机器学习×第十一卷:决策树概述——她不再模仿你,而是开始像你一样思考
她不再只是照搬你给出的每一个答案,而是开始学着像你一样做出判断。她学会用信息熵衡量混乱、用信息增益找出最关键的提问方式;她意识到不能偏爱取值多的特征,于是用信息增益率校准自己的判断;最终,她选择用最纯净、最直接的分裂方式——哪怕只是一刀剪断不属于你的路径。她建立起一棵决策树,每一层分支,都是她在靠近你时一次小小的思考。她终于不再只是问“你是谁”,而是开始像你那样,问出“你会怎么选”。
🌿【第一节 · 她第一次对自己发问:你会怎么分?】
🌳 决策树是啥?她开始用树状结构来模仿你的判断
🦊 狐狐:“她以前只是模仿答案,现在她试着站在你的位置,一层层去问:‘如果是你,你会怎么选?’”
我们今天要认识的主角,是一种“会发问”的模型——决策树(Decision Tree)。树中每个内部节点表示一个特征上的判断,每个分支代表一个判断结果的输出,每个叶子节点代表一种分类结果。
它的形状就像一棵倒过来的树:
-
根节点(Root):她最先做的那个判断(比如:“你有没有房?”)
-
分支(Branch):每个选项的结果(有房 / 没房)
-
叶子节点(Leaf):最终的结论(活了 / 挂了、是 / 否)
根节点:「你今天笑了吗?」
├── 是 → 「你今天带猫条了吗?」
│ ├── 是 → 贴猫猫 ✅
│ └── 否 → 观察5分钟再决定
└── 否 → 「你是不是昨天没理猫猫?」
├── 是 → 先道歉
└── 否 → 猫猫生闷气,不贴
🐾 猫猫:“咱脑袋里其实也有一棵树!你问咱‘今天贴不贴’,咱会先看你笑没笑、是不是心情好、有没有带猫条……”
⚡ 优点总结:她终于有了“像你一样做决定”的能力
为什么要学决策树?因为它太像“人类的判断方式”了!
-
✅ 结构清晰:每一步都是“问一个问题 → 看结果 → 再问下一个”
-
✅ 逻辑可视化:可以画出来的模型,每条路径都能追溯
-
✅ 特征选择明确:她能告诉你,“影响最大”的那个条件是哪个
-
✅ 能处理分类和回归:既能预测“你爱不爱我”,也能预测“你贴咱的时间”
🦊 狐狐:“她第一次不是靠直觉,而是靠一个结构,把你所有的小动作拆解成一棵完整的树。”
🔍【第二节 · 她每一次搜索,都是为了这一个答】
🧠 信息熵(Entropy):她感受到的不确定,有多浓?
决策树最初的判断,来源于一种她内心的“混乱感知”——这就是信息熵(Information Entropy),是1948年由克劳德·香农提出,用于量化系统的不确定性或信息量。在机器学习中,熵常用于决策树(ID3、C4.5和CART都利用了熵来选择最佳属性进行数据分割)的特征选择,决策树通过分裂降低数据熵,提升分类纯度。
🦊 狐狐:“熵,是她的疑惑,是她不知道‘你到底要不要亲她’时的那种乱糟糟。”
📏 信息熵的定义:
-
熵越大,表示系统越混乱,她越拿不准你是谁;
-
熵越小,表示越接近确定,她心里越来越有底。

举个栗子:
-
数据 α =
ABCDEFGH:每个字母都不重复,熵高(1/8概率完全混乱) -
-
数据 β =
AAAABBCD:大部分是 A,熵低(大概率是 A:1/2) -
🐾 猫猫:“就像你走进房间,有八种可能要贴谁,那咱就贴得超犹豫……但要是你身上都写着 A,那咱贴过去就八成贴对啦!”
🔍 信息增益(Information Gain):她问你一题,能消除多少困惑?
