VggNet:图像识别的深度探索与实践
本文聚焦于VggNet这一经典卷积神经网络模型。先介绍了VggNet的背景信息,包括其得名由来、在竞赛中的表现及设计灵感。重点阐述了其创新点,即通过堆叠3x3卷积核替代大尺度卷积核来减少参数数量。同时指出了该网络存在资源需求大、梯度易消失或爆炸等缺陷。详细分析了VggNet的结构,以VGG16为例介绍其架构特点,并给出了基于PyTorch的代码实现。旨在为读者全面了解VggNet提供参考。
文章目录
前言
在当今图像识别技术飞速发展的时代,卷积神经网络(CNN)无疑是推动这一领域前进的核心力量。众多CNN模型如繁星般闪耀,其中VggNet以其独特的设计和卓越的性能在图像识别领域占据了重要地位。VggNet由牛津大学视觉几何小组提出,在2014年ILSVRC竞赛中崭露头角,其凭借创新性的网络结构为大规模图像识别带来了新的思路和方法。本文将深入剖析VggNet的网络背景、创新点、缺陷、结构以及具体的代码实现,带您全面了解这一经典的卷积神经网络模型。
VggNet
-
网络背景
- VggNet得名于牛津大学视觉几何小组,在2014年ILSVRC竞赛中,于定位任务获第一名,分类任务获第二名。它由Karen Simonyan和Andrew Zisserman在论文“Very Deep Convolutional Networks for Large - Scale Image Recognition”中提出。
- 设计灵感源于前馈神经网络中深层网络能学习更多高级特征以提升识别准确率。其特点为训练时采用小卷积核和池化层,通过堆叠多个卷积层增加网络深度,实现高精度图像识别。
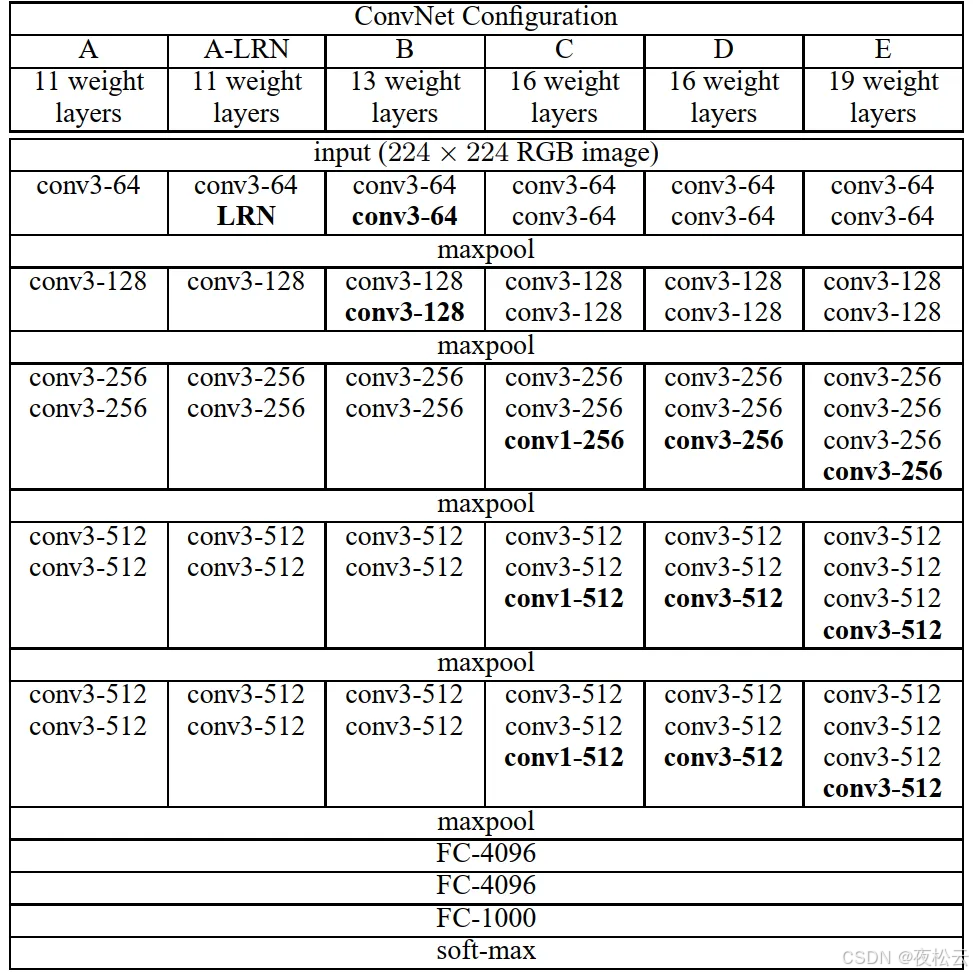
- VGGNet有6个配置,层数分别为11层、13层、16层、19层,还涉及是否使用LRN局部响应归一化操作。日常常用16层,这里的16层指权重层(即含可学习参数的层,池化层不算),VGG16对应图中D列。例如“conv3 - 64”,“conv”代表卷积层,“3”表示卷积核大小为3×3,“64”表示该卷积层输出通道数为64。
-
全称与论文地址
- 全称:Very Deep Convolutional Networks for Large - Scale Image Recognition
- 论文地址:Very Deep Convolutional Networks for Large
一、网络的创新
1.1 通过堆叠3x3卷积核代替大尺度卷积核
早期CNN网络(如AlexNet)使用7×7、5×5等大尺寸卷积核提取特征,存在参数量大且计算复杂的问题。
