3D真实世界的神经表示和渲染(刘玲洁)
之前的方法都是利用多视角图片作为一个输入,但是在进行新的三维场景重构的时候并不需要一个多视角图片的输入 ,因为多视角的图片集是不长存在的,常存在的图片集是单视角的图片(未知相机信息,未知其他视角图片),那么新的三维场景重构就可通过单视角的图片进行场景重建。人工智能就是模仿人类捕捉世界的能力,人看到的世界都是二维的图片,通过二维的图片一样得到三维的信息,并进行真实感的渲染,更上层的要求是希望能够进行
1、Nerf引入
我们生活在一个三维世界,人和人之间进行交互。在数字化世界的时候,我们希望是三维的,因为这样,我们就可以重各个角度去观察场景中的物体。三维的数字模型对于医疗、原宇宙(人与虚拟世界的无缝交互)、人工智能机器人的三维感知能力
长远的看法,希望人工智能与三维感知相融合。人工智能技术能够帮助进行三维建模和三维渲染,相反三维也可以赋予人工智能一个三维感知的能力。
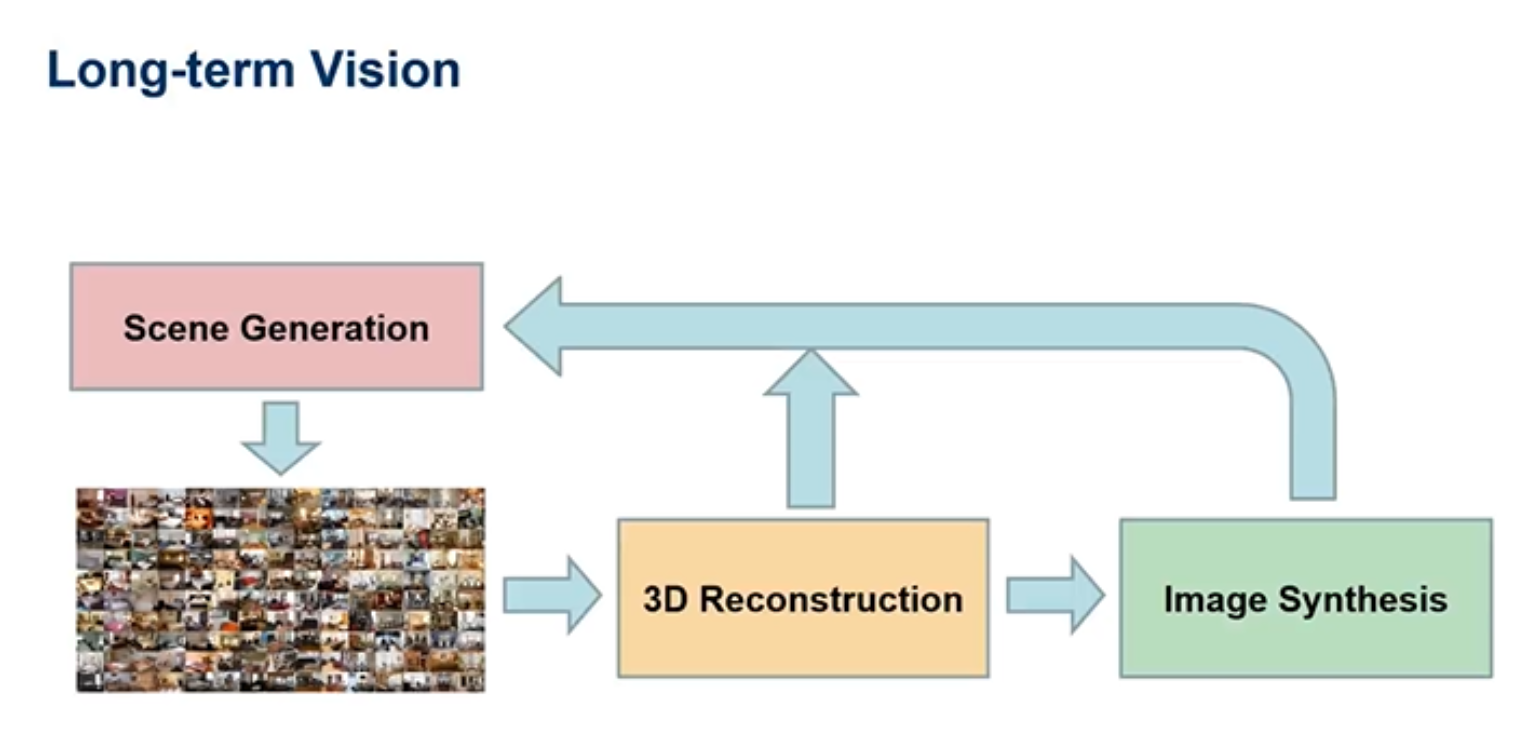
如何将人工智能与三维感知相结合?人工智能就是模仿人类捕捉世界的能力,人看到的世界都是二维的图片,通过二维的图片一样得到三维的信息,并进行真实感的渲染,更上层的要求是希望能够进行大规模高质量三维场景模型的重建,可以对三维模型进行自优化。

这一套系统可以用于很多的下层应用,如AR/VR,医疗,游戏,自动驾驶等等。
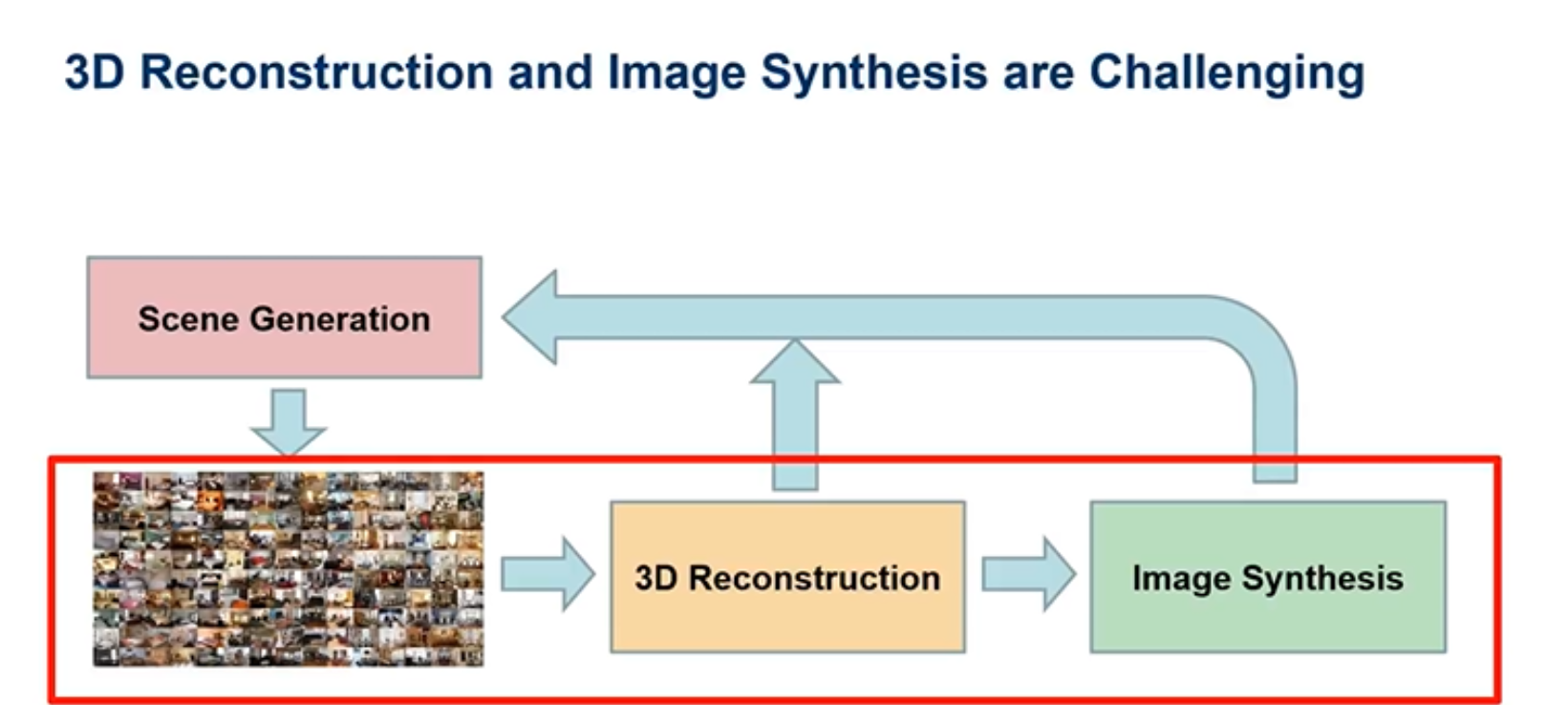
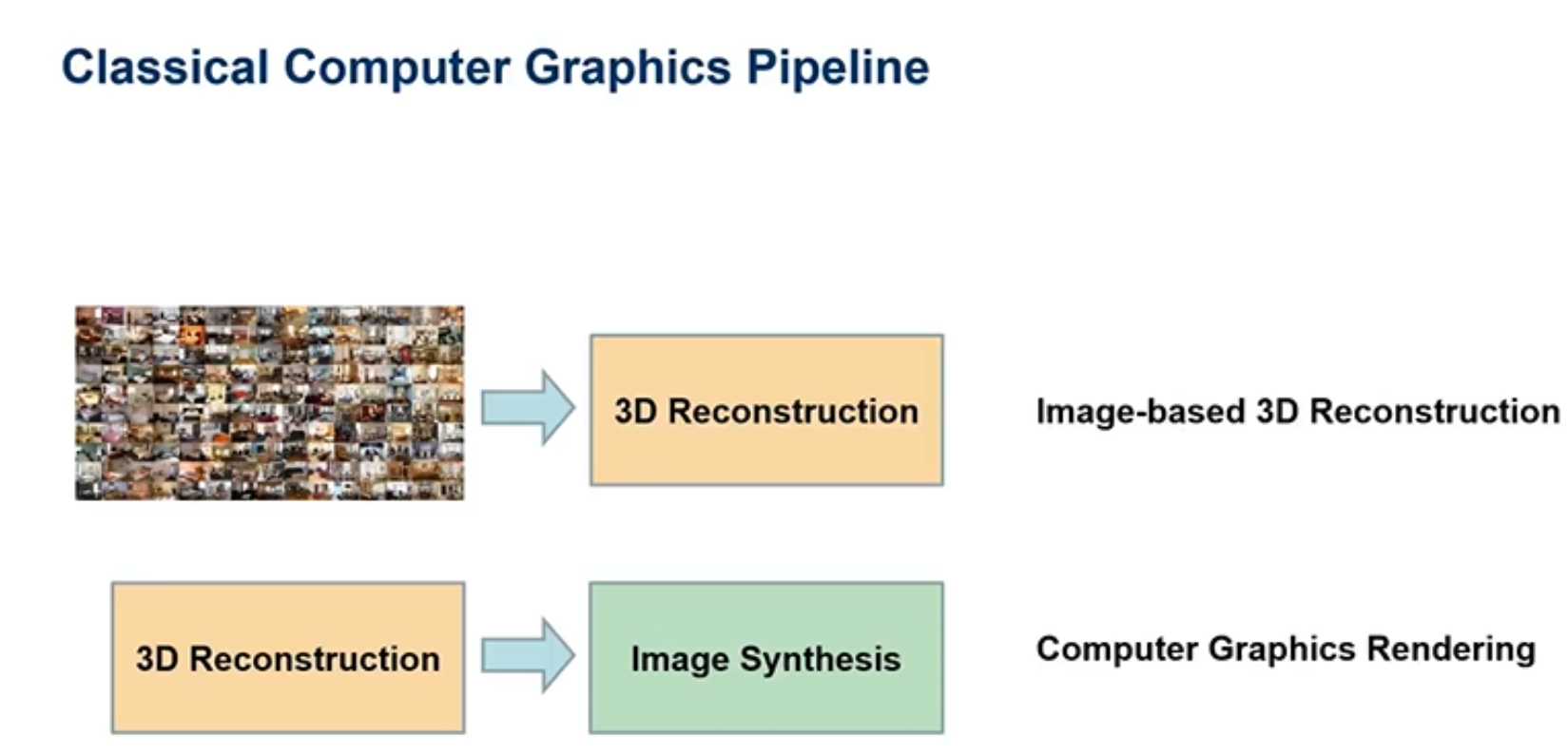
这套系统是有难度的,首先是底层(红框内)要求通过二维图片得到三维表达,进而进行真实渲染。传统的方法有两步,第一步就是通过多视角的二维图片,去重建一个比较好的三维模型,第二步是进行真实感的渲染得到另一个未见视角的图像。



