数据分析实战技巧大揭秘与学习体会
【数据分析实践要点】数据探索是基础,需检查数据类型、缺失值和分布特征;数据清洗需处理缺失值、重复值等问题。可视化工具(matplotlib/seaborn)能直观呈现数据规律。常用库包括pandas(核心操作)、numpy(数值计算)和scikit-learn(机器学习)。预处理时需标准化数据并进行特征工程。分析方法上,EDA可挖掘数据特征,模型选择需匹配问题类型。项目应遵循完整流程,注重代码规范
@[TOC]
# 实践经验
# 学习心得
# 基础语法
## 1.数据探索很重要:在进行分析前,先对数据进行全面探索,包括查看数据的基本信息(如数据类型、缺失值、唯一值等),了解数据的分布特征,这有助于发现数据中的异常情况和潜在问题,为后续分析提供方向。
## 2.数据清洗要细致:实际数据往往存在各种问题,如缺失值、重复值、错误数据等。要熟练掌握数据清洗的方法,如使用 fillna() 填充缺失值、 drop_duplicates() 去除重复值等,确保数据的质量,这是保证分析结果准确性的基础。
## 3.善用可视化:利用 matplotlib 、 seaborn 等库进行数据可视化,能直观地展示数据的特征和关系,帮助理解数据,发现数据中的规律和趋势,也便于向他人展示分析结果。
## 4.掌握常用库: pandas 是数据分析的核心库,要熟练掌握其数据结构(如 Series 和 DataFrame )和常用操作(如数据读取、筛选、分组、合并等)。 numpy 用于数值计算,提供了高效的数组操作和数学函数。对于机器学习相关的数据分析, scikit - learn 库很实用,它提供了丰富的机器学习算法和工具。
<a href="Python基础语法全解-CSDN博客"></a>
数据预处理技巧
## 1.数据标准化与归一化:根据数据特点和分析模型的需求,选择合适的方法对数据进行标准化或归一化处理,如使用 sklearn.preprocessing 模块中的 StandardScaler 或 MinMaxScaler ,可提升模型的准确性和收敛速度。
## 2.特征工程:结合业务知识和数据特点,进行特征提取、选择和创建新特征。例如,从日期时间数据中提取年、月、日、星期等特征,可能有助于挖掘数据中的时间序列信息。
# 分析方法与模型应用
## 1.探索性数据分析(EDA):运用描述性统计分析、相关性分析等方法,深入了解数据的特征和变量之间的关系。使用 pandas 的 describe() 方法可以快速获取数据的基本统计信息,用 corr() 方法计算相关性矩阵。
## 2.模型选择与评估:根据分析目标选择合适的机器学习或统计模型,如分类问题可选择决策树、支持向量机等模型,回归问题可选用线性回归、随机森林回归等。使用交叉验证、均方误差、准确率等指标评估模型性能,并通过调参优化模型。
项目流程与协作