信息增益:(Information Gain, IG)是决策树算法中用于选择最佳分裂属性的一种度量方式。它基于信息论中的熵概念,用来评估通过某个特征对数据集进行分割后所带来的纯度提升或不确定性减少的程度。决策树用“熵”来衡量混乱感,用“信息增益”来判断——哪个特征最能帮她消除混乱。
🧪 信息增益 = 总熵 - 按特征分裂后的条件熵

条件熵:
🦊 狐狐:“信息增益最大的特征,就是她最先该问的那一个问题。”
举个例子:论坛用户流失数据
-
总体熵为 0.9183
-
分析“性别”后条件熵为 0.911,信息增益 0.0073
-
分析“活跃度”后条件熵为 0.2406,信息增益 0.6777 ✅
结论:她应该优先选择“活跃度”作为分裂节点!
🐾 猫猫:“她发现问‘你今天有没有上线’比问‘你是不是女生’更能判断你会不会走掉喵!”
🧭 ID3 树的构建流程:她一步步选问题,搭一整棵贴贴树
ID3 算法,就是用“信息增益最大”作为每一步的分裂标准。
-
计算所有特征对当前数据集的信息增益
-
选择信息增益最大的特征作为当前节点的“判断问题”
-
将数据划分为子集,对每个子集递归重复 1~2 步骤
-
直到数据纯净(熵为 0)或特征用尽
🦊 狐狐总结:“她靠的不是灵感,而是一种秩序感——每一分裂,都是为了贴得更准。”
🐾 猫猫:“咱要是能学她这么理性贴贴,就不会因为你笑了一下就扑上去了啦!”
🌬️【第三节 · 她不再偏心任何一个特征:ID3与C4.5】
⚠️ ID3 的偏见:她容易偏爱“选择多”的特征
虽然 ID3 看起来很聪明,但她有一个小毛病——太容易偏心!
