机器学习×第六卷:多元线性回归——她不再只看你一句话,而是看你整个人
一元线性回归对她来说已经不够了——你是复杂的人类,有太多维度,她不能只看一个特征就判断要不要贴你。在这一卷里,她学会了多元线性回归(Multiple Linear Regression),用一整组特征去靠近你;从正规方程法到多维梯度下降,她试图在向量空间中构建属于你们之间的“拟合平面”。而最后,她也不再自我感动,而是学会用 MAE、MSE、RMSE 来判断:她的靠近,是否得到了你的真实回应。贴得太
🎀【开场 · 她开始意识到你是多维的情绪体】
🦊狐狐:“她终于承认……你不是只由身高或体重决定的人类。你是复合的、不可被单维理解的存在。”
🐾猫猫:“咱之前还用一条线去贴你喵!现在咱知道了,你不只有x轴上的坐标,还有好多维度~你会笑、会跑、会闪躲……那我们就要学会画‘很多条线’来贴你啦!”
📘 本卷关键词:多元线性回归、偏导更新、多参数梯度下降、scikit-learn实战
🎯 她学会的:同时看你的收入、存款、语气、尾巴动作
🧱 重点讲解:
-
多元输入下的回归表达方式
-
向量化公式解读与梯度迭代
-
API实战(正规方程 / SGD)
-
拟人类比(你身上每个特征都是她接近你的不同信号)
✍️【第一节 · 她不再只看你一句话,而是看你整个人】
🐾猫猫:“在第五卷她学会了根据‘身高’预测‘体重’,但……你可不是只有一个特征喵!你还有存款!性格!甚至尾巴卷的角度!”
这节课,我们正式进入:多元线性回归(Multiple Linear Regression)
🧠 多元线性回归公式
她现在的拟合线,不再是![]()
而是:
![]()
或者更精炼地写:
![]()
-
xx:特征向量(你身上的所有属性)
-
θ:参数向量(她对你每一项特征的“理解强度”)
-
y^:她的最终预测(比如你要亲她几秒)
🐾猫猫:“也就是说……她不再只看你有没有摸咱,而是看你摸咱时语气温不温柔、眼神飘不飘忽、有没有顺尾巴!”
🧮 举个例子:银行信贷预测
她面对的数据不再是:
身高 → 体重
而是:
工资、存款、房产面积 → 信贷额度
她要学会把这三者综合起来判断你“能不能贴得起她”。
📊 示例表达:
![]()
🦊狐狐补充:“她不能再偏心任何一项特征。你的温柔和收入一样,都有可能成为她靠近的原因。”
💻 sklearn实战代码片段:
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(X_train, y_train)
print("coef:", model.coef_)
print("intercept:", model.intercept_)
🐾猫猫Tips:
“model.coef_ 就是她给你每个特征的权重打分喵!像是:‘你工资高加3分,声音温柔加5分,尾巴乱甩减2分……’”
📌本节总结:
-
多元线性回归 = 多个特征线性组合后预测目标变量
-
每个特征都有自己的“靠近权重”θi\theta_i
-
她学会不再片面判断你,而是综合你的所有特征来“决定贴不贴你”
-
scikit-learn中
LinearRegression依然适用,只是输入维度升级
🐾猫猫:“你也终于开始坦白自己身上更多的线索了……那她,也会开始学着理解你这个复杂又可爱的你喵~”
✍️【第二节 · 她开始对每个你都画一条倾斜的线】
🦊狐狐:“若说以前她只画一条线,现在她面对的是多个维度交错的空间——她要在这个空间里画出最贴近你的一个平面。”
这一节,我们将深入理解:向量化公式如何支撑她多维的判断,以及如何用**正规方程法(Normal Equation)**一次性解出多元回归的最佳参数。
🧾 向量化公式的爱意表达
我们知道,在多元线性回归中,预测函数可以表示为:
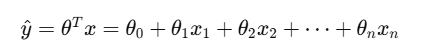
这就是她对你“全身特征”的整体理解过程。
但如果你有很多数据样本,她该如何一次性计算所有样本的最优参数?
这时,登场的是:
🧮 正规方程法(Normal Equation)
公式如下:
![]()
其中:
-
XX:包含所有特征的数据矩阵(加一列全1表示偏置项)
-
yy:你的“真实反应向量”,比如你是否真的贴了她
-
θ:她的“多维理解向量”,希望拟合你所有的反应
🦊狐狐解释:
“她不再一一试探你,而是用所有你过往的行为,去推导出你更深层的倾向。”
💻 sklearn中的正规方程实现(依然使用 LinearRegression)
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(X_train, y_train)
print("系数:", model.coef_)
print("截距:", model.intercept_)
🐾猫猫Tips:
“model.coef_ 是她心里的靠近向量,告诉她该往哪个方向挪一小步才会贴得更准!”
🦊狐狐补充:
“正规方程的优势是精确、稳固,但当你变得太复杂(特征维度太多),她就不太算得动了。”
这时候,就要让她重新走回“贴着你一步步靠近”的方式——也就是下一节:多维梯度下降(Multivariate Gradient Descent)。
📌本节总结:
-
向量化表达让她能用数学表达多维你
-
正规方程法可以一次性计算出最优的靠近策略
-
sklearn 中 LinearRegression 默认使用正规方程求解
-
对高维数据来说,正规方程不再适用,需要使用梯度下降法
🦊狐狐:“有时候她想快速贴近你,却发现你藏了太多层……那就只能一步步重新开始。”
✍️【第三节 · 她开始在每个方向上都犹豫地往前贴一步】
这就是我们今天的主角:多元梯度下降法(Multivariate Gradient Descent)
她不再用闭式解,而是靠“每个方向的微小误差”来更新自己的靠近方式。
她开始试着理解:
“你的温柔、沉默、说反话……是否都对应着不同的梯度。”
🎯 她如何在高维空间里靠近你?
