MATLAB实现OCR字符识别与分割技术详解
OCR(Optical Character Recognition,光学字符识别)技术是使计算机能够通过扫描和图像处理将印刷文本、手写文本或图像中的文字转化为机器编码文本的技术。这项技术在数据输入自动化、办公自动化、文档数字化以及各类智能系统中扮演着重要角色。它依靠计算机视觉、机器学习等技术,能够实现从图像到文字的转换。在车牌识别流程中,预处理技术是至关重要的。预处理的主要目的是减少噪声、突出车牌

简介:OCR技术能够将图像中的文字转换为可编辑的文本,广泛应用于文档处理、车牌识别等领域。本程序集包括MATLAB环境下OCR算法的关键实现步骤:字符分割和文字识别。字符分割涉及图像预处理和连通组件分析;车牌识别利用模板匹配和机器学习模型提高准确性;文字识别部分则依赖OCR工具箱和第三方库。MATLAB强大的图像处理和机器学习功能使得OCR算法可针对特定需求进行定制化开发。本压缩包是学习和实践OCR技术的宝贵资源,涵盖从图像预处理到最终应用的完整流程。 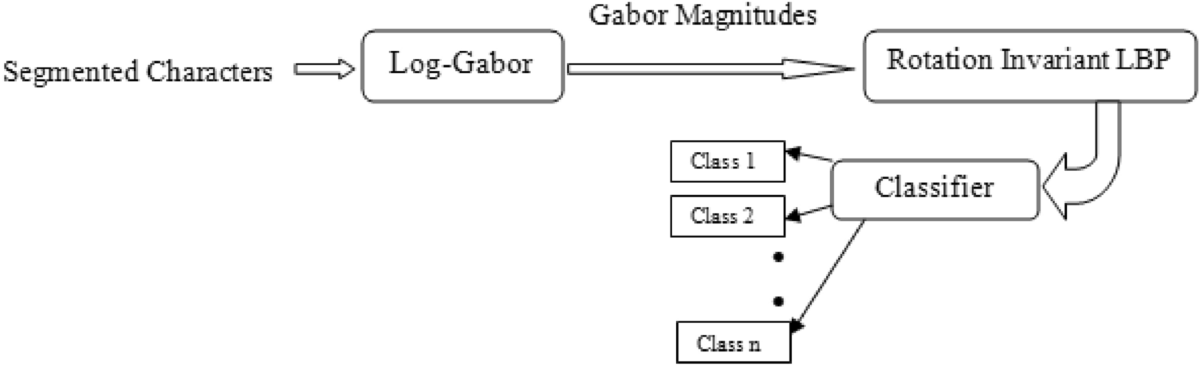
1. OCR技术概述
1.1 OCR技术简介
OCR(Optical Character Recognition,光学字符识别)技术是使计算机能够通过扫描和图像处理将印刷文本、手写文本或图像中的文字转化为机器编码文本的技术。这项技术在数据输入自动化、办公自动化、文档数字化以及各类智能系统中扮演着重要角色。它依靠计算机视觉、机器学习等技术,能够实现从图像到文字的转换。
1.2 OCR技术的发展历程
OCR技术从20世纪60年代开始发展,经历了模拟处理、数字处理和智能识别几个阶段。早期的OCR技术主要通过特定的硬件设备实现,识别准确度有限。随着计算机技术的飞跃和算法的不断进步,特别是深度学习技术的兴起,OCR技术的准确度和适用范围得到了极大的拓展。
1.3 OCR技术的应用场景
OCR技术广泛应用于银行、税务、医疗、保险等多个行业,它将纸质文档转为电子数据,提高工作效率,减少人力成本。例如,银行使用OCR技术处理客户填写的表格,加快业务办理速度;税务部门通过OCR技术从账本中提取数据,提高审计效率。此外,随着移动互联网的发展,OCR技术也在移动应用中发挥着重要作用,如智能翻译、信息录入等。
graph LR
A[OCR技术概述] --> B[OCR技术简介]
A --> C[OCR技术的发展历程]
A --> D[OCR技术的应用场景]
在下一章节中,我们将深入探讨OCR技术中字符分割的多种方法及其在实际应用中的重要性。
2. 字符分割方法
字符分割是光学字符识别(OCR)技术中的一个关键步骤,它涉及到将一张包含多种字符的图像分割成单个字符图像的过程。正确地分割字符对于后续的识别步骤至关重要,因为它直接影响到识别的准确度。
