MVSNet代码详解
导入软件包。import os......#自定义模块#定义了一个常量DEFAULT_PADDING,其值为SAME,SAME是深度学习中常用的填充方法,特别是在卷积神经网络中,它用于在输入图像边缘周围添加适当的零值,使得输入的特征图和输出的特征图大小一样。定义函数layer,该函数用于为网络层创建统一的接口,以便构建组合式的网络结构。里面还定义了一个内置函数layer_decorated,是函数
1 算法的宏观把握
-
输入:一些已知相机内参、外参的图片(往往这时候已经用colmap做过一遍sfm,从而获取到了相机的内参和外参)。
-
过程:1)把图片重新分组,1张参考图+2张源图为一组,源图是参考图的辅助,最终输出的深度图对应参考图;2)将源图在不同深度下单应性变换(homography)到参考图上,理论上,对于某一个像素来说,如果深度正确(其中一个深度),不同图像(不同特征体)上的像素值是相同的 3)相当于就能看到场景中同一点在不同图像上的像素坐标对应关系,从而解算出每一点的深度 。
-
输出:参考图的深度图,除了rgb三个维度之外,还加入了第四维的depth(深度)信息。
2 从论文角度理解算法
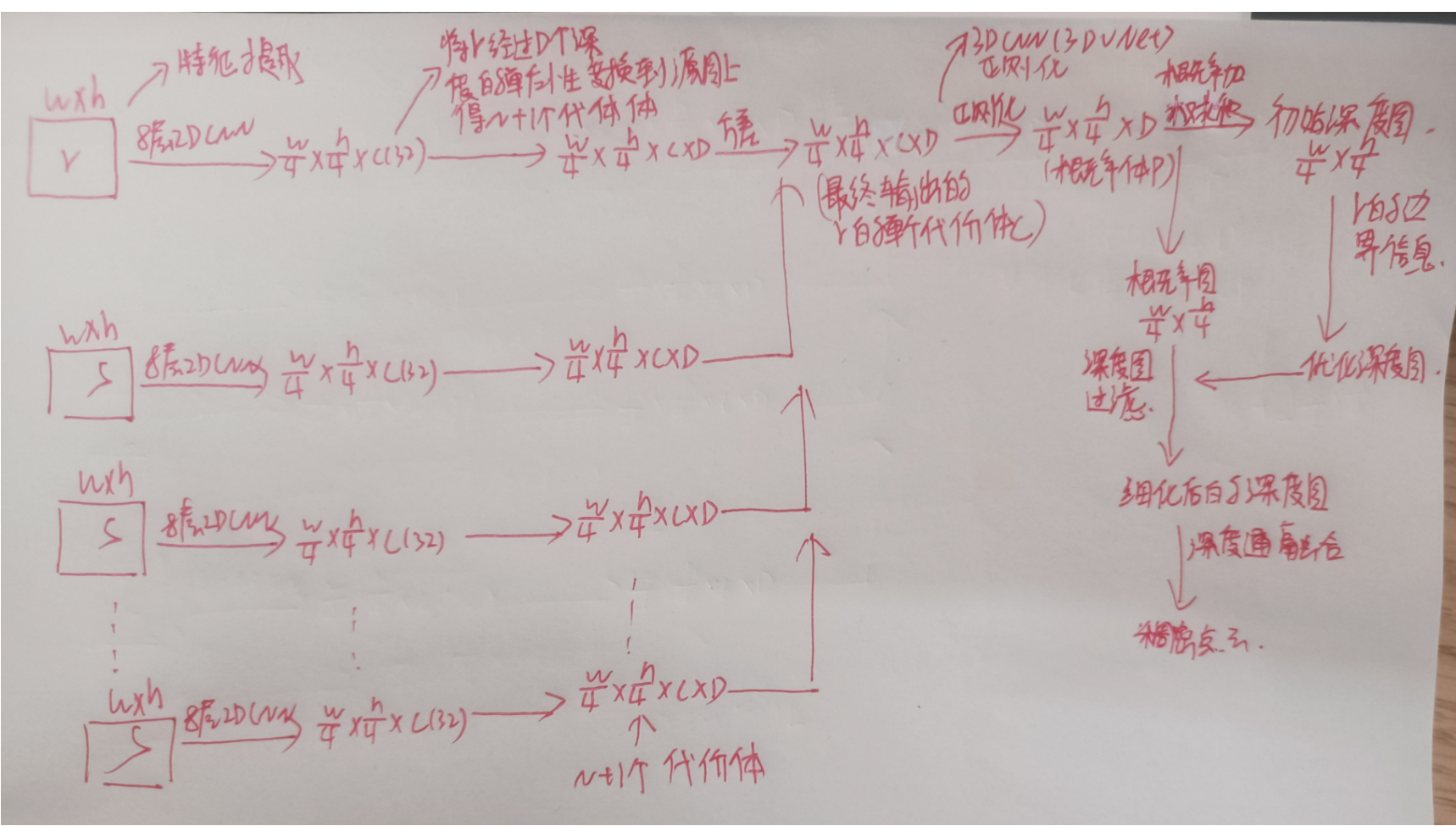
2.1 训练数据处理
数据准备:使用dtu数据集,因为其GT(Ground Truth数据)为点云或网格格式,采用SPSR(筛选的泊松表面重建)+网格渲染将原GT转化为深度图GT。
视图的选择:①每个原图像分别与参考图像计算得分,取得分高的前N张图像作为网络输入原图像;②同时缩小图像尺寸至800×600,然后从中心裁剪W=640、H=512的图像块作为训练输入,输入的相机参数会相应地更改;③深度假设:[425,935]mm均匀取样,分辨率为2mm(D=256)或[425,902.5],分辨率为2.5mm(D=192)。
2.2 特征提取(提取特征点,以便用单应性变换构建代价体)
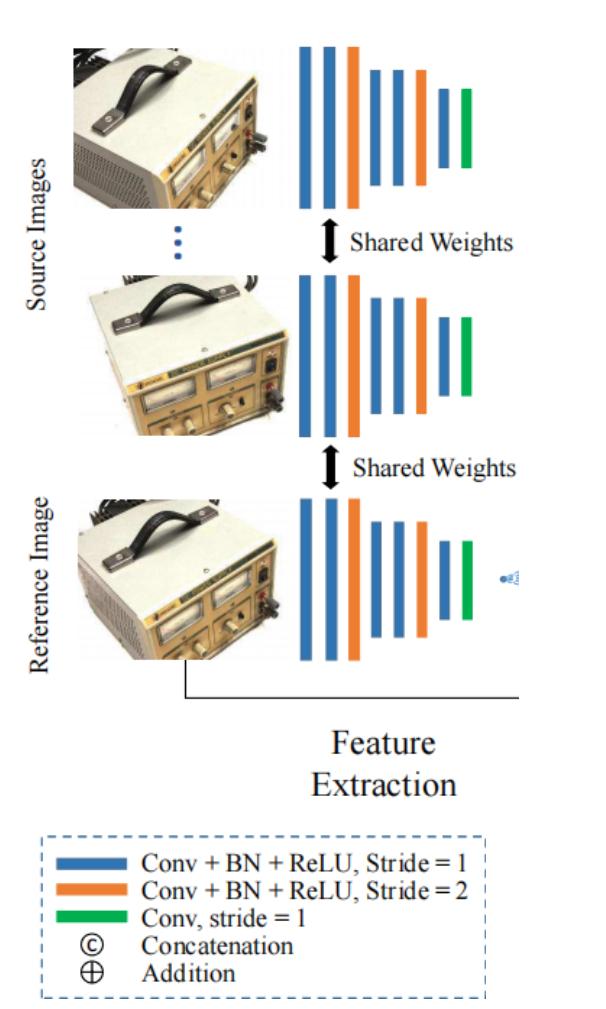
目标:8层2DCNN提取每幅输入图像的特征,输入1个参考图像+N个原图像,输出N+1个32通道的特征图。 ①参数共享:与常见的匹配任务类似,参数在所有特征图间共享,即对所有视角的输入图像,用同一网络提取特征。 ②每个输入图像输出一个1/4原尺寸,32通道的特征图。 由于在这里图片尺寸变为了原来的1/4。那么相应的相机内参也应该缩小为1/4,变成K/4。(图片等比例的改变大小,必须要同时调整内参,这样才能够保证相对应关系)
③上图是MVSNet工作流程图的第一步特征提取,可见是采用的8层的卷积神经网络进行特征提取.
2.3 构建代价体(构建源图和参考图之间的多个代价体)
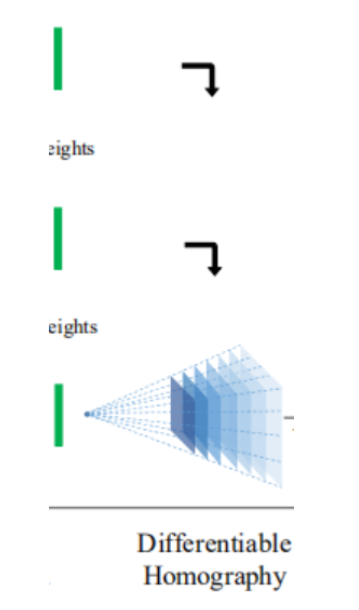
目标:将所有特征图变换到参考相机的锥形立体空间,形成N个代价体Vi。
①四维空间:这里的空间是四维的,首先对四维空间有一个抽象的认知:三维空间是一本书,书页的大小用长W和宽H来表示,书的每一页是一个Channel(通道),W、H、Channel三个维度构成了三维空间。四维空间是一摞书,每一本书构成第四个维度,用Depth(深度)来表示。
②在这里,使用单应性矩阵对每个特征图进行变换得到代价体
-
首先,每个特征图Fi对应D(深度采样数)个单应性矩阵,把每张特征图看成一本书,那么每个深度经单应性变换得到一本书,D个深度,会得到一摞书,书有D本。
-
变换过程:已知参考视角的内外参数矩阵,深度信息,可以计算参考视角像素坐标的世界坐标系值,即将其投影到世界坐标系。再通过已知的源视角内外参数矩阵,可以投影到源视角的相机坐标系,归一化后得到源视角的像素坐标。从参考视角到去找源视角的像素坐标对应点的计算过程,可以用单应性矩阵来描述。这里的单应性变换是可微的,即可以实现反向传播,进行端到端训练(单应性变换只负责找对应点,实际的梯度计算和矩阵无关,是沿特征图反向传播的)。最终,将在源视角对应点的特征(通道维度的所有数据)存放在参考视角的像素位置处完成变换。
-
最终,得到N+1摞书,每个特征图得到了一摞书,每一摞书是一个代价体,每本书代表一个深度,每本书的每一页代表一个通道,每本书的通道数相同,都为32(原特征图的通道数)。
2.4 代价空间(利用方差将多个代价体计算为参考图的单个代价体)
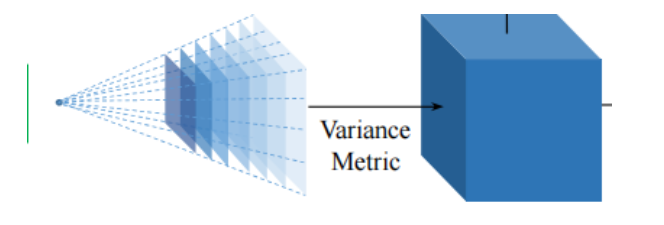
上图的个人理解:对输入的r img以及s img经过8层2D的CNN特征提取后,得到特征图
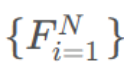
(F1 表示r img的对应的特征图,其余表示s img的特征图)。它们的维度是相同的,但是经过经过Homography变换之后,把s img的特征图,映射到r img的特征图对应的锥形立体空间之后,由于深度不一样,形成上面的锥形(长宽也不一样)。然后对锥形的每个特征图进行线性插值,让他们长宽相同。这里是一个比较重要的过程,因为这里完成的2D到3D的转换,让3D端到端的训练成为了可能。
N+1个特征图,得到N+1摞书(N+1个代价体),这里实际上已经5维了,下一步计算将这N+1个代价体在同一空间位置的相似性进行代价度量,得到代价空间(最终参考图的代价体),降回4维。
目标:将N+1个代价体聚合为一个统一的代价空间C(将N+1摞书合并为一摞书)。C.shape:(D,W,H,F),D、W、H、F为深度采样数、输入图像的宽度,高度的1/4和特征图的通道数。
①理论:如果假设深度接近实际深度值,那么找到的对应点更准确,所有代价体在同一位置的特征相似性高,反之相似性低。即特征对应点的相似性度量可以判断深度假设接近实际深度值的程度。方差反映了一组数据的波动情况,即数据越相似,方差越小,是一个反比关系。
②实现过程:N+1个特征体是重叠在同一空间位置的,对同一空间位置的点计算方差。比如说,将每摞书第一页左上角的点都取出来,然后计算方差,得到输出的那摞书的第一页左上角的点。对每个空间点都进行这样的计算,得到输出的一摞书,即最终的代价空间。
③输出:现在代价空间(最终参考图的代价体)是一摞页面大小相同的书,同样,页面大小为W、H,每一页代表一个通道,每一本代表一个深度。由于最后我们只需要参考图的代价体,但是在单应性变换过程中,每个源图和参考图之间都得到了一个代价体,因此有N个代价体,所以需要计算这N个代价体的方差作为最后输出的参考图代价体。
④方差公式如下:
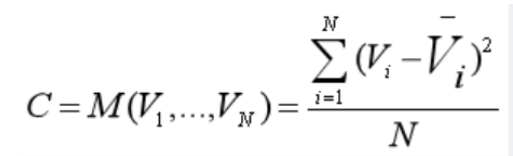

2.5 代价空间正则化(为了去除代价体中的噪声,正则化代价体得到概率体)
目标:根据代价空间C得到概率空间P(将一摞书合并为一本书)。
①在这一步做了三件事:
-
通过三维卷积对代价空间正则化,即将深度的取值集中起来,尽可能变成单峰分布。
-
三维卷积的最后将通道降为1,也就是把每本书都变成一页纸,一张纸代表一个深度。这个时候可以把这些纸按序纸合并为一本书(W,H,D),页面大小为(W,H),页数为D,这就是最终的代价空间,对于书页((W,H)平面)上的每一个点,若它在第三页的值最小,那么这个点的深度就为第三页的取值(例如,[425,935]mm均匀取样,分辨率为2mm(D=256),那么第三页的深度为425+3x2=431mm)。
-
沿页数方向用softmax进行归一化,即对于(W,H)平面上的每个点,沿D方向的概率合为1,这便得到最终的概率空间P.
②网络:类似于3D-UNet,使用编码器-解码器结构,以相对较低的内存和计算成本,从一个大的感受野聚集相邻的信息。为了进一步减少内存的消耗,在第一个3D卷积之后我们把32通道的cost volume减少到8个通道,并且在第2层和第3层缩小得图片的尺寸。最后的3D卷积层输出一个单通道的volume。
③简单说一下三维卷积和二维卷积的区别:
-
二维卷积:一般的二维卷积核有三个维度,窗口大小(h,w)和与输入特征图相同的通道数c,每次卷积得到的是单通道图,即输入特征图为(B,C,H,W)时,输出特征图为(B,1,H,W),用卷积核数量控制输出通道数。(将卷积核数量也看作一个维度时,是4个维度)。
-
三维卷积:卷积核有四个维度,窗口大小(h,w),与输入特征图相同的通道数c,在depth维度的取值d,每次卷积所有通道参与,部分深度参与(取决于d的值)。若输入特征维度为(B,C,D,H,W),输出维度为(B,1,D,H,W)(深度维度的步长是1,有填充时),同样用卷积核数量控制输出的通道数。
2.6 概率图(从概率空间计算得到概率图,概率图中保存着估计的每个点的深度是真实深度的概率值)
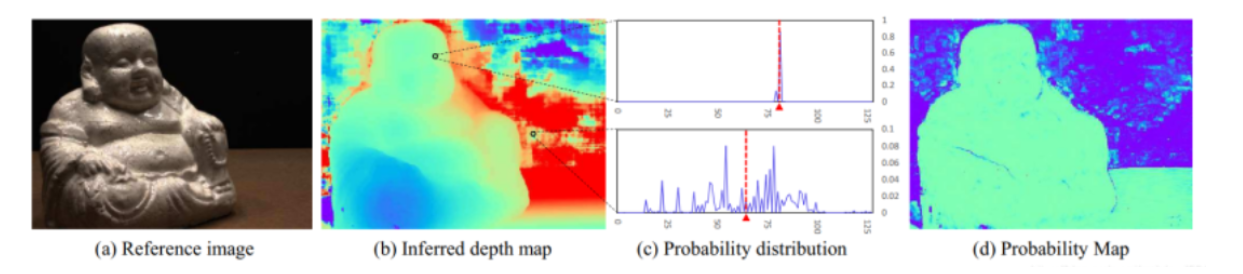
目标:由概率空间P获取深度质量的估计d(也是一张纸(W,H,1)),对深度图进行过滤。 ①深度估计的质量d:估计值在真实值附近一个小范围的概率。 ②计算方式:对概率空间,沿深度维度计算每四个邻域的概率和,再沿深度维度取最大的概率和。
③概率图:每个点的值表示该位置深度估计的有效性,概率越高,越可能为正确的深度估计(或该点的深度估计有效,不是背景等)。
2.7 深度图初始估计(利用概率图计算初始深度图)
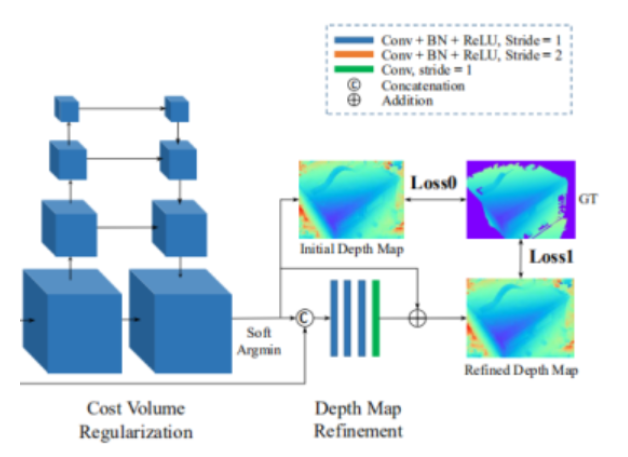
目标:从概率空间P中获取深度图(将一本书变成一页纸,(W,H,1))。
①方法:对(W,H)平面每个点,沿书页D方向计算期望,期望值即为该点的深度估计。公式如下图:
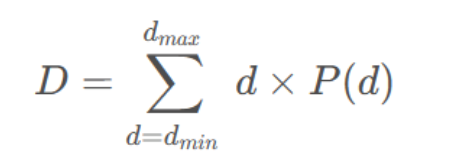
②使用期望的优势: 1.相比于argmax,过程可微 2.可以产生连续的深度估计
2.8 优化深度图(初始深度图是从概率体中得到的,但是概率体经过了正则化,一些边界信息被平滑掉了,因此需要参考图的边界信息优化深度图)
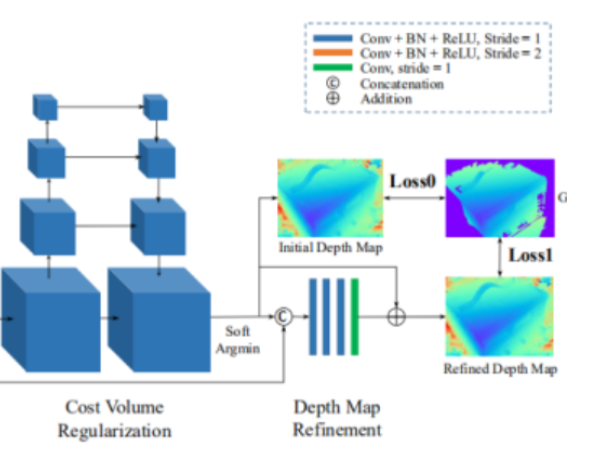
目标:利用参考图像的边界信息优化深度图。原始图像和原始深度叠加在一起,然后过卷积层,转换一下特征空间,形成深度图的残差。这时候再和初始深度图加一起,形成了最终的优化后深度图。
具体做法: ①将参考图像(RGB3通道)缩小1/4,使其和初始深度图尺寸相同(W,H,3)。同时,将深度图(W,H,1)归一化[0,1](减最小值再除以(最大值减最小值)),防止在某个深度比例上产生偏差。将处理过的两个图进行通道拼接(W,H,4) ②将拼接后的4通道图像放入 4层残差结构的卷积网络进行信息融合 ③将残差网络输出的单通道特征图(W,H,1)还原到深度假设的区间(与归一化过程相逆),将其与初始深度图逐元素相加,由此得到优化后的深度图。
2.9 损失计算
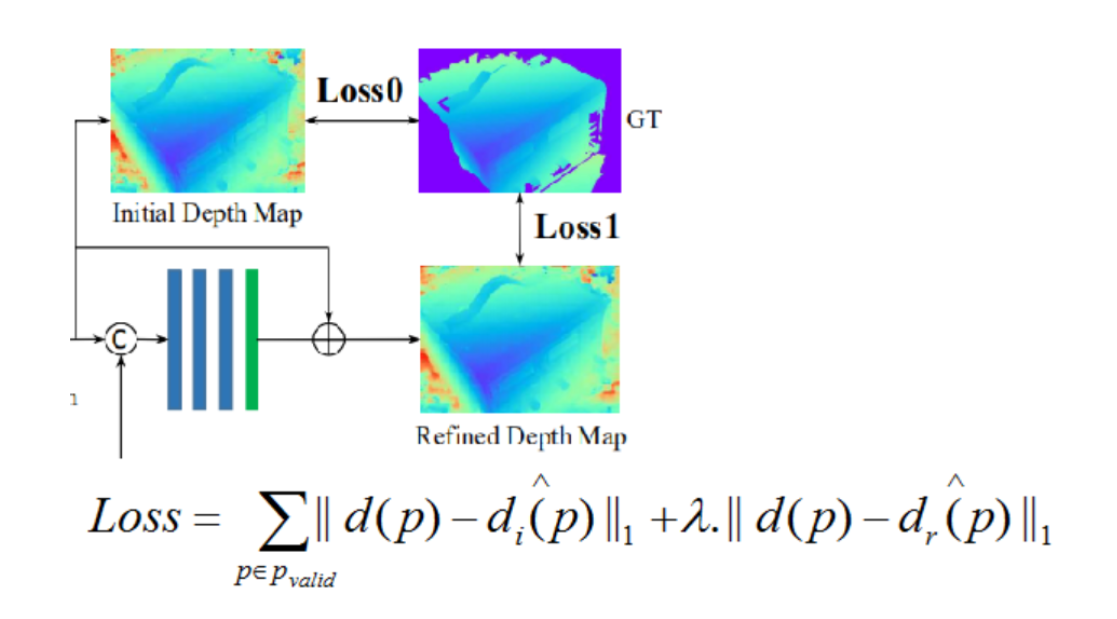
①使用L1损失,分别对初始深度图和优化深度图进行损失计算,再以权重系数λ相加,λ一般设置为1.0。 ②只考虑GT(真实地图标签)中有深度信息的像素点(除过图中蓝色背景的区域)。
2.10 后处理
①深度图过滤(对优化后的深度图进一步过滤,减少遮挡光照等影响):1.光度一致性度量匹配质量。用网络得到概率图来衡量深度估计的质量。在实验中,将概率低于0.8的像素视为漏光像素。2.几何约束度量多个视图之间的深度一致性,类似于立体图像的左右视差检查。
②深度图融合(深度图融合的意思就是将深度图采用一种可见的融合算法投射到空间中去,形成稠密点云):将不同视点的深度图融合到统一的点云表示中,使用基于可见性的融合算法,把遮挡,光照等影响降到了最低,使得不同视点之间的深度遮挡和冲突最小化。为了进一步抑制重建噪声,在滤波步骤中确定每个像素的可见视图,并将所有重投影深度的平均值作为像素的最终深度估计。融合后的深度图直接投影到空间,生成三维点云。
3 代码阅读
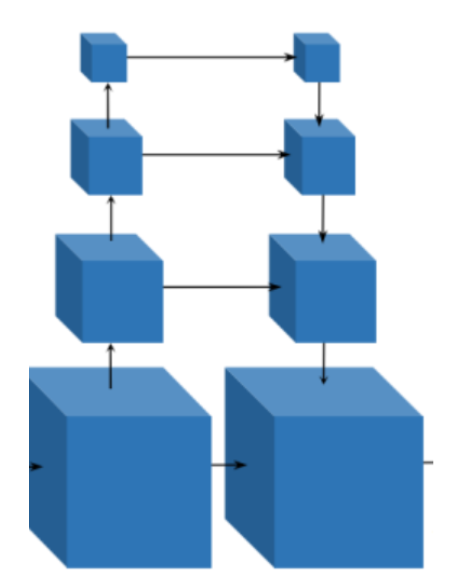
3.1 代码的宏观组成
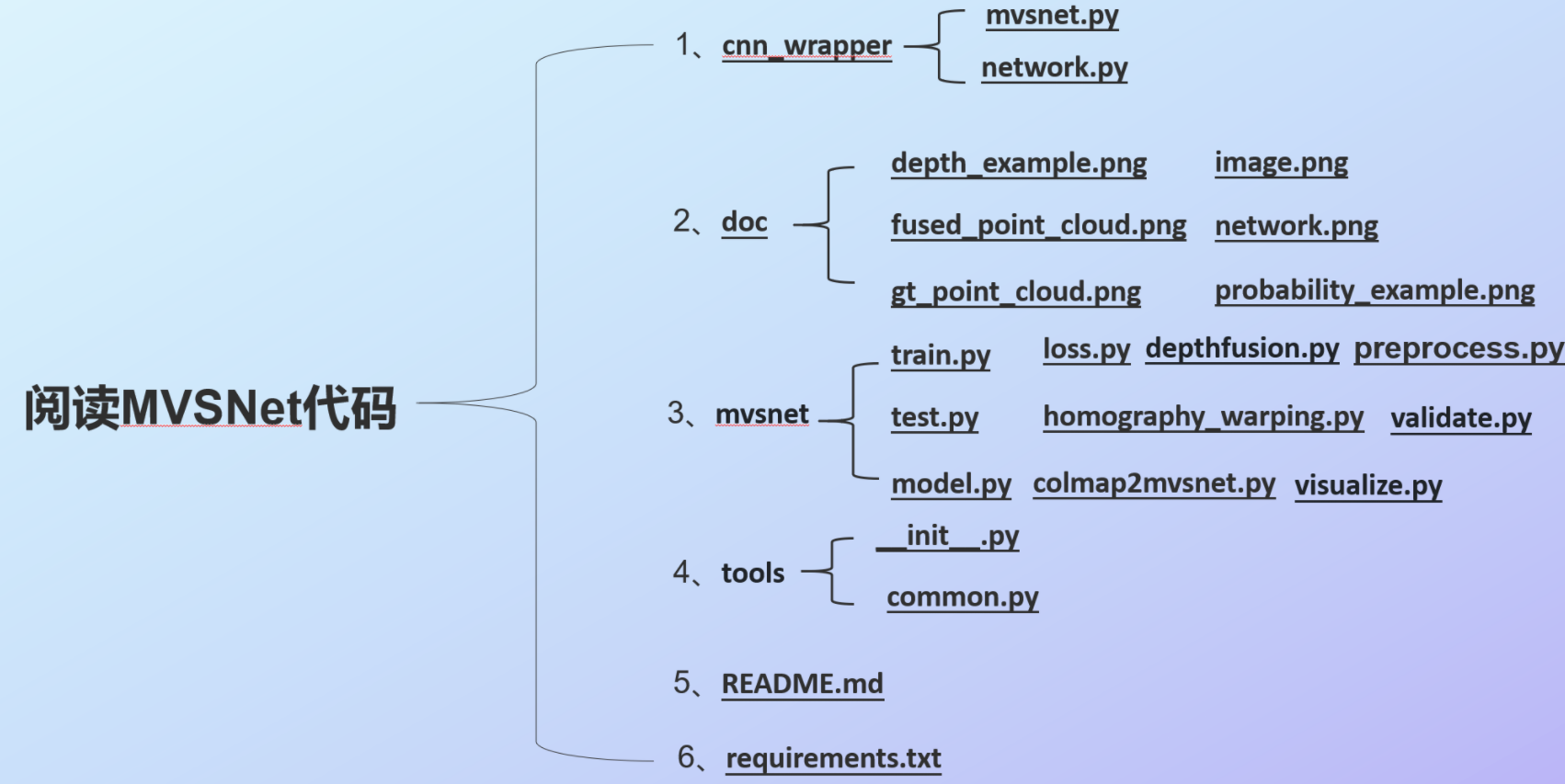
上图是MVSNet项目代码的总体框架图,下面我将逐一分析每个代码文件的作用:
-
cnn_wrapper(各种CNN操作和子模块的实现函数):mvsnet.py是子模块的实现函数的;network.py是定义的各种CNN操作。
-
doc(各种示例文件):depth_example.png是深度图的示例;fused_point_cloud.png是深度图融合后的点云结果示例;gt_point_cloud.png是真实地面数据的点云结果示例;image.png是输入视图的示例;network.png是整个MVSNet的网络框架图;probability_example.png是概率图结果示例。
-
mvsnet(MVSNet模型训练和评估代码文件,只分析了关键代码文件的作用):train.py训练模型代码;test.py测试模型代码;model.py定义mvsnet模型的整体神经网络框架,包括前向传播、损失函数、反向传播等;loss.py损失函数计算代码;homography_warping.py单应性变换代码;colmap2mvsnet.py将colmap得到的场景文件转为mvsnet模型使用的数据格式;depthfusion.py深度图的融合方法;preprocess.py数据预处理方法;validate.py验证模型代码;visualize.py定义了输出可视化结果(深度图、点云)的代码。
验证和测试的区别:验证主要用于在训练过程中评估模型的性能、调整超参数以及防止过拟合,使得模型达到较好的效果;测试主要用于评估模型在真实世界数据上的性能,检查其泛化能力。
-
tools(工具函数):commom.py定义了各种工具函数。
-
README.md(代码实操知道文件)
-
requirements.txt(环境配置要求文件)
3.2 MVSNet/tools/common.py阅读
导入软件包。(不能理解的代码行做了标注,能够理解的没做标注)
#python2中独特的语法,作用就是能够在python2中使用python3中的print函数,因为在python2中print是一个语句,用法是print "Hello, world!",而在python3中print是一个函数,用法是print ("Hello, world!"),定义了下述语法之后就能在python2中使用 Python3 的 print 函数语法。
from __future__ import print_function
import os
from datetime import datetime定义类ClassProperty,继承于父类property,该类的作用是使得定义在该类的属性可以直接通过类访问,而不用创建类实例访问,该类里面定义的__get__方法用于动态地获取属性的值,这里用来动态的获取系统时间。
class ClassProperty(property):
def __get__(self, cls, owner):
return classmethod(self.fget).__get__(None, owner)()定义类Notify,用于为控制台输出添加带有颜色的前缀,以便区分不同类别的信息。
class Notify(object):
def __init__(self):
pass
@ClassProperty
def HEADER(cls):
return str(datetime.now()) + ': \033[95m'
......定义了函数read_list,作用是根据指定路径读取文件,并将该文件的内容按行分割后返回。
def read_list(list_path):
if list_path is None or not os.path.exists(list_path):
print(Notify.FAIL, 'Not exist', list_path, Notify.ENDC)
exit()
content = open(list_path).read().splitlines()
return content定义函数write_list,用于将指定列表list_in里的内容按行输入指定文件path_save中。
def write_list(list_in, path_save):
fout = open(path_save, 'w')
fout.write('\n'.join(list_in))定义函数replace_str_in_file,用于将指定文件list_in里面的指定字符串orig_str换为另一个指定字符串dest_str。
def replace_str_in_file(list_in, orig_str, dest_str):
if os.path.exists(list_in):
content = open(list_in).read()
new_content = content.replace(orig_str, dest_str)
open(list_in, 'w').write(new_content)
else:
print(Notify.WARNING + 'Not exist', list_in, Notify.ENDC)3.3 MVSNet/cnn_wrapper阅读
3.3.1 network.py(定义CNN的各种操作)
导入软件包。
from __future__ import print_function
import os
......
#自定义模块
from tools.common import Notify
#定义了一个常量DEFAULT_PADDING,其值为SAME,SAME是深度学习中常用的填充方法,特别是在卷积神经网络中,它用于在输入图像边缘周围添加适当的零值,使得输入的特征图和输出的特征图大小一样。
DEFAULT_PADDING = 'SAME'定义函数layer,该函数用于为网络层创建统一的接口,以便构建组合式的网络结构。里面还定义了一个内置函数layer_decorated,是函数layer的真正执行体,链式调用时返回自身。
from __future__ import print_function
import os
......
#自定义模块
from tools.common import Notify
#定义了一个常量DEFAULT_PADDING,其值为SAME,SAME是深度学习中常用的填充方法,特别是在卷积神经网络中,它用于在输入图像边缘周围添加适当的零值,使得输入的特征图和输出的特征图大小一样。
DEFAULT_PADDING = 'SAME'下面是network.py脚本中的主体部分Network类,该类里面定义了各种CNN操作。下面的__init__是类的构造函数,用于初始化类实例,为类设置初始属性值。里面的属性值包括输入节点、训练状态、Dropout正则化消除率等等。
from __future__ import print_function
import os
......
#自定义模块
