《Python数据分析实战与学习心得分享》
未来,我计划深入学习机器学习相关知识,将数据分析与预测建模结合,解决更复杂的实际问题。在《Python数据分析》课程的学习过程中,我系统掌握了从数据获取、清洗、分析到可视化的全流程知识。在数据分析过程中,原始数据的数据类型可能并不符合分析需求,因此数据类型转换是一项重要的操作。利用 pandas 的 describe() 方法,能够快速获取数值型数据的统计特征,如均值、标准差、四分位数等。例子:以
一、开篇:与Python数据分析的初遇
作为一名数据科学初学者,接触《Python数据分析》这门课程,就像打开了一扇通往数据世界的新大门。从最初对 Pandas、Numpy 这些库的陌生,到逐渐能用代码挖掘数据价值,过程充满挑战与惊喜。这篇博客,就来分享我在课程学习中的实践经验与心得,希望能给同路的学习者一些启发 。在《Python数据分析》课程的学习过程中,我系统掌握了从数据获取、清洗、分析到可视化的全流程知识。课程依托Python强大的生态库,让我深刻体会到数据分析在实际场景中的应用价值。接下来,我将从几个关键章节展开,分享实践经验与学习心得。
二、实践操作:在摸索中成长
实践是检验学习成果的关键。在处理真实数据集时,我深刻体会到理论与实际的差距。数据清洗环节,面对缺失值、异常值,需要结合业务逻辑判断处理方式,不是简单地删除或填充。比如分析用户行为数据,缺失的浏览记录可能隐藏着用户习惯,得谨慎处理。数据分析过程中,也会遇到代码报错、逻辑错误,这促使我不断调试、查阅资料,在解决问题中提升技能。当通过数据可视化发现业务趋势,用分组聚合找出关键影响因素时,那种成就感难以言表,也让我明白实践出真知,只有多动手才能真正掌握数据分析。
三、获取与预处理实践
