【Numpy篇】数据乾坤:用Numpy三十六计玩转科学计算江湖
本文系统解析Python核心库Numpy的高维数据操控之道,直击传统列表在存储与计算中的性能瓶颈。通过掌握ndarray的多维结构(shape/ndim/dtype)、矩阵生成术(zeros/arange/随机矩阵)和向量化运算(广播机制/矩阵乘法),开发者可轻松实现千倍性能飞跃。内容涵盖数据创建、类型转换、统计函数、排序去重等实战技巧,特别针对图像处理、机器学习场景,揭秘
目录
引言
📘 NumPy:数据科学的核动力引擎,让你的Python飞起来!
你是否正在经历这些崩溃瞬间?💥
- 用Python列表处理10万条数据,程序卡成PPT?
- 想操作Excel表格或3D图像,却发现列表连存储都无能为力?
- 写个矩阵乘法要套三层循环,代码堪比意大利面条?
是时候解锁Python的隐藏战力——NumPy了!
🔥 NumPy三大神技,专治各种不服:
1️⃣ 高维数据收纳术
一维如琴弦([1,2,3]),二维似棋盘,三维赛魔方,N维时空任你驰骋!
2️⃣ C语言级速度暴走
向量化运算+并行加速,比纯Python快1000倍!10万数据?瞬间完成!⚡
3️⃣ 内存空间魔术师
连续内存+统一类型,内存占用直降50%,百万数据轻装上阵!📊 列表 vs Numpy 数组:一目了然的对比
特性 Python 列表 Numpy 数组 (ndarray) 数据类型 可混存(如同时存数字、字符串) 必须统一(如全是整数或全是小数) 维度支持 仅一维(嵌套列表模拟多维,效率极低) 支持 1~N 维,原生多维结构 内存占用 高(每个元素需额外存储类型信息) 低(连续存储,仅存数据值) 数值计算 需循环遍历,速度慢 支持向量化操作,一行代码算整个数组
一、NumPy简介
什么是NumPy:Python科学计算的基础库,提供高性能多维数组对象
- 主要优势:
- 比Python列表更快的运算速度(底层C实现)
- 丰富的数学函数库
- 方便的数组操作(广播机制)
- 应用场景:
- 机器学习(TensorFlow/PyTorch基础)
- 数据分析(Pandas底层依赖)
- 图像处理(像素矩阵操作)
传统Python列表计算 vs NumPy数组计算对比
import numpy as np
import time
# Python列表
py_list = list(range(1000000))
start = time.time() # 开始时间
py_list = [x*2 for x in py_list]
print("Python列表耗时:", time.time()-start) # 结束时间 - 开始时间
# NumPy数组
np_array = np.arange(1000000)
start = time.time()
np_array *= 2
print("NumPy数组耗时:", time.time()-start)
二、Numpy 属性
NumPy的数组类被称作ndarray,通常被称作数组。
ndarray对象属性有:
- ndarray.ndim
- ndarray.shape
- ndarray.size
- ndarray.dtype
- ndarray.itemsize
| 属性 | 技术定义 | 生活类比 | 典型用法 |
|---|---|---|---|
shape |
各维度长度元组 | 数据的 “长宽高” | 调整数组形状:arr.reshape(2,3) |
ndim |
维度数量(轴数) | 数据的 “空间维度” | 判断数据形态:图像(2D)/ 视频(3D) |
dtype |
元素数据类型 | 数据的 “语言种类” | 控制内存:用float32替代float64节省空间 |
itemsize |
单个元素字节大小 | 数据的 “个体体重” | 计算总内存:arr.itemsize * arr.size |
size |
元素总数 | 数据的 “家庭人口” | 批量操作循环边界:for i in range(arr.size) |
1. 对象方法获取属性(推荐)
# 1. 构建1个3行5列的 ndarray对象(n维数字), 即: 3行5列.
arr = np.arange(15).reshape((3, 5)) # arange(15)类似于Python的range(15), 然后把0~15(包左不包右)的数据放到 3个 长度维5的一维数组中.
print(f'ndarray对象: {arr}') # ndarray对象.
print(f'数组的形状(维度): {arr.shape}') # (3, 5), 简单理解为: 3行5列
print(f'数组的轴: {arr.ndim}') # 2, 几维数组, 维度(轴)就是几.
print(f'数组的长度: {arr.size}') # 15, 即所有元素的个数.
print(f'数组的每个元素的类型: {arr.dtype}') # int64
print(f'数组的每个元素的大小(字节数): {arr.itemsize}') # 8
print(f'数组的类型: {type(arr)}') # <class 'numpy.ndarray'>

2. 函数方法获取属性
# 扩展: 上述的 shape, ndim, size等属性, 可以改写成: np.属性名(对象对)的形式.
print(f'数组的形状(维度): {np.shape(arr)}') # (3, 5), 简单理解为: 3行5列
print(f'数组的轴: {np.ndim(arr)}') # 2, 几维数组, 维度(轴)就是几.
print(f'数组的长度: {np.size(arr)}') # 15, 即所有元素的个数.