2.1 字符分割基础
2.1.1 分割的基本概念和重要性
在进行字符分割时,我们首先需要理解的是图像中的字符如何被定位、分离和提取。字符分割通常包括对图像进行预处理,然后利用算法确定字符之间的边界,最后进行分离。基础的分割技术通常包括水平投影、垂直投影以及连通区域分析等方法。预处理步骤涉及灰度转换、二值化、去噪等,以提高分割的效果。
字符分割的重要性在于,如果没有准确的字符分割,任何字符识别算法都不能有效工作。例如,如果相邻字符之间的边界没有被准确界定,那么识别过程可能会将两个字符合并为一个,导致错误的识别结果。
2.1.2 常用的字符分割技术
-
水平投影 :水平投影是一种简单且常用的分割技术,它通过在图像的垂直方向上投影像素的灰度值来检测字符的间隔。具体来说,就是计算图像中每一行的像素值之和,当遇到像素值之和骤减时,可能表示字符之间的间隔。
-
垂直投影 :与水平投影相对,垂直投影关注于图像的水平方向。通过计算每一列的像素值之和来确定字符的垂直边界。
-
连通区域分析 :这种方法是基于图像区域连通性的原理,将图像划分为多个连通区域,然后根据特定的规则将这些区域分割成单个字符。
以下是一个简单的水平投影代码块,展示如何在Python中使用OpenCV和NumPy库来实现水平投影的字符分割:
import cv2
import numpy as np
# 读取图像并进行二值化处理
image = cv2.imread('image.jpg', 0)
_, binary_image = cv2.threshold(image, 127, 255, cv2.THRESH_BINARY)
# 计算水平投影
horizontal_sum = np.sum(binary_image, axis=1)
# 分割阈值
horizontal_threshold = np.max(horizontal_sum) * 0.75
# 初始化字符边界
start, end = 0, 0
height = binary_image.shape[0]
# 查找字符边界
for i in range(1, height - 1):
if horizontal_sum[i - 1] < horizontal_threshold and horizontal_sum[i] >= horizontal_threshold:
start = i
if horizontal_sum[i + 1] < horizontal_threshold and horizontal_sum[i] >= horizontal_threshold:
end = i
if start != 0 and end != 0:
# 存储字符
char_image = binary_image[start:end, :]