3.1 数据读取与基本查看
使用 pandas 库能够高效读取多种格式的数据文件,如CSV、Excel、JSON等。以下是读取CSV文件并查看数据基本信息的代码:
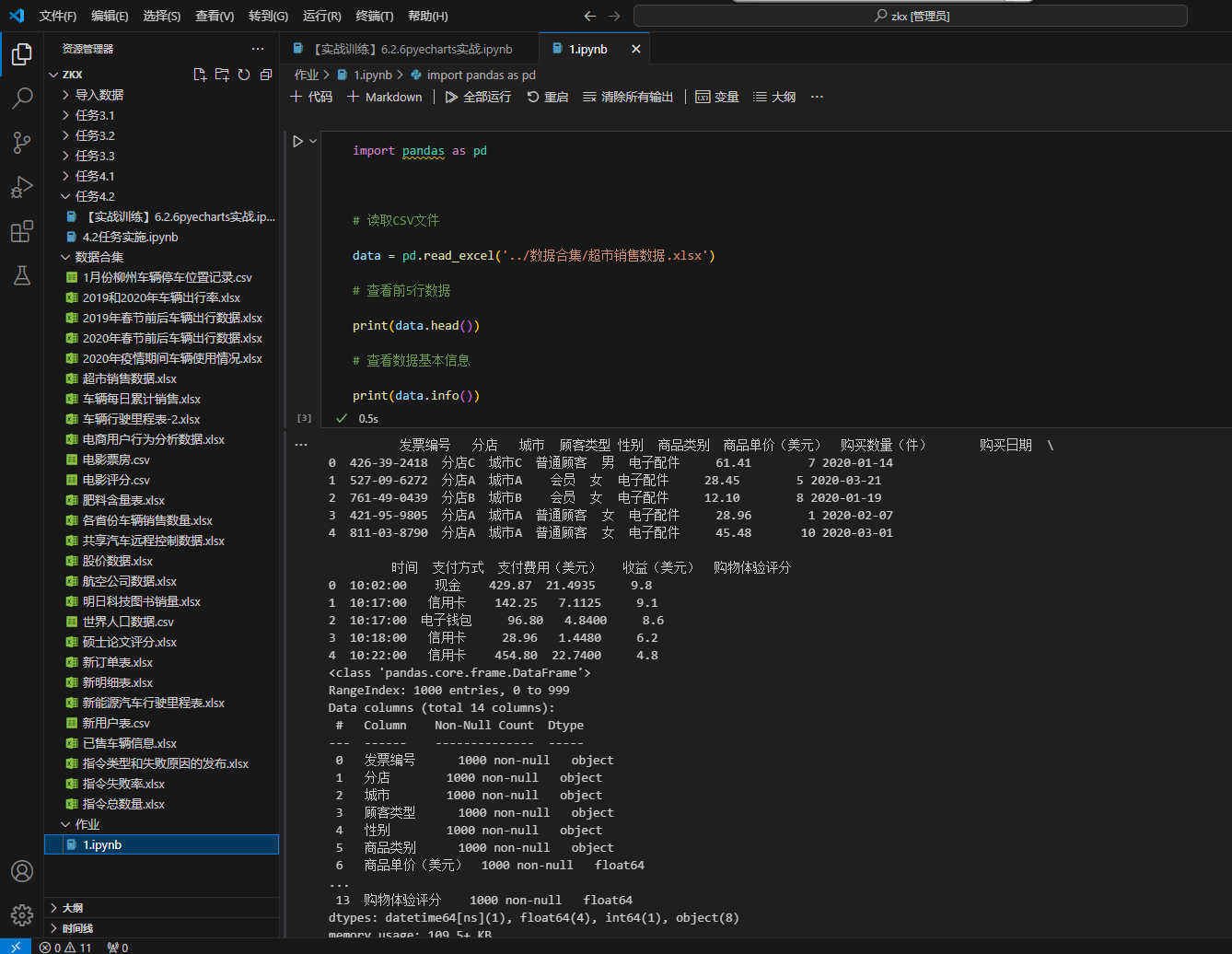
通过 head() 方法可以快速预览数据结构, info() 方法则能展示每列的数据类型和非空值数量,帮助我们初步了解数据集状况。
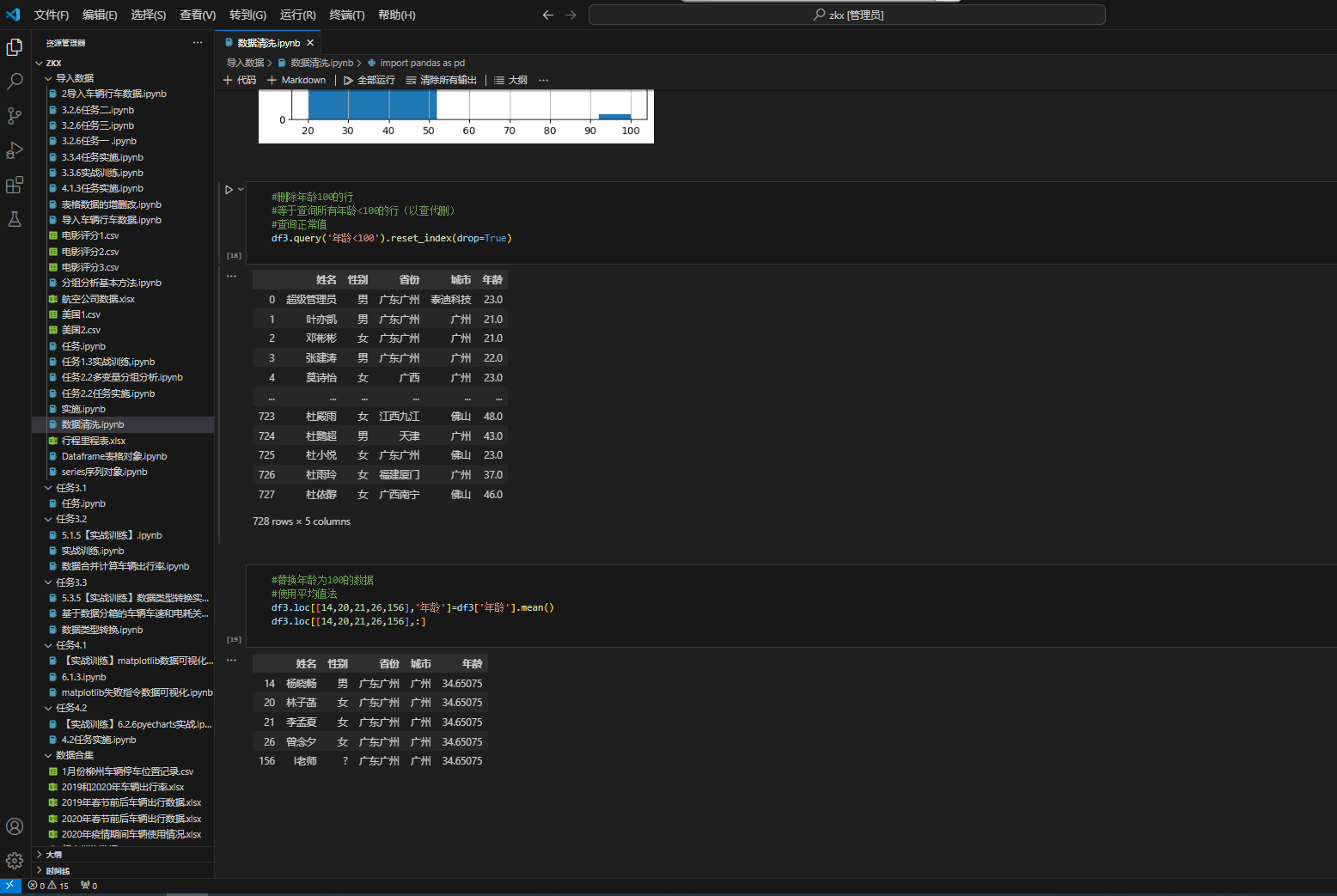
3.2 数据清洗实战
实际获取的数据往往存在缺失值、重复值等问题,需要进行清洗。
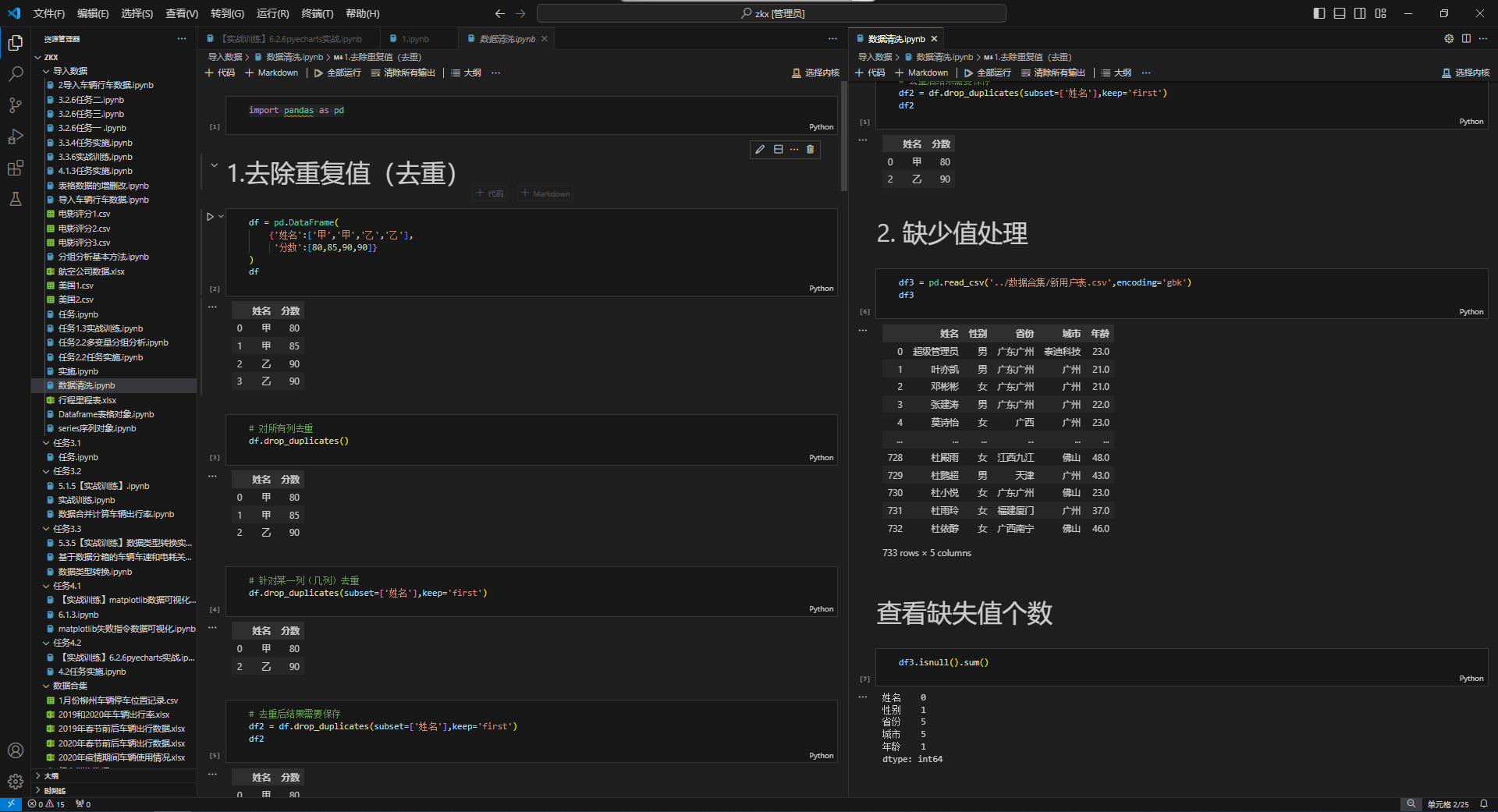
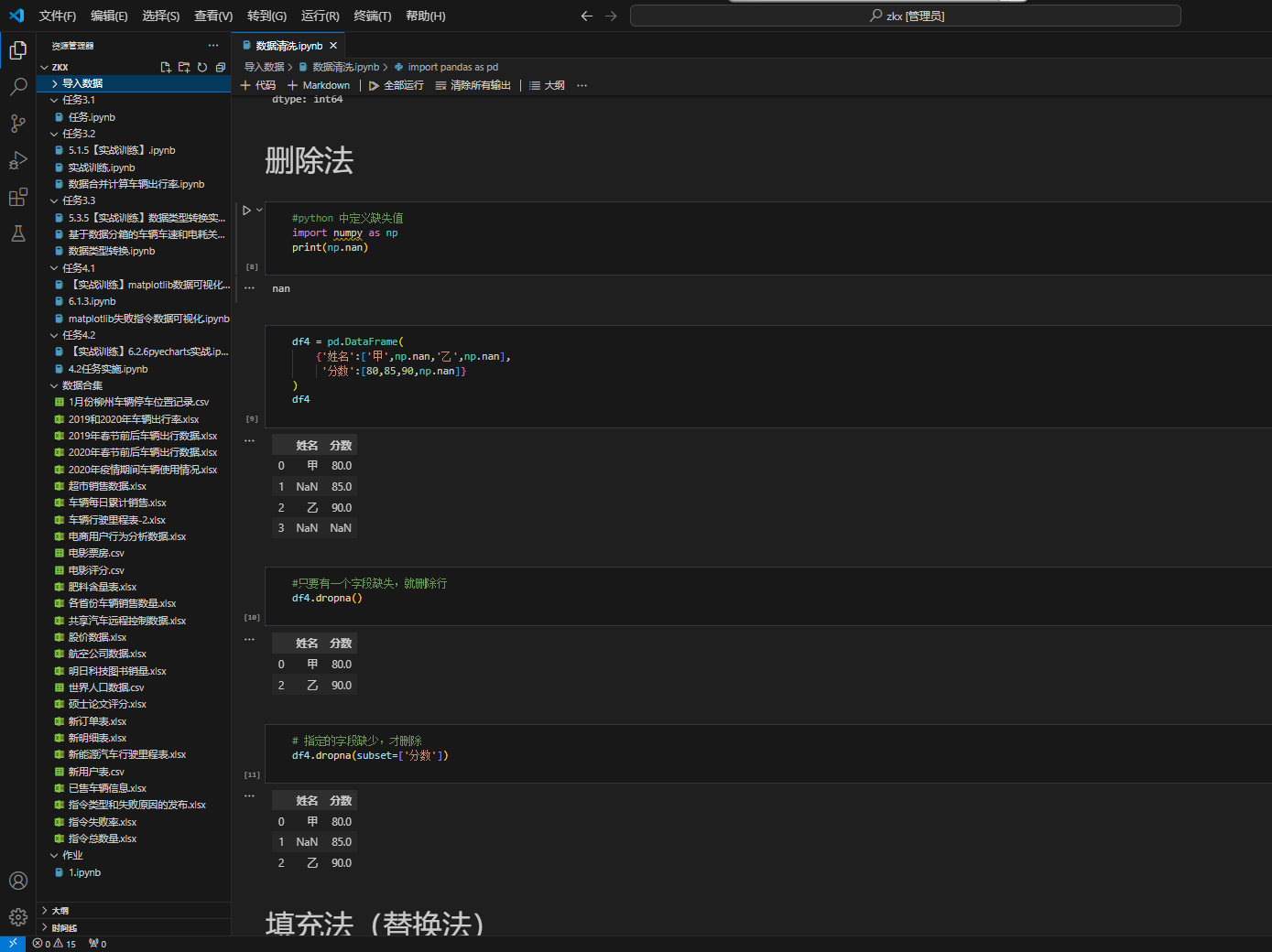
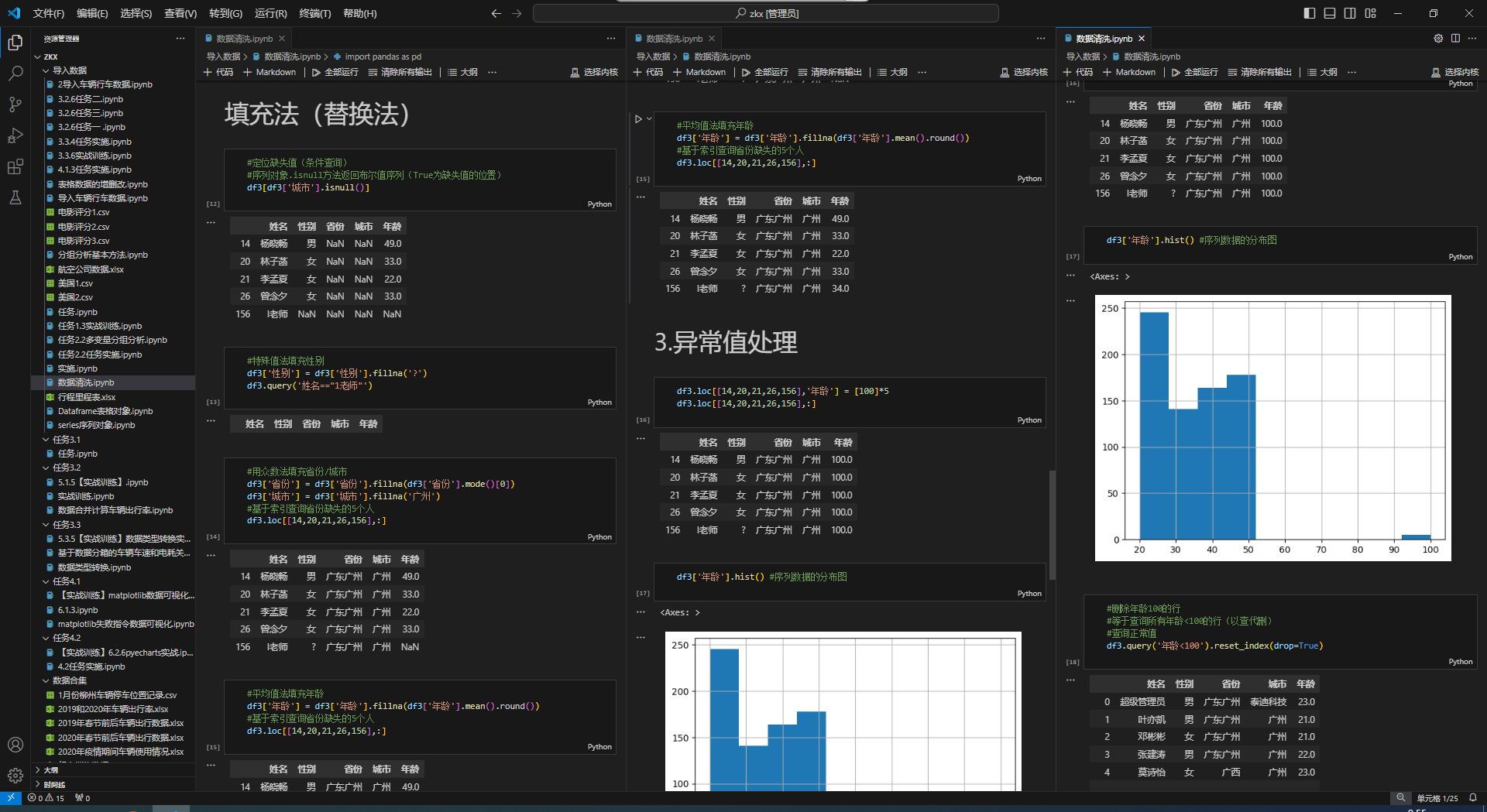
四、数据探索性分析
4.1 描述性统计分析
利用 pandas 的 describe() 方法,能够快速获取数值型数据的统计特征,如均值、标准差、四分位数等。
print(data.describe())结果示例:
| 列名 | 计数 | 均值 | 标准差 | 最小值 | 25%分位数 | 50%分位数 | 75%分位数 | 最大值 |
| col1 | 100 | 15.2 | 3.4 | 8.0 | 12.0 | 15.0 | 18.0 | 22.0 |
4.2 数据分组与聚合
当需要对数据按某个维度进行分类统计时,分组聚合操作十分实用。例如,按“类别”列分组计算“数值”列的平均值:
grouped = data.groupby('category')
['value'].mean()
print(grouped)五、数据可视化呈现