from tools.common import Notify
#定义了一个常量DEFAULT_PADDING,其值为SAME,SAME是深度学习中常用的填充方法,特别是在卷积神经网络中,它用于在输入图像边缘周围添加适当的零值,使得输入的特征图和输出的特征图大小一样。
DEFAULT_PADDING = 'SAME'下面也是Network类里面定义的一个函数setup,该函数是一个抽象方法,用于构建神经网络,但是只在Network类中被定义,并没有被具体的实现,要求在子类中给出具体的网络结构和实现细节。
def setup(self):
raise NotImplementedError('Must be implemented by the subclass.')下面也是Network类里面定义的一个函数load,用于加载预训练网络的权重到当前tensorflow的对话,用于模型的预训练和微调。
def load(self, data_path, session, ignore_missing=False, exclude_var=None):
data_dict = np.load(data_path).item()
......下面也是Network类里面定义的一个函数feed,下一步操作设置输入,通过替换终端节点来实现。这个方法使得可以在构建网络时方便地指定输入,而无需显式地指定输入节点。
def feed(self, *args):
assert args
self.terminals = []
......下面也是Network类里面定义的一个函数get_output,作用是返回当前网络的输出,即 self.terminals 列表的最后一个元素。self.terminals 列表存储的是网络中的终端节点(terminal nodes),也就是网络中的最终输出层或者中间层的输出。当需要在网络中指定输入时,可以通过 feed 方法来替换 self.terminals 列表中的元素,从而方便地更改网络的输入。而在需要获取网络的输出时,则可以通过 get_output 方法直接获取 self.terminals 列表的最后一个元素,即网络的最终输出结果。
def get_output(self):
return self.terminals[-1]下面也是Network类里面定义的一个函数get_output_by_name,指定的层名称layer_name获取网络中对应的节点。self.layers列表里面是键值对,键是层名称,值是对应的网络节点,通过在self.layers列表里面搜索层名称layer_name来获取网络节点。
def get_output_by_name(self, layer_name):
return self.layers[layer_name]下面也是Network类里面定义的一个函数get_unique_name,作用是为给定的前缀prefix生成一个带索引后缀的唯一名称。具体做法遍历 self.layers 字典中的键(即层名称),统计以指定前缀开头的层的数量,然后将统计得到的数量加一,作为新层的索引号,最后将前缀和索引号拼接成一个唯一的名称,并返回该名称。这个方法通常用于在构建网络时自动生成层的名称。
def get_unique_name(self, prefix):
ident = sum(t.startswith(prefix) for t, _ in self.layers.items()) + 1
eturn '%s_%d' % (prefix, ident)下面也是Network类里面定义的一个函数change_inputs,作用是更改网络的输入。接受一个参数 input_tensors,是一个字典,表示要更改的输入张量。字典的键是要更改的层的名称,值是要替换为的新输入张量。
def change_inputs(self, input_tensors):
#断言input_tensors字典的长度为1,即只能更改一个输入张量。如果长度不为1,则会引发 AssertionError。
assert len(input_tensors) == 1
#遍历 input_tensors 字典,对于每个键(层的名称),将对应的值(新的输入张量)赋给 self.layers 字典中相应的键(层的名称)。
for key in input_tensors:
self.layers[key] = input_tensors[key]下面也是Network类里面定义的一个函数conv,该函数用于定义卷积层(2D卷积层/3D卷积层),对于输入张量进行卷积操作。与其他函数不一样的是,这里用了@layer装饰器,@layer是python中的装饰器语法,用于在定义函数或方法时应用装饰器函数,这里用来修饰 conv 方法,将 conv 方法转化为 layer_decorated 函数,以在不修改原始函数定义的情况下,增加一些额外的功能或修改函数的行为。
@layer
def conv(self,
#输入张量
input_tensor,
#卷积核大小
kernel_size,
#卷积核个数
filters,
#滑动步长
strides,
#层级名称
name,
#是否调用relu激活函数
relu=True,
#扩张率,用于控制步长,采用跳跃滑动的方式,增大感受野
dilation_rate=1,
#填充的方式
padding=DEFAULT_PADDING,
#是否设置偏置项
biased=True,
#是否共享参数
reuse=False,
#是否使用可分离的卷积操作(深度卷积和逐点卷积)
separable=False):
#根据参数配置创建一个卷积层
kwargs = {'filters': filters,
'kernel_size': kernel_size,
'strides': strides,
'activation': tf.nn.relu if relu else None,
'use_bias': biased,
'dilation_rate': dilation_rate,
#是否设置为训练模式
'trainable': self.trainable,
'reuse': self.reuse or reuse,
#正则化偏置项
'bias_regularizer': self.regularizer if biased else None,
'name': name,
'padding': padding}
#如果设置了可分离卷积,则将标准卷积操作,划分为深度卷积和逐点卷积
if separable:
kwargs['depthwise_regularizer'] = self.regularizer
kwargs['pointwise_regularizer'] = self.regularizer
#如果美誉设置可分离卷积,仍然使用标准卷积
else:
kwargs['kernel_regularizer'] = self.regularizer
#根据输入张量的维度判断使用2D卷积还是3D卷积,并将卷积后的结果特征图返回。
if len(input_tensor.get_shape()) == 4:
if not separable:
......下面也是Network类里面定义的一个函数conv_gn,该函数用于实现带有组归一化的卷积操作,也就是对刚刚定义的conv函数输出的特征图进行组归一化的操作,输出最终的特征图,归一化在深度学习中起着至关重要的作用,其主要目的是使得输入数据具有统一的分布或范围,以便更好地训练神经网络。其中的组归一化的操作步骤是:①将输入数据按通道维度分成多个组;②对每个组内的数据计算均值和标准差;③使用每个组内的均值和标准差对该组内的数据进行归一化;④可选地,对归一化后的数据进行缩放和平移,以便学习适合当前任务的特定统计特征。(个人想法:该脚本定义的第一个函数layers是一个为网络层创建同一接口,便于创建组合式的网络层结构,那么我觉得带有@layer的函数和方法都是可以进行组合,进而形成一个卷积神经网络)。
@layer
def conv_gn(self,
input_tensor,
......
#归一化后对每个通道进行中心化(即减去均值)。
center=False,
#是否在归一化后对每个通道进行缩放(即乘以缩放因子)。
scale=False,
dilation_rate=1,
#是否按通道独立地进行归一化。
channel_wise=True,
#分组归一化中的组数.
group=32,
#每个组内的通道数。
group_channel=8,
......):
#断言输入的张量只能是4维度(批次Bxwxhxc),如果不是4维度则发生错误,表示这里是对于输入的图像进行处理,如果输入的张量是5维度(批次Bxwxhxcxd),那么表示的是对于中间的代价体(带有深度信息)进行处理。
assert len(input_tensor.get_shape()) == 4
#调用刚刚定义的函数conv得到2D卷积后的特征图
conv = self.conv(input_tensor, kernel_size, filters, strides, name, relu=False,
dilation_rate=dilation_rate, padding=padding,
biased=biased, reuse=self.reuse, separable=separable)
#改变获得特征图的形状,将通道数变到第二个维度上面来,并获取需要归一化的真实组数。
x = tf.transpose(conv, [0, 3, 1, 2])
......
#计算每个组内的均值和方差,进行归一化
x = tf.reshape(x, [N, G, C // G, H, W])
mean, var = tf.nn.moments(x, [2, 3, 4], keep_dims=True)
x = (x - mean) / tf.sqrt(var + self.bn_epsilon)
# 根据传入的参数center和scale计算缩放因子和偏差,对归一化后的结果进一步处理。
with tf.variable_scope(name + '/gn', reuse=self.reuse):
......
# 将最后的处理结果恢复为原来特征图的形状,并决定是否采用relu函数对卷积组归一化后的结果进行处理,最后输出处理完成的特征图。
output = tf.transpose(output, [0, 2, 3, 1])
if relu:
output = self.relu(output, name + '/relu')
return output下面也是Network类里面定义的一个函数conv_bn,该函数用于实现批量归一化卷积操作,也就是对刚刚定义的conv函数输出的特征图进行批量归一化的操作,输出最终的特征图。
@layer
def conv_bn(self,
......):
#调用刚刚定义的函数conv得到卷积后的特征图
conv = self.conv(input_tensor, kernel_size, filters, strides, name, relu=False,
dilation_rate=dilation_rate, padding=padding,
biased=biased, reuse=reuse, separable=separable)
#利用批次归一化函数对得到的特征图进行批量归一化操作,并将得到的结果进行返回
conv_bn = self.batch_normalization(conv, name + '/bn',
center=center, scale=scale, relu=relu, reuse=reuse)
return conv_bn下面也是Network类里面定义的一个函数deconv,用于实现2D/3D反卷积操作,也就是将卷积conv函数得到的特征图经过反卷积得到更大的特征图,其作用就是保证输入的图像与输出的特征图大小一致,或者是提高图像的分辨率。
@layer
def deconv(self,
#输入的张量就是经过conv函数卷积后的特征图
input_tensor,
......):
#根据输入的张量形状以及参数构建一个反卷积层
kwargs = {'filters': filters,
......}
#根据输入张量的维度,选择采用2D/3D反卷积进行操作,并返回扩大后的特征图。
if len(input_tensor.get_shape()) == 4:
......下面也是Network类里面定义的一个函数deconv_bn,它的作用是对反卷积deconv函数返回的特征图进行进一步的批量归一化处理。
@layer
def deconv_bn(self,
......):
#获取反卷积deconv函数扩大的特征图
deconv = self.deconv(input_tensor, kernel_size, filters, strides, name,
relu=False, padding=padding, biased=biased, reuse=reuse)
#对获取的特征图进行批量归一化处理,并返回处理的结果
deconv_bn = self.batch_normalization(deconv, name + '/bn',
center=center, scale=scale, relu=relu, reuse=reuse)
return deconv_bn下面也是Network类里面定义的一个函数deconv_gn,它的作用是对反卷积deconv函数返回的特征图进行进一步的组归一化处理。
@layer
def deconv_gn(self,
......):
assert len(input_tensor.get_shape()) == 4
# deconvolution
.......下面也是Network类里面定义的一个函数relu,它的作用是对于输入的张量input_tensor执行relu非线性激活函数的操作,这个输入的张量我觉得应该是经过归一化卷积的特征图,或者是归一化反卷积的特征图。参数name应该是需要进行relu计算的层级名称。
@layer
def relu(self, input_tensor, name=None):
return tf.nn.relu(input_tensor, name=name)下面也是Network类里面定义的一个函数max_pool,该函数用于创建一个池化层,采用的下采样方法是最大池化法,传入的参数分别是输入张量(经过relu处理过的归一化卷积后的特征图)、池化窗口大小、步长、需要池化操作的层级名称、以及填充方式。
@layer
def max_pool(self, input_tensor, pool_size, strides, name, padding=DEFAULT_PADDING):
#利用传入的参数和最大池化法创建池化层
return tf.layers.max_pooling2d(input_tensor,
......)下面也是Network类里面定义的一个函数avg_pool,该函数用于创建一个池化层,采用的下采样方法是平均池化法。
@layer
def avg_pool(self, input_tensor, pool_size, strides, name, padding=DEFAULT_PADDING):
#利用传入的参数和平均池化法创建池化层
return tf.layers.average_pooling2d(input_tensor,
......)下面也是Network类里面定义的一个函数l2_pool,该函数用于创建一个池化层,采用的下采样方法是L2池化法。L2池化法是对窗口里面的内容先平方,在平均,最后平方根得到一个特征值。
@layer
def l2_pool(self, input_tensor, pool_size, strides, name, padding=DEFAULT_PADDING):
#利用传入的参数和L2池化法创建池化层
return tf.sqrt(tf.layers.average_pooling2d(
......)下面也是Network类里面定义的一个函数lrn,该函数的作用是对输入张量进行LRN局部响应归一化操作。LRN一般是对激活值进行归一化操作,抑制较大的激活值,增强较小的激活值,使得模型有更好的泛化能力,鲁棒性和准确性。LRN操作一般是在卷积和relu之后,因此下面的输入张量,应该是经过relu计算后的卷积归一化的特征图。
@layer
def lrn(self, input_tensor, radius, alpha, beta, name, bias=1.0):
#调用tf.nn.local_response_normalization函数,根据输入的参数,对输入张量的每一个位置进行局部响应归一化,并返回结果。
return tf.nn.local_response_normalization(input_tensor,
......)下面也是Network类里面定义的一个函数concat,用于将多个输入张量input_tensors按照指定的轴axis进行拼接,得到更大的或者是更深的特征图(根据指定轴而定),增强模型的表示能力,name是指需要进行特征图拼接的层级名称。
@layer
def concat(self, input_tensors, axis, name):
return tf.concat(values=input_tensors, axis=axis, name=name)下面也是Network类里面定义的一个函数add,用于将多个输入张量input_tensors相对应位置的元素相加,进而增强网络的表示能力和优化训练过程。
@layer
def add(self, input_tensors, name):
return tf.add_n(input_tensors, name=name) 下面也是Network类里面定义的一个函数fc,该函数的作用是实现全连接层,其参数有输入张量、全连接层输出单元个数、层级的名称、是否使用偏置项、是否使用relu函数、是否扁平化输入张量(也就是将输入的特征图变成一个列向量)、是否共享参数。
@layer
def fc(self, input_tensor, num_out, name, biased=True, relu=True, flatten=True, reuse=False):
#根据传入参数flatten的值决定是否要将输入的特征图进行扁平化处理
if flatten:
flatten_tensor = tf.layers.flatten(input_tensor)
else:
flatten_tensor = input_tensor
#调用函数tf.layers.dense创建全连接层
return tf.layers.dense(flatten_tensor,
......
