惠普、英伟达等领衔,百万比特量子计算机落地路线图公开!量子-HPC协同方案将终结经典算力瓶颈
尽管p-bit无法替代qubit,但其硬件和采样技术可以显著推动经典模拟的边界,为高性能计算中的优化和采样任务提供加速,并可集成到异构混合量子-经典硬件架构中。半导体产品成本的大幅降低很大程度上是由于激烈的竞争,因此,利用竞争性的半导体供应链的量子计算机也将随着时间的推移降低成本。然而,电路编织的指数级采样开销仍是亟待解决的问题。对FeMoco(一种广泛研究的超越经典量子模拟候选对象)的资源估计,
近期,来自惠普、1QBit、Quantum Machines、威斯康星大学麦迪逊分校、加州大学圣塔芭芭拉分校、英伟达、费米国家实验室、应用材料公司(Applied Materials)、美国宇航局(NASA)、Synopsys、Qlab、滑铁卢大学、圆周理论物理研究所等的研究人员在arXiv平台发表题为“How to Build a Quantum Supercomputer: Scaling from Hundreds to Millions of Qubits”(如何构建量子超级计算机:从数百个量子比特扩展到数百万个量子比特)的研究论文。

这篇文章从超导路线出发,全面审视了量子计算规模化过程中的挑战,指出通过以下途径可突破发展瓶颈:采用现有半导体技术构建更高质量的量子比特、运用系统工程方法、在异构高性能计算基础设施中实现分布式量子计算。研究表明,通过量子硬件与算法的协同优化可实现数个数量级的性能提升。同时研究团队论证,为经济高效地解决工业级经典优化与机器学习问题,应当将基于定制加速器的异构量子-概率计算作为规模化发展的补充路径。
研究团队预估,量子超级计算机的成本将达到1亿到10亿美元。同时强调,转向半导体兼容的制造工艺对于降低成本至关重要。
目录
(一)迈向经济高效的量子计算技术
(二)迈向高性能混合量子-经典计算
(三)近期应用:分布式量子模拟
(四)迈向量子启发与量子辅助的概率计算
(五)总结
*为全面呈现这篇论文的精华内容,我们分上、中、下三篇系列推文对其进行编译。本文为系列文章的第三篇,承接(一)(二)(内容包括量子计算机的过去现在与未来挑战、量子硬件的系统工程、量子计算规模化进程、迈向高质量量子硬件和高性能控制、迈向容错量子计算、容错量子计算的资源估计等),欲知前文请点击下方链接阅读。
如何构建量子超级计算机?惠普、英伟达、NASA等十余家单位科研人员合作完成,一篇论文讲清了(一)
如何构建量子超级计算机?惠普、英伟达等十余家单位科研人员,用一篇论文讲清了(二)

迈向经济高效的量子计算技术
实用规模的量子计算机应被定义为一种其计算价值超过总成本的机器。实现实用规模是量子计算的一个关键里程碑,标志着这些先进系统在经济上开始适用于实际应用。人们普遍预期,最初的量子计算机将极其昂贵,远远超出实用规模的范围。因此,我们必须分析量子计算机成本降低的速率,以便其能够覆盖更多的实用规模问题。本文首先描述降低量子超级计算机成本的系统工程考虑因素,然后讨论量子超级计算机的供应链如何随着时间降低研发和制造成本。
(一)系统工程