5.1 Matplotlib基础绘图
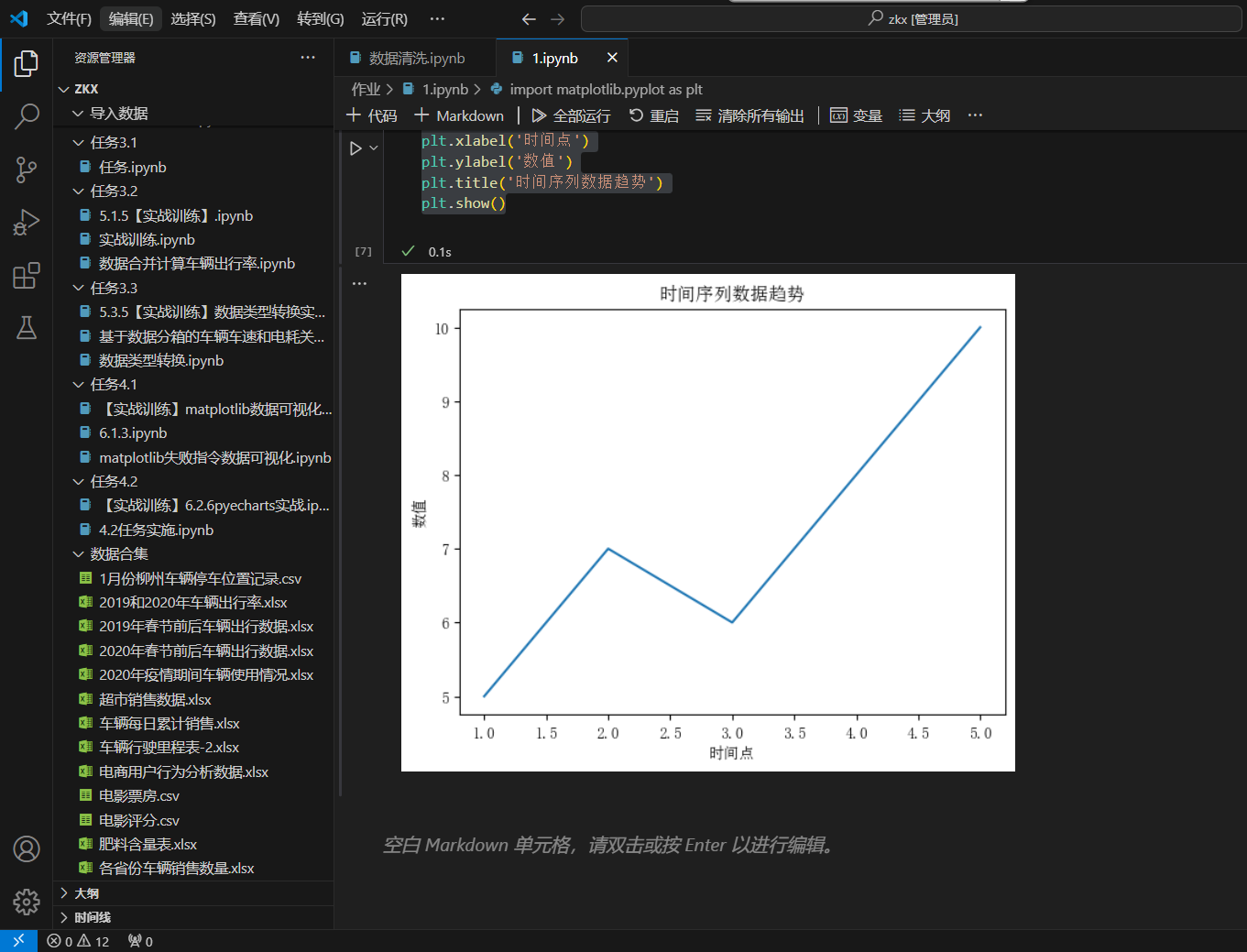
使用 Matplotlib 绘制折线图展示时间序列数据趋势:
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimSun']
plt.rcParams['axes.unicode_minus'] = False
x = [1, 2, 3, 4, 5]
y = [5, 7, 6, 8, 10]
plt.plot(x, y)
plt.xlabel('时间点')
plt.ylabel('数值')
plt.title('时间序列数据趋势')
plt.show()生成的折线图如下(插入对应折线图图片):
六、表格数据的增删改
6.1、Python 中表格数据增删改的核心工具 ——Pandas 库
Pandas 是 Python 数据分析的得力助手,处理表格数据(常以 DataFrame 结构呈现)的增删改操作,它提供了简洁高效的方法。接下来我以电影票房数据为例,借助 Pandas 库完成相关实践。
6.2、数据准备:读取电影票房数据
首先,使用 Pandas 读取本地电影票房 CSV 数据,代码如下:
import pandas as pd
# 读取数据,设置编码为 gbk 避免中文乱码
df = pd.read_csv('../数据集/电影票房.csv', encoding='gbk')
print("初始电影票房表格:")
print(df.head()) # 展示前几行数据这样就将电影票房数据加载为 DataFrame 结构,方便后续操作,初始数据包含排名、电影名称、上映时间、总票房(元)等字段 。