#对全连接层权重矩阵和偏置项进行正则化的参数
kernel_regularizer=self.regularizer,
bias_regularizer=self.regularizer if biased else None,
name=name)下面也是Network类里面定义的一个函数fc_bn,用于对全连接层的输出结果进行批量归一化处理,并返回处理后的结果。
@layer
def fc_bn(self, input_tensor, num_out, name,
biased=False, relu=True, center=False, scale=False, flatten=True, reuse=False):
......下面也是Network类里面定义的一个函数softmax,用于根据指定维度dim的值对输入张量(全连接层归一化后的输出)的每个元素进行softmax操作,即将其传为概率值。softmax操作常用于多分类的任务的输出层,将神经网络的原始输出转为概率值,所有的概率值和为1。
@layer
def softmax(self, input_tensor, name, dim=-1):
return tf.nn.softmax(input_tensor, dim=dim, name=name)下面也是Network类里面定义的一个函数batch_normalization,该函数用于对输入张量实施批量归一化操作,也就是上面卷积层的批量归一化,反卷积的批量归一化,以及全连接层的批量归一化都是直接调用的这个函数,这个函数的具体实现细节如下,而组归一化的具体实施细节是直接定义在卷积层的组归一化和反卷积的组归一化中的,因为只有卷积层可能会用到组归一化,因此不用单独定义。
@layer
def batch_normalization(self, input_tensor, name,
center=False, scale=False, relu=False, reuse=False):
......下面也是Network类里面定义的一个函数dropout,作用是对输入的张量进行droupout正则化操作,防止过拟合。
@layer
def dropout(self, input_tensor, name):
return tf.layers.dropout(input_tensor,
#droupout正则化中的消除概率
rate=self.dropout_rate,
training=self.training,
#droupout正则化中的随机消除种子
seed=self.seed,
name=name)下面也是Network类里面定义的一个函数l2norm,作用是根据指定维度dim对输入张量的每个样本进行L2归一化操作。在深度学习中,L2 范数归一化常用于将输入向量进行标准化处理,以提高模型的稳定性和收敛速度。
@layer
def l2norm(self, input_tensor, name, dim=-1):
return tf.nn.l2_normalize(input_tensor, dim=dim, name=name)下面也是Network类里面定义的一个函数squeeze,作用是根据指定的维度axis对输入的张量对应的维度进行挤压操作,或者是移除操作,从而降低张量的维度。比如从单个代价体(4维)进行正则化到概率体(3维)的时候就进行了挤压操作,也就是去除了通道这一维度。
@layer
def squeeze(self, input_tensor, axis=None, name=None):
return tf.squeeze(input_tensor, axis=axis, name=name)下面也是Network类里面定义的一个函数reshape,作用是将输入的张量重塑为指定的形状shape。
@layer
def reshape(self, input_tensor, shape, name=None):
return tf.reshape(input_tensor, shape, name=name)下面也是Network类里面定义的一个函数flatten,作用是将输入的张量进行扁平化操作,也就是将多个维度的张量,变为列向量。
@layer
def flatten(self, input_tensor, name=None):
return tf.layers.flatten(input_tensor, name=name)下面也是Network类里面定义的一个函数tanh,作用是返回计算的输入张量的tanh激活值。
@layer
def tanh(self, input_tensor, name=None):
return tf.tanh(input_tensor, name=name)network.py脚本总结:整个文件定义了一个名为 Network 的类,该类作为一个神经网络的抽象,封装了网络的构建过程以及各种常用的层和操作。
-
构造函数
__init__: 初始化网络,设置输入节点、训练状态、dropout率、正则化参数等。 -
网络构建方法
setup: 抽象方法,需要在子类中实现,用于构建整个网络结构。 -
层级操作装饰器
@layer: 该装饰器用于定义各种网络层的操作函数,这些函数接受输入张量并对其进行相应的操作,如卷积、池化、全连接等。 -
各种网络层的操作函数:
-
卷积层:
conv,conv_gn,conv_bn -
反卷积层:
deconv,deconv_gn,deconv_bn -
池化层:
avg_pool,l2_pool,max_pool -
归一化操作:
l2norm,batch_normalization,lrn -
激活函数:
relu,tanh -
全连接层:
fc,fc_bn -
分类任务概率层:
softmax -
正则化Dropout层:
dropout -
扁平化操作:
flatten -
重塑操作:
reshape -
压缩操作:
squeeze -
合并操作:
concat,add
-
-
辅助函数:
-
加载预训练的网络权重矩阵:
load -
设置输入节点:
feed -
获取网络输出:
get_output -
根据层名称获取网络节点:
get_output_by_name -
获取唯一名称:
get_unique_name -
改变网络输入:
change_inputs
-
该脚本提供了一个灵活且可扩展的网络构建框架,使得用户可以方便地定义、组合和配置各种常用的神经网络层,并构建自己的深度学习模型。
3.3.2 mvsnet.py(实现各种子模块函数)
导入软件包,只导入了自定义的Mvsnet/cnn_wrapper/network.py里面定义的Network类,该类里面定义了各种CNN网络层和各种操作。
from cnn_wrapper.network import Network定义了一个名为UniNetDS2的类,该类的作用是定义一个带有批量归一化的CNN,用于特定的图像处理任内务,对于输入的图像进行特征提取和学习。它是继承于Network的子类,在Network类中定义了大量的CNN网络层级和各种操作,那么继承Network的子类UniNetDS2就可以调用父类Network中定义的各种属性和操作来实现自定义的CNN。
父类Network中有一个抽象方法setup,用于实现网络的具体构造,在父类Network中并没有实际被定义,要求必须在子类中被定义,因此子类UniNetDS2中就定义了该方法setup,UniNetDS2在定义该方法时通过调用Network父类的各种属性来创建自定义的CNN。
该卷积层有3层conv0, conv1, conv2,每个卷积层都有多个卷积操作和批量归一化操作,该卷积层可以实现图像的特征提取,以及批量归一化操作,以提高网络的训练稳定性和收敛速度。(没有显示的使用池化层,可能是通过步长控制)
class UniNetDS2(Network):
def setup(self):
#2D32通道的卷积层
print ('2D with 32 filters')
#初始的卷积核个数为8
base_filter = 8
#为后续的卷积操作设置输入数据data
(self.feed('data')
.conv_bn(3, base_filter, 1, center=True, scale=True, name='conv0_0')
.conv_bn(3, base_filter, 1, center=True, scale=True, name='conv0_1')
.conv_bn(5, base_filter * 2, 2, center=True, scale=True, name='conv1_0')
.conv_bn(3, base_filter * 2, 1, center=True, scale=True, name='conv1_1')
.conv_bn(3, base_filter * 2, 1, center=True, scale=True, name='conv1_2')
.conv_bn(5, base_filter * 4, 2, center=True, scale=True, name='conv2_0')
.conv_bn(3, base_filter * 4, 1, center=True, scale=True, name='conv2_1')
.conv(3, base_filter * 4, 1, biased=False, relu=False, name='conv2_2'))定义了一个名为UniNetDS2GN的类,该类的作用是定义一个带有组归一化的CNN,用于特定的图像处理任内务,对于输入的图像进行特征提取和学习。定义的方法与上述的UniNetDS2类定义方法一样,只不过采用的是组归一化卷积函数conv_gn。(没有显示的使用池化层,可能是通过步长控制)
class UniNetDS2GN(Network):
def setup(self):
print ('2D with 32 filters')
base_filter = 8
(self.feed('data')
.conv_gn(3, base_filter, 1, center=True, scale=True, name='conv0_0')
......))定义了一个名为UNetDS2GN的类,该类也是Network的子类,在setup方法中创建了类似于2DUNet结构的卷积神经网络,并用组归一化方法进行归一化。所谓的2D-UNet结构,就是U型的神经网路,分为编码(下采样)和解码(上采样)两部分,可以提取不同尺度的特征,通过跳跃连接将低级和高级的特征连接在一起。setup方法中编码部分是卷积层和池化层,用于提取特征,并降低分辨率,解码是反卷积层和跳跃连接,用于恢复分辨率。
class UNetDS2GN(Network):
"""2D U-Net with group normalization."""
def setup(self):
print ('2D UNet with 32 channel output')
base_filter = 8
(self.feed('data')
.conv_gn(3, base_filter * 2, 2, center=True, scale=True, name='2dconv1_0')
......))
......
(self.feed('2dconv2_0')
.conv_gn(3, base_filter * 4, 1, center=True, scale=True, name='2dconv2_1')
.conv_gn(3, base_filter * 4, 1, center=True, scale=True, name='2dconv2_2'))
......
(self.feed('2dconv4_0')
.conv_gn(3, base_filter * 16, 1, center=True, scale=True, name='2dconv4_1')
.conv_gn(3, base_filter * 16, 1, center=True, scale=True, name='2dconv4_2')
.deconv_gn(3, base_filter * 8, 2, center=True, scale=True, name='2dconv5_0'))
(self.feed('2dconv5_0', '2dconv3_2')
.concat(axis=-1, name='2dconcat5_0')
.conv_gn(3, base_filter * 8, 1, center=True, scale=True, name='2dconv5_1')
.conv_gn(3, base_filter * 8, 1, center=True, scale=True, name='2dconv5_2')
.deconv_gn(3, base_filter * 4, 2, center=True, scale=True, name='2dconv6_0'))
......定义了一个名为RegNetUS0的类,也是Network的子类,这个类用于定义正则化3D成本体积网络,也就是类似于3D-UNet的结构,也是分为编码器和解码器,但不会改变图像的大小,只会对输入的3D代价体进行正则化操作。该网络的编码器部分包含很多的卷积操作,通过增加卷积核的个数和步长来提取3D代价体的特征信息。而解码器包含的是反卷积的操作,逐步恢复特征图的大小,并融合不同尺度的特征图,最后输出一个经过正则化的代价体,也就是所谓的概率体。
class RegNetUS0(Network):
def setup(self):
print ('Shallow 3D UNet with 8 channel input')
base_filter = 8
(self.feed('data')
.conv_bn(3, base_filter * 2, 2, center=True, scale=True, name='3dconv1_0')
......))
......
(self.feed('3dconv4_0', '3dconv2_1')
.add(name='3dconv4_1')
.deconv_bn(3, base_filter * 2, 2, center=True, scale=True, name='3dconv5_0'))
......定义了一个名为RefineNet的类,也是Network的子类,它的作用是定义了使用原始图像对于初始估计的深度图进行细化的网络(细化边缘轮廓信息),该网络的输入就是原始图像和始估计的深度图。
class RefineNet(Network):
def setup(self):
#将原始图像与初始估计的深度图进行拼接
(self.feed('color_image', 'depth_image')
.concat(axis=3, name='concat_image'))
#利用卷积提取拼接后的边界特征信息
(self.feed('concat_image')
.conv_bn(3, 32, 1, name='refine_conv0')
.conv_bn(3, 32, 1, name='refine_conv1')
.conv_bn(3, 32, 1, name='refine_conv2')
.conv(3, 1, 1, relu=False, name='refine_conv3'))
#将提取的边界特征信息加于初始估计的深度图中
(self.feed('refine_conv3', 'depth_image')
.add(name='refined_depth_image'))mvsnet.py脚本总结:该脚本定义了五个网络,其中UniNetDS2和UniNetDS2GN是基础的卷积神经网络,而UNetDS2G、RegNetUS0和RefineNet都是根据特定的任务定制化的网络,其中UNetDS2G是2D-UNet,用于原始图像的特征提取,RegNetUS0是3D-UNet,用于代价体的特征提取,RefineNet用于深度图的细化。
3.4 MVSNet/mvsnet 阅读
3.4.1 homography_warping.py(单应性变换矩阵的定义)
导入软件包。
import tensorflow as tf
import numpy as np下面定义了一个名为get_homographies的函数,该函数的作用就是计算得到单应性变换矩阵,单应性变换矩阵是场景中同一点在两个不同视角摄影机下成像点之间的约束关系,如下是它的公式:
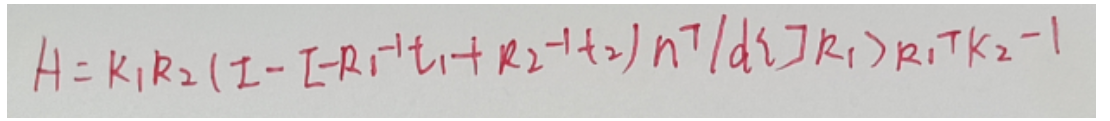
该函数的输入是左边一个摄影机的参数(内参外参)left_cam、右边一个摄影机的参数(内参外参)right_cam、划分平面时的深度个数depth_num,划分平面时起始平面深度depth_start、划分平面时的深度间隔depth_interval。
下图是代码中相应变量代表的公式:

def get_homographies(left_cam, right_cam, depth_num, depth_start, depth_interval):
with tf.name_scope('get_homographies'):
#根据传入的左右相机的参数矩阵,获取相机的内外参矩阵,也就是单应性变换矩阵公式中的R1、R2、t1、t2、K1、K2
R_left = tf.slice(left_cam, [0, 0, 0, 0], [-1, 1, 3, 3])
R_right = tf.slice(right_cam, [0, 0, 0, 0], [-1, 1, 3, 3])
t_left = tf.slice(left_cam, [0, 0, 0, 3], [-1, 1, 3, 1])
t_right = tf.slice(right_cam, [0, 0, 0, 3], [-1, 1, 3, 1])
K_left = tf.slice(left_cam, [0, 1, 0, 0], [-1, 1, 3, 3])
K_right = tf.slice(right_cam, [0, 1, 0, 0], [-1, 1, 3, 3])
#将划分平面时的深度个数depth_num转为Tensorflow张量,便于处理
depth_num = tf.reshape(tf.cast(depth_num, 'int32'), [])
#depth中保存着划分的每个平面的深度
depth = depth_start + tf.cast(tf.range(depth_num), tf.float32) * depth_interval
#num_depth里面存储着depth的长度,也就是所谓的划分的平面的个数
num_depth = tf.shape(depth)[0]
#计算内参矩阵K1的逆矩阵和旋转矩阵R1、R2的转置,注意旋转矩阵的逆矩阵等于转置矩阵
K_left_inv = tf.matrix_inverse(tf.squeeze(K_left, axis=1))
R_left_trans = tf.transpose(tf.squeeze(R_left, axis=1), perm=[0, 2, 1])
R_right_trans = tf.transpose(tf.squeeze(R_right, axis=1), perm=[0, 2, 1])
#fronto_direction的负值就是nTR1的值,具体原因在MVSNet论文阅读里面。大概说一下就是nTR1就等于R1最后一行的负值,而fronto_direction恰好取的是R1最后一行的值。
fronto_direction = tf.slice(tf.squeeze(R_left, axis=1), [0, 2, 0], [-1, 1, 3]) # (B, D, 1, 3)
c_left = -tf.matmul(R_left_trans, tf.squeeze(t_left, axis=1))
c_right = -tf.matmul(R_right_trans, tf.squeeze(t_right, axis=1)) # (B, D, 3, 1)
c_relative = tf.subtract(c_right, c_left)
#获取R1第一维度的值,也就是批处理的样本数量 batch_size
batch_size = tf.shape(R_left)[0]
temp_vec = tf.matmul(c_relative, fronto_direction)
depth_mat = tf.tile(tf.reshape(depth, [batch_size, num_depth, 1, 1]), [1, 1, 3, 3])
temp_vec = tf.tile(tf.expand_dims(temp_vec, axis=1), [1, num_depth, 1, 1])
middle_mat0 = tf.eye(3, batch_shape=[batch_size, num_depth]) - temp_vec / depth_mat
middle_mat1 = tf.tile(tf.expand_dims(tf.matmul(R_left_trans, K_left_inv), axis=1), [1, num_depth, 1, 1])
middle_mat2 = tf.matmul(middle_mat0, middle_mat1)
homographies = tf.matmul(tf.tile(K_right, [1, num_depth, 1, 1])
, tf.matmul(tf.tile(R_right, [1, num_depth, 1, 1])
, middle_mat2))
return homographies下面定义了一个名为get_homographies_inv_depth的函数,它的作用和上一个函数get_homographies差不多,都是为了计算得到单应性矩阵,它们的区别有两个:
①传入的参数不同:get_homographies传入的参数是左边一个摄影机的参数(内参外参)left_cam、右边一个摄影机的参数(内参外参)right_cam、划分平面时的深度个数depth_num,划分平面时起始平面深度depth_start、划分平面时的深度间隔depth_interval。get_homographies_inv_depth传入的参数是左边一个摄影机的参数(内参外参)left_cam、右边一个摄影机的参数(内参外参)right_cam、划分平面时的深度个数depth_num,划分平面时起始的平面深度depth_start、划分平面时结束的平面深度depth_end。
②获取划分的平面的深度信息的方式不同:get_homographies是利用划分平面时的深度个数depth_num,划分平面时起始平面深度depth_start、划分平面时的深度间隔depth_interval三者就可以得到每个平面的深度信息最后保存在depth列表中。get_homographies_inv_depth的做法是首先将传入的划分平面的范围depth_start和depth_end变为逆深度范围inv_depth_start、inv_depth_end,在利用函数 tf.lin_space在逆深度范围中均等的取值,获得逆深度信息inv_depth,然后利用tf.div取逆深度信息inv_depth的倒数,即深度信息。
所谓的逆深度来表示深度信息,可以防止深度信息为0或者无穷大的情况,因此保持深度信息的数值稳定。
下面只展示了获取深度信息不一样的部分代码。
def get_homographies_inv_depth(left_cam, right_cam, depth_num, depth_start, depth_end):
......
# 将划分平面时的深度个数depth_num转为Tensorflow张量,便于处理
depth_num = tf.reshape(tf.cast(depth_num, 'int32'), [])
#将传入的划分平面的范围depth_start和depth_end变为逆深度范围inv_depth_start、inv_depth_end
inv_depth_start = tf.reshape(tf.div(1.0, depth_start), [])
inv_depth_end = tf.reshape(tf.div(1.0, depth_end), [])
#利用函数 tf.lin_space在逆深度范围中均等的取值,获得逆深度信息inv_depth
inv_depth = tf.lin_space(inv_depth_start, inv_depth_end, depth_num)
#利用tf.div取逆深度信息inv_depth的倒数,即深度信息
depth = tf.div(1.0, inv_depth)
# preparation
......下面定义了一个名为get_pixel_grids的函数,该函数用于构建纹理坐标,其传入的参数是图像的高度height和宽度width。所谓的纹理坐标可以描述模型表面的点在纹理空间的位置。
def get_pixel_grids(height, width):
#根据传入的图像高度和宽度,利用函数tf.linspace创建两个线性空间向量x_linspace 、y_linspace
x_linspace = tf.linspace(0.5, tf.cast(width, 'float32') - 0.5, width)
y_linspace = tf.linspace(0.5, tf.cast(height, 'float32') - 0.5, height)
#利用函数tf.meshgrid将两个线性向量x_linspace 、y_linspace变为二维的网格x_coordinates, y_coordinates
x_coordinates, y_coordinates = tf.meshgrid(x_linspace, y_linspace)
#将二维的网格x_coordinates, y_coordinates利用tf.reshape函数改变其形状为一维度的网格
x_coordinates = tf.reshape(x_coordinates, [-1])
y_coordinates = tf.reshape(y_coordinates, [-1])
#ones是一个单位向量
ones = tf.ones_like(x_coordinates)
#将三个向量连接形成3维度的纹理坐标
indices_grid = tf.concat([x_coordinates, y_coordinates, ones], 0)
return indices_grid下面定义了一个名为repeat_int函数,它的作用是将整数向量x的值重复num_repeats次,举个例子:x=[1,2,3]、num_repeats=2,那么这个函数返回的就是x=[1,1,2,2,3,3].
def repeat_int(x, num_repeats):
#ones是一个单位向量,它的维度根据num_repeats的值来定
ones = tf.ones((1, num_repeats), dtype='int32')
#将x变为二维的
x = tf.reshape(x, shape=(-1, 1))
#将x和ones相乘
x = tf.matmul(x, ones)
#将x张量的形状又变为一维的,并返回
return tf.reshape(x, [-1])下面定义了一个名为repeat_float函数,它的作用是将浮点数向量x的值重复num_repeats次。
def repeat_float(x, num_repeats):
ones = tf.ones((1, num_repeats), dtype='float')
x = tf.reshape(x, shape=(-1, 1))
x = tf.matmul(x, ones)
return tf.reshape(x, [-1])下面定义了一个名为interpolate的函数,该函数用于对传入图像image的指定坐标(x,y)进行双线性插值。所谓的双线性插值是常用的图像插值方法,双线性插值常用于在已知像素点上估算介于这些点之间位置的像素值。
在双线性插值中,假设已知的四个像素点位于一个矩形的四个顶点上,需要在该矩形内的任意位置进行插值。插值的过程如下:①首先根据输入位置的坐标找到四个最近的已知像素点,通常是左上角、右上角、左下角和右下角的四个像素点;②计算输入位置与最近的四个像素点之间的距离,并根据距离计算相应的权重。通常使用距离的倒数作为权重,距离越近的像素点权重越大;③根据四个像素点的像素值和对应的权重,计算插值结果。通常使用加权平均的方式计算插值结果,即将每个像素点的像素值乘以对应的权重,然后求和,最后求和的值就是所求坐标点的像素值。
#输入的参数为图像张量image和需要插值的坐标(x,y)
def interpolate(image, x, y):
#利用tf.shape获取输入图像的形状image_shape,然后根据输入图像的形状获得图像的高宽和批次大小
image_shape = tf.shape(image)
batch_size = image_shape[0]
height =image_shape[1]
width = image_shape[2]
#将x和y都减去0.5,使得(x,y)从坐标变为像素坐标
x = x - 0.5
y = y - 0.5
#x0、x1、y0、y1是离坐标(x,y)最近的整数坐标索引
x0 = tf.cast(tf.floor(x), 'int32')
x1 = x0 + 1
y0 = tf.cast(tf.floor(y), 'int32')
y1 = y0 + 1
#下面的一小段代码是为了使得插值的过程不超出图像范围
#max_y和max_x是图像最大的垂直和水平宽度
max_y = tf.cast(height - 1, dtype='int32')
max_x = tf.cast(width - 1, dtype='int32')
#利用tf.clip_by_value保证四个整数坐标索引x0、x1、y0、y1不超出图像范围
x0 = tf.clip_by_value(x0, 0, max_x)
x1 = tf.clip_by_value(x1, 0, max_x)
y0 = tf.clip_by_value(y0, 0, max_y)
y1 = tf.clip_by_value(y1, 0, max_y)
#b记录的是像素点所在数据批次,调用了刚刚定义的函数repeat_int
b = repeat_int(tf.range(batch_size), height * width)
#下面的四个值获得的是四个整数坐标索引x0、x1、y0、y1组合得到的坐标(x0,y0)、(x1,y0)、(x0,y1)、(x1,y1)
indices_a = tf.stack([b, y0, x0], axis=1)
indices_b = tf.stack([b, y0, x1], axis=1)
indices_c = tf.stack([b, y1, x0], axis=1)
indices_d = tf.stack([b, y1, x1], axis=1)
#下面的四个值获得的是离(x,y)最近的四个坐标(x0,y0)、(x1,y0)、(x0,y1)、(x1,y1)的像素值
pixel_values_a = tf.gather_nd(image, indices_a)
pixel_values_b = tf.gather_nd(image, indices_b)
pixel_values_c = tf.gather_nd(image, indices_c)
pixel_values_d = tf.gather_nd(image, indices_d)
x0 = tf.cast(x0, 'float32')
x1 = tf.cast(x1, 'float32')
y0 = tf.cast(y0, 'float32')
y1 = tf.cast(y1, 'float32')
#计算四个坐标中每个坐标离(x,y)的距离,将这个距离值的倒数作为最后双线性插值的权重值。
area_a = tf.expand_dims(((y1 - y) * (x1 - x)), 1)
area_b = tf.expand_dims(((y1 - y) * (x - x0)), 1)
area_c = tf.expand_dims(((y - y0) * (x1 - x)), 1)
area_d = tf.expand_dims(((y - y0) * (x - x0)), 1)
#使得四个坐标中的每个坐标的像素值都乘上对应的权重值之后求和得到(x,y)的像素值。
output = tf.add_n([area_a * pixel_values_a,
area_b * pixel_values_b,
area_c * pixel_values_c,
area_d * pixel_values_d])
return output下面定义了一个名为homography_warping的函数,用于将输入图像input_image经过指定单应性变换矩阵homography的单应性变换,从而得到单应性变换后的图像。
#input_image是输入的图像张量,homography是指定的单应性变换矩阵
def homography_warping(input_image, homography):
#利用tf.shape获取输入图像的形状image_shape,然后根据输入图像的形状获得图像的高宽和批次大小
with tf.name_scope('warping_by_homography'):
image_shape = tf.shape(input_image)
batch_size = image_shape[0]
height = image_shape[1]
width = image_shape[2]
#将给定的单应性矩阵切片为(2,3)的仿射矩阵affine_mat和(1,3)的除法矩阵
affine_mat = tf.slice(homography, [0, 0, 0], [-1, 2, 3])
div_mat = tf.slice(homography, [0, 2, 0], [-1, 1, 3])
#利用刚刚定义的函数get_pixel_grid构建针对输入图像的像素网格,用于描述输入图像每个像素点的位置
pixel_grids = get_pixel_grids(height, width)
pixel_grids = tf.expand_dims(pixel_grids, 0)
pixel_grids = tf.tile(pixel_grids, [batch_size, 1])
pixel_grids = tf.reshape(pixel_grids, (batch_size, 3, -1))
# return pixel_grids
#利用仿射矩阵和除法矩阵对针对输入图像的像素网格进行变换,得到新的像素位置grids_inv_warped
grids_affine = tf.matmul(affine_mat, pixel_grids)
grids_div = tf.matmul(div_mat, pixel_grids)
grids_zero_add = tf.cast(tf.equal(grids_div, 0.0), dtype='float32') * 1e-7 # handle div 0
grids_div = grids_div + grids_zero_add
grids_div = tf.tile(grids_div, [1, 2, 1])
grids_inv_warped = tf.div(grids_affine, grids_div)
x_warped, y_warped = tf.unstack(grids_inv_warped, axis=1)
x_warped_flatten = tf.reshape(x_warped, [-1])
y_warped_flatten = tf.reshape(y_warped, [-1])
#对于新获得的像素位置grids_inv_warped进行双线性插值,得到经过单应性变换后的图像warped_image
warped_image = interpolate(input_image, x_warped_flatten, y_warped_flatten)
warped_image = tf.reshape(warped_image, shape=image_shape, name='warped_feature')
return warped_image下面定义了一个名为tf_transform_homography的函数,它的作用和homography_warping一样,用于将输入图像input_image经过指定单应性变换矩阵homography的单应性变换,从而得到单应性变换后的图像。
tf_transform_homography和homography_warping的区别如下:
①homography_warping:这个函数是通过自定义的单应性变换来得到单应性变换后的图像。首先,根据给定的单应性矩阵,对输入图像中的每个像素进行仿射变换,计算其在目标图像中的坐标。然后,利用双线性插值方法根据原图像的像素值找到目标对应坐标的像素值,从而完成投影变换,得到单应性变换后的图像。
②tf_transform_homography:这个函数利用 TensorFlow 提供的tf.contrib.image.transform 函数完成图像的单应性变换。它首先对给定的单应性矩阵进行了一些变换,以适配 tf.contrib.image.transform 函数的输入格式要求。然后根据变换后的单应性矩阵和双线性插值,利用 TensorFlow 提供的图像变换函数 tf.contrib.image.transform 对输入图像进行了单应性变换。
#input_image是输入的图像张量,homography是指定的单应性变换矩阵
def tf_transform_homography(input_image, homography):
#首先将给定的单应性矩阵homography转换为适合tf.contrib.image.transform函数的输入格式,因为tf.contrib.image.transform函数对应的是图像坐标,而homography对应的是像素坐标。
homography = tf.reshape(homography, [-1, 9])
a0 = tf.slice(homography, [0, 0], [-1, 1])
......