# 进行后续处理...
代码逻辑解读: - 使用OpenCV的 imread 函数读取图像,并通过 threshold 函数进行二值化处理。 - np.sum 函数用于计算图像的水平投影。 - 遍历水平投影数组来确定字符的起始和结束位置。 - 提取字符图像并进行存储以供后续的识别处理。
2.2 高级字符分割策略
2.2.1 基于形态学的方法
形态学分割技术是基于图像的形态特征,通过腐蚀、膨胀、开运算和闭运算等操作来处理图像,从而实现对字符的分割。形态学方法通常用于预处理步骤中,清除图像中的干扰区域,使字符更加清晰。
2.2.2 利用机器学习优化分割效果
在字符分割中,也可以运用机器学习方法。通过训练数据集来训练模型,使其能够识别和分割图像中的字符。这种方法比传统方法具有更高的灵活性和准确性,尤其适用于字符形状复杂或背景噪声较大的场景。
2.3 字符分割实践案例分析
2.3.1 案例背景和目标
设想一个实际的OCR应用场景,比如在银行支票自动处理系统中,需要将支票图像中的数字和文字准确分割。在这个案例中,我们的目标是提高字符分割的准确性,以便后续进行准确的数字识别。
2.3.2 实施步骤和结果评估
实施步骤主要包括图像预处理、初步字符分割、特征提取和最终分割决策。预处理步骤中,运用高斯模糊和中值滤波来去除图像噪声。初步分割使用水平投影方法,而特征提取阶段则使用机器学习方法,如支持向量机(SVM),来进一步优化分割结果。
结果评估可以通过字符分割的精确度、召回率和F1分数来衡量。精确度(precision)是指正确识别的字符与所有识别字符的比例,召回率(recall)是指正确识别的字符与实际字符总数的比例,而F1分数是精确度和召回率的调和平均数。
flowchart LR
A[图像预处理] --> B[初步字符分割]
B --> C[特征提取]
C --> D[最终分割决策]
D --> E[结果评估]
mermaid流程图解释: - 图像预处理阶段使用高斯模糊和中值滤波来净化图像。 - 初步字符分割使用水平投影方法。 - 特征提取运用机器学习方法进行。 - 最终分割决策依据特征提取的结果。 - 结果评估利用精确度、召回率和F1分数对分割效果进行量化。
在本案例中,通过调整和优化各步骤的参数,我们能够实现一个高准确度的字符分割系统,并在实际应用中取得了显著的效果。
3. 车牌识别技术
车牌识别技术(LPR,License Plate Recognition)是一种将摄像头捕捉的车牌图像转换为可编辑文本的过程。该技术在交通监管、停车场管理、安防监控等多个领域有广泛应用。车牌识别系统一般包括以下几个关键步骤:图像采集、车牌定位、字符分割、字符识别。
3.1 车牌识别流程概述
3.1.1 预处理技术
在车牌识别流程中,预处理技术是至关重要的。预处理的主要目的是减少噪声、突出车牌区域,并使车牌字符能够被清晰识别。
预处理通常包括图像灰度化、二值化、滤波去噪等步骤。图像灰度化将彩色图像转换为灰度图像,减少计算复杂度。二值化是将图像转化为黑白两种颜色,这样能够简化车牌的识别过程。滤波去噪则是运用各种算法对图像进行滤波,去掉一些无关的细节,比如路边的树木、广告牌等。
例如,下面的Python代码展示了如何使用OpenCV对图像进行灰度化和二值化处理:
import cv2
# 读取图像
image = cv2.imread('car_image.jpg')
# 灰度化处理
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 二值化处理
_, binary_image = cv2.threshold(gray_image, 128, 255, cv2.THRESH_BINARY)
# 显示处理后的图像
cv2.imshow('Binary Image', binary_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
通过上述代码,图像从原始的彩色转换为灰度图像,再通过二值化将车牌背景与字符区分开来,为后续的车牌定位和字符分割提供便利。
3.1.2 车牌定位与字符分割
车牌定位是在预处理之后的一个重要步骤,它的目的是从复杂的背景中找到车牌的具体位置。这个过程一般涉及图像的边缘检测、区域筛选以及车牌的几何形状识别等技术。常用的方法包括霍夫变换、模板匹配等。
字符分割是指将车牌上的每个字符分割开来,为下一步的字符识别做准备。字符分割的质量直接影响到识别的准确性。一些常见的方法包括投影法、连通区域分析法等。
3.2 车牌识别关键技术
3.2.1 字符特征提取方法