基于上文(详见系列推文第二篇)对FeMoco(一种广泛研究的超越经典量子模拟候选对象)的资源估计,初步估计表明,实用规模的量子计算机需要10到50个量子加速器,每个加速器需要10万到100万个量子比特。这些是粗略估计,由于量子比特质量、算法改进以及用于连接量子加速器的技术等因素,存在相当的不确定性。乐观估计,建造每个加速器的成本约为1000万美元,因此可以想象,量子超级计算机的成本将达到1亿到10亿美元。
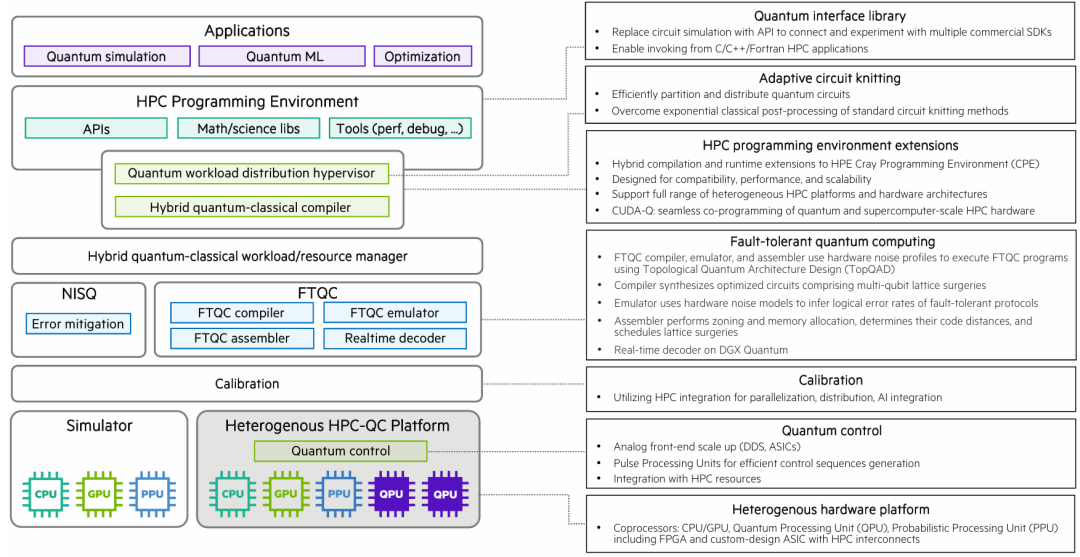
图:量子-经典全栈解决方案架构图。在最高层,HPC编程环境扩展以包括量子加速器API,包括用于无缝调用量子内核的接口库、用于高效量子工作负载分区和分布的自适应电路编织监督器,以及混合量子-经典编译器。混合量子-经典工作负载管理器确保在多用户环境中最优量子资源利用。为了支持容错量子计算,编译器、仿真器、汇编器和实时解码器共同使用已知的硬件噪声特性来合成优化的容错量子电路以解决手头的问题。量子资源的校准和控制使用与HPC集成的专业硬件。包括CPU/GPU、量子处理单元(QPU)、概率处理单元(PPU)在内的异构协处理器允许系统将特定问题划分为子问题,这些问题可以发送到适当的协处理器。
目前,超导量子比特的成本主要由同轴电缆、稀释制冷机(由于环流器的尺寸和功率)以及量子比特的质量主导。例如,一个拥有150个量子比特的超导量子计算机仅在布线上就需要约400万美元,稀释制冷机则需约100万美元。直接扩展到10万个量子比特的系统将成本过高。研究认为,通过柔性布线和晶圆级布线晶圆的结合,可以消除同轴布线。量子比特的质量也是一个关键因素,因为可产生的逻辑量子比特数量主要由量子比特的质量决定。
系统的其他方面可以显著降低成本:利用现成的CMOS工艺进行低温控制可以降低每个射频通道的成本。此外,通过利用现有的HPC基础设施,可以将量子纠错等昂贵的经典计算任务卸载到其他设备上。
(二)供应链管理
除了制造和运营费用,量子计算机的成本还包括摊销的研发投资。本文的观点是,利用现有的半导体供应链可以帮助分摊研发和制造的成本。为了进一步实现这种分摊,确保尽可能多地重用量子模块和制造技术用于各种量子应用(尤其是具有重大计算需求的应用)也至关重要。
本文对半导体供应链的分析提出了两个问题:
1)供应链是否具有足够的竞争力以降低成本,同时避免依赖单一来源或受外国控制的制造?
2)未来10年,可以利用哪些现有的半导体研究项目降低实用规模量子计算机的研发成本?
从制造成本的角度来看,转向半导体兼容的制造工艺对于降低成本至关重要。
美国正在通过公私合作伙伴关系(例如美国CHIPS法案)建设多个300毫米先进制造设施,这将减少对单一来源/外国制造商的依赖。尽管这种方法需要升级半导体代工厂的设备,但升级的成本只是建设最先进的300毫米代工厂成本的一小部分,这反过来又将降低建造量子超级计算机所需的各个组件的成本。
半导体产品成本的大幅降低很大程度上是由于激烈的竞争,因此,利用竞争性的半导体供应链的量子计算机也将随着时间的推移降低成本。此外,像应用材料公司和纽约州立大学理工学院等现有的研究代工厂可以在量子计算完全商业化之前作为临时制造设施。量子计算机的运行可以与运行GPU机架相提并论,都需要复杂的冷却要求和能耗密集型操作。例如,当今的超导量子计算机运行大约需要20千瓦的功率,其中大部分被稀释制冷机和微波电子设备消耗。因此,建立供应链以降低量子计算机的运营负担也是至关重要的。