#将转换得到的单应性矩阵homography进行切片
homography_linear = tf.slice(homography, begin=[0, 0], size=[-1, 8])
homography_linear_div = tf.tile(tf.slice(homography, begin=[0, 8], size=[-1, 1]), [1, 8])
homography_linear = tf.div(homography_linear, homography_linear_div)
#根据变换后的单应性矩阵homography_linear和双线性插值,利用tf.contrib.image.transform对输入图像进行了单应性变换。
warped_image = tf.contrib.image.transform(
input_image, homography_linear, interpolation='BILINEAR')
# return input_image
return warped_imagehomography_warping.py脚本总结:该脚本就是用来计算单应性矩阵的,然后利用计算的单应性矩阵来完成图像的单应性变换。
-
单应性变换矩阵:get_homographies
-
利用逆深度获得深度信息的单应性变换矩阵:get_homographies_inv_depth
-
辅助函数:get_pixel_grids(创建网格坐标),repeat_int(复制整数张量)、repeat_float(复制浮点数张量),interpolate(双线性插值)
-
自定义的单应性变换:homography_warping
-
利用Tensorflow得到的单应性变换:tf_transform_homography
3.4.2 model.py(定义了MVSNet模型最关键的一步——深度估计)
导入软件包
import sys
......
#导入自定义的模块
#导入cnn_wrapper.mvsnet模块的所有类,cnn_wrapper.mvsnet模块里面定义了多个CNN以及细化网络
from cnn_wrapper.mvsnet import *
#导入convgru模块中的类ConvGRUCell,定义了循环神经网络(RNN)的变种神经网络,用于处理序列数据,又可以保存卷积神经网络并行计算的优势
from convgru import ConvGRUCell
#导入homography_warping模块中的所有方法,实现单应性变换
from homography_warping import *
#这是Tensorflow里面常用的语法,变量FLAGS里面存储的就是命令行参数和其他的全局配置,设置了这一行代码以后就可以通过命令行传递不同的选项,而不用修改代码
FLAGS = tf.app.flags.FLAGS定义了一个名为get_propability_map的函数,用于从初始的深度图和概率体中获得概率图,该函数接受的参数有概率体cv、初始深度图depth_map(深度图中的每个像素值代表了对应像素的深度值)、深度范围的起始值depth_start、深度间隔depth_interval。所谓的概率图中每个像素值都表示该位置属于目标物体的概率,概率图中的每个像素位置的总概率值是由概率体的左侧低深度、左侧高深度、右侧低深度和右侧高深度的像素值之和组成的。
def get_propability_map(cv, depth_map, depth_start, depth_interval):
#定义了一个名为_repeat_的辅助函数,该函数与单应性变换脚本homography_warping.py里面的函数repeat_int和repeat_float很像,都是将输入张量x的每一个元素都复制num_repeats次
def _repeat_(x, num_repeats):
......
return tf.reshape(x, [-1])
#利用tf.shap获取初始深度图depth_map的形状信息,再从中获取批次大小、高度、宽度等信息
shape = tf.shape(depth_map)
batch_size = shape[0]
height = shape[1]
width = shape[2]
#从概率体cv中获取深度信息,因为cv的形状为[批次 深度 宽 高],因此第二个维度就是深度信息
depth = tf.shape(cv)[1]
#创建三个网络坐标,分别是垂直坐标y_coordinates、水平坐标x_coordinates和批次索引b_coordinates
b_coordinates = tf.range(batch_size)
y_coordinates = tf.range(height)
x_coordinates = tf.range(width)
b_coordinates, y_coordinates, x_coordinates = tf.meshgrid(b_coordinates, y_coordinates, x_coordinates)
b_coordinates = _repeat_(b_coordinates, batch_size)
y_coordinates = _repeat_(y_coordinates, batch_size)
x_coordinates = _repeat_(x_coordinates, batch_size)
#获取深度坐标序列d_coordinates,并获取左侧高深度、左侧低深度、右侧高深度、右侧低深度的整数深度坐标序列
d_coordinates = tf.reshape((depth_map - depth_start) / depth_interval, [-1])
d_coordinates_left0 = tf.clip_by_value(tf.cast(tf.floor(d_coordinates), 'int32'), 0, depth - 1)
d_coordinates_left1 = tf.clip_by_value(d_coordinates_left0 - 1, 0, depth - 1)
d_coordinates1_right0 = tf.clip_by_value(tf.cast(tf.ceil(d_coordinates), 'int32'), 0, depth - 1)
d_coordinates1_right1 = tf.clip_by_value(d_coordinates1_right0 + 1, 0, depth - 1)
#将左侧高深度、左侧低深度、右侧高深度、右侧低深度的整数深度坐标序列与像素坐标组合,得到包含深度信息的体素坐标
voxel_coordinates_left0 = tf.stack(
[b_coordinates, d_coordinates_left0, y_coordinates, x_coordinates], axis=1)
voxel_coordinates_left1 = tf.stack(
[b_coordinates, d_coordinates_left1, y_coordinates, x_coordinates], axis=1)
voxel_coordinates_right0 = tf.stack(
[b_coordinates, d_coordinates1_right0, y_coordinates, x_coordinates], axis=1)
voxel_coordinates_right1 = tf.stack(
[b_coordinates, d_coordinates1_right1, y_coordinates, x_coordinates], axis=1)
# 利用函数tf.gather_nd从概率体cv中获取左侧高深度、左侧低深度、右侧高深度、右侧低深度对应的体素坐标的像素值,然后将像素相加得到每个像素的概率值,从而得到概率图,最后将概率图的形状变为与深度图一样大小
prob_map_left0 = tf.gather_nd(cv, voxel_coordinates_left0)
prob_map_left1 = tf.gather_nd(cv, voxel_coordinates_left1)
prob_map_right0 = tf.gather_nd(cv, voxel_coordinates_right0)
prob_map_right1 = tf.gather_nd(cv, voxel_coordinates_right1)
prob_map = prob_map_left0 + prob_map_left1 + prob_map_right0 + prob_map_right1
prob_map = tf.reshape(prob_map, [batch_size, height, width, 1])
return prob_map定义了一个名为inference的函数,该函数用于从输入的图片images,以及摄像机的内外参数cams推断出初始的深度图。传入该函数的参数有初始输入网络的图片张量images,相机内外参数cams,划分的深度平面数量depth_num,深度范围的起始值depth_start,深度间隔depth_interval,is_master_gpu根据布尔值判断当前GPU是否为主GPU,如果是,则创建新的实例模型,如果不是则沿用原来的实例模型。
该函数内部包括了MVSNet推断初始深度图的全部流程:
①划分图片组,一张参考图和N张源图;
②利用2D CNN提取图片组的特征(调用cnn_wrapper\mvsnet.py里面定义的2D CNN函数UNetDS2GN);
③根据每组图像源图和参考图的摄像机参数得到它们之间对应的单应性矩阵(调用mvsnet\homography_warping.py里面定义的获取单应性矩阵的函数get_homographies);
④利用构建的单应性矩阵构建多个代价体(调用mvsnet\homography_warping.py里面定义的获取单应性矩阵变换后图片的函数tf_transform_homography);
⑤利用方差得到一组图片对应的一个代价体,代码与公式完全相同,如下图:
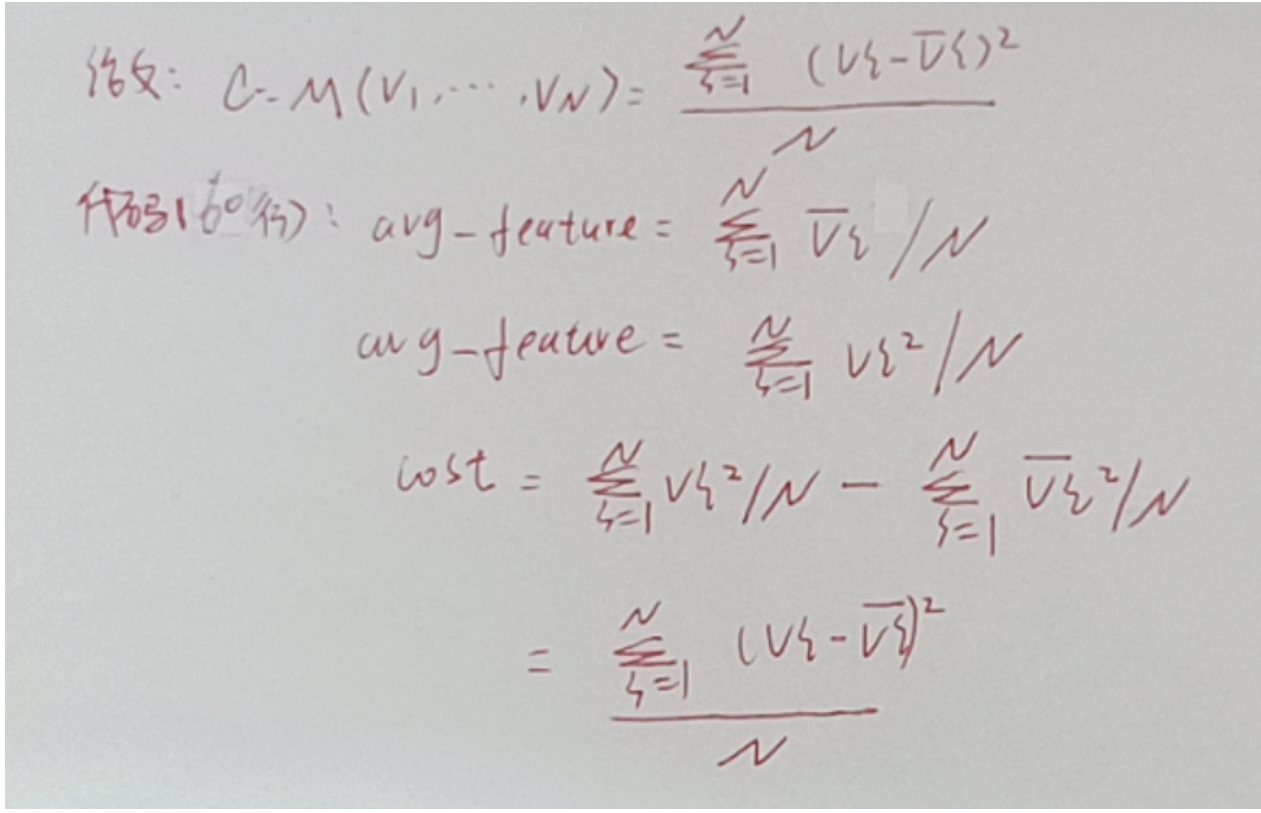
⑥利用3D CNN对代价体进行正则化的得到概率体(调用cnn_wrapper\mvsnet.py里面定义的3D CNN函数RegNetUS0);
⑦对概率体加权求和得到初始深度图,代码与公式完全相同,如下图:

⑧根据概率体和初始深度图调用函数get_propability_map来获取概率图。
def inference(images, cams, depth_num, depth_start, depth_interval, is_master_gpu=True):
#根据传入的参数depth_num和depth_start(变化的)动态的计算深度范围的末端值。
depth_end = depth_start + (tf.cast(depth_num, tf.float32) - 1) * depth_interval
#利用tf.slice对输入的图片张量images切片,得到参考图片。并利用tf.squeeze将参考图片中为1的维度压缩掉,即使得参考图片最后的形状为[B,H,W,3]
ref_image = tf.squeeze(tf.slice(images, [0, 0, 0, 0, 0], [-1, 1, -1, -1, 3]), axis=1)
#利用tf.slice对输入的相机参数cams切片,得到参考相机参数。并利用tf.squeeze将参考相机参数中为1的维度压缩掉,即使得参考相机参数最后的形状为[B,2,4,4]
ref_cam = tf.squeeze(tf.slice(cams, [0, 0, 0, 0, 0], [-1, 1, 2, 4, 4]), axis=1)
#第②步,判断是否在主GPU上进行参考图片的特征提取
if is_master_gpu:
#在主GPU上调用cnn_wrapper\mvsnet.py里面定义的2D CNN函数UNetDS2GN,提取参考图像的特征
ref_tower = UNetDS2GN({'data': ref_image}, is_training=True, reuse=False)
else:
#在其他的GPU上调用cnn_wrapper\mvsnet.py里面定义的2D CNN函数UNetDS2GN,提取参考图像的特征
ref_tower = UNetDS2GN({'data': ref_image}, is_training=True, reuse=True)
#创建一个空列表view_towers用于存储源图提取的图像特征
view_towers = []
#遍历除参考图之外的其他源图
for view in range(1, FLAGS.view_num):
#利用tf.slice根据视图索引view对输入的图片张量images切片,得到源图图片。并利用tf.squeeze将参考图片中为1的维度压缩掉。
view_image = tf.squeeze(tf.slice(images, [0, view, 0, 0, 0], [-1, 1, -1, -1, -1]), axis=1)
#调用cnn_wrapper\mvsnet.py里面定义的2D CNN函数UNetDS2GN,提取源图图像的特征
view_tower = UNetDS2GN({'data': view_image}, is_training=True, reuse=True)
view_towers.append(view_tower)
#第③步,定义了一个空列表view_homographies,用于存储一组图片(1张参考图+N张源图)中存在的单应性变换矩阵
view_homographies = []
#遍历所有源图
for view in range(1, FLAGS.view_num):
#利用tf.slice对输入的相机参数cams切片,得到源图相机参数。并利用tf.squeeze将参考相机参数中为1的维度压缩掉。
view_cam = tf.squeeze(tf.slice(cams, [0, view, 0, 0, 0], [-1, 1, 2, 4, 4]), axis=1)
#调用mvsnet\homography_warping.py里面定义的获取单应性矩阵的函数get_homographies来得到一组图片中存在的单应性变换矩阵
homographies = get_homographies(ref_cam, view_cam, depth_num=depth_num,
depth_start=depth_start, depth_interval=depth_interval)
view_homographies.append(homographies)
#第④、⑤步, 根据一组图片中不同的单应性矩阵,构建多个代价体,最后根据方差得到一组图片最终对应的一个代价体
with tf.name_scope('cost_volume_homography'):
#定义了一个空列表depth_costs,用于存储每组图片对应的代价体
depth_costs = []
#遍历所有的深度
for d in range(depth_num):
#计算每组图片存在的多个代价体的均值,用于方差计算
ave_feature = ref_tower.get_output()
#计算每组图片存在的多个代价体的平方值,用于方差计算
ave_feature2 = tf.square(ref_tower.get_output())
#遍历所有的源图
for view in range(0, FLAGS.view_num - 1):
#获取每张源图与参考图对应的单应性变换矩阵
homography = tf.slice(view_homographies[view], begin=[0, d, 0, 0], size=[-1, 1, 3, 3])
homography = tf.squeeze(homography, axis=1)
#调用mvsnet\homography_warping.py里面定义的获取单应性矩阵变换后图片的函数tf_transform_homography,获取一张源图与参考图对应的单个代价体
warped_view_feature = tf_transform_homography(view_towers[view].get_output(), homography)
#将所有求得的代价体的均值求和
ave_feature = ave_feature + warped_view_feature
#将所有求得的代价体的平方求和
ave_feature2 = ave_feature2 + tf.square(warped_view_feature)
#将所有求得的代价体的均值求和的结果除以一组图片的数量
ave_feature = ave_feature / FLAGS.view_num
#将所有求得的代价体的平方求和的结果除以一组图片的数量
ave_feature2 = ave_feature2 / FLAGS.view_num
#再将两个值相减,与论文中方差求代价体的式子一样
cost = ave_feature2 - tf.square(ave_feature)
depth_costs.append(cost)
cost_volume = tf.stack(depth_costs, axis=1)
#第⑥步,调用cnn_wrapper\mvsnet.py里面定义的3D CNN函数RegNetUS0对得到的多组图片的代价体进行正则化,得到正则化后的代价体
#判断是都在住GPU上调用3D CNN对代价体进行正则化
if is_master_gpu:
#调用cnn_wrapper\mvsnet.py里面定义的3D CNN函数RegNetUS0对代价体正则化
filtered_cost_volume_tower = RegNetUS0({'data': cost_volume}, is_training=True, reuse=False)
else:
filtered_cost_volume_tower = RegNetUS0({'data': cost_volume}, is_training=True, reuse=True)
#将正则化后的代价体为1的维度压缩掉,其形状变为[H,W,D]
filtered_cost_volume = tf.squeeze(filtered_cost_volume_tower.get_output(), axis=-1)
with tf.name_scope('soft_arg_min'):
#将正则化后的代价体经过softmax归一化变为概率体,即所有概率的总和为1
probability_volume = tf.nn.softmax(
tf.scalar_mul(-1, filtered_cost_volume), axis=1, name='prob_volume')
#第⑦步,对概率体进行加权求和得到初始的深度图
volume_shape = tf.shape(probability_volume)
soft_2d = []
for i in range(FLAGS.batch_size):
soft_1d = tf.linspace(depth_start[i], depth_end[i], tf.cast(depth_num, tf.int32))
soft_2d.append(soft_1d)
soft_2d = tf.reshape(tf.stack(soft_2d, axis=0), [volume_shape[0], volume_shape[1], 1, 1])
#soft_4d是加权求和中的权重矩阵,包含深度范围的一系列深度值。
soft_4d = tf.tile(soft_2d, [1, 1, volume_shape[2], volume_shape[3]])
#将概率体与权重矩阵的乘积求和,与原文重点公式一样
estimated_depth_map = tf.reduce_sum(soft_4d * probability_volume, axis=1)
estimated_depth_map = tf.expand_dims(estimated_depth_map, axis=3)
#根据概率体和初始深度图调用函数get_propability_map来获取概率图,最后返回概率图和初始深度图。
prob_map = get_propability_map(probability_volume, estimated_depth_map, depth_start, depth_interval)
return estimated_depth_map, prob_map定义了一个名为inference_mem的函数,该函数的作用也是根据输入的图片images,以及摄像机的内外参数cams推断出初始的深度图。上一个函数inference 与这个函数 inference_mem 在功能上非常相似,它们的主要区别在于内存管理和计算效率上:
内存使用:
-
inference函数在构建成本体积时使用了大量的内存,因为它在每个深度层上保存了特征的平均值和平方平均值。这可能会导致内存使用量较高,尤其是在大规模数据集上运行时。 -
inference_mem函数则更加节省内存,因为它通过循环在每个深度层上依次计算特征的平均值和平方平均值,而不是一次性保存整个成本体积。
计算效率:
-
由于
inference_mem函数采用了逐层计算的方式,可能会比inference函数稍微慢一些,特别是在深度层较多、图像分辨率较高的情况下。然而,它节省了大量内存,因此对于资源受限的环境更具有优势。
下面的代码是inference_mem和inference不同的部分,其余省略的代码都是相同的。不同的代码也就和上述一样,主要表现在代价体构建部分,inference是一次性构建所有深度层的代价体并保存,而inference_mem在每个深度层上依次计算代价体,对于内存要求没有这么高。
def inference_mem(images, cams, depth_num, depth_start, depth_interval, is_master_gpu=True):
# dynamic gpu params
depth_end = depth_start + (tf.cast(depth_num, tf.float32) - 1) * depth_interval
feature_c = 32
feature_h = FLAGS.max_h / 4
feature_w = FLAGS.max_w / 4
......
# image feature extraction
if is_master_gpu:
ref_tower = UNetDS2GN({'data': ref_image}, is_training=True, reuse=False)
else:
ref_tower = UNetDS2GN({'data': ref_image}, is_training=True, reuse=True)
ref_feature = ref_tower.get_output()
ref_feature2 = tf.square(ref_feature)
......
# get all homographies
......
# build cost volume by differentialble homography
with tf.name_scope('cost_volume_homography'):
depth_costs = []
for d in range(depth_num):
# compute cost (standard deviation feature)
ave_feature = tf.Variable(tf.zeros(
[FLAGS.batch_size, feature_h, feature_w, feature_c]),
name='ave', trainable=False, collections=[tf.GraphKeys.LOCAL_VARIABLES])
ave_feature2 = tf.Variable(tf.zeros(
[FLAGS.batch_size, feature_h, feature_w, feature_c]),
name='ave2', trainable=False, collections=[tf.GraphKeys.LOCAL_VARIABLES])
ave_feature = tf.assign(ave_feature, ref_feature)
ave_feature2 = tf.assign(ave_feature2, ref_feature2)
def body(view, ave_feature, ave_feature2):
"""Loop body."""
homography = tf.slice(view_homographies[view], begin=[0, d, 0, 0], size=[-1, 1, 3, 3])
homography = tf.squeeze(homography, axis=1)
# warped_view_feature = homography_warping(view_features[view], homography)
warped_view_feature = tf_transform_homography(view_features[view], homography)
ave_feature = tf.assign_add(ave_feature, warped_view_feature)
ave_feature2 = tf.assign_add(ave_feature2, tf.square(warped_view_feature))
view = tf.add(view, 1)
return view, ave_feature, ave_feature2
view = tf.constant(0)
cond = lambda view, *_: tf.less(view, FLAGS.view_num - 1)
_, ave_feature, ave_feature2 = tf.while_loop(
cond, body, [view, ave_feature, ave_feature2], back_prop=False, parallel_iterations=1)
ave_feature = tf.assign(ave_feature, tf.square(ave_feature) / (FLAGS.view_num * FLAGS.view_num))
ave_feature2 = tf.assign(ave_feature2, ave_feature2 / FLAGS.view_num - ave_feature)
depth_costs.append(ave_feature2)
cost_volume = tf.stack(depth_costs, axis=1)
# filtered cost volume, size of (B, D, H, W, 1)
if is_master_gpu:
filtered_cost_volume_tower = RegNetUS0({'data': cost_volume}, is_training=True, reuse=False)
else:
filtered_cost_volume_tower = RegNetUS0({'data': cost_volume}, is_training=True, reuse=True)
filtered_cost_volume = tf.squeeze(filtered_cost_volume_tower.get_output(), axis=-1)
# depth map by softArgmin
......
# probability map
......
# return filtered_depth_map,
......定义了一个名为inference_prob_recurrent的函数,它的作用是利用GRU网络生成给定输入图像的深度的概率分布(概率体)。通过GRU网络在每个像素位置迭代计算,可以改进我们在每个像素位置估计的深度值。
def inference_prob_recurrent(images, cams, depth_num, depth_start, depth_interval, is_master_gpu=True):
""" infer disparity image from stereo images and cameras """
# dynamic gpu params
......
# reference image
......
# image feature extraction
......
# get all homographies
......
