深度学习入门(6):R-CNN系列理论介绍
(2). 性能瓶颈:由于所有的候选框会被放缩到固定的尺寸,这将导致图像的畸变,不符合物体的常见比例,而且由于重复计算的问题,时间上难以容忍多尺度多比例的数据增强(data augmentation)方法去训练模型,使得模型的性能很难有进一步的提升;分别对应着我们回归参数 x 的smoothL1的回归损失,回归参数 y 的smoothL1的回归损失,回归参数 w 的smoothL1的回归损失与最后的
引言
前面所有提及的网络本质都是为了去为yolo系列铺垫,yolo系列是目前视觉部署算是比较通用的网络,因此在介绍yolo前的最后一站是其借鉴的前身R-CNN系列的思想。
本篇R-CNN借鉴目标检测算法R-CNN简介_rcnn是什么神经网络-CSDN博客
fast R-CNN参考Fast R-CNN网络结构、框架原理详解-CSDN博客
faster R-CNN参考目标检测之Faster R-CNN_faster rcnn-CSDN博客
正文
R-CNN
R-CNN思想比较简单,这是其整体流程:
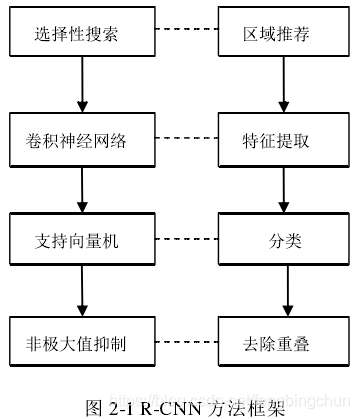
(1). 区域推荐(region proposal)即候选区域:常见的方法有selective search和edge boxes,给定一张图片,通过选择性搜索算法产生1000~2000个候选边框,但形状和大小是不相同的,这些框之间是可以互相重叠互相包含的;利用图像中的纹理、边缘、颜色等信息,可以保证在选取较少窗口的情况下保持较高的召回率(Recall);
(2). 特征提取:利用卷积神经网络(CNN)对每一个候选边框提取深层特征;
(3). 分类:利用线性支持向量机(SVM)对卷积神经网络提取的深层特征进行分类;
(4). 去除重叠:将非极大值抑制方法应用于重叠的候选边框,挑选出支持向量机得分较高的边框(bounding box)。
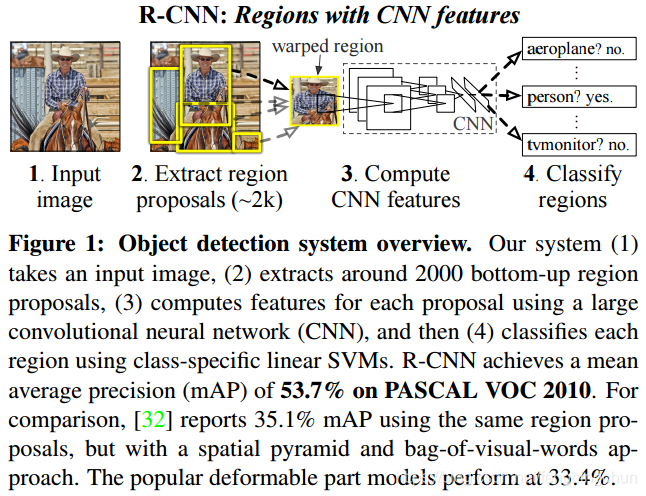
R-CNN缺点:
(1). 重复计算:重复为每个候选框提取特征是非常耗时的。Selective Search为每张图像产生大约2000个候选框,那么每张图像需要经过2000次的完整的CNN前向传播得到特征,而且这2000个候选框有很多重叠的部分,造成很多计算都是重复的,这将导致计算量大幅上升,相当耗时;
(2). 性能瓶颈:由于所有的候选框会被放缩到固定的尺寸,这将导致图像的畸变,不符合物体的常见比例,而且由于重复计算的问题,时间上难以容忍多尺度多比例的数据增强(data augmentation)方法去训练模型,使得模型的性能很难有进一步的提升;
(3). 步骤繁琐:整个训练过程分为多个步骤,步骤繁琐不易操作,而且每个阶段分开训练,不利于取得最优的解。此外,每个阶段得到的结果都需要保存,消耗大量的磁盘空间;