1.明确项目流程:遵循“提出问题 - 数据收集 - 数据预处理 - 数据分析与建模 - 结果可视化与解读 总结与汇报”的流程,确保分析过程的系统性和完整性。
## 2.代码规范与文档化:编写规范、易读的代码,并做好注释和文档记录。这不仅有助于自己后期回顾和维护代码,也方便团队成员之间的协作和交流。
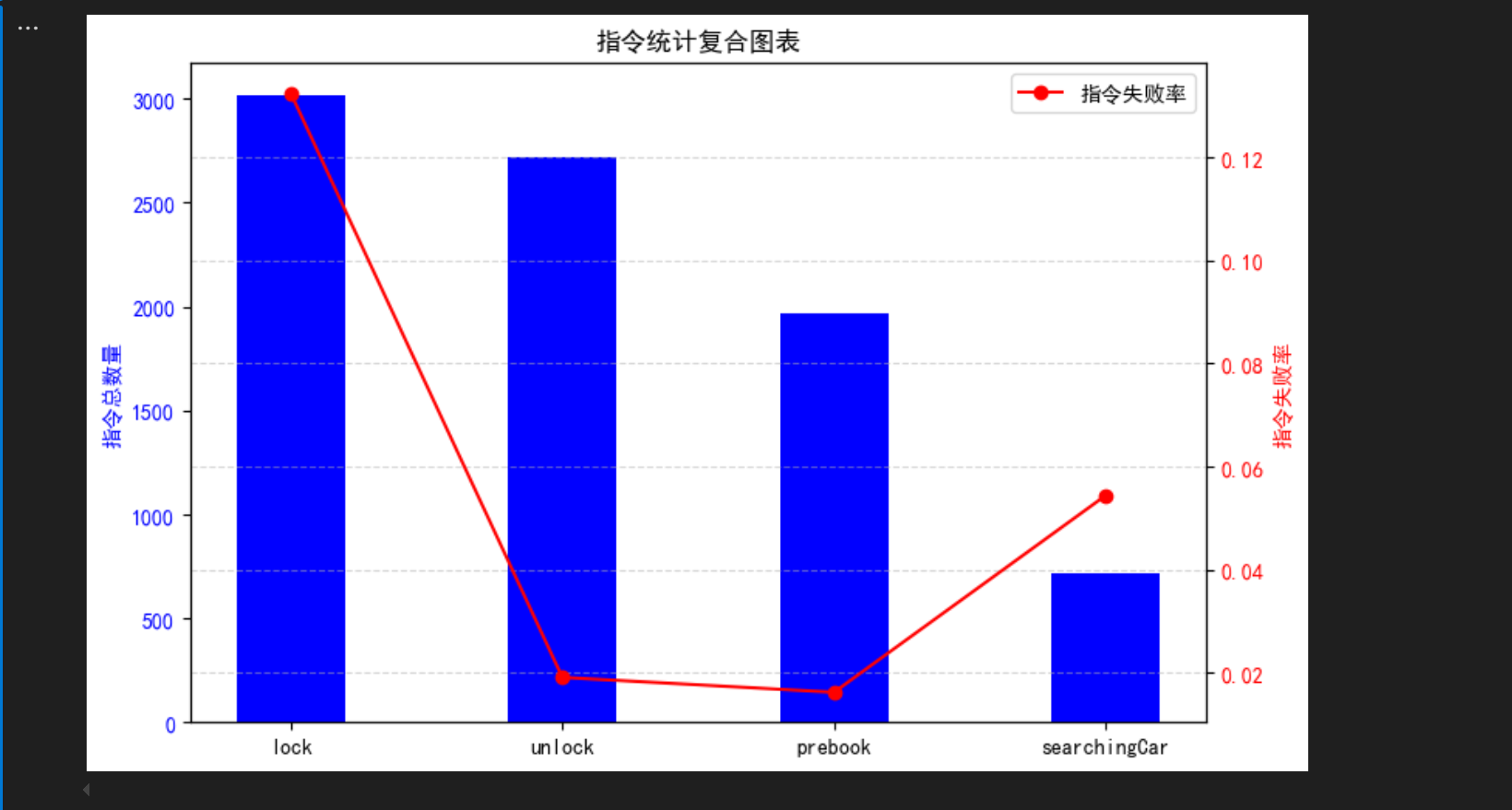
# 统一指令顺序(按 lock、unlock、prebook、searchingCar 排序)
order = ['lock', 'unlock', 'prebook', 'searchingCar']
df1 = df1.set_index('CMD').loc[order].reset_index()
df2 = df2.set_index('CMD').loc[order].reset_index()
# 合并数据(确保顺序一致)
merged_df = pd.merge(df1, df2, on='CMD')
# 绘制复合图表
fig, ax1 = plt.subplots(figsize=(8, 5))
# 左轴:柱状图(指令总数量)
ax1.bar(merged_df['CMD'], merged_df['指令总数量'], color='blue', width=0.4, label='指令总数量')
ax1.set_ylabel('指令总数量', color='blue')
ax1.tick_params(axis='y', labelcolor='blue')
# 右轴:折线图(指令失败率)
ax2 = ax1.twinx()
ax2.plot(merged_df['CMD'], merged_df['指令失败率'], color='red', marker='o', label='指令失败率')
ax2.set_ylabel('指令失败率', color='red')
ax2.tick_params(axis='y', labelcolor='red')
# 图表配置
plt.title('指令统计复合图表')
plt.xlabel('指令类型')
plt.legend(loc='upper right')
plt.grid(linestyle='--', alpha=0.5)
plt.tight_layout()
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体为 SimHei(宋体)
