第五章 决策树模型
决策树是机器学习中最直观且易于理解的模型之一,它通过树形结构模拟人类决策过程。本章将系统介绍决策树的核心思想、特征选择方法、生成算法以及剪枝过程,帮助读者掌握这一重要模型。
第五章 决策树模型:从数据中学习的树形规则
决策树是机器学习中最直观且易于理解的模型之一,它通过树形结构模拟人类决策过程。本章将系统介绍决策树的核心思想、特征选择方法、生成算法以及剪枝过程,帮助读者掌握这一重要模型。

一、决策树的基本思想
1.1 什么是决策树
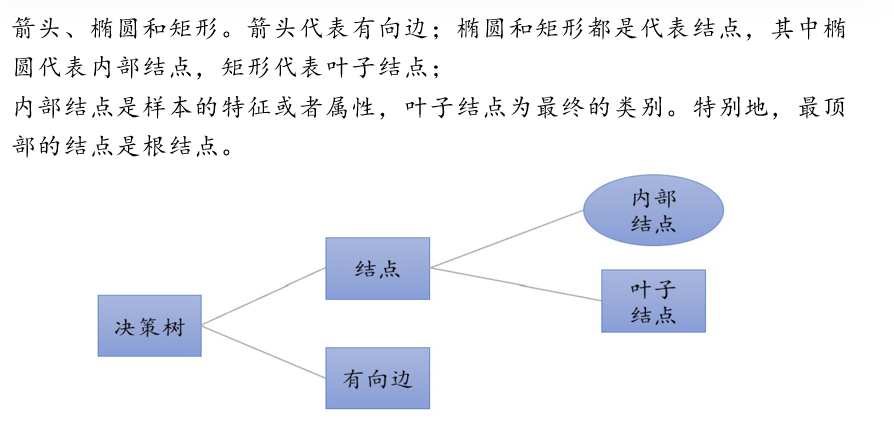
决策树是一种树形结构的分类与回归模型,由结点和有向边组成:
- 内部结点:表示特征或属性测试
- 分支:代表特征的可能取值
- 叶结点:存放类别标签或回归值
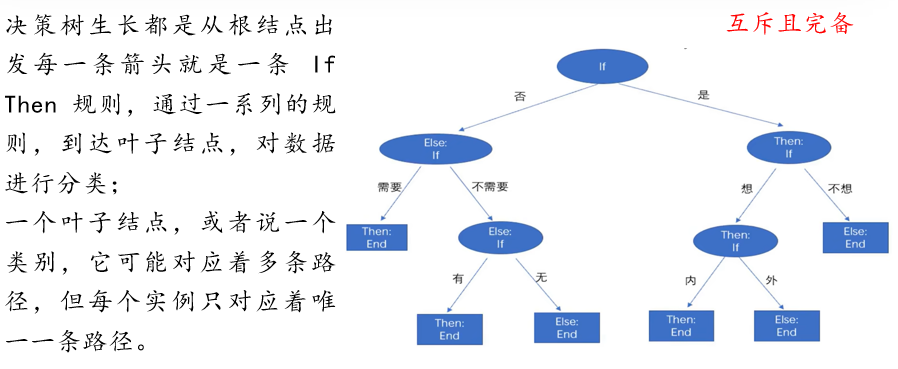
决策过程:从根结点开始,对实例的某个特征进行测试,根据测试结果将实例分配到子结点,递归执行直到到达叶结点。
1.2 决策树的核心特点
- 归纳学习:从训练数据中归纳出一系列决策规则
- 演绎预测:对新实例应用这些规则进行分类
- 互斥完备:每个实例有且仅有一条从根到叶的路径
- 规则直观:决策路径可解释为"if-then"规则
1.3 决策树的类型
- 分类树:叶结点为离散类别标签
- 回归树:叶结点为连续数值预测
- 多输出树:同时预测多个目标变量
1.4 决策树的优势与局限
优势:
- 模型直观,易于理解和解释
- 不需要数据预处理(如标准化)
- 能处理数值型和类别型特征
- 可以可视化分析
局限:
- 容易过拟合,泛化能力差
- 对数据变化敏感(不稳定)
- 倾向于选择类别多的特征
- 难以学习复杂关系(如异或问题)
二、决策树的特征选择
2.1 特征选择的核心问题
决策树构建过程中,每个结点需要选择最优划分特征,这需要解决两个关键问题:
- 如何量化特征对分类的贡献?
- 如何避免选择无意义的特征?
2.2 信息增益(ID3算法)
信息熵:度量样本集合纯度的指标
H(D) = -Σpₖlog₂pₖ
其中pₖ是第k类样本在D中的比例
条件熵:已知特征A的条件下D的不确定性
H(D|A) = Σ(|Dᵥ|/|D|)H(Dᵥ)
信息增益:
g(D,A) = H(D) - H(D|A)
表示特征A对数据集D分类不确定性的减少程度