第一步通常是通过colmap得到的,但是由于colmap的输入是多张图片,有多个噪声点,重建的三维模型效果并不是很好。在第二步当中如果想要得到一个比较好的渲染效果,一是需要一个高质量的三维模型,二是要有清晰的纹理结构。所以说第一步到第二步,三维模型的质量是关键的挑战。因为想要进行大规模高质量的三维场景模型重建就是更具有挑战的工作。
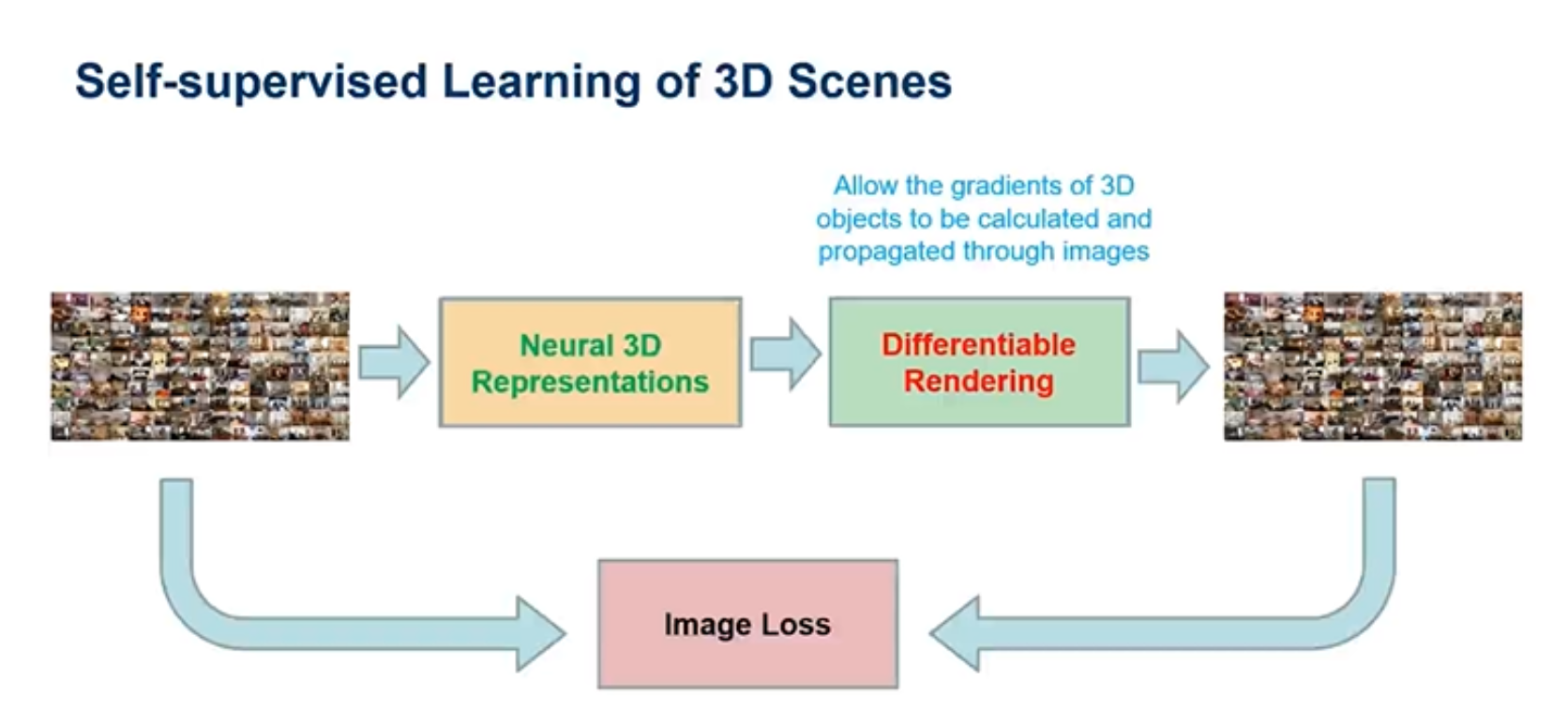
现在很多的三维建模,仍然是手工建模,这是非常耗费时间和精力的。为了解决这个问题,一些研究者通过人工智能得到了一些启发,将传统方法分开的两步合为连续的两步(端到端的过程),真实感渲染过程变为变为可微分渲染。整个过程以二维图片作为输入,获得三维信息后,进行可微分渲染,得到输出的一组二维图片,在将输入输出图片进行一个损失值的运算,从而更新三维信息(神经三维表达),这样不断迭代这个过程,直到损失值达到较小的临界值。
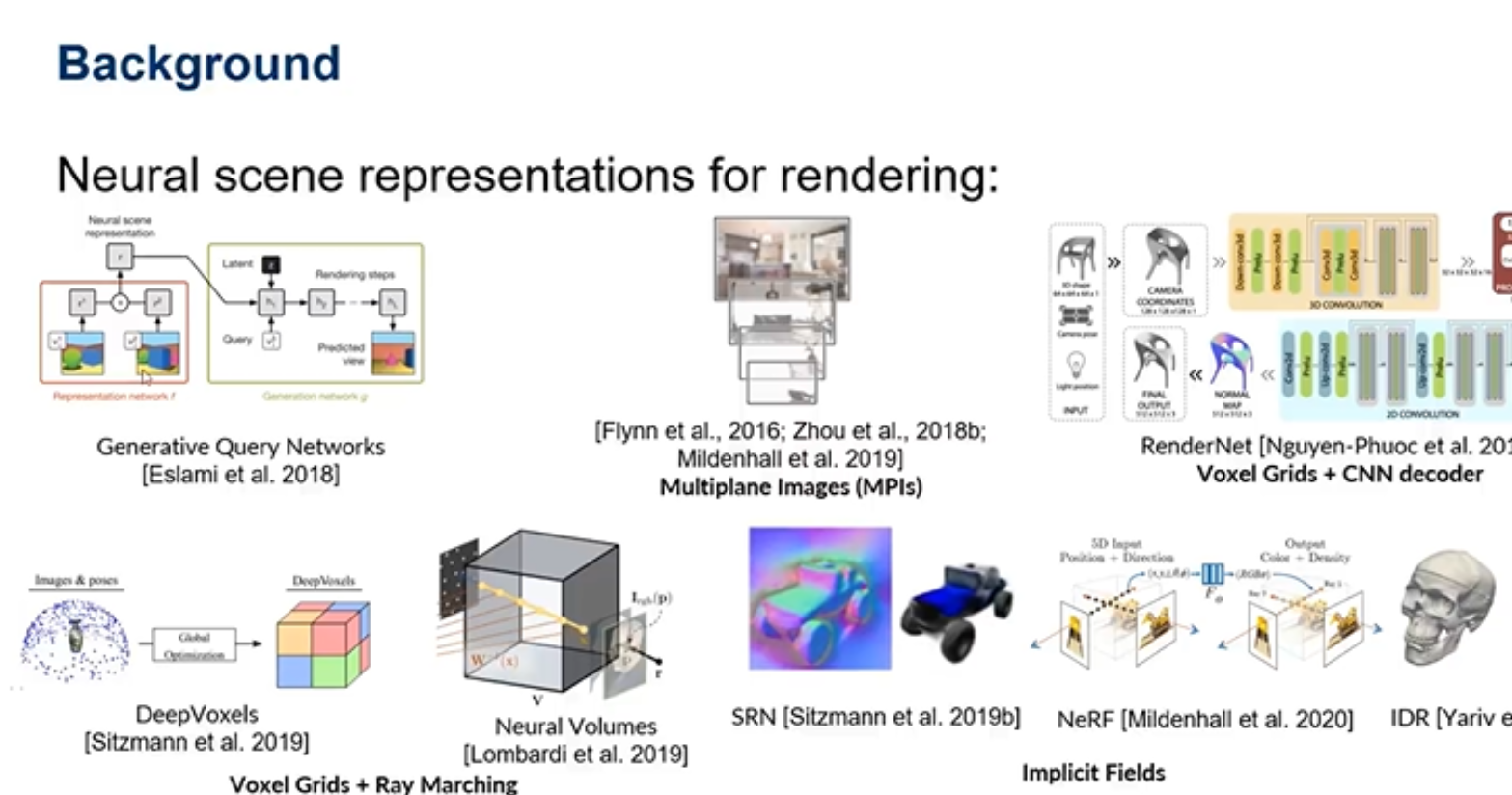
上图是已经提出的常用的神经三维场景方法,其中最近的Nerf热度很高,因为它的渲染效果很好。
2、Nerf的改进
2.1 NSVF对于Nerf速度的改进
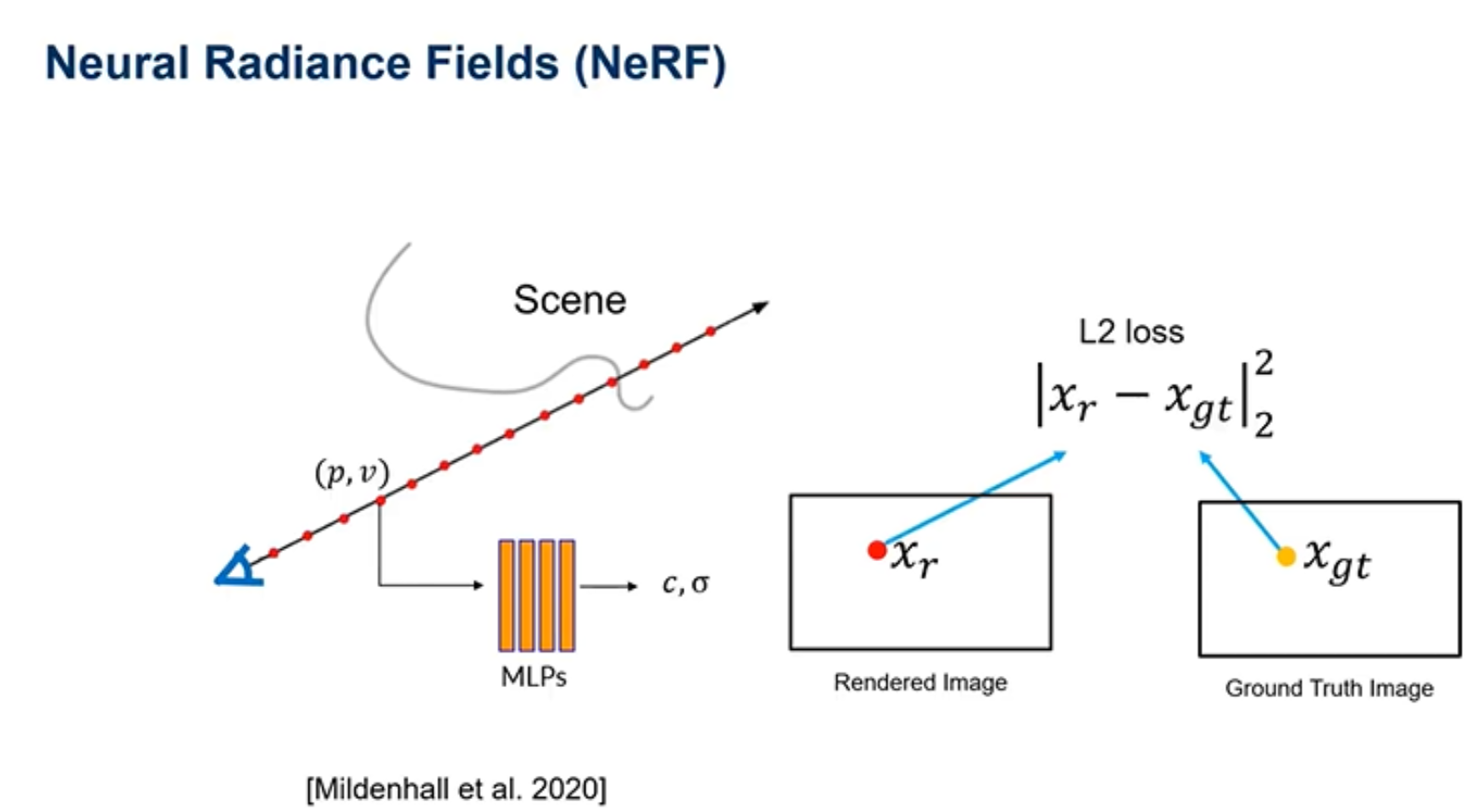
Nerf是将真实场景里面的点(如P点),全部放到MLP里面,计算每个点的颜色和密度,进而求出所输出图像的所有点,每个点求出的颜色都会和真实点的颜色做一个损失值的计算,进而更新MLP里面的值,从而更好的渲染。
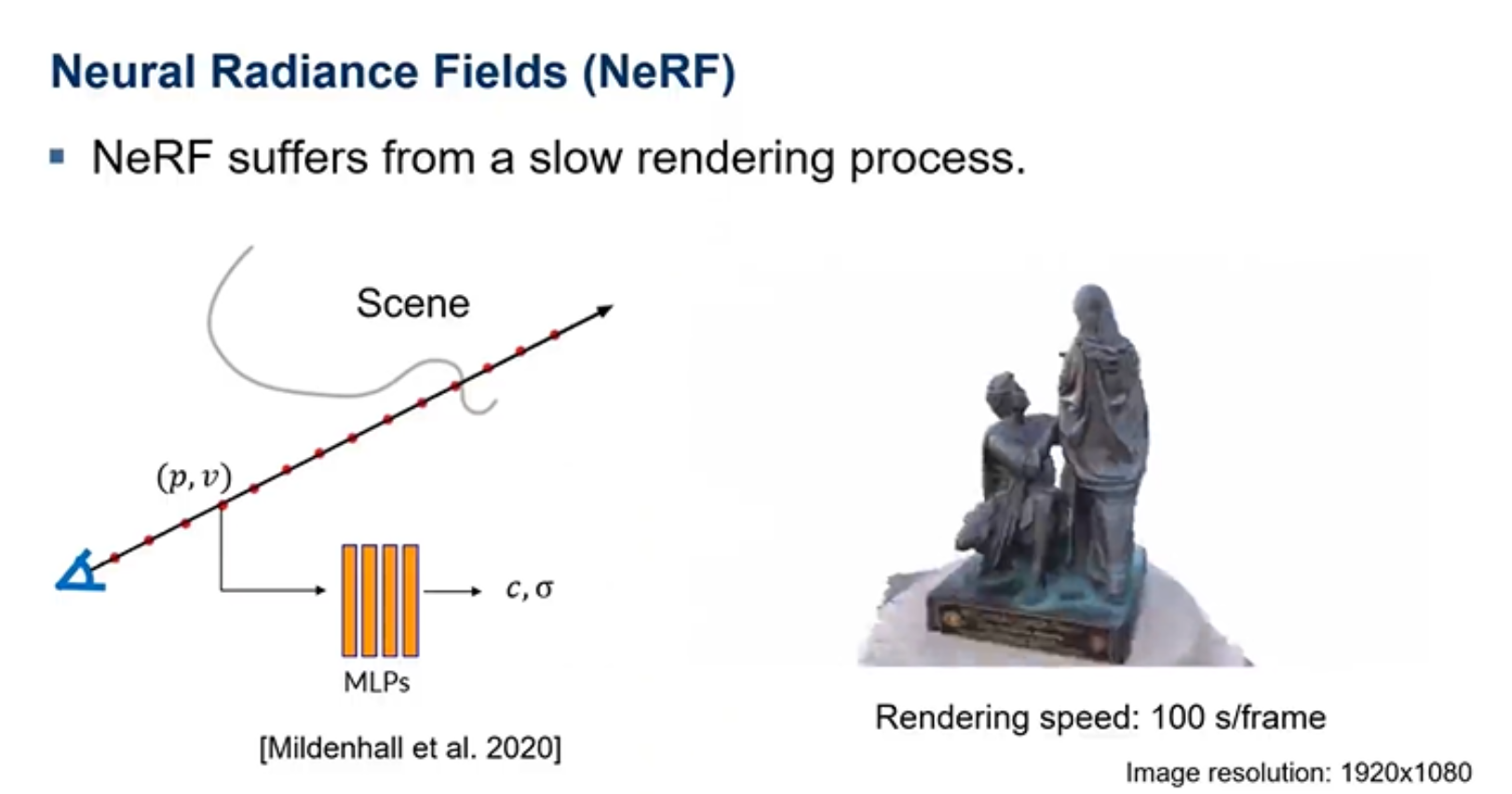
Nerf的最大问题就是它的渲染速度比较慢,因为它需将每个像素点发射出去的光线上面所有采样点都输入MLP进行计算。