本文概述了如何通过跨半导体研究工作的联盟来降低研发成本:
1)纳米级晶体管的进步需要对制造参数进行原子级控制,这反过来又可以抑制双能级系统缺陷;
2)消除大型AI芯片的内存瓶颈,进而实现低温晶圆级集成;
3)通过低温CMOS降低AI芯片的能耗,可用于可扩展的射频控制;
4)将射频控制技术(如相控阵微波接收器)扩展到可扩展的量子控制;
5)将量子计算机与由各种经典硬件加速器(包括GPU、FPGA和PPU,即专门的ASIC和为概率计算定制设计的硬件)驱动的异构高性能计算集成,可以在速度和能效方面实现数量级的提升。
将现有的半导体研究整合到量子计算中,其好处可能是相互的。

迈向高性能混合量子-经典计算
量子计算作为高性能计算(HPC)的有力补充,被视为超越百亿亿次级系统的潜在技术。量子计算机并非要完全取代经典计算机,而是作为加速器,执行特定任务。要实现大规模实用量子计算,必须实现与现有异构HPC基础设施的无缝集成,并开发完整的混合量子-经典计算堆栈。
将量子计算与HPC结合面临诸多挑战,包括硬件和系统设计上的差异(如物理尺度、可靠性、控制电子学等),以及算法上的问题(如内存访问、数据共享和移动)。某些量子算法缺乏可卸载到量子处理单元(QPU)的清晰内核,且数据移动开销可能会抵消量子算法的性能优势,尤其在变分算法中。因此,物理共置经典和量子计算资源、实现低延迟高带宽通信是必要的。
(一)HPC编程环境扩展
混合量子-HPC系统需要易于编程。将QPU视为加速器,尽量减少对HPC程序结构的更改,可降低开发风险。一种解决方案是将量子编程、编译和执行工具集成到现有的经典HPC编程环境中,例如HPE Cray编程环境(CPE)。CPE支持多种编程环境和硬件架构,通过扩展可以显著减少开发工作量,并支持多种量子SDK(如CUDA-Q、Qiskit等)。开发工作包括量子接口库、量子编译器和运行时扩展,以及自适应量子电路编织管理程序,以实现量子工作负载的高效分配。
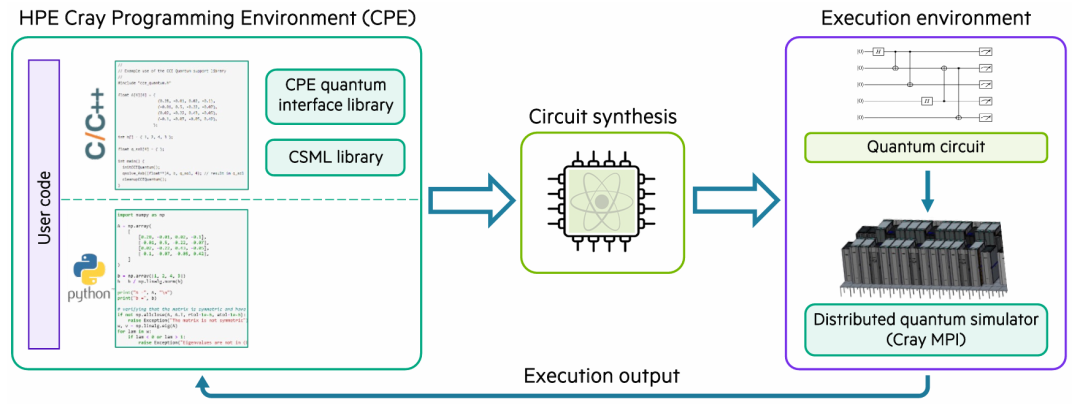
图:利用CPE 量子接口库的混合量子-HPC 应用程序开发工作流程示意图。
· 具有API扩展的量子接口库
CPE量子接口库已成功应用于开发混合量子-HPC应用,支持Python和C/C++编程语言。量子内核由Classiq的量子SDK提供。例如,使用HHL算法求解线性方程组的结果与CPE BLAS库的偏差小于2%;QAOA算法用于解决MaxCut问题,将大型图划分为可在量子设备上表示的子图。这些应用展示了混合经典-量子执行的潜力,尤其在超级计算机上。HPE和Classiq在IPDPS24上发表了相关研究,并在ISC24上通过芬兰LUMI超级计算机接入的20量子比特设备进行了演示,通信开销在秒级,但可通过紧密集成进一步降低。
· 量子编译器和运行时扩展
随着量子比特数量和硬件性能的提升,编译瓶颈和经典-量子组件间的延迟成为关键问题。研究者正通过扩展经典编译工具链(如Clang/LLVM)来解决大规模量子-HPC工作负载的编译问题。量子汇编语言OpenQASM和LLVM IR/QIR被用作中间语言,以适应不同量子硬件和软件。CUDA-Q等工具通过动态代码生成技术优化量子程序的执行,确保硬件支持和软件兼容性。