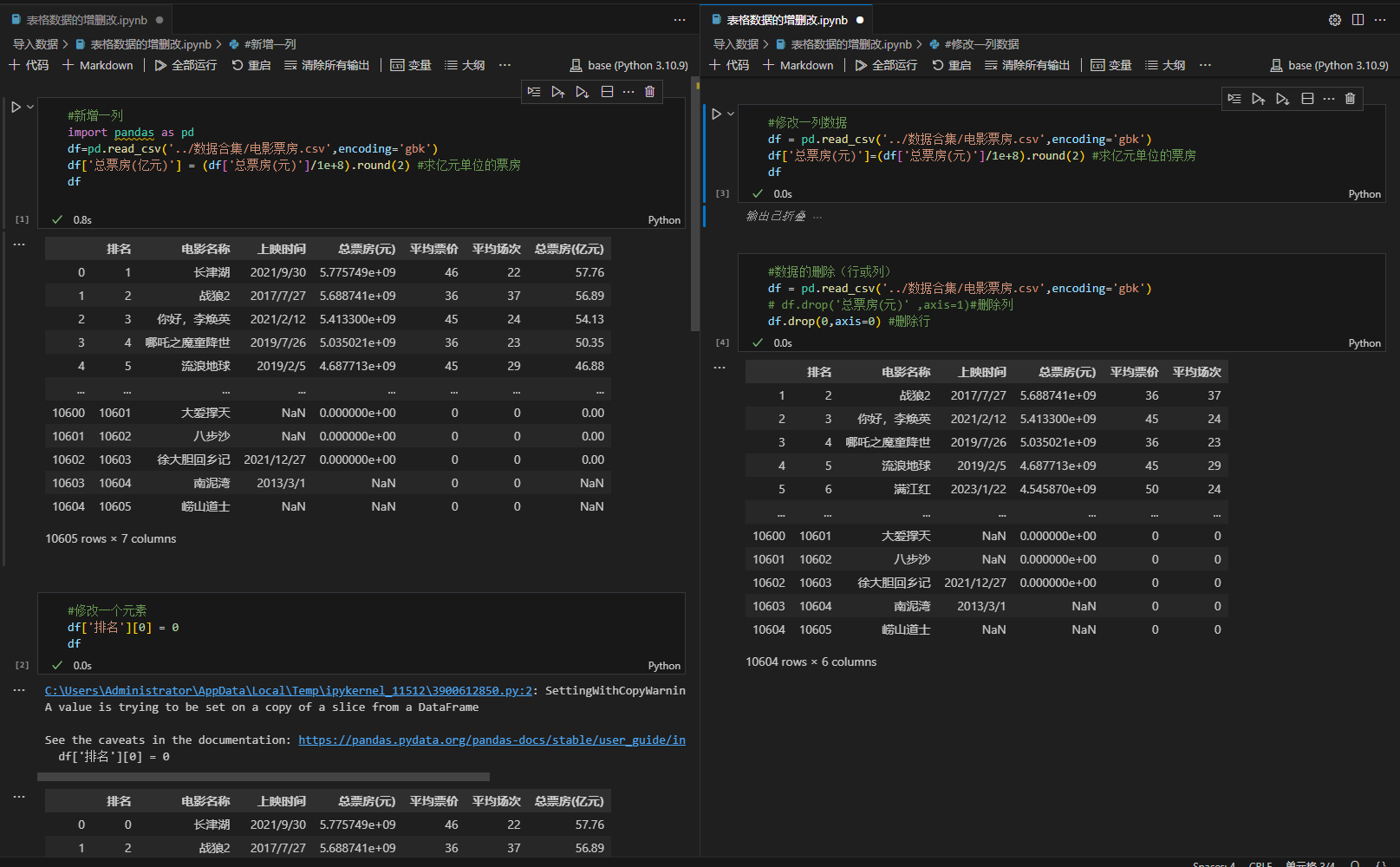
6.3、数据增加(增)操作
(一)新增列:换算总票房(亿元)
为了更直观查看票房的亿元量级数据,新增 “总票房(亿元)” 列,通过对 “总票房(元)” 列换算得到,代码:
# 总票房(元)转亿元,除以 1e8 并保留 2 位小数
df['总票房(亿元)'] = (df['总票房(元)'] / 1e8).round(2)
print("\n新增'总票房(亿元)'列后:")
print(df[['电影名称', '总票房(元)', '总票房(亿元)']].head())借助 Pandas 向量运算,简洁实现新列创建与数据计算,让票房数据呈现更贴合日常习惯 。
6.4、数据修改(改)操作
(一)修改单个元素:修正排名数据
发现数据中排名存在需要修正的情况,比如将索引为 0 位置的排名修改,代码:
# 修改排名列索引为 0 的元素值
df['排名'][0] = 0
print("\n修改单个排名元素后:")
print(df[['排名', '电影名称']].head(2))
# 注:此处可能触发 SettingWithCopyWarning,更规范的写法可用 df.loc[0, '排名'] = 0 虽然简单赋值可实现,但要注意 Pandas 的警告提示,规范写法推荐使用 loc 方法精准定位修改,避免潜在数据问题 。
(二)修改一列数据:重新换算总票房(亿元)
若想重新调整总票房(亿元)的换算逻辑,比如更换保留小数位数,重新计算该列数据:
# 重新换算,保留 1 位小数
df['总票房(亿元)'] = (df['总票房(元)'] / 1e8).round(1)
print("\n修改'总票房(亿元)'列数据后:")