#下面这段代码是为了准备用于GRU(Gated Recurrent Unit)的状态变量和相关的初始化。
#gru1_filters、gru2_filters和gru3_filters分别指定了三个不同的GRU层的滤波器数量。
gru1_filters = 16
gru2_filters = 4
gru3_filters = 2
#定义了特征张量的形状
feature_shape = [FLAGS.batch_size, FLAGS.max_h/4, FLAGS.max_w/4, 32]
#指定了GRU单元的输入形状
gru_input_shape = [feature_shape[1], feature_shape[2]]
#state1、state2和state3是用于存储三个不同GRU层的状态张量的
state1 = tf.zeros([FLAGS.batch_size, feature_shape[1], feature_shape[2], gru1_filters])
state2 = tf.zeros([FLAGS.batch_size, feature_shape[1], feature_shape[2], gru2_filters])
state3 = tf.zeros([FLAGS.batch_size, feature_shape[1], feature_shape[2], gru3_filters])
#conv_gru1、conv_gru2和conv_gru3是分别对应于三个GRU层的ConvGRUCell对象,用于构建GRU网络。
conv_gru1 = ConvGRUCell(shape=gru_input_shape, kernel=[3, 3], filters=gru1_filters)
conv_gru2 = ConvGRUCell(shape=gru_input_shape, kernel=[3, 3], filters=gru2_filters)
conv_gru3 = ConvGRUCell(shape=gru_input_shape, kernel=[3, 3], filters=gru3_filters)
#exp_div和soft_depth_map是用于存储计算过程中的中间变量的零张量。
exp_div = tf.zeros([FLAGS.batch_size, feature_shape[1], feature_shape[2], 1])
soft_depth_map = tf.zeros([FLAGS.batch_size, feature_shape[1], feature_shape[2], 1])
with tf.name_scope('cost_volume_homography'):
......
#下面一段代码是通过GRU(Gated Recurrent Unit)网络生成的一个概率体。
#通过三个ConvGRUCell对象(conv_gru1、conv_gru2和conv_gru3)分别对输入进行处理,得到相应的输出和状态。这里的输入是-cost,即负的损失值。这些损失值通过GRU网络进行处理,以学习如何在不同深度下组合特征以生成更好的深度估计。
reg_cost1, state1 = conv_gru1(-cost, state1, scope='conv_gru1')
reg_cost2, state2 = conv_gru2(reg_cost1, state2, scope='conv_gru2')
reg_cost3, state3 = conv_gru3(reg_cost2, state3, scope='conv_gru3')
#将最终的输出通过一个卷积层(tf.layers.conv2d)处理,以生成每个像素位置对应的深度的估计概率值。
reg_cost = tf.layers.conv2d(
reg_cost3, 1, 3, padding='same', reuse=tf.AUTO_REUSE, name='prob_conv')
depth_costs.append(reg_cost)
#将所有深度的估计概率值堆叠起来,形成一个三维的概率体积,并对其进行softmax操作,以确保所有概率值都在0到1之间,并且总和为1。
prob_volume = tf.stack(depth_costs, axis=1)
prob_volume = tf.nn.softmax(prob_volume, axis=1, name='prob_volume')
return prob_volume定义一个名为inference_winner_take_all的函数,它的作用是定义了一个Winner Take All的深度估计方法,该方法用于在众多的深度假设中找出最好的深度值,该函数还有一个作用,就是可以根据给定的多视图以及相机参数,得到深度图和概率图,由于是利用的Winner Take All的深度估计方法,因此最后得到的深度图是最佳深度图。
该函数接受的参数有初始输入网络的图片张量images;相机内外参数cams;划分的深度平面数量depth_num;深度范围的起始值depth_start;深度间隔depth_interval;根据布尔值判断当前GPU是否为主GPU(如果是,则创建新的实例模型,如果不是则沿用原来的实例模型)is_master_gpu;指定在计算深度估计时使用的正则化类型为GRU(门控循环单元)reg_type;控制是否使用逆深度估计法(如果为Ture则需要调用mvsnet\homography_warping.py里面定义的使用逆深度法获取单应性矩阵的函数get_homographies_inv_depth来得到单应性矩阵)inverse_depth。
def inference_winner_take_all(images, cams, depth_num, depth_start, depth_end,
is_master_gpu=True, reg_type='GRU', inverse_depth=False):
#判断是否使用的正常方法求单应性矩阵,如果是则计算深度间隔depth_interval
if not inverse_depth:
depth_interval = (depth_end - depth_start) / (tf.cast(depth_num, tf.float32) - 1)
# 从图片集中获取参考图
......
# 对参考图和源图进行特征提取
......
# 计算单应性变换矩阵
for view in range(1, FLAGS.view_num):
view_cam = tf.squeeze(tf.slice(cams, [0, view, 0, 0, 0], [-1, 1, 2, 4, 4]), axis=1)
#根据传入参数inverse_depth的值判断是否采用逆深度估计法计算单应性变换矩阵
#如果inverse_depth的值为Ture,则调用homography_warping.py里面的get_homographies_inv_depth来计算单应性变换矩阵,否则调用get_homographies来计算单应性变换矩阵
if inverse_depth:
homographies = get_homographies_inv_depth(ref_cam, view_cam, depth_num=depth_num,
depth_start=depth_start, depth_end=depth_end)
else:
homographies = get_homographies(ref_cam, view_cam, depth_num=depth_num,
depth_start=depth_start, depth_interval=depth_interval)
view_homographies.append(homographies)
# 准备GRU网络所需的状态变量以及初始化,为构建GRU网络做好准备
......
#下面的这段代码创建了几个 TensorFlow 变量和张量
# exp_sum,用于跟踪每个像素位置的累积概率值。
exp_sum = tf.Variable(tf.zeros(
[FLAGS.batch_size, feature_shape[1], feature_shape[2], 1]),
name='exp_sum', trainable=False, collections=[tf.GraphKeys.LOCAL_VARIABLES])
#depth_image,用于存储每个像素位置的估计深度值。
depth_image = tf.Variable(tf.zeros(
[FLAGS.batch_size, feature_shape[1], feature_shape[2], 1]),
name='depth_image', trainable=False, collections=[tf.GraphKeys.LOCAL_VARIABLES])
#max_prob_image,用于存储每个像素位置的最大概率值。
max_prob_image = tf.Variable(tf.zeros(
[FLAGS.batch_size, feature_shape[1], feature_shape[2], 1]),
name='max_prob_image', trainable=False, collections=[tf.GraphKeys.LOCAL_VARIABLES])
#init_map,用于存储初始化的深度值
init_map = tf.zeros([FLAGS.batch_size, feature_shape[1], feature_shape[2], 1])
#上述变量都被设置为不可训练,因为它们在模型推断期间保持不变。它们被添加到 tf.GraphKeys.LOCAL_VARIABLES 集合中,以便在计算图的其他部分使用。
#在inference_winner_take_all函数里面定义了如下名为body的函数,该函数的目的是计算每个深度层的代价,并用存储最大概率值的变量max_prob_image去更新存储累计概率值的变量exp_sum和存储深度值的变量depth_image。实际上就是WTA深度估计法的循环体,为找到最佳深度值。
#该函数在Tensorflow中tf.while.loop中作为循环体传递更新参数,所谓的tf.while.loop是Tensorflow中的一个循环控制流,允许设定循环,该循环的参数有三个:①cond:循环条件,是一个布尔值;②body:循环体;③loop_vars:一个张量列表,用于存储循环遍量,这些变量每次迭代都会更新。该函数body就是tf.while.loop中的循环体,会执行一些操作,并更新循环变量的值,然后根据条件函数cond的返回值来决定是否继续循环。
#该函数接受的参数有:①depth_index: 表示当前深度层的索引;②state1, state2, state3: 表示三个不同GRU单元的状态变量;③depth_image: 表示存储深度值的变量,也叫深度图像;④max_prob_image:存储表示最大概率的变量;⑤exp_sum: 存储概率的累积和的变量;⑥incre: 表示深度索引的增量。这些参数都会在运行body这个循环体中得到更新。
def body(depth_index, state1, state2, state3, depth_image, max_prob_image, exp_sum, incre):
#下面一段代码用于构建代价体,大部分代码都与inference函数中构建代价体的代码一样,我只对不一样的部分进行注释,不一样的地方就是利用转置的单应性矩阵进行的代价体构建
ave_feature = ref_tower.get_output()
ave_feature2 = tf.square(ref_tower.get_output())
for view in range(0, FLAGS.view_num - 1):
#根据视图索引view将一组图像的所有的单应性变换矩阵取出来放在homographies中
homographies = view_homographies[view]
#将所有的单应性变换矩阵进行转置操作
homographies = tf.transpose(homographies, perm=[1, 0, 2, 3])
#取出当前深度层索引depth_index对应的单应性矩阵
homography = homographies[depth_index]
warped_view_feature = tf_transform_homography(view_towers[view].get_output(), homography)
ave_feature = ave_feature + warped_view_feature
ave_feature2 = ave_feature2 + tf.square(warped_view_feature)
ave_feature = ave_feature / FLAGS.view_num
ave_feature2 = ave_feature2 / FLAGS.view_num
cost = ave_feature2 - tf.square(ave_feature)
cost.set_shape([FLAGS.batch_size, feature_shape[1], feature_shape[2], 32])
#以下一段代码是利用之前准备好的用于构建GRU网络的状态变量和初始化来构建GRU网络,进而能够在多个深度值的组合中有更好的深度估计。其过程就是输入的代价体进行了三次卷积GRU的迭代过程,然后将结果传递给一个卷积层以输出概率。
#将代价体和之前的状态变量在三个不同的卷积GRU单元进行迭代,得到新的状态变量以及代价体
reg_cost1, state1 = conv_gru1(-cost, state1, scope='conv_gru1')
reg_cost2, state2 = conv_gru2(reg_cost1, state2, scope='conv_gru2')
reg_cost3, state3 = conv_gru3(reg_cost2, state3, scope='conv_gru3')
#将迭代的结果传递给一个卷积层
reg_cost = tf.layers.conv2d(
reg_cost3, 1, 3, padding='same', reuse=tf.AUTO_REUSE, name='prob_conv')
#将卷积的结果进行指数操作得到每个像素位置估计的概率值
prob = tf.exp(reg_cost)
# 以下一段代码用于根据深度索引值depth_index计算出,当前深度层的深度
#将深度索引值depth_index转为浮点数
d_idx = tf.cast(depth_index, tf.float32)
#根据传入参数inverse_depth的值采用不同的方法计算当前深度层的深度
#如果inverse_depth为Ture则采用逆深度估计发的方式计算当前深度层的深度,逆深度也就是深度值的倒数,否则则采用正常的方法计算当前深度层的深度
if inverse_depth:
inv_depth_start = tf.div(1.0, depth_start)
inv_depth_end = tf.div(1.0, depth_end)
inv_interval = (inv_depth_start - inv_depth_end) / (tf.cast(depth_num, 'float32') - 1)
inv_depth = inv_depth_start - d_idx * inv_interval
depth = tf.div(1.0, inv_depth)
else:
depth = depth_start + d_idx * depth_interval
#将计算得到的深度值 depth 转换为 TensorFlow 张量,并将其重塑为与特征图像素数量相匹配的形状。
temp_depth_image = tf.reshape(depth, [FLAGS.batch_size, 1, 1, 1])
temp_depth_image = tf.tile(
temp_depth_image, [1, feature_shape[1], feature_shape[2], 1])
#以下一段代码用于更新最大概率图像max_prob_image和最佳深度图像
#利用tf.less比较当前的最大概率图像max_prob_image和GRU网络得到当前的概率prob,生成一个更新标志图像update_flag_image。如果当前概率prob大于max_prob_image,则对应的像素值为 1,否则为 0。
update_flag_image = tf.cast(tf.less(max_prob_image, prob), dtype='float32')
#利用更新标志图像update_flag_image更新最大概率图,得到新的最大概率图new_max_prob_image
new_max_prob_image = update_flag_image * prob + (1 - update_flag_image) * max_prob_image
#利用更新标志图像update_flag_image更新深度图,其中temp_depth_image表示得到的当前深度值,depth_image是原始深度值
new_depth_image = update_flag_image * temp_depth_image + (1 - update_flag_image) * depth_image
#将更新的值重新赋予给变量max_prob_image和depth_image
max_prob_image = tf.assign(max_prob_image, new_max_prob_image)
depth_image = tf.assign(depth_image, new_depth_image)
#以下两行代码用于更新其他的变量
#将利用GRU网络得到的新概率值加到累计概率变量exp_sum,完成更新
exp_sum = tf.assign_add(exp_sum, prob)
#完成一次迭代就要使得深度层索引的值加1.也就是加上深度索引增量incre,从而完成深度索引depth_index的更新
depth_index = tf.add(depth_index, incre)
#tf.while.loop的循环体函数body最后会返回所有更新的变量,也就是所有初始传入的参数被更新了,又被返回回去作为下次循环的传入参数
return depth_index, state1, state2, state3, depth_image, max_prob_image, exp_sum, incre
#下面一段代码用于循环体body的初始化,以及body的调用
#累计概率值exp_sum、深度图depth_image、最大概率值max_prob_image的初始化都等于初始深度图init_map里面的值
exp_sum = tf.assign(exp_sum, init_map)
depth_image = tf.assign(depth_image, init_map)
max_prob_image = tf.assign(max_prob_image, init_map)
#深度索引被初始化为0,表示迭代的初始值
depth_index = tf.constant(0)
#深度索引的增量被初始化为1
incre = tf.constant(1)
#利用lambda表达式定义tf.while.loop循环的条件数cond,通过tf.less判断 depth_index 是否小于 depth_num,即是否还有深度索引需要处理。
#通过调用tf.while_loop函数,cond就是刚刚定义的条件,body就是上面定义的循环体函数,传入一系列变量,back_prop=False 表示不需要计算梯度,因为这是一个纯循环操作,不需要反向传播,parallel_iterations=1 表示每次迭代都是串行执行的,即一个接一个地执行。
cond = lambda depth_index, *_: tf.less(depth_index, depth_num)
_, state1, state2, state3, depth_image, max_prob_image, exp_sum, incre = tf.while_loop(
cond, body
, [depth_index, state1, state2, state3, depth_image, max_prob_image, exp_sum, incre]
, back_prop=False, parallel_iterations=1)
#下面一段代码用于计算循环后的输出
#计算修正后的exp_sum,加上一个非常小的常量1e-7,以防止出现除以零的情况。
forward_exp_sum = exp_sum + 1e-7
#forward_depth_map 被设置为循环结束时的depth_image,即在每个像素位置处记录的最佳深度值。
forward_depth_map = depth_image
#返回修正后的forward_depth_map和归一化的max_prob_image
return forward_depth_map, max_prob_image / forward_exp_sum下面定义了一个名为depth_refine的函数,该函数的作用是调用MVSNet/cnn_wrapper/mvsnet.py中定义的函数RefineNet,根据传入的参考图image的边界信息去细化初始估计的深度图init_depth_map。其接受的参数有初始估计的深度图init_depth_map;参考图image;深度数量depth_num;深度范围的起始值depth_start;深度间隔depth_interval;判断当前GPU是否为主GPU,从而是否创建新的实例模型is_master_gpu=True。
def depth_refine(init_depth_map, image, depth_num, depth_start, depth_interval, is_master_gpu=True):
#下面一段代码用于归一化深度范围
#获取初始深度图的形状depth_shape
depth_shape = tf.shape(init_depth_map)
#获取深度范围的结束值depth_end
depth_end = depth_start + (tf.cast(depth_num, tf.float32) - 1) * depth_interval
#获取深度范围起始值的矩阵张量,首先用tf.reshape将其形状变为[batch_size, 1, 1, 1],然后利用tf.tile将矩阵张量在空间维度变为与深度图一样的形状
depth_start_mat = tf.tile(tf.reshape(
depth_start, [depth_shape[0], 1, 1, 1]), [1, depth_shape[1], depth_shape[2], 1])
depth_end_mat = tf.tile(tf.reshape(
depth_end, [depth_shape[0], 1, 1, 1]), [1, depth_shape[1], depth_shape[2], 1])
#将深度范围起始值的矩阵张量与深度范围结束值的矩阵张量相减获取深度范围归一化因子depth_scale_mat,便于后续深度图归一化
depth_scale_mat = depth_end_mat - depth_start_mat
# 利用深度范围归一化因子depth_scale_mat,得到归一化后的深度图init_norm_depth_map
init_norm_depth_map = tf.div(init_depth_map - depth_start_mat, depth_scale_mat)
#利用双线性插值的方法将输入的参考图变为与深度图一样的形状
resized_image = tf.image.resize_bilinear(image, [depth_shape[1], depth_shape[2]])
#判断当前的GPU是否为主GPU,如果是则创建新的RefineNet网络,否则沿用原来旧的RefineNet网络。
if is_master_gpu:
#调用MVSNet/cnn_wrapper/mvsnet.py中定义的函数RefineNet,将变换了形状的参考图resized_image对归一化后的深度图init_norm_depth_map进行细化。
norm_depth_tower = RefineNet({'color_image': resized_image, 'depth_image': init_norm_depth_map},
is_training=True, reuse=False)
else:
norm_depth_tower = RefineNet({'color_image': resized_image, 'depth_image': init_norm_depth_map},
is_training=True, reuse=True)
norm_depth_map = norm_depth_tower.get_output()
# 将细化后的深度图进行逆归一化,得到最终的深度图
refined_depth_map = tf.multiply(norm_depth_map, depth_scale_mat) + depth_start_mat
return refined_depth_mapmodel.py总结:MVSNet是一个多视角立体匹配的神经网络模型,通过多张图片的信息以及相机参数推断出场景深度,在model.py中定义了6个函数,可以分为以下三类:
-
深度估计:get_propability_map(得到概率图)、inference(推断深度图)、inference_mem(推断深度图,对内存要求比较低)
-
深度优化:inference_prob_recurrent(利用GRU网络得到概率体)、inference_winner_take_all(优化深度估计,得到最佳的深度估计)
-
深度精炼:depth_refine(细化初始估计深度图)
3.4.3 loss.py(定义MVSNet模型的损失函数)
导入软件包
import sys
......
FLAGS = tf.app.flags.FLAGS定义了一个名为non_zero_mean_absolute_diff的函数,该函数的作用是计算非零均值绝对差损失。因为在深度估计过程通常会有一些像素点的深度值为零,这可能表示这些像素点的深度值无法被成功估计或者表示场景中的空洞,为了避免这些无法估计的像素对损失函数的影响,可以使用非零均值绝对差损失。
该函数接受的参数为:①真实深度图y_true;②预测深度图y_pred;③深度间隔interval。
def non_zero_mean_absolute_diff(y_true, y_pred, interval):
with tf.name_scope('MAE'):
#利用tf.shape获取预测深度图的形状
shape = tf.shape(y_pred)
#将深度间隔interval重塑为批次大小,以适应每个批次中样本的形状
interval = tf.reshape(interval, [shape[0]])
#mask_true记录了真实深度图y_true中的非零位置,也就是将y_true中非零的位置写为1,为零的位置写为0。首先利用tf.not_equal函数返回一个布尔矩阵,y_true中为0的像素值为False,非零的像素值为True,然后利用tf.cast返回一个浮点数矩阵,也就是将True变为1,将False变为0.
mask_true = tf.cast(tf.not_equal(y_true, 0.0), dtype='float32')
#记录mask_true中非零元素的个数denom,加上一个很小的数1e-7,防止除以0
denom = tf.reduce_sum(mask_true, axis=[1, 2, 3]) + 1e-7
#计算非零位置绝对误差masked_abs_error。y_true - y_pred是求真实深度图与预测深度图所有像素的误差,mask_true * (y_true - y_pred)是只保留非零位置的误差,tf.abs(mask_true * (y_true - y_pred))是对非零位置的误差求取绝对值
masked_abs_error = tf.abs(mask_true * (y_true - y_pred)) #计算每个样本所有非零位置绝对误差之和masked_mae,也就是说masked_mae中每个元素都是对应样本所有非零位置绝对误差之和
masked_mae = tf.reduce_sum(masked_abs_error, axis=[1, 2, 3]) #计算最终的非零位置平均绝对误差masked_mae。masked_mae / interval) / denom是计算每个样本的非零位置平均绝对误差,并考虑了深度间隔,最后利用tf.reduce_sum对所有样本的非零位置平均绝对误差求和得到了最终的非零位置平均绝对误差。
masked_mae = tf.reduce_sum((masked_mae / interval) / denom)
return masked_mae定义了一个名为less_one_percentage的函数,该函数的作用是计算每个批次中真实深度图与预测深度图之间的误差在特定的阈值范围内(0-1)的百分比。
def less_one_percentage(y_true, y_pred, interval):
with tf.name_scope('less_one_error'):
shape = tf.shape(y_pred)
mask_true = tf.cast(tf.not_equal(y_true, 0.0), dtype='float32')
denom = tf.reduce_sum(mask_true) + 1e-7
#将深度间隔的形状转换为与预测深度图相同的形状
interval_image = tf.tile(tf.reshape(interval, [shape[0], 1, 1, 1]), [1, shape[1], shape[2], 1])
#获取真实深度图与预测深度图之间的误差的绝对值,并除以深度间隔,以考虑不同深度值之间的比较。
abs_diff_image = tf.abs(y_true - y_pred) / interval_image
#将abs_diff_image中误差值小于等于1的位置设为1,误差值大于1的位置设为0.并且只考虑真实深度图中的非零位置。
less_one_image = mask_true * tf.cast(tf.less_equal(abs_diff_image, 1.0), dtype='float32')
#返回小于等于1的误差的百分比,也就是将less_one_image中非零位置上的小于等于1的误差值的数量进行求和然后除以非零位置的总数量,得到最后的百分比
return tf.reduce_sum(less_one_image) / denom定义了一个名为less_three_percentage的函数,该函数的作用是计算每个批次中真实深度图与预测深度图之间的误差在特定的阈值范围内(0-3)的百分比。
def less_three_percentage(y_true, y_pred, interval):
""" less three accuracy for one batch """
with tf.name_scope('less_three_error'):
shape = tf.shape(y_pred)
mask_true = tf.cast(tf.not_equal(y_true, 0.0), dtype='float32')
denom = tf.reduce_sum(mask_true) + 1e-7
interval_image = tf.tile(tf.reshape(interval, [shape[0], 1, 1, 1]), [1, shape[1], shape[2], 1])
abs_diff_image = tf.abs(y_true - y_pred) / interval_image
less_three_image = mask_true * tf.cast(tf.less_equal(abs_diff_image, 3.0), dtype='float32')
return tf.reduce_sum(less_three_image) / denom定义了一个名为mvsnet_regression_loss的函数,该函数的作用是计算MVSNet模型的非零均值绝对差损失、小于等于1的误差的百分比、小于等于3的误差的百分比。
def mvsnet_regression_loss(estimated_depth_image, depth_image, depth_interval):
# 非零均值绝对差损失
masked_mae = non_zero_mean_absolute_diff(depth_image, estimated_depth_image, depth_interval)
#小于等于1的误差的百分比
less_one_accuracy = less_one_percentage(depth_image, estimated_depth_image, depth_interval)
# 小于等于3的误差的百分比
less_three_accuracy = less_three_percentage(depth_image, estimated_depth_image, depth_interval)
return masked_mae, less_one_accuracy, less_three_accuracy定义了一个名为mvsnet_classification_loss函数,该函数的作用是计算MVSNet模型的分类损失。该函数接受的参数有:①prob_volume模型输出的深度概率体;②gt_depth_image真实的深度图像;③depth_num深度值的数量;④depth_start深度值的起始点;⑤depth_interval深度值的间隔。
def mvsnet_classification_loss(prob_volume, gt_depth_image, depth_num, depth_start, depth_interval):
#将真实深度图gt_depth_image非零的位置全部变为1,为零的位置不变,得到mask_true
mask_true = tf.cast(tf.not_equal(gt_depth_image, 0.0), dtype='float32')
#计算真实深度图gt_depth_image非零的位置的数量valid_pixel_num
valid_pixel_num = tf.reduce_sum(mask_true, axis=[1, 2, 3]) + 1e-7
#以下一段代码用于从真实深度图gt_depth_image中获取深度索引图gt_index_image
#获取真实深度图gt_depth_image的形状
shape = tf.shape(gt_depth_image)
#计算深度范围的结束值depth_end
depth_end = depth_start + (tf.cast(depth_num, tf.float32) - 1) * depth_interval
#利用函数tf.tile将深度范围的起始值depth_start和深度间隔depth_interval变为与深度图一样形状,以便后续能够深度图做相关的计算
start_mat = tf.tile(tf.reshape(depth_start, [shape[0], 1, 1, 1]), [1, shape[1], shape[2], 1])
interval_mat = tf.tile(tf.reshape(depth_interval, [shape[0], 1, 1, 1]), [1, shape[1], shape[2], 1])
#将真实深度图变为深度索引图
#将深度图像减去起始深度,并除以深度间隔,以获得深度值对应的索引。
gt_index_image = tf.div(gt_depth_image - start_mat, interval_mat)
#计算真实深度图非零位置的深度索引图
gt_index_image = tf.multiply(mask_true, gt_index_image)
#将浮点型索引图像四舍五入为整数类型
gt_index_image = tf.cast(tf.round(gt_index_image), dtype='int32')
#将深度图像的离散索引转换为独热编码形式的体积数据(即三维独热编码张量),以便后续计算交叉熵损失
gt_index_volume = tf.one_hot(gt_index_image, depth_num, axis=1)
#这行代码用于计算交叉熵损失
cross_entropy_image = -tf.reduce_sum(gt_index_volume * tf.log(prob_volume), axis=1)
#下面几行代码用于计算真实深度图非零位置的交叉熵损失,总交叉熵损失和平均每个有效像素位置的交叉熵损失。
masked_cross_entropy_image = tf.multiply(mask_true, cross_entropy_image)
masked_cross_entropy = tf.reduce_sum(masked_cross_entropy_image, axis=[1, 2, 3])
masked_cross_entropy = tf.reduce_sum(masked_cross_entropy / valid_pixel_num)
#利用WTA深度估计算法得到最佳的深度估计
wta_index_map = tf.cast(tf.argmax(prob_volume, axis=1), dtype='float32')
wta_depth_map = wta_index_map * interval_mat + start_mat
# 非零均值绝对差损失
masked_mae = non_zero_mean_absolute_diff(gt_depth_image, wta_depth_map, tf.abs(depth_interval))
# 误差小于1的百分比
less_one_accuracy = less_one_percentage(gt_depth_image, wta_depth_map, tf.abs(depth_interval))
# 误差小于3的百分比
less_three_accuracy = less_three_percentage(gt_depth_image, wta_depth_map, tf.abs(depth_interval))
#返回非零位置的平均交叉熵损失、非零均值绝对差损失、误差小于1的百分比、误差小于3的百分比、最佳深度图
return masked_cross_entropy, masked_mae, less_one_accuracy, less_three_accuracy, wta_depth_maploss.py总结:定义了一系列用于 MVSNet 深度估计模型的损失函数和评估指标计算方法。
-
non_zero_mean_absolute_diff(y_true, y_pred, interval): 计算非零均值绝对差的损失函数,用于评估深度估计模型的准确性。 -
less_one_percentage(y_true, y_pred, interval): 计算绝对误差小于等于 1 的像素比例,用于评估深度估计模型的准确性。 -
less_three_percentage(y_true, y_pred, interval): 计算绝对误差小于等于 3 的像素比例,用于评估深度估计模型的准确性。 -
mvsnet_regression_loss(estimated_depth_image, depth_image, depth_interval): 计算深度估计模型的回归损失和准确度指标。 -
mvsnet_classification_loss(prob_volume, gt_depth_image, depth_num, depth_start, depth_interval): 计算深度估计模型的分类损失和准确度指标,包括交叉熵损失、非零均值绝对差损失以及绝对误差小于等于 1 和 3 的像素比例。 -
3.4.4 train.py(训练MVSNet模型的脚本)
导入软件包
#python2中独特的语法,作用就是能够在python2中使用python3中的print函数,因为在python2中print是一个语句,用法是print "Hello, world!",而在python3中print是一个函数,用法是print ("Hello, world!"),定义了下述语法之后就能在python2中使用 Python3 的 print 函数语法。 from __future__ import print_function import os ...... #导入argparse模块,用于处理命令行参数 import argparse #导入random库中的randint模块,该模块的作用是生成随机整数 from random import randint ...... #导入MVSNET/tools/commom.py定义的Notify函数,为控制台输出添加带有颜色的前缀,以便区别不同种类的信息 from tools.common import Notify #导入MVSNET/mvsnet/preprocess.py中全部定义的函数,用于数据预处理(数据格式修改:以适应模型的输入输出;数据增强:增加模型的泛化能力) from preprocess import * #导入MVSNET/mvsnet/model.py定义的全部函数,用于MVSNet模型的深度估计、深度优化、深度精炼 from model import * #导入MVSNET/mvsnet/loss.py定义的全部函数,包含非零均值绝对差损失、误差小于1和3的百分比、交叉熵损失,其中前三者是MVSNet的精度评估指标 from loss import * #导入MVSNET/mvsnet/homography_warping.py定义的get_homographies、homography_warping这两个函数,作用分别是使用常规的方法获取单应性变换矩阵和手工编辑的图片的单应性变换过程 from homography_warping import get_homographies, homography_warping #导入MVSNET/mvsnet/photometric_augmentation.py定义的全部函数,该脚本是MVSNet模型的光照数据增强脚本,所谓的光照数据增强就是改变图片的光照属性,从而增加数据的多样性,以及增加模型对于光照变化的鲁棒性和泛化能力。 import photometric_augmentation as photaug以下一段代码定义了一系列路径、训练参数,以及控制训练过程的布尔标志。
#定义了BlendedMVS、eth3d、DTU数据集的根目录路径
tf.app.flags.DEFINE_string('blendedmvs_data_root', '/data/BlendedMVS/dataset_low_res',
"""Path to dtu dataset.""")