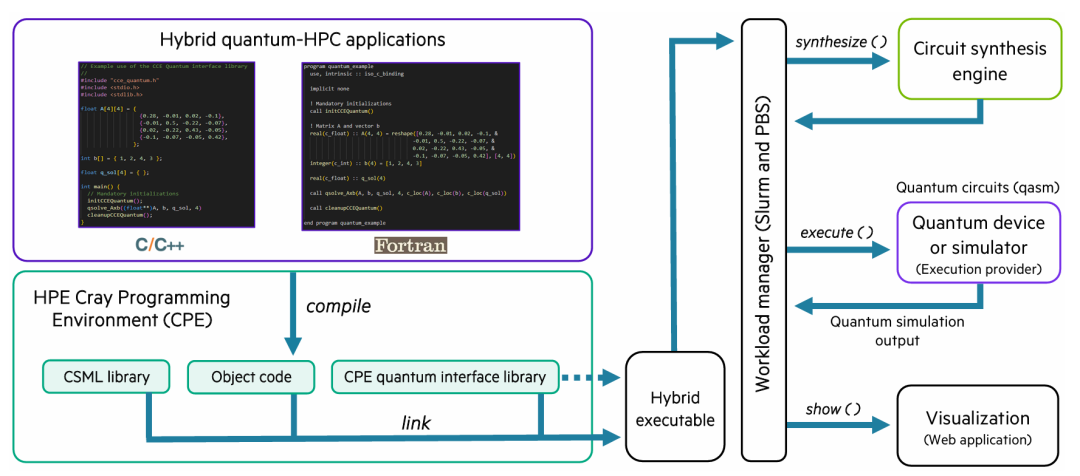
图:通过HPE Cray编程环境(CPE)中的量子接口库,在C/C++/Fortran中开发和执行混合量子HPC应用程序。
· 多QPU工作负载分配管理程序
为了实现量子计算的大规模运行,需要在多个QPU上高效并行化工作负载。研究者开发了自适应电路编织策略,作为分布式经典和量子计算节点之间的管理程序。该策略利用机器学习优化量子电路分解,捕获最大量子纠缠,同时实现高性能通信。这种方法支持分布式量子模拟和量子机器学习,为大规模量子计算提供了新的可能性。
(二)异构量子-经典超级计算的编程框架
开发高效的量子-HPC系统软件平台是异构量子-经典计算的主要挑战之一。近期和中期的算法需要同时高效利用CPU、GPU和QPU,这要求精确的资源估计和能够平衡工作负载的调度器。然而,量子硬件供应商提供的硬件规格和软件库难以获取,且缺乏标准化接口和协议,使得QPU与现有HPC系统的集成变得复杂。针对近期关键应用(如量子纠错)的平台必须支持GPU和QPU之间的低延迟执行和紧密协调。CUDA-Q因其对GPU加速和内核执行的原生支持,成为一种有前景的解决方案,特别适合像DGX Quantum这样的紧密耦合异构系统。此外,动态电路编程和中间测量能力(如量子子空间扩展和零噪声外推)对于实现混合量子-经典计算框架至关重要。
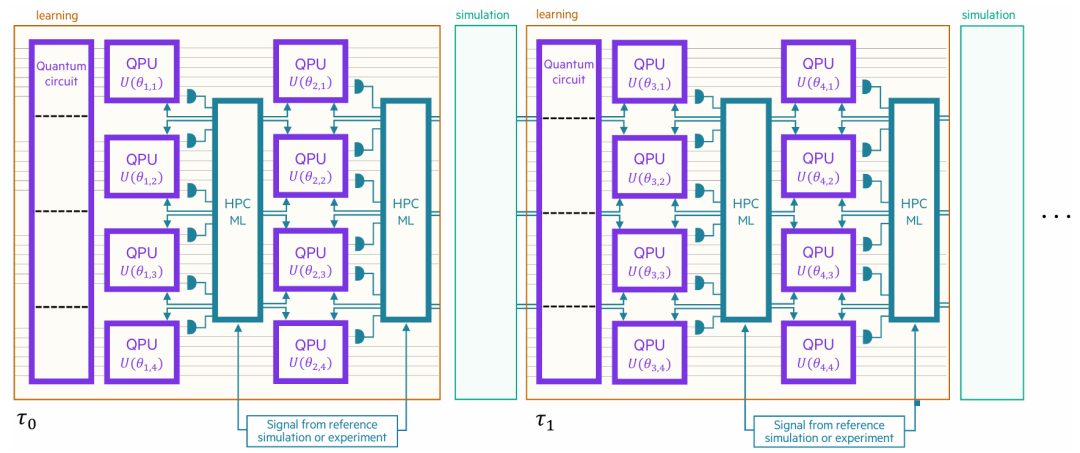
图:自适应电路编织管理程序(用于分布式量子模拟/学习)
(三)高性能量子工作负载分配
现有的量子处理器量子比特数量有限且保真度较低,难以解决大规模实用问题。即使未来的纠错量子计算机也难以满足实用所需的逻辑量子比特数量。因此,必须在多个QPU之间高效分配计算任务。电路编织技术通过将大型电路分解为可在NISQ设备上运行的子电路,成为一种有前景的解决方案。然而,电路编织的指数级采样开销仍是亟待解决的问题。为此,研究者提出了自适应电路编织(ACK)技术,通过机器学习动态优化量子电路分解,减少采样开销。ACK框架可以作为管理程序,支持分布式量子模拟和机器学习,并通过MPI实现QPU之间的通信。进一步的推广是时空异构电路编织(SHCK),通过动态切割和合并电路,将子电路分配到不同的量子和经典加速器上,以实现高效计算。
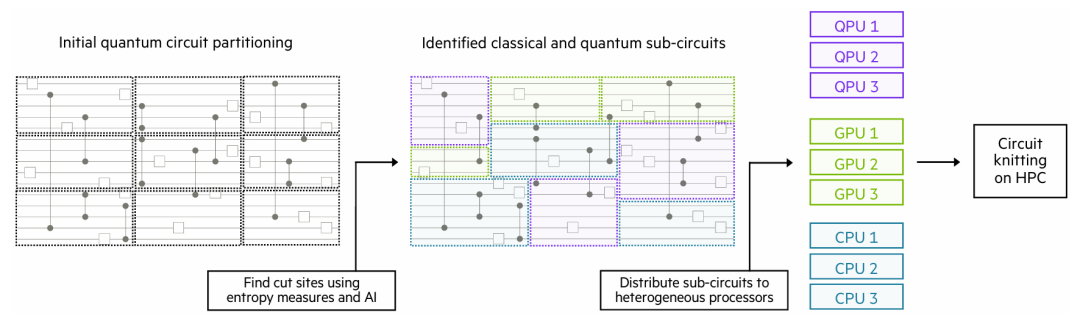
图:时空异构电路编织(SHCK)框架
(四)高性能量子-经典工作负载调度
量子计算资源稀缺,高效利用是关键,尤其在多用户环境中。量子计算机的利用率受校准时间和任务执行开销影响,大规模量子处理器需高效校准,同时通过基准测试任务监控校准状态。混合量子-经典算法的执行开销主要来自量子任务的执行和加载,其时间尺度从毫秒到秒不等,与经典任务差异显著。例如,超导量子比特的测量任务仅需毫秒级时间,而其他模态可能需数秒。迭代任务的持续时间可能大幅增加,导致量子计算机在经典计算阶段空闲,尤其在交互式工作流中,空闲时间可能延长。