print(df[['电影名称', '总票房(元)', '总票房(亿元)']].head())通过直接对列赋值,实现整列数据的批量修改,灵活调整数据计算规则 。
6.5、数据删除(删)操作
(一)删除列:移除 “总票房(元)” 列
当不需要 “总票房(元)” 列数据时,可删除该列,代码:
# axis=1 表示操作列,inplace=True 直接在原 DataFrame 生效(也可赋值给新变量)
df.drop('总票房(元)', axis=1, inplace=True)
print("\n删除'总票房(元)'列后:")
print(df.head())drop 方法结合 axis 参数,轻松实现列删除,让表格结构更贴合需求 。
(二)删除行:按条件删除
假设要删除 “总票房 (亿元)” 为 0.0 的行(无效数据),代码:
# 筛选出总票房(亿元) 不等于 0 的行,重新赋值给 df
df = df[df['总票房(亿元)'] != 0]
print("\n删除总票房(亿元)为 0 的行后:")
print(df.head())利用布尔索引筛选,简洁实现行删除,清理无效数据,让分析更聚焦有效内容 。
6.6、表格数据增删改的实践总结与思考
通过电影票房数据的增、删、改实践,我熟练掌握了 Pandas 库的核心操作。在过程中,也发现规范使用修改方法(如 loc )可避免警告,删除操作需谨慎筛选条件。这些基础操作是数据分析的基石,后续计划结合更多复杂场景(如多表关联增删改)深入学习。
以下是我的实操图片
七、数据类型转换实战
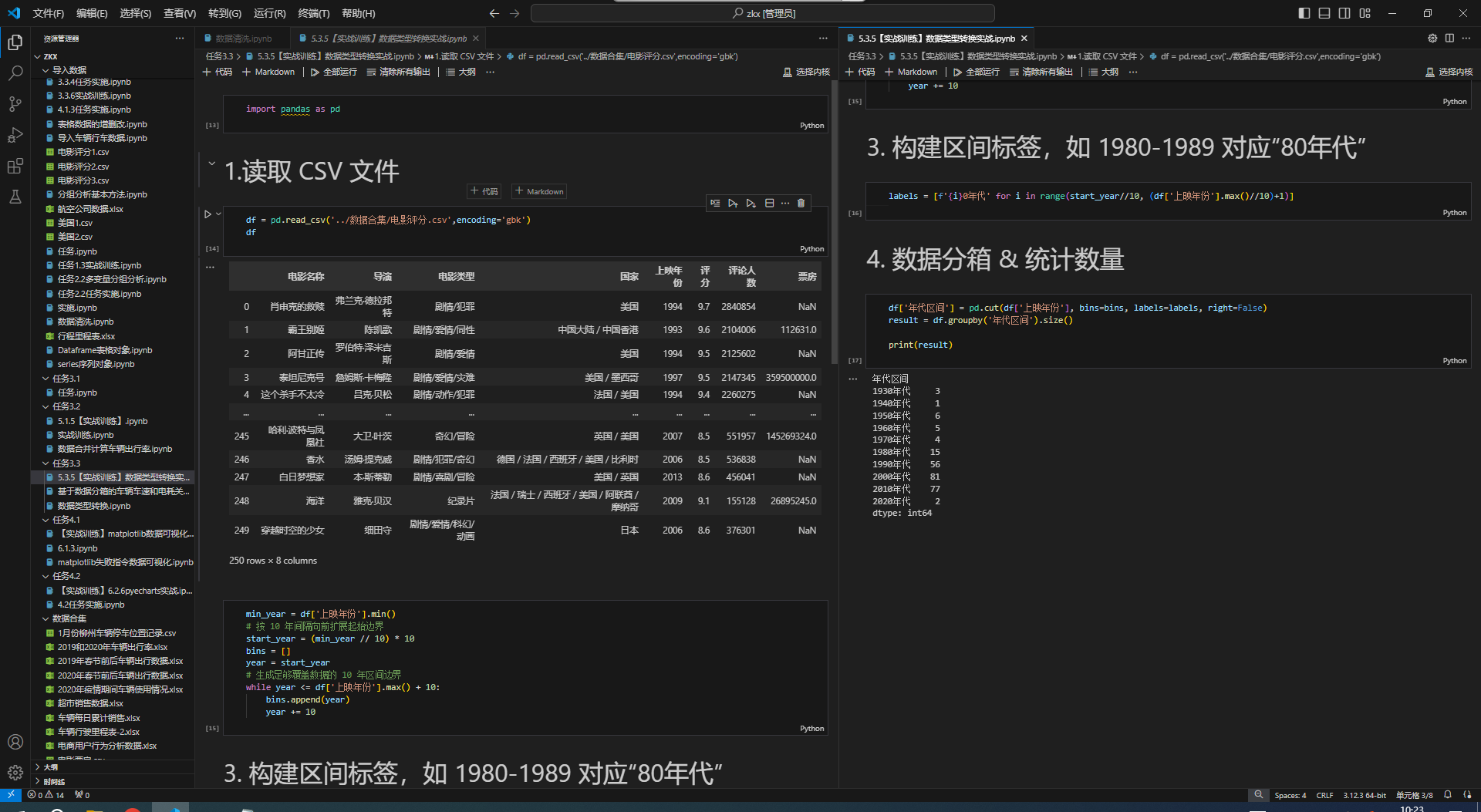
在数据分析过程中,原始数据的数据类型可能并不符合分析需求,因此数据类型转换是一项重要的操作。在Python和Pandas中,有多种方式可以实现数据类型的转换。