由于Nerf速度比较慢的问题,刘玲洁老师工作室提出了NSVF(比Nerf快十倍)。
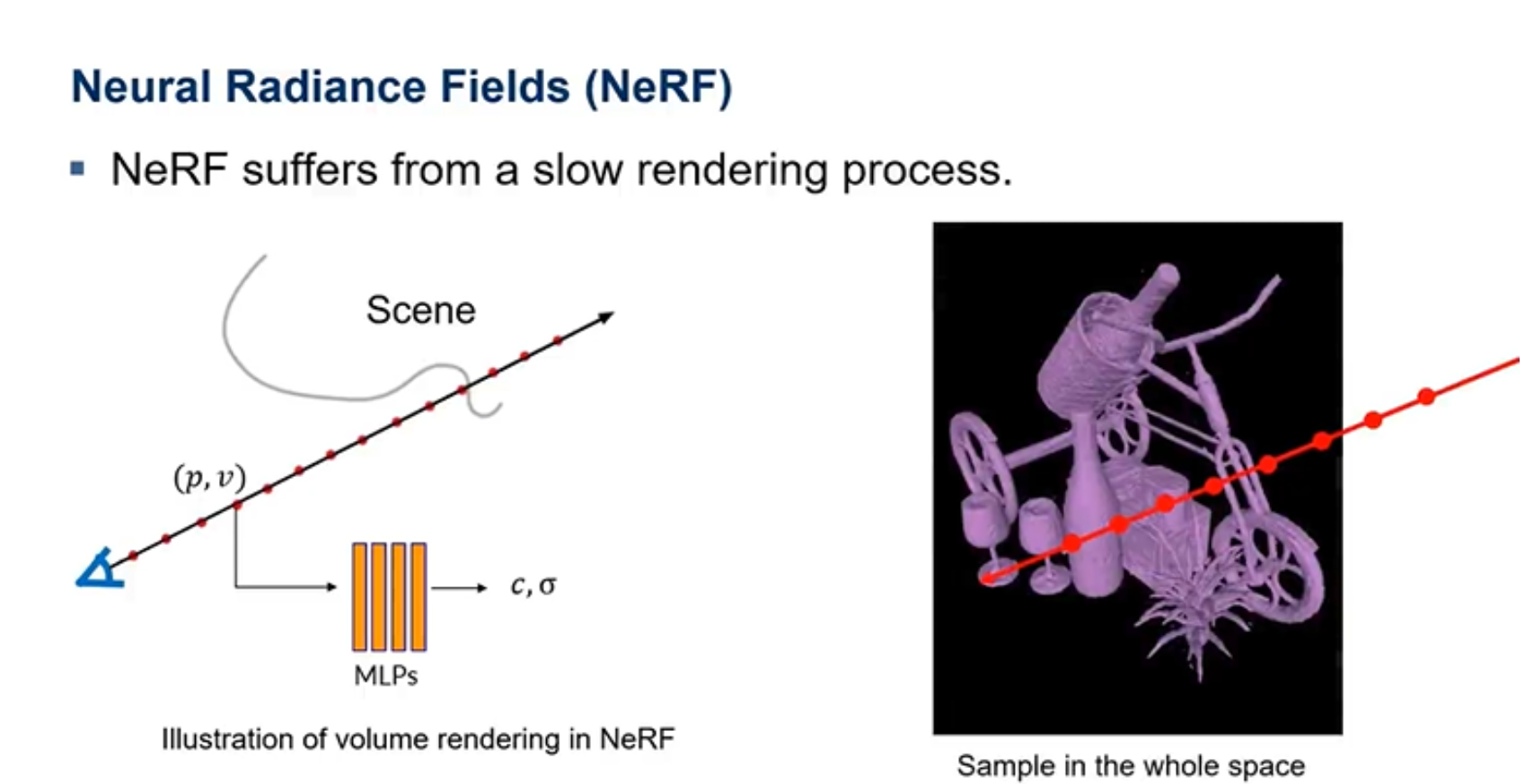
Nerf渲染速度比较慢的一个原因就是采样过程中,取了太多的采样点,然后一些位于空气中的采样点,对最后的成像是没有帮助的。
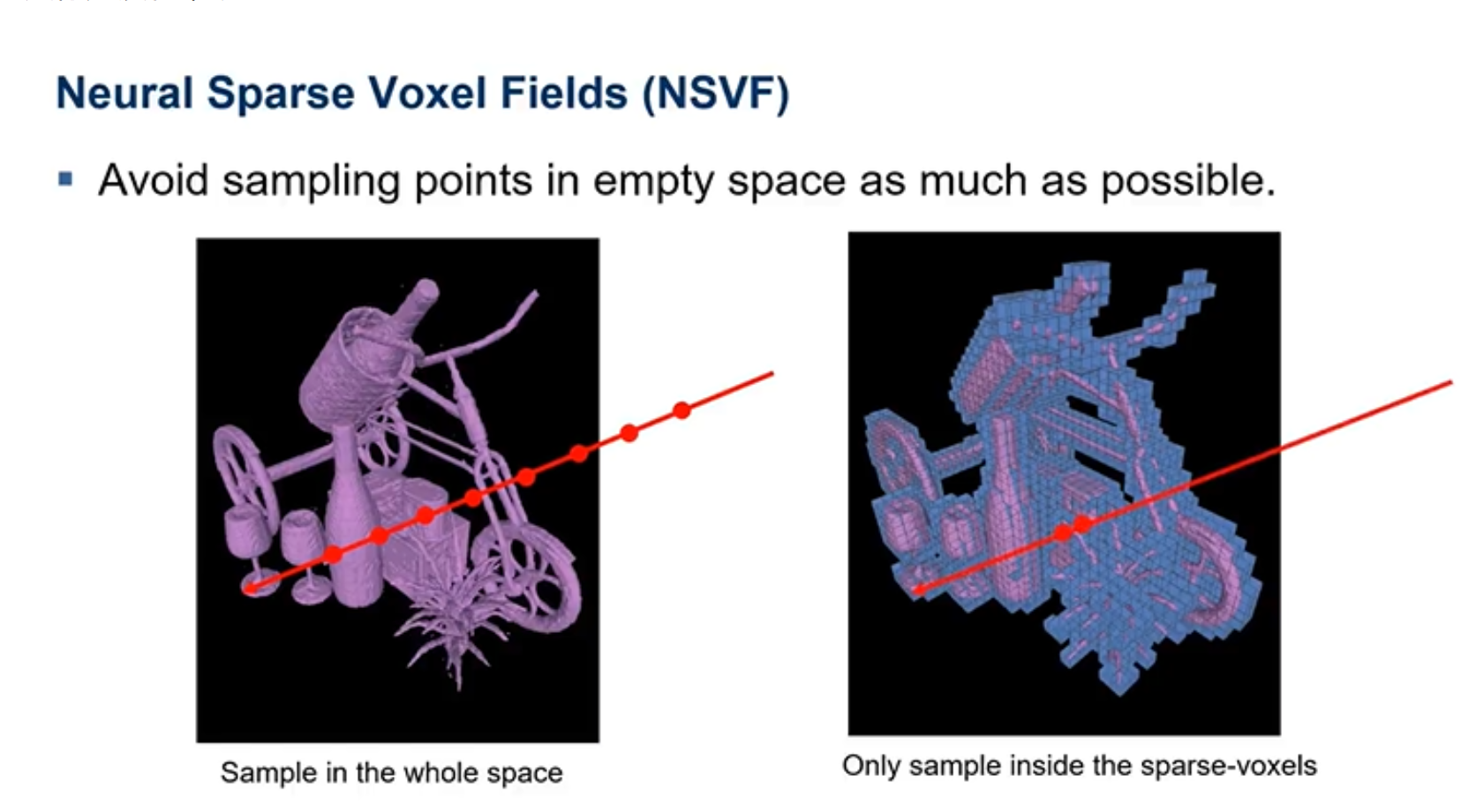
NSVF是将Nerf隐式的表达和一个显示的表达进行融合,只取位于物体上的采样点。
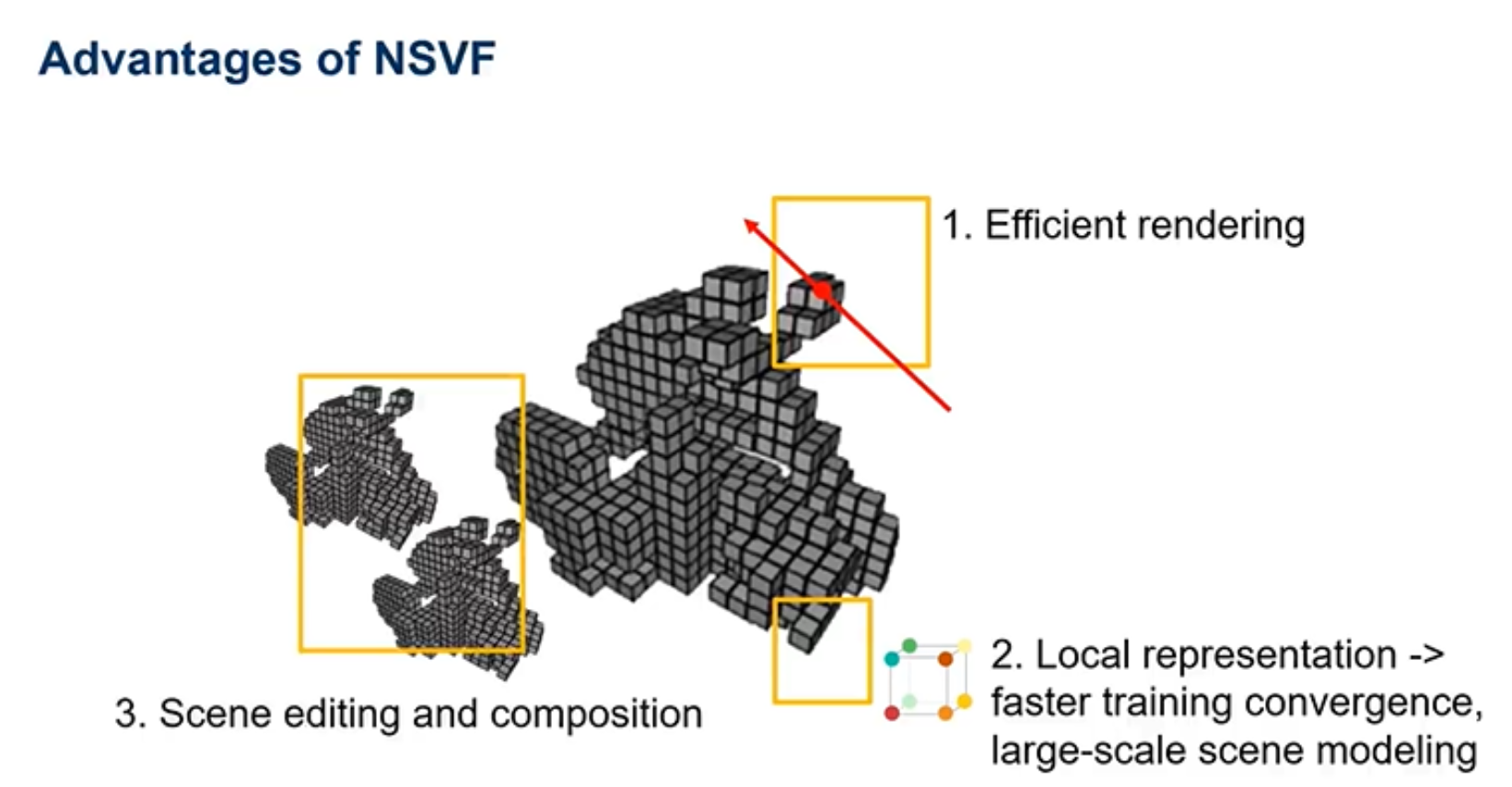
NSFV有三个优点:1、可以提高渲染的速度。2、可以更快的在训练集上收敛。3、更适用于大规模场景。

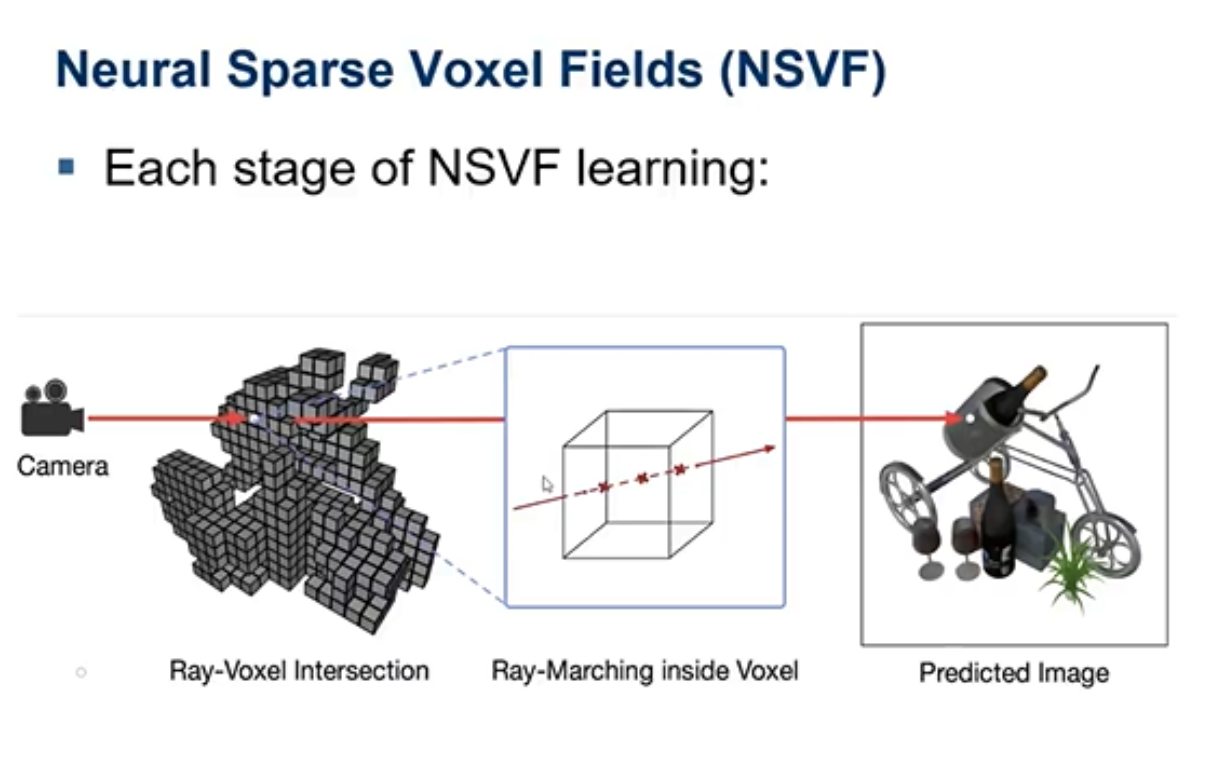
NSVF在训练过程中,会让一个大的体素模型,慢慢接近于真实物体形状,并且采样只对经过体素哥的采样点采样。
2.2 Neus对于Nerf的3D表示的改进
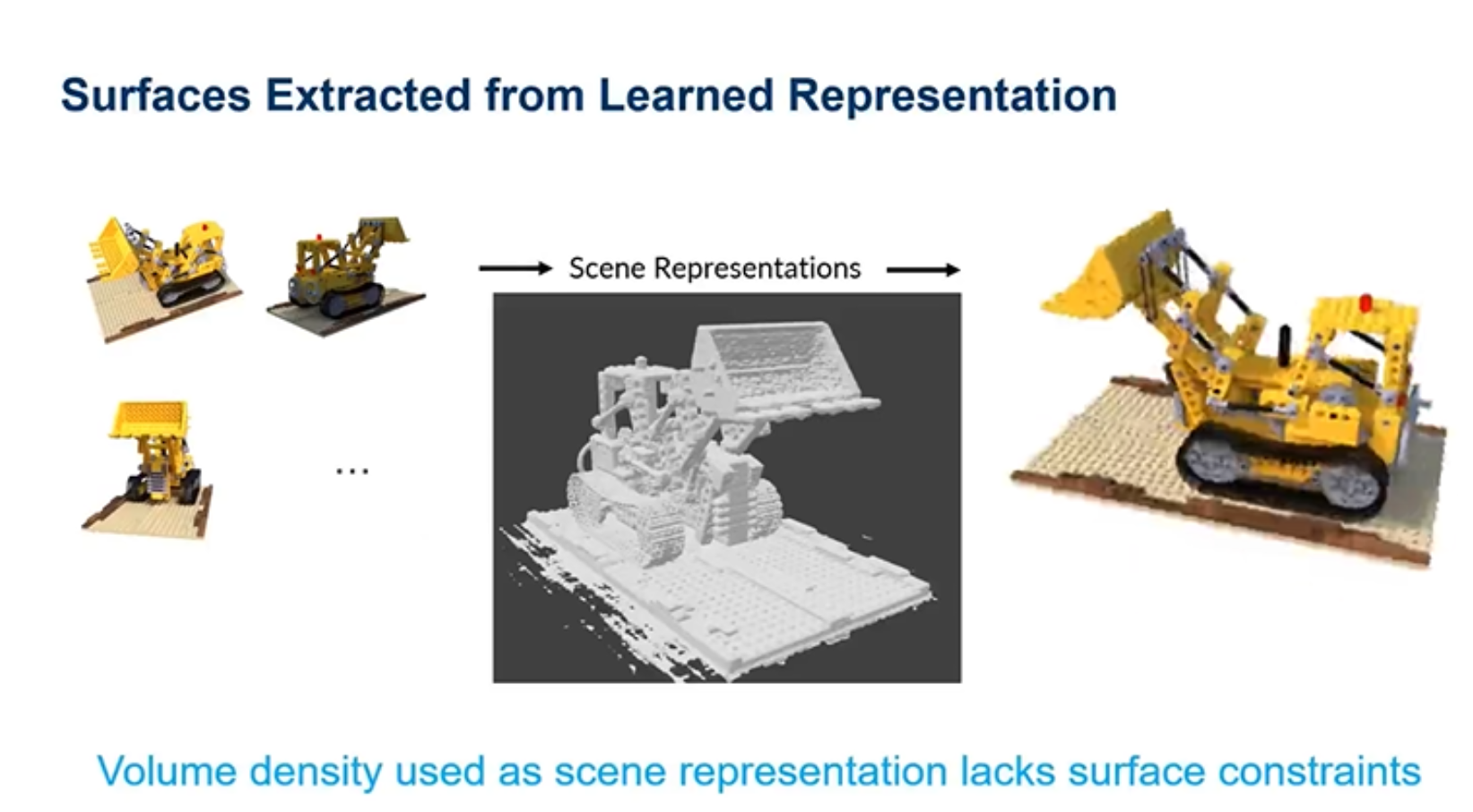
Nerf和NSVF都是以多张图片作为输入,然后得到一个三维表示后进行自由视角的渲染,那么这个三维表示可不可以用于表面重建来表示场景,然而Nerf提取的三维表示含有很多的噪声点,使得表面重建非常粗糙。
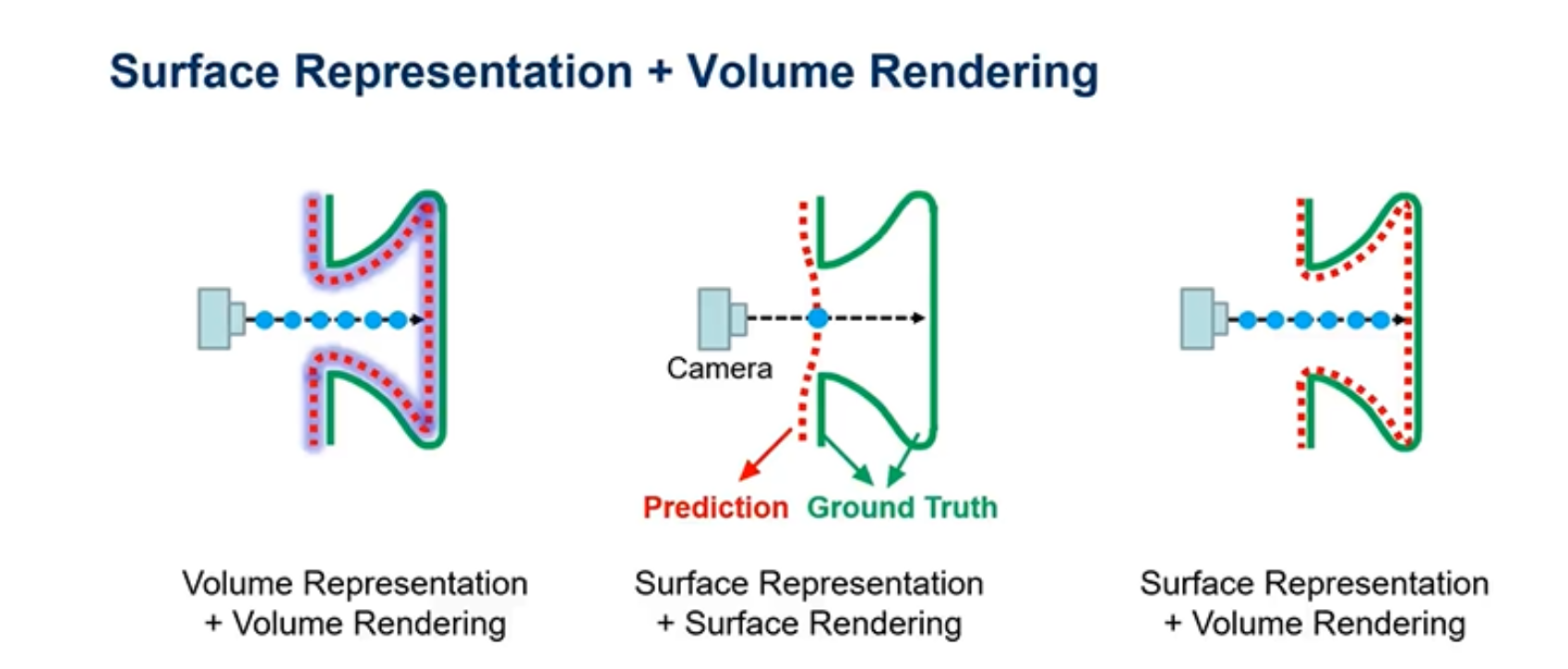
为了使得表面重建比较光滑,引入了一种表面渲染和表面重建的场景表示,但是表面渲染的效果不好,然后Nerf是体积重建的效果不好,Neus就是将体积渲染与表面重建相结合来进行场景表示。
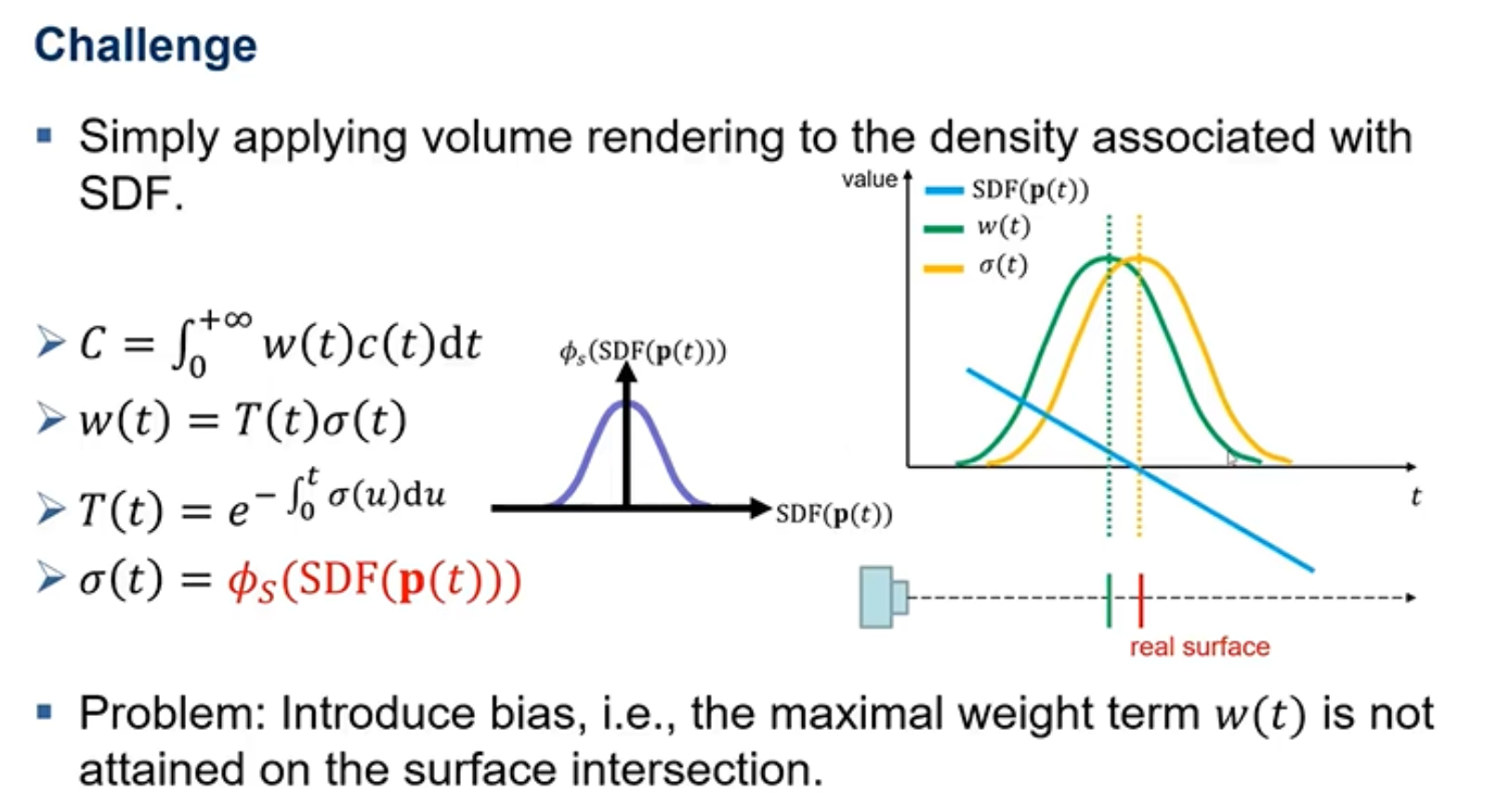
Neus的这个设计带来的挑战就是将密度这个函数进行高斯的表示。但这样最终出现的问题就是密度最大的哪个点(黄色波峰),他对于颜色的贡献最大,但是它的波峰值却没有与权重的波峰相重合,这就会导致表面重建不准确。进而要设置一个新的权重函数,使得权重函数的最大值逼近表面重建密度值的最大值,也就是使蓝绿波峰尽可能的重合。权重函数满足的条件:1、SDF蓝色的这条直线经过t轴的时候,也就是SDF=0的时候,不仅是密度值要最大,权重值也要最大。2、当像素点的光线射出去的时候,我们希望光线经过物体前面那个点的权重值要比后面个点的权重值大,因为前面那个点可能把后面那个点遮住了。


