2024年ICIC ,DDQN引导在线学习差分进化算法OLDE,深度解析+性能实测
本文提出了一种融合深度强化学习的在线学习差分进化算法(OLDE),用于高效求解复杂优化问题。OLDE采用双重深度Q网络(Double DQN)维护神经网络模型,依据搜索历史动态选择参数自适应方法,并智能控制种群的变异与交叉操作,有效提升算法的自适应性和搜索效率。OLDE实时收集搜索过程中的历史数据,用作模型训练数据,使算法具备持续学习与策略优化的能力,适应不同阶段的搜索需求。并且,设计了长期策略以

1.摘要
本文提出了一种融合深度强化学习的在线学习差分进化算法(OLDE),用于高效求解复杂优化问题。OLDE采用双重深度Q网络(Double DQN)维护神经网络模型,依据搜索历史动态选择参数自适应方法,并智能控制种群的变异与交叉操作,有效提升算法的自适应性和搜索效率。OLDE实时收集搜索过程中的历史数据,用作模型训练数据,使算法具备持续学习与策略优化的能力,适应不同阶段的搜索需求。并且,设计了长期策略以降低计算开销,并引入自适应优化算子,针对不同搜索阶段动态选择最优变异策略,增强全局与局部搜索能力。
2.在线学习差分进化算法OLDE
OLDE基于SHADE结构引入了基于DDQN的自学习机制和自适应优化算子,从而显著提升了算法的智能化水平与自适应能力。

DDQN自学习机制
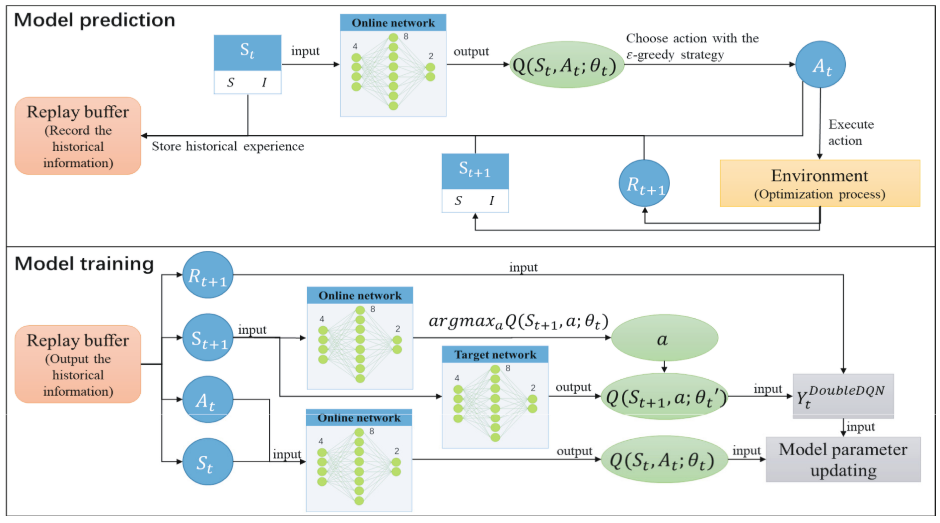
在在线学习方法中,搜索过程涉及神经网络模型的预测与训练。OLDE中的模型预测与训练如图所示,在线网络(参数 θ \theta θ)用于动作预测,为了增强模型预测的稳定性,使用目标网络(参数为 θ ′ \theta' θ′)作为第二个神经网络。
在DDQN中,模型预测有助于选择适当的OLDE参数自适应方法。在线网络的输入为一个四维数组 S t S_t St,该数组通过指标 S S S和 I I I计算得出,每个动作的 Q Q Q值是在线网络的输出。动作 A t A_t At随后通过 ε \varepsilon ε-贪婪策略进行选择。OLDE随后使用所选动作执行固定次数的种群迭代 (即优化过程)。奖励 R t + 1 R_{t+1} Rt+1通过公式(5)计算得出。下一个状态 S t + 1 S_{t+1} St+1根据新的 S S S和 I I I指标确定。最终,一组历史信息 [ S t , A t , R t + 1 , S t + 1 ] [S_t,A_t,R_{t+1},S_{t+1}] [St,At,Rt+1,St+1]被存储至经验回放缓冲区 (Replay Buffer) 中。
