 层的神经网络,第 l 层的梯度需要通过后面所有层的梯度和权重进行累乘计算。如果每层的梯度和权重的乘积小于 1,随着层数 L 的增加,累乘结果会指数级减小,使得靠近输入层的梯度趋近于 0。
影响
梯度消失使得靠近输入层的参数几乎无法更新,模型无法学习到输入数据的底层特征。这会导致模型的训练效率低下,训练时间大幅增加,最终模型的性能也会受到严重影响,无法达到预期的准确率或预测效果。
三、梯度爆炸:失去控制的 “狂飙”
现象描述
与梯度消失相反,梯度爆炸是指在反向传播过程中,梯度变得越来越大,呈现指数级增长 。在训练过程中,会观察到模型的损失值突然急剧增大,参数出现大幅波动,甚至模型的训练过程崩溃,无法继续进行。
成因分析
- 权重初始化不当:如果模型的权重初始化值过大,在反向传播过程中,梯度与权重相乘后会变得更大,随着层数的增加,这种放大效应不断累积,最终导致梯度爆炸。
- 网络结构问题:某些复杂的网络结构,如循环神经网络(RNN)在处理长序列时,如果没有合适的机制来控制梯度,也容易出现梯度爆炸。因为 RNN 在每个时间步的梯度都需要反向传播并累加到之前的梯度上,长序列会加剧梯度的累积效应。
- 链式法则的累乘效应:和梯度消失类似,链式法则在反向传播中的累乘计算,如果每层的梯度和权重的乘积大于 1,随着层数增加,累乘结果会指数级增大,引发梯度爆炸。
影响
梯度爆炸会使模型的参数更新幅度过大,导致参数值超出合理范围,甚至出现 “NaN”(非数)的情况,使得模型无法正常训练。即使模型没有崩溃,过大的梯度更新也会使模型在训练过程中偏离最优解,难以收敛到良好的性能。
四、应对策略
激活函数的改进
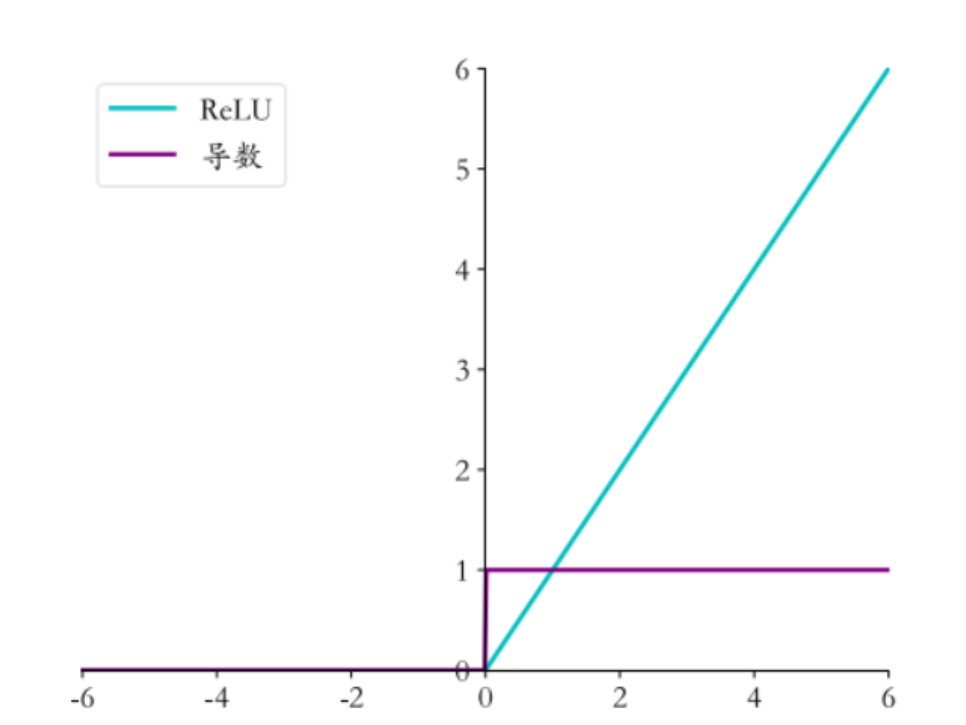
- ReLU 系列函数:ReLU(Rectified Linear Unit)函数
在
时,导数恒为 1,避免了梯度饱和问题,有效缓解了梯度消失。其变种如 Leaky ReLU、PReLU 等,进一步改进了 ReLU 在
时的表现,在实践中也取得了良好的效果。
- Swish 函数:Swish 函数
结合了 Sigmoid 函数的平滑性和 ReLU 函数的非饱和性,在一些任务中也展现出了优秀的性能,有助于改善梯度问题。
梯度裁剪(Gradient Clipping)
梯度裁剪是一种直接限制梯度大小的方法。在反向传播计算出梯度后,检查梯度的范数(如 L2 范数),如果超过某个预设的阈值,则将梯度按比例缩放,使其范数等于阈值。这种方法可以有效防止梯度爆炸,同时不会影响模型的正常学习。
正则化技术
- L1 和 L2 正则化:通过在损失函数中添加正则化项,对模型的参数进行约束,防止参数过大,从而减少梯度爆炸的风险。L2 正则化(权重衰减)在损失函数中添加
项,L1 正则化添加
项,其中
是模型参数,
是正则化强度。
- Dropout:在训练过程中,以一定概率随机将神经元的输出设置为 0,这相当于每次训练使用不同的子网络,减少了神经元之间的复杂依赖关系,有助于缓解梯度消失和梯度爆炸问题,同时还能起到防止过拟合的作用。
优化网络结构
- ResNet 残差网络:引入残差连接(Skip Connection),使得网络可以学习输入与输出之间的残差,而不是直接学习复杂的映射关系。残差连接为梯度提供了直接传播的路径,避免了梯度在深层网络中的衰减,有效缓解了梯度消失问题,使得训练更深层的网络成为可能。
- LSTM 和 GRU:在处理序列数据的 RNN 中,长短期记忆网络(LSTM)和门控循环单元(GRU)通过门控机制,能够更好地控制信息的流动和梯度的传播,解决了传统 RNN 中的梯度消失和梯度爆炸问题,在自然语言处理和时间序列分析等领域得到广泛应用。
五、总结
梯度消失和梯度爆炸是深度学习训练过程中面临的重要挑战,它们的出现会严重影响模型的训练和性能。通过深入理解其成因,我们可以采取针对性的策略,如选择合适的激活函数、优化权重初始化、应用梯度裁剪和正则化技术以及改进网络结构等,来有效应对这些问题。随着深度学习技术的不断发展,未来还会有更多创新的方法出现,帮助我们更好地驯服这两股 “暗流”,推动深度学习模型向更深、更强的方向发展。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐

 13
13 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)