pandas在深度学习中对文件常见的预处理操作
如图所示我们有三个文件,train.csv为训练数据,test.csv为测试数据,sample_submission.csv为最后应该输出的格式样例。而通常测试集与训练机数据格式相同,因此我们先查看train.csv的数据规模print(data_train_raw.head())# head()默认可输出数据的前5行及其数据规模print(data_train_raw.shape)#输出数据整体
在进行回归任务处理的时候我们经常会遇到预处理csv文件的操作,下面以kaggle中的California House Prices中的Data为例,对常用的pandas预处理操作进行汇总。
目录
1 预处理示例的介绍
如图所示我们有三个文件,train.csv为训练数据,test.csv为测试数据,sample_submission.csv为最后应该输出的格式样例。而通常测试集与训练机数据格式相同,因此我们先查看train.csv的数据规模
import pandas as pd
data_train_raw=pd.read_csv('p15_california/california_house_prices/train.csv')
print(data_train_raw.head())# head()默认可输出数据的前5行及其数据规模
print(data_train_raw.shape)#输出数据整体大小 结果如图所示,训练数据大小为47439行*41列。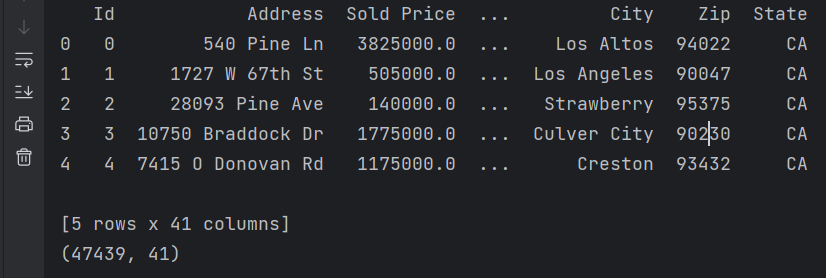
可以看到输入的数据既有object类型,float,int类型。而进行模型训练时,需要的往往只是浮点型数据。因此我们要对数据进行预处理。处理操作包括但不限于:文件的读取与写入,删除不需要的列,逐列遍历(以列为单位进行操作),查看列的数据类型,归一化处理,one-hot编码等...
2 预处理示例
2.1 文件读取
data_train_raw=pd.read_csv('./california_house_prices/train.csv')
data_test_raw=pd.read_csv('./california_house_prices/test.csv')文件读取后会以DataFrame的类型暂存在内存中
2.2 删除指定整列
删除整列使用.drop()方法,通常数据中的'Id'字段为冗余数据,将需要删除的列名传给参数columns,columns可接受str型列表。
data_train=data_train_raw.drop(columns=['Id','Sold Price'])
data_test=data_test_raw.drop(columns='Id')
print('初试训练数据大小为{},测试数据大小为{}'.format(data_train.shape,data_test.shape))输出结果为:“初试训练数据大小为(47439, 39),测试数据大小为(31626, 39)”
2.3 两个表的上下合并操作
为了方便我们后续处理数据,可先将两个表合并成一张表,上述列删除后,train和test数据列数相同。因此使用pd.concat进行合并操作,其中参数objs可接收一个DataFrame序列,axis参数可指定按哪个轴的方向拼接,axis=0表示按行左右方向拼接,axis=1表示按列上下方向拼接。
data_all=pd.concat([data_train,data_test],axis=0)
print('数据合并后:',data_all.shape)输出结果为:“数据合并后: (79065, 39)”
2.4 筛选出无关字符列
训练数据中往往存在着许多非实数类型的列,如果我们直接对其进行one-hot编码,则可能导致内存爆炸,因此我们需要筛选出所有非实数列中,不同数值过多的列,并对其进行删除。
关键方法DataFrame.value_counts(),调用此方法会返回当前列中的所有数据的数量分布,形如 数据值:出现次数。 对DataFrame类型进行遍历会返回逐个列的列名,因此我们以列名name为索引遍历所有列。并找出列中不同数值的个数大于300的列
col_drop=[]
for name in data_all:
category=len(data_all[name].value_counts())
if data_all[name].dtype==object and category>300:
col_drop.append(name)
#inplace=True表示直接在原DataFrame进行操作而非开辟新空间
data_all.drop(columns=col_drop,inplace=True)
print("删除冗余非数字列后大小为",data_all.shape)输出结果为:“删除冗余非数字列后 大小为(79065, 21)”
2.5 空值的位置填0
我们要筛选出所有非obkject列的索引,代码如下
num_index=data_all.dtypes[data_all.dtypes!='object'].index
data_all[num_index]=data_all[num_index].fillna(0)其中data_all.dtypes!='object'可返回一个bool型列表。长度为data_all的列的个数。data_all.types用于返回当前DataFrame所有列的数据类型。.index用于返回所有列的数据类型的索引
2.6 归一化处理
训练数据的不同列的值范围不同,因此可对每列进行归一化处理以使训练更加稳定。DataFrame.apply()方法可对DataFrame中的数据进行处理,其中参数func可写入lambda表达式。
data_all[num_index]=data_all[num_index].apply(lambda x:(x-x.mean())/x.std())
2.7 对非数值进行One-Hot编码
pd.get_dummies可对数据进行one-hot编码,其中dummy_na=True表示设立空字段(当数据中其中一列中有值为nan的时候才有意义),dtype=float表明指定编码后的格式为float
data_after=pd.get_dummies(data_all,dummy_na=True,dtype=float)
print('one-hot编码后大小为:',data_after.shape)输出结果为:“one-hot编码后大小为: (79065, 474)”
注意将最后预处理好的数据写入tensor时,需使用DataFrame.values()将数据拿出来,例如
labels=data_train_raw['Sold Price'].values2.8 预测结果写入csv文件
假设我们要生成的csv格式如图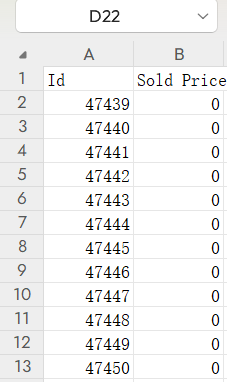 格式,需要将预测结果以及Id写入csv文件。需要用到DataFrame.insert()方法和DataFrame.to_csv()方法。其中value参数可接收列表或numpy数组等数据。假设这里我们已经有了Id和res的数据。
格式,需要将预测结果以及Id写入csv文件。需要用到DataFrame.insert()方法和DataFrame.to_csv()方法。其中value参数可接收列表或numpy数组等数据。假设这里我们已经有了Id和res的数据。
df=pd.DataFrame()#创建一个空的DataFrame
df.insert(loc=0,column='Id',value=Id)
df.insert(loc=1,column='Sold Price',value=res)
#写入csv文件
df.to_csv('res.csv',index=False)#这里推荐index写成False,否则生成的csv文件第0列会默认插入从0开始的索引
insert方法可直接插入一整列。参数loc表明插入的位置,其索引用整形表示,colum表明要插入的列名,value填入要插入的数据。
注意用此方法插入数据时,要保证插入数据的维度相同(即行数相同),否则会报错。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐

 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)