上图是新设计的权重函数,但是它只是公正的不是遮挡感知的。而原来Nerf的权重函数是遮挡感知的而不是公正的。Neus所做的工作就是将这两种权重函数相结合,做到权重函数即是公正的,也是遮挡感知的。

上图是Neus重建的结果,可以看出相对于IDR,Neus训练过程更加稳定,相对于Nerf,Neus重建的模型表面更光滑。给Neus一组图片,可以得到更高质量的几何和高质量的渲染结果。

Neus的局限是当输入的照片表面纹理信息很差的时候,重建效果很差。(室内场景一般纹理性都很差,比如大块的白墙等)。
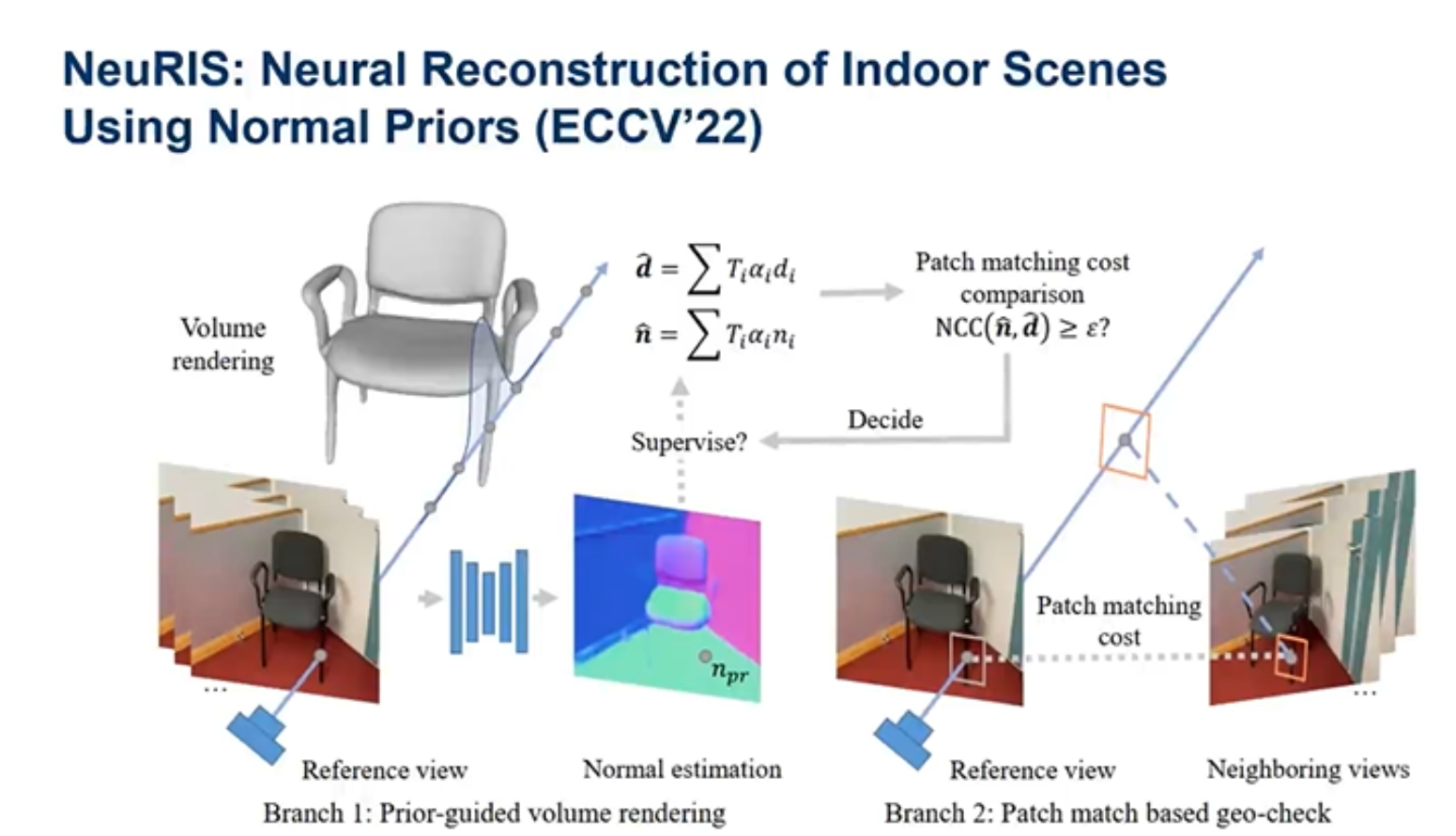
因此提出了NeuRIS,使得Neus能够很好的对室内场景进行重建。其原理就是在Neus训练的过程中加入了正态估计,进行体积渲染。