(4). 训练占用内存大:对于每一类分类器和回归器,都需要大量的特征作为训练样本;
(5). 训练过程是多阶段的:首先对卷积神经网络微调训练;然后提取全连接层特征作为SVM的输入,训练得到目标检测器;最后训练边框回归器;
(6). 目标检测速度慢;
(7). 输入CNN网络的图像大小固定为227*227,在输入网络前需要对候选区域图像进行归一化,容易使物体产生截断或拉伸,会导致输入CNN的信息丢失。
Fast R-CNN
Fast R-CNN 是为了解决 R-CNN 计算慢、存储开销大的问题而提出的一种目标检测方法,它对整个图像一次性提取特征,然后基于这些特征进行区域分类与边框回归。
整体流程图(简要概览)
- 输入图像
- 生成候选区域(ROI)
- 整张图像送入 CNN,提取特征图
- 将 ROI 映射到特征图上
- ROI Pooling(变成统一大小)
- 分类(Softmax)+ 边框回归(回归器)
- NMS 处理输出
Fast R-CNN 的完整流程:
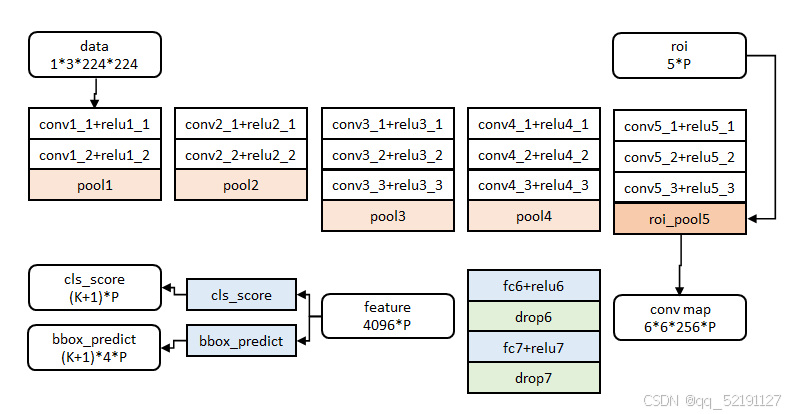
Fast R-CNN 工作流程详解
Fast R-CNN 是为了解决 R-CNN 计算慢、存储开销大的问题而提出的一种目标检测方法,它对整个图像一次性提取特征,然后基于这些特征进行区域分类与边框回归。
整体流程图(简要概览)
-
输入图像
-
生成候选区域(ROI)
-
整张图像送入 CNN,提取特征图
-
将 ROI 映射到特征图上
-
ROI Pooling(变成统一大小)
-
分类(Softmax)+ 边框回归(回归器)
-
NMS 处理输出
步骤详解:
步骤 1:输入图像
-
输入任意尺寸的原始图像。
步骤 2:生成候选区域(Region Proposals)
-
通常使用 Selective Search 算法,在原图中提取大约 2000 个候选框(ROIs)。
-
注意:这些 ROI 是 基于原图坐标系的。

步骤 3:整张图像送入 CNN,提取特征图
-
整张图像一次性输入 CNN 网络(如 VGG16),经过多层卷积与池化后输出一张 特征图(Feature Map)。
-
CNN 提取特征图时使用了下采样操作(如stride=16),所以特征图尺寸比原图小。
举例:
-
原图:800 × 600
-
特征图:800/16 × 600/16 ≈ 50 × 37(视网络而定)
-
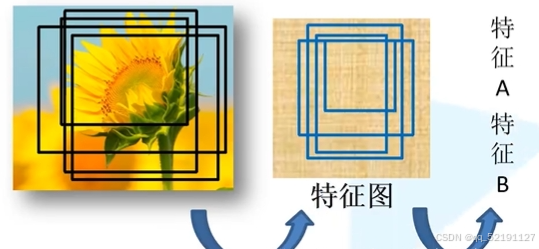
步骤 4:将 ROI 映射到特征图上
-
把原图中的 ROI 映射到特征图上:
-
使用一个缩放因子(通常为卷积网络的 stride,比如16)。
-
原图上的坐标除以 stride,得到特征图上的坐标。