例子:以10年为一个年代区间,统计各年代(...、80年代、90年代、00年代、...)的高分电影数量
使用数据分箱方法实现。
八、数据分析实战——用数据解决问题
8.1分组聚合:挖掘分组规律
课程里分组聚合的知识超实用,能按某个或多个列分组,计算其他列的统计量。比如按“地区”分组,求“销售额”的总和:
# 按地区分组,计算销售额总和
result = data.groupby('region')['sales'].sum()
print(result)分析公司各地区销售业绩时,用这个方法很快就能看出哪个地区贡献大,为资源分配提供参考。
8.2数据关联:合并多表信息
实际分析中,数据常存在多张表。Pandas 的 merge 方法能合并表,把相关信息整合。比如订单表和用户信息表,通过用户 ID 关联:
# order_data 是订单表,user_info 是用户信息表,按 user_id 关联
merged_data = pd.merge(order_data, user_info, on='user_id')
print(merged_data.head())做用户订单行为分析时,合并表后能同时看到用户信息和订单详情,分析维度更丰富。
九、思维转变:从数据到决策
Python数据分析不仅是技能学习,更是思维重塑。它让我学会用数据说话,面对问题不再凭经验臆断,而是从数据中找依据。分析销售数据时,能通过Python挖掘出不同地区、不同时段的销售规律,为库存管理、营销策划提供数据支撑。这种数据驱动的思维,有助于在工作和生活中做出更理性、更科学的决策,也让我看到数据分析在各行业的巨大应用潜力,激励我持续深入学习,探索更多数据分析的应用场景。
十、总结
(一)理论与实践结合:越用越熟