上图就是NeuRIS相对于Neus的室内场景重建结果。
2.3 Neural Actor针对于动态场景对Nerf(静态)的改进
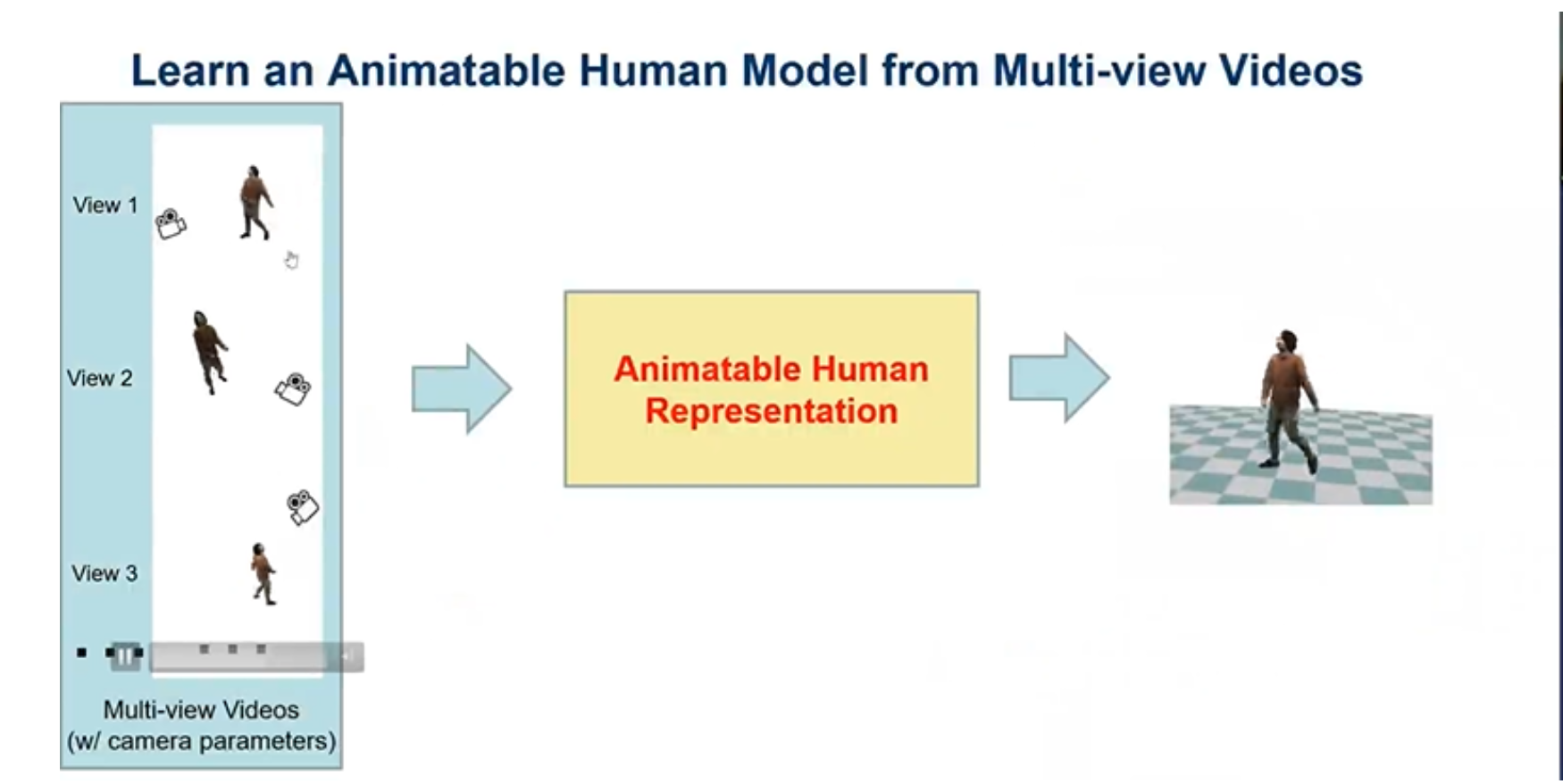
给定一个人类动画模型的多视点视频,是一个时间序列模型,从中就可以学到人类动画模型的三维表示,从而对人类模型的各个视角进行渲染。
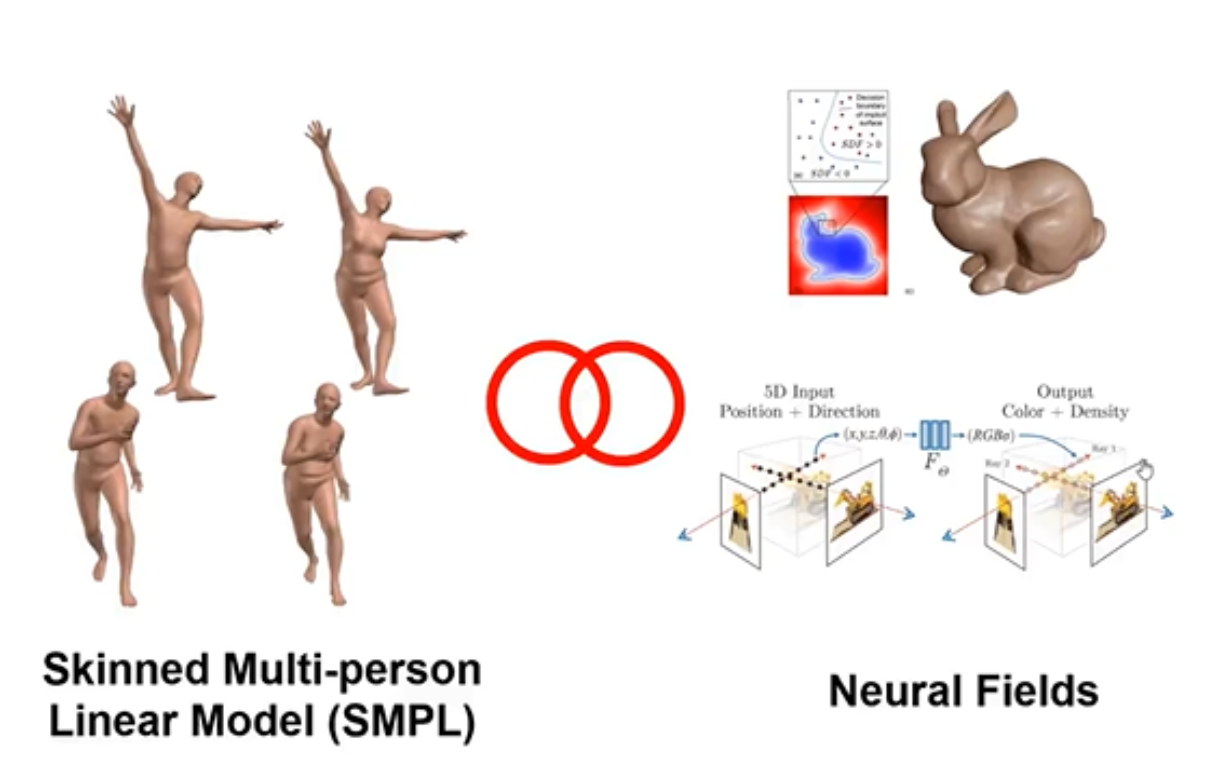
上图提出来一个Neural Actor,它是讲将一个蒙皮多人线性模型与之前的隐式的静态场景表达相融合。
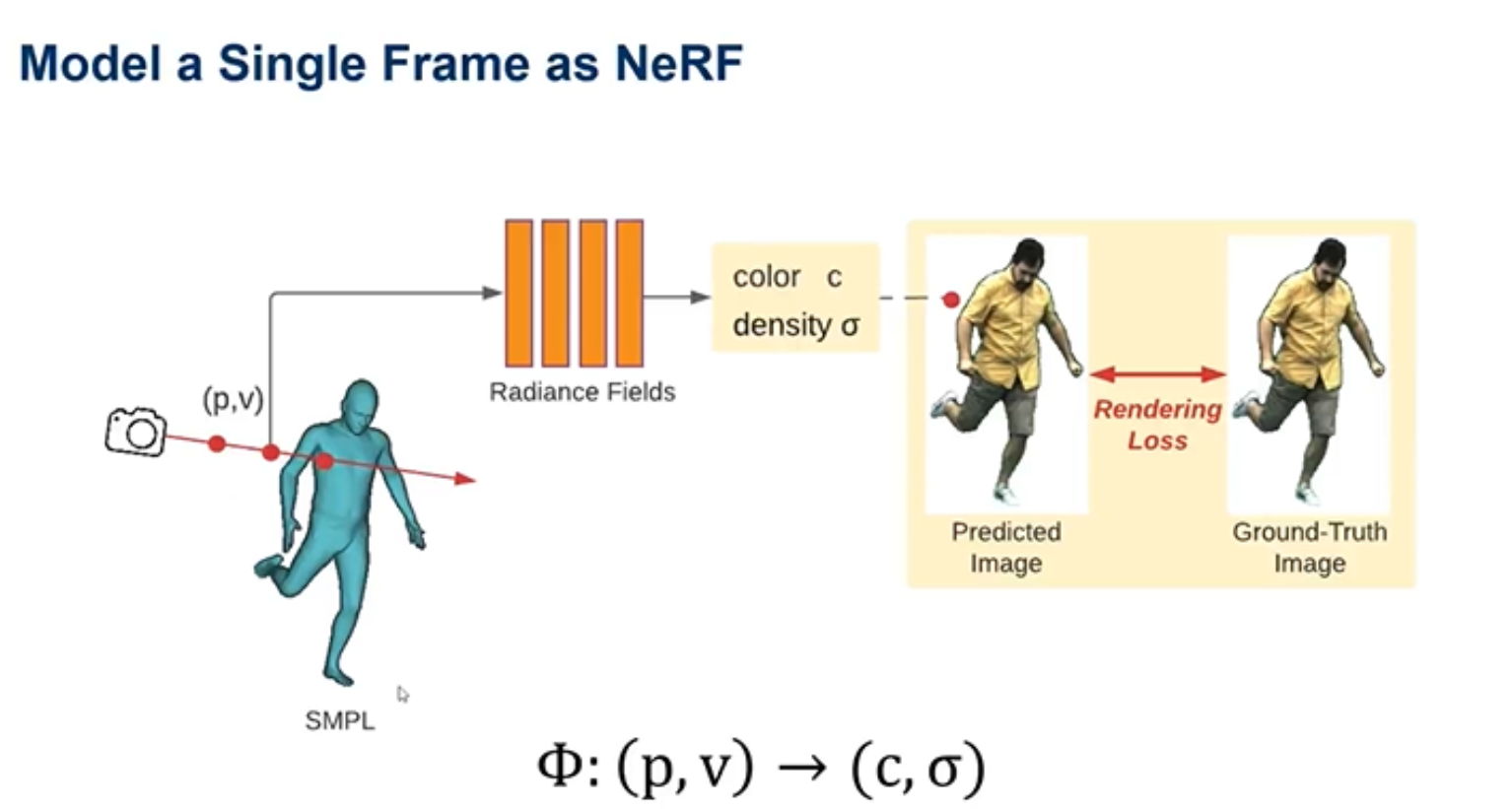
上图是指将视屏我每一帧都进行分割,然后针对于每一张的图片,都训练一个Nerf模型(一个模型针对于一个场景)出来。

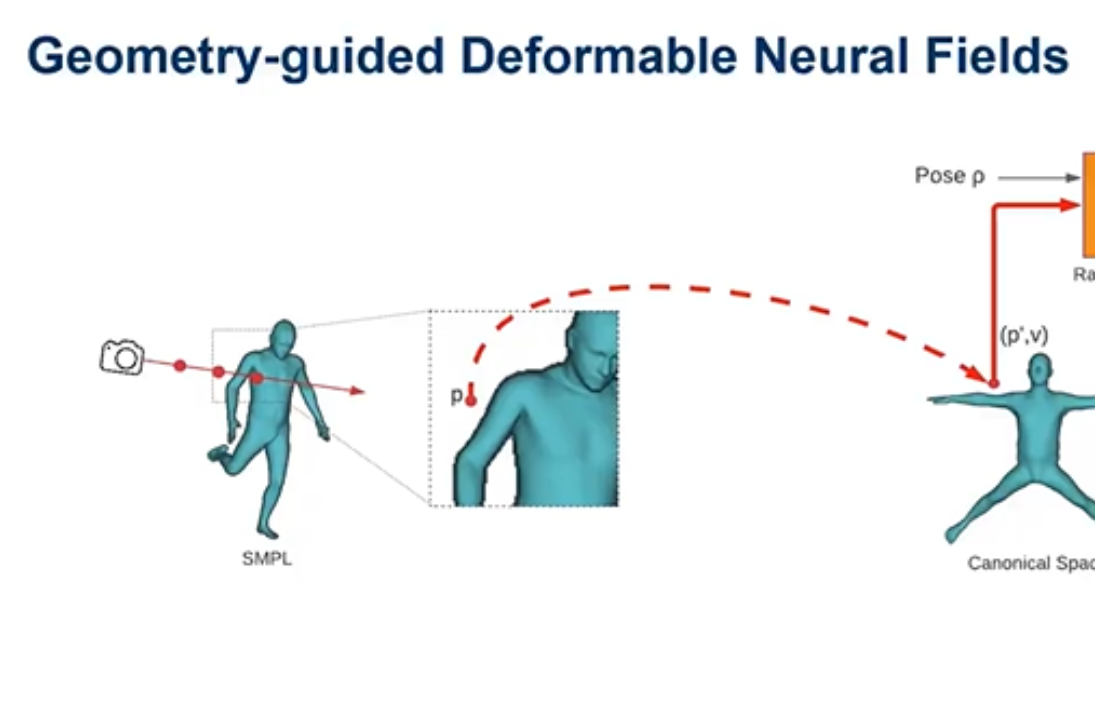
为了对动态的人体模型进行重建,采用姿势控制的方法,但是姿势控制最终的效果并不好,我们要充分利用时间序列之间的关系,人的整体形状和外貌在时间序列里是不会变的。在Neural Actor当中是把人的每个姿势的形状都放到一个规范空间,在到规范空间里面去学里面的颜色和密度。
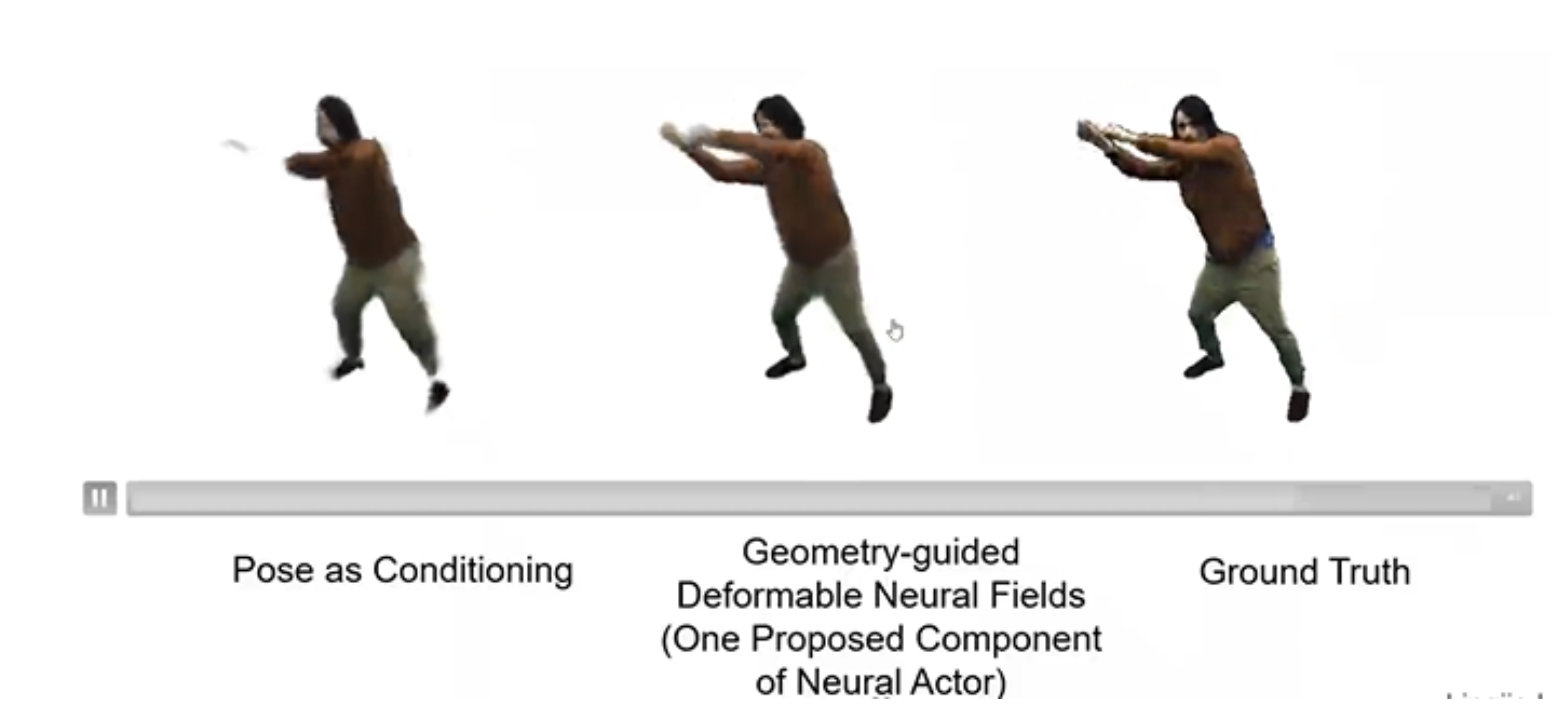
上图是中间是Neural Actor对于动态场景的渲染结果,他比最初的姿势控制效果好,但是还是缺少纹理特征。