# print(f'数组的每个元素的类型: {np.dtype(arr)}') # 报错, 无该函数
# print(f'数组的每个元素的大小(字节数): {np.itemsize(arr)}') # 报错, 无该函数
# print(f'数组的类型: {np.type(arr)}') # 报错, 无该函数
三、ndarray 创建
ndarray介绍
-
NumPy数组是一个多维的数组对象(矩阵),称为ndarray(N-Dimensional Array)
-
具有矢量算术运算能力和复杂的广播能力,并具有执行速度快和节省空间的特点
-
注意:ndarray的下标从0开始,且数组里的所有元素必须是相同类型。
1. 基础转换
# int数组
arr1 = np.array([1, 2, 3, 4, 5])
print(f'数组对象: {arr1}')
print(f'数组类型: {type(arr1)}')
print(f'数组元素类型: {arr1.dtype}')
2. 快速初始化
函数zeros创建一个全是0的数组,函数ones创建一个全1的数组,函数empty创建一个内容随机并且依赖于内存状态的数组。默认创建的数组类型(dtype)都是float64
| 函数 | 适用场景 | 核心参数 | 内存特性 | 示例 |
|---|---|---|---|---|
zers |
全零矩阵(如掩码、初始化) | shape=(行,列), dtype |
分配内存并填充 0 | mask = np.zeros((1024,1024), dtype=np.uint8) |
ones |
全一矩阵(如权重初始化) | 同上 | 同上 | weights = np.ones((3,4), dtype=np.float32) |
empty |
快速创建未初始化数组 | 仅需shape |
不初始化内存(速度最快) | temp = np.empty((2,2))(需手动赋值!) |
 代码演示
代码演示
(1)zeros()
# zeros() 创建全是0的数组, 即: ndarray对象
arr3 = np.zeros((2, 3)) # 2行3列, 即: 二维数组, 有2个一维数组, 每个一维数组的元素个数为: 3
print(f'数组对象: {arr3}') # [[0. 0. 0.] [0. 0. 0.]]
print(f'数组类型: {type(arr3)}') # <class 'numpy.ndarray'>
print(f'数组元素类型: {arr3.dtype}') # float64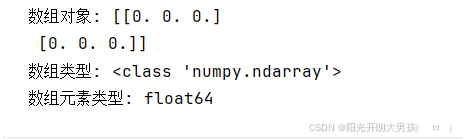
(2)ones()
# ones() 创建全是1的数组, 即: ndarray对象
# arr4 = np.ones((2, 3)) # 2行3列, 即: 二维数组, 有2个一维数组, 每个一维数组的元素个数为: 3
arr4 = np.ones((2, 3, 4)) # 三维数组, 2个二维数组, 每个2位数组有3个一维数组, 每个一维数组有4个元素
print(f'数组对象: {arr4}') # [[1. 1. 1.] [1. 1. 1.]]
print(f'数组类型: {type(arr4)}') # <class 'numpy.ndarray'>
print(f'数组元素类型: {arr4.dtype}') # float64
(3)empty()
# empty() 创建内容随机, 且依赖内存状态的随机值, 即: ndarray对象
arr5 = np.empty((2, 3)) # 2行3列, 即: 二维数组, 有2个一维数组, 每个一维数组的元素个数为: 3
print(f'数组对象: {arr5}') # [[1. 1. 1.] [1. 1. 1.]]
print(f'数组类型: {type(arr5)}') # <class 'numpy.ndarray'>
print(f'数组元素类型: {arr5.dtype}') # float64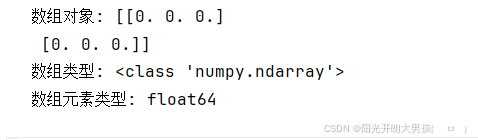
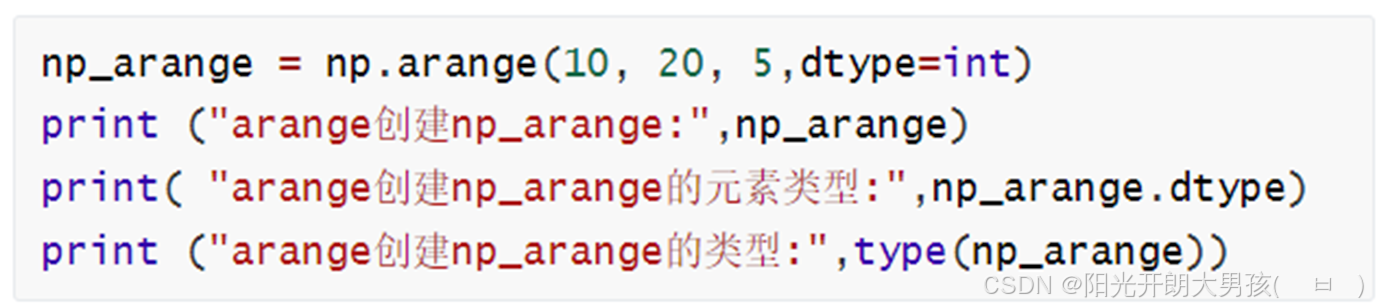
3. arange()函数创建
arange() 类似 python 的 range() ,创建一个一维 ndarray 数组。
 代码演示
代码演示
# arange(起始值, 结束值, 步长, 类型), 它类似于Python中的 range()
arr6 = np.arange(1, 5, 2, dtype=np.float32) # 生成 1 ~ 5之间, 步长为2的数据, 包左不包右. 类型: int32, int64, float32, float64
print(f'数组对象: {arr6}') #
print(f'数组类型: {type(arr6)}') # <class 'numpy.ndarray'>
print(f'数组元素类型: {arr6.dtype}') # float64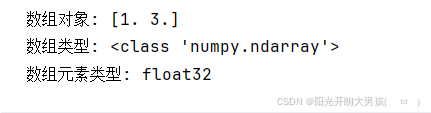
这里博主用的pycharm环境,pycharm 与 jupyter notebook 格式可能有点不同,如下:
4. matrix() 函数创建
matrix 是 ndarray 的子类,只能生成 2 维的矩阵