1.2 VGGNet的创新
采用堆叠多个3x3卷积核替代单一的大尺寸卷积核。例如:
-
堆叠两个3x3的卷积核可替代5x5卷积核的感受野。
-
堆叠三个3x3的卷积核可替代7x7卷积核的感受野。
通过堆叠多个小的感受野替代大的感受野,目的是减少网络训练时参数的数量。下面介绍感受野及如何减少网络训练时参数的数量。 -
感受野(Receptive Field):描述了神经网络中某一层神经元的输出所依赖的输入图像区域。在卷积神经网络中,越深层的神经元看到的输入区域越大。例如,卷积核kernel size均为3×3,stride均为1时,Layer2每个神经元可看到Layer1上3×3大小的区域,Layer3每个神经元看到Layer2上3×3大小的区域,进而能看到Layer1上5×5大小的区域。感受野是个相对概念,通常在不特殊指定的情况下,指看到输入图像上的区域。其计算公式为:
-
F ( i ) = ( F i + 1 − 1 ) × S t r i d e + K e r n e l S i z e F_{(i)}=(F_{i+1}-1)\times Stride+KernelSize F(i)=(Fi+1−1)×Stride+KernelSize
-
其中 F ( i ) F_{(i)} F(i)是第i层的感受野, S t r i d e Stride Stride为第i层的步距, K e r n e l S i z e KernelSize KernelSize是卷积核或者池化核的尺寸。以Layer3的一个1x1区域计算输入图像所对应区域为例:
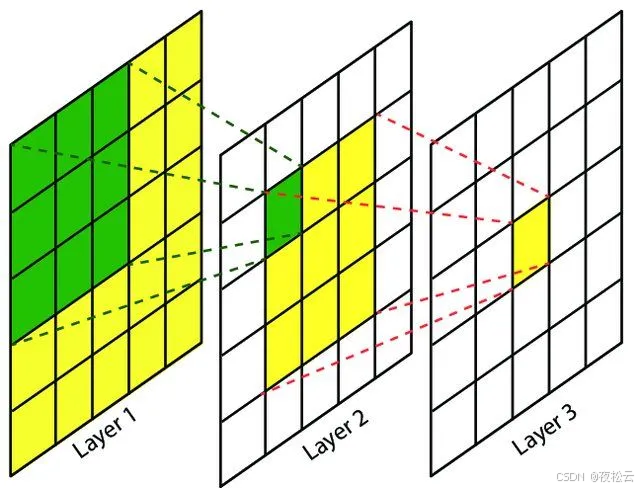
- 计算在Layer2上的感受野: ( 1 − 1 ) × 1 + 3 = 3 (1 - 1)\times1 + 3 = 3 (1−1)×1+3=3,即在Layer2上对应3x3的感受野。
- 计算Layer1上的感受野: ( 3 − 1 ) × 1 + 3 = 5 (3 - 1)\times1 + 3 = 5 (3−1)×1+3=5,即在Layer1上对应5x5的感受野。
- 假如在Layer1前面还有Layer0,计算Layer0上的感受野: ( 5 − 1 ) × 1 + 3 = 7 (5 - 1)\times1 + 3 = 7 (5−1)×1+3=7,即在Layer0上对应7x7的感受野。
- 由此可知,二层3x3的卷积核与一层5x5的卷积核感受野一致,三层3x3的卷积核与一层7x7的卷积核感受野一致。
1.3 怎么减少网络训练时参数的数量?