上图是导致Neural Actor对动态场景渲染结果比较模糊的原因。因为每个姿势的渲染,都是基于几何和纹理的融合,但是由于表面复杂的动态学、姿势跟踪的错误和身体与衣服的摩擦导致对于姿势结构、动态几何和表面的绘制不是很清晰。
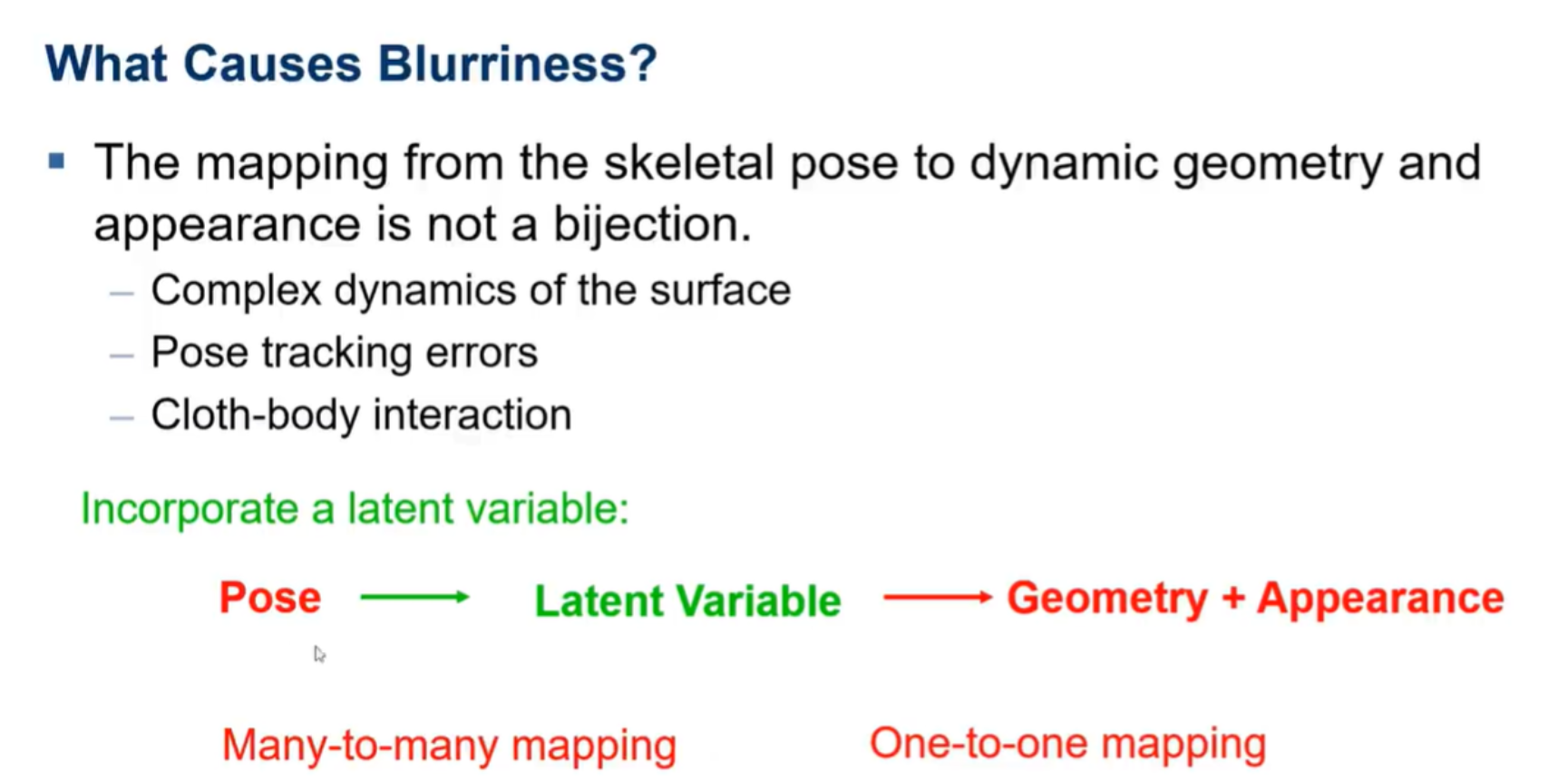
为了解决这些问题加入了潜在变量,姿势估计到潜在变量的多对多的绘制,潜在变量到几何+纹理是单对单的绘制,然后用nerf去学习后面的绘制。
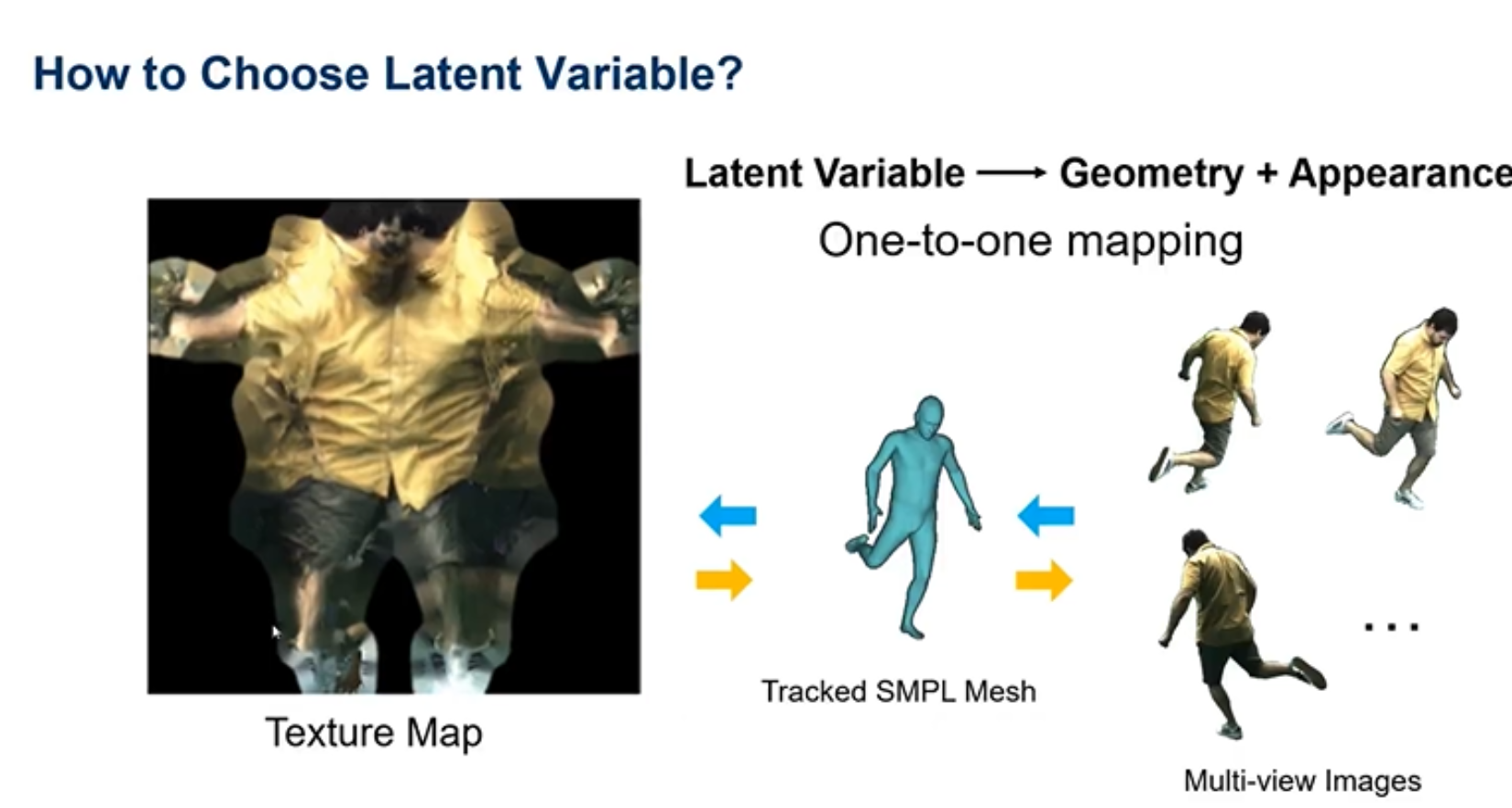
怎样选择一个潜在变量?这里有一个texture map就是一个潜在变量,它有一个好处就是可以保证后面潜在变量到几何+纹理是单对单的绘制。如上图multi-view images可以得到一个SMPL Mesh,进而得到一个texture map,相反将一个texture map粘贴到SMPL Mesh,就可以得到一个multi-view image。
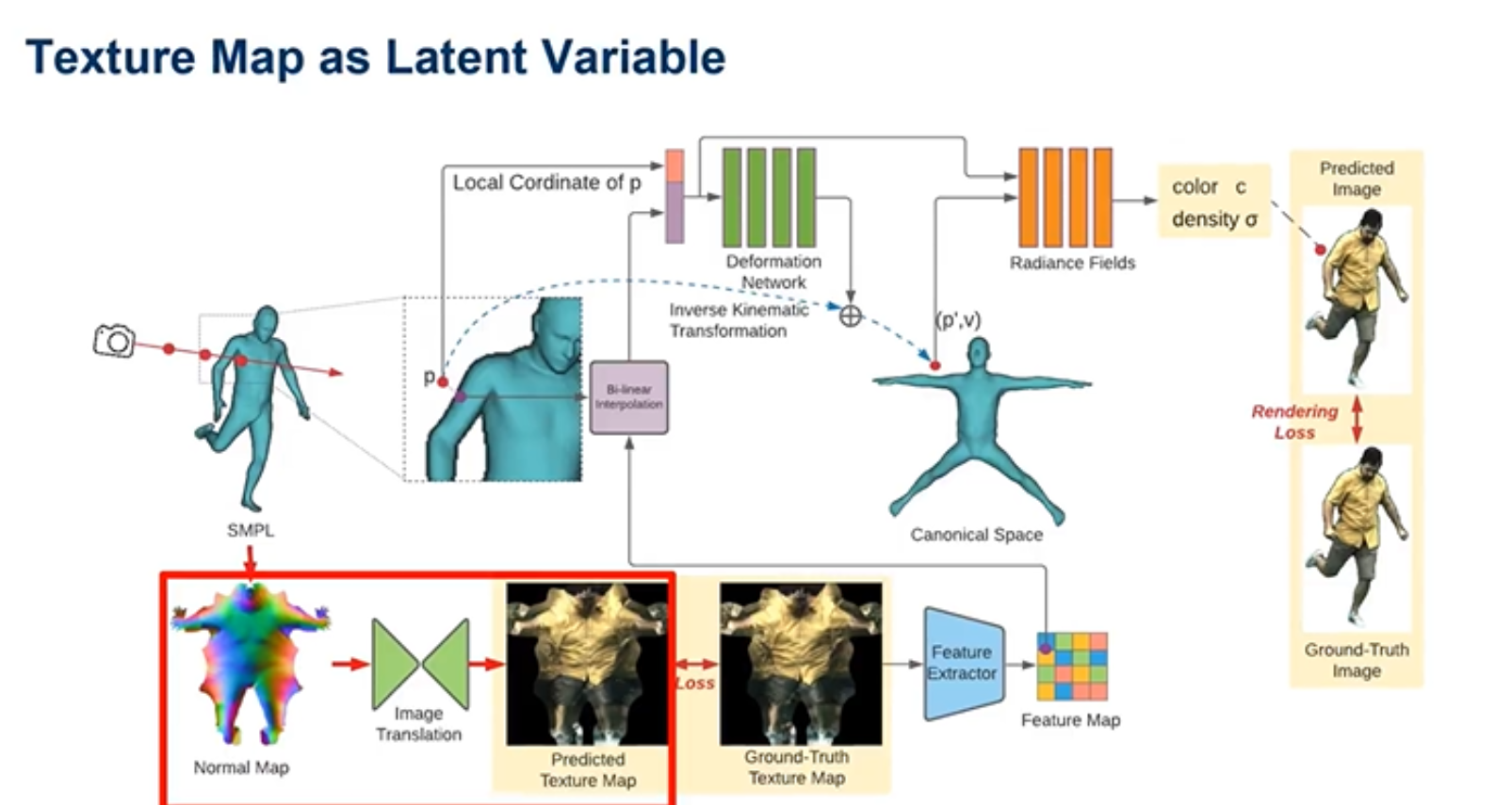
选择 texture map作为潜在变量,因为texture map富含许多纹理信息,另外对于pose到texture map过程中可以选择一些比较成熟的Image Translation的方法。

可以看到引入了texture map作为潜在变量后,Neural Actor重建的模型多了许多的纹理信息,越来越接近真实模型。

Neural Actor与许多较前沿的方法相比较,仍然有一个比较好的渲染效果。
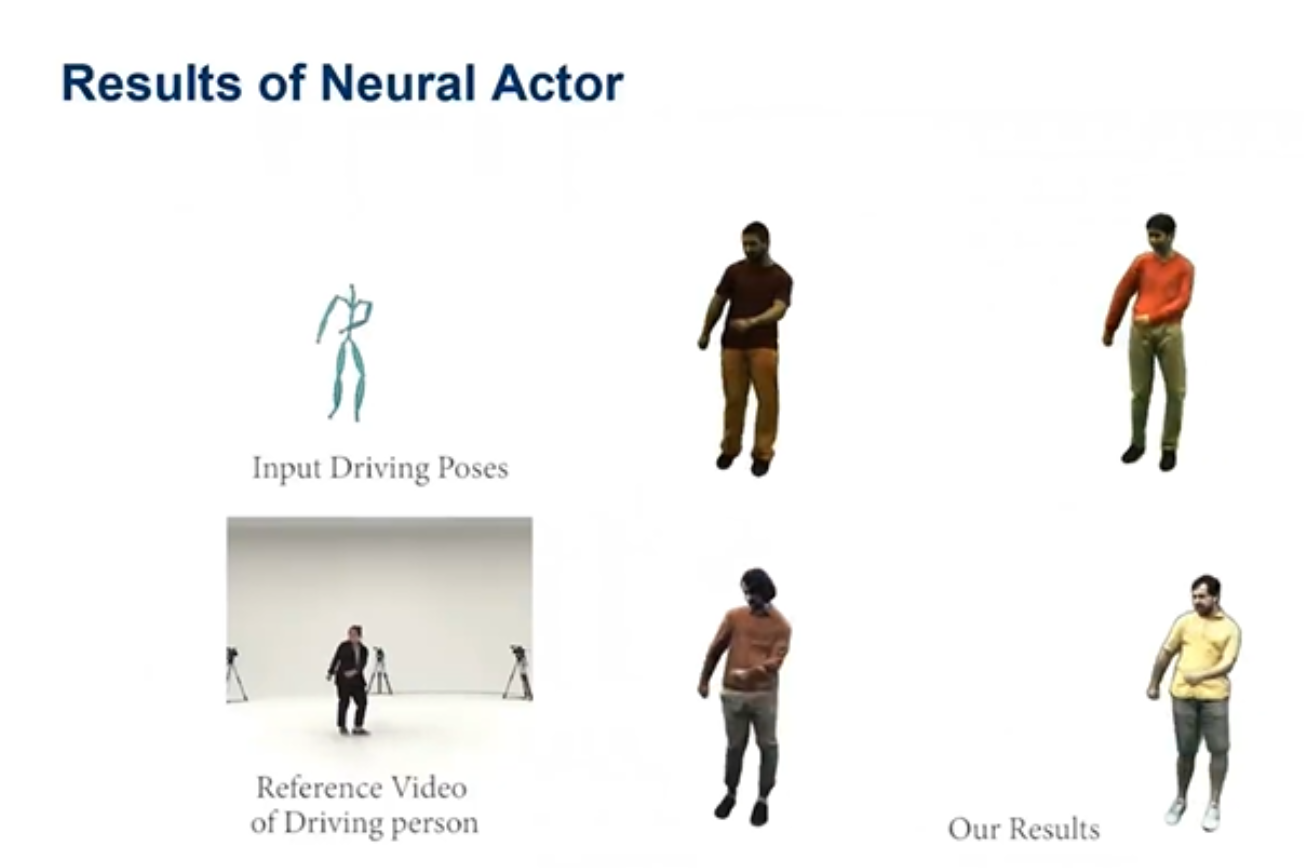
Neural Actor可以输入任何的姿势,进而去驱动序列产生一个较好的动画神经人类三维模型,并且有不同可以指定不同的动画人物。
2.4 Physics Informed Neural Fields针对于物理模型对于Nerf的改进