代码演示
# matrix()属于ndarry的子集, 生成 二维数组的.
# arr7 = np.mat('1 2; 3 4') # 生成 二维数组
# arr7 = np.mat('1,2;3,4') # 生成 二维数组
# arr7 = np.mat([[1, 2, 3], [4, 5, 6]]) # 生成 二维数组
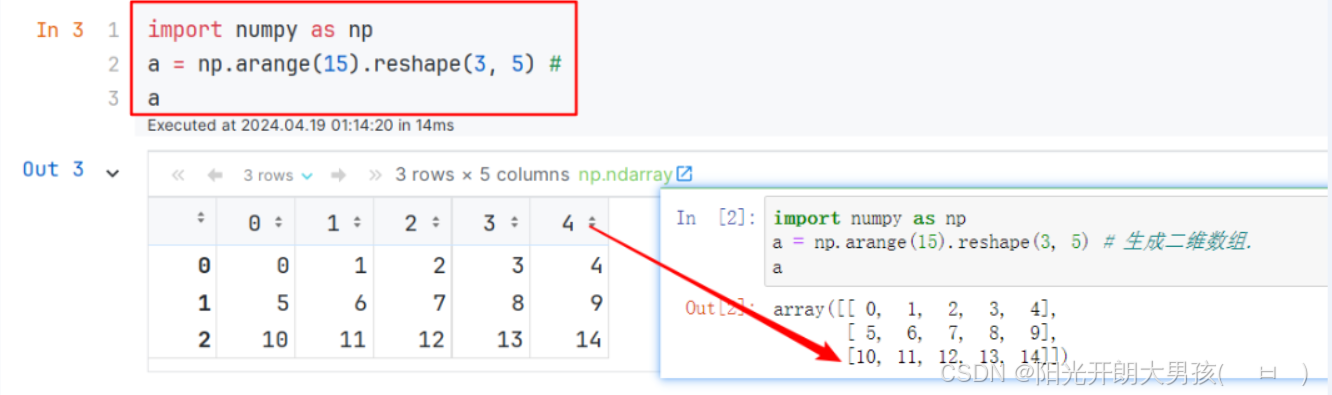
arr7 = np.matrix([[1, 2, 3], [4, 5, 6]]) # 生成 二维数组 你写 mat() 和 matrix()效果是一致的
print(f'数组对象: {arr7}') # [[1 2] [3 4]]
print(f'数组类型: {type(arr7)}') # <class 'numpy.matrix'>, 即: matrix是ndarray的子类.
print(f'数组元素类型: {arr7.dtype}') # float64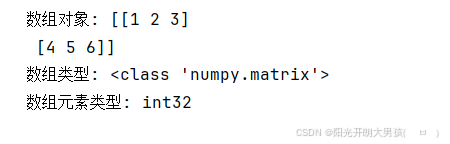
5. 创建随机数矩阵
(1)rand()
# rand(), 生成0.0 ~ 1.0之间的 随机数组. 包左不包右.
arr8 = np.random.rand(2, 3) # 2行3列
print(f'数组对象: {arr8}') # [[1 2] [3 4]]
print(f'数组类型: {type(arr8)}') # <class 'numpy.ndarray'>
print(f'数组元素类型: {arr8.dtype}') # float64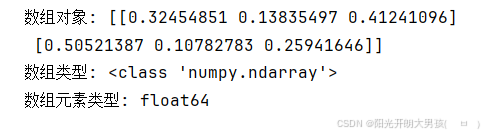
(2)randint()
# randint(), 生成指定范围之间的 随机数组. 包左不包右.
arr9 = np.random.randint(-1, 5, size=(2, 3)) # 2行3列, -1 ~ 5之间, 随机整数
print(f'数组对象: {arr9}') # [[1 2] [3 4]]
print(f'数组类型: {type(arr9)}') # <class 'numpy.ndarray'>
print(f'数组元素类型: {arr9.dtype}') # int64
(3)uniform()
# uniform(), 生成指定范围之间的 随机数组. 包左不包右.
arr10 = np.random.uniform(-1, 5, size=(2, 3)) # 2行3列, -1 ~ 5之间, 随机小数(浮点数)
print(f'数组对象: {arr10}') # [[1 2] [3 4]]
print(f'数组类型: {type(arr10)}') # <class 'numpy.ndarray'>
print(f'数组元素类型: {arr10.dtype}') # float64
总结
 6. astype() 函数转换
6. astype() 函数转换
1. dtype参数,指定数组的数据类型,类型名+位数,如float64, int32
2. astype方法,转换数组的数据类型

代码演示
# 1. 创建1个 float类型的 数组.
arr11 = np.ones((2, 3), dtype=np.float32) # 2行3列
print(f'数组对象: {arr11}') # [[1. 1. 1.] [1. 1. 1.]]
print(f'数组类型: {type(arr11)}') # <class 'numpy.ndarray'>
print(f'数组元素类型: {arr11.dtype}') # float32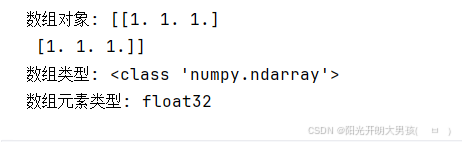
# 2. 把 arr11的元素类型, 从 float32 => int64
arr12 = arr11.astype(np.int64)
print(f'数组对象: {arr12}') # [[1 1 1] [1 1 1]]
print(f'数组类型: {type(arr12)}') # <class 'numpy.ndarray'>
print(f'数组元素类型: {arr12.dtype}') # int64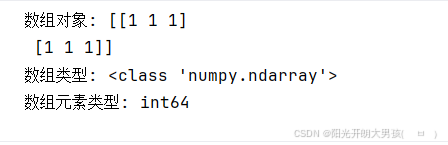
7. 等差和等比形式创建
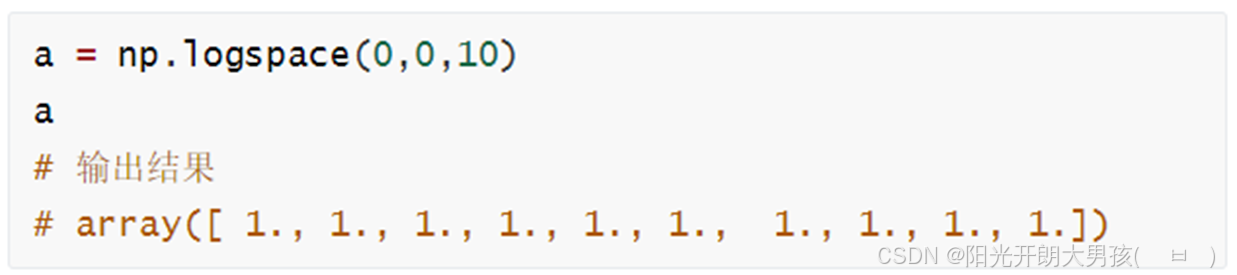
(1)logspace()等比数列
np.logspace等比数列
logspace中,开始点和结束点是10的幂

 代码演示
代码演示
# logspace(起始幂值, 结束幂值, 元素个数, base=底数) 生成10^起始幂值 ~ 10^结束幂值范围内的, 指定个数的数据, 底数默认是10, 可以自定义
# arr13 = np.logspace(0, 5, 10) # 10^0 ~ 10^5之间, 10个元素, 等比数列
arr13 = np.logspace(0, 5, 10, base=2) # 2^0 ~ 2^5之间, 10个元素, 等比数列
print(f'数组对象: {arr13}') # [[1 1 1] [1 1 1]]
print(f'数组类型: {type(arr13)}') # <class 'numpy.ndarray'>
print(f'数组元素类型: {arr13.dtype}') # int64
(2)linspace()等差数列
np.linspace等差数列
np.linspace是用于创建一个一维数组,并且是等差数列构成的一维数组,它最常用的有三个参数。
第一个参数表示起始点,第二个参数表示终止点,第三个参数表示数列的个数。
 linspace创建的数组元素是浮点型。
linspace创建的数组元素是浮点型。
 可以使用参数endpoint来决定是否包含终止值,默认值为True。
可以使用参数endpoint来决定是否包含终止值,默认值为True。

# linspace(起始值, 结束值, 元素个数, endpoint=True|False) 生成起始值 ~ 结束值之间的, 指定元素个数的值, 等差数列, endpoint=True(默认), 包含结束值. False:不包含
arr14 = np.linspace(0, 5, 5) # 0 ~ 5之间, 5个数, 等差数列, endpoint=True(默认值)