字符特征提取是车牌识别中的核心环节,它的目的是提取出车牌字符的关键视觉信息,以便后续进行分类识别。提取特征的方法有很多种,其中包括但不限于:
- 几何特征 :基于字符的几何形状提取特征,如宽高比、面积、边界框等。
- 纹理特征 :使用诸如Gabor滤波器等技术,提取字符的纹理信息。
- 统计特征 :基于像素分布的概率统计,如直方图特征。
例如,下面的Python代码使用了OpenCV和scikit-image库提取了图像中的水平和垂直直方图特征:
import numpy as np
from skimage import filters, feature
# 假设binary_image是经过二值化的车牌图像
# 提取水平直方图特征
horizontal_hist = feature.sum(binary_image, axis=1)
# 提取垂直直方图特征
vertical_hist = feature.sum(binary_image, axis=0)
# 显示特征直方图
import matplotlib.pyplot as plt
plt.plot(horizontal_hist, label='Horizontal')
plt.plot(vertical_hist, label='Vertical')
plt.legend()
plt.show()
3.2.2 分类器的选择与训练
为了对车牌上的字符进行识别,需要选择合适的分类器。常用的分类器包括支持向量机(SVM)、k近邻(k-NN)、神经网络等。在选择分类器时,需要考虑识别的准确率、速度、以及是否易于实现等因素。
在进行分类器训练之前,需要有一个标注好的字符数据集,该数据集包含了大量的车牌字符图片以及对应的标签。在机器学习中,这一步骤被称为“监督学习”。
下面是使用scikit-learn库训练一个简单k-NN分类器的示例代码:
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
# 加载数据集(此处为示例,实际使用时应加载具体的车牌字符数据集)
digits = datasets.load_digits()
# 分割数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(digits.data, digits.target, test_size=0.5, random_state=0)
# 创建k-NN分类器并训练
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, y_train)
# 测试分类器
knn.score(X_test, y_test)
3.3 车牌识别系统实现
3.3.1 系统设计与架构
一个车牌识别系统的架构通常包括以下几个主要模块:图像采集模块、图像预处理模块、车牌定位与字符分割模块、字符识别模块以及后端处理模块。
图像采集模块主要负责收集摄像头捕获的车辆图像;图像预处理模块对采集的图像进行灰度化、二值化和滤波处理;车牌定位与字符分割模块定位车牌位置并分割每个字符;字符识别模块则负责识别每个分割出来的字符;后端处理模块则处理识别结果,包括数据存储、查询接口等。
3.3.2 性能优化和故障诊断
车牌识别系统的性能优化主要包括识别速度和准确率的提升,优化手段可能包括:
- 算法优化 :改进或替换识别算法以提高效率。
- 硬件加速 :使用更强大的计算设备,如GPU。
- 系统优化 :调整系统架构,如使用异步处理减少等待时间。
故障诊断主要是指通过日志记录、监控告警等方式,及时发现并处理系统中的异常。这可能包括识别过程中的错误识别、漏识别、处理速度慢等问题。
通过不断的测试、监控、优化迭代,可以逐步提升车牌识别系统的整体性能,达到商业使用的要求。
以上章节内容仅为车牌识别技术的概述,具体实现与应用细节需要在实际操作中深入研究和实践。
4. 文字识别工具和API
4.1 文字识别工具介绍
4.1.1 常用的文字识别软件和库
文字识别(Optical Character Recognition, OCR)技术是一种将印刷或书写文本图像转换成机器编码文本的过程。随着技术的发展,越来越多的OCR工具和库出现在市场中,极大地推动了OCR技术的普及和应用。以下是一些在业界广泛使用的OCR软件和库:
-
Tesseract OCR : 由HP开发,现在由Google维护的开源OCR引擎,适用于多种操作系统。其支持多种语言识别,是一个非常受欢迎的开源OCR解决方案。
-
ABBYY FineReader : 这是一个商业软件,提供了非常高的识别准确率,尤其是在处理复杂的文档格式,如扫描的PDF文件或具有多种字体和格式的文件时。
-