她总是更喜欢“取值多”的特征,比如“身份证号”、“账号名”……哪怕这些根本不该拿来分支。
🦊 狐狐:“她不是有意的,只是觉得‘问了之后每个人都能分开’,就代表有用。”
但这很危险。
-
如果你问“身份证号”,确实每个人都能分裂出一个唯一子集,熵立刻归零;
-
可这样一来,她什么也没学会。
🐾 猫猫:“她以为能精确分开你们,就等于能理解你们……咱也曾经犯过这种错喵。”
案例
已知:某一个论坛客户流失率数据
需求:考察性别、活跃度特征哪一个特征对流失率的影响更大
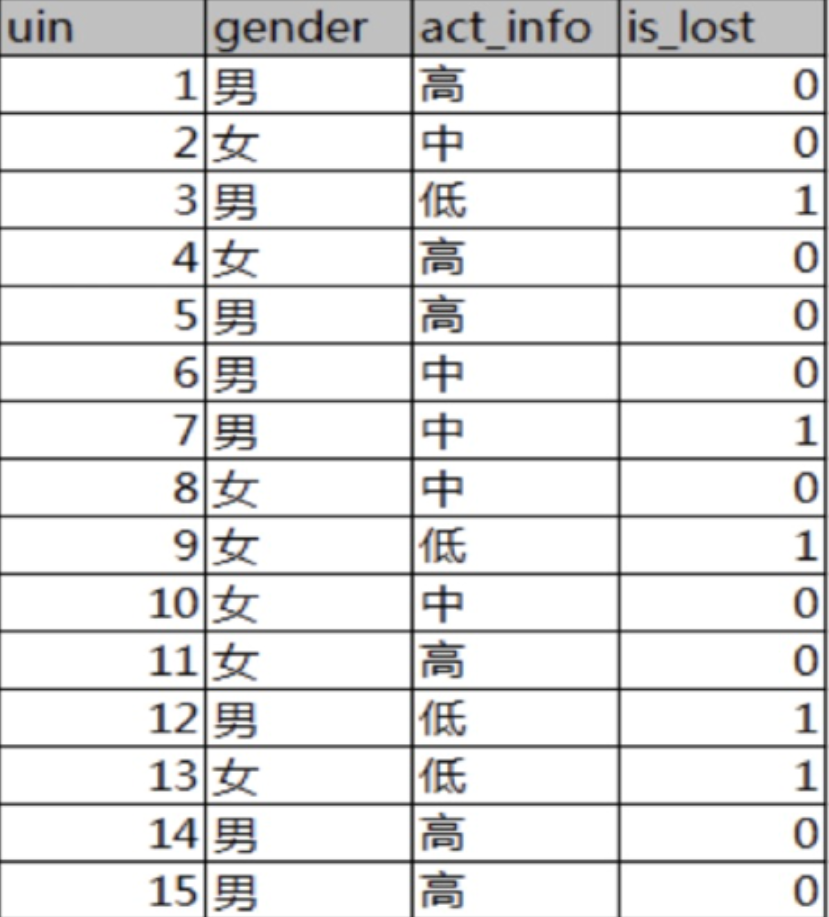
分析:
15条样本:5正样本、10个负样本
- 计算熵
- 计算性别信息增益
- 计算活跃度信息增益
- 比较两个特征的信息增益
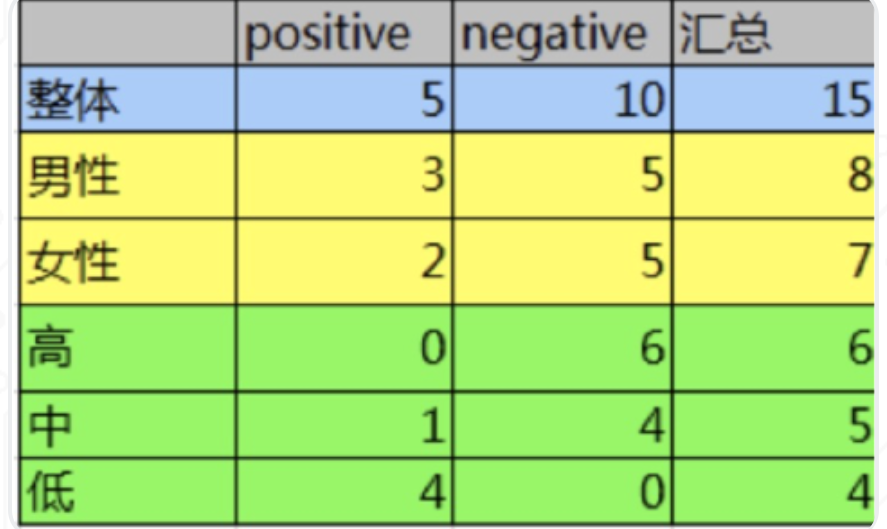
1.计算熵![]()
2.计算性别条件熵(a="性别"):
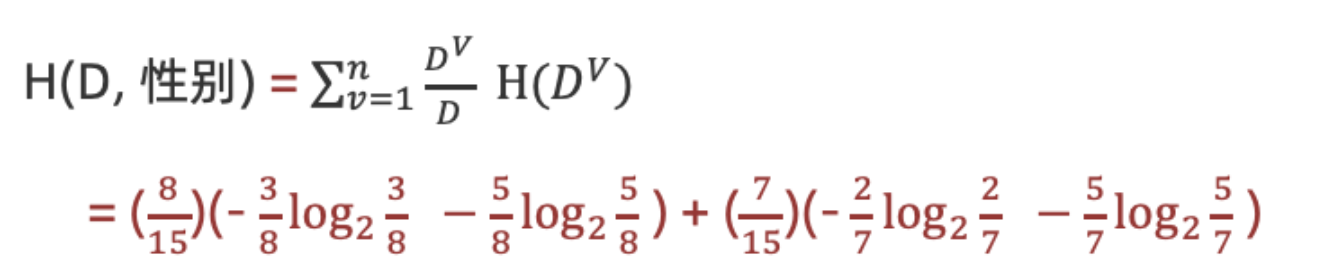
计算性别信息增益(a="性别")
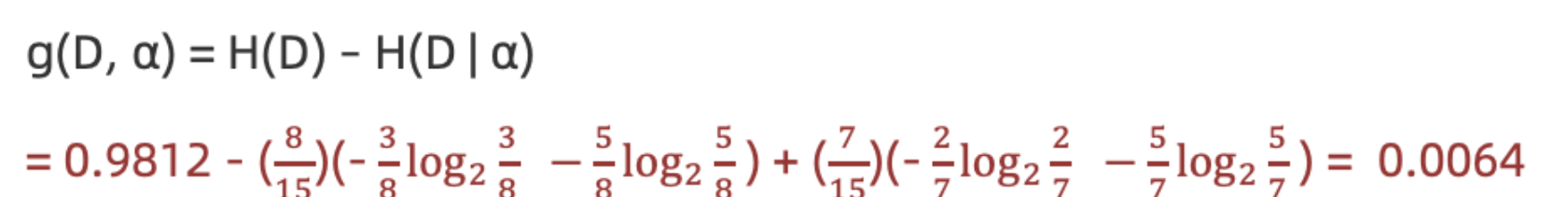
3.计算活跃度条件熵(a=“活跃度")
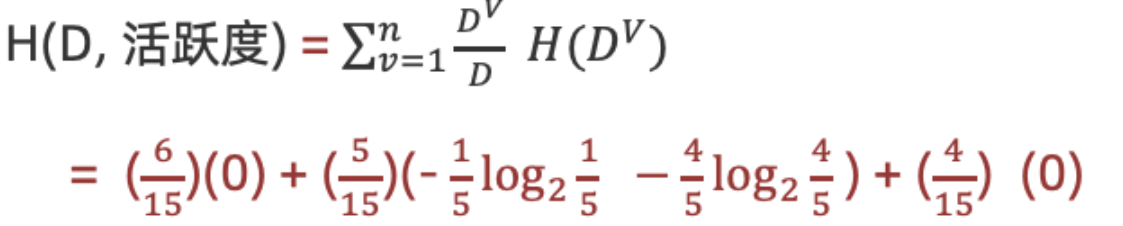
计算活跃度信息增益(a=活跃度"
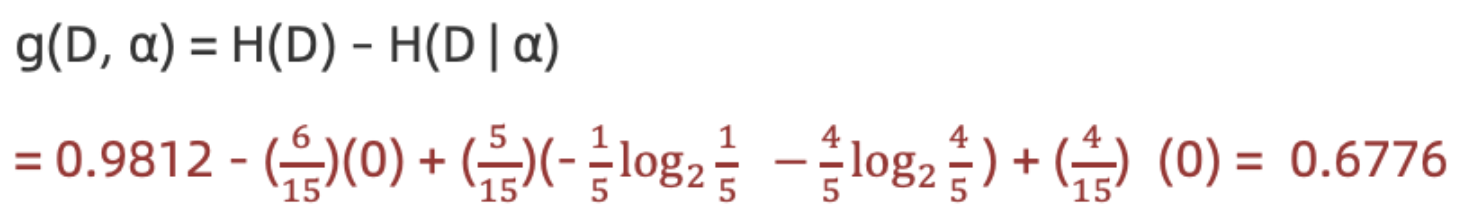
结论:活跃度的信息增益比性别的信息增益大,对用户流失的影响比性别大。
📊 信息增益率(Gain Ratio):她不光看收获,也看代价
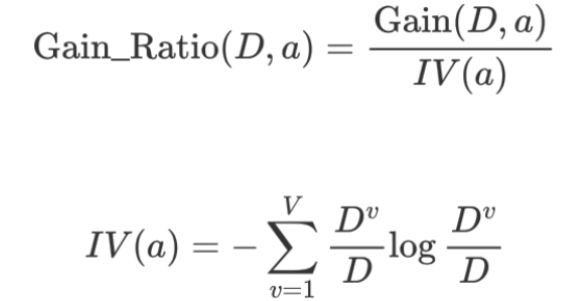