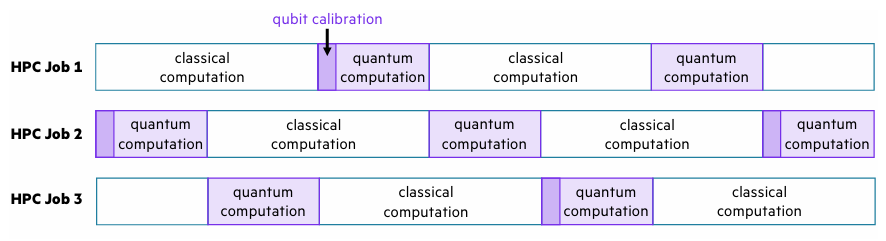
图:三个迭代经典量子算法的示例
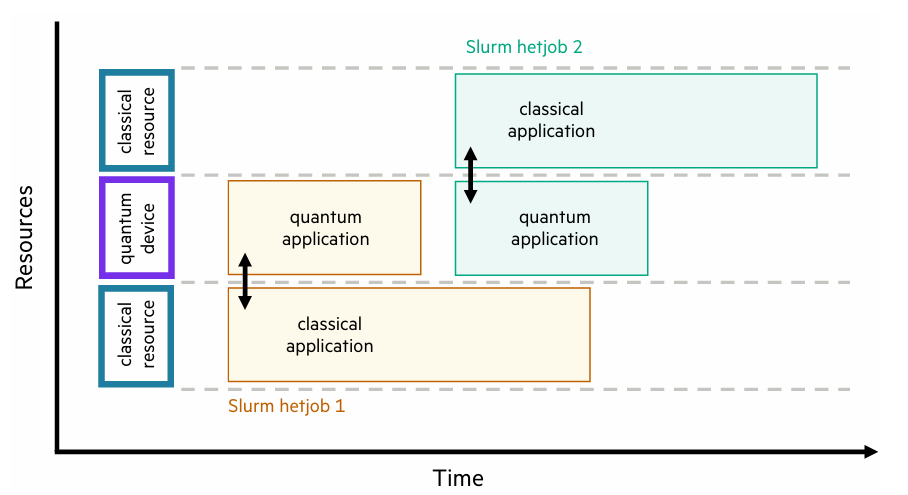
图:两个Slurm异构作业的示意图
为优化量子计算机利用率,需同时调度不同算法和作业的任务,减少经典计算阶段的空闲时间。在无法实现最优调度时,单个用户可通过工作负载管理器(如Slurm)独占量子设备,但可能浪费资源。通过Slurm的异构作业支持,可减少空闲时间,但量子和经典计算的同步开始无法保证。未来需开发更智能的自适应和异构任务调度算法,考虑量子资源可用性并动态调整任务分配。
(五) 混合量子-经典计算的算法设计
尽管量子处理器取得进展,但目前仍小且脆弱;许多量子或混合算法虽有量子优势,但实际性能分析因硬件缺乏和模拟开销而难以捉摸。随着硬件成熟,混合算法将在容错量子计算(FTQC)时代占据主导地位,长期来看仍是性能最佳的算法。排序等任务已被证明不存在量子优势,许多量子算法在实际应用中也难以体现量子优势,这些任务将继续由经典计算解决。
分布式量子计算硬件的研究仍处于起步阶段,设计标准包括联合推进经典和量子算法,利用经典算法和高性能计算(HPC)的知识,考虑常数和对数因子,识别常见量子子程序,评估经典数据与量子子程序之间的交互代价,以及进行算法、纠错和硬件的协同设计。
· 超越二次加速:组合优化中的量子优势
许多经典搜索算法的子程序可以用具有二次量子加速的量子子程序替换,但必须考虑经典数据访问的开销。二次加速可能仅在远期容错量子计算阶段才有用,而四次加速则更有希望。最近的研究表明,某些组合优化问题可能实现四次甚至指数级加速。未来的研究方向包括扩展提供此类加速的技术范围、将其纳入混合量子-经典方法并探索分布式实现。许多研究小组继续探索量子近似优化算法(QAOA)和其他变分算法,这些是最简单的可能奏效的算法。
· 常见子程序
许多利用量子计算的算法需要量子版本的经典例程,例如实现初等数值函数的量子电路。开发这些子程序的显式电路、为混合架构创建分布式版本以及了解何时使用经典计算与量子计算是实现量子计算影响的关键方向。量子傅里叶变换是另一个重要领域,进一步提高其在分布式架构中的效率是很有希望的研究方向。
· 量子辅助和量子就绪的机器学习
机器学习和人工智能是快速发展的领域,混合方法可以在推动这些领域的发展中发挥作用,为当前使用提供支持,同时为量子计算的长期潜在影响提供见解。量子就绪算法包括可以被量子子程序替换的经典算法,例如量子辅助变分自编码器(QVAE)和量子辅助关联对抗网络(QAAAN)。
(六)混合量子-经典计算机的性能基准测试
需要对混合量子-经典计算机进行全面性能基准测试,而不仅仅是关键组件的功能测试。理想情况下,性能基准测试应硬件无关,但这在中等规模的测试中可能难以完全实现。可以借鉴HPC领域的经验,该领域已开发出多种针对不同类型计算的性能基准,如密集线性代数(HPL)、图分析(Graph500)、人工智能(MLPerf)和科学工作负载(NPB)等,为评估计算性能提供了重要参考。