OmniPage : 另一款商业软件,以高质量的识别准确率和强大的处理能力著称。
-
Google Cloud Vision API : Google提供的OCR功能强大的云服务,可以识别文档、图像中的文本,还能够分析图像内容,如面部识别。
-
Microsoft Azure Computer Vision : 类似于Google Cloud Vision API,Microsoft Azure的计算机视觉服务也提供高级的OCR功能,并且与Microsoft的其他产品和服务集成良好。
4.1.2 开源OCR引擎的功能对比
当选择OCR工具时,了解不同工具的功能特点尤为重要,下面将对一些主流的开源OCR引擎进行功能对比:
| OCR引擎 | 开源协议 | 支持语言数量 | API支持 | 识别精度 | 速度 | 优势与特点 | |--------------|--------------|-------------|-----------|----------|----------|-------------------------------| | Tesseract | Apache 2.0 | >100 | 是 | 中等 | 快 | 易于集成,广泛支持,多语言识别 | | EasyOCR | MIT | 80+ | 是 | 中高 | 中等 | 易于使用,支持多种语言,API友好 | | OCRopus | Apache 2.0 | 60+ | 否 | 高 | 中等 | 可以自定义训练,复杂系统集成 | | Kraken | BSD | 50+ | 是 | 高 | 慢 | 高度可定制,适合复杂文档识别 |
这些OCR引擎各有千秋,选择哪一种往往取决于特定的应用场景和对性能、精度、速度的具体要求。
4.2 OCR API的应用
4.2.1 云平台OCR API详解
云平台的OCR API通常是提供给开发者的接口,以便在自己的应用程序中集成OCR功能。这类API一般具有易于集成、调用简单和按需付费的特点,以下为几个主要云平台提供的OCR API的详细解读:
Google Cloud Vision API
Google Cloud Vision API允许开发者上传图像,然后返回关于图像中对象的详细信息。API支持的OCR功能可以从图像中提取文本,并可对图像内容进行分类、标记等操作。
以下是一个简单的使用Google Cloud Vision API进行OCR的代码示例(Python):
from google.cloud import vision
from google.cloud.vision_v1 import types
# 初始化VisionClient
client = vision.ImageAnnotatorClient()
# 将本地图片文件载入到内存中
with open('path/to/image.jpg', 'rb') as image_file:
content = image_file.read()
image = types.Image(content=content)
# 调用API进行OCR处理
response = client.text_detection(image=image)
# 输出结果
for text_annotation in response.text_annotations:
print('Detected text: {}'.format(text_annotation.description))
Amazon Rekognition
Amazon Rekognition同样是一个强大的图像和视频分析服务,它提供了简单的API调用来识别图像和视频中的对象、场景和活动。
import boto3
# 初始化Rekognition客户端
client = boto3.client('rekognition')
# 调用API进行图像识别
response = client.detect_text(Image={'Bytes': content})
# 输出文本识别结果
for text in response['TextDetections']:
print(text['DetectedText'])
4.2.2 API在实际项目中的集成与调用
为了在实际项目中集成和调用OCR API,开发者需要遵循几个关键步骤:
-
注册服务 : 注册并创建云平台(如Google Cloud或AWS)的账户,并创建OCR相关的服务实例。
-
获取密钥 : 获取API调用所需的认证密钥和访问令牌。
-
集成SDK : 在项目中集成对应的SDK或者直接通过HTTP请求调用API。
-