学 Python 数据分析,光看理论没用,得多动手。课程里的知识点,自己跟着敲代码、改参数、处理不同数据,才能真正掌握。比如一开始对 groupby 理解不深,多做几个分组聚合的练习,就慢慢吃透了。
(二)善用资源:遇到问题别慌
学习中遇到报错、不懂的知识点,CSDN 上的博客、官方文档、论坛,都是很好的老师。我遇到数据合并报错时,在 CSDN 搜关键词,找到别人的解决方案,问题就解决了,大家分享的经验真的能少走很多弯路。
(三)持续学习:数据分析无止境
课程只是入门,数据分析领域一直在发展。后面还想深入学机器学习库(像 Scikit - learn ),把数据分析和机器学习结合,挖掘数据更深层的价值。
十一、结语
初涉 Python 数据分析,语法学习是基石。从基础的数据类型,如整数、浮点数、字符串,到复杂的数据结构,像列表、元组、字典,每一步都需要扎实掌握。通过不断练习基础语法,编写简单程序,我逐渐熟悉了 Python 的语言逻辑,培养起编程思维,这为后续深入学习数据分析库筑牢根基。例如,学会用循环语句遍历数据,用条件判断筛选特定数据,这些看似基础的操作,却是数据处理的关键环节。
当具备一定语法基础后,我开始投身于数据分析库的学习。NumPy 库的出现,让数值计算变得轻而易举。它提供的多维数组和矩阵对象,以及高效的数值运算函数,大大提升了数据处理效率。通过 NumPy,我能快速对大规模数据进行加、减、乘、除等运算,实现数据的批量处理。Pandas 库更是功能强大,它的 DataFrame 数据结构如同一个灵活的表格,便于数据的存储、清洗与分析。我学会了使用 Pandas 读取各种格式的数据文件,处理数据中的缺失值,如用特定值填充或删除缺失行;识别并修正异常值,确保数据的准确性。还能通过数据透视表对数据进行多角度分析,挖掘数据背后隐藏的信息。
