【机器学习|学习笔记】决策树中的熵 (Entropy)、信息增益 (Information Gain) 和信息增益率 (Information Gain Ratio)详解。
【机器学习|学习笔记】决策树中的熵 (Entropy)、信息增益 (Information Gain) 和信息增益率 (Information Gain Ratio)详解。
·
【机器学习|学习笔记】决策树中的熵 (Entropy)、信息增益 (Information Gain) 和信息增益率 (Information Gain Ratio)详解。
【机器学习|学习笔记】决策树中的熵 (Entropy)、信息增益 (Information Gain) 和信息增益率 (Information Gain Ratio)详解。
文章目录
欢迎铁子们点赞、关注、收藏!
祝大家逢考必过!逢投必中!上岸上岸上岸!upupup
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文。详细信息可关注VX “
学术会议小灵通”或参考学术信息专栏:https://blog.csdn.net/2401_89898861/article/details/147196847
一、基础概念回顾
1. 熵(Entropy)
- 衡量数据集的纯度或不确定性。熵越低,数据越纯。
对分类问题,熵定义为: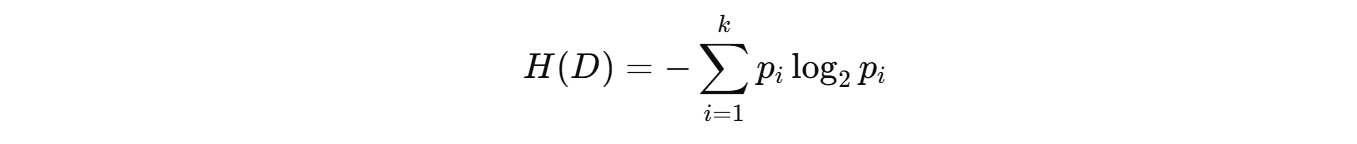
- 其中 p i p_i pi是第 i i i 类在数据集 D D D 中的比例。
2. 信息增益(Information Gain)
- 划分数据集前后熵的减少量,用于衡量特征划分效果。
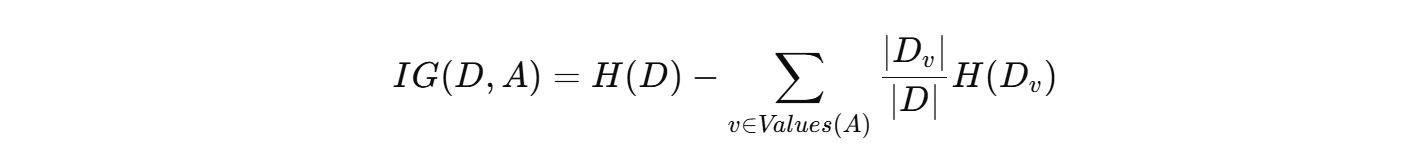
- D v D_v Dv 是特征 A A A 取值为 v v v 的子集 H ( D v ) H(D_v) H(Dv) 是子集的熵
3. 信息增益率(Information Gain Ratio)
- 解决信息增益偏向多值特征的问题,引入固有值(Intrinsic Value,IV):
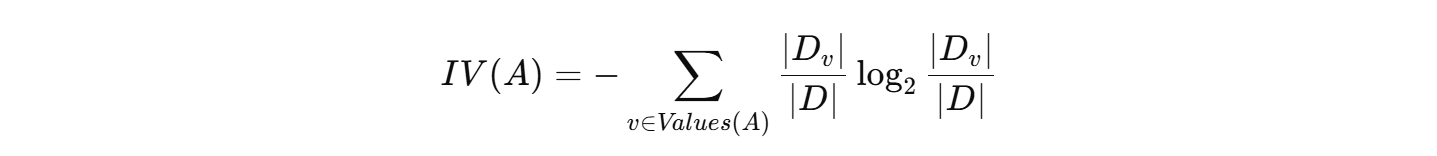
- 信息增益率定义为:
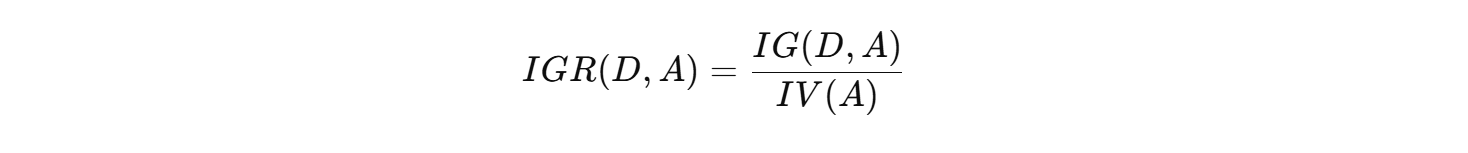
二、Python代码实现
import math
from collections import Counter
def entropy(data):
total = len(data)
counts = Counter(data)
ent = 0.0
for count in counts.values():
p = count / total
ent -= p * math.log2(p)
return ent
def information_gain(data, feature_values):
# data: list of class labels
# feature_values: list of feature values (same length as data)
total_entropy = entropy(data)
total_len = len(data)
value_subsets = {}
for val, label in zip(feature_values, data):
value_subsets.setdefault(val, []).append(label)
weighted_entropy = 0.0
for subset in value_subsets.values():
weighted_entropy += len(subset) / total_len * entropy(subset)
return total_entropy - weighted_entropy
def intrinsic_value(feature_values):
total_len = len(feature_values)
counts = Counter(feature_values)
iv = 0.0
for count in counts.values():
p = count / total_len
iv -= p * math.log2(p)
return iv
def information_gain_ratio(data, feature_values):
ig = information_gain(data, feature_values)
iv = intrinsic_value(feature_values)
if iv == 0:
return 0
return ig / iv
# 示例数据
# 假设我们有如下数据集:
labels = ['yes', 'yes', 'no', 'no', 'no', 'yes', 'no', 'yes', 'yes', 'no']
feature = ['sunny', 'sunny', 'overcast', 'rain', 'rain', 'rain', 'overcast', 'sunny', 'sunny', 'rain']
print(f"Entropy of labels: {entropy(labels):.4f}")
print(f"Information Gain of feature: {information_gain(labels, feature):.4f}")
print(f"Intrinsic Value of feature: {intrinsic_value(feature):.4f}")
print(f"Information Gain Ratio of feature: {information_gain_ratio(labels, feature):.4f}")
三、运行结果示例
Entropy of labels: 0.9709
Information Gain of feature: 0.2467
Intrinsic Value of feature: 1.3700
Information Gain Ratio of feature: 0.1801
四、小结
- 熵 表示样本纯度,越低越纯。
- 信息增益 衡量划分前后熵的减少,选最大信息增益的特征。
- 信息增益率 是对信息增益的修正,避免偏向取值多的特征。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐



 14
14 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)