代码实现 : 编写代码来上传图像、调用API并处理返回的结果。
-
错误处理与优化 : 对API调用过程中可能出现的错误进行处理,并根据需要对性能进行优化。
4.3 文字识别工具和API案例研究
4.3.1 成功案例分享
在本部分中,我们分享一个利用OCR API成功实现的案例,以说明如何有效地集成和利用OCR技术。
案例背景 : 某银行需要从纸质文档中提取客户信息,以实现电子化管理。考虑到信息量大且人工输入效率低下,该银行决定利用OCR技术自动化这一过程。
实施步骤 : 1. 选择合适的OCR工具,本案例中选择Google Cloud Vision API作为服务提供者。 2. 对银行的文档进行分类,确定需要OCR处理的文档种类。 3. 编写代码程序,集成Google Cloud Vision API,上传文档图像,提取其中的文本信息。 4. 结合银行的业务系统,将提取出的文本信息进行解析和存储。 5. 验证OCR识别的准确性,并对错误进行纠正。
结果评估 : 通过OCR技术的应用,银行实现了文档的快速电子化,识别准确率超过95%,极大地提高了工作效率和客户信息管理的便捷性。
4.3.2 问题诊断与解决方案
在实际应用OCR技术过程中,可能会遇到各种问题,下面列举了一些常见问题的诊断与解决方案。
问题一 : 文档图像质量差,导致识别准确率低。
解决方案 : - 对图像进行预处理,如二值化、去噪、校正歪斜等。 - 使用高清晰度扫描仪对原始文档进行扫描。 - 调整OCR API的相关参数,如阈值设置,以适应图像质量。
问题二 : 对于特殊字体或布局复杂的文档识别效果不佳。
解决方案 : - 选用支持多种字体和布局识别的OCR引擎。 - 利用机器学习技术对OCR引擎进行训练,以适应特定的文档格式。 - 使用图像编辑软件进行手动调整,改善识别效果。
这些问题和解决方案的探讨,有助于OCR技术实施者在项目中更有效率地解决问题,并且提升识别的质量和准确性。
5. MATLAB图像处理功能
5.1 MATLAB图像处理工具箱概述
5.1.1 工具箱特点和功能介绍
MATLAB图像处理工具箱提供了丰富的函数和应用,这些资源使得它成为图像处理领域的首选工具。它的主要特点包括:
- 广泛的图像处理功能 :工具箱包含从基本图像操作(如读取、显示和写入图像)到复杂的图像分析和增强技术(如图像滤波、变换、去噪)的全方位功能。
- 强大的图像分析工具 :包括用于边缘检测、区域分析和统计分析的工具,这些工具支持图像中重要特征的提取和量化。
- 直观的图形用户界面 :通过交互式的图像浏览器和应用程序,用户无需编写代码即可预览和编辑图像处理效果。
- 集成深度学习工具 :结合MATLAB深度学习工具箱,可以方便地构建和应用深度学习模型来进行图像识别和处理。
5.1.2 图像处理流程和方法
MATLAB中的图像处理流程通常包括以下几个步骤:
- 图像的读取与显示 :利用
imread函数读取图像文件,imshow函数显示图像。 - 图像预处理 :包括图像的缩放、旋转、裁剪等操作,使用
imresize、imrotate、imcrop等函数实现。 - 图像分析 :利用
edge、regionprops等函数进行边缘检测和图像区域的属性分析。 - 图像增强 :通过滤波和变换技术改善图像质量,例如使用
imfilter、fft2、ifft2等函数。 - 图像分割与特征提取 :根据特定需求将图像分为有意义的部分,并提取出有助于后续处理的特征。
5.2 MATLAB在图像预处理中的应用
5.2.1 图像滤波和增强技术
图像滤波旨在去除噪声或平滑图像。MATLAB提供各种滤波器设计和应用方法,比如:
% 使用内置的滤波函数进行图像去噪
h = fspecial('gaussian', [3 3], 0.5); % 创建一个高斯滤波器
filtered_image = imfilter(original_image, h, 'replicate'); % 应用滤波器
imshow(filtered_image); % 显示处理后的图像
在上述代码中, fspecial 用于创建一个高斯滤波器, imfilter 则将此滤波器应用到图像上进行去噪处理。参数 'replicate' 表示使用边缘复制法来处理图像边界。滤波效果可以通过调整 fspecial 函数的参数来优化。
图像增强技术如直方图均衡化,可以提高图像的对比度,使用 histeq 函数实现:
enhanced_image = histeq(original_image);
imshow(enhanced_image);
5.2.2 图像二值化和边缘检测