数据可视化是 Python 数据分析中极具魅力的部分。Matplotlib 和 Seaborn 库让枯燥的数据鲜活起来。利用 Matplotlib,我能绘制出折线图,清晰展现数据随时间或其他变量的变化趋势;柱状图则能直观对比不同类别数据的大小差异;散点图帮助我发现数据间的潜在关系,判断变量之间是否存在相关性。Seaborn 库在 Matplotlib 基础上,进一步优化了图表样式,只需简单几行代码,就能生成美观专业的图表,如带有拟合曲线的回归图、展示数据分布的箱线图等。通过调整图表的颜色、字体、标签等细节,我能让图表更准确传达数据信息,增强其说服力。
学习之路并非一帆风顺,遇到复杂数据问题时,我曾陷入迷茫。比如处理高维数据时,数据特征过多导致分析困难,运行代码出现各种错误。但正是这些挑战,促使我不断查阅官方文档、参考专业书籍、请教经验丰富的前辈,逐渐找到解决办法。在这个过程中,我的技术能力不断提升,更培养了独立思考、耐心钻研和解决问题的能力。
如今,我深刻体会到 Python 数据分析的强大魅力。它不仅让我能从海量数据中提取有价值的信息,为决策提供有力支持,还重塑了我的思维方式,让我在面对问题时,习惯从数据角度出发,寻找数据依据,理性分析解决。未来,我将持续深入学习,探索更多高级分析技术,如机器学习算法在数据分析中的应用,将 Python 数据分析更好地应用到实际工作与生活中,挖掘数据背后更多的奥秘,创造更大价值。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐



 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)