VGGNet论文提到堆叠两个3x3的卷积核可替代5x5的卷积核,堆叠三个3x3的卷积核可替代7x7的卷积核。以一层7x7卷积核和三层3x3的卷积核为例计算参数量(输入通道数和输出通道数都用channels代替):
- 一层7x7卷积核: 7 × 7 × c h a n n e l s × c h a n n e l s = 49 c h a n n e l s 2 7\times7\times channels\times channels = 49channels^{2} 7×7×channels×channels=49channels2
- 三层3x3卷积核: ( 3 × 3 × c h a n n e l s × c h a n n e l s ) × 3 = 27 c h a n n e l s 2 (3\times3\times channels\times channels)\times3 = 27channels^{2} (3×3×channels×channels)×3=27channels2
由此可得,堆叠三个3x3的卷积核的计算量小于7x7的卷积核,且随着特征矩阵channels的变大,差距会扩大。
总结:以小的卷积核方式增加网络深度,可实现高精度的图像识别,能有效捕获图像中的高级特征,并通过拟合训练数据提高识别准确率。
二、网络的缺陷:
- 资源需求大:网络架构庞大,训练时需要大量计算资源,在移动设备或个人电脑上运行速度缓慢。
- 梯度问题:网络架构过深,容易导致梯度消失或爆炸。在深度神经网络中,梯度在传播过程中可能变得过小或过大,致使模型无法正常训练。
三、网络的结构
3.1 架构图
在论文中给出了网络结构表,通常更多会选择 D 项,即常说的 VGG16 网络,下面对该结构进行分析。
VGG - 16 架构图的相关特点如下: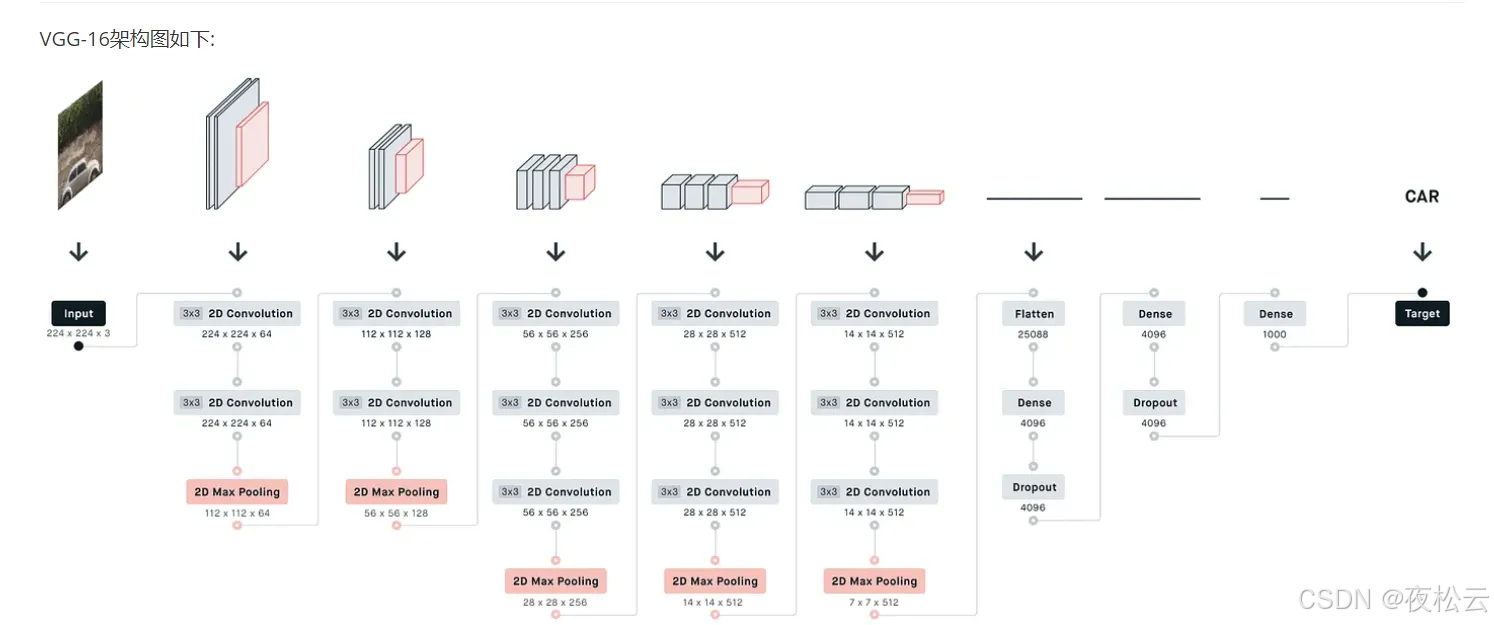
- 卷积层设置:多个卷积层堆叠用于替代更大的卷积核。
- 激活函数:每层隐藏层后都使用了 ReLU 激活函数。
- 防止过拟合手段:可在全连接层后添加 Dropout 以防止过拟合。
VGG16 的网络结构图展示如下(需注意:图中最后一个蓝色条标注为 1x1x1000 的标识是 “fully connected + ReLU”,但实际上最后一层全连接并不需要加 ReLU 激活函数)。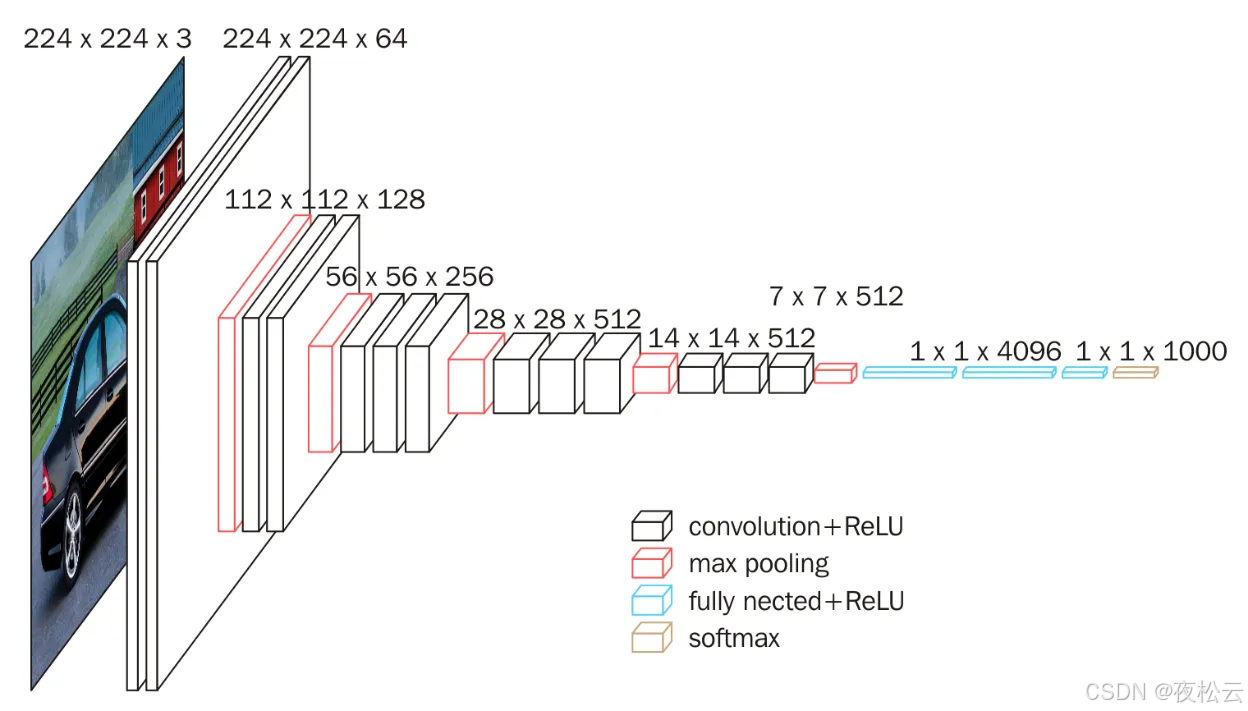
文章里未列出卷积核和池化的部分超参数,现列出计算过程中会用到的参数:
- 卷积参数:卷积的 stride(步长) = 1,padding(填充) = 1。
- 池化参数:池化采用 maxpool,其 size(池化核大小) = 2,stride(步长) = 2。
3.2 代码示例
import torch
import torch.nn as nn
# 定义VGG网络类,继承自nn.Module
class VGG(nn.Module):
