机器学习模型评估:欠拟合、过拟合与交叉验证策略
本文深入探讨机器学习模型评估相关知识。详细介绍欠拟合与过拟合的应对策略,同时介绍了交叉验证的主要作用和K折交叉验证的原理与特点。助力读者全面掌握模型评估要点。
内容摘要
本文深入探讨机器学习模型评估相关知识。详细介绍欠拟合与过拟合的应对策略,同时介绍了交叉验证的主要作用和K折交叉验证的原理与特点。助力读者全面掌握模型评估要点。
关键词:误差分析;欠拟合;过拟合;交叉检验
一、引言
在机器学习领域,构建模型只是第一步,准确评估模型性能至关重要。它不仅能帮助我们判断模型的优劣,还能指导我们改进模型,使其在实际应用中发挥更好的效果。然而,模型评估并非易事,其中涉及多种方法、复杂概念和潜在陷阱。本文将深入剖析机器学习里的模型评估相关知识,助力读者全面掌握这一关键环节。
二、图解欠拟合与过拟合
根据不同的坐标方式,欠拟合与过拟合的图解不同,主要有以下三种情况:
- 横轴为训练样本数量,纵轴为误差:
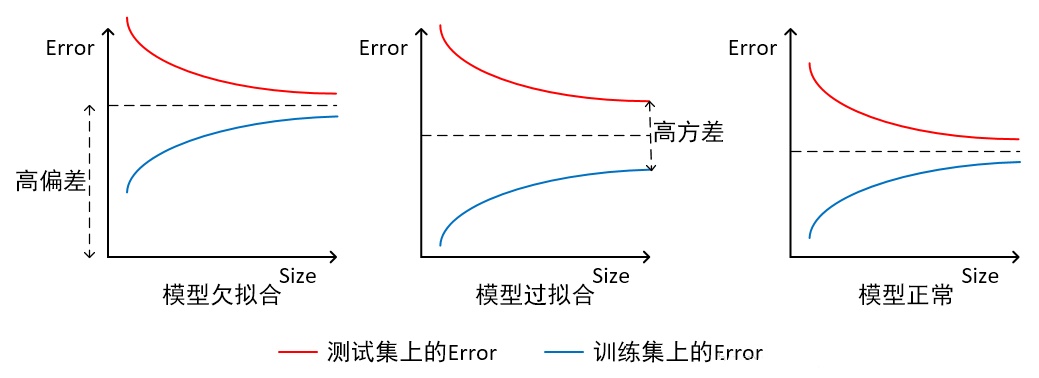
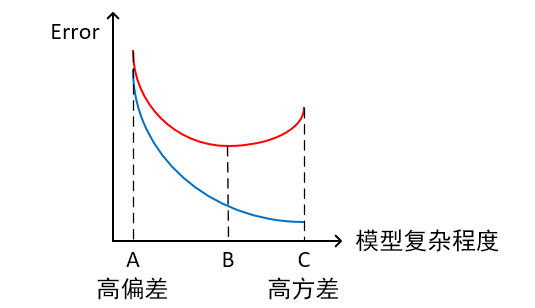
在此情况下,欠拟合的模型在训练集及测试集上同时具有较大的误差,此时模型的偏差较大;过拟合的模型在训练集上具有较小的误差,在测试集上具有较大的误差,此时模型的方差较大;而正常的模型在训练集及测试集上,同时具有相对较小的偏差及方差。 - 横轴为模型复杂程度,纵轴为误差:
 当模型处于欠拟合状态时,在训练集及测试集上同时具有较大的误差,偏差较大;过拟合时,在训练集上误差较小,测试集上误差较大,方差较大;模型复杂程度控制在某一合适点时为正常状态,此时误差较小。
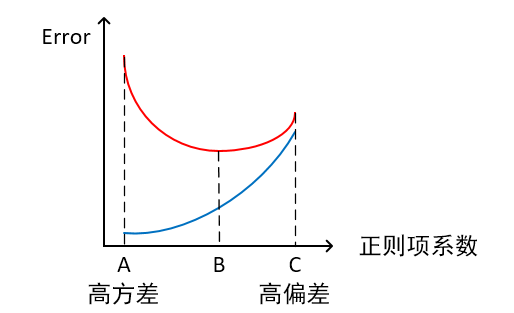
当模型处于欠拟合状态时,在训练集及测试集上同时具有较大的误差,偏差较大;过拟合时,在训练集上误差较小,测试集上误差较大,方差较大;模型复杂程度控制在某一合适点时为正常状态,此时误差较小。 - 横轴为正则项系数,纵轴为误差:
模型欠拟合时,在训练集及测试集上同时具有较大的误差,偏差较大;过拟合时,在训练集上具有较小的误差,在测试集上具有较大的误差,方差较大。通常,模型复杂程度控制在某一特定点时为最优状态。
三、如何解决欠拟合与过拟合
3.1 解决欠拟合的方法
- 添加其他特征项:比如添加组合、泛化、相关性、上下文特征、平台特征等。有时特征项不够会导致模型欠拟合,增加这些特征可以提高模型的拟合能力。
- 添加多项式特征:例如,将线性模型添加二次项或三次项使模型泛化能力更强。像FM(Factorization Machine)模型/FFM(Field - aware Factorization Machine)模型,本质是线性模型,增加了二阶多项式,保证了模型一定的拟合程度。
- 增加模型的复杂程度:可以选择更复杂的模型结构,如使用<深度神经网络>替代简单的线性模型。
- 减小正则化系数:正则化的目的是防止过拟合,但模型出现欠拟合时,需要减少正则化参数,让模型有更大的学习空间。
3.2 解决过拟合的方法