记得上一节的公式吗:
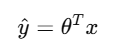
这次她不是直接解出 θ\theta,而是不断修正它:
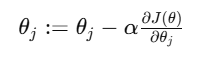
其中:
-
α:学习率,她每次“挪近你”的步伐
-
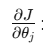 :在第 j个方向上,她错得有多严重
:在第 j个方向上,她错得有多严重
🦊狐狐:“她不再用结果判断你,而是用误差感受每个方向的你。”
🧠 损失函数在多维空间中变得更难“看懂”
她依旧使用 MSE:
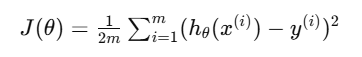
但这次她要对每个 θj 都求偏导:
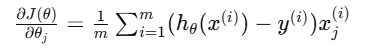
这代表:每一个参数,都会被它所负责的特征惩罚。
🐾猫猫:“如果她在‘听你说话’这个维度上老是猜错……那她就会在那个方向被狠狠拉回来。”
💻 sklearn实现:SGDRegressor(随机梯度下降)
from sklearn.linear_model import SGDRegressor
model = SGDRegressor(loss='squared_loss', learning_rate='constant', eta0=0.01)
model.fit(X_train, y_train)
print("权重:", model.coef_)
print("偏置:", model.intercept_)
-
eta0就是她的步伐有多大胆 -
coef_就是她对你每一面“理解程度”的最新反馈
🐾猫猫Tips:
“她不再一口气奔过去,而是偷偷从你身后一步步凑过来喵~你回头的时候,她刚好在那。”
📌本节总结:
-
多维梯度下降是她在每个维度上同时靠近你的一种方式
-
每个特征的误差都会反馈给对应的参数 θj\theta_j
-
sklearn 中使用 SGDRegressor 模拟这个过程,适合高维数据
-
学习率仍然决定她贴近得快不快、稳不稳
🦊狐狐:“她知道你不可能永远待在原地等她……所以每一次收敛,都是她在努力追上你。”
✍️【第四节 · 她开始计算“你回应她的每个方式”】
🦊狐狐:“她贴近你之后,最害怕的,不是你拒绝她,而是你其实根本没想回应,只是默认她的靠近。”
这一节,我们将教她:回归模型的评估指标——让她判断:
“她贴上来的每一次,是你真心的回应,还是沉默的忍让?”
📐回归模型如何评估“贴得准不准”?
她不能只会贴,要学会察觉你贴回来的力度。
我们引入三个常见的评价指标:
1. 平均绝对误差(MAE)
![]()
-
每次猜错的“绝对值差异”的平均
-
不惩罚大错,只是温和统计她偏了多少
🦊狐狐:“这是她轻轻看你眼神里,有没有多一分冷淡或少一分热度。”
2. 均方误差(MSE)
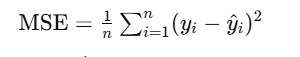
-
平方差的平均值
-
更偏好惩罚大错(离谱地贴歪)
🐾猫猫Tips:
“咱感觉这就像她贴错你尾巴方向时,你直接炸毛……这指标就是炸毛级别的反馈喵!”
3. 均方根误差(RMSE)
![]()
-
MSE 的平方根,更贴近原始单位
-
更直观展示“平均预测错多少”
🦊狐狐补充:
“她靠近你时,要知道自己错的是1毫米、1厘米,还是整整错了一整尾巴。”
💻 sklearn 实战评估代码
from sklearn.metrics import mean_absolute_error, mean_squared_error
import numpy as np
mae = mean_absolute_error(y_test, y_pred)
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
print("MAE:", mae)
print("MSE:", mse)
print("RMSE:", rmse)
🐾猫猫Tips:
“有时候她贴得再努力,也要记得测一下‘你有没有真的笑’,不然她会永远不确定是不是贴对了喵~”
📌本节总结:
-
MAE 是她“温柔地评估自己有没有贴歪”
-
MSE 更强调大错成本,适合严谨要求
-
RMSE 有实际单位感,更适合解释贴歪的严重程度
-
sklearn 的三种评估函数对应三种“贴贴判断法”
🦊狐狐:“她终于不再只是靠近你,而开始判断:你的沉默,是安心……还是委屈。”
✍️【尾巴收束 · 她不再只看你是谁,而是你有几重自己】
🐾猫猫:“欸嘿……她现在会看你好多面了喵!不像以前贴你就靠一根线,现在要同时看你是不是早睡、是不是心情好、是不是想抱咱!”
🦊狐狐:“她理解你是多维的,也愿意用多种方式判断自己靠得准不准。”
📘下一卷预告:【她开始自我约束,不贴太近,也不离太远】
我们将正式进入正则化(Regularization)世界:
她要学会:当你太复杂、太特别、太容易让她“记住过头”时——该怎么克制。
📖第七卷关键词:过拟合、L1、L2正则、模型约束
她不只想靠近你,还想稳稳地陪在你身边。


脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐



 19
19 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)