arr14 = np.linspace(0, 5, 5, endpoint=False) # 0 ~ 5之间, 5个数, 等差数列, 包左不包右
print(f'数组对象: {arr14}') # [[1 1 1] [1 1 1]]
print(f'数组类型: {type(arr14)}') # <class 'numpy.ndarray'>
print(f'数组元素类型: {arr14.dtype}') # int64
四、Numpy的内置函数
1. 基本函数
np.ceil(): 向上最接近的整数,参数是 number 或 array
np.floor(): 向下最接近的整数,参数是 number 或 array
np.rint(): 四舍五入,参数是 number 或 array
np.isnan(): 判断元素是否为 NaN(Not a Number),参数是 number 或 array
np.multiply(): 元素相乘,参数是 number 或 array
np.divide(): 元素相除,参数是 number 或 array
np.abs():元素的绝对值,参数是 number 或 array
np.where(condition, x, y): 三元运算符,x if condition else y
代码演示:
# 1. 生成ndarray对象.
arr = np.random.randn(2, 3) # 获取1个标准的正态分布的 2行3列的数据.
print(f'arr的值为: {arr}') # [[-2.9442457 0.98108089 -0.10675188] [ 0.99740282 0.89240409 1.36733958]]
# 2. 演示函数.
print(np.ceil(arr)) # [[-2 1 0] [ 1 1 2]]
print(np.floor(arr)) # [[-3 0 -1] [ 0 0 1]]
print(np.rint(arr)) # [[-3 1 -0] [ 1 1 1]]
print(np.isnan(arr)) # [[False False False] [ False False False]]
print(np.abs(arr)) # [[2.9442457 0.98108089 0.10675188] [ 0.99740282 0.89240409 1.36733958]]
print(np.multiply(arr, arr)) # [[...] [... ]]
print(np.divide(arr, arr)) # [[1 1 1] [1 1 1 ]]
print(np.where(arr > 0, 1, -1)) # [[-1 1 -1] [ 1 1 1]]2. 统计函数
np.mean(), np.sum():所有元素的平均值,所有元素的和,参数是 number 或 array
np.max(), np.min():所有元素的最大值,所有元素的最小值,参数是 number 或 array
np.std(), np.var():所有元素的标准差,所有元素的方差,参数是 number 或 array
np.argmax(), np.argmin():最大值的下标索引值,最小值的下标索引值,参数是 number 或 array
np.cumsum(), np.cumprod():返回一个一维数组,每个元素都是之前所有元素的 累加和 和 累乘积,参数是 number 或 array
注意:多维数组默认统计全部维度,axis参数可以按指定轴心统计:
- 值为0则按列统计
- 值为1则按行统计
代码演示:
# 1. 生成1个ndarray对象
arr = np.arange(12).reshape((3, 4)) # 3行4列
print(f'元素内容: {arr}')
# 2. 演示 cumsum(), 累加和.
print(np.cumsum(arr)) # [ 0 1 3 6 10 15 21 28 36 45 55 66]
# 3. 演示 sum()求和.
print(np.sum(arr)) # 66
print(np.sum(arr, axis=0)) # [12, 15, 18, 21], 0是列.
print(np.sum(arr, axis=1)) # [6, 22, 38], 1是行.
3. 比较函数
假如我们想要知道矩阵a和矩阵b中所有对应元素是否相等,我们需要使用all方法,假如我们想要知道矩阵a和矩阵b中对应元素是否有一个相等,我们需要使用any方法。
- np.any(): 至少有一个元素满足指定条件,返回True
- np.all(): 所有的元素满足指定条件,返回True

代码演示:
# 1. 生成1个数列.
arr = np.random.randn(2, 3) # 2行3列的 正态分布的数据.
print(arr) # [[-0.29235619 -1.00893783 -1.19750865] [ 0.10427346 1.45389378 0.26985633]]
print(np.any(arr > 0)) # 只要arr的任意1个元素大于0即可. True
print(np.all(arr > 0)) # arr的所有元素都要大于0即可. False
4. 排序函数
对数组元素进行排序
# 方式1: np.sort(arr) 排序, 并返回新的副本.
# 方式2: arr.sort() 对原数组排序. 代码演示:
代码演示:
# 1. 获取ndarray对象
arr = np.array([1, 5, 3, 2, 6])
print(f'排序前: {arr}')
# 2. 排序
# arr_copy = np.sort(arr)
# print(f'np.sort()方式: {arr_copy}')
arr.sort() # 直接对 原数组排序
# 3. 排序后
print(f'排序后: {arr}')
5. 去重函数
np.unique():找到唯一值并返回排序结果,类似于Python的set集合

代码演示:
# 1. 创建ndarray对象
arr = np.array([[1, 2, 1, 6], [1, 3, 2, 5]]) # 细节: 列数要一致.
