Google机器学习实践指南(机器学习四大数据划分方法详解)
2. 交叉验证法 (K-fold Cross Validation)Google机器学习(16)-四大数据划分技术解析(约6分钟)3. 留一法 (Leave-One-Out, LOO)将数据集D直接划分为互斥的训练集S和测试集T。1000样本数据集(500正例+500反例)→ 训练集700样本(350正+350反)→ 测试集300样本(150正+150反)常用k=5或10,数据量大时可减小k值。k
🔥 Google机器学习(16)-机器学习四大数据划分方法详解
Google机器学习(16)-四大数据划分技术解析(约6分钟)
一、机器学习核心步骤
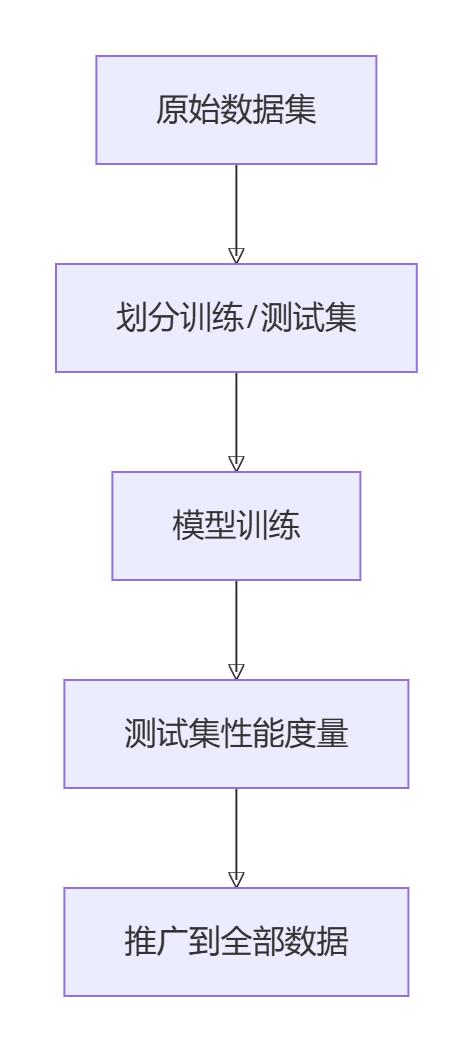
- 数据划分
将数据集分为训练集和测试集两部分
- 泛化性能度量
在测试集上评估模型性能
- 统计推广
基于测试结果推断模型在全部数据上的泛化性能
二、四大数据划分方法
1. 留出法 (Hold-out)
原理:
将数据集D直接划分为互斥的训练集S和测试集T
数学表示: D = S ∪ T, S ∩ T = ∅
关键要点:
保持数据分布一致性(分层抽样)
典型比例:
- 训练集70-80%,测试集20-30%
多次随机划分取平均减少误差
示例:
1000样本数据集(500正例+500反例)
→ 训练集700样本(350正+350反)
→ 测试集300样本(150正+150反)
2. 交叉验证法 (K-fold Cross Validation)
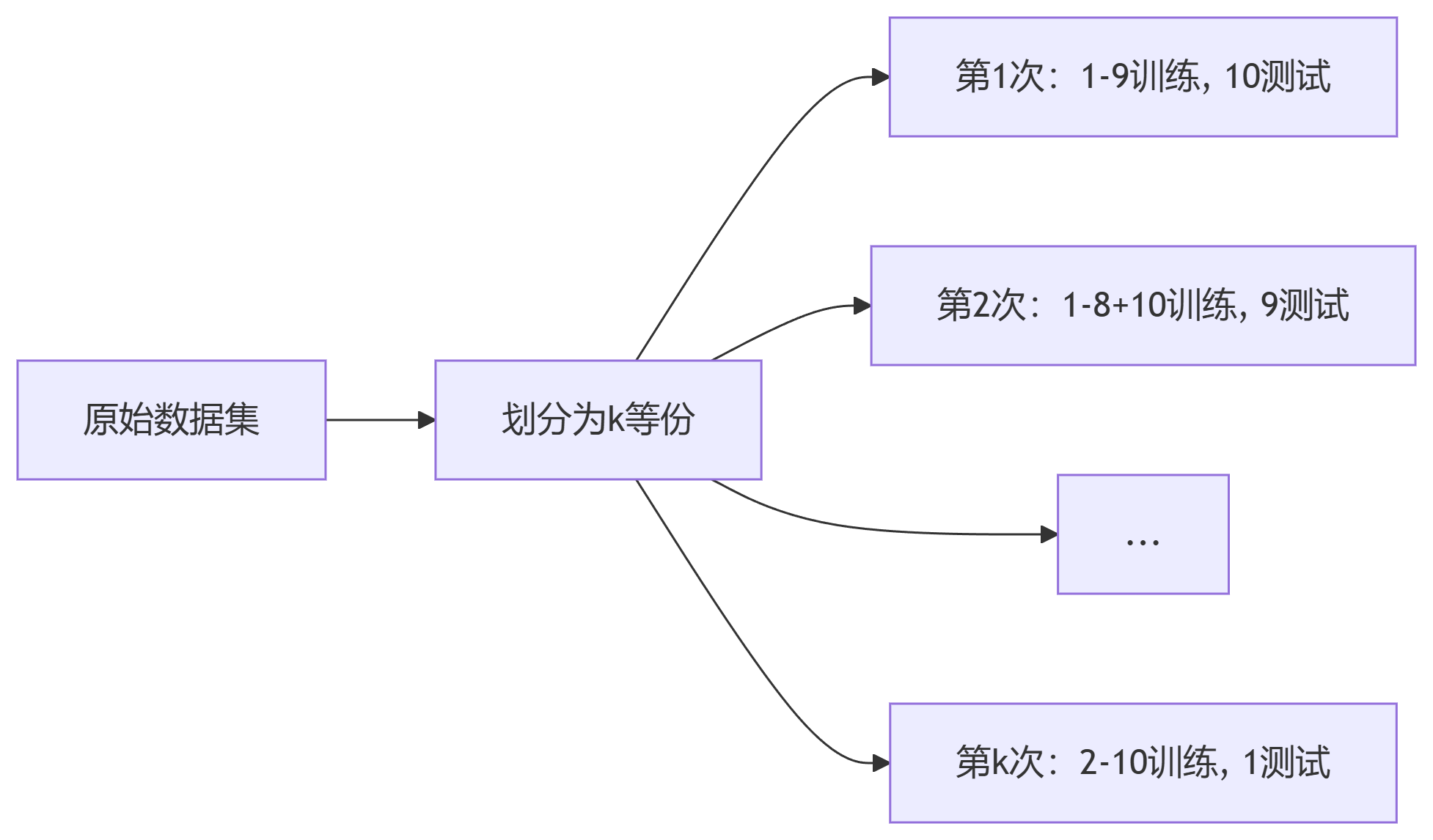
原理:
将数据集D划分为k个互斥子集
数学表示:
D = D 1 ∪ D 2 ∪ . . . ∪ D k , D i ∩ D j = ∅ ( i ≠ j ) D = D₁ ∪ D₂ ∪ ... ∪ Dₖ, Dᵢ ∩ Dⱼ = ∅ (i ≠ j) D=D1∪D2∪...∪Dk,Di∩Dj=∅(i=j)
特点:
-
k常取5或10(10折交叉验证)