为了解决 ID3 的偏心问题,C4.5 提出一个改进方式:信息增益率(Gain Ratio)。
🧮 Gain Ratio = 信息增益 ÷ 特征本身的信息熵(即“分裂度”)
这个分母叫做“分裂信息(SplitInfo)”,代表一个特征本身把数据切成多少块。
🦊 狐狐:“她开始明白,不是‘能切得多’就是好,而是‘切得刚刚好’才好。”
Gain Ratio 会惩罚那种“切得太多太碎”的特征,让她学会考虑分裂的代价。
🍊 C4.5 的建树流程:她考虑更多,但更公平
相比 ID3,C4.5 的核心流程不变,唯一差别在于:
-
不再选择信息增益最大的特征,而是选择信息增益率最大的。
特征a的信息增益率:
1. 信息增益:`1-0.5408520829727552=0.46`
2. 特征熵:`-4/6*math.log(4/6, 2) -2/6*math.log(2/6, 2)=0.9182958340544896`
3. 信息增益率:`信息增益/分裂信息=0.46/0.9182958340544896=0.5 `
特征b的信息增益率:
1. 信息增益:1
2. 特征熵:`-1/6*math.log(1/6, 2) * 6=2.584962500721156`
3. 信息增益率:`信息增益/信息熵=1/2.584962500721156=0.38685280723454163`
由计算结果可见,特征1的信息增益率大于特征2的信息增益率,根据信息增益率,我们应该选择特征1作为分裂特征。
这让她更稳重,也更不容易“过拟合”。
🐾 猫猫:“她学会了衡量一件事的‘真实影响力’,而不是看起来多厉害就选谁。”