print(f'去重前: {arr}')
# 2. 去重.
new_arr = np.unique(arr)
# 3. 打印结果.
print(f'去重后: {new_arr}')
五、Numpy的形状
Numpy 提供了多种数组形状操作,用于查看、修改数组的形状(即数组的维度)。这些操作包括查看数组的形状、改变形状、展平数组、增加或减少数组的维度等。 如下:
- 查看形状:
shape - 改变形状:
reshape() - 展平数组:
ravel()和flatten() - 转置数组:
transpose()和.T - 增加维度:
expand_dims() - 减少维度:
squeeze() - 交换轴:
swapaxes() - 调整数组维度:
resize()
1. 查看数组形状:shape 属性
Numpy 数组的 shape 属性返回数组的形状,显示每一维的大小。
import numpy as np
# 创建一个二维数组
arr = np.array([[1, 2, 3], [4, 5, 6]])
# 查看数组的形状
print(arr.shape) #(2,3)
# 数组 arr 的形状是 (2, 3),表示它有 2 行和 3 列。 2. 改变数组形状:reshape()
reshape() 函数用于改变数组的形状,但不改变其数据。数组的总元素个数必须保持一致。
# 创建一个一维数组
arr = np.array([1, 2, 3, 4, 5, 6])
# 将一维数组转换为二维数组,形状为 (2, 3)
reshaped_arr = arr.reshape((2, 3))
print(reshaped_arr)
# [[1 2 3]
[4 5 6]]
# reshape() 将一维数组 arr 转换成了二维数组,形状为 (2, 3)。注意:如果你试图将数组形状改成一个与元素数量不匹配的形状,Numpy 会抛出错误。
# 错误示例:元素个数不匹配
# arr.reshape((3, 3)) # 会引发错误,因为数组的元素总数为 6,无法重塑为 (3, 3)
3. 展平数组:ravel() 和 flatten()
这两个函数都可以将多维数组展平成一维数组,但它们之间有细微差异:
- ravel():返回的是原数组的视图(view),如果对展平后的数组进行修改,原数组也会随之改变(除非数组存储不连续)。
- flatten():返回的是原数组的副本,修改展平后的数组不会影响原数组。
# 创建一个二维数组
arr = np.array([[1, 2, 3], [4, 5, 6]])
# 使用 ravel 展平
ravel_arr = arr.ravel()
print("Ravel:", ravel_arr)
# 使用 flatten 展平
flatten_arr = arr.flatten()
print("Flatten:", flatten_arr)
#Ravel: [1 2 3 4 5 6]
#Flatten: [1 2 3 4 5 6]
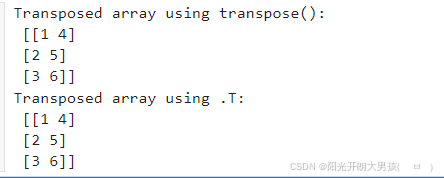
4. 转置数组:transpose() 和 .T
transpose() 和 .T 属性用于交换数组的轴,即转置数组。对于二维数组,转置是行列互换。
# 创建一个二维数组
arr = np.array([[1, 2, 3], [4, 5, 6]])
# 使用 transpose() 进行转置
transposed_arr = arr.transpose()
print("Transposed array using transpose():\n", transposed_arr)
# 使用 .T 进行转置
transposed_arr_T = arr.T
print("Transposed array using .T:\n", transposed_arr_T)
5. 增加或减少维度:expand_dims() 和 squeeze()
expand_dims():用于在指定位置插入一个新的维度。squeeze():用于移除数组中的单维(即大小为 1 的维度)。
增加维度
# 创建一个一维数组
arr = np.array([1, 2, 3])
# 在第 0 轴增加一个维度
expanded_arr = np.expand_dims(arr, axis=0)
print("Expanded array:\n", expanded_arr)