尽管目前已有算法层面的基准测试提议,但在中等规模的基准测试方面仍有大量工作要做。测试的设计可以参考DARPA QB计划中识别的高影响力实用规模问题。随着量子硬件的成熟,开发能够指导和衡量硬件及算法发展的基准测试族至关重要。这些基准测试应具有可调节的规模和难度,以适应量子计算不同发展阶段的性能测试需求。
此外,未来的工作需要从仅关注量子处理时间转向同时考虑经典处理时间,还要帮助识别瓶颈并为硬件和算法开发设定优先级。

近期应用:分布式量子模拟
近期量子计算机仍将只有相对较少的量子比特与较低的门保真度,在此期间,经典量子计算机模拟器,尤其是针对HPC系统优化的模拟器,在原型设计、基准测试和量子算法开发中具有重要意义。
(一)多GPU:二维横向场伊辛模型的动态量子相变
这项研究利用多节点、GPU加速的CUDA-Q NVIDIA态矢量模拟器,研究量子材料中的奇异现象,助力新材料设计,展示了CUDA-Q如何在HPC系统上编译和执行分布式量子电路模拟。
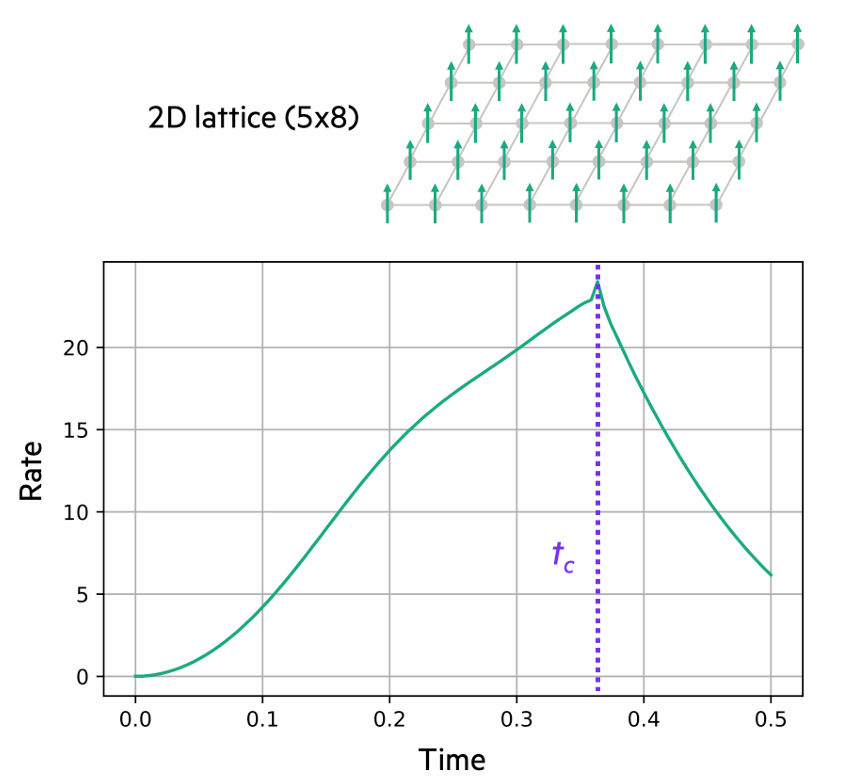
图:在40量子比特二维横向场伊辛模型中观察到的动态量子相变(DQPT)
研究团队在从单个CPU到128节点(512个GPU)的各种计算配置上,对二维自旋晶格进行了多次模拟。上图展示了在最大的8×5自旋晶格(40个量子比特)中发现的动态量子相变(DQPT)。在许多模拟的相变中,量子系统的纠缠熵接近最大值,难以用张量网络技术进行经典模拟。对于单个A100 GPU,20到25个量子比特的一个Trotter时间步的电路执行时间范围为0.04–4秒;对于分布在512个A100 GPU上的40个量子比特,时间约为1小时,比30个量子比特的CPU模拟快近两个数量级。
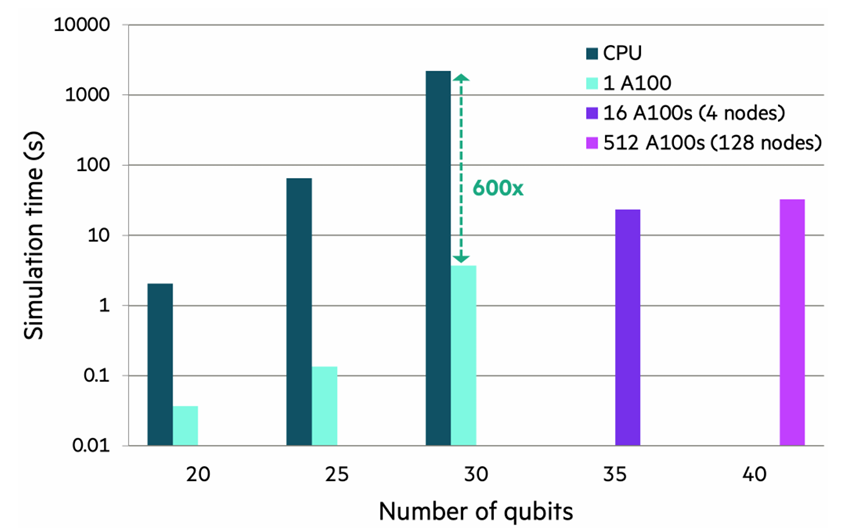
图:CUDA-Q模拟器在不同硬件配置下的性能对比
这些结果突显了软件和硬件的多节点并行效率。高性能态矢量模拟器能够准确研究多达40个量子比特的二维自旋晶格中的DQPT,超出了近似方法的能力。该框架还可用于研究其他量子系统以及噪声的影响。然而,即使是超级计算机,超过40个量子比特的态矢量模拟也难以实现,因此近似方法(如张量网络技术)变得至关重要。
(二)多QPU:强无序量子自旋玻璃
本节介绍了自适应电路编织(ACK)方法,用于降低量子电路编织的采样开销。该方法通过在纠缠最小的位置切割电路,显著降低了经典计算开销。ACK方法借鉴了张量网络技术,结合了线性深度量子电路的结构,能够高效表示量子态并优化纠缠模式。通过迭代优化和熵热图分析,ACK方法动态调整切割位置,以最小化分区之间的纠缠。
研究以强无序量子自旋链为例,展示了ACK方法在模拟非平衡动力学中的应用。结果表明,与简单的负载平衡切割相比,自适应切割的开销降低了1到2个数量级。在32量子比特的模拟中,自适应切割的中位数成本降低了15倍,75%和95%的百分位数分别降低了59倍和450倍。随着模拟时间的增加,自适应切割的优势更为明显。
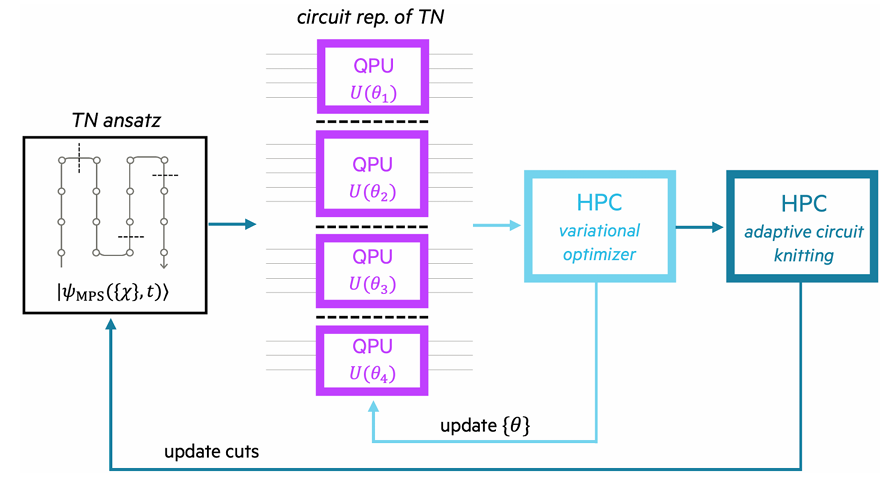
图:基于张量网络的自适应电路编织方法示意图
这种ACK方法有望在近期应用中高效划分量子电路,尤其在模拟凝聚态系统时。未来的工作将包括研究快速纠缠度量、改进收敛标准以及探索二维系统中的高阶张量网络技术,高性能的CUDA-Q实现将为这些方法的快速原型设计提供支持,捕捉有趣的物理现象。

