[NAACL 2025]FLIQA-AD: a Fusion Model with Large Language Model for Better Diagnose and MMSE Predicti
计算机-人工智能-大模型MRI神经精神疾病分类和得分预测

论文代码:https://github.com/junhao667/FLIQA-AD.git
英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用
目录
2.3.3. Question Answering Decoder
2.4.2. Experimental Setting Detail
2.4.3. Performance of Our Proposed Method
2.4.5. Interpretability Analysis
1. 心得
(1)同上篇,除了prompt,医学影像特征也可以进大模型
2. 论文逐段精读
2.1. Abstract
①Traditional models could not extract complete information from MRI, so the authors proposed a multi-task Fusion Language Image Question Answering model (FLIQA-AD) to identify AD and mental state (Mini-Mental State Examination, MMSE)
2.2. Introduction
①⭐Text encoder: bioClinicalBERT, which specifically pre-trained on diagnostic question-answering texts
②The overall framework of FLIQA-AD:
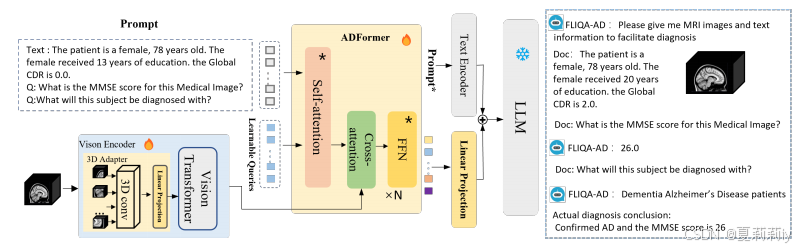
senile adj.衰老的;年老糊涂的
atrophy n. 萎缩 vi.萎缩;衰退
2.3. Method
2.3.1. 3D Adapter
①Global and local image information are important as the same way
②For image at size
and patch size
, the total number of patch is
③Each patch gets dimension features, and the input of Vision Transformer is
with
batch size
2.3.2. ADFormer
①Encoding electronic health records (EHR) (gender, age, education level, etc.) informations by pre-trained model
②For input image-text feature pair with sample number
, image feature
and text feature
③Attention block: bio-Clinicalbert
2.3.3. Question Answering Decoder
①LLM: FLANT5
②Loss:
where denotes input text sequence,
is the length of text token,
denotes the sequence of ADFormer output,
is the number of learnable Queries,
denotes previous
prediction
2.3.4. Training Objective
①Contrastive learning for alignment:
where denotes the target of the prediction
②The total loss:
2.4. Experiments
2.4.1. Data and preprocessing
①Datasets: ADNI and OASIS with statistic data:

2.4.2. Experimental Setting Detail
①Data split in ADNI: randomly choose 300 of each category for test set and the rests are training set and validation set
②All 373 samples from OASIS-2 were used for zero-shot tests
③Input image size: 126×126×126 with patch size of 18 and patch number of 343
④Input size of Vit: 344 × 1408 (with class token preserved)
⑤ViT: EVA_CLIP
⑥Learnable queries: 32
⑦Optimizer: AdamW
⑧Learning rate: adjusted by WarmupCosine with initial 2e-5
⑨Batch size: 8
2.4.3. Performance of Our Proposed Method
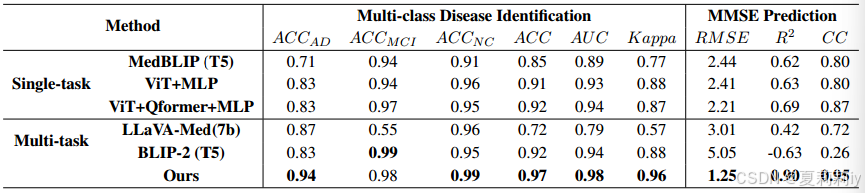
①Comparison table on ADNI(感觉和消融差不多,都不是很算对比主表吧):
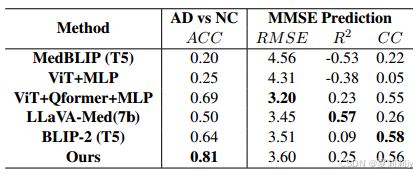
②Performance on OASIS:
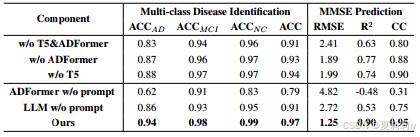
2.4.4. Ablation Study
①Ablation results:
2.4.5. Interpretability Analysis
①Predicted MMSE and cluster distribution:
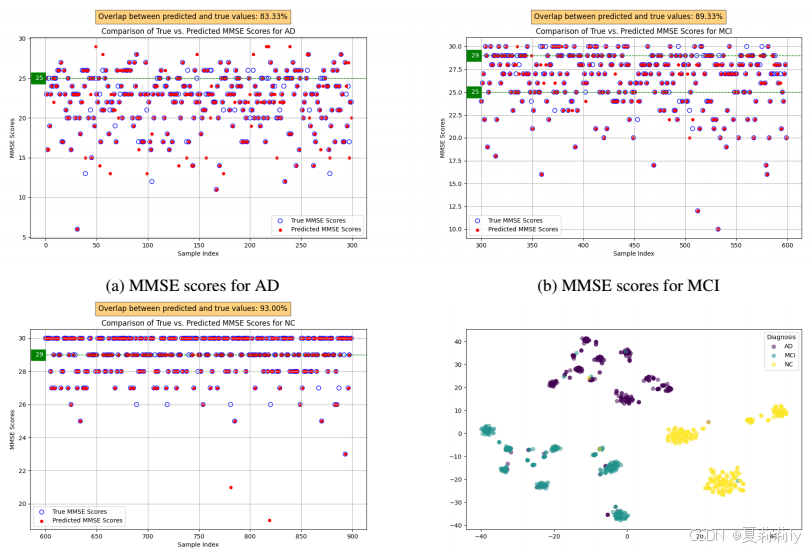
2.5. Conclusion
~

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 22
22 0
0- 0



 已为社区贡献42条内容
已为社区贡献42条内容

所有评论(0)