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示为方块的问题
plt.show()
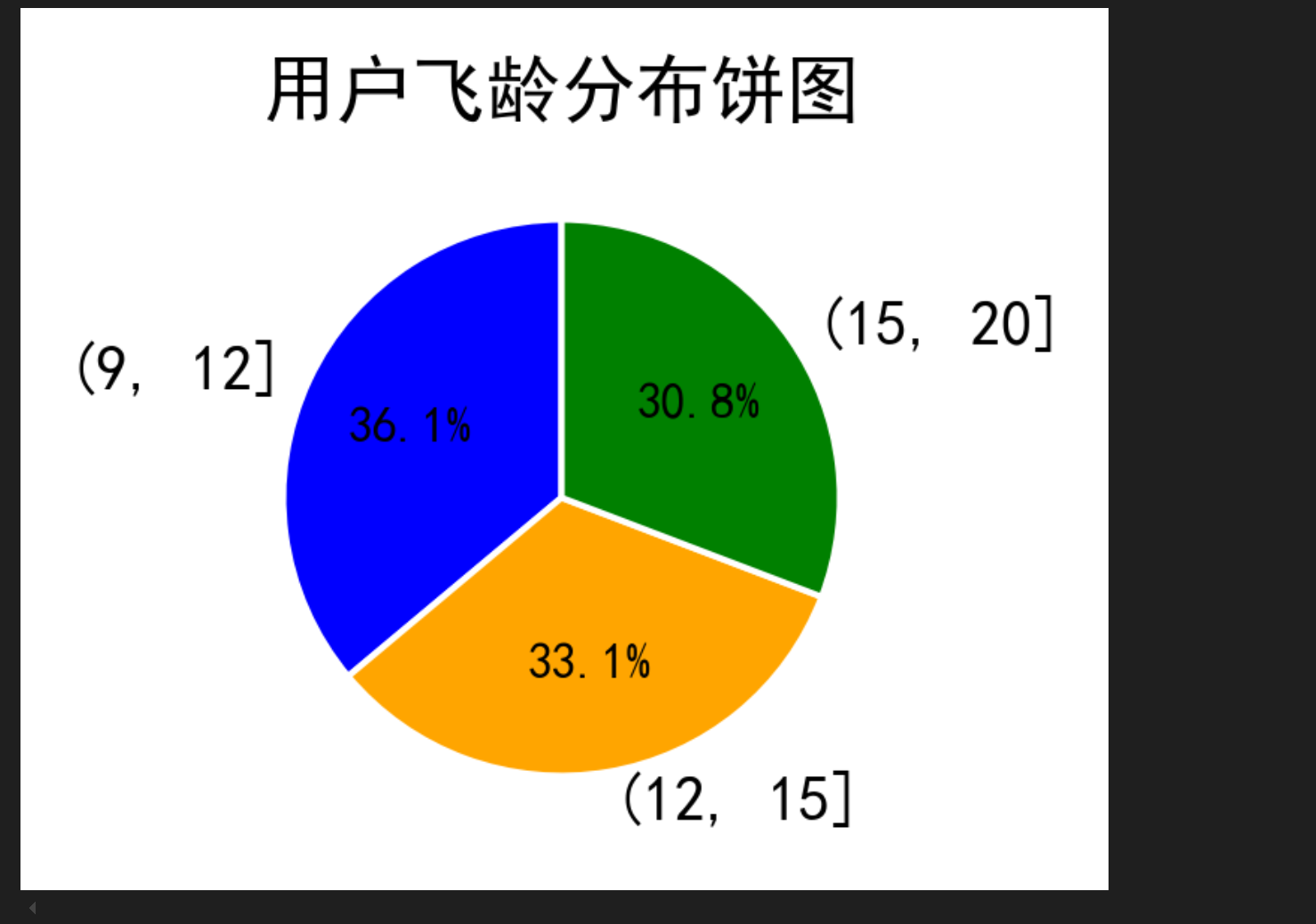
## 饼图:
import matplotlib.pyplot as plt
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 飞龄分组及对应的人数占比
labels = ['(9, 12]', '(12, 15]', '(15, 20]']
sizes = [36.1, 33.1, 30.8]
colors = ['blue', 'orange', 'green']
plt.figure(figsize=(2, 3))
# 绘制饼图
wedges, texts, autotexts = plt.pie(sizes, labels=labels, colors=colors, autopct='%1.1f%%',
startangle=90, wedgeprops={'linewidth': 1, 'edgecolor': 'white'})
# 优化文本显示
plt.setp(autotexts, size=8, weight="bold")
# 添加图表标题
plt.title('用户飞龄分布饼图')
# 显示图表
plt.show()
<a href="Python 教程 — Python 3.13.5 文档"></a>
学习心得
## 1.多实践多练习:通过实际项目和案例进行练习,加深对知识的理解和掌握。可以从简单的数据集开始,逐步处理复杂的数据,不断积累经验。
## 2.阅读文档和源码:Python的数据分析库都有完善的文档,遇到问题及时查阅文档,能深入了解函数和方法的用法。阅读优秀的代码示例和库的源码,学习他人的编程思路和技巧,有助于提高自己的编程水平。
## 3.加入社区和交流:参与相关的社区和论坛,如Stack Overflow、Kaggle等,与其他数据分析师交流经验、分享问题和解决方案,还能了解到行业的最新动态和技术趋势。
## 4.持续学习:数据分析领域发展迅速,新的技术和方法不断涌现。要保持学习的热情,不断更新知识体系,学习新的算法、模型和工具,以适应不断变化的需求
import pandas as pd
df=pd.DataFrame(
{
'姓名':['甲','乙','丙','丁'],
'分数':[95,87,72,79]
}
)
df
# 使用cut函数进行数据分箱
series_bins=pd.cut(
df['分数'],
bins=[0,60,70,80,90,100]