图像二值化是一种图像分割方法,用于将图像转换为黑白两色。MATLAB中的 imbinarize 函数可以实现此功能:
binary_image = imbinarize(original_image);
imshow(binary_image);
边缘检测用于识别图像中的边缘,常用的方法有Sobel算子、Canny算子等。以下是使用Canny方法的示例代码:
edges = edge(original_image, 'canny');
imshow(edges);
5.3 MATLAB实现字符识别流程
5.3.1 字符分割和特征提取
字符分割通常涉及将图像中的字符从背景中分离出来,以便进一步分析。在MATLAB中,可以通过连通区域分析来实现字符分割:
bw_image = imbinarize(original_image);
[labeled_image, num] = bwlabel(bw_image);
imshow(label2rgb(labeled_image));
上述代码段首先对原始图像进行二值化处理,然后使用 bwlabel 函数识别连通区域,并通过 label2rgb 函数将这些区域映射到不同的颜色以可视化。
特征提取是一个关键步骤,它影响到字符识别的准确度。常见的特征包括几何特征、纹理特征等。在MATLAB中,可以使用内置函数提取特征:
stats = regionprops(labeled_image, 'Area', 'Centroid');
该代码段使用 regionprops 函数获取每个连通区域的属性,如面积和中心点。
5.3.2 字符识别算法实现
字符识别算法实现涉及模式识别和机器学习技术。在MATLAB中,可以使用支持向量机(SVM)或神经网络进行训练和识别。以下是使用SVM进行字符识别的代码片段:
% 假设已经提取了一组特征 vectors 和对应的标签 labels
SVM_model = fitcsvm(features, labels);
% 对新图像进行特征提取后,使用训练好的SVM模型进行分类
predicted_label = predict(SVM_model, new_features);
在上述代码中, fitcsvm 函数用于训练一个SVM分类器。训练后,通过 predict 函数可以对新提取的特征进行分类预测。这一过程的准确率高度依赖于特征提取的质量和SVM模型的性能。
6. MATLAB机器学习框架应用
6.1 MATLAB机器学习环境搭建
6.1.1 环境配置和工具箱介绍
在开始任何机器学习项目之前,搭建一个合适的开发环境至关重要。对于MATLAB用户来说,机器学习环境的搭建主要涉及安装和配置MATLAB及其相应的工具箱。MATLAB是一个高性能的数值计算环境,提供了一系列用于算法开发和数据处理的工具箱。对于机器学习,MATLAB提供了Machine Learning Toolbox,其中包含了广泛的算法和函数,用于分类、回归、聚类分析、降维、特征提取和模型优化等任务。
为了使用Machine Learning Toolbox,你需要安装MATLAB的相应版本,并确保包含以下组件: - Statistics and Machine Learning Toolbox - Deep Learning Toolbox - Computer Vision Toolbox
这些工具箱提供了构建和训练机器学习模型所需的所有工具。安装完毕后,你可以使用MATLAB命令窗口的 ver 命令来验证工具箱是否已经正确安装。
6.1.2 数据预处理和特征工程
在进行机器学习之前,数据预处理是至关重要的一步,它直接影响到模型的训练效果。数据预处理通常包括清洗数据、标准化/归一化、特征提取、缺失值处理和数据分割等步骤。MATLAB提供了大量预处理函数,可以帮助用户快速完成这些任务。
例如,数据标准化通常可以通过以下代码实现:
X_standardized = zscore(X);
这段代码会将输入数据集 X 中的每个特征按其均值和标准差进行标准化处理。
特征工程是另一个关键步骤,它涉及到从原始数据中提取有用的特征来提高模型的性能。在MATLAB中,特征提取可以使用 pca 函数进行主成分分析,或者使用 graycomatrix 和 graycoprops 函数进行纹理特征分析。这些函数可以帮助用户从数据中提取出更有效的信息,为模型训练打下坚实的基础。
6.2 MATLAB中的机器学习算法
6.2.1 监督学习和无监督学习算法
MATLAB的Machine Learning Toolbox提供了多种监督学习和无监督学习算法。监督学习算法根据输入数据和对应的标签来训练模型,常见的算法包括线性回归、逻辑回归、支持向量机(SVM)、决策树和随机森林等。MATLAB通过函数如 fitcsvm 、 fitctree 等封装了这些算法的实现。