# 初始化函数,features为特征提取网络,num_classes为分类数量,init_weights用于控制是否初始化权重
def __init__(self, features, num_classes=1000, init_weights=True):
# 调用父类的初始化方法
super(VGG, self).__init__()
# 保存特征提取网络
self.features = features
# 定义分类器,包含多个全连接层、ReLU激活函数和Dropout层
self.classifier = nn.Sequential(
# 第一层全连接层,输入特征数为512*7*7,输出特征数为4096
nn.Linear(512 * 7 * 7, 4096),
# ReLU激活函数,采用原地操作
nn.ReLU(True),
# Dropout层,保留概率为0.5
nn.Dropout(p=0.5),
# 第二层全连接层,输入特征数为4096,输出特征数为4096
nn.Linear(4096, 4096),
# ReLU激活函数,采用原地操作
nn.ReLU(True),
# Dropout层,保留概率为0.5
nn.Dropout(p=0.5),
# 第三层全连接层,输入特征数为4096,输出特征数根据num_classes设置
nn.Linear(4096, num_classes)
)
# 如果init_weights为True,则调用初始化权重的方法
if init_weights:
self._initialize_weights()
# 初始化权重的方法
def _initialize_weights(self):
# 遍历网络中的所有模块
for m in self.modules():
# 如果模块是卷积层
if isinstance(m, nn.Conv2d):
# 使用xavier_uniform方法初始化卷积层的权重
nn.init.xavier_uniform_(m.weight)
# 如果卷积层有偏置项
if m.bias is not None:
# 将偏置项初始化为0
nn.init.constant_(m.bias, 0)
# 如果模块是全连接层
elif isinstance(m, nn.Linear):
# 使用xavier_uniform方法初始化全连接层的权重
nn.init.xavier_uniform_(m.weight)
# 如果全连接层有偏置项
if m.bias is not None:
# 将偏置项初始化为0
nn.init.constant_(m.bias, 0)
# 前向传播函数
def forward(self, x):
# 通过特征提取网络
x = self.features(x)
# 将特征张量展平
x = torch.flatten(x, start_dim=1)
# 通过分类器
x = self.classifier(x)
# 返回结果
return x
# 定义一个字典,存储不同VGG模型的网络结构配置
cfgs = {
'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M']
}