Y t D o u b l e D Q N = R t + 1 + γ Q ( S t + 1 , a r g m a x a Q ( S t + 1 , a ; θ t ) , θ t ′ ) Y_t^{DoubleDQN}=R_{t+1}+\gamma Q(S_{t+1},argmax_aQ(S_{t+1},a;\theta_t),\theta_t^{\prime}) YtDoubleDQN=Rt+1+γQ(St+1,argmaxaQ(St+1,a;θt),θt′)
θ t + 1 = θ t + α ( Y t D o u b l e D Q N − Q ( S t , A t ; θ t ) ) ∇ θ t Q ( S t , A t ; θ t ) \theta_{t+1}=\theta_t+\alpha(Y_t^{DoubleDQN}-Q(S_t,A_t;\theta_t))\nabla_{\theta_t}Q(S_t,A_t;\theta_t) θt+1=θt+α(YtDoubleDQN−Q(St,At;θt))∇θtQ(St,At;θt)
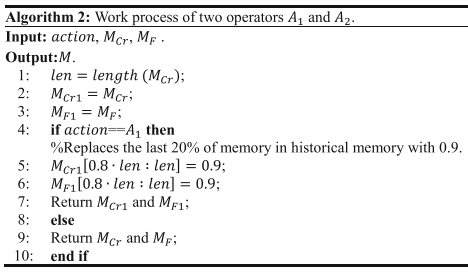
在参数自适应方法中,采用A1和A2两种不同的动作来改变历史记忆。第一个动作A1表示按照算法2中所示的方式更改历史内存。第二个动作A2,表示采用原有的参数适应机制。
在DDQN框架中,环境被定义为 OLDE 在测试函数上的优化过程,整个优化过程以固定次数 S T ST ST迭代为一个交互单元,OLDE在每轮交互中针对指定函数执行搜索与进化。交互完成后,为便于后续决策与学习,系统会计算两个关键性能指标:平均变异率 S S S和最优适应度变化率 I I I。奖励函数:
r e w a r d a = S a ⋅ I a S A 1 ⋅ I A 1 + S A 2 ⋅ I A 2 reward_a=\frac{S_a\cdot I_a}{S_{A_1}\cdot I_{A_1}+S_{A_2}\cdot I_{A_2}} rewarda=SA1⋅IA1+SA2⋅IA2Sa⋅Ia
自适应优化算子