举例:
-
ROI在原图中为 (x=160, y=160, w=160, h=160)
-
特征图缩小了16倍 → 对应为 (x=10, y=10, w=10, h=10)
-
-
步骤 5:ROI Pooling
-
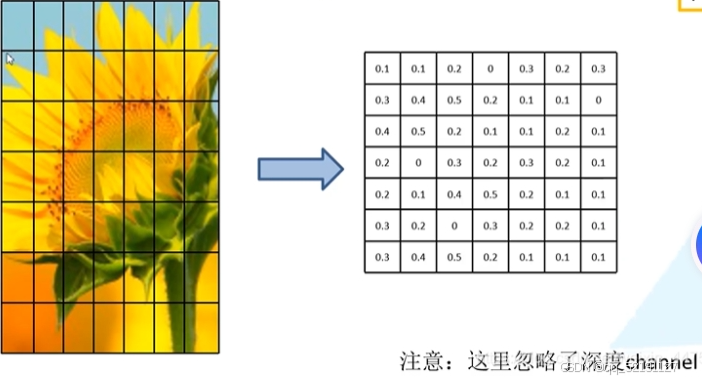
问题:不同 ROI 大小不一,无法直接送入全连接层。
-
解决:将 ROI 映射到特征图后,使用 ROI Pooling 操作把每个区域转为固定大小(如 7×7):
-
把 ROI 区域划分成 7×7 个小块;
-
每个小块里做 最大池化;
-
得到一个统一大小的 7×7 特征图(+通道数)。
-
-
步骤 6:分类 + 边框回归
-
ROI Pooling 之后,特征送入:
-
全连接层 → 提取最终特征;
-
分成两个分支:
-
Softmax 分类器 → 判定 ROI 属于哪个类别;

-
边框回归器 → 对 ROI 的位置进行微调(输出4个偏移值:dx, dy, dw, dh)。
-
-
步骤 7:正负样本采样(训练阶段)
-
Fast R-CNN 训练时不能用所有 ROIs(太多、太多负样本)。
-
所以做正负样本采样:
-
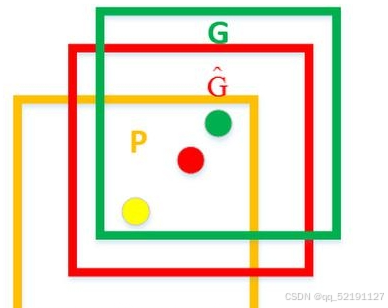
正样本:与某个 Ground Truth 的 IoU ≥ 0.5;
-
负样本:与所有 GT 的 IoU ∈ [0.1, 0.5);
-
-
从中采样固定数量(例如一个 mini-batch 取 128 个 ROIs,正负比例 1:3)。
步骤 8:训练目标函数(Multi-task Loss)
Fast R-CNN 的损失函数是一个多任务损失函数,包括:
-
分类损失(softmax loss)
-
边框回归损失(smooth L1 loss)
总损失 = 分类损失 + λ × 回归损失(λ 通常为1)
其中真实目标边界框回归参数的计算公式为:
其中对于分类损失:
其中对于边界框回归损失:
注意,这个损失是由4个部分组成的。分别对应着我们回归参数 x 的smoothL1的回归损失,回归参数 y 的smoothL1的回归损失,回归参数 w 的smoothL1的回归损失与最后的回归参数 h 的smoothL1的回归损失。
tu对应边界框回归器预测的对应类别u的回归参数(tux,tuy,tuw,tuh)
v对应真实目标的边界框回归参数(vx,vy,vw,vh)
而具体的smoothL1损失的计算公式为:
λ 是一个平衡系数,用于平衡分类损失与边界框回归损失。
[u ≥ 1] 是艾佛森括号,也可以理解为一个计算公式。当u满足条件是,公式的值为1;而当u不满足条件时,也就是u<1时,也就是u=0时,(u为类别的标签),此时类别标签为背景,公式的值为0.