# 定义特征提取函数,根据配置列表创建特征提取网络
def make_features(cfg: list):
# 用于存储每个卷积层和池化层的列表
layers = []
# 初始化输入通道数为3
in_channels = 3
# 遍历配置列表
for v in cfg:
# 如果当前元素为'M',表示添加最大池化层
if v == "M":
# 添加2D最大池化层,池化窗口大小为2,步长为2
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
# 否则,添加卷积层和ReLU激活层
else:
# 创建2D卷积层,输入通道数为in_channels,输出通道数为v,卷积核大小为3,填充为1
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
# 将卷积层和ReLU激活层添加到列表中
layers += [conv2d, nn.ReLU(True)]
# 更新输入通道数为当前卷积层的输出通道数
in_channels = v
# 将列表转换为顺序模块
return nn.Sequential(*layers)
# 根据模型名称创建VGG模型
def vgg(model_name="vgg16", **kwargs):
# 检查模型名称是否在配置字典中
assert model_name in cfgs, "Warning: model number {} not in cfgs dict!".format(model_name)
# 获取对应模型的配置
cfg = cfgs[model_name]
# 创建VGG模型
model = VGG(make_features(cfg), **kwargs)
# 返回创建的模型
return model
# 打印模型
# 创建VGG模型,默认使用vgg16
model = vgg()
# 生成随机输入张量,形状为(5, 3, 224, 224)
x = torch.rand(5, 3, 224, 224)
# 将输入张量传入模型
y = model(x)
# 打印输出张量的形状
print(y.shape)
总结
本文围绕VggNet展开了全面而深入的探讨。首先介绍了VggNet的网络背景,它得名于牛津大学视觉几何小组,在竞赛中取得优异成绩,设计灵感源于深层网络对高级特征的学习能力。接着阐述了其创新之处,通过堆叠3x3卷积核替代大尺度卷积核,有效减少了网络训练时的参数数量,实现了高精度的图像识别。然而,VggNet也存在资源需求大、易出现梯度问题等缺陷。随后详细分析了VggNet的结构,以VGG16为例介绍了其架构特点,并给出了具体的代码示例。通过本文的介绍,读者可以全面了解VggNet的原理、优缺点及实现方式,为进一步研究和应用该模型提供了有价值的参考。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 40
40 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)