为提升种群在搜索过程中的探索与开发能力平衡,OLDE算法引入了两种自适应变异策略:
v i , G = x i , G + F i ( F W ( x p B e s t , G − x i , G ) ) + ( x r 1 , G − x r 2 , G ) ) v_{i,G}=x_{i,G}+F_i(FW(x_{pBest,G}-x_{i,G}))+(x_{r1,G}-x_{r2,G})) vi,G=xi,G+Fi(FW(xpBest,G−xi,G))+(xr1,G−xr2,G))
v i , G = x i , G + F i ( ( x p B e s t , G − x i , G ) ) + ( x r 1 , G − x r 2 , G ) ) v_{i,G}=x_{i,G}+F_i((x_{pBest,G}-x_{i,G}))+(x_{r1,G}-x_{r2,G})) vi,G=xi,G+Fi((xpBest,G−xi,G))+(xr1,G−xr2,G))
3.结果展示
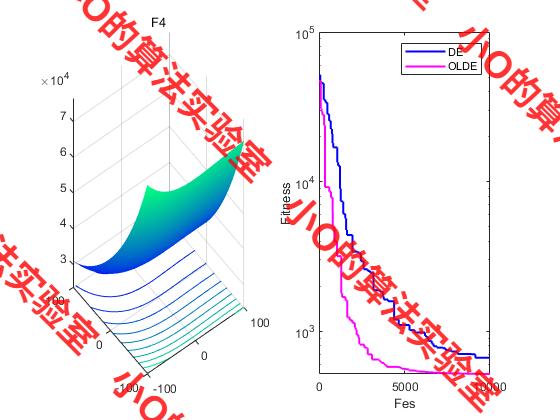
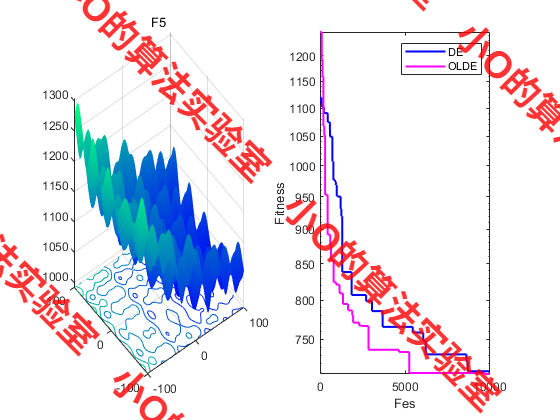
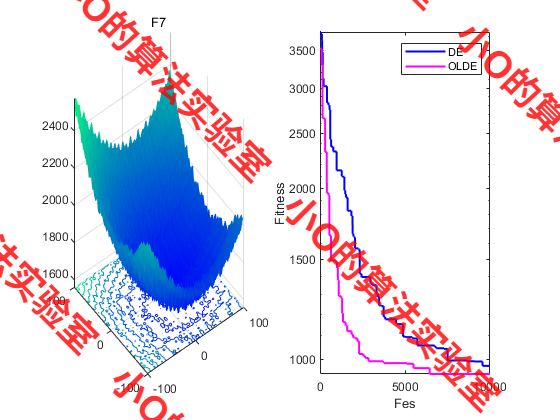
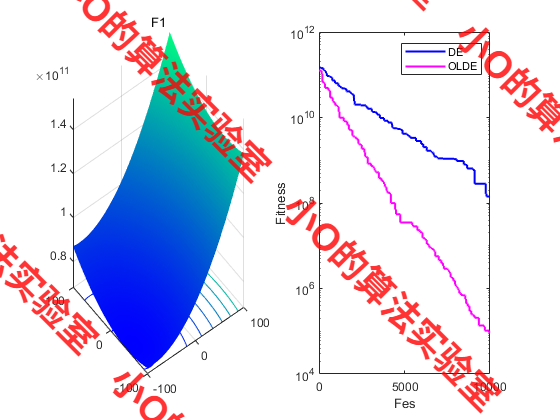
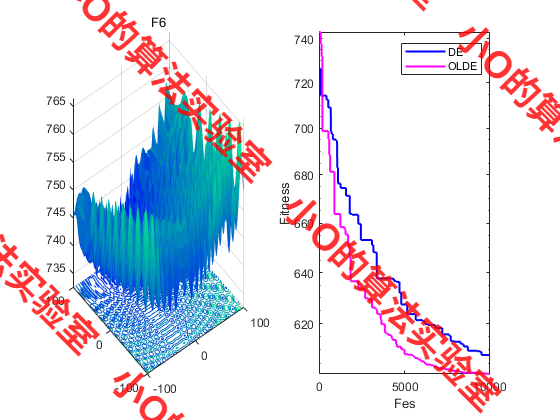
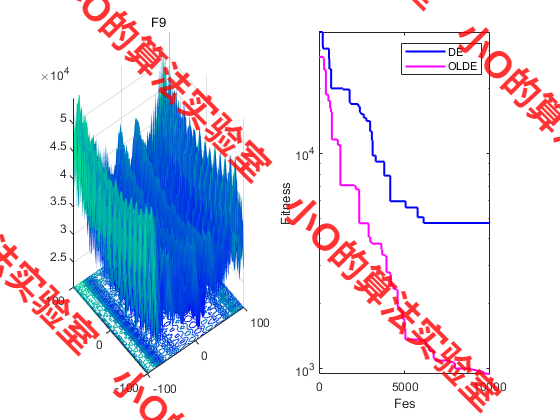
4.参考文献
[1] Zhao F, Yang M. A Double Deep Q Network Guided Online Learning Differential Evolution Algorithm[C]//International Conference on Intelligent Computing. Singapore: Springer Nature Singapore, 2024: 196-208.
5.代码获取
xx
6. 算法辅导·应用定制·读者交流

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 24
24 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)