tf.app.flags.DEFINE_string('eth3d_data_root', '/data/eth3d/lowres/training/undistorted',
"""Path to dtu dataset.""")
tf.app.flags.DEFINE_string('dtu_data_root', '/data/dtu',
"""Path to dtu dataset.""")
#定义了是否训练BlendedMVS、BlendedMVg、eth3d、DTU模型的布尔标志
tf.app.flags.DEFINE_boolean('train_blendedmvs', False,
"""Whether to train.""")
tf.app.flags.DEFINE_boolean('train_blendedmvg', False,
"""Whether to train.""")
tf.app.flags.DEFINE_boolean('train_dtu', False,
"""Whether to train.""")
tf.app.flags.DEFINE_boolean('train_eth3d', False,
"""Whether to train.""")
#定义了存储日记和模型的文件路径
tf.app.flags.DEFINE_string('log_folder', '/data/tf_log',
"""Path to store the log.""")
tf.app.flags.DEFINE_string('model_folder', '/data/tf_model',
"""Path to save the model.""")
#定义了检查点步数
tf.app.flags.DEFINE_integer('ckpt_step', 0,
"""ckpt step.""")
#定义了是否采用预训练模型的布尔标志
tf.app.flags.DEFINE_boolean('use_pretrain', False,
"""Whether to train.""")以下一段代码定义了训练过程中的一系列参数。
#定义使用的GPU数量
tf.app.flags.DEFINE_integer('num_gpus', 1,
"""Number of GPUs.""")
#定义训练过程中一个批次中样本数量的多少,也就是批次大小
tf.app.flags.DEFINE_integer('batch_size', 1,
"""Training batch size.""")
#定义训练的轮次数
tf.app.flags.DEFINE_integer('epoch', 6,
"""Training epoch number.""")
#定义初始学习率
tf.app.flags.DEFINE_float('base_lr', 0.001,
"""Base learning rate.""")
#定义日志展示的时间间隔
tf.app.flags.DEFINE_integer('display', 1,
"""Interval of loginfo display.""")
#定义学习率衰减的部署步数间隔
tf.app.flags.DEFINE_integer('stepvalue', 10000,
"""Step interval to decay learning rate.""")
#定义保存模型的部署间隔
tf.app.flags.DEFINE_integer('snapshot', 5000,
"""Step interval to save the model.""")
#定义学习率衰减率
tf.app.flags.DEFINE_float('gamma', 0.9,
"""Learning rate decay rate.""")
#定义是否要在训练时对数据进行在线的数据加强,增加数据的多样性
tf.app.flags.DEFINE_boolean('online_augmentation', False,
"""Whether to apply image online augmentation during training""")FLAGS是Tensorflow常用的约定,用于定义和管理命令行,允许在命令行执行Tensorflow脚本的时候设置各种命令行参数。
FLAGS = tf.app.flags.FLAGS以下代码定义了一个online_augmentation的函数,该函数的作用是在训练过程中对于输入的数据进行在线的数据增强,以便增加数据的多样性,模型的鲁棒性和泛化能力。其接受的参数有输入的图像image;用于控制是否随机打乱数据增强操作顺序的布尔值random_order,如果该布尔值为True的话,图像增强操作的顺序会被打乱,模型会学习到不同顺序下图像的特征,增加模型的泛化能力。
def online_augmentation(image, random_order=True):
#下面一行代码将photometric_augmentation.py脚本里面定义的各种数据增强操作的函数定义(函数的具体实现)存储在列表primitives中,包括随机调整图像亮度、随机调整图像对比度,给图像增加高斯噪声、给图像增加斑点噪声、给图像增加阴影效果、给图像增加模糊效果这六个图像增强操作
primitives = photaug.augmentations
#创建了一个空列表config,用于存储photometric_augmentation.py脚本里面定义的各种数据增强操作函数参数,包括最大光度、对比度调整范围等等。
config = {}
#在config列表中定义的第一个键值对是对图像进行随机光度的调整的函数random_brightness的参数:最大光度调整值max_abs_change为50。
config['random_brightness'] = {'max_abs_change': 50}
#在config列表中定义的第二个键值对是随机增强图像对比度(使得图像的明暗分明,增加图像的细节)的函数random_contrast的参数值:对比度的调整范围strength_range。
config['random_contrast'] = {'strength_range': [0.3, 1.5]}
#在config列表中定义的第三个键值对是对图像增加高斯噪声的函数additive_gaussian_noise的参数:高斯噪声的标准差范围stddev_range。
config['additive_gaussian_noise'] = {'stddev_range': [0, 10]}
#在config列表中定义的第四个键值对是对图像增加斑点噪声的函数additive_speckle_noise的参数:斑点噪声的分布概率范围prob_range。
config['additive_speckle_noise'] = {'prob_range': [0, 0.0035]}
#在config列表中定义的第五个键值对是对图像增加阴影效果的函数additive_shade的参数:阴影透明度的范围transparency_range和阴影核尺寸范围kernel_size_range。
config['additive_shade'] = {'transparency_range': [-0.5, 0.5], 'kernel_size_range': [100, 150]}
#在config列表中定义的第五个键值对是对图像增加模糊效果的函数motion_blur的参数:最大模糊核(卷积核)max_kernel_size的尺寸大小。
config['motion_blur'] = {'max_kernel_size': 3}
with tf.name_scope('online_augmentation'):
#下面一行代码中的prim_config是一个列表,该列表将primitives列表和config列表进行结合,也就是将config列表中定义的参数值传入primitives中定义的各种图像增强操作的函数中、。
prim_configs = [config.get(p, {}) for p in primitives]
#indices是一个范围,其值为0到len(primitives)-1,代表的就是各种图像增强操作的索引号。
indices = tf.range(len(primitives))
#根据传入参数random_order的布尔值判断是否要打乱代表各种图像增强操作的索引号indices。
if random_order:
indices = tf.random.shuffle(indices)
#定义了一个辅助函数step,该函数是tf.while_loop函数的循环体body。该函数的作用是根据打乱了的图像增强操作的索引号indices对输入的图像image进行相应的图像增强操作,最后返回增强后的图片。每迭代一次这个循环体就对图像进行一种图像增强操作。
def step(i, image):
#fn_pairs是根据图像增强操作的索引号indices确定的相应的图像增强操作
fn_pairs = [(tf.equal(indices[i], j), lambda p=p, c=c: getattr(photaug, p)(image, **c))
for j, (p, c) in enumerate(zip(primitives, prim_configs))]
#利用tf.case函数将fn_pairs对应图像增强操作对图像进行处理
image = tf.case(fn_pairs)
#最后返回图像增强后的图片
return i + 1, image
#这行代码调用了tf.while_loop这个函数,它的作用就是根据括号里面的一系列参数判断是否还要迭代循环体step,括号里面的这些参数就相当于tf.while_loop函数的判断条件,即cond。
_, aug_image = tf.while_loop(lambda i, image: tf.less(i, len(primitives)),
step, [0, image], parallel_iterations=1)
#最后返回迭代结束后的图像,即经过多种图像增强操作后的图像。
return aug_image下面定义了一个名为MVSGenerator的类,该类是数据生成器,用于生成训练数据,实际作用其实就是数据的预处理,调用了MVSNet/mvsnet/preprocess.py脚本中定义的很多函数。该函数从给定的样本列表sample_list中提取每个样本的图片、相机参数和深度图,对其进行预处理,将处理的结果作为MVSNet模型训练过程中输入的批次数据。
class MVSGenerator:
#构造函数__init__用于构造类MVSGenerator,并初始化该类实例对象的一些属性,如样本列表sample_list,视角数量view_num,样本数量sample_num,样本处理计数器(处理完一个样本,计数器就加1)counter。该函数接受的参数就样本列表sample_list和视角数量view_num。
def __init__(self, sample_list, view_num):
self.sample_list = sample_list
self.view_num = view_num
self.sample_num = len(sample_list)
self.counter = 0
#定义了一个名为__iter__的函数,该函数是类MVSGenerator生成训练数据的迭代体。之所以为迭代体是因为这个函数每次从样本列表sample_list只取一个样本,然后加载该样本里面的图像、相机参数和深度图,对其进行预处理(裁剪、缩放和掩码等处理),将处理完毕的结果返回给MVSNet训练模型,作为MVSNet训练模型输入的批次数据,然后接着处理下一个样本,直到样本列表里面的样本都被处理完,即self.counter=self.sample_num 。
#该函数一共包括六个步骤:①取出一个样本,然后加载样本中的图像、相机参数和深度图;②判断取出来的数据是什么类型,是DTU,还是进行blendedmvs,根据类型的不同选择不同的方法进行预处理;③跳过无效视角样本的处理;④修正深度的范围以及深度采样数;⑤掩盖超出深度范围的像素值;⑥将预处理的结果返回给MVSNet模型,作为模型的训练输入;⑦将预处理的结果进行反向处理传给GRU网络作为正则化的输入。
def __iter__(self):
#定义了一个无限循环
while True:
#从样本列表中取出一个样本,命名为data
for data in self.sample_list:
#设置处理样本的开始时间,目的是看一个样本预处理所需要的时间
start_time = time.time()
#设置两个空列表images,cams,分别用于存储一个样本中多个视点的图像以及摄像机参数。
images = []
cams = []
#将样本data中每个视点view的图像以及相机参数取出来放入两个空列表中
for view in range(self.view_num):
image = cv2.imread(data[2 * view])
cam = load_cam(open(data[2 * view + 1]))
images.append(image)
cams.append(cam)
#将每个样本对应的深度图取出来,函数load_pfm和load_cam在预处理脚本preprocess.py中被定义
depth_image = load_pfm(open(data[2 * self.view_num]))
#判断取出的样本对应的数据是哪个数据集的,根据不同的数据集选择不同的预处理方式
#假如样本的数据对应的数据集是blendedmvs,那么就需要将深度图和相机参数缩小4倍,以适应深度图像的输出
if FLAGS.train_blendedmvs:
depth_image = scale_image(depth_image, scale=FLAGS.sample_scale)
cams = scale_mvs_camera(cams, scale=FLAGS.sample_scale)
#假如样本的数据对应的数据集是dtu,那么就需要将深度范围调整为[425,937]
elif FLAGS.train_dtu:
cams[0][1, 3, 0] = 425
cams[0][1, 3, 3] = 937
#假如样本的数据对应的数据集是eth3d,那么就需要将图像进行裁剪,并将深度图和相机参数缩小4倍,以适应深度图像的输出
elif FLAGS.train_eth3d:
images, cams, depth_image = crop_mvs_input(
images, cams, depth_image, max_w=FLAGS.max_w, max_h=FLAGS.max_h)
depth_image = scale_image(depth_image, scale=FLAGS.sample_scale)
cams = scale_mvs_camera(cams, scale=FLAGS.sample_scale)
#如果样本的数据不对应任何的数据集,则发送报错信息,并中止代码的执行
else:
print ('Please specify a valid training dataset.')
exit(-1)
#下面两行代码的目的跳过无效视角,也就是说如果相机参数的深度范围不符合要求,就利用continue语句不处理这个样本,直接处理下一个样本呢。
if cams[0][1, 3, 0] <= 0 or cams[0][1, 3, 3] <= 0:
continue
#下面两行代码用于修正深度范围和深度间隔
#将相机参数中的cams[0][1, 3, 2]元素定为最大的深度范围
cams[0][1, 3, 2] = FLAGS.max_d
#将相机参数中的cams[0][1, 3, 1]元素定为深度间隔
cams[0][1, 3, 1] = (cams[0][1, 3, 3] - cams[0][1, 3, 0]) / FLAGS.max_d
#掩盖超出深度范围的像素
#计算深度范围的起始值depth_start,其值为深度范围的下限加上深度间隔
depth_start = cams[0][1, 3, 0] + cams[0][1, 3, 1]
#计算深度范围的结束值depth_end,其值为深度范围的下限加上深度步长乘以最大深度值减去2
depth_end = cams[0][1, 3, 0] + (FLAGS.max_d - 2) * cams[0][1, 3, 1]
#利用mask_depth_image函数对于图像中超出深度范围的像素进行掩盖处理
depth_image = mask_depth_image(depth_image, depth_start, depth_end)
#下面一段代码用于将预处理的结果返回作为mvsnet模型的训练过程的输入
#处理完一个样本,计数器counter加一
self.counter += 1
#计算该样本的处理时间duration
duration = time.time() - start_time
#将预处理后的图像和相机参数利用函数 np.stack变为 axis=0维度的张量
images = np.stack(images, axis=0)
cams = np.stack(cams, axis=0)
#输出深度范围
print('Forward pass: d_min = %f, d_max = %f.' % \
(cams[0][1, 3, 0], cams[0][1, 3, 0] + (FLAGS.max_d - 1) * cams[0][1, 3, 1]))
#返回处理后的数据
yield (images, cams, depth_image)
#下面一段代码的作用是将预处理的结果进行反向处理,作为正则化网络GRU的输入,所谓的反向处理就是将深度范围被调整为负值,以便产生与前向传递相反的效果。
#先判断是否要使用GRU对网络进行正则化
if FLAGS.regularization == 'GRU':
self.counter += 1
start_time = time.time()
#将与深度有关的相机参数进行反向处理
cams[0][1, 3, 0] = cams[0][1, 3, 0] + (FLAGS.max_d - 1) * cams[0][1, 3, 1]
cams[0][1, 3, 1] = -cams[0][1, 3, 1]
duration = time.time() - start_time
print('Back pass: d_min = %f, d_max = %f.' % \
(cams[0][1, 3, 0], cams[0][1, 3, 0] + (FLAGS.max_d - 1) * cams[0][1, 3, 1]))
yield (images, cams, depth_image) 以下代码定义了一个名为average_gradients的函数,该函数的作用是计算共享变量在所有GPU上的平均梯度,可接受的参数tower_grads是一个列表,包含了所有GPU上该共享变量的梯度,目的就是计算该共享变量的梯度在所有GPU上的平均,最后返回该共享变量的平均梯度。注意列表tower_grads中只有一个共享变量,但由于它在不同的GPU上梯度不一样,可能命名有差异,也就是tower_grads中保存着一个共享变量在不同GPU上的梯度值。
所谓的共享变量是指一个变量在做个GPU上共享,每个GPU上这个变量的含义以及值都是一样的,在深度学习中,经常将模型参数(权重、偏置等等)进行共享,以提高训练效率。
def average_gradients(tower_grads):
#定义了一个列表,该列表用来存储共享变量在所有GPU上的平均梯度
average_grads = []
#tower_grads是一个列表,包含了所有GPU上该共享变量的梯度。zip(*tower_grads)是将所有的共享变量(同一个)和梯度两两组成一个元组,每个元组里面都包括每个GPU上的变量和梯度。然后用for循环,循环遍历取出每一个元组,存于列表grad_and_vars中
for grad_and_vars in zip(*tower_grads):
#定义一个列表grads用来存储每个GPU上的梯度,而不存储变量,因为变量只有一个,只不过名称多样化。
grads = []
#g代表grad_and_vars中的梯度,_代表grad_and_vars中的变量
for g, _ in grad_and_vars:
#利用tf.expand_dim函数给每一个梯度值都加一个维度,以便后续平均操作
expanded_g = tf.expand_dims(g, 0)
#将加了维度的梯度添加到列表grads
grads.append(expanded_g)
#利用tf.concat将grads列表中的梯度沿着axis=0轴进行拼接,然后利用tf.reduce_mean对梯度值求平均,这样就得到了共享变量的平均梯度值grad
grad = tf.concat(axis=0, values=grads)
grad = tf.reduce_mean(grad, 0)
#由于只针对一个共享变量,因此取变量的时候只用取出grad_and_vars列表中第一个GPU的变量v即可,然后将该变量v以及平均梯度grad组成一个元组,存于grad_and_var中,最后在加入存储共享变量平均梯度的列表average_grads中。
v = grad_and_vars[0][1]
grad_and_var = (grad, v)
average_grads.append(grad_and_var)
return average_grads定义了一个名为train的函数,该函数的作用就是调用之前定义的路径、训练参数、数据在线加强函数online_augmentation、预处理类MVSGenerator、计算共享变量平均梯度函数average_gradients来训练MVSNet模型。其接受的参数traning_list是一个存有训练样本的列表,每个样本存储着图像、相机参数和深度图等数据,通过类MVSGenerator(数据生成器)对该列表的样本迭代依次取出进行预处理生成训练数据。
def train(traning_list):
#获取样本数量
training_sample_size = len(traning_list)
#判断该模型是否使用GRU正则化网络,如果使用了样本数量翻倍,并输出样本数量
if FLAGS.regularization == 'GRU':
training_sample_size = training_sample_size * 2
print ('Training sample number: ', training_sample_size)
#指定了Tensorflow的构图方式和计算设备。tf.Graph().as_default()创建了一个Tensorflow的新图,并设为默认图,意味着整个模型的计算图在这个图中构建。 tf.device('/cpu:0')指定计算设备为CPU,意味着该模块定义了所有操作都要在CPU上进行,这里是为了在构图时i,使得变量的创建以及计算密集的操作都在CPU上进行,从而不影响到GPU。
with tf.Graph().as_default(), tf.device('/cpu:0'):
#利用MVSGenerator类对样本列表traning_list进行预处理,并用iter创建了用于生成训练数据的迭代器
training_generator = iter(MVSGenerator(traning_list, FLAGS.view_num))
#指定生成训练数据(图像、深度图、相机参数)的类型
generator_data_type = (tf.float32, tf.float32, tf.float32)
#利用函数tf.data.Dataset.from_generator创建数据集,并将数据集划分为合适大小的批次,并为每个批次数据后设置固定大小的缓冲区,以便可以在一个批次数据快处理完的时候缓存下一个批次的数据,以加快训练速度。
training_set = tf.data.Dataset.from_generator(lambda: training_generator, generator_data_type)
training_set = training_set.batch(FLAGS.batch_size)
training_set = training_set.prefetch(buffer_size=1)
#设置训练数据的迭代器
training_iterator = training_set.make_initializable_iterator()
#利用函数tf.Variable创建了一个全局步数变量global_step,该变量的作用是计算训练过程的步数,初始值为0,设置为不可训练,因为它就是一个计算步数的,不参与参数的更新。
global_step = tf.Variable(0, trainable=False, name='global_step')
#利用tf.train.exponential_decay创建了一个学习率指数衰减器lr_op,它会根据全局步数的指数衰减学习率。初始的学习率为base_lr,学习率开始衰减的步数为stepvalue,衰减率为gamma。
lr_op = tf.train.exponential_decay(FLAGS.base_lr, global_step=global_step,
decay_steps=FLAGS.stepvalue, decay_rate=FLAGS.gamma, name='lr')
#创建了一个RMSprop梯度优化器opt
opt = tf.train.RMSPropOptimizer(learning_rate=lr_op)
#创建了一个列表tower_grads用于存储每个GPU上共享变量的梯度
tower_grads = []
#遍历每个GPU的索引号
for i in xrange(FLAGS.num_gpus):
#将操作指定到第i个gpu上
with tf.device('/gpu:%d' % i):
#可视化
with tf.name_scope('Model_tower%d' % i) as scope:
#利用training_iterator获取下一个批次的训练数据
images, cams, depth_image = training_iterator.get_next()
#下面一段代码是对一个批次的训练数据进行在线数据加强和归一化操作
#列表arg_images用于存储进行数据加强和归一化的图像
arg_images = []
#遍历每一个批次的数据
for view in range(0, FLAGS.view_num):
#利用tf.slice将一个批次训练数据里面的view视角的图像取出来,并利用tf.squeeze将为1的维度压缩掉
image = tf.squeeze(tf.slice(images, [0, view, 0, 0, 0], [-1, 1, -1, -1, 3]), axis=1)
#判断是否要进行数据加强
if FLAGS.online_augmentation:
#调用上面定义的在线数据加强函数online_augmentation对图像进行加强操作
image = tf.map_fn(online_augmentation, image, back_prop=False)
#利用tf.image.per_image_standardization对图像进行标准化操作
image = tf.image.per_image_standardization(image)
#将处理后的数据加入arg_images列表
arg_images.append(image)
#将获取的一个批次数据里面的图像变为axis=1维度的张量
images = tf.stack(arg_images, axis=1)
#改变图像、相机参数、深度范围、深度间隔的形状
images.set_shape(tf.TensorShape([None, FLAGS.view_num, None, None, 3]))
cams.set_shape(tf.TensorShape([None, FLAGS.view_num, 2, 4, 4]))
depth_image.set_shape(tf.TensorShape([None, None, None, 1]))
depth_start = tf.reshape(
tf.slice(cams, [0, 0, 1, 3, 0], [FLAGS.batch_size, 1, 1, 1, 1]), [FLAGS.batch_size])
depth_interval = tf.reshape(
tf.slice(cams, [0, 0, 1, 3, 1], [FLAGS.batch_size, 1, 1, 1, 1]), [FLAGS.batch_size])
#设置is_master_gpu布尔值,用于标识当前的GPU是否为主GPU
is_master_gpu = False
if i == 0:
is_master_gpu = True
#下面一段代码会根据选择的正则化方法不同,从而选择model.py和loss.py当中不同的函数进行深度估计和精度指标计算
#如果MVSNet模型选择3D CNN进行正则化,则调用model.py中的inference估计深度图和概率图,并通过refinement标志判断是否要对深度图进行细化操作,如果要细化则调用model.py里面定义的depth_refine函数,否则不进行细化操作。最后调用mvsnet_regression_loss函数分别计算没有细化的深度图和细化的深度图的精度指标。
if FLAGS.regularization == '3DCNNs':
depth_map, prob_map = inference(
images, cams, FLAGS.max_d, depth_start, depth_interval, is_master_gpu)
if FLAGS.refinement:
#利用tf.slice将输入图像中的参考图切片出来
ref_image = tf.squeeze(
tf.slice(images, [0, 0, 0, 0, 0], [-1, 1, -1, -1, 3]), axis=1)
refined_depth_map = depth_refine(depth_map, ref_image,
FLAGS.max_d, depth_start, depth_interval, is_master_gpu)
else:
refined_depth_map = depth_map
loss0, less_one_temp, less_three_temp = mvsnet_regression_loss(
depth_map, depth_image, depth_interval)
loss1, less_one_accuracy, less_three_accuracy = mvsnet_regression_loss(
refined_depth_map, depth_image, depth_interval)
#最终的损失值等于两个损害值的平均值
loss = (loss0 + loss1) / 2
#如果MVSNet模型选择GRU进行正则化,则调用model.py中的inference_prob_recurrent估计概率体,并通过mvsnet_classification_loss函数计算精度指标。
elif FLAGS.regularization == 'GRU':
prob_volume = inference_prob_recurrent(
images, cams, FLAGS.max_d, depth_start, depth_interval, is_master_gpu)
loss, mae, less_one_accuracy, less_three_accuracy, depth_map = \
mvsnet_classification_loss(
prob_volume, depth_image, FLAGS.max_d, depth_start, depth_interval)
#获取训练过程中的变量和指标
summaries = tf.get_collection(tf.GraphKeys.SUMMARIES, scope)
# 利用RMSprop梯度优化器opt计算精度指标的梯度
grads = opt.compute_gradients(loss)
#将精度指标的梯度加入GPU的梯度列表tower_grads
tower_grads.append(grads)
#获取损失函数在每个GPU上的平均梯度,为反向传播(梯度下降)做准备
grads = average_gradients(tower_grads)
#创建了一个操作 train_opt,利用函数opt.apply_gradients() 函数将平均梯度应用到模型参数上,实现了梯度下降的一次迭代。,并且会在应用完梯度之后更新全局步数 global_step。
train_opt = opt.apply_gradients(grads, global_step=global_step)
#summary 会在训练过程中定期被写入到日志文件中,然后可以通过 TensorBoard 可视化工具进行查看和分析。
#tf.summary.scalar() 用于记录标量值,如损失函数值、准确率等。
summaries.append(tf.summary.scalar('loss', loss))
summaries.append(tf.summary.scalar('less_one_accuracy', less_one_accuracy))
summaries.append(tf.summary.scalar('less_three_accuracy', less_three_accuracy))
summaries.append(tf.summary.scalar('lr', lr_op))
#tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES) 获取所有可训练的变量。