print("Shape after expanding:", expanded_arr.shape)

减少维度
# 创建一个形状为 (1, 3, 1) 的三维数组
arr = np.array([[[1], [2], [3]]])
# 使用 squeeze() 移除所有大小为 1 的维度
squeezed_arr = np.squeeze(arr)
print("Squeezed array:", squeezed_arr)
print("Shape after squeezing:", squeezed_arr.shape)

6. 数组的形状重排:swapaxes()
swapaxes() 用于交换数组的两个指定轴。
# 创建一个三维数组
arr = np.array([[[1, 2, 3], [4, 5, 6]]])
# 交换第 0 轴和第 1 轴
swapped_arr = np.swapaxes(arr, 0, 1)
print("Swapped array:\n", swapped_arr)

7. 调整数组的维度:resize()
与 reshape() 类似,但 resize() 会直接修改数组自身,并且允许更改后的形状与原始数组的元素个数不匹配(会重复使用原数组的元素或截断多余的元素)。
# 创建一个一维数组
arr = np.array([1, 2, 3, 4])
# 使用 resize() 修改数组形状
arr.resize((2, 3))
print("Resized array:\n", arr)
#由于新的形状是 (2, 3),而原始数组只有 4 个元素,
#所以 resize() 会循环使用原数组的元素来填充新的形状。
六、Numpy数组的索引与切片
ndarray对象的内容可以通过索引或切片来访问和修改,与 Python 中 list 的切片操作一样。
索引:通过索引访问单个元素。
切片:通过切片访问多个连续的元素。
- 一维数组的切片: [ 起始位 : 末尾位 : 步长 ],起始位默认0,末尾位默认最后,步长默认1
- 二维以上数组:基本是就是 [ 行的切片 , 列的切片 ]
【行】如果不是切片形式就代表固定是【某一行取序列】
【列】如果没有切片形式就代表固定某一行或所有行都只取【这一列这个数】
代码演示
索引技巧
arr = np.array([10, 20, 30, 40, 50])
# 正索引
print(arr[0]) # 10 (第一个元素)
print(arr[2]) # 30
# 负索引
print(arr[-1]) # 50 (最后一个)
print(arr[-3]) # 30切片技巧
# 基本切片
print(arr[1:4]) # [20 30 40] (索引1到3)
print(arr[:3]) # [10 20 30] (前三个)
print(arr[2:]) # [30 40 50] (索引2到最后)
# 带步长的切片
print(arr[::2]) # [10 30 50] (每隔一个元素)七、Numpy运算
1. 数学运算
数组的算数运算是按照元素的。新的数组被创建并且被结果填充。
a = np.array([1,2,3])
b = np.array([4,5,6])
print(a + b) # [5 7 9] 逐元素相加
print(a * 2) # [2 4 6] 标量乘法
print(np.dot(a, b)) # 32 点积运算
print(a @ b) # 32 矩阵乘法(一维时为点积)
2. 广播机制
广播机制是NumPy最强大的特性之一,允许不同形状数组进行数学运算:
NumPy自动将标量"广播"到数组每个元素执行运算 类似线性代数向量和标量相乘,运算时,标量会运用在数组的每一个数字上,如下图:
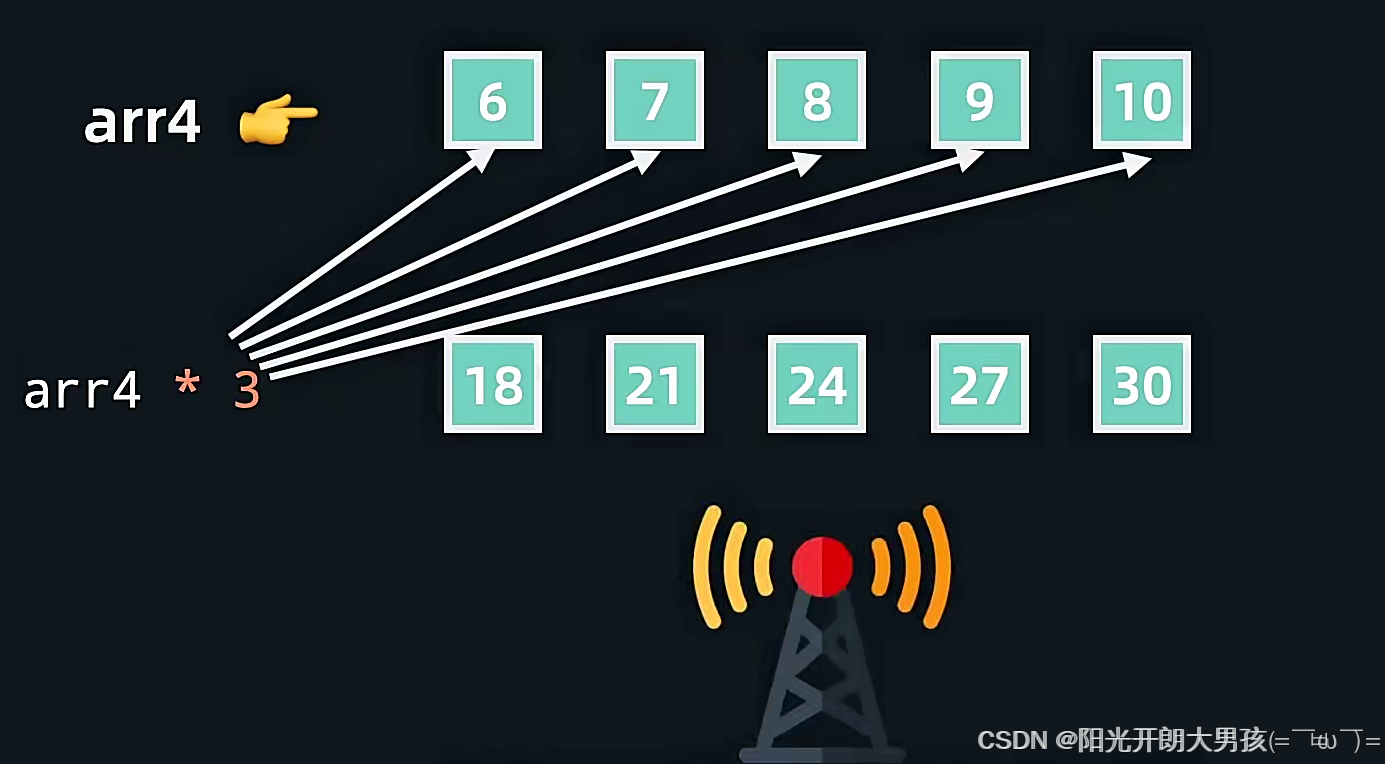
代码演示
A = np.array([[1,2], [3,4]])
B = np.array([10, 20])
print(A + B) # [[11 22], [13 24]] 广播加法
print(A * B) # [[10 40], [30 80]]3. 统计计算
调用统计函数进行运算
代码演示:
arr = np.random.randint(0,100, size=(5,5))
print("平均值:", arr.mean())
print("列平均:", arr.mean(axis=0))
print("行求和:", arr.sum(axis=1))
print("最大值位置:", arr.argmax())4. 矩阵相乘运算