刚才的那些方法都是基于二维图片恢复三维场景,但是真实情况中,恢复的三维模型不仅仅要符合二维图片,还要符合现实中的物理模型。流线重建是在汽车模型当中非常常用的,用于检测每辆车的流线设计,但是在传统的图像学中进行流线重建是比较困难的,因为需要提前对光照进行一个设定。
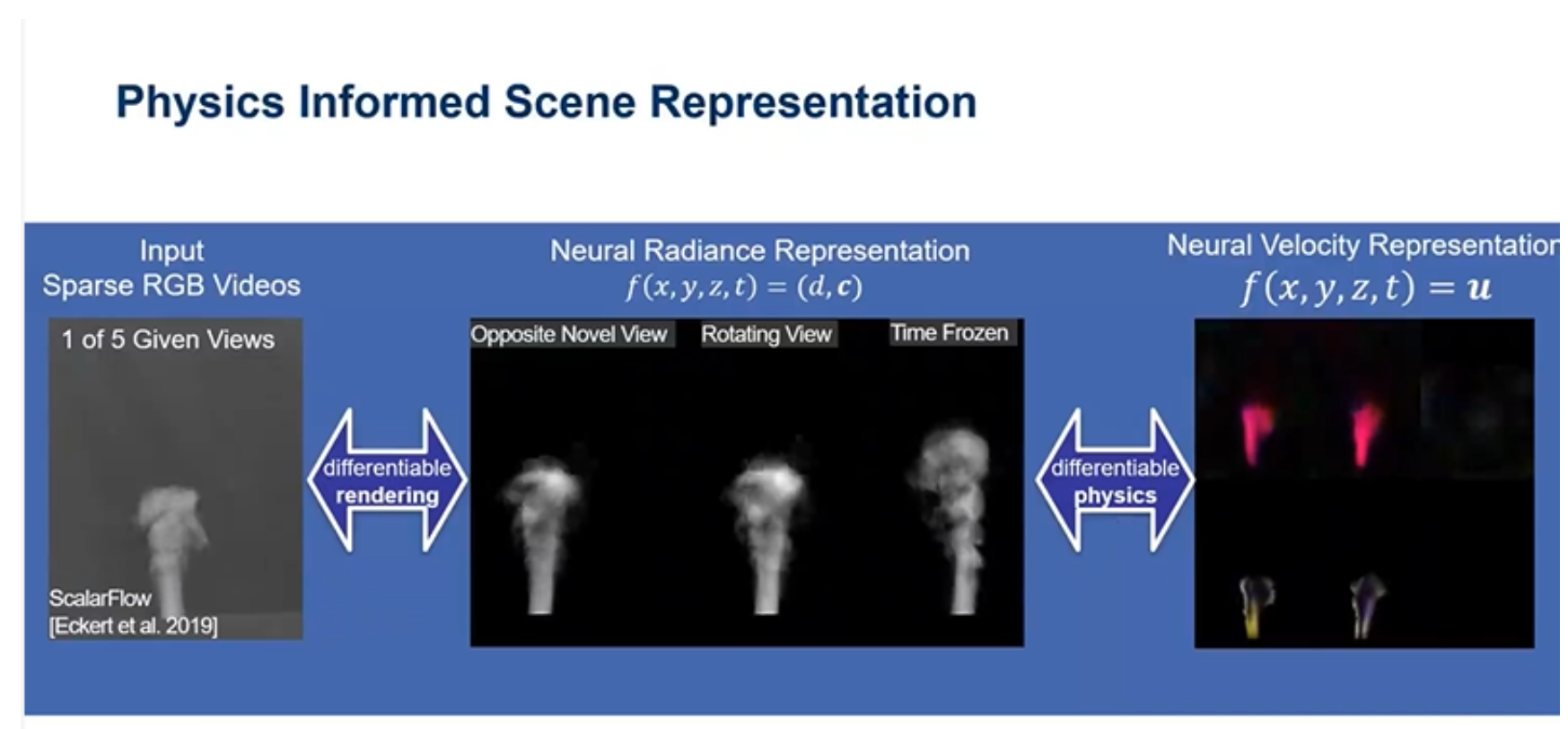
Neus,还包括其他一些技术都对烟雾进行了重建。上图对于烟雾进行了五个角度的拍摄,最后用neus生成的效果缺少物理结构,因此加入可微的物理模块进行重建。
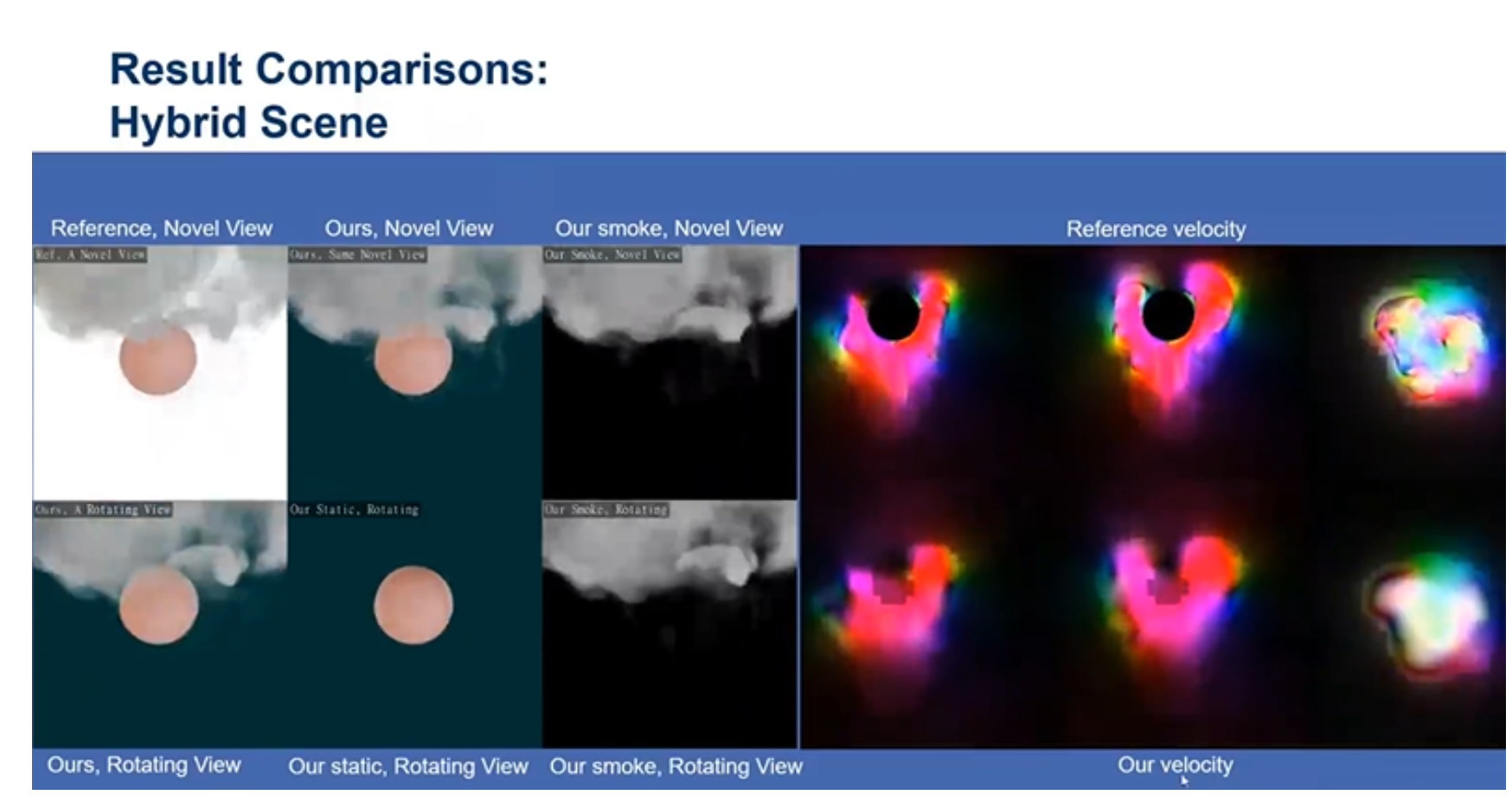
加入了物理模块之后就可以自动的分离球体和烟雾,并且这个模型是符合物理模型的,因此还能给出烟雾的速度等信息。
2.5 styleNerf针对于新三维场景生成对于Nerf的改进

新的三维场景重构需要看过很多的三维场景,从而才能有一个较好的场景预知能力。之前的方法都是利用多视角图片作为一个输入,但是在进行新的三维场景重构的时候并不需要一个多视角图片的输入 ,因为多视角的图片集是不长存在的,常存在的图片集是单视角的图片(未知相机信息,未知其他视角图片),那么新的三维场景重构就可通过单视角的图片进行场景重建。
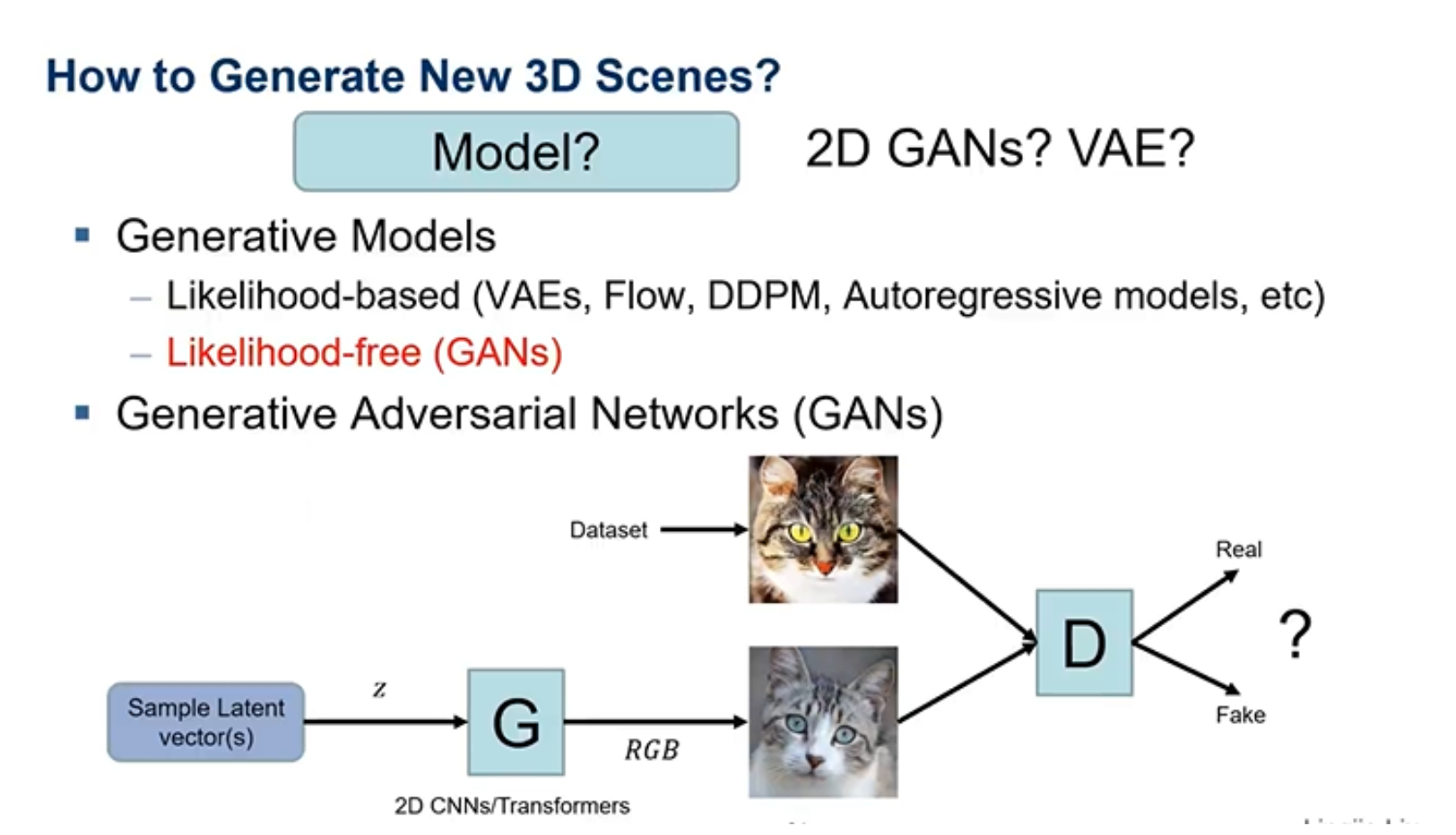
如何进行新三维场景的重构?这里有一些2D生成模型,其中生成对抗网络(GAN)是有一个生成器和辨别器,生成器生成一张图片,再拿一张数据库里面的图片让辨别器判断哪一张是生成的图片,哪一张是真实的图片,从而生成器和判别器都相互的不断优化。

但是这些二维模型生成器都是有缺点的,因为它生成的这些图片里面是不含任何三维信息的。上图是styleGAN2生成的二维图片,如果我们想要控制生成人像的胖瘦或者是观测其他视角就是不行的。

所以2022年就提出了一个styleNerf的模型,里面包括3D GANs,也就是三维模型生成的生成对抗网络。
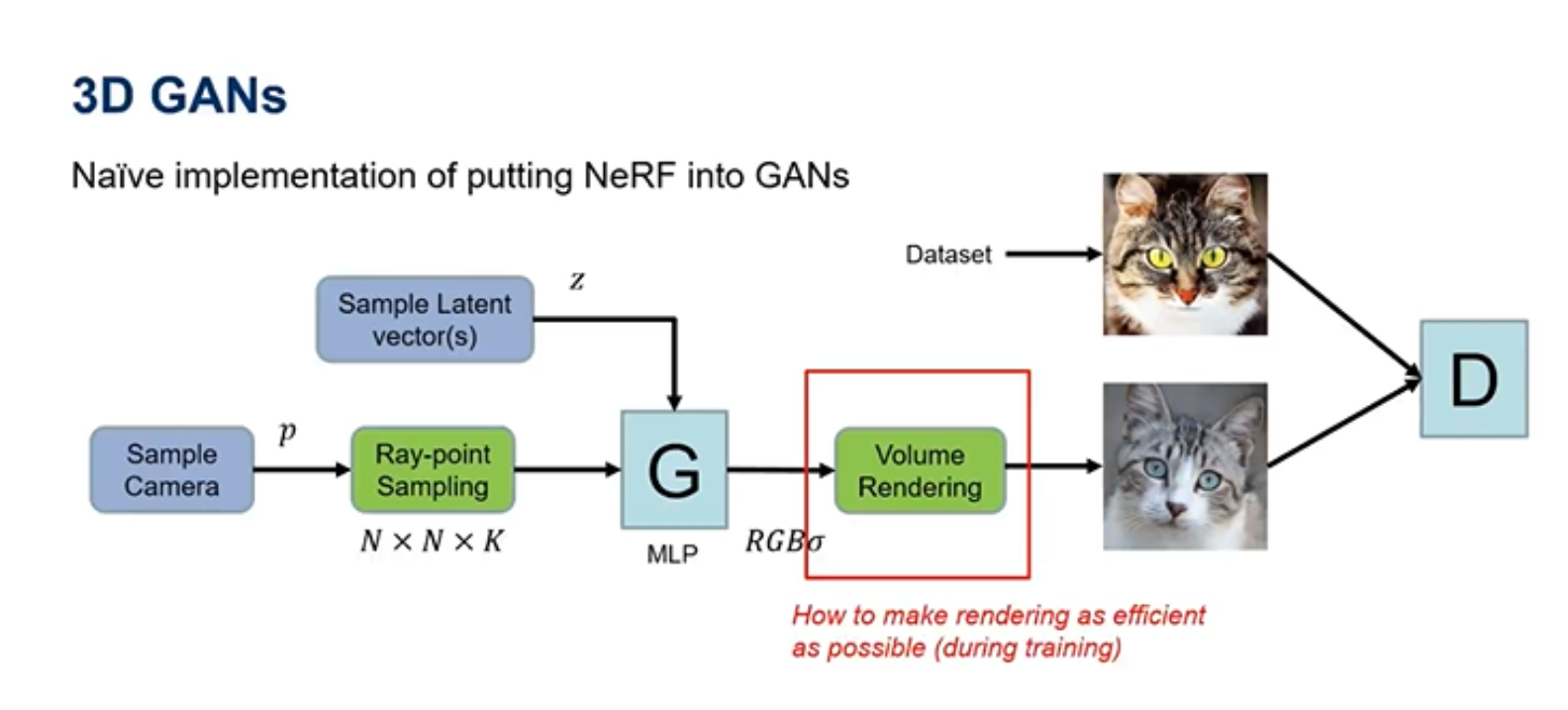

3D GANS可以学习相机的参数以及场景的一些信息进而进行体素渲染一张图片,但是体素渲染非常慢,虽然NSVF一直致力于加快Nerf的渲染速度,但是NSVF并不适用于生成对抗网络,因为GAN要求在训练过程中就渲染出一张图片。因而要进行改进,达到一个高质量渲染、高效渲染和多视角(三维)一致性的目的。
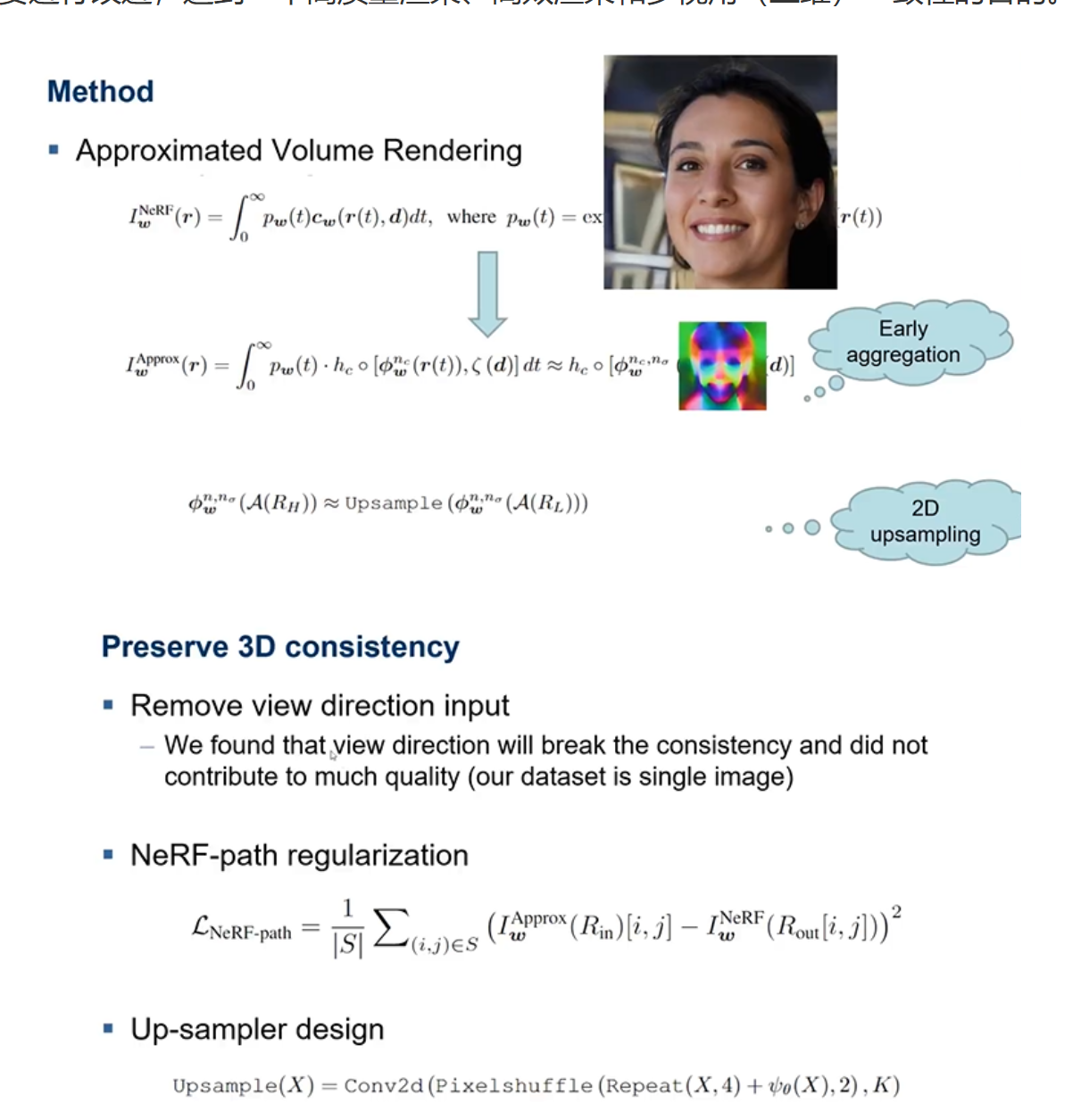
为了解决体素渲染慢的问题,提出了一个Approxiamted 体渲染,也就是先生成一张非常小的特征图,然后再通过upsampling进行扩大,这样渲染比较快,得到一个较大的图片,但是这样损害了三维的一致性,因为是在二维上进行扩大。因此为了保证三维的一致性,提出了三个建议,一是移除Nerf的图片的直接输入,二是通过通过Nerf生成一个较差的RGB,然后再通过upsampler进行扩大,最后将生出的模型于Nerf胜出的模型进行损失计算,进而对模型进行优化。