-
充分利用数据,避免局部极值
-
计算开销大(需训练k个模型)
3. 留一法 (Leave-One-Out, LOO)
原理:
k折交叉验证的特例(k=样本数m)
特点:
-
每次只用一个样本测试
-
结果接近直接使用D训练
-
仅适用于小样本集(m<50)
4. 自助法 (Bootstrapping)
原理:
有放回抽样生成训练集
数学特性:
初始样本在m次采样中不被采到的概率:
( 1 − 1 / m ) m → 1 / e ≈ 0.368 ( 当 m → ∞ ) (1 - 1/m)ᵐ → 1/e ≈ 0.368 (当m→∞) (1−1/m)m→1/e≈0.368(当m→∞)
适用场景:
-
小数据集难以划分
-
集成学习
缺点:
改变初始数据分布
三、方法选择指南
| 方法 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| 留出法 | 中大型数据集 | 实现简单,计算高效 | 单次划分可能偏差 |
| 交叉验证 | 中小型数据集 | 结果稳定,数据利用率高 | 计算开销大 |
| 留一法 | 极小样本集(<50) | 无随机性偏差 | 计算量极大 |
| 自助法 | 小样本/集成学习 | 适用于小样本 | 改变数据分布 |
最佳实践:
大数据集 → 留出法
中数据集 → 10折交叉验证
小数据集 → 留一法或自助法
# 技术问答 #
Q:为什么需要多次随机划分?
A:减少单次划分的随机性偏差,提高评估稳定性
Q:交叉验证中k值如何选择?
A:常用k=5或10,数据量大时可减小k值
Q:自助法为什么改变数据分布?
A:有放回抽样导致某些样本多次出现,某些从未出现
参考文献:
[1] 机器学习数据划分方法对比
[2] Google机器学习最佳实践

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 40
40 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)