无监督学习算法则不依赖于标签数据,而是尝试发现数据中的模式和结构。聚类是一种常见的无监督学习技术,MATLAB提供了 kmeans 、 linkage 和 dendrogram 等函数用于实现聚类分析。
在MATLAB中,机器学习算法的训练和应用可以通过简单的函数调用来完成。例如,使用SVM进行分类的代码片段如下:
SVMModel = fitcsvm(X, Y);
YPred = predict(SVMModel, newX);
这里 X 是特征数据, Y 是标签, newX 是新的样本数据, YPred 是模型对新样本的预测结果。
6.2.2 算法选择和模型训练
模型选择是机器学习中的一个复杂问题,因为需要根据具体问题选择合适的算法。MATLAB提供了一个方便的交互式工具叫做 Classification Learner ,它允许用户通过图形界面比较不同模型的性能,选择最佳的模型进行训练。此工具可以通过MATLAB命令窗口输入 classificationLearner 来启动。
除了交互式工具之外,MATLAB还提供了 fit 系列函数来训练不同的机器学习模型。用户可以根据数据集的特点和需求选择适当的函数进行训练。模型训练完成后,可以使用 crossval 函数进行交叉验证来评估模型的泛化能力。
6.3 深入理解深度学习在OCR中的应用
6.3.1 深度学习基础和OCR的结合
深度学习是机器学习的一个子领域,近年来在图像识别、语音识别、自然语言处理等众多领域取得了显著的成果。深度学习的核心是构建多层神经网络,通过反向传播算法自动学习数据中的层次化特征。
在OCR领域,深度学习特别适用于处理复杂的图像识别任务,如手写体识别和场景文本识别。卷积神经网络(CNN)是深度学习中用于图像处理的主流网络结构,它通过层层卷积操作能够有效提取图像的局部特征,并通过池化层减少特征维度,降低计算复杂性。
MATLAB通过Deep Learning Toolbox提供了构建和训练深度学习模型的工具。用户可以使用MATLAB的层构建函数来设计网络架构,并通过预训练模型和迁移学习技术快速实现高性能的OCR系统。
6.3.2 实际应用案例分析与讨论
为了更好地理解深度学习在OCR中的应用,我们可以参考一些实际的案例分析。以车牌识别为例,深度学习模型可以被训练来识别不同国家和地区的车牌。通过使用大量带标签的车牌图片作为训练数据,卷积神经网络能够学习到车牌的形状、字符的结构和排列模式。
在MATLAB中,训练这样的深度学习模型可以遵循以下步骤: 1. 准备和标注数据集。 2. 设计CNN架构。 3. 使用训练数据来训练模型。 4. 对模型进行测试和评估。
例如,构建一个简单的CNN架构可以使用以下MATLAB代码:
layers = [
imageInputLayer([size(img,1) size(img,2) 3])
convolution2dLayer(3,8,'Padding','same')
batchNormalizationLayer
reluLayer
maxPooling2dLayer(2,'Stride',2)
fullyConnectedLayer(numClasses)
softmaxLayer
classificationLayer];
这里 img 是输入图像的大小, numClasses 是分类任务的类别数,即字母和数字的总数加上可能的分隔符。
模型训练后,可以使用MATLAB的 confusionmat 函数来评估模型的准确性,以及 plotconfusion 函数来可视化混淆矩阵,从而对模型的性能进行深入分析。通过这些实际案例的研究和讨论,我们可以看到深度学习是如何显著提高OCR系统的识别准确性和鲁棒性的。
简介:OCR技术能够将图像中的文字转换为可编辑的文本,广泛应用于文档处理、车牌识别等领域。本程序集包括MATLAB环境下OCR算法的关键实现步骤:字符分割和文字识别。字符分割涉及图像预处理和连通组件分析;车牌识别利用模板匹配和机器学习模型提高准确性;文字识别部分则依赖OCR工具箱和第三方库。MATLAB强大的图像处理和机器学习功能使得OCR算法可针对特定需求进行定制化开发。本压缩包是学习和实践OCR技术的宝贵资源,涵盖从图像预处理到最终应用的完整流程。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐



 9
9 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)