迈向量子启发与量子辅助的概率计算
随机性在计算算法中的作用早已被认可,尤其是蒙特卡洛算法,它被广泛认为是20世纪十大算法之一。如今,大量工作负载(如组合优化、计算科学和人工智能)本质上是概率性的。短期内部署工业规模的概率计算机,可以为未来量子技术开发软件栈、专业知识和市场契合度。概率计算机借鉴物理学中的随机动力学、异步更新等特性,通过大规模并行演化实现复杂的多体现象,难以用传统计算模拟。概率比特(p-bit)可作为蒙特卡洛算法、贝叶斯学习、组合优化等概率应用的原生处理器。尽管p-bit无法替代qubit,但其硬件和采样技术可以显著推动经典模拟的边界,为高性能计算中的优化和采样任务提供加速,并可集成到异构混合量子-经典硬件架构中。
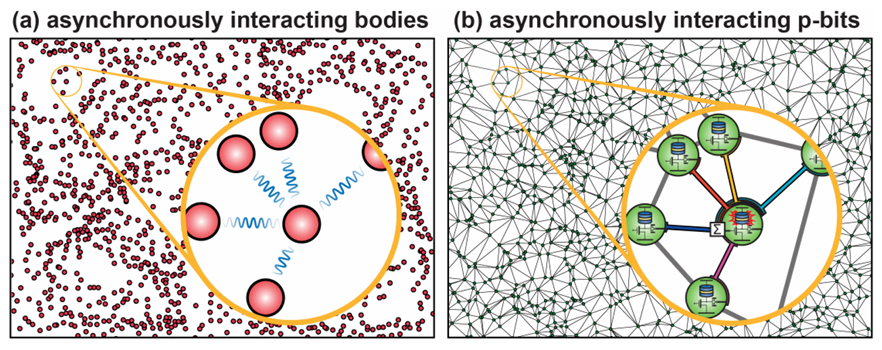
图:(a)异步相互作用体与(b)概率比特的物理类比。两者均具有异步性、稀疏连接的局域相互作用及大规模并行特性,展现了多体概率系统的计算潜力
(一)具有内在高阶相互作用的概率计算
概率计算机(p-computer)通过吉布斯采样实现马尔可夫链蒙特卡洛算法,基于随机激活和局部场计算。基于存内计算的高阶架构已实现,通过交互矩阵编码子句变量,用于解决k-SAT问题。与传统二次无约束二进制优化(QUBO)相比,高阶相互作用允许原生嵌入问题,无需辅助变量,从而提高收敛速度,减少硬件资源利用。
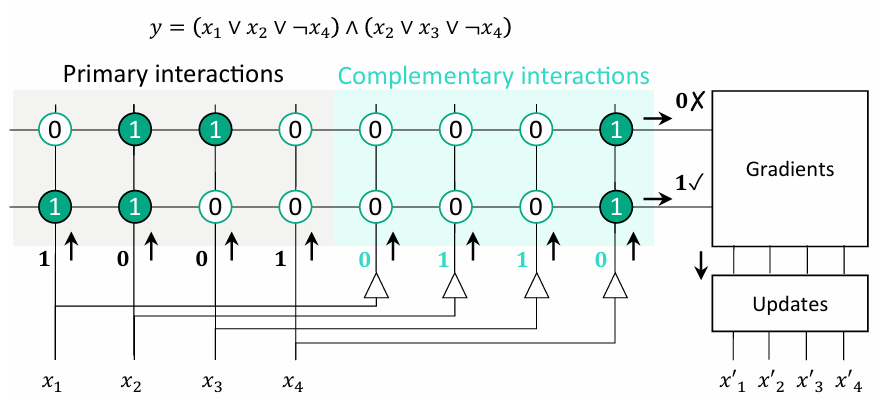
图:基于存内计算实现k-local相互作用加速的SAT公式求解架构
(二)p-计算机的硬件实现
p-计算机的硬件实现方式多样,包括嘈杂材料、模拟和数字CMOS技术。目前最先进的p-计算机基于磁隧道结(MTJ)的纳米器件原型,利用MTJ的自然噪声解决小规模问题,展示了磁随机存取存储器(MRAM)技术作为构建能效型p-计算机的潜力。磁存储行业已实现与CMOS晶体管集成的MTJ的千兆比特密度。将这些MRAM芯片中的稳定MTJ转变为低势垒的不稳定状态,有望开发出集成数千万p-bit的专用概率计算机。
在实现大规模集成p-计算机之前,研究人员已通过CMOS基的现场可编程门阵列(FPGA)构建p-bit的数字仿真器,研究大规模p-计算机的架构和算法性能。即使是基于单个FPGA的p-计算机实现,也展现出与现有技术相媲美的性能。
(三)扩展p-计算机:分布式方法
单个处理单元(PE)如FPGA/GPU/TPU通常无法处理包含数千到数百万变量的实际问题实例。为解决这一问题,分布式架构将大问题划分为较小的子图,分别存储在不同的PE中。初步结果显示,只要通信链路的速度快于单个p-bit的时钟速度,分布式概率计算机可以创造出一个幻象,即一个可以容纳更大图的单一PE。每纳秒超过1000次翻转的采样率是可行的,这对于复杂的组合优化和采样问题非常有利。
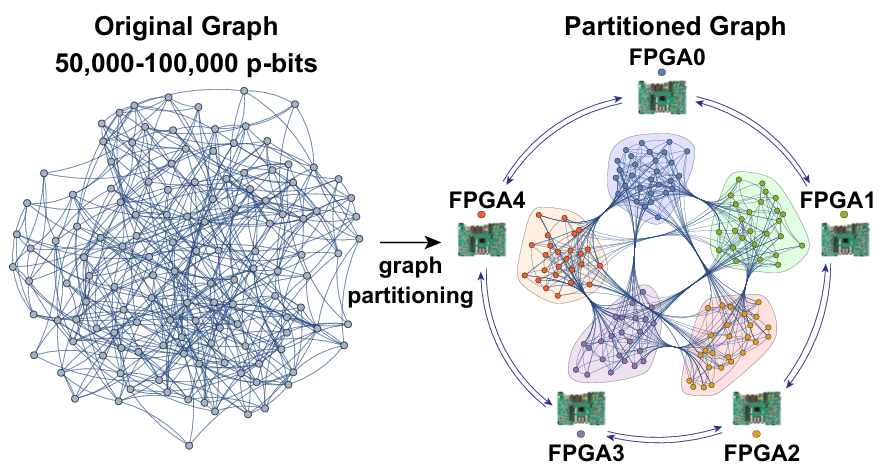
图:分布式概率计算机架构
概率人工智能模型中的许多工作负载涉及大量的矩阵运算。因此,采用涉及传统数字加速器和p-计算机的异构方法是可取的。GPU可用于大部分前向运算,而p-计算机可实现随机神经元运算。这种架构可用于扩展到大量p-bit,从而实现下一代EBM的训练和推理。