u代表了目标的真是标签,u ≥ 1表示候选区域确实属于所需检测的某一个类别当中,也就是对应着正样本。当u=0时,此时候选区域对应着为背景,不属于所需检测的某一个类别当中。那既然是背景,就没有边界框回归损失这一项了。
也就是Fast R-CNN的总损失 = 分类损失 + 边界框回归损失然后对其进行反向传播就可以训练Fast R-CNN网络了。
步骤 9:推理(测试阶段)
-
对图像进行一次前向传播,得到特征图;
-
对每个 ROI 进行 ROI Pooling → 分类+回归;
-
最后使用 NMS(非极大值抑制) 去除重叠高的候选框,输出最终检测结果。
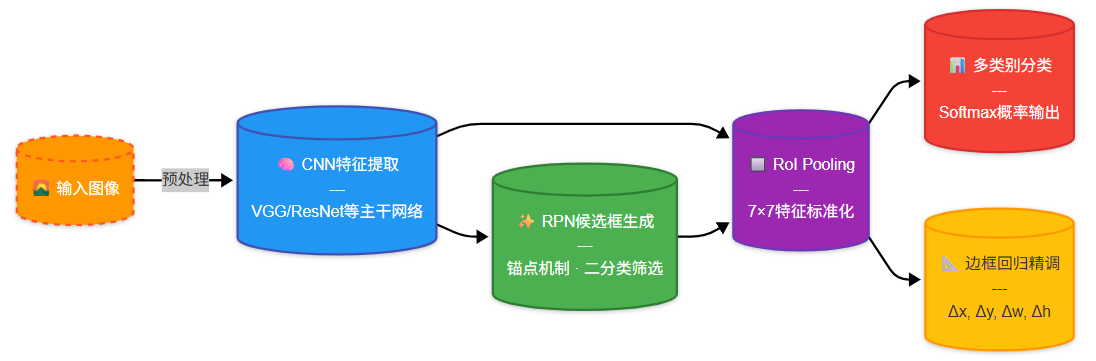
Faster R-CNN
Faster R-CNN 的总体流程图
Faster R-CNN 的整体结构可以分为两个主要阶段:
- 特征提取 + 候选区域生成(RPN)
- 候选区域分类与边框回归
简要流程如下:
一、输入阶段
-
输入一张原始图像(RGB 图像)
二、特征提取(Backbone)
-
使用 CNN 主干网络(如 ResNet、VGG)对图像提取特征图
F
原始图像 → [Backbone CNN] → 特征图 F(尺寸较小但包含语义信息)
三、区域建议网络 RPN(Region Proposal Network)
功能:
从特征图 F 上,生成一组可能包含目标的候选区域(Region Proposals)。
详细步骤:
-
在每个特征点生成多个锚框(anchors)
-
多尺度 + 多比例(例如每点生成 9 个)
-
-
对每个 anchor 执行两项任务:
-
分类:是目标 or 背景?(2类)
-
回归:微调位置,让它更贴近真实目标(bbox regression)
-
-
生成候选框(Proposals)
-
经过 NMS(非极大值抑制)去除重复/重叠度太高的框
-
输出前
N个得分最高的建议框(如 200 个)
-
特征图 F → [RPN] → 候选框 proposals(约 200 个)
四、RoI Align(区域特征对齐)
-
将每个候选框映射到特征图 F 上,提取对应区域的特征
-
使用 RoI Align(或早期的 RoI Pooling)统一为固定尺寸(如 7×7)
Proposals + 特征图 → [RoI Align] → 每个 proposal 对应一个固定大小的特征
五、Fast R-CNN Head(分类 + 精修框)
对每个 proposal 的特征执行:
-
分类(多分类)
-
猫?狗?人?背景?等类别
-
-
边框回归
-
再次调整框的位置,使其更精确地贴合目标边界
-
RoI 特征 → 分类得分 + 精细边框坐标(回归)
六、输出(最终检测结果)
-
根据分类得分选择非背景类
-
使用 NMS 去掉重复框
-
最终输出每个目标的:
-
类别(标签)
-
位置(bbox 坐标)
-
置信度(score)
-
最终输出:[(label, score, bbox), ...]
训练流程总结
联合训练(end-to-end):
整个网络(Backbone + RPN + Fast R-CNN Head)是一起训练的,loss 结构如下:
每次输入图像后:
-
一次前向传播
-
一次反向传播
-
更新所有模块的参数(包括共享的 backbone)
总流程图(简化版)
原图像
↓
[Backbone CNN] 提取特征图
↓
┌─────────────┬──────────────────────┐
│ │ │
│ [RPN:候选区域生成] │
│ ↓ ↓
│ proposals(粗略位置) │
└─────────────┬──────────────────────┘
↓
[RoI Align]
↓
[Fast R-CNN Head]
↓
分类(多类) + 精修(框回归)
↓
[NMS + 输出结果]

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐



 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)