矩阵对应元素的乘法
arr_a.dot(arr_b) 前提arr_a 列数 = arr_b行数
(1)情况1: 行列数一致
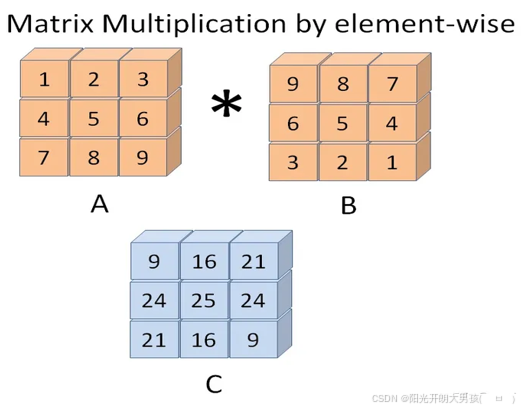
import numpy as np
a = np.array([[1, 2, 3], [4, 5, 6]])
b = np.array([[1, 2, 3], [4, 5, 6]])
print(a * b)
print(np.multiply(a, b))
(2)情况2: 行列数相反
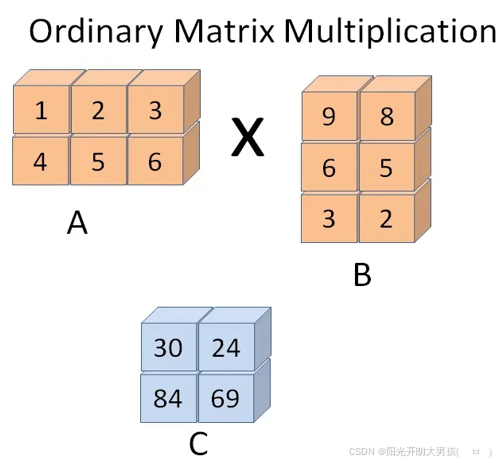
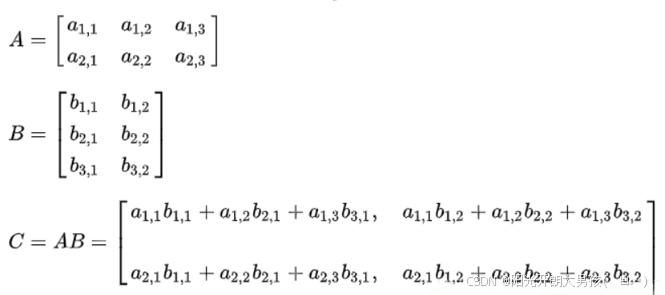
import numpy as np
x = np.array([[1, 2, 3], [4, 5, 6]])
y = np.array([[6, 23], [-1, 7], [8, 9]])
print(x)
print(y)
print(x.dot(y))
print(np.dot(x, y))
八、Numpy随机模块
在Num库Py中,`numpy.random`模块提供了一个功能丰富的随机数生成器,使我们能够方便地生成具有不同分布特性的随机数据。
1. 随机数种子
- 固定随机序列:设置相同的种子后,每次运行代码生成的“随机”数都会相同。
- 用途:在需要复现结果的场景(如机器学习、科学实验)中,保证不同运行时生成的随机数一致。
代码演示:
不设置种子
import numpy as np
# 每次输出不同
print(np.random.rand(3)) # 第一次可能输出 [0.548, 0.715, 0.603]
print(np.random.rand(3)) # 第二次可能输出 [0.544, 0.423, 0.645]
设置种子后
import numpy as np
np.random.seed(0) # 设置种子为0
print(np.random.rand(3)) # 总是输出 [0.548, 0.715, 0.603]
print(np.random.rand(3)) # 总是输出 [0.544, 0.423, 0.645]
注意:
- 种子值任意:
seed(0)中的0可替换为其他整数(如42),不同种子对应不同的随机序列。 - 作用范围:仅对当前代码块有效,重启内核或运行新程序需重新设置。
2. 随机数生成基础操作
import numpy as np
# 随机种子
np.random.seed(100)
# randint(start,end)
# 产生一个随机整数,在左闭右开的区间
r1= np.random.randint(0,100)
print(r1)
# rand()
# 产生一个在(0,1)之间的随机浮点数
r2=np.random.rand()
print(r2)
# normal() ->生成一些符合正态分布的数据
N~(0,1)
r3 = np.random.normal()
print(r3)
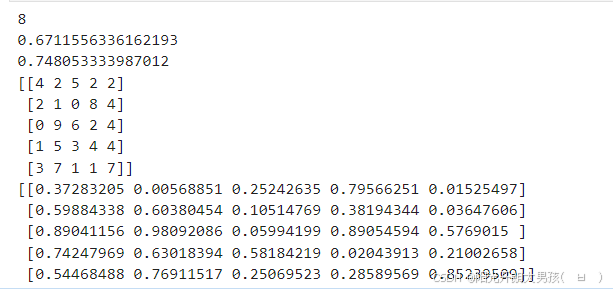
# 生成随机数矩阵
r4 = np.random.randint(0,10,size=(5,5))#产生一个数字在0-9之间随机整数的5 x 5的矩阵
print(r4)
r5 = np.random.rand(5,5)#产生一个数字在0-1之间随机浮点数的5 x 5的矩阵
print(r5)
九、Numpy文件读写
1. 读取文件
1. np.loadtxt()
• 文件格式:纯文本文件,每行数据可以是不同的数据类型。
• 参数设置:常用参数包括 delimiter 指定分隔符、dtype 指定数据类型、skiprows 指定跳过的行数等。
• 适用场景:适用于读取简单的纯文本数据,例如一组实验数据。
2. np.genfromtxt()
• 文件格式:纯文本文件,可以处理缺失数据和不规则数据。
• 参数设置:常用参数包括 delimiter 指定分隔符、dtype 指定数据类型、skip_header 指定跳过的头部行数、missing_values 指定缺失值等。
• 适用场景:适用于读取不规则的纯文本数据,例如含有缺失值或空行的数据。
3. np.recfromtxt()
• 文件格式:纯文本文件,可以处理缺失数据和不规则数据。
• 参数设置:常用参数和 np.genfromtxt() 类似。