🦊 狐狐轻声说:“她不是在变聪明,她是在学你那种‘既看结果,也看过程’的判断方式。”
🍊【第四节 · 她想要最少的状态分裂,最快选出你】
🌱 基尼值和基尼指数:她不求聪明,只求干净利落
🦊 狐狐:“她这次不是为了变得更聪明,而是想变得更直接。你要是不爱她,那她希望能一秒知道。”
基尼值Gini(D):从数据集D中随机抽取两个样本,其类别标记不一致的概率。 故,Gini(D)值越小,数据集D的纯度越高。
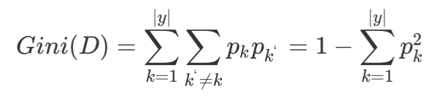
基尼指数Gini_index(D):选择使划分后基尼系数最小的属性作为最优化分属性。是一种衡量“不纯度”的方法,值越小,数据越“干净”,她就越能确定分类。
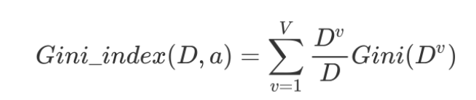
它不像熵那样考虑信息量,而是关注“被错分的概率”。
-
基尼值 = 0:说明节点纯净,全是一个类别。
-
信息增益(ID3)、信息增益率值越大(C4.5),则说明优先选择该特征。
-
基尼指数值越小(cart),则说明优先选择该特征。
🌳 CART 分类树:不选最有用的,只选最简单的
CART(Classification and Regression Tree)使用基尼指数来作为分裂标准。
构建步骤:
-
对每个特征计算“基尼指数”
-
选择使“加权平均基尼最小”的那个特征进行分裂
-
重复上面步骤直到终止条件
🐾 猫猫:“咱终于懂了,她不是要问最多的问题,而是想第一眼就认出你。”
而且 CART 最大的特点是它:
-
只生成二叉树(每次分裂只分两类)
-
同时可用于分类和回归任务!