- 重新清洗数据:数据不纯会导致过拟合,此时需要重新清洗数据,去除噪声和异常值。
- 增加训练样本数量:更多的训练数据可以让模型学习到更普遍的规律,减少对训练集的依赖,降低过拟合风险。
- 降低模型复杂程度:选择更简单的模型结构,避免模型过于复杂而学习到训练数据中的噪声和特殊情况。
- 增大正则项系数:增强正则化力度,限制模型的复杂度,防止模型过度拟合训练数据。
- 采用丢弃法(Dropout):在训练的时候让神经元以一定的概率不工作,使模型泛化性更强,不会太依赖某些局部的特征。
- 使用早停法(Early Stopping):在模型训练过程中,监控验证集上的性能指标,当指标不再提升时停止训练,避免过度训练导致过拟合。
- 减少迭代次数:防止模型在训练集上过度训练,从而减少过拟合的可能性。
- 增大学习率:使模型参数更新的幅度更大,加快训练速度,但需要注意可能会导致模型不稳定。
- 添加噪声数据:增加数据的多样性,让模型学习到更鲁棒的特征。
- 在树结构中,对树进行剪枝:去除不必要的分支,降低模型复杂度。
- 减少特征项:去除一些相关性高或不重要的特征,简化模型输入。
解决欠拟合与过拟合的这些方法,需要根据实际问题、实际模型进行选择 。
四、交叉验证的主要作用
交叉验证(Cross Validation)主要用于如 主成分回归(Principal Component Regression,PCR) 和 偏最小二乘回归(Partial Least Squares Regression,PLS) 等建模应用中。其主要作用是为了得到更为稳健可靠的模型,对模型的 泛化误差 进行评估,得到模型泛化误差的近似值。当有多个模型可以选择时,通常选择 “泛化误差” 最小的模型。交叉验证的方法有许多种,但是最常用的是 留一交叉验证 和 K 折交叉验证。
五、理解 K 折交叉验证
K 折交叉验证 是将数据集切分成 K 份,验证集和测试集相互形成补集,循环交替。
- K 折交叉验证的一般步骤
将含有 N 个样本的数据集,分成 K 份,每份含有 N/KN/KN/K 个样本。选择其中一份作为测试集,另外 K−1K - 1K−1 份作为训练集,测试集就有 K 种情况。在每种情况中,用训练集训练模型,用测试集测试模型,计算模型的 泛化误差。交叉验证重复 K 次,每份验证一次,平均 K 次的结果或者使用其他结合方式,最终得到一个单一估测,得到模型最终的 泛化误差。 - K 折交叉验证的特点
一般 2≤K≤102 ≤K ≤102≤K≤10,10 折交叉验证 是最常用的。训练集中样本数量要足够多,一般至少大于总样本数的 50%,以保证模型能够学习到足够的信息。训练集和测试集必须从完整的数据集中均匀取样,以减少训练集、测试集与原数据集之间的偏差。
总结
欠拟合和过拟合是 机器学习 模型训练中常见的问题,通过合适的方法可以有效解决。交叉验证是评估模型 泛化能力 的重要手段,K 折交叉验证 在数据量有限时具有重要作用。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 25
25 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)