weights_list = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES)
#tf.summary.histogram() 用于记录变量的分布情况,如权重、梯度等。
for var in weights_list:
summaries.append(tf.summary.histogram(var.op.name, var))
for grad, var in grads:
if grad is not None:
summaries.append(tf.summary.histogram(var.op.name + '/gradients', grad))
#利用函数tf.train.Saver创建TensorFlow 中用于保存和恢复模型的Saver对象。Saver 对象允许将模型的参数保存到磁盘上,以便在需要时进行恢复或继续训练。
#tf.global_variables()表示要保存的所有全局变量,max_to_keep=None表示保留所有模型。
saver = tf.train.Saver(tf.global_variables(), max_to_keep=None)
#将summaries合并,它将在训练期间被写入日志文件中。
summary_op = tf.summary.merge(summaries)
#初始化全局变量
init_op = tf.global_variables_initializer()
#配置 TensorFlow 的运行时选项
config = tf.ConfigProto(allow_soft_placement = True)
#动态分配GPU内存
config.gpu_options.allow_growth = True
#下面一段代码是整个训练过程的主体部分
#tf.Session(config=config) 创建了一个 TensorFlow 会话,用于执行计算图中的操作。通过配置 config,设置了会话的一些运行选项。
with tf.Session(config=config) as sess:
#跟踪训练中的总步数,以便在保存模型检查点和记录训练日志时使用。
total_step = 0
#初始化所有全局变量为默认值
sess.run(init_op)
#创建了一个用于写入 TensorBoard 日志的文件写入器,将 TensorFlow 计算图写入日志目录。
summary_writer = tf.summary.FileWriter(FLAGS.log_folder, sess.graph)
# 判断是否使用了预训练模型,则会从指定路径加载预训练模型。并输出带有颜色前缀的预训练模型来自于那哪个路径的的信息
if FLAGS.use_pretrain:
pretrained_model_path = os.path.join(FLAGS.model_folder, FLAGS.regularization, 'model.ckpt')
restorer = tf.train.Saver(tf.global_variables())
restorer.restore(sess, '-'.join([pretrained_model_path, str(FLAGS.ckpt_step)]))
print(Notify.INFO, 'Pre-trained model restored from %s' %
('-'.join([pretrained_model_path, str(FLAGS.ckpt_step)])), Notify.ENDC)
total_step = FLAGS.ckpt_step
#迭代训练的每一个轮次
for epoch in range(FLAGS.epoch):
#重新初始化数据集迭代器,以确保每个样本都能被遍历到。
step = 0
sess.run(training_iterator.initializer)
#迭代每个GPU所需要处理的样本数量,保证每个GPU处理差不多的数据
for _ in range(int(training_sample_size / FLAGS.num_gpus)):
#记录每个批次数据处理的起始时间
start_time = time.time()
try:
#多次执行以下操作,在每个步骤中进行训练、计算损失和精度,并且生成日志信息。同时,周期性地将训练过程中的摘要信息写入到 TensorBoard 日志中。
out_summary_op, out_opt, out_loss, out_less_one, out_less_three = sess.run(
[summary_op, train_opt, loss, less_one_accuracy, less_three_accuracy])
#当数据集的所有元素都被遍历完毕时,迭代器会抛出OutOfRangeError异常,此时程序会输出"End of dataset"并终止当前循环,因为数据集已经遍历完毕。
except tf.errors.OutOfRangeError:
print("End of dataset")
break
#计算处理一个批次的数据需要多少时间
duration = time.time() - start_time
#保证在每个训练步骤的开始打印信息
if step % FLAGS.display == 0:
#使用print 函数输出带有颜色前缀的训练的相关信息,如当前训练的轮数(epoch)、步数(step)、总步数(total_step)、损失(loss)、小于1像素的精度(< 1px)、小于3像素的精度(< 3px)以及每步的耗时。
print(Notify.INFO,
'epoch, %d, step %d, total_step %d, loss = %.4f, (< 1px) = %.4f, (< 3px) = %.4f (%.3f sec/step)' %
(epoch, step, total_step, out_loss, out_less_one, out_less_three, duration), Notify.ENDC)
#每个一定的步数将summary写入TensorBoard 日志中,以便在 TensorBoard 中可视化监控训练的进度和性能。
if step % (FLAGS.display * 10) == 0:
summary_writer.add_summary(out_summary_op, total_step)
#下面一段代码代码用于定期保存模型的检查点(checkpoint),以便在训练过程中进行模型的恢复和继续训练,或者在训练结束后进行模型的加载和评估。
#确保每隔一定步数进行一次模型检查点的保存操作。
if (total_step % FLAGS.snapshot == 0 or step == (training_sample_size - 1)):
#创建保存检查点的路径以及文件夹,并输出保存检查点文件夹的路径
model_folder = os.path.join(FLAGS.model_folder, FLAGS.regularization)
if not os.path.exists(model_folder):
os.mkdir(model_folder)
ckpt_path = os.path.join(model_folder, 'model.ckpt')
print(Notify.INFO, 'Saving model to %s' % ckpt_path, Notify.ENDC)
#。它将当前会话sess中的模型参数保存到指定的路径ckpt_path中,并使用global_step来表示保存的模型的步数
saver.save(sess, ckpt_path, global_step=total_step)
#将已完成的训练步数和全局总步数都进行递增操作
step += FLAGS.batch_size * FLAGS.num_gpus
total_step += FLAGS.batch_size * FLAGS.num_gpus下面定义了一个名为main的函数,该函数是整个程序的入口点,它接受的参数argv 是一个字符串列表,用于存储命令行参数。当你在命令行中运行Python脚本时,可以向脚本传递参数。argv 列表中的第一个元素是脚本的名称,后面的元素是传递给脚本的参数。在这个函数中,argv=None的意思是如果没有传递任何命令行参数,则默认为 None。
def main(argv=None):
# 准备所有可能的训练样本列表sample_list,其中包括blendedmvs、blendedmvg、dtu、eth3d,都是根据指定的路径将相应数据集的样本都取出来。
if FLAGS.train_blendedmvs:
sample_list = gen_blendedmvs_path(FLAGS.blendedmvs_data_root, mode='training_mvs')
if FLAGS.train_blendedmvg:
sample_list = gen_blendedmvs_path(FLAGS.blendedmvs_data_root, mode='training_mvg')
if FLAGS.train_dtu:
sample_list = gen_dtu_resized_path(FLAGS.dtu_data_root)
if FLAGS.train_eth3d:
sample_list = gen_eth3d_path(FLAGS.eth3d_data_root, mode='training')
#对样本列表进行随机打乱,以增加训练的随机性,有助于模型更好地泛化。
random.shuffle(sample_list)
#调用刚刚定义的train函数根据打乱的样本列表对MVSNet模型进行训练
train(sample_list)if __name_ == '_main__'是python中的常见用法,它的作用就是当该脚本被直接执行时就执行下述操作,如果该脚本是被其他脚本当作模块调用,就不执行下面的操作。
if __name__ == '__main__':
#输出训练视图的数量
print ('Training MVSNet with totally %d views inputs (including reference view)' % FLAGS.view_num)
#调用 tf.app.run() 函数,这个函数会执行main()函数。tf.app.run() 的作用是解析命令行参数,然后调用 main() 函数,并将解析后的参数传递给它。
tf.app.run()train.py脚本总结:它是训练MVSNet模型的脚本,它的总体框架可总结如下:
-
导入必要的库
-
定义全局变量:定义了一些全局变量,如训练参数、数据集路径等。
-
定义辅助函数:在线数据增强online_augmentation、数据生成器类MVSGenerator、平均梯度函数average_gradients
-
定义模型训练函数:train()函数,该函数用于训练 MVSNet 模型。这个函数包括数据集的准备、优化器的定义、梯度更新、模型的构建、模型的初始化、训练循环、日志以及保存训练过程中的模型等功能。
-
定义程序入口:main()函数,用于解析命令行参数,并调用train()函数开始训练。
-
命令行入口:使用tf.app.run()调用main()函数,解析命令行参数并启动程序。
3.4.5 validate.py(验证MVSNet模型的脚本)
导入软件包(与训练脚本train.py里面导入的软件包差不多)
from __future__ import print_function
import os
.....
import cv2
....
sys.path.append("../")
from tools.common import Notify
....以下一段代码定义了大量的全局变量,包括数据集路径、配置参数、模型路径等。
#定义了BlendedMVS、eth3d、DTU、验证数据集的根目录路径
tf.app.flags.DEFINE_string('blendedmvs_data_root', '/data/BlendedMVS/dataset_low_res',
"""Path to dtu dataset.""")
tf.app.flags.DEFINE_string('eth3d_data_root', '/data/eth3d/lowres/training/undistorted',
"""Path to dtu dataset.""")
tf.app.flags.DEFINE_string('dtu_data_root', '/data/dtu',
"""Path to dtu dataset.""")
tf.app.flags.DEFINE_string('validate_set', 'dtu',
"""Dataset to validate.""")
#定义了一个场景中的视图数量为3,其中包括一张参考图和2张其他视角的图片(源图)
tf.app.flags.DEFINE_integer('view_num', 3,
"""Number of images (1 ref image and view_num - 1 view images).""")
#定义了最大的深度平面数量为256
tf.app.flags.DEFINE_integer('max_d', 256,
"""Maximum depth step when training.""")
#定义了最大的图像宽度为640
tf.app.flags.DEFINE_integer('max_w', 640,
"""Maximum image width when training.""")
#定义了最大的图像高度为512
tf.app.flags.DEFINE_integer('max_h', 512,
"""Maximum image height when training.""")
#定义了构建代价体时下采样的比例为0.25
tf.app.flags.DEFINE_float('sample_scale', 0.25,
"""Downsample scale for building cost volume.""")
#定义了构建代价体时间隔比例为1
tf.app.flags.DEFINE_float('interval_scale', 1,
"""Downsample scale for building cost volume.""")
#定义了验证过程中批次数据的批次大小为1
tf.app.flags.DEFINE_integer('batch_size', 1,
"""training batch size""")
#定义了是否采用逆深度方法的布尔值为False,即不采用逆深度的方法求取单应性变换矩阵
tf.app.flags.DEFINE_bool('inverse_depth', False,
"""Apply inverse depth.""")
#定义采用的正则化类型为3D CNNs
tf.app.flags.DEFINE_string('regularization', '3DCNNs',
"""Regularization type.""")
#定义了保存预训练模型检查点的路径
tf.app.flags.DEFINE_string('pretrained_model_ckpt_path',
'/data/tf_model/3DCNNs/BlendedMVS/blended_augmented/model.ckpt',
"""Path to restore the model.""")
#定义了恢复预训练模型的检查点步数为150000,意为要从第150000步处恢复预训练模型
tf.app.flags.DEFINE_integer('ckpt_step', 150000,
"""ckpt step.""")
#定义了保存验证结果的路径
tf.app.flags.DEFINE_string('validation_result_path',
'/data/tf_model/3DCNNs/BlendedMVS/blended_augmented/validation_results.txt',
"""Path to restore the model.""")
FLAGS = tf.app.flags.FLAGS下面定义了一个名为MVSGenerator的类,这个类和train.py里面定义的类MVSGenerator基本上都相同.这里就没做解析了,因为train.py里面对于数据生成器MVSGenerator解析得非常的详细。
该类是数据生成器,用于生成验证数据,实际作用其实就是数据的预处理,调用了MVSNet/mvsnet/preprocess.py脚本中定义的很多函数。该函数从给定的样本列表sample_list中提取每个样本的图片、相机参数和深度图,对其进行预处理,将处理的结果作为MVSNet模型验证过程中输入的批次数据。
class MVSGenerator:
......定义了一个名为validate_mvsnet的函数,该函数的作用就是调用之前定义的一系列全局变量,比如数据集路径、配置参数、模型路径,还有数据生成器MVSGenerator来验证MVSNet模型。其接受的参数mvs_list是一个存有验证样本集的列表,每个样本存储着图像、相机参数和深度图等数据,通过类MVSGenerator(数据生成器)对该列表的样本迭代依次取出进行预处理生成验证数据。
def validate_mvsnet(mvs_list):
#输出验证样本集的样本数量
print ('Validation sample number: ', len(mvs_list))
#利用数据生成器MVSGenerator迭代验证样本集中的每个样本,对每个样本都进行预处理。利用函数iter创建生成验证数据的迭代器mvs_generator
mvs_generator = iter(MVSGenerator(mvs_list, FLAGS.view_num))
#将生成的验证数据(深度图、图像、相机参数)都指定为float32类型
generator_data_type = (tf.float32, tf.float32, tf.float32)
#利用函数tf.data.Dataset.from_generator,并调用用于生成验证数据的迭代器mvs_generator和数据类型generator_data_type创建验证数据集mvs_set,并将数据集划分为合适大小的批次,并为每个批次数据后设置固定大小的缓冲区,以便可以在一个批次数据快处理完的时候缓存下一个批次的数据,以加快验证速度。
mvs_set = tf.data.Dataset.from_generator(lambda: mvs_generator, generator_data_type)
mvs_set = mvs_set.batch(FLAGS.batch_size)
mvs_set = mvs_set.prefetch(buffer_size=1)
#创建用于迭代验证数据集的迭代器mvs_iterator
mvs_iterator = mvs_set.make_initializable_iterator()
#利用验证数据迭代器mvs_iterator和函数get_next获取下一个批次的验证数据
images, cams, depth_image = mvs_iterator.get_next()
#以下一段代码用于对输入的数据进行整理和预处理
#将预处理得到的图像、相机参数、深度图像设置为Tensorflow张量,并为其设置特定的形状
images.set_shape(tf.TensorShape([None, FLAGS.view_num, None, None, 3]))
cams.set_shape(tf.TensorShape([None, FLAGS.view_num, 2, 4, 4]))
depth_image.set_shape(tf.TensorShape([None, None, None, 1]))
#利用函数tf.slice从相机参数cams中切片出深度起始值、深度间隔、深度数量,并为这些变量重新设置形状,只有在获取深度数量depth_num的时候还要使用tf.cast函数取整
depth_start = tf.reshape(tf.slice(cams, [0, 0, 1, 3, 0], [FLAGS.batch_size, 1, 1, 1, 1]),
[FLAGS.batch_size])
depth_interval = tf.reshape(tf.slice(cams, [0, 0, 1, 3, 1], [FLAGS.batch_size, 1, 1, 1, 1]),
[FLAGS.batch_size])
depth_num = tf.cast(tf.reshape(tf.slice(cams, [0, 0, 1, 3, 2], [1, 1, 1, 1, 1]), []), 'int32')
#判断是否采用逆深度方法,如果使用则采用下面的方法获取深度范围结束值,否则通过已知量depth_start、depth_num、depth_interval计算深度范围结束值。
if FLAGS.inverse_depth:
depth_end = tf.reshape(
tf.slice(cams, [0, 0, 1, 3, 3], [FLAGS.batch_size, 1, 1, 1, 1]), [FLAGS.batch_size])
else:
depth_end = depth_start + (tf.cast(depth_num, tf.float32) - 1) * depth_interval
#以下一段代码用于图像的归一化
#定义一个空列表,用于存储归一化后的图像
normalized_images = []
#利用for循环遍历每一个批次的视图
for view in range(0, FLAGS.view_num):
#利用函数tf.slice从图像images中获取指定视角view的图像,并用tf.squeeze将图像中为的维度压缩掉
image = tf.squeeze(tf.slice(images, [0, view, 0, 0, 0], [-1, 1, -1, -1, 3]), axis=1)
#对图像进行归一化处理
image = tf.image.per_image_standardization(image)
#将归一化后的图像加入列表normalized_images中
normalized_images.append(image)
#将列表normalized_images变为轴axis=1的张量
images = tf.stack(normalized_images, axis=1)
#下面一段代码会根据选择的正则化方法不同,从而选择model.py和loss.py当中不同的函数进行深度估计和精度指标计算
#如果MVSNet模型选择3D CNN进行正则化,则调用model.py中的inference估计深度图和概率图
if FLAGS.regularization == '3DCNNs':
depth_map, prob_map = inference(
images, cams, FLAGS.max_d, depth_start, depth_interval)
#如果MVSNet模型选择GRU进行正则化,则调用model.py中的nference_winner_take_all估计概率图和深度图
elif FLAGS.regularization == 'GRU':
depth_map, prob_map = inference_winner_take_all(images, cams,
depth_num, depth_start, depth_end, reg_type='GRU', inverse_depth=FLAGS.inverse_depth)
#根据inverse_depth参数的值,判断是否采用逆深度法,根据是否采用逆深度法选择不同的损失计算方法
#如果要使用逆深度法,则通过tf.ones_like获取深度间隔,并调用loss.py中的mvsnet_regression_loss函数计算损失和精度指标。否则就使用正常的深度间隔,并调用loss.py中的mvsnet_regression_loss函数计算损失和精度指标。
if FLAGS.inverse_depth:
interval = tf.ones_like(depth_interval)
loss, less_one_accuracy, less_three_accuracy = mvsnet_regression_loss(
depth_map, depth_image, interval)
else:
loss, less_one_accuracy, less_three_accuracy = mvsnet_regression_loss(
depth_map, depth_image, depth_interval)
#定义初始化全局变量为默认值的操作init_op
init_op = tf.global_variables_initializer()
#定义Tensorflow会话的运行选项
config = tf.ConfigProto()
#动态分配GPU的内存
config.gpu_options.allow_growth = True
#初始化存储平均损失ave_loss、平均精度ave_per1、ave_per3的变量为0
ave_loss = 0
ave_per1 = 0
ave_per3 = 0
#获取存储train.py训练出来的MVSNet模型(预训练模型)的检查点的路径。其中FLAGS.pretrained_model_ckpt_path包含目录和文件夹两部分用函数os.path.split将其分离开,并只取其中的第一个元素,就是目录。
model_folder = os.path.split(FLAGS.pretrained_model_ckpt_path)[0]
#下面一段代码是整个验证过程的主体部分
#tf.Session(config=config) 创建了一个TensorFlow会话,并通过配置config,设置了会话的一些运行选项。
with tf.Session(config=config) as sess:
#调用操作init_op初始化所有全局变量为默认值
sess.run(init_op)
#初始化验证过程中的总步数,以便保存验证过程中的模型检查点
total_step = 0
#如果存储train.py训练出来的MVSNet模型(预训练模型)的检查点的路径不为空则执行以下操作。
if FLAGS.pretrained_model_ckpt_path is not None:
#利用tf.global_variables()获取全局变量,并用tf.train.Saver创建对象restorer,用于恢复train.py训练出来的MVSNet模型(预训练模型)
restorer = tf.train.Saver(tf.global_variables())
#将预训练模型中所有的参数加载到本次Tensorflow会话中
restorer.restore(
sess, '-'.join([FLAGS.pretrained_model_ckpt_path, str(FLAGS.ckpt_step)]))
#输出带有颜色的预训练模型的路径信息
print(Notify.INFO, 'Pre-trained model restored from %s' %
('-'.join([FLAGS.pretrained_model_ckpt_path, str(FLAGS.ckpt_step)])), Notify.ENDC)
total_step = FLAGS.ckpt_step
#重新初始化验证数据集迭代器,以确保每个样本都能被遍历到。
sess.run(mvs_iterator.initializer)
#遍历每一个验证数据集中的样本
for step in range(len(mvs_list)):
#记录每个样本处理的起始时间
start_time = time.time()
try:
#多次执行以下操作,在每个步骤中进行训练、计算损失和精度,并且生成深度图。
out_loss, out_less_one, out_less_three, out_depth_map = sess.run([
loss, less_one_accuracy, less_three_accuracy, depth_map])
#当数据集的所有元素都被遍历完毕时,迭代器会抛出OutOfRangeError异常,此时程序会输出"End of dataset"并终止当前循环,因为数据集已经遍历完毕。
except tf.errors.OutOfRangeError:
print("all dense finished") # ==> "End of dataset"
break
#计算每个样本的处理时间
duration = time.time() - start_time
#输出一个样本在验证过程的处理结果,包括步数、损失、精度、处理时间
print(Notify.INFO, 'depth map validation for %d, loss=%.3f, < 1 = %.3f, < 3 = %.3f. (%.3f sec/step)'
% (step, out_loss, out_less_one, out_less_three, duration),
Notify.ENDC)
#下面的ave_loss、ave_per1、ave_per3是所有样本的累计损失值和累计精度值(小于1和3的像素误差率)
ave_loss += out_loss
ave_per1 += out_less_one
ave_per3 += out_less_three
total_step += 1
#将累计的损失值和累计的精度值除以样本数量,求取平均损失值和精度值,并打印出来
ave_loss /= len(mvs_list)
ave_per1 /= len(mvs_list)
ave_per3 /= len(mvs_list)
print ('ave_loss', ave_loss)
print ('ave_per1', ave_per1)
print ('ave_per3', ave_per3)
#将验证过程的梳理结果写入指定文件validation_result_path中,包括损失值、精度值和模型检查点的步数
with open(FLAGS.validation_result_path, 'a') as log_file:
log_file.write('Model check point %d, L1 loss = %f, < 1 = %f, < 3 = %f \n'
% (int(FLAGS.ckpt_step), float(ave_loss), float(ave_per1), float(ave_per3)))下面定义了一个名为main的函数,该函数是程序的入口点。其接受的参数argv是一个字符串列表,用于存储命令行参数,在命令行中运行Python脚本就会通过该参数向脚本中传递命令行参数。argv中第一元素就是脚本的名称,后面存储的就是该脚本需要传入的参数,这里argv=None,说明不用向该脚本传递任何的命令行参数。
def main(argv=None):
#准备所有可能的验证集样本列表validate_set,包括blendedmvs、eth3d、dtu,根据各个数据集的根本路径取出数据集对应的样本
if FLAGS.validate_set == 'blendedmvs':
sample_list = gen_blendedmvs_path(FLAGS.blendedmvs_data_root, mode='validation')
elif FLAGS.validate_set == 'eth3d':
sample_list = gen_eth3d_path(FLAGS.eth3d_data_root, mode='validation')
elif FLAGS.validate_set == 'dtu':
sample_list = gen_dtu_resized_path(FLAGS.dtu_data_root, mode='validation')
#调用刚刚定义的验证模型的函数validate_mvsnet,根据验证样本集列表对MVSNet模型进行验证
validate_mvsnet(sample_list)if __name_ == '_main__'是python中的常见用法,它的作用就是当该脚本被直接执行时就执行下述操作,如果该脚本是被其他脚本当作模块调用,就不执行下面的操作。
if __name__ == '__main__':
#输出视图的数量
print ('Validating MVSNet with totally %d view inputs (including reference view)' % FLAGS.view_num)
#利用tf.app.run()解析命令行参数,并将解析好的参数传递给函数main,最后调用main函数,启动程序。
tf.app.run()validate.py总结:它是一个用于验证模型的脚本
-
导入软件包
-
定义全局变量:包括模型路径、数据集路径、配置参数等等
-
定义辅助函数:类MVSGenerator(数据生成器),对输入的验证数据集进行预处理。
-
定义模型验证函数:validate_mvsnet,用于验证MVSNet模型,其中包括打印验证样本集样本数量、利用MVSGenerator生成验证数据集、提取数据、整理数据、图像归一化、深度推断、损失计算、创建Tensorflow会话、加载模型、执行验证过程、保存验证结果
-
定义程序入口:main()函数,用于解析命令行参数,并调用validate_mvsnet()函数开始验证。
-
定义命令行人口:使用tf.app.run()调用main()函数,解析命令行参数并启动程序。
3.4.6 test.py(测试MVSNet模型的脚本)
导入软件包(与训练脚本train.py里面导入的软件包差不多)
from __future__ import print_function
import os
......