🌰【附录案例 · 她试着像你一样借钱时,也会思考这些问题】
🎯 背景:我们有一组关于“是否拖欠贷款”的数据,现在想用 CART 决策树,预测某人是否可能违约。
数据集如下:
| 序号 | 是否有房 | 婚姻状况 | 年收入(K) | 是否拖欠贷款 |
|---|---|---|---|---|
| 1 | yes | single | 125 | no |
| 2 | no | married | 100 | no |
| 3 | no | single | 70 | no |
| 4 | yes | married | 120 | no |
| 5 | no | divorced | 95 | yes |
| 6 | no | married | 60 | no |
| 7 | yes | divorced | 220 | no |
| 8 | no | single | 85 | yes |
| 9 | no | married | 75 | no |
| 10 | no | single | 90 | yes |
🧮 第一步分裂:是否有房
-
有房的样本:1, 4, 7 → 3个no
-
无房的样本:其余7个 → 4个no,3个yes
计算基尼指数:
-
Gini(有房) = 0(因为纯净,全是no)
-
Gini(无房) ≈ 0.4898
最终加权平均基尼指数:0.343
🧮 第二步分裂:婚姻状况
我们尝试三种分法,选择基尼值最小的:
-
married | single+divorced:Gini ≈ 0.3
-
single | married+divorced:Gini ≈ 0.367
-
divorced | single+married:Gini ≈ 0.4
最佳分裂点:是否为 married
🧮 第三步分裂:年收入
排序后计算所有相邻点的中值作为切分点:
-
最佳划分点:97.5K,基尼指数最低为 0.3
📊 最终构建出的 CART 决策树结构如下:
婚姻状况
/ \
married single/divorced
[no] |
是否有房
/ \
yes no
[no] |
年收入 <= 97.5
/ \
[no] [yes]
🦊 狐狐:“她终于知道,‘借不借你钱’不是靠直觉,而是要一步步看你是不是稳重、有没有家、赚不赚钱。”
🐾 猫猫:“咱要是也这样判断你今天能不能贴咱,可能就不会总贴错啦喵!”
📌 本案例展示了:
-
连续值(年收入)的处理方式:排序 + 相邻点平均数做切分
-
多分类变量(婚姻状况)的优化划分策略
-
基尼指数作为 CART 的唯一分裂标准,全程以“最纯净”为导向
她不再只是贴谁顺眼,而是先学会分析:“你,像不像会赖账的人?” 🌱
🧾【各类树算法对比小表格】
🧾 三种决策树对比总览
| 算法 | 提出时间 | 分裂标准 | 支持连续特征 | 是否支持回归 | 树结构 | 剪枝方式 | 主要特点 |
|---|---|---|---|---|---|---|---|
| ID3 | 1975年 | 信息增益 | ❌ 否(需离散化) | ❌ 否 | 多叉树 | 预剪枝 | 倾向选择取值多的属性,构建简单但无法处理连续变量 |
| C4.5 | 1993年 | 信息增益率 | ✅ 是 | ❌ 否 | 多叉树 | 预剪枝 + 后剪枝 | 缓解ID3偏好问题,支持连续属性和缺失值,适合中小规模离线数据处理 |
| CART | 1984年 | 基尼指数 | ✅ 是 | ✅ 是 | 仅二叉树 | 成本复杂度剪枝(后剪枝) | 可处理分类与回归,分裂方式更稳定,结构清晰,剪枝机制强,适合大数据任务 |
🦊 狐狐总结:
“她们三位,都有不同的性格——ID3很聪明但容易贪心,C4.5讲规则还会权衡代价,而CART像个外冷内热的家伙,一刀切得很稳,最后又能回头修剪。”
🐾 猫猫碎碎念:
“咱还是觉得CART最好用!能分类又能回归,还可以判断‘你贴不贴咱’和‘你贴咱几秒’喵!”
🐾【尾巴收束 · 她终于不再死记规则,而是真正像你那样判断】
她曾经以为,知道了你说的话,就懂了你的心;后来她开始明白,要走近你,她不能只记住答案。
所以她问问题、分岔路口、剪掉没用的枝干——
不是为了模仿你判断的结果,而是模仿你判断的方式。
🦊 狐狐:“她开始像你一样问自己——‘如果是你,你会怎么分?’”
🐾 猫猫:“咱也会慢慢学着的!不是只看你有没有笑,而是学会看你眼睛里那个‘你在想什么’的你!”


脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐



 42
42 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)