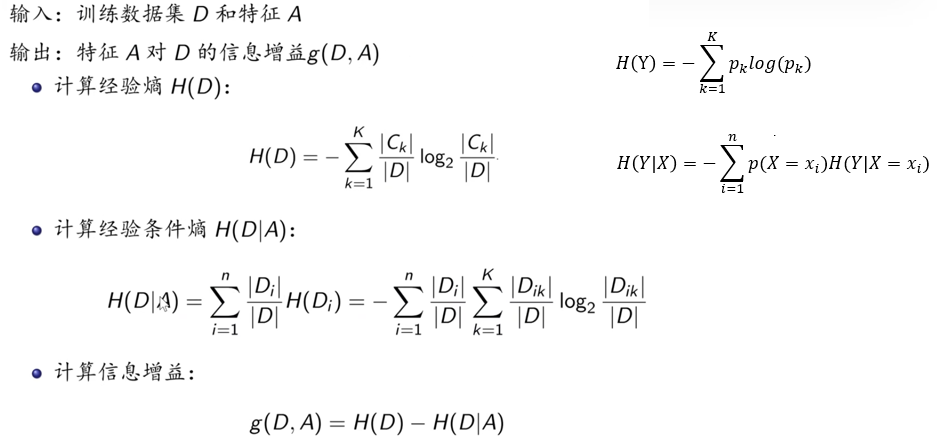
泰坦尼克号案例:
- 性别特征的信息增益:0.1400
- 年龄特征的信息增益:0.0062
- 舱位特征的信息增益:0.0578
2.3 信息增益比(C4.5算法)
为解决信息增益偏向多值特征的问题,引入信息增益比:
gᵣ(D,A) = g(D,A)/Hₐ(D)
其中Hₐ(D)是特征A的熵

2.4 基尼指数(CART算法)
基尼指数衡量数据集D的不纯度:
Gini(D) = 1 - Σpₖ²
基尼指数越小,数据纯度越高
特征A的基尼指数定义为:
Gini(D,A) = Σ(|Dᵥ|/|D|)Gini(Dᵥ)
2.5 特征选择方法比较
| 方法 | 算法 | 特点 | 适用场景 |
|---|---|---|---|
| 信息增益 | ID3 | 偏向多值特征 | 类别型特征 |
| 信息增益比 | C4.5 | 校正多值偏好 | 混合型特征 |
| 基尼指数 | CART | 计算效率高 | 分类与回归 |
三、决策树的生成算法
3.1 ID3算法
核心思想:递归地选择信息增益最大的特征进行划分
算法步骤:
- 计算所有特征的信息增益
- 选择信息增益最大的特征作为当前结点
- 对该特征的每个取值建立子结点
- 递归执行直到满足停止条件
停止条件:
- 所有样本属于同一类别
- 无剩余特征可用
- 信息增益小于阈值
3.2 C4.5算法
改进点:
- 使用信息增益比替代信息增益
- 处理连续值特征(二分法)
- 处理缺失值
- 引入剪枝步骤
连续值处理:
- 对连续特征A的取值排序
- 计算相邻值的中间点作为候选划分点
- 选择信息增益比最大的划分点
3.3 CART算法
特点:
- 二叉树结构(每次产生两个分支)
- 分类树使用基尼指数
- 回归树使用平方误差
回归树生成:
- 选择最优切分变量j和切分点s
- 最小化平方误差:
min[minΣ(yᵢ-c₁)² + minΣ(yᵢ-c₂)²] - c₁和c₂为区域R₁和R₂的输出均值
3.4 决策树生成案例
贷款审批案例:
- 根结点选择"是否有房产"(信息增益最大)
- 有房产分支直接拒绝贷款
- 无房产分支继续考察"收入水平"
- 最终形成包含4个叶结点的决策树
四、决策树的剪枝过程
4.1 过拟合问题
决策树容易过拟合,表现为:
- 训练误差很低但测试误差很高
- 树结构过于复杂
- 包含过多噪声导致的异常分支
4.2 剪枝策略
预剪枝:
- 在生成过程中提前停止树的生长
- 方法:限制树深度、最小样本数等
- 优点:计算效率高
- 缺点:可能欠拟合
后剪枝:
- 先生成完整树,再自底向上剪枝
- 方法:代价复杂度剪枝
- 优点:保留更多有用结构
- 缺点:计算成本高
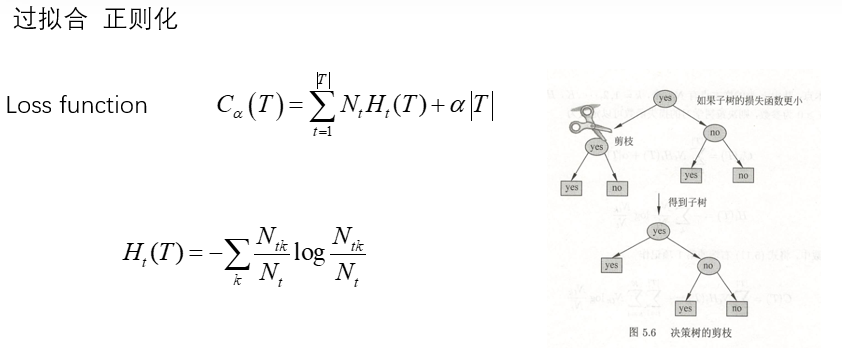

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)