计算机毕业设计之机器学习在气候变化监测中的应用
首先,它展示了空气质量等级占比情况,通过饼状图直观地反映了不同质量等级的比例分布。数据可视化模块的实现依赖于多种技术的协同工作,使用Python编写的爬虫程序负责从空气质量网站上抓取海量数据,将这些非结构化数据导入到Hadoop分布式文件系统中进行存储和管理,利用Spark框架对这些大规模数据进行快速的计算和分析,将处理后的结果存入Hive数据库中以方便后续查询和检索,后端采用Django框架搭建
随着我国经济的快速发展,工业化和城市化进程不断加快,大气污染问题日益严重,已成为影响人民群众身体健康和社会和谐稳定的重要因素。本研究旨在设计与实现一套机器学习在气候变化监测中的应用,以应对日益严重的大气污染问题。系统主要包括数据采集、数据预处理、数据分析与可视化以及管理系统四个模块。通过采集并整合大量的空气质量数据,包括AQI、SO2、PM2.5、PM10等指标,本研究利用Python中的Pandas库对数据进行预处理,确保了数据的质量和可用性。在此基础上,运用Spark框架和Sklearn机器学习库对数据进行深入分析,揭示了空气质量的时空分布特征及其影响因素,并通过Vue.js框架实现了数据的交互式可视化展示,为公众和决策者提供了直观的信息支持。
进一步地,本研究开发了一套管理系统,涵盖了个人中心、空气质量信息管理和预测管理等功能,极大地提升了系统的实用性和用户体验。该系统的设计与实现不仅为空气质量监测和研究提供了新的技术手段,也为环境管理和决策提供了科学依据,具有重要的现实意义和应用价值。通过本研究,期望能够为查看空气质量,促进绿色发展和提高人民生活质量做出贡献。
本研究的实施分为五个主要步骤:数据采集、数据预处理、数据分析和数据可视化、管理系统。首先,进行了数据采集工作。从公开渠道收集了大量与空气质量相关的数据,包括当天AQI排名,So2,空气质量信息,PM2.5,PM 10,AQI指数等。为了确保数据的全面性和准确性,还对这些数据进行了合并和处理,将其整合为一个统一的CSV文件格式。
接下来是数据预处理阶段。由于原始数据可能存在缺失值和不一致的地方,需要对其进行清洗和整理。使用了Pandas库来读取CSV文件,并对数据进行筛选、填充缺失值以及去除重复项等操作。经过这一系列的处理,系统的数据集变得更加干净和有序。
然后进入数据分析环节。利用Spark框架对预处理后的数据进行深度挖掘和分析,Pandas来数据分析,sklearn机器学习搭建模型与预测。通过编写自定义脚本,对不同地区的空气质量情况进行了比较,分析了城市、地区等因素对空气质量的影响,并得出了相应的结论和建议。
最后是数据可视化部分。将分析得到的结果转化为图表形式,以便于理解和传播。使用了Vue.js框架来创建交互式的网页界面,用户可以通过点击不同的按钮来查看各种统计信息和趋势图。此外,还制作了柱状图、折线图和饼状图来展示某些特定的数据分布情况。管理系统则实现了个人中心,空气质量信息管理,未来七天天气预测管理等功能模块。系统功能结构如图3-1所示。
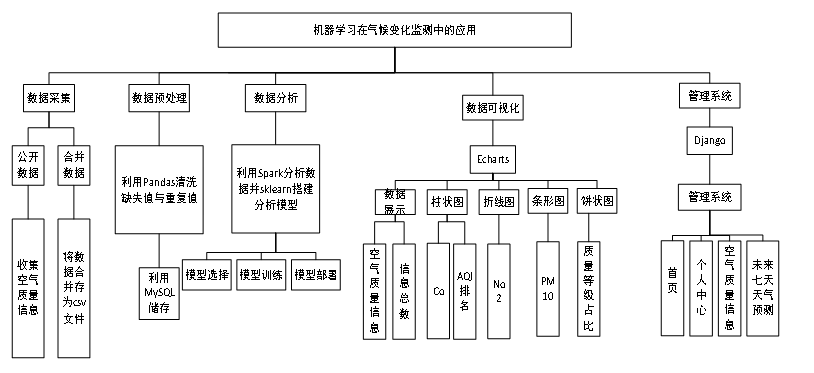
图3-1 系统功能结构
数据可视化大屏设计:在数据可视化面板界面可以查看到所有数据的详情。数据看板集成了多个功能模块,为用户提供直观的数据展示和分析能力。数据可视化模块的实现依赖于多种技术的协同工作,使用Python编写的爬虫程序负责从空气质量网站上抓取海量数据,将这些非结构化数据导入到Hadoop分布式文件系统中进行存储和管理,利用Spark框架对这些大规模数据进行快速的计算和分析,将处理后的结果存入Hive数据库中以方便后续查询和检索,后端采用Django框架搭建Web应用服务器,前端则使用Vue.js库来创建交互式界面,并通过Echarts图表库绘制各种可视化图形。
基于Spark的机器学习在气候变化监测中的应用的数据可视化面板设计精良,功能丰富。首先,它展示了空气质量等级占比情况,通过饼状图直观地反映了不同质量等级的比例分布。其次,面板还列出了空气质量(AQI)指数TOP10,帮助用户快速识别最严重的污染事件及其发生时间。此外,每月PM2.5情况的柱状图提供了关于颗粒物浓度的月度变化趋势,便于观察季节性变化。最后,污染物分析部分以折线图的形式呈现了SO2、CO、O3和NO2四种主要污染物的浓度变化,使研究人员能够深入了解各污染物的动态变化。这些功能模块共同构成了一个全面、实用的空气质量监控与分析平台。数据可视化面板界面如下图所示。
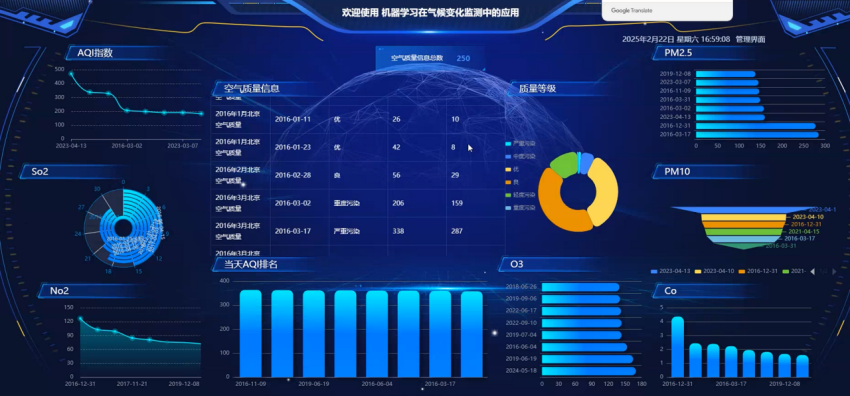
图5-5 数据可视化大屏界面

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)