import cv2
......
sys.path.append("../")
from tools.common import Notify下面一段代码定义了一系列全局变量,包括有关保存模型检查点的参数、输入数据的相关参数、有关网络架构的参数。
#以下一段代码定义了有关保存模型检查点的参数
#定义了保存深度重建结果的文件路径,默认为None
tf.app.flags.DEFINE_string('dense_folder', None,
"""Root path to dense folder.""")
#定义了保存模型的检查点的路径,默认为/data/tf_model/3DCNNs/BlendedMVS/blended_augmented/model.ckpt
tf.app.flags.DEFINE_string('pretrained_model_ckpt_path',
'/data/tf_model/3DCNNs/BlendedMVS/blended_augmented/model.ckpt',
"""Path to restore the model.""")
#定义了保存模型的检查点的步数,默认为150000
tf.app.flags.DEFINE_integer('ckpt_step', 150000,
"""ckpt step.""")
#以下一段代码定义了有关输入数据的参数
#定义了输入视图的数量,默认为5,其中一张参考图,4张源图
tf.app.flags.DEFINE_integer('view_num', 5,
"""Number of images (1 ref image and view_num - 1 view images).""")
#定义了最大的深度平面数量,默认为256
tf.app.flags.DEFINE_integer('max_d', 256,
"""Maximum depth step when testing.""")
#定义了最大的图像宽度,默认为1600
tf.app.flags.DEFINE_integer('max_w', 1600,
"""Maximum image width when testing.""")
#定义了最大的图像高度,默认为1200
tf.app.flags.DEFINE_integer('max_h', 1200,
"""Maximum image height when testing.""")
#定义了构建代价体时下采样的比例,默认为0.25
tf.app.flags.DEFINE_float('sample_scale', 0.25,
"""Downsample scale for building cost volume (W and H).""")
#定义了构建代价体时间隔的比例,默认为0.8
tf.app.flags.DEFINE_float('interval_scale', 0.8,
"""Downsample scale for building cost volume (D).""")
#定义了基础图像的大小,默认为8
tf.app.flags.DEFINE_float('base_image_size', 8,
"""Base image size""")
#定义了测试批次的大小,默认为1
tf.app.flags.DEFINE_integer('batch_size', 1,
"""Testing batch size.""")
#定义了一个布尔值,是否允许自适应的调整图像的尺寸,以适应网络结构,包括裁剪和缩放,默认为True
tf.app.flags.DEFINE_bool('adaptive_scaling', True,
"""Let image size to fit the network, including 'scaling', 'cropping'""")
#下面一段代码定义了有关网络架构的参数
#定义了正则化网络类型为“GRU”
tf.app.flags.DEFINE_string('regularization', 'GRU',
"""Regularization method, including '3DCNNs' and 'GRU'""")
#定义了布尔值,是否对测试过程中的深度图进行细化,默认值为False
tf.app.flags.DEFINE_boolean('refinement', False,
"""Whether to apply depth map refinement for MVSNet""")
#定义了布尔值,是否采用逆深度法,默认值为True
tf.app.flags.DEFINE_bool('inverse_depth', True,
"""Whether to apply inverse depth for R-MVSNet""")FLAGS是Tensorflow常见的约定,用于管理和定义命令行,允许在命令行运行脚本的时候设置命令行参数。
FLAGS = tf.app.flags.FLAGS
下面定义了一个名为MVSGenerator的类,该类是数据生成器,用于生成测试数据,实际作用其实就是数据的预处理,调用了MVSNet/mvsnet/preprocess.py脚本中定义的很多函数。该函数从给定的样本列表sample_list中提取每个样本的图片、相机参数和深度图,对其进行预处理,将处理的结果作为MVSNet模型测试过程中输入的批次数据。
class MVSGenerator:
##构造函数__init__用于构造类MVSGenerator,并初始化该类实例对象的一些属性,如样本列表sample_list,视角数量view_num,样本数量sample_num,样本处理计数器(处理完一个样本,计数器就加1)counter。该函数接受的参数就样本列表sample_list和视角数量view_num。
def __init__(self, sample_list, view_num):
self.sample_list = sample_list
self.view_num = view_num
self.sample_num = len(sample_list)
self.counter = 0
#定义了一个名为__iter__的函数,该函数是类MVSGenerator生成测试数据的迭代体。之所以为迭代体是因为这个函数每次从样本列表sample_list只取一个样本,然后加载该样本里面的图像、相机参数和深度图,对其进行预处理(裁剪、缩放和掩码等处理),将处理完毕的结果返回给MVSNet测试模型,作为MVSNet测试模型输入的批次数据,然后接着处理下一个样本,直到样本列表里面的样本都被处理完,即self.counter=self.sample_num 。
def __iter__(self):
#定义了一个无限循环
while True:
#从样本列表中取出一个样本,命名为data
for data in self.sample_list:
#从样本中读取相机参数和图像存于列表images和cams中
images = []
cams = []
#os.path.basename用于获取该样本数据里面的图像文件路径,然后用os.path.splitext将文件名和扩展名分开,最后用[0]获取去除扩展名的文件名。
image_index = int(os.path.splitext(os.path.basename(data[0]))[0])
#获取这个样本中图像的数量,也因为data中是包括相机参数(相机参数里面包含深度)以及图像的,因此要除以2
selected_view_num = int(len(data) / 2)
#遍历所有视图,但是遍历的范围不能超过设定的视图数量view_num和实际的视图数量selected_view_num
for view in range(min(self.view_num, selected_view_num)):
#获取该样本data的图像文件路径,位于2 * view的位置,然后用file_io.FileIO打开文件
image_file = file_io.FileIO(data[2 * view], mode='r')
#从图像文件image_file中以RGB的方式读取图像
image = scipy.misc.imread(image_file, mode='RGB')
#将图像格式从RGB变为BGR,因为Opencv的图像通道顺序是BGR
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
#获取该样本data的相机参数文件路径,位于2 * view+1的位置,然后用file_io.FileIO打开文件
cam_file = file_io.FileIO(data[2 * view + 1], mode='r')
#利用preprocess.py里面定义的函数load_cam从cam_file读取相机参数
cam = load_cam(cam_file, FLAGS.interval_scale)
#如果相机参数中的深度为0,则将其设为FLAGS.max_d的值
if cam[1][3][2] == 0:
cam[1][3][2] = FLAGS.max_d
#将图像和相机参数加入对应的列表中
images.append(image)
cams.append(cam)
#判断实际的视图数量selected_view_num是否小于设定的视图数量view_num,如果是则说明一个样本里面包含的视图数量不满足设定的视图数量,则采取如下操作:反复从同一个视角的图像文件和相机参数文件中读取数据,以填充selected_view_num达到view_num。
if selected_view_num < self.view_num:
for view in range(selected_view_num, self.view_num):
image_file = file_io.FileIO(data[0], mode='r')
image = scipy.misc.imread(image_file, mode='RGB')
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
cam_file = file_io.FileIO(data[1], mode='r')
cam = load_cam(cam_file, FLAGS.interval_scale)
images.append(image)
cams.append(cam)
#最后输出第一个相机参数的范围信息,代表空间位置范围
print ('range: ', cams[0][1, 3, 0], cams[0][1, 3, 1], cams[0][1, 3, 2], cams[0][1, 3, 3])
#确定一个适当的大小来调整输入的尺寸
#resize_scale是最终的缩放比例,这里初始化为1,表示对输入的图像和相机参数不做任何的缩放操作
resize_scale = 1
#根据参数adaptive_scaling判断是否自适应的调整图像的尺寸,以适应网络结构,结果是True
if FLAGS.adaptive_scaling:
#初始化缩放的高宽比例为0
h_scale = 0
w_scale = 0
#遍历每一个视图
for view in range(self.view_num):
#计算输入图像的高度和宽度与FLAGS.max_h、FLAGS.max_w的比例,以确定缩放比例,并且确保图像尺寸并不会超过设定的最大图像尺寸。
height_scale = float(FLAGS.max_h) / images[view].shape[0]
width_scale = float(FLAGS.max_w) / images[view].shape[1]
#将计算的比例给缩放的高宽比例赋值,只记录最大的缩放高宽比例
if height_scale > h_scale:
h_scale = height_scale
if width_scale > w_scale:
w_scale = width_scale
#如果计算出来的比例比1大,说明图像尺寸并会超过设定的最大图像尺寸。退出程序运行
if h_scale > 1 or w_scale > 1:
print ("max_h, max_w should < W and H!")
exit(-1)
#将高宽缩放比例中较大的一个赋值给最终的缩放比例resize_scale
resize_scale = h_scale
if w_scale > h_scale:
resize_scale = w_scale
#利用计算的缩放比例resize_scale对输入的图像和相机参数处理
scaled_input_images, scaled_input_cams = scale_mvs_input(images, cams, scale=resize_scale)
#对相机参数和图像进行裁剪以适应网络结构
croped_images, croped_cams = crop_mvs_input(scaled_input_images, scaled_input_cams)
#将裁剪后的图片进行中心化
centered_images = []
for view in range(self.view_num):
centered_images.append(center_image(croped_images[view]))
#对相机参数进行下采样以便构建代价体
real_cams = np.copy(croped_cams)
scaled_cams = scale_mvs_camera(croped_cams, scale=FLAGS.sample_scale)
#将处理完后的样本数据返回给MVSNet模型作为测试数据,并将计数器counter+1,表示处理完一个样本。
scaled_images = []
for view in range(self.view_num):
scaled_images.append(scale_image(croped_images[view], scale=FLAGS.sample_scale))
scaled_images = np.stack(scaled_images, axis=0)
croped_images = np.stack(croped_images, axis=0)
scaled_cams = np.stack(scaled_cams, axis=0)
self.counter += 1
yield (scaled_images, centered_images, scaled_cams, image_index) 定义了一个名为mvsnet_pipeline的函数,该函数的作用就是调用之前定义的一系列全局变量,比如保存模型的检查点的相关参数、输入数据的相关参数、网络架构的相关参数,还有数据生成器MVSGenerator来测试MVSNet模型。其接受的参数mvs_list是一个存有测试样本集的列表,每个样本存储着图像、相机参数和深度图等数据,通过类MVSGenerator(数据生成器)对该列表的样本迭代依次取出进行预处理生成测试数据。
def mvsnet_pipeline(mvs_list):
#打印测试集样本数量
print ('Testing sample number: ', len(mvs_list))
#创建保存测试结果的路径
output_folder = os.path.join(FLAGS.dense_folder, 'depths_mvsnet')
if not os.path.isdir(output_folder):
os.mkdir(output_folder)
#利用数据生成器MVSGenerator迭代测试样本集中的每个样本,对每个样本都进行预处理。利用函数iter创建生成测试数据的迭代器mvs_generator
mvs_generator = iter(MVSGenerator(mvs_list, FLAGS.view_num))
#将生成的测试数据(深度图、图像、相机参数)都指定为float32类型
generator_data_type = (tf.float32, tf.float32, tf.float32, tf.int32)
#利用函数tf.data.Dataset.from_generator,并调用用于生成测试数据的迭代器mvs_generator和数据类型generator_data_type创建测试数据集mvs_set,并将数据集划分为合适大小的批次,并为每个批次数据后设置固定大小的缓冲区,以便可以在一个批次数据快处理完的时候缓存下一个批次的数据,以加快验证速度。
mvs_set = tf.data.Dataset.from_generator(lambda: mvs_generator, generator_data_type)
mvs_set = mvs_set.batch(FLAGS.batch_size)
mvs_set = mvs_set.prefetch(buffer_size=1)
#创建用于迭代测试数据集的迭代器mvs_iterator
mvs_iterator = mvs_set.make_initializable_iterator()
#利用测试数据迭代器mvs_iterator和函数get_next获取下一个批次的验证数据
scaled_images, centered_images, scaled_cams, image_index = mvs_iterator.get_next()
#以下一段代码用于对输入的数据进行整理和预处理
#将预处理得到的图像、相机参数、深度图像设置为Tensorflow张量,并为其设置特定的形状
scaled_images.set_shape(tf.TensorShape([None, FLAGS.view_num, None, None, 3]))
centered_images.set_shape(tf.TensorShape([None, FLAGS.view_num, None, None, 3]))
scaled_cams.set_shape(tf.TensorShape([None, FLAGS.view_num, 2, 4, 4]))
depth_start = tf.reshape(
tf.slice(scaled_cams, [0, 0, 1, 3, 0], [FLAGS.batch_size, 1, 1, 1, 1]), [FLAGS.batch_size])
depth_interval = tf.reshape(
tf.slice(scaled_cams, [0, 0, 1, 3, 1], [FLAGS.batch_size, 1, 1, 1, 1]), [FLAGS.batch_size])
depth_num = tf.cast(
tf.reshape(tf.slice(scaled_cams, [0, 0, 1, 3, 2], [1, 1, 1, 1, 1]), []), 'int32')
#判断是否采用逆深度方法和3D CNN正则化方法,如果使用则采用下面的方法获取深度范围结束值,否则通过已知量depth_start、depth_num、depth_interval计算深度范围结束值。
if FLAGS.inverse_depth:
if FLAGS.regularization == '3DCNNs' and FLAGS.inverse_depth:
depth_end = tf.reshape(
tf.slice(scaled_cams, [0, 0, 1, 3, 3], [FLAGS.batch_size, 1, 1, 1, 1]), [FLAGS.batch_size])
else:
depth_end = depth_start + (tf.cast(depth_num, tf.float32) - 1) * depth_interval
#下面一段代码会根据选择的正则化方法不同,从而选择model.py中不同的函数进行深度估计,并选择是否进行深度细化
#如果MVSNet模型选择3D CNN进行正则化,则调用model.py中的inference_mem(对内存要求更小)估计深度图和概率图
if FLAGS.regularization == '3DCNNs':
init_depth_map, prob_map = inference_mem(
centered_images, scaled_cams, FLAGS.max_d, depth_start, depth_interval)
#根据参数refinement的值判断是否要调用model.py里面的depth_refine函数进行深度细化
if FLAGS.refinement:
ref_image = tf.squeeze(tf.slice(centered_images, [0, 0, 0, 0, 0], [-1, 1, -1, -1, 3]), axis=1)
refined_depth_map = depth_refine(
init_depth_map, ref_image, FLAGS.max_d, depth_start, depth_interval, True)
#如果MVSNet模型选择GRU进行正则化,则调用model.py中的nference_winner_take_all估计概率图和深度图
elif FLAGS.regularization == 'GRU':
init_depth_map, prob_map = inference_winner_take_all(centered_images, scaled_cams,
depth_num, depth_start, depth_end, reg_type='GRU', inverse_depth=FLAGS.inverse_depth)
#定义初始化所有的全局变量为默认值的操作init_op
init_op = tf.global_variables_initializer()
#定义初始化所有的局部变量为默认值的操作var_init_op
var_init_op = tf.local_variables_initializer()
#定义Tensorflow会话的运行选项
config = tf.ConfigProto()
#动态分配GPU的内存
config.gpu_options.allow_growth = True
#下面一段代码是整个测试过程的主体部分
#tf.Session(config=config) 创建了一个TensorFlow会话,并通过配置config,设置了会话的一些运行选项。
with tf.Session(config=config) as sess:
#调用操作init_op和var_init_op初始化所有全局变量和局部变量为默认值
sess.run(var_init_op)
sess.run(init_op)
#初始化验证过程中的总步数,以便保存验证过程中的模型检查点
total_step = 0
#如果存储的MVSNet模型的检查点的路径不为空则执行以下操作。
if FLAGS.pretrained_model_ckpt_path is not None:
#利用tf.global_variables()获取全局变量,并用tf.train.Saver创建对象restorer,用于恢复先前运行的MVSNet模型
restorer = tf.train.Saver(tf.global_variables())
#将先前保存的模型中所有的参数加载到本次Tensorflow会话中
restorer.restore(
sess, '-'.join([FLAGS.pretrained_model_ckpt_path, str(FLAGS.ckpt_step)]))
#输出带有颜色的先前保存的模型的路径信息
print(Notify.INFO, 'Pre-trained model restored from %s' %
('-'.join([FLAGS.pretrained_model_ckpt_path, str(FLAGS.ckpt_step)])), Notify.ENDC)
total_step = FLAGS.ckpt_step
#重新初始化测试数据集迭代器,以确保每个样本都能被遍历到。
sess.run(mvs_iterator.initializer)
#遍历每一个测试数据集中的样本
for step in range(len(mvs_list)):
#记录每个样本处理的起始时间
start_time = time.time()
try:
#多次执行以下操作,在每个步骤中计算初始深度图、概率图、数据预处理。
out_init_depth_map, out_prob_map, out_images, out_cams, out_index = sess.run(
[init_depth_map, prob_map, scaled_images, scaled_cams, image_index])
#当数据集的所有元素都被遍历完毕时,迭代器会抛出OutOfRangeError异常,此时程序会输出"End of dataset"并终止当前循环,因为数据集已经遍历完毕。
except tf.errors.OutOfRangeError:
print("all dense finished") # ==> "End of dataset"
break
#计算每个样本的处理时间
duration = time.time() - start_time
#输出一个样本在测试过程的处理结果,包括步数、处理时间
print(Notify.INFO, 'depth inference %d finished. (%.3f sec/step)' % (step, duration),
Notify.ENDC)
#将输出的结果由张量变为Numpy数组,并且都使用函数np.squeeze将为1的维度压缩掉。
out_init_depth_image = np.squeeze(out_init_depth_map)
out_prob_map = np.squeeze(out_prob_map)
out_ref_image = np.squeeze(out_images)
out_ref_image = np.squeeze(out_ref_image[0, :, :, :])
out_ref_cam = np.squeeze(out_cams)
out_ref_cam = np.squeeze(out_ref_cam[0, :, :, :])
out_index = np.squeeze(out_index)
#定义输出结果存储的路径,其中output_folder是输出文件夹路径,out_index是输出结果的索引,两者组合使得每个输出结果都构成独立的文件
init_depth_map_path = output_folder + ('/%08d_init.pfm' % out_index)
prob_map_path = output_folder + ('/%08d_prob.pfm' % out_index)
out_ref_image_path = output_folder + ('/%08d.jpg' % out_index)
out_ref_cam_path = output_folder + ('/%08d.txt' % out_index)
#将输出的测试结果保存为特定格式的文件
write_pfm(init_depth_map_path, out_init_depth_image)
write_pfm(prob_map_path, out_prob_map)
out_ref_image = cv2.cvtColor(out_ref_image, cv2.COLOR_RGB2BGR)
image_file = file_io.FileIO(out_ref_image_path, mode='w')
scipy.misc.imsave(image_file, out_ref_image)
write_cam(out_ref_cam_path, out_ref_cam)
total_step += 1下面定义了名为main的函数,该函数是程序的入口点。其接受的参数_是一个占位符,没有任何作用,表示该函数不接受任何的参数。
def main(_):
#调用预处理脚本preprocess.py里面的函数gen_pipeline_mvs_list来获取测试样本集
mvs_list = gen_pipeline_mvs_list(FLAGS.dense_folder)
#调用mvsnet_pipeline函数进行模型测试
mvsnet_pipeline(mvs_list)if __name_ == '_main__'是python中的常见用法,它的作用就是当该脚本被直接执行时就执行下述操作,如果该脚本是被其他脚本当作模块调用,就不执行下面的操作。
if __name__ == '__main__':
#输出训练视图的数量
print ('Testing MVSNet with totally %d view inputs (including reference view)' % FLAGS.view_num)
#调用 tf.app.run() 函数,这个函数会执行main()函数。tf.app.run() 的作用是解析命令行参数,然后调用 main() 函数,并将解析后的参数传递给它。
tf.app.run()test.py脚本总结:该脚本用于测试模型用
-
导入软件包
-
定义全局变量:包括保存模型的检查点的相关变量、网络架构相关变量、输入数据相关变量
-
定义辅助函数:类MVSGenerator(数据生成器),对输入的测试数据集进行预处理。
-
定义模型验证函数:mvsnet_pipeline,用于测试MVSNet模型,其中包括打印测试样本集样本数量、利用MVSGenerator生成测试数据集、提取数据、整理数据、深度推断、创建Tensorflow会话、加载模型、执行测试过程、保存测试结果
-
定义程序入口:main()函数,用于解析命令行参数,并调用mvsnet_pipeline()函数开始测试。
-
定义命令行人口:使用tf.app.run()调用main()函数,解析命令行参数并启动程序。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐



 12
12 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)