)
series_bins2=pd.cut(
df['分数'],
bins=[0,60,70,80,90,100],
labels=['不及格','及格','一般','良好','优秀']
)
df['分数区间']=series_bins
df['等级']=series_bins2
df
基础语法
1.数据类型:包括整数、浮点数、字符串、列表、元组、字典、集合等,要掌握它们的定义、操作和特点。
2.控制结构:有if - else条件语句、for和while循环语句,用于控制程序的执行流程。
3. 函数:学会定义和调用函数,掌握函数的参数传递、返回值等概念,以及匿名函数的使用。
面向对象编程
1.类和对象:理解类的定义、属性和方法,以及如何创建对象并调用对象的方法。
2.继承和多态:掌握继承的概念,通过继承实现代码的复用;理解多态的原理,使不同子类对象可以对同一方法有不同的实现。
模块和包
1.模块:了解如何创建和导入模块,将代码组织成多个模块,提高代码的可维护性和可复用性。
2.包:学会创建和使用包,将相关模块组织在一起,形成更复杂的项目结构。
常用标准库
os模块:用于与操作系统进行交互,如文件和目录操作、进程管理等。
sys模块:提供了与Python解释器相关的功能,如命令行参数处理、标准输入输出等。
datetime模块:用于处理日期和时间相关的操作。
第三方库
NumPy:用于数值计算,提供了高性能的多维数组和矩阵运算功能。
pandas:用于数据处理和分析,提供了数据结构和数据分析工具。
matplotlib:用于数据可视化,能绘制各种类型的图表。
其他方面
异常处理:学会使用try - except语句捕获和处理异常,增强程序的稳定性和健壮性。
文件操作:掌握文件的打开、读取、写入和关闭操作,以及不同文件格式的处理。
在参与Python数据分析项目并完成报告撰写的过程中,我对数据处理、分析方法以及结果呈现等方面有了深刻的认识与体会。
一、Python强大的数据处理能力是基石
Python丰富的库为数据分析提供了强大支撑。Pandas库在数据清洗和预处理阶段堪称“利器”,通过 read_csv 、 read_excel 等函数能快速读取多种格式的数据,使用 dropna 、 fillna 处理缺失值, duplicated 结合 drop_duplicates 处理重复数据,极大提高了数据质量。如在处理某销售数据时,通过Pandas的 groupby 方法,快速实现了不同地区、不同时间段的销售总额统计,高效且便捷。
Numpy库则在数值计算上发挥重要作用,其强大的数组运算功能,支持向量化操作,相比传统的循环方式,大幅提升了计算效率。例如在计算数据的标准差、均值等统计量时,Numpy的函数简洁高效,为后续分析奠定基础。