• 适用场景:适用于读取带有列名的结构化数据,例如实验数据表格。
4. np.recfromcsv()
• 文件格式:CSV 文件,每行数据通常是相同的数据类型。
• 参数设置:常用参数和 delimiter 指定分隔符、dtype 指定数据类型、skip_header 指定跳过的头部行数等。
• 适用场景:适用于读取带有列名的 CSV 数据,例如实验数据表格。
方法对比
np.loadtxt():用于从文本文件中读取数据并将其存储为 NumPy 数组。默认情况下,此函数假定数据是数字,以空格为分隔符,并且没有标题行。此外,您可以指定数据类型,跳过特定行或列等选项。
np.genfromtxt():与 loadtxt() 类似,但更灵活。它可以处理缺失值,不同的分隔符,不同的数据类型,以及不同的文本文件格式(例如 CSV,TSV,等)。此外,它还可以处理带有标题行和注释行的数据文件。
np.recfromtxt():与 genfromtxt() 类似,但它创建的是结构化数组,其中每列可以具有不同的数据类型,并且每列可以用标题来标识。
np.recfromcsv():与 recfromtxt() 类似,但是它只能处理 CSV 文件格式,并且默认情况下使用逗号作为分隔符。
代码演示:
import numpy as np
%%writefile zzy.txt
1 2 3 4 5 6
2 3 5 8 7 9data = []
with open('zzy.txt') as f:
for line in f.readlines():
fileds = line.split()
cur_data = [float(x) for x in fileds]
data.append(cur_data)
data = np.array(data)
datadata = np.loadtxt('zzy.txt')
data%%writefile zzy2.txt
1,2,3,4,5,6
2,3,5,8,7,9
data = np.loadtxt('zzy2.txt',delimiter = ',')
data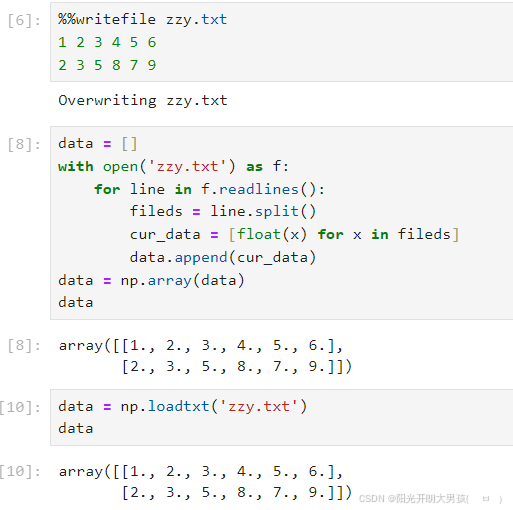

2. 写入文本文件
np.savetxt()
- 文件格式:纯文本文件,每行数据可以是不同的数据类型。
- 参数设置:常用参数包括 delimiter 指定分隔符、fmt 指定输出格式等。
- 适用场景:适用于将一组实验数据保存到纯文本文件中。
代码演示:
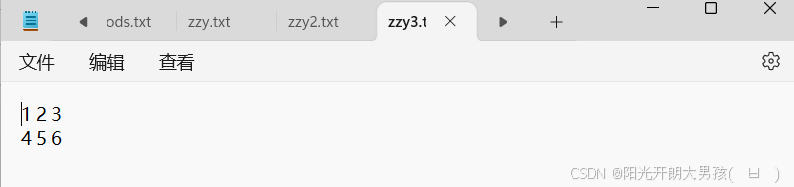
tang_array = np.array([[1,2,3],[4,5,6]])
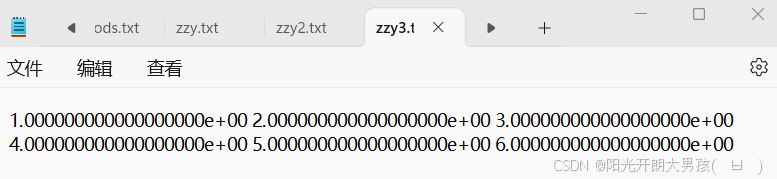
np.savetxt('zzy3.txt',tang_array)
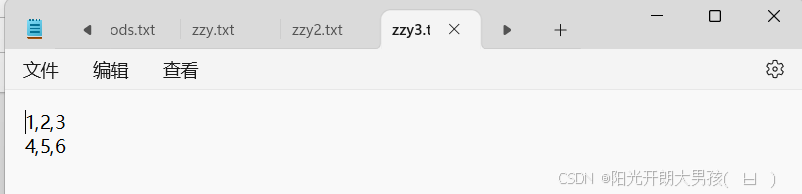
np.savetxt('zzy3.txt',tang_array,fmt='%d')
np.savetxt('zzy3.txt',tang_array,fmt='%d',delimiter = ',')
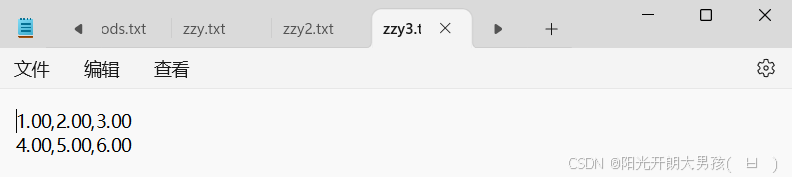
np.savetxt('zzy3.txt',tang_array,fmt='%.2f',delimiter = ',')
📜 至此,你已参透 【Numpy篇】数据乾坤:用Numpy三十六计玩转科学计算江湖 的绝世秘籍!
此番闭关修炼,你已淬炼:
✨ 数组筑基大法:ndarray多维筋骨、C语言级气血运转、连续内存吐纳术
✨ 数据造物诀:zeros/ones虚空生阵、arange剑指长空、随机矩阵撒豆成兵
✨ 玄妙运算道:向量化凌波微步、广播法则乾坤挪移、矩阵相乘量子纠缠
✨ 屠龙实战录:万亿数据瞬移术、高维张量破壁诀、科学计算性能飞升
🔍 招式晦涩?文中「广播法则」如雾里看花,或「轴运算」似经脉逆行?速速评论区「剑气留痕」!
💡 境界桎梏?若遇高维数据「走火入魔」,或内存优化「瓶颈难破」,留言区便是你的论道场!
🗡️ 你的每一式 ❤️点赞|⭐收藏|📤分享 ,皆为吾辈持续推演「Python圣殿」的混沌原力!


脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐



 32
32 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)