与之前的一些3D GANS相比,styleNerf当中的3D GANS效果比较好。

刘玲洁团队最开始提出的styleNerf当中的3D GANS能够对不同角度的新场景进行重建,后面还提出了GAN2X,可用于不同光照下场景的重建。
2.6 其他的Nerf改进
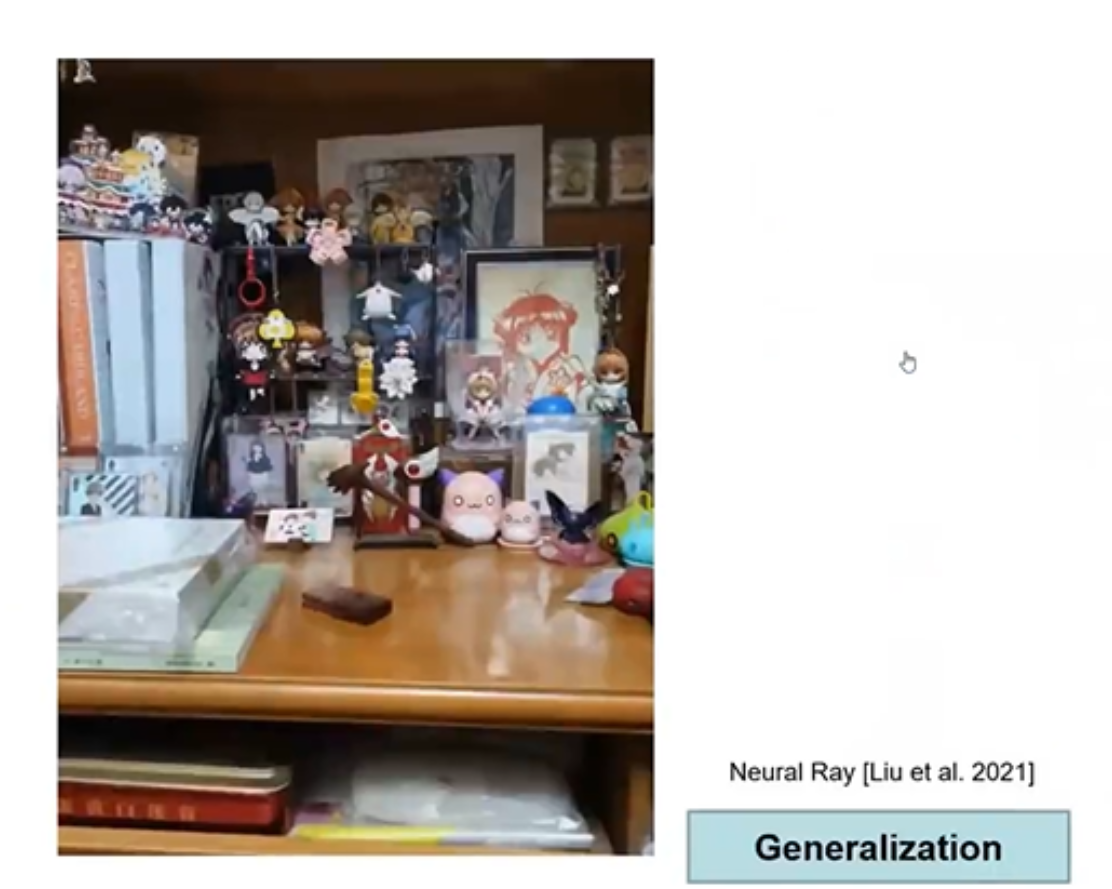
上图的Neural Ray模型是指这个模型已经在非常多的场景上训练过了,所以在一个新场景加入的时候,不用重新训练模型就可以进行重建。
3、Nerf领域未来发展前景
3.1 更加复杂场景的重建

之前的Nerf以及对于Nerf的改进,都是针对一静态场景,或者是单一的动态场景(如人体),但是现实生活中往往有更多复杂的场景,例如人与物的交互:人必须坐在凳子上,人必须站在地面上,总之就是人与物要有接触点。可以考虑引入一些物理的控制和环境控制来实现这样的交互问题。
3.2 三维模型生成器
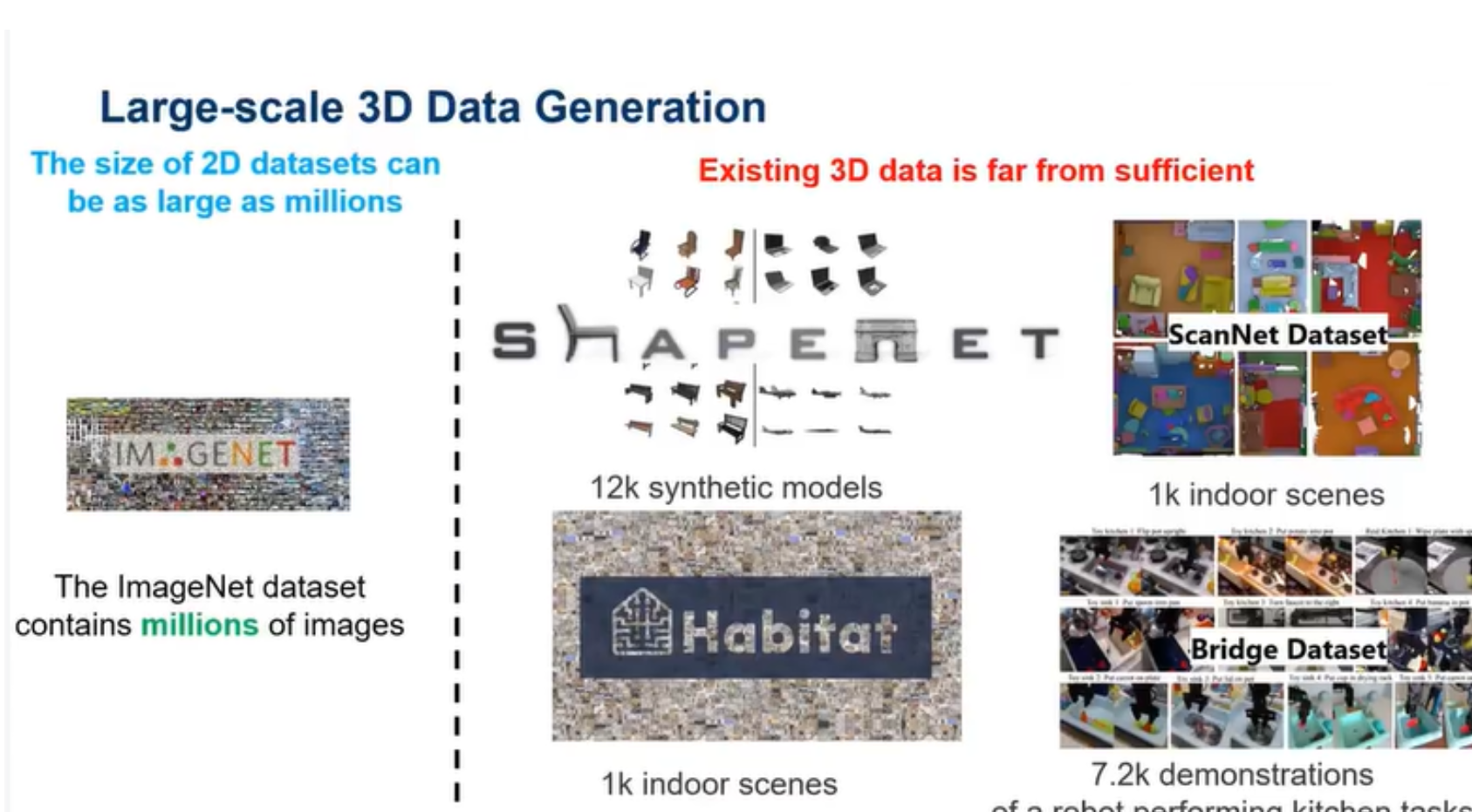
二维数据集很好获得,并且现在还有大量的二维数据集的生成模型。但是三维的数据就不那么好获得了。

现目前的一些三维数据生成模型都只能用在单一的数据集上,对于其他不一样的数据集缺少泛化能力。所以接下来希望做的工作就是,能够生成一个泛化能力比较强的三维数据生成器。
3.3 多模式学习
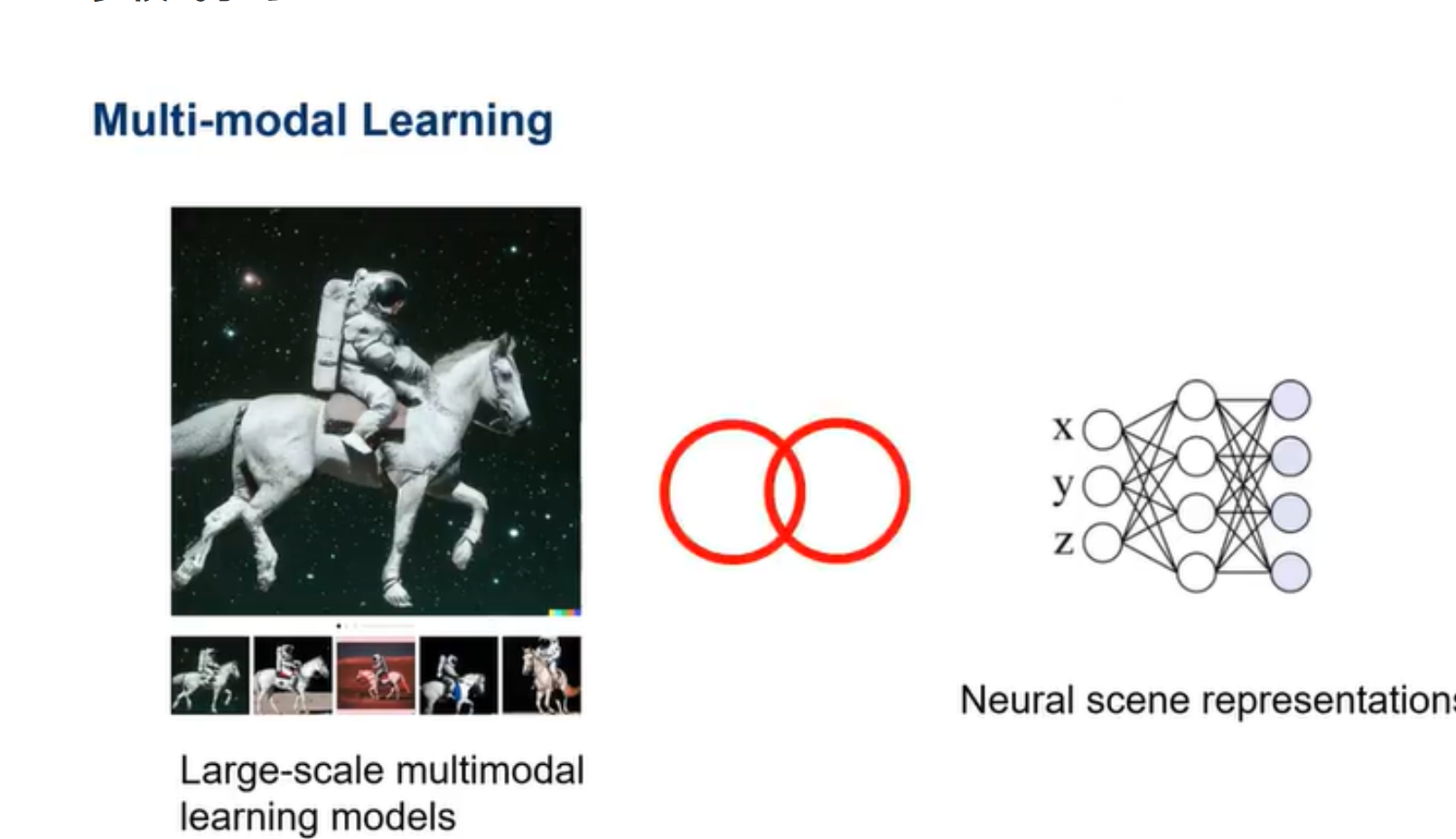
将大规模的多模式学习模型与神经场景表示相结合。
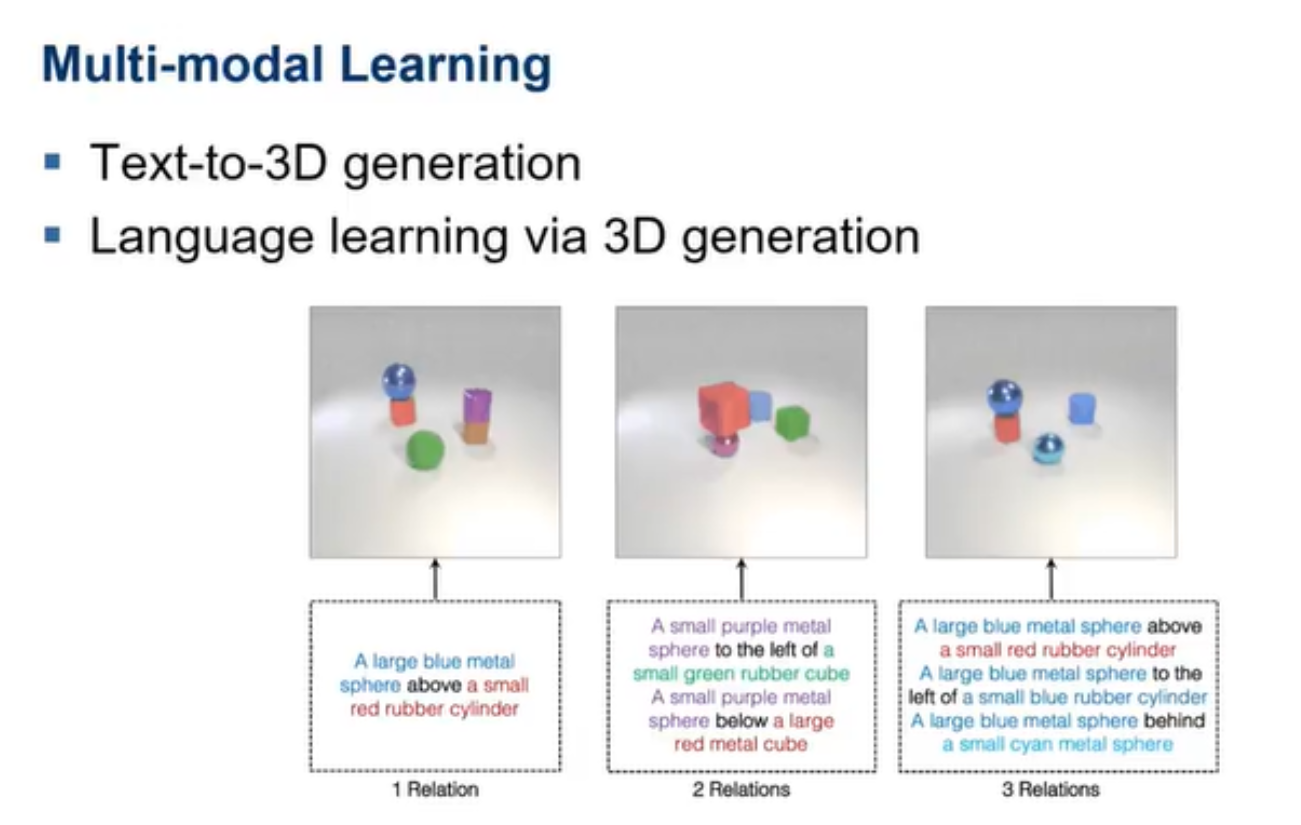
这种结合之后的模型可以针对于文本直接重建出一个三维模型。
3.4 更多的应用

神经场表示和渲染技术除了可以处理计算机图片,我们还希望它能够有其他的应用,比如机器人。机器人抓取物体的时候,就是通过二维图片进行三维场景的构建,从而获取抓取物体的边缘。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 18
18 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)