然而,这种架构可能面临两个问题:一是采样时间是否是优化的关键部分;二是PCIe通信可能成为瓶颈。采用对等通信(P2P)和分离式内存的架构可以减少这种瓶颈,使FPGA和GPU可以直接通信,避免访问CPU主内存。
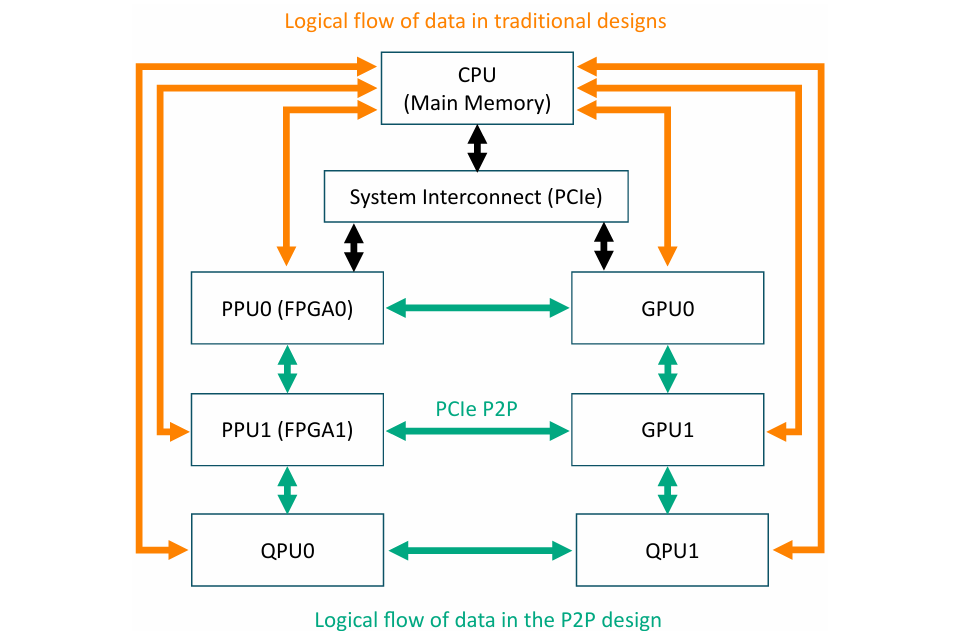
图:含GPU与FPGA的异构系统架构框图
(四)量子辅助概率计算与定制加速器
量子涨落和热涨落在概率计算框架中相互作用,可从问题空间、算法空间和解空间三个角度理解。在问题空间中,通过稀疏化技术将复杂问题分解为可嵌入量子加速器的小子图,量子求解器可以是基于量子退火的模拟设备或基于QAOA的数字设备。在算法空间中,量子求解器为经典概率框架提供热启动/种子,反之亦然,用于量子辅助并行退火或遗传算法。在解空间中,量子涨落通过量子行走加速配置空间的扩散,尤其在破碎的配置空间中。这种量子辅助方法可以与经典概率加速器结合,实现大规模和小规模的非局部探索。
这种混合算法可集成到异构HPC平台中,支持CPU、GPU、FPGA、QPU等加速器之间的点对点通信。在某些实现中,量子和经典处理器可集成在同一芯片上,以提高性能。这种量子-概率框架能够在给定时间和能量预算下,显著提升解决方案的质量和多样性,比单独使用概率或量子加速器更高效。

总结
开发实用规模量子计算机的最终目标是提供能够证明其成本价值的计算,实现这一目标需要满足几个关键标准:
(1)存在一组能够产生可衡量价值的计算任务;
(2)量子计算机的成本低于其产生的价值;
(3)没有其他方法(经典、模拟、量子等)能够更经济地执行这些计算。
本研究主要关注第二个标准,提供了对量子超级计算机的规模、尺寸和成本的初步整体理解,并识别了关键挑战。
本文提出了一个结合HPC和超导量子比特的量子超级计算机设计。该设计通过300毫米半导体加工技术显著提高了量子比特的质量、可靠性和扩展性。通过晶圆级集成和片上测量系统,该架构减少了对昂贵设备的需求,并通过模块化方法降低了扩展成本。此外,还提出了一个混合量子-经典全栈架构,支持容错量子计算与经典计算的无缝集成。该架构通过低延迟、高带宽的PCIe接口实现量子处理器与经典计算资源的高性能连接,支持量子纠错、自适应电路编织等混合过程。
研究团队通过详细的资源估计评估了设计,展示了在当前硬件质量下,实现化学精度的量子模拟需要数亿个物理量子比特和1.4年的运行时间。如果硬件质量显著提高,运行时间和量子比特数量可以显著减少。敏感性分析表明,提高门保真度对表面码的误差抑制效果显著优于减少SPAM误差或保护空闲量子比特。此外,还展示了量子网络技术的阈值行为,并建议探索部分容错编译和电路编织等替代技术。
本文所提出的量子超级计算愿景通过现有技术紧密集成了量子计算、经典计算和控制组件,研究团队希望通过公开这些挑战和基线设计来激发学术界和工业界发现创新的解决方案。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐



 46
46 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)