二、可视化助力数据洞察
Matplotlib和Seaborn等可视化库让数据“说话”。Matplotlib的灵活性很高,通过对图表的各个元素进行精细设置,如坐标轴标签、图例、颜色等,能绘制出满足特定需求的图表。Seaborn则更注重统计可视化,利用 relplot 、 catplot 等函数,可以轻松展示变量间的关系,挖掘数据背后的规律。在一次分析用户年龄与消费金额关系的项目中,通过Seaborn绘制的散点图,清晰地呈现出两者之间的正相关趋势,让数据洞察更加直观。
三、数据分析方法的合理选择是关键
面对不同的数据和分析目标,需要选择合适的方法。描述性统计可以快速了解数据的基本特征,如均值、中位数、众数等,为后续深入分析提供基础。在进行假设检验时,如t检验、卡方检验等,能够判断不同组数据之间是否存在显著差异,从而验证分析假设。在处理复杂的多变量数据时,主成分分析(PCA)可以实现数据降维,简化数据结构,同时保留主要信息。合理运用这些方法,能让分析更具深度和科学性。
四、报告撰写需注重逻辑性与可读性
数据分析报告是成果展示的重要载体。撰写时,首先要明确报告的受众和目的,针对不同的对象调整内容和表述方式。报告结构应清晰,从问题提出、数据来源与处理、分析过程到结果讨论,要有严谨的逻辑顺序。在文字表述上,避免使用过于专业晦涩的术语,确保读者能够理解。同时,图表要简洁明了,配以必要的文字说明,突出重点结论。
五、实践中遇到的问题与解决
在实际操作中,也遇到了诸多问题。数据缺失和异常值处理时,如何选择合适的填充或剔除方法,需要综合考虑数据特点和业务背景。在可视化过程中,图表类型的选择不当可能导致信息传达不准确,需要反复尝试和优化。此外,复杂的数据分析模型在应用时,容易出现参数设置不合理等问题,这就需要不断查阅资料、请教他人,通过实践逐步解决。
六、未来提升方向
通过这次实践,我意识到自身还有很多不足。在技术层面,需要深入学习更多高级的数据分析算法和模型,如机器学习中的聚类算法、回归算法等,提升分析能力。在业务理解方面,要加强与业务部门的沟通,深入了解业务需求,使数据分析更贴合实际应用。同时,持续锻炼报告撰写和汇报能力,更好地将分析成果传递给他人。
Python数据分析是一个理论与实践紧密结合的过程,在未来的学习和工作中,我将不断积累经验,提升能力,用Python挖掘数据背后的价值,为